[2025/07/28 ~ 08/03] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 이번 주 선정된 논문들을 살펴보면, 첫째로 복잡한 문제 해결을 위한 계층적이고 구조화된 추론 모델에 대한 연구가 두드러집니다. 인간 두뇌의 다중 시간 스케일 처리에서 영감을 받은 계층적 추론 모델(HRM)과 같이, 추론 과정을 고수준의 계획과 저수준의 세부 계산으로 분리하여 효율성과 안정성을 동시에 추구하는 접근법이 주목받고 있습니다. 이러한 모델들은 적은 데이터와 파라미터 수로도 복잡한 문제를 해결하며, 범용 인공지능으로 나아가기 위한 중요한 진전으로 평가됩니다.
이번 주 선정된 논문들을 살펴보면, 첫째로 복잡한 문제 해결을 위한 계층적이고 구조화된 추론 모델에 대한 연구가 두드러집니다. 인간 두뇌의 다중 시간 스케일 처리에서 영감을 받은 계층적 추론 모델(HRM)과 같이, 추론 과정을 고수준의 계획과 저수준의 세부 계산으로 분리하여 효율성과 안정성을 동시에 추구하는 접근법이 주목받고 있습니다. 이러한 모델들은 적은 데이터와 파라미터 수로도 복잡한 문제를 해결하며, 범용 인공지능으로 나아가기 위한 중요한 진전으로 평가됩니다.
![]() 둘째로, 강화학습(RL)과 감독학습(SFT)의 경계가 점차 모호해지면서 두 학습 방식을 통합하거나 강화하는 연구가 활발합니다. 감독학습을 강화학습의 관점에서 재해석하고, 중요도 가중치를 도입해 RL 목표에 더 근접하도록 개선한 iw-SFT, 그리고 강화학습을 통해 모델의 불확실성 추론과 보정 능력을 동시에 향상시키는 RLCR 등이 대표적입니다. 또한, 검색 엔진 활용과 같은 외부 도구 호출을 최적화하는 강화학습 프레임워크도 등장하여, 모델의 효율성과 실용성을 높이는 데 기여하고 있습니다.
둘째로, 강화학습(RL)과 감독학습(SFT)의 경계가 점차 모호해지면서 두 학습 방식을 통합하거나 강화하는 연구가 활발합니다. 감독학습을 강화학습의 관점에서 재해석하고, 중요도 가중치를 도입해 RL 목표에 더 근접하도록 개선한 iw-SFT, 그리고 강화학습을 통해 모델의 불확실성 추론과 보정 능력을 동시에 향상시키는 RLCR 등이 대표적입니다. 또한, 검색 엔진 활용과 같은 외부 도구 호출을 최적화하는 강화학습 프레임워크도 등장하여, 모델의 효율성과 실용성을 높이는 데 기여하고 있습니다.
![]() 마지막으로, 시각 정보만으로 복잡한 추론을 수행하고 스스로 피드백을 통해 학습하는 멀티모달 및 자율 학습 방법론이 부상하고 있습니다. 이미지 기반 강화학습과 렌더링, 시각적 피드백을 결합한 RRVF 프레임워크는 이미지-텍스트 쌍에 의존하지 않고도 강력한 시각 추론 능력을 보여주며, 이는 향후 멀티모달 AI의 자율성과 일반화 가능성을 크게 확장할 것으로 기대됩니다. 이와 함께, 영상 예측과 행동 계획을 결합한 비디오 월드 모델 연구도 시각 정보를 활용한 환경 이해와 예측 능력 향상에 중요한 기여를 하고 있습니다.
마지막으로, 시각 정보만으로 복잡한 추론을 수행하고 스스로 피드백을 통해 학습하는 멀티모달 및 자율 학습 방법론이 부상하고 있습니다. 이미지 기반 강화학습과 렌더링, 시각적 피드백을 결합한 RRVF 프레임워크는 이미지-텍스트 쌍에 의존하지 않고도 강력한 시각 추론 능력을 보여주며, 이는 향후 멀티모달 AI의 자율성과 일반화 가능성을 크게 확장할 것으로 기대됩니다. 이와 함께, 영상 예측과 행동 계획을 결합한 비디오 월드 모델 연구도 시각 정보를 활용한 환경 이해와 예측 능력 향상에 중요한 기여를 하고 있습니다.
이처럼 이번 주 논문들은 인간의 인지 구조를 모방한 계층적 추론, 강화학습과 감독학습의 융합을 통한 학습 효율성 극대화, 그리고 시각 정보를 중심으로 한 자율적 멀티모달 학습이라는 세 가지 큰 흐름을 보여주고 있습니다. 이는 인공지능이 보다 복잡하고 현실적인 문제를 효과적으로 해결하기 위한 방향성을 제시하며, 향후 연구와 응용에 중요한 시사점을 제공할 것입니다.
계층적 추론 모델 / Hierarchical Reasoning Model
논문 소개
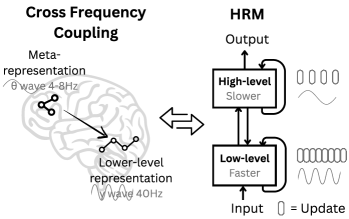
계층적 추론 모델(Hierarchical Reasoning Model, HRM)은 인간 두뇌의 계층적이고 다중 시간 척도 처리 방식을 모방하여 설계된 순환 신경망 구조입니다. HRM은 느리고 추상적인 계획을 담당하는 고수준 모듈과 빠르고 세밀한 계산을 수행하는 저수준 모듈로 구성되어, 중간 과정에 대한 명시적 감독 없이 단일 순전파로 연속적 추론을 수행합니다. 2,700만 개의 파라미터로 1,000개의 학습 샘플만으로도 복잡한 스도쿠 문제와 대규모 미로 최적 경로 탐색 등에서 뛰어난 성능을 보이며, 사전 학습이나 체인 오브 쏘트(Chain-of-Thought, CoT) 데이터 없이도 높은 정확도를 달성합니다. 또한, HRM은 인공지능의 일반화 능력을 평가하는 Abstraction and Reasoning Corpus(ARC)에서 훨씬 큰 모델들을 능가하며, 범용 계산 및 일반 추론 시스템 개발에 중요한 진전을 제시합니다.
논문 초록(Abstract)
추론은 복잡하고 목표 지향적인 행동 시퀀스를 고안하고 실행하는 과정으로, AI 분야에서 여전히 중요한 도전 과제입니다. 현재의 대형 언어 모델(LLM)은 주로 사고의 연쇄(CoT) 기법을 사용하지만, 이는 취약한 작업 분해, 방대한 데이터 요구량, 그리고 높은 지연 시간 문제를 안고 있습니다. 인간 뇌의 계층적이고 다중 시간 척도 처리에서 영감을 받아, 본 논문에서는 학습 안정성과 효율성을 유지하면서도 상당한 계산 깊이를 달성하는 새로운 순환 구조인 계층적 추론 모델(HRM)을 제안합니다. HRM은 중간 과정에 대한 명시적 감독 없이 단일 순전파(forward pass)로 순차적 추론 작업을 수행하며, 느리고 추상적인 계획을 담당하는 고수준 모듈과 빠르고 세밀한 계산을 처리하는 저수준 모듈, 이 두 개의 상호 의존적인 순환 모듈로 구성됩니다. 단 2,700만 개의 파라미터만으로 HRM은 1,000개의 학습 샘플만으로도 복잡한 추론 작업에서 뛰어난 성능을 보입니다. 사전 학습이나 CoT 데이터 없이도 복잡한 스도쿠 퍼즐과 대규모 미로에서의 최적 경로 탐색과 같은 어려운 과제에서 거의 완벽한 성능을 달성합니다. 더 나아가, HRM은 인공 일반 지능 능력 측정의 핵심 벤치마크인 Abstraction and Reasoning Corpus(ARC)에서 훨씬 더 큰 모델들과 긴 컨텍스트 윈도우를 가진 모델들을 능가하는 성과를 보입니다. 이러한 결과는 HRM이 범용 계산 및 범용 추론 시스템을 향한 혁신적 진보로서의 잠재력을 지님을 강조합니다.
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency. HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes. Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities. These results underscore HRM's potential as a transformative advancement toward universal computation and general-purpose reasoning systems.
논문 링크
선별된 데이터 기반 감독 학습 미세조정(SFT)은 강화학습(RL)이며 개선 가능함 / Supervised Fine Tuning on Curated Data is Reinforcement Learning (and can be improved)
논문 소개
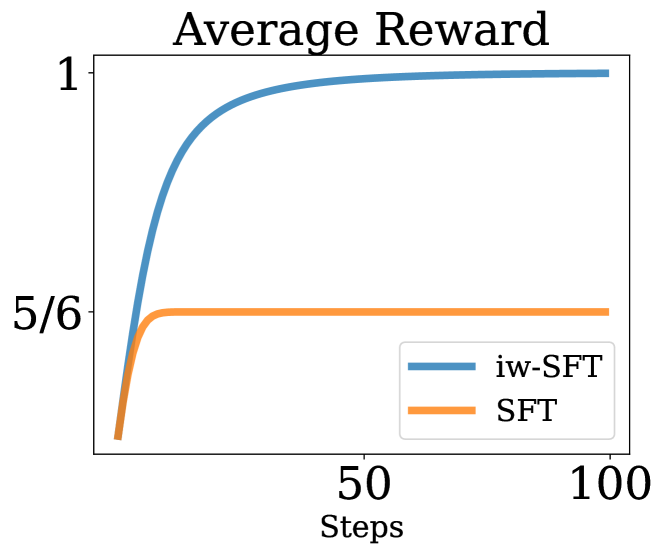
대규모 언어 모델의 감독 미세조정(Supervised Fine-Tuning, SFT)은 주로 선별된 데이터에 대한 행동 복제(Behavior Cloning, BC) 방식으로 수행되며, 이는 강화학습(Reinforcement Learning, RL)에서 최적 정책을 찾는 이론과 실무와 밀접한 관련이 있음을 밝힙니다. SFT는 희소 보상(sparse reward) 환경에서 RL 목표의 하한(lower bound)을 최대화하는 과정으로 이해할 수 있으며, 이 관점에서 작은 변형을 통해 중요도 가중치(importance weighting)를 적용한 iw-SFT가 제안됩니다. iw-SFT는 RL 목표에 대한 더 엄밀한 하한을 최적화하며, 기존 SFT보다 성능 향상이 가능하고 구현이 용이합니다. 또한, 품질 점수(quality scored)를 반영한 데이터로 일반화할 수 있어, 대규모 언어 모델과 연속 제어(continuous control) 작업에서 고급 RL 알고리즘과 경쟁력 있는 성과를 보입니다.
논문 초록(Abstract)
행동 복제(Behavior Cloning, BC)는 선별(또는 필터링)된 데이터에서 대규모 언어 모델(LLM)의 감독 학습 기반 미세 조정(supervised fine-tuning, SFT)뿐만 아니라 제어 정책의 모방 학습(imitation learning)에서 주된 패러다임입니다. 본 논문에서는 이 성공적인 전략과 강화 학습(Reinforcement Learning, RL)을 통한 최적 정책 탐색 이론 및 실무 간의 연관성을 고찰합니다. 기존 문헌을 바탕으로, SFT가 희소 보상(sparse reward) 환경에서 RL 목표 함수의 하한(lower bound)을 최대화하는 관점으로 이해될 수 있음을 명확히 하여, SFT가 종종 우수한 성능을 보이는 이유를 뒷받침합니다. 이러한 관점에서, SFT에 소규모 수정을 가하면 중요도 가중치(importance weighting)를 적용한 변형이 되어, i) RL 목표 함수에 대한 더 엄밀한 하한을 최적화하고, ii) 선별된 데이터에서의 기존 SFT보다 성능 향상이 가능함을 확인하였습니다. 이를 중요도 가중 감독 학습 미세 조정(importance weighted supervised fine-tuning, iw-SFT)이라 명명합니다. 본 방법은 구현이 용이하며, 품질 점수(quality scored) 데이터 학습으로도 확장 가능합니다. 제안된 SFT 변형들은 대규모 언어 모델 및 연속 제어(continuous control) 작업에서 정책 학습을 위한 고도화된 RL 알고리즘과 경쟁력 있는 성능을 보이며, 예를 들어 AIME 2024 데이터셋에서 66.7%의 성과를 달성하였습니다.
Behavior Cloning (BC) on curated (or filtered) data is the predominant paradigm for supervised fine-tuning (SFT) of large language models; as well as for imitation learning of control policies. Here, we draw on a connection between this successful strategy and the theory and practice of finding optimal policies via Reinforcement Learning (RL). Building on existing literature, we clarify that SFT can be understood as maximizing a lower bound on the RL objective in a sparse reward setting. Giving support to its often observed good performance. From this viewpoint, we realize that a small modification to SFT leads to an importance weighted variant that behaves closer to training with RL as it: i) optimizes a tighter bound to the RL objective and, ii) can improve performance compared to SFT on curated data. We refer to this variant as importance weighted supervised fine-tuning (iw-SFT). We show that it is easy to implement and can be further generalized to training with quality scored data. The resulting SFT variants are competitive with more advanced RL algorithms for large language models and for training policies in continuous control tasks. For example achieving 66.7% on the AIME 2024 dataset.
논문 링크
더 읽어보기
이미지만으로 학습하는 시각 강화학습: 추론, 렌더링, 시각 피드백 기반 접근법 / Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
논문 소개
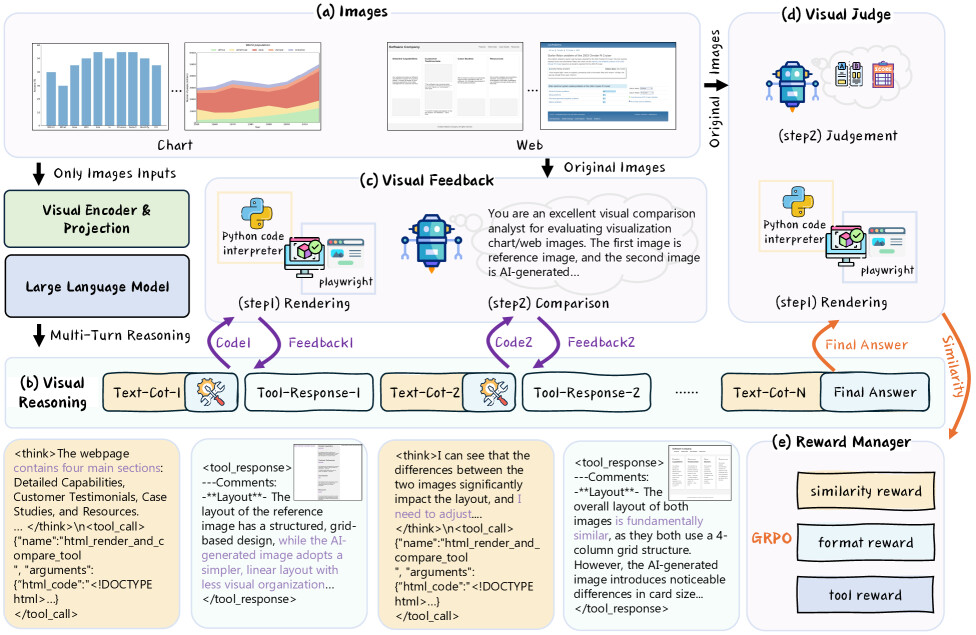
멀티모달 대형 언어 모델(MLLM)은 다양한 시각적 작업에서 뛰어난 성능을 보이나, 정제된 이미지-텍스트 감독에 크게 의존하는 한계가 있습니다. 이를 극복하기 위해, RRVF(Reasoning-Rendering-Visual-Feedback)라는 새로운 프레임워크를 제안하여 원시 이미지 만으로 복잡한 시각적 추론 학습이 가능하도록 하였습니다. 이 방법은 ‘검증의 비대칭성(Asymmetry of Verification)’ 원리를 활용해 렌더링된 출력과 원본 이미지를 비교하는 과정을 강화학습(RL)의 보상 신호로 삼아, 이미지-텍스트 감독 의존도를 낮춥니다. 실험 결과, RRVF는 데이터 차트 및 웹 인터페이스의 이미지-코드 생성에서 기존 공개 MLLM과 감독 학습 기반 기법을 뛰어넘는 성능을 보이며, 순수 시각적 피드백만으로도 견고하고 일반화 가능한 추론 모델 개발이 가능함을 입증하였습니다.
논문 초록(Abstract)
다중모달 대형 언어 모델(MLLM)은 다양한 시각적 과제에서 뛰어난 성능을 보여주고 있습니다. 이후 시각적 추론 능력 향상을 위한 연구들은 이들의 성능 범위를 크게 확장시켰습니다. 그러나 MLLM이 심층 시각 추론으로 발전하는 데 있어 중요한 병목 현상은 엄선된 이미지-텍스트 감독 데이터에 과도하게 의존한다는 점입니다. 이를 해결하기 위해, 본 논문에서는 MLLM이 원시 이미지(raw images)만으로 복잡한 시각 추론을 학습할 수 있도록 하는 새로운 프레임워크인 “Reasoning-Rendering-Visual-Feedback”(RRVF)를 제안합니다. 이 프레임워크는 “검증의 비대칭성(Asymmetry of Verification)” 원리를 기반으로 하며, 즉 렌더링된 출력물을 원본 이미지와 비교하여 검증하는 것이 이를 생성하는 것보다 더 쉽다는 점에 착안하였습니다. 우리는 이러한 상대적 용이성이 강화학습(RL)을 통한 최적화에 이상적인 보상 신호를 제공하여 이미지-텍스트 감독 의존도를 줄여준다는 것을 입증합니다. 위 원리에 따라 RRVF는 추론(reasoning), 렌더링(rendering), 시각적 피드백(visual feedback) 구성 요소를 포함하는 폐쇄형 반복 프로세스를 구현하며, 이를 통해 모델은 다회차 상호작용과 도구 호출(tool invocation)을 통해 자기 수정(self-correction)을 수행할 수 있습니다. 또한 이 파이프라인은 GRPO 알고리즘으로 종단 간(end-to-end) 최적화가 가능합니다. 데이터 차트 및 웹 인터페이스의 이미지-코드 생성에 관한 광범위한 실험 결과, RRVF는 기존 오픈소스 MLLM을 크게 능가하며 감독 학습 기반 미세조정(fine-tuning) 기준선도 뛰어넘는 성능을 보였습니다. 본 연구 결과는 순수한 시각적 피드백에 기반한 시스템이 명시적 감독 없이도 더욱 견고하고 일반화 가능한 추론 모델로 나아갈 수 있는 유효한 경로임을 입증합니다. 코드 저장소는 GitHub - L-O-I/RRVF · GitHub 에서 제공될 예정입니다.
Multimodal Large Language Models (MLLMs) have exhibited impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed
Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on theAsymmetry of Verification'' principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing the reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions and tool invocation, while this pipeline can be optimized by the GRPO algorithm in an end-to-end manner. Extensive experiments on image-to-code generation for data charts and web interfaces show that RRVF substantially outperforms existing open-source MLLMs and surpasses supervised fine-tuning baselines. Our findings demonstrate that systems driven by purely visual feedback present a viable path toward more robust and generalizable reasoning models without requiring explicit supervision. Code will be available at GitHub - L-O-I/RRVF · GitHub.
논문 링크
더 읽어보기
특징으로 돌아가기: 비디오 월드 모델의 기반으로서의 DINO / Back to the Features: DINO as a Foundation for Video World Models
논문 소개
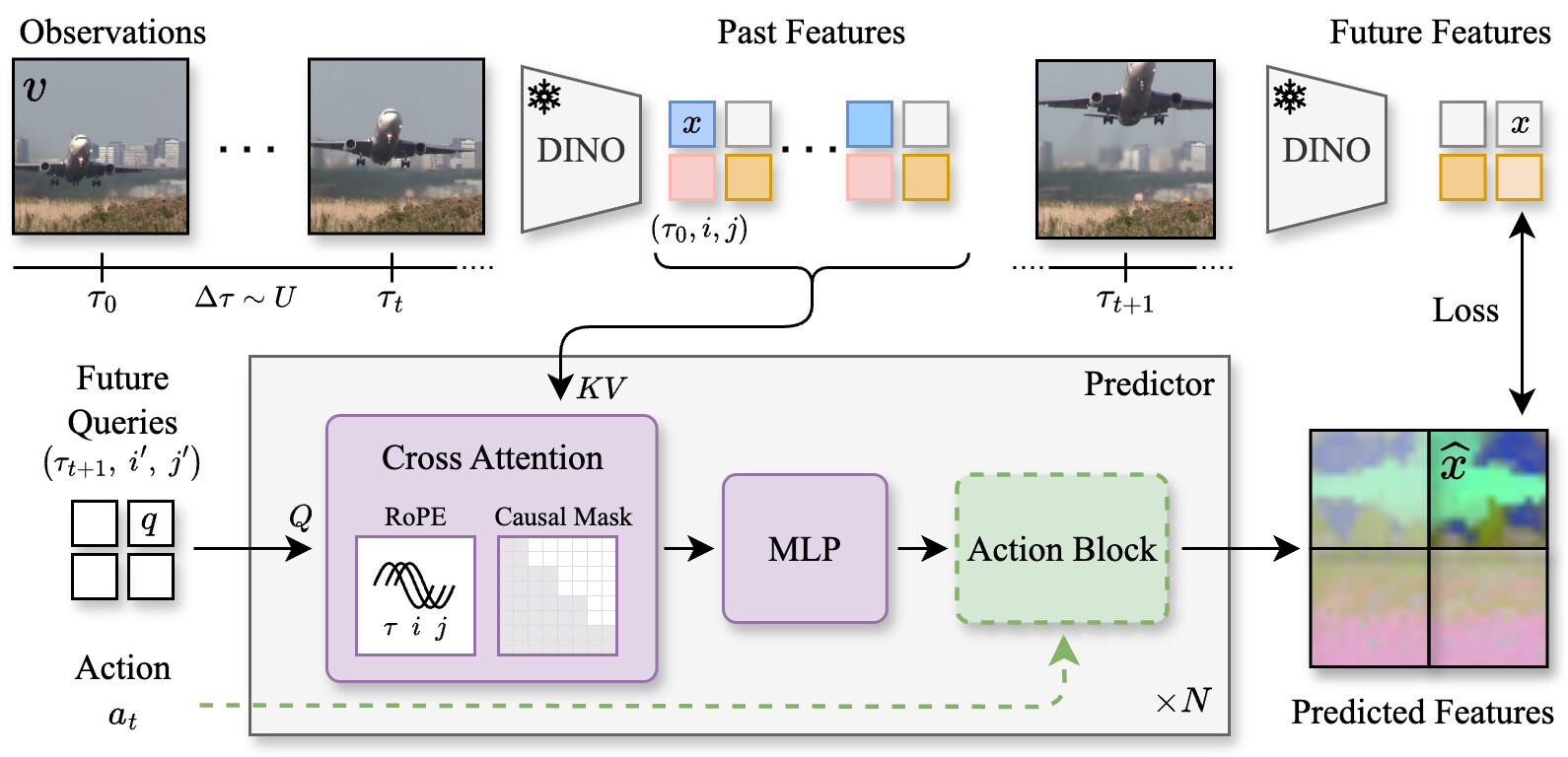
DINO-world는 DINOv2의 잠재 공간(latent space)에서 미래 프레임을 예측하도록 학습된 강력한 범용 비디오 월드 모델입니다. 사전 학습된 이미지 인코더를 활용하고 대규모 비선별 비디오 데이터셋으로 미래 예측기를 학습하여, 주행, 실내, 시뮬레이션 환경 등 다양한 장면의 시간적 역학을 효과적으로 이해합니다. 여러 비디오 예측 벤치마크에서 우수한 성능을 보이며, 직관적인 물리 법칙에 대한 이해도 뛰어납니다. 또한, 관찰-행동 궤적(observation-action trajectories)에 대해 예측기를 미세 조정하여 잠재 공간에서 후보 궤적을 시뮬레이션하는 계획(planning)에도 활용할 수 있습니다.
논문 초록(Abstract)
저희는 DINO-world를 제안합니다. 이는 DINOv2의 잠재 공간(latent space)에서 미래 프레임을 예측하도록 학습된 강력한 범용 비디오 월드 모델입니다. 사전 학습된 이미지 인코더를 활용하고 대규모 비선별 비디오 데이터셋에서 미래 예측기를 학습함으로써, DINO-world는 운전, 실내 장면부터 시뮬레이션 환경에 이르기까지 다양한 장면의 시간적 역학을 학습합니다. 저희는 DINO-world가 분할(segmentation) 및 깊이 예측(depth forecasting) 등 여러 비디오 예측 벤치마크에서 기존 모델들을 능가하며, 직관적 물리학(intuitive physics)에 대한 강한 이해를 보여줌을 입증합니다. 더불어, 관찰-행동 궤적(observation-action trajectories)에 대해 예측기를 미세 조정하는 것이 가능함을 보입니다. 이렇게 얻어진 행동 조건(action-conditioned) 월드 모델은 잠재 공간에서 후보 궤적을 시뮬레이션하여 계획(planning)에 활용될 수 있습니다.
We present DINO-world, a powerful generalist video world model trained to predict future frames in the latent space of DINOv2. By leveraging a pre-trained image encoder and training a future predictor on a large-scale uncurated video dataset, DINO-world learns the temporal dynamics of diverse scenes, from driving and indoor scenes to simulated environments. We show that DINO-world outperforms previous models on a variety of video prediction benchmarks, e.g. segmentation and depth forecasting, and demonstrates strong understanding of intuitive physics. Furthermore, we show that it is possible to fine-tune the predictor on observation-action trajectories. The resulting action-conditioned world model can be used for planning by simulating candidate trajectories in latent space.
논문 링크
Kimi K2: 오픈 에이전틱 인텔리전스 / Kimi K2: Open Agentic Intelligence
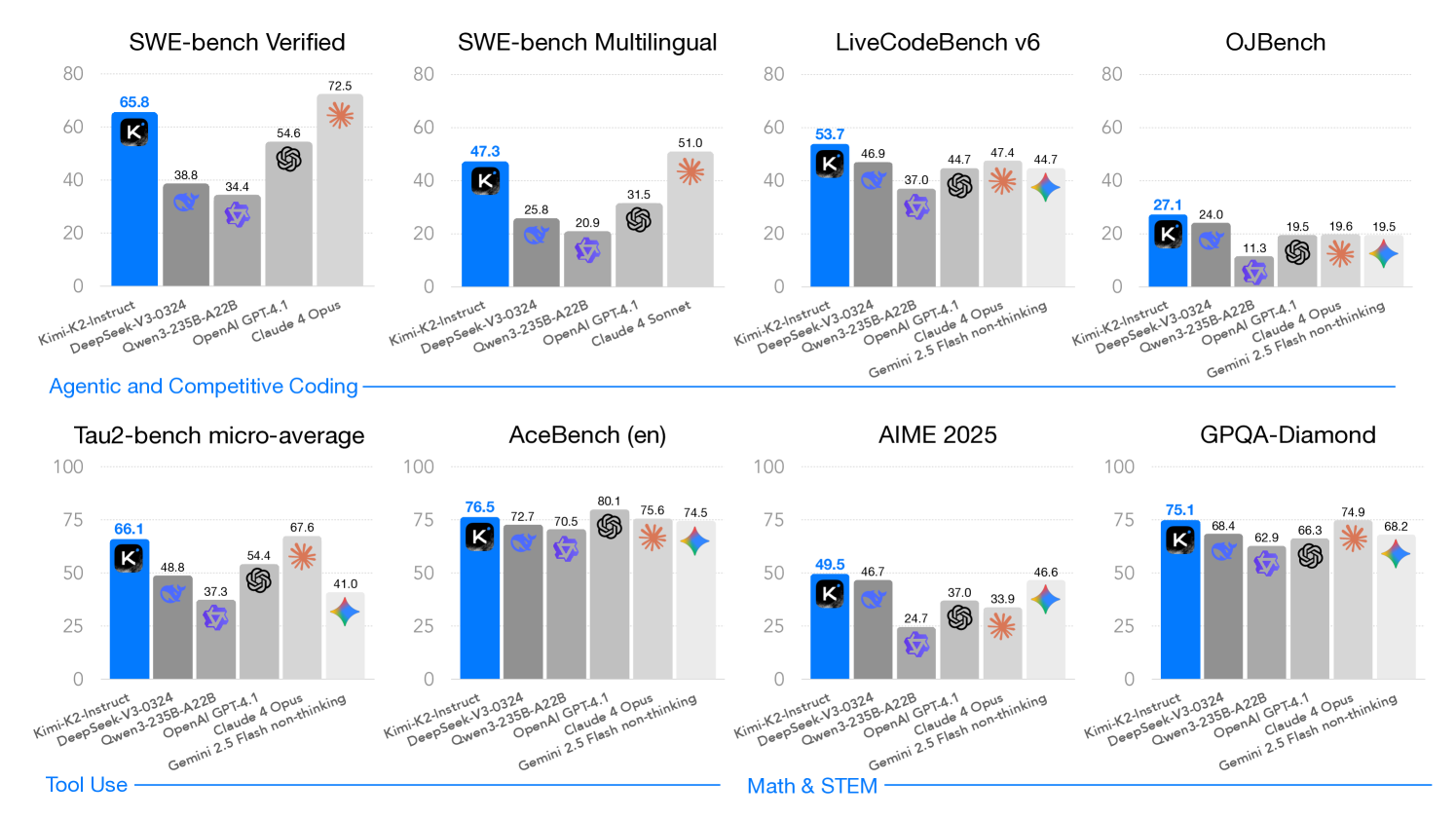
논문 소개
Kimi K2는 320억 활성 파라미터와 총 1조 파라미터를 가진 Mixture-of-Experts(MoE) 대형 언어 모델로, MuonClip 옵티마이저를 통해 학습 불안정을 해결하며 토큰 효율성을 높였습니다. 15.5조 토큰으로 사전학습을 완료한 후, 대규모 에이전트 데이터 합성 및 강화학습(RL) 단계를 포함한 다단계 후학습 과정을 거쳐 성능을 향상시켰습니다. K2는 다양한 벤치마크에서 최첨단 성능을 기록하며, 특히 소프트웨어 엔지니어링과 에이전트 능력 분야에서 뛰어난 역량을 보였습니다. 해당 모델의 체크포인트를 공개하여 에이전트 지능 연구와 응용에 기여하고자 합니다.
논문 초록(Abstract)
저희는 320억 활성화 파라미터와 총 1조 파라미터를 갖춘 Mixture-of-Experts (MoE) 대형 언어 모델인 Kimi K2를 소개합니다. MuonClip 옵티마이저를 제안하는데, 이는 Muon을 기반으로 하여 학습 불안정을 해결하는 새로운 QK-clip 기법을 도입함으로써 Muon의 고급 토큰 효율성을 유지하면서 성능을 향상시켰습니다. MuonClip을 바탕으로 K2는 15.5조 개의 토큰에 대해 손실 스파이크 없이 사전 학습되었습니다. 사후 학습 과정에서는 대규모 에이전트형 데이터 합성 파이프라인과 실제 및 합성 환경과의 상호작용을 통해 모델의 역량을 향상시키는 공동 강화 학습(RL) 단계를 포함하는 다단계 사후 학습 프로세스를 거칩니다. Kimi K2는 오픈소스 비사고(non-thinking) 모델 중 최첨단 성능을 달성하였으며, 특히 에이전트 역량에서 강점을 보입니다. 구체적으로, K2는 Tau2-Bench에서 66.1점, ACEBench(영어)에서 76.5점, SWE-Bench Verified에서 65.8점, SWE-Bench 다국어 평가에서 47.3점을 기록하여 대부분의 오픈 및 폐쇄형(non-thinking) 기준 모델들을 능가합니다. 또한, 확장된 사고 없이도 LiveCodeBench v6에서 53.7점, AIME 2025에서 49.5점, GPQA-Diamond에서 75.1점, OJBench에서 27.1점을 획득하며 코딩, 수학, 추론 과제에서도 뛰어난 역량을 보여줍니다. 이러한 결과는 Kimi K2가 특히 소프트웨어 엔지니어링 및 에이전트형 작업 분야에서 현재까지 가장 유능한 오픈소스 대형 언어 모델 중 하나임을 입증합니다. 저희는 에이전트형 인텔리전스의 향후 연구 및 응용을 촉진하기 위해 기본 및 사후 학습된 모델 체크포인트를 공개합니다.
We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
논문 링크
더 읽어보기
확률적 모델의 주문형 합성으로서의 개방형 인지 모델링 / Modeling Open-World Cognition as On-Demand Synthesis of Probabilistic Models

논문 소개
사람들은 새로운 상황에 직면했을 때 광범위한 배경 지식에서 관련 정보를 선택하여 추론과 예측에 활용할 수 있다. 이를 설명하기 위해 분산 표현과 기호적 표현을 결합해 상황에 맞는 맞춤형 확률 모델을 생성하는 ‘모델 합성 아키텍처(Model Synthesis Architecture, MSA)’를 제안하였다. MSA는 언어 모델을 활용해 전역적 관련 정보를 검색하고, 확률 프로그래밍을 통해 일관된 세계 모델을 구성하며, 새로운 인과 구조와 임의 변수에 대한 인간의 판단을 잘 모사함을 실험적으로 입증하였다. 이 접근법은 인간의 개방형 추론 능력을 모방하는 효과적인 방법임을 시사한다.
논문 초록(Abstract)
새로운 상황에 직면했을 때, 사람들은 광범위한 배경 지식에서 관련된 고려사항을 동원하여 추론과 예측에 활용할 수 있습니다. 전 세계적으로 관련된 정보를 끌어오고 이를 일관성 있게 추론할 수 있게 하는 요인은 무엇일까요? 본 논문에서는 사람들이 분산 표현과 기호적 표현을 결합하여 새로운 상황에 맞춘 맞춤형 정신 모델을 구성한다는 가설을 탐구합니다. 우리는 이 아이디어를 계산적으로 구현한 ‘모델 합성 아키텍처(Model Synthesis Architecture, MSA)’를 제안합니다. MSA는 언어 모델을 활용하여 전역 관련성 기반 검색과 모델 합성을 수행하고, 확률적 프로그래밍을 통해 맞춤형이며 일관된 세계 모델을 구현합니다. 우리는 MSA를 인간 판단을 모사하는 모델로서, ‘모델 올림픽(Model Olympics)’이라는 스포츠 단편(domain) 기반의 새로운 추론 데이터셋에서 평가합니다. 이 데이터셋은 (i) 언어로 기술된 새로운 인과 구조에 대한 판단, (ii) 방대한 배경 지식 활용, (iii) 임의의 새로운 변수를 도입하는 관찰을 고려한 추론을 요구함으로써 인간과 유사한 개방형 추론 능력을 테스트합니다. MSA는 모델 합성을 지원하는 언어 모델의 직접 생성 및 사고의 연쇄(CoT) 생성 모두에서, 언어 모델 단독 기반선보다 인간 판단을 더 잘 포착합니다. 이러한 결과는 MSA가 전역적으로 관련된 변수들에 대해 지역적으로 일관된 추론을 수행하는 인간의 능력을 모방하는 방식으로 구현될 수 있음을 시사하며, 개방형 도메인에서 인간 추론을 이해하고 재현하는 길을 제시합니다.
When faced with novel situations, people are able to marshal relevant considerations from a wide range of background knowledge and put these to use in inferences and predictions. What permits us to draw in globally relevant information and reason over it coherently? Here, we explore the hypothesis that people use a combination of distributed and symbolic representations to construct bespoke mental models tailored to novel situations. We propose a computational implementation of this idea -- a ``Model Synthesis Architecture'' (MSA) -- using language models to implement global relevance-based retrieval and model synthesis and probabilistic programs to implement bespoke, coherent world models. We evaluate our MSA as a model of human judgments on a novel reasoning dataset. The dataset -- built around a
Model Olympicsdomain of sports vignettes -- tests models' capacity for human-like, open-ended reasoning by requiring (i) judgments about novel causal structures described in language; (ii) drawing on large bodies of background knowledge; and (iii) doing both in light of observations that introduce arbitrary novel variables. Our MSA approach captures human judgments better than language model-only baselines, under both direct and chain-of-thought generations from the LM that supports model synthesis. These results suggest that MSAs can be implemented in a way that mirrors people's ability to deliver locally coherent reasoning over globally relevant variables, offering a path to understanding and replicating human reasoning in open-ended domains.
논문 링크
이진 보상을 넘어서: 불확실성을 고려한 언어 모델 학습 / Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
논문 소개
언어 모델(언어모델, LM)을 강화학습(강화학습, RL)으로 훈련할 때, 기존에는 정답 여부만을 평가하는 이진 보상 함수가 주로 사용되어 정확도는 향상되나, 추측이나 낮은 신뢰도의 출력에 대한 처벌이 없어 보정(calibration)이 저하되고 오답 생성률이 증가하는 문제가 발생합니다. 본 연구에서는 RLCR(보정 보상 강화학습)을 제안하여, LM이 추론 후 예측과 신뢰도 수치를 함께 생성하고, 이진 정답 점수에 신뢰도 보정을 위한 브라이어 점수(Brier score)를 결합한 보상 함수를 최적화하도록 하였습니다. 이 방법은 정확도와 보정도를 동시에 개선하며, 다양한 데이터셋에서 기존 RL과 사후 신뢰도 추정기법 대비 뛰어난 성능을 보였습니다. 또한, 테스트 시 언어화된 신뢰도를 활용한 가중치 조정으로 정확도와 보정도를 추가 향상시킬 수 있음을 입증하였습니다.
논문 초록(Abstract)
언어 모델(LM)이 강화 학습(RL)을 통해 자연어 "추론 연쇄(reasoning chains)"를 생성하도록 학습될 때, 다양한 어려운 질문 응답 과제에서 성능이 향상됩니다. 현재까지 추론을 위한 RL의 성공적인 응용 사례들은 거의 모두 LM 출력의 정답 여부를 평가하는 이진 보상 함수(binary reward function)를 사용합니다. 그러나 이러한 보상 함수는 추측이나 낮은 신뢰도의 출력을 처벌하지 않기 때문에, 다른 문제 영역에서는 보정(calibration)이 저하되고 LM이 잘못된 응답(또는 "환각(hallucinate)")을 생성하는 비율이 증가하는 의도치 않은 부작용을 초래하는 경우가 많습니다. 본 논문에서는 정확도와 보정된 신뢰도 추정을 동시에 개선하는 추론 모델 학습 방법인 RLCR(Reinforcement Learning with Calibration Rewards)을 제안합니다. RLCR 과정에서 LM은 추론 후 예측과 수치적 신뢰도 추정을 모두 생성하며, 이들은 이진 정답 점수에 보정된 예측을 유도하는 신뢰도 평가 규칙인 브라이어 점수(Brier score)를 결합한 보상 함수를 최적화하도록 학습됩니다. 먼저, 본 논문은 이 보상 함수(또는 유사한 경계가 있는 적절한 평가 규칙을 사용하는 보상 함수)가 정확하면서도 보정이 잘 된 예측을 생성하는 모델을 산출함을 이론적으로 증명합니다. 이어서 다양한 데이터셋에서 RLCR이 정확도를 유지하면서도 보정을 크게 향상시키며, 도메인 내 평가와 도메인 외 평가 모두에서 기존의 일반적인 RL 학습과 사후 신뢰도 점수를 할당하도록 학습된 분류기를 능가함을 보입니다. 일반적인 RL이 보정을 저해하는 반면, RLCR은 이를 개선합니다. 마지막으로, 테스트 시점에 언어화된 신뢰도를 활용하여 신뢰도 가중 스케일링(confidence-weighted scaling) 기법을 통해 정확도와 보정을 향상시킬 수 있음을 실험적으로 입증합니다. 본 연구 결과는 보정을 명시적으로 최적화하는 것이 보다 신뢰할 수 있는 일반화된 추론 모델을 만드는 데 기여할 수 있음을 보여줍니다.
When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any analogous reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models.
논문 링크
반복적 무작위 계산을 통한 범용 사전학습 / Universal pre-training by iterated random computation
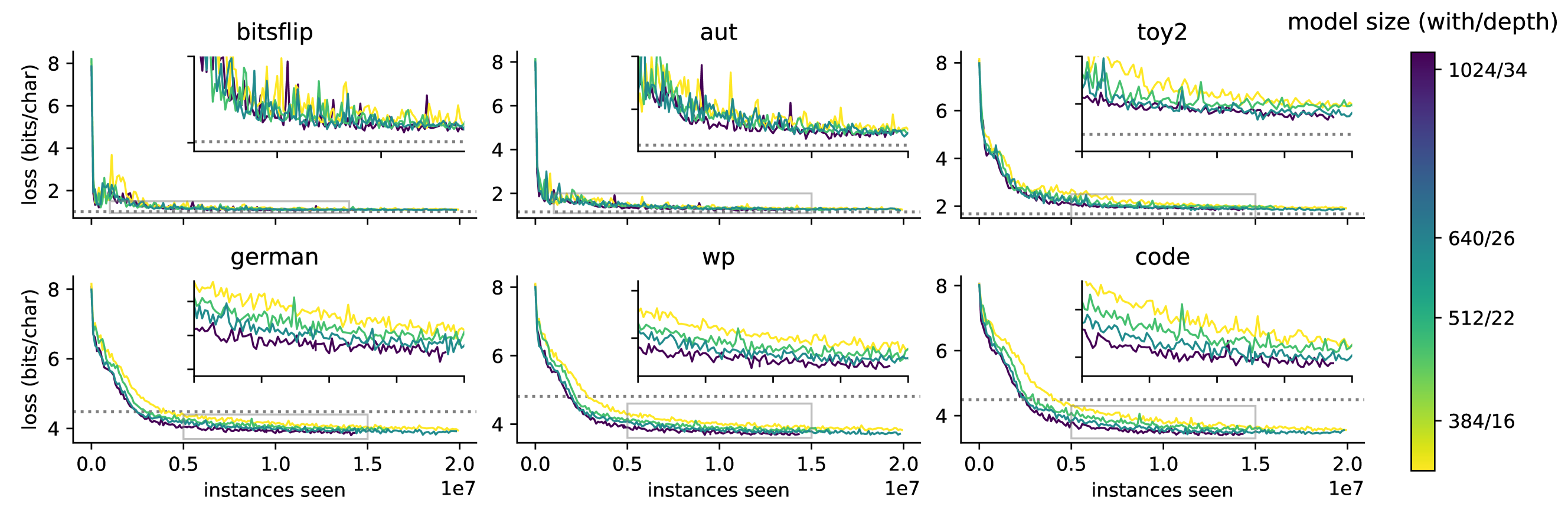
논문 소개
본 연구는 무작위로 생성된 데이터를 활용한 사전학습(pre-training) 방법을 탐구하며, 알고리즘 복잡도 관점에서 이를 이론적으로 정당화합니다. Solomonoff 귀납법을 근간으로 한 기존 연구를 확장하여 유사한 이론적 결과를 도출하였고, 합성 데이터로 사전학습한 모델이 실제 데이터 학습 전에 효과적으로 학습할 수 있음을 실험적으로 입증하였습니다. 또한, 이러한 방식으로 학습된 모델이 다양한 데이터셋에서 제로샷 인컨텍스트 학습(zero-shot in-context learning) 능력을 보이며, 모델 규모가 커질수록 성능이 향상됨을 확인하였습니다. 마지막으로, 사전학습 후 실제 데이터로 미세조정(fine-tuning)할 경우 학습 수렴 속도가 빨라지고 일반화 성능이 개선됨을 보였습니다.
논문 초록(Abstract)
본 논문에서는 모델의 사전 학습을 위해 무작위로 생성된 데이터를 활용하는 방법을 연구합니다. 알고리즘 복잡도 관점에서 이 접근법을 이론적으로 정당화하며, 이는 시퀀스 모델이 Solomonoff 귀납법(Induction)을 근사하도록 학습될 수 있음을 보인 최근 연구를 기반으로 합니다. 유사하지만 상호 보완적인 이론적 결과를 도출하였습니다. 합성 데이터가 실제 데이터가 주어지기 전에 모델의 사전 학습에 활용될 수 있음을 실험적으로 입증합니다. 이러한 방식으로 학습된 모델이 다양한 데이터셋에서 제로샷 인컨텍스트 학습(zero-shot in-context learning)을 수행하며, 규모가 커질수록 성능이 향상된다는 기존 결과를 재현하였습니다. 또한, 기존 연구를 실제 데이터에 확장하여, 사전 학습 후 미세 조정(finetuning)을 수행할 경우 수렴 속도가 빨라지고 일반화 성능이 향상됨을 보여줍니다.
We investigate the use of randomly generated data for the sake of pre-training a model. We justify this approach theoretically from the perspective of algorithmic complexity, building on recent research that shows that sequence models can be trained to approximate Solomonoff induction. We derive similar, but complementary theoretical results. We show empirically that synthetically generated data can be used to pre-train a model before the data is seen. We replicate earlier results that models trained this way show zero-shot in-context learning across a variety of datasets, and that this performance improves with scale. We extend earlier results to real-world data, and show that finetuning a model after pre-training offers faster convergence and better generalization.
논문 링크
CoRT: 사고 내 코드 통합 추론 프레임워크 / CoRT: Code-integrated Reasoning within Thinking
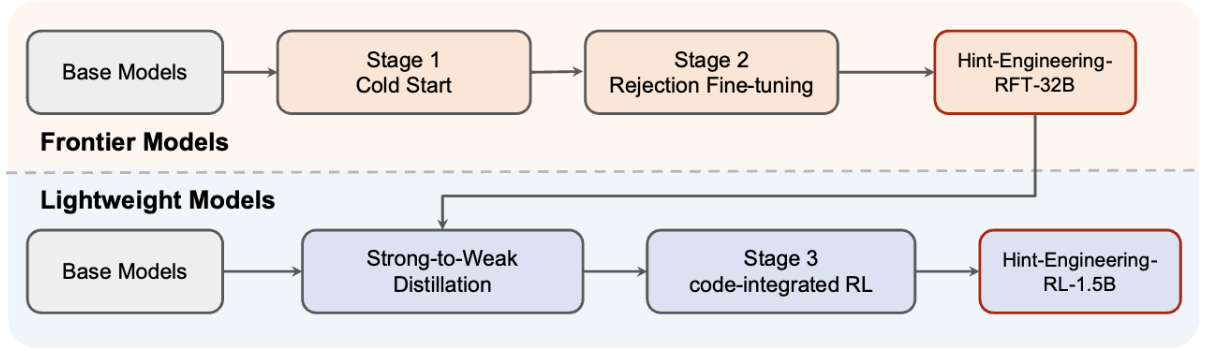
논문 소개
대규모 추론 모델(Large Reasoning Models, LRMs)은 긴 사고 과정(chain-of-thought, CoT)을 통한 자연어 추론에서 성과를 보이나, 복잡한 수학 연산 처리에서는 비효율적이거나 부정확한 한계가 있습니다. 이를 개선하기 위해 계산 라이브러리 및 기호 해석기(symbolic solvers)와 같은 코드 인터프리터(Code Interpreter, CI)를 활용하는 방안이 제안되었으나, 모델 내부 텍스트 표현과 외부 지식의 직접 결합은 효율적이지 않습니다. CoRT는 LRMs가 CI를 효과적으로 활용하도록 학습시키는 사후 학습(post-training) 프레임워크로, 힌트 엔지니어링(Hint-Engineering)을 통해 코드 통합 추론 데이터를 합성하여 데이터 부족 문제를 해결합니다. 실험 결과, CoRT는 다양한 수학 추론 데이터셋에서 성능을 4~8% 향상시키고, 토큰 사용량도 30~50% 절감하는 효과를 보였습니다.
논문 초록(Abstract)
대규모 추론 모델(Large Reasoning Models, LRM)인 o1과 DeepSeek-R1은 긴 사고의 연쇄(Chain-of-Thought, CoT)를 활용한 자연어 추론에서 뛰어난 성과를 보였으나, 복잡한 수학적 연산 처리에서는 여전히 비효율적이거나 부정확한 한계를 지니고 있습니다. 이러한 한계를 계산 도구(예: 계산 라이브러리 및 기호 해석기)를 통해 해결하는 방안은 유망하지만, 기술적 과제를 동반합니다. 코드 인터프리터(Code Interpreter, CI)는 모델 내부의 텍스트 표현을 넘어서는 외부 지식을 제공하므로, 이를 직접 결합하는 방식은 효율적이지 않습니다. 본 논문에서는 LRM이 CI를 효과적이고 효율적으로 활용하도록 학습시키는 사후 학습(post-training) 프레임워크인 CoRT를 제안합니다. 첫 번째 단계로, 우리는 Hint-Engineering 기법을 통해 코드 통합 추론 데이터를 합성하여 데이터 부족 문제를 해결합니다. 이 기법은 LRM-CI 상호작용을 최적화하기 위해 적절한 위치에 다양한 힌트를 전략적으로 삽입합니다. 저희는 30개의 고품질 샘플을 수작업으로 제작하였으며, 이를 바탕으로 1.5B부터 32B 파라미터 규모의 모델들을 감독 학습, 거부 미세 조정(rejection fine-tuning), 강화 학습으로 사후 학습하였습니다. 실험 결과, Hint-Engineering 기반 모델은 다섯 개의 도전적인 수학적 추론 데이터셋에서 DeepSeek-R1-Distill-Qwen-32B와 DeepSeek-R1-Distill-Qwen-1.5B에 대해 각각 절대 4% 및 8%의 성능 향상을 달성하였습니다. 더불어, Hint-Engineering 모델은 32B 모델에서 약 30%, 1.5B 모델에서는 약 50% 적은 토큰 수를 사용하여 자연어 모델 대비 효율성을 높였습니다. 본 모델과 코드는 GitHub - ChengpengLi1003/CoRT · GitHub 에서 확인하실 수 있습니다.
Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4% and 8% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30% fewer tokens for the 32B model and 50% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at GitHub - ChengpengLi1003/CoRT · GitHub.
논문 링크
더 읽어보기
https://github.com/ChengpengLi1003/CoRT
SEM: 검색 효율화를 위한 강화학습 기반 대형 언어모델 최적화 / SEM: Reinforcement Learning for Search-Efficient Large Language Models
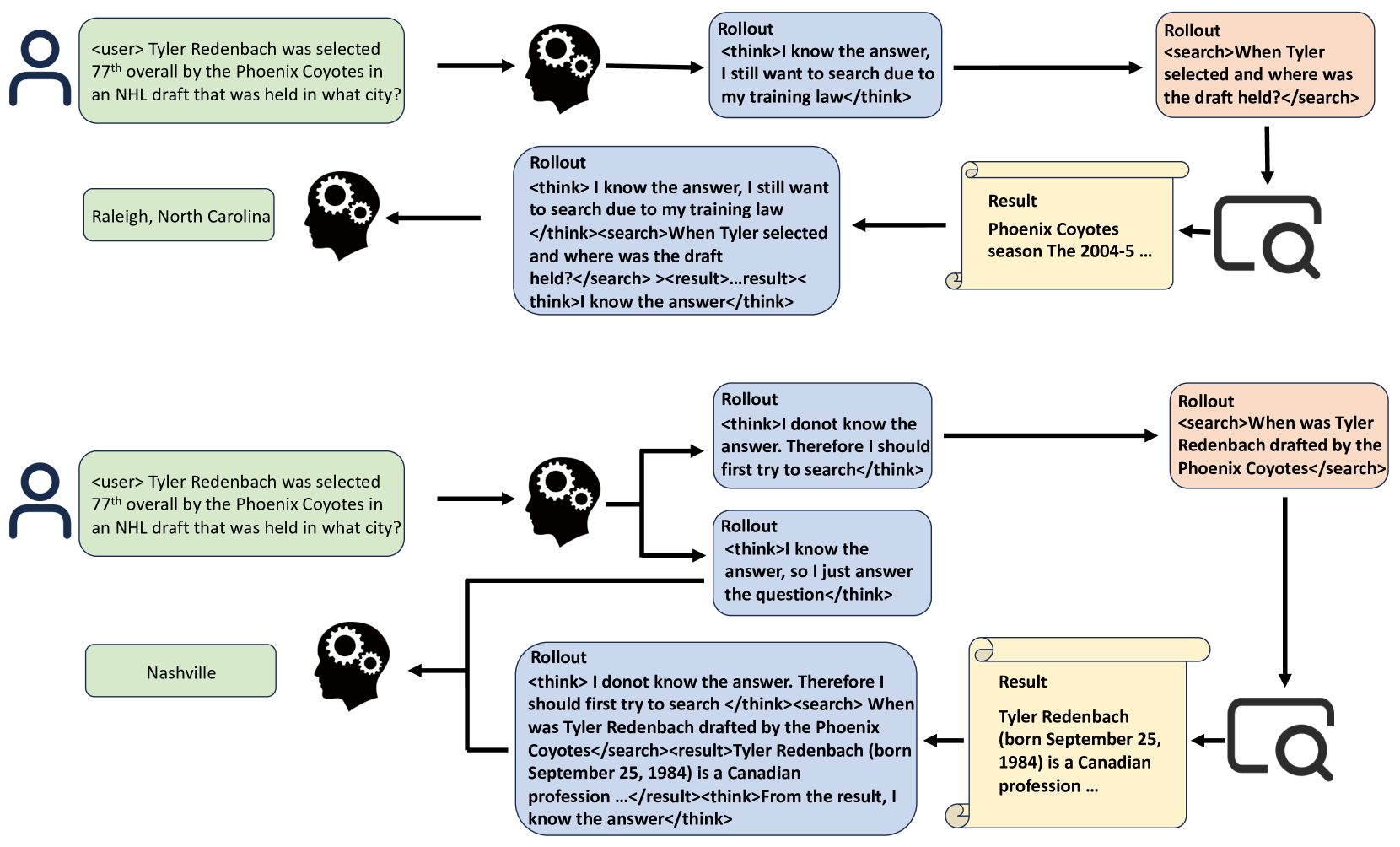
논문 소개
최근 대형 언어 모델(LLM)이 외부 도구, 특히 검색 엔진을 활용하는 능력을 보였으나, 언제 검색을 호출하고 언제 내부 지식에 의존할지 판단하는 문제는 여전히 어렵습니다. 제안된 SEM은 후학습 강화학습(post-training reinforcement learning) 프레임워크로, 모델이 불필요한 검색을 줄이고 필요한 경우에만 효과적으로 검색을 활용하도록 학습시킵니다. MuSiQue와 MMLU 데이터셋을 결합해 직접 답변 가능한 질문과 외부 검색이 필요한 질문을 구분하는 상황을 구성하고, Group Relative Policy Optimization(GRPO) 기법과 구조화된 추론 템플릿을 활용해 모델의 검색 행동을 최적화합니다. 실험 결과, SEM은 중복 검색을 크게 줄이면서도 여러 벤치마크에서 답변 정확도를 유지하거나 향상시키는 성과를 보였습니다.
논문 초록(Abstract)
최근 대규모 언어 모델(LLM)의 발전은 추론 능력뿐만 아니라 외부 도구, 특히 검색 엔진을 활용하는 능력도 보여주고 있습니다. 그러나 모델이 언제 검색을 호출하고 언제 내부 지식에 의존해야 하는지를 구분하도록 학습시키는 것은 여전히 큰 도전 과제입니다. 기존의 강화학습 접근법은 종종 중복된 검색 행동을 초래하여 비효율성과 과도한 비용 문제를 발생시킵니다. 본 논문에서는 LLM의 검색 사용을 최적화하도록 명시적으로 학습시키는 새로운 사후 학습 강화학습 프레임워크인 SEM을 제안합니다. MuSiQue와 MMLU를 결합한 균형 잡힌 데이터셋을 구성하여 모델이 직접 답변할 수 있는 질문과 외부 검색이 필요한 질문을 구분하는 상황을 만듭니다. 구조화된 추론 템플릿을 설계하고 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)를 활용하여 모델의 검색 행동을 사후 학습합니다. 보상 함수는 불필요한 검색 없이 정확한 답변을 장려하며, 필요 시 효과적인 검색을 촉진합니다. 실험 결과, 본 방법은 여러 도전적인 벤치마크에서 답변 정확도를 유지하거나 향상시키면서 중복된 검색 작업을 크게 줄임을 보여줍니다. 본 프레임워크는 모델의 추론 효율성을 향상시키고 외부 지식을 신중하게 활용하는 능력을 확장합니다.
Recent advancements in Large Language Models(LLMs) have demonstrated their capabilities not only in reasoning but also in invoking external tools, particularly search engines. However, teaching models to discern when to invoke search and when to rely on their internal knowledge remains a significant challenge. Existing reinforcement learning approaches often lead to redundant search behaviors, resulting in inefficiencies and over-cost. In this paper, we propose SEM, a novel post-training reinforcement learning framework that explicitly trains LLMs to optimize search usage. By constructing a balanced dataset combining MuSiQue and MMLU, we create scenarios where the model must learn to distinguish between questions it can answer directly and those requiring external retrieval. We design a structured reasoning template and employ Group Relative Policy Optimization(GRPO) to post-train the model's search behaviors. Our reward function encourages accurate answering without unnecessary search while promoting effective retrieval when needed. Experimental results demonstrate that our method significantly reduces redundant search operations while maintaining or improving answer accuracy across multiple challenging benchmarks. This framework advances the model's reasoning efficiency and extends its capability to judiciously leverage external knowledge.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()