[2025/08/11 ~ 17] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 이번 주 선정된 논문들을 살펴보면, 첫째로 대규모 비전 및 멀티모달 모델의 효율성 향상과 토큰 압축에 관한 연구가 두드러집니다. DINOv3와 Fourier-VLM, VisionThink 논문들은 각각 자가 지도 학습을 통한 고성능 시각 표현 학습, 주파수 영역에서의 시각 토큰 압축, 그리고 동적 해상도 조절을 통한 시각-언어 모델의 효율적 처리 방식을 제안하며, 대용량 데이터와 모델을 효과적으로 다루기 위한 다양한 전략을 보여줍니다.
이번 주 선정된 논문들을 살펴보면, 첫째로 대규모 비전 및 멀티모달 모델의 효율성 향상과 토큰 압축에 관한 연구가 두드러집니다. DINOv3와 Fourier-VLM, VisionThink 논문들은 각각 자가 지도 학습을 통한 고성능 시각 표현 학습, 주파수 영역에서의 시각 토큰 압축, 그리고 동적 해상도 조절을 통한 시각-언어 모델의 효율적 처리 방식을 제안하며, 대용량 데이터와 모델을 효과적으로 다루기 위한 다양한 전략을 보여줍니다.
![]() 또한, 강화학습(RL)을 활용한 대형 언어 모델(LLM) 및 멀티모달 에이전트의 추론 및 적응 능력 향상에 관한 연구가 활발히 진행되고 있습니다. ‘Thinking With Videos’와 ‘Part I: Tricks or Traps?’, ‘VisionThink’ 논문은 RL 기법을 통해 긴 영상 추론, LLM 추론 최적화, 그리고 시각-언어 모델의 동적 처리 결정에 적용하여 복잡한 환경에서의 문제 해결 능력을 높이고자 하는 시도를 보여줍니다.
또한, 강화학습(RL)을 활용한 대형 언어 모델(LLM) 및 멀티모달 에이전트의 추론 및 적응 능력 향상에 관한 연구가 활발히 진행되고 있습니다. ‘Thinking With Videos’와 ‘Part I: Tricks or Traps?’, ‘VisionThink’ 논문은 RL 기법을 통해 긴 영상 추론, LLM 추론 최적화, 그리고 시각-언어 모델의 동적 처리 결정에 적용하여 복잡한 환경에서의 문제 해결 능력을 높이고자 하는 시도를 보여줍니다.
![]() 마지막으로, 자율적이고 지속적으로 진화하는 AI 에이전트 및 대규모 다중 에이전트 시스템에 대한 관심이 증가하고 있습니다. ‘A Comprehensive Survey of Self-Evolving AI Agents’와 ‘DeepFleet’, ‘TheAgentCompany’ 논문들은 환경과 상호작용하며 스스로 적응 및 진화하는 에이전트 시스템, 대규모 로봇 군집의 협업 및 계획, 그리고 실제 업무 환경에서의 AI 에이전트 활용 가능성 평가에 초점을 맞추고 있습니다.
마지막으로, 자율적이고 지속적으로 진화하는 AI 에이전트 및 대규모 다중 에이전트 시스템에 대한 관심이 증가하고 있습니다. ‘A Comprehensive Survey of Self-Evolving AI Agents’와 ‘DeepFleet’, ‘TheAgentCompany’ 논문들은 환경과 상호작용하며 스스로 적응 및 진화하는 에이전트 시스템, 대규모 로봇 군집의 협업 및 계획, 그리고 실제 업무 환경에서의 AI 에이전트 활용 가능성 평가에 초점을 맞추고 있습니다.
DINOv3: 확장성과 효율성을 갖춘 차세대 자기지도 학습 비전 파운데이션 모델 / DINOv3
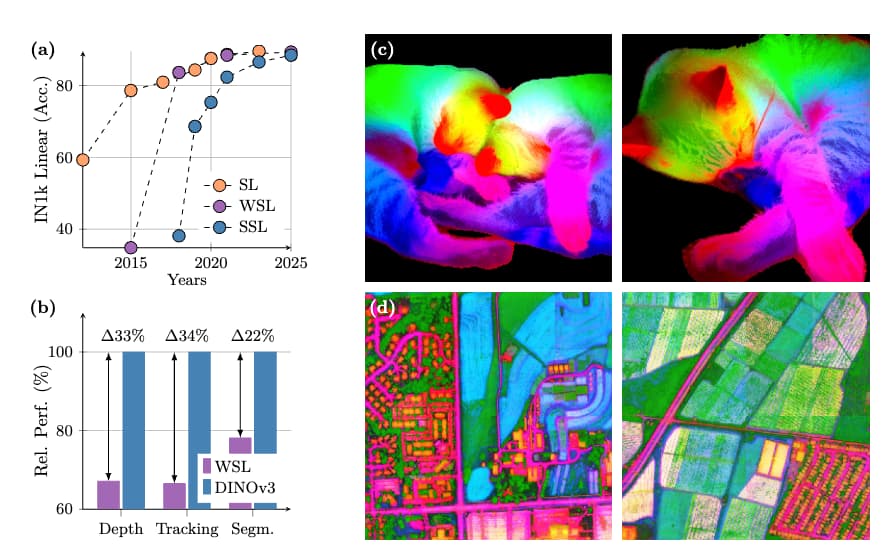
논문 소개
DINOv3는 대규모 데이터셋과 모델 크기 확장의 이점을 극대화하기 위해 정교한 데이터 준비와 최적화 기법을 활용합니다. Gram anchoring이라는 새로운 방법을 도입하여 장기 학습 시 밀집 특징 맵(dense feature maps)의 성능 저하 문제를 효과적으로 해결합니다. 또한, 해상도, 모델 크기, 텍스트 정렬과 관련된 유연성을 높이는 사후 처리 전략을 적용하여 다양한 비전 작업에서 미세 조정 없이도 최첨단 성능을 달성합니다. 이를 통해 DINOv3는 기존의 자기지도 및 약지도 학습 기반 모델을 크게 능가하는 고품질 밀집 특징을 생성하며, 다양한 자원 환경과 배포 시나리오에 적합한 확장 가능한 비전 모델 군을 제공합니다.
논문 초록(Abstract)
자기지도 학습은 수동 데이터 주석의 필요성을 제거하고, 모델이 대규모 데이터셋과 더 큰 아키텍처로 손쉽게 확장할 수 있는 가능성을 제시합니다. 특정 작업이나 도메인에 맞추어지지 않은 이 학습 패러다임은 단일 알고리즘을 사용하여 자연 이미지부터 항공 이미지에 이르기까지 다양한 출처에서 시각적 표현을 학습할 잠재력을 가지고 있습니다. 본 기술 문서에서는 이러한 비전을 실현하기 위한 중요한 이정표인 DINOv3를 소개합니다. DINOv3는 간단하면서도 효과적인 전략을 활용합니다. 첫째, 신중한 데이터 준비, 설계 및 최적화를 통해 데이터셋과 모델 크기 확장의 이점을 극대화합니다. 둘째, 장기간 학습 스케줄 동안 밀집 특징 맵이 저하되는 알려졌으나 해결되지 않은 문제를 효과적으로 다루는 새로운 방법인 Gram anchoring을 도입합니다. 마지막으로, 해상도, 모델 크기 및 텍스트 정렬에 대한 모델의 유연성을 더욱 향상시키는 사후 전략을 적용합니다. 그 결과, 미세조정 없이도 다양한 설정에서 특화된 최첨단 모델들을 능가하는 다목적 비전 파운데이션 모델을 제시합니다. DINOv3는 다양한 비전 작업에서 탁월한 성능을 발휘하는 고품질 밀집 특징을 생성하며, 이전의 자기지도 및 약지도 파운데이션 모델들을 크게 능가합니다. 또한, 다양한 자원 제약과 배포 시나리오에 대응할 수 있는 확장 가능한 솔루션을 제공하여 광범위한 작업과 데이터에서 최첨단 성능을 진전시키기 위해 설계된 DINOv3 비전 모델군도 함께 공개합니다.
Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
논문 링크
더 읽어보기
https://github.com/facebookresearch/dinov3
Fourier-VLM: 대규모 비전-언어 모델을 위한 주파수 영역 시각 토큰 압축 기법 / Fourier-VLM: Compressing Vision Tokens in the Frequency Domain for Large Vision-Language Models
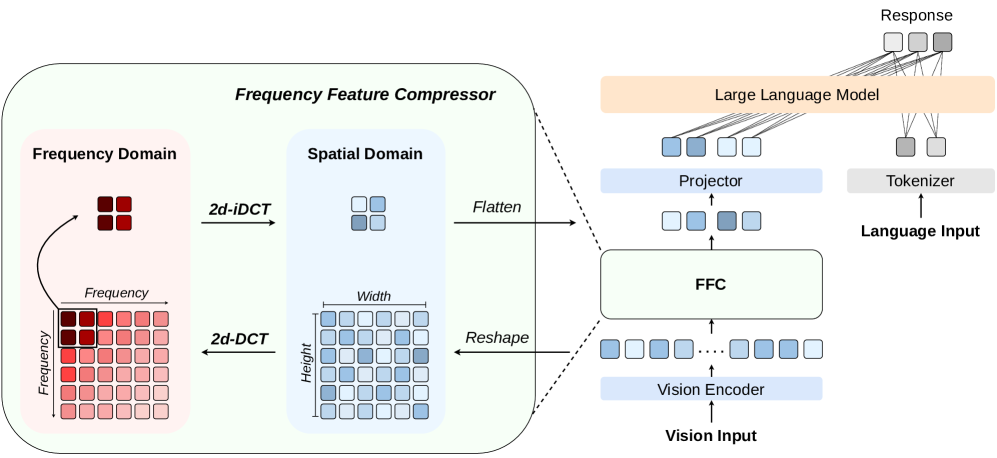
논문 소개
Fourier-VLM은 대형 비전-언어 모델에서 시각 토큰 수를 줄이기 위해 주파수 영역에서 시각 표현을 압축하는 효율적인 방법입니다. 비전 인코더 출력의 저주파 성분에 에너지가 집중된 점에 착안하여, 2차원 이산 코사인 변환(Discrete Cosine Transform, DCT)과 고속 푸리에 변환(Fast Fourier Transform, FFT)을 활용해 저역통과 필터링을 수행합니다. 이 과정은 추가 파라미터 없이 계산 복잡도를 크게 낮추며, 실험 결과 LLaVA 및 Qwen-VL 아키텍처에서 최대 83.8%의 추론 FLOPs 감소와 31.2%의 생성 속도 향상을 달성하면서도 경쟁력 있는 성능과 우수한 일반화 능력을 보였습니다.
논문 초록(Abstract)
비전-언어 모델(VLM)은 일반적으로 텍스트 지시문 내에 미리 정의된 이미지 플레이스홀더 토큰()을 이미지 인코더에서 추출한 시각적 특징으로 대체하여, 이를 백본 대규모 언어 모델(LLM)의 입력으로 사용합니다. 그러나 다수의 비전 토큰은 컨텍스트 길이를 크게 증가시켜 높은 계산 비용과 추론 지연을 초래합니다. 기존 연구들은 중요한 시각적 특징만을 선택하거나 학습 가능한 쿼리를 활용하여 토큰 수를 줄임으로써 이를 완화하고자 했으나, 종종 성능 저하나 상당한 추가 비용을 수반하는 문제가 있었습니다. 이에 본 논문에서는 주파수 영역에서 시각적 표현을 압축하는 간단하면서도 효율적인 방법인 Fourier-VLM을 제안합니다. 본 접근법은 비전 인코더에서 출력되는 시각적 특징이 저주파 성분에 에너지가 집중되어 있다는 관찰에 기반합니다. 이를 활용하여 2차원 이산 코사인 변환(DCT)을 이용해 저역 통과 필터를 시각적 특징에 적용합니다. 특히, DCT는 빠른 푸리에 변환(FFT) 연산자를 통해 시간 복잡도 $\mathcal{O}(n\log n)$로 효율적으로 계산되어, 추가 파라미터 없이도 연산 비용을 최소화합니다. 다양한 이미지 기반 벤치마크에서의 광범위한 실험 결과, Fourier-VLM은 LLaVA 및 Qwen-VL 아키텍처 모두에서 강력한 일반화 능력과 경쟁력 있는 성능을 보였습니다. 특히, LLaVA-v1.5 대비 추론 FLOPs를 최대 83.8%까지 감소시키고 생성 속도를 31.2% 향상시켜, 뛰어난 효율성과 실용성을 입증합니다.
Vision-Language Models (VLMs) typically replace the predefined image placeholder token () in textual instructions with visual features from an image encoder, forming the input to a backbone Large Language Model (LLM). However, the large number of vision tokens significantly increases the context length, leading to high computational overhead and inference latency. While previous efforts mitigate this by selecting only important visual features or leveraging learnable queries to reduce token count, they often compromise performance or introduce substantial extra costs. In response, we propose Fourier-VLM, a simple yet efficient method that compresses visual representations in the frequency domain. Our approach is motivated by the observation that vision features output from the vision encoder exhibit concentrated energy in low-frequency components. Leveraging this, we apply a low-pass filter to the vision features using a two-dimentional Discrete Cosine Transform (DCT). Notably, the DCT is efficiently computed via the Fast Fourier Transform (FFT) operator with a time complexity of \mathcal{O}(n\log n), minimizing the extra computational cost while introducing no additional parameters. Extensive experiments across various image-based benchmarks demonstrate that Fourier-VLM achieves competitive performance with strong generalizability across both LLaVA and Qwen-VL architectures. Crucially, it reduce inference FLOPs by up to 83.8% and boots generation speed by 31.2% compared to LLaVA-v1.5, highlighting the superior efficiency and practicality.
논문 링크
비디오 사고: 장기 영상 추론을 위한 다중모달 도구 증강 강화학습 / Thinking With Videos: Multimodal Tool-Augmented Reinforcement Learning for Long Video Reasoning
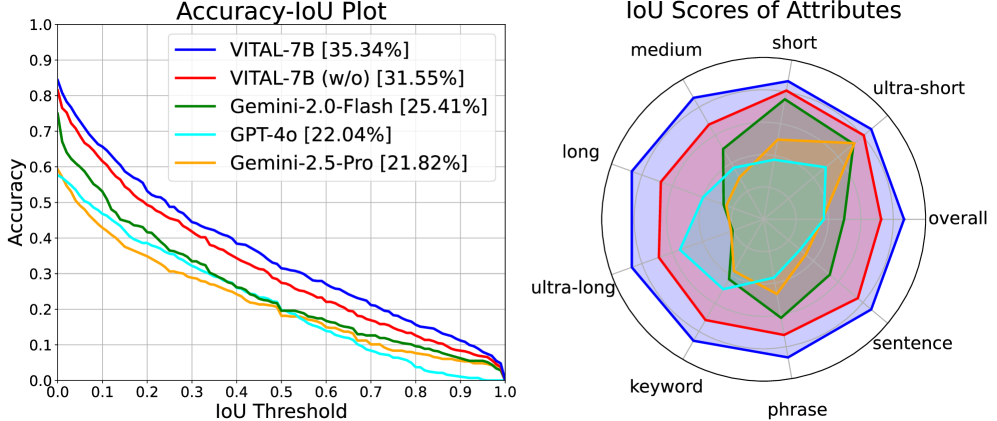
논문 소개
멀티모달 대형 언어 모델(MLLM)의 영상 추론 능력은 영상 질문 응답과 시간적 위치 지정과 같은 하위 과제에서 매우 중요합니다. 기존의 텍스트 기반 연쇄 사고(chain-of-thought, CoT) 추론 방식은 교차 모달 상호작용이 제한적이고, 긴 영상이나 복잡한 추론 시 환각(hallucination) 문제가 발생하는 단점이 있습니다. 이를 해결하기 위해 VITAL이라는 시각 도구 상호작용 기반의 종단 간 영상 추론 프레임워크를 제안하며, 이는 필요에 따라 영상 프레임을 밀도 있게 샘플링하고 멀티모달 CoT를 생성하여 긴 영상에 대한 정밀한 추론을 가능하게 합니다. 또한, 시간적 위치 지정과 질문 응답을 상호 보완적인 다중 과제로 보고, 이를 위한 대규모 데이터셋과 난이도 인지 그룹 상대 정책 최적화(DGRPO) 알고리즘을 도입하여 다중 과제 강화학습의 난이도 불균형 문제를 완화하였으며, 다양한 벤치마크에서 기존 방법을 능가하는 성능을 입증하였습니다.
논문 초록(Abstract)
멀티모달 대규모 언어 모델(MLLM)의 비디오 추론 능력은 비디오 질문 응답 및 시간적 그라운딩과 같은 하위 작업에 매우 중요합니다. 최근 연구들은 MLLM을 위한 텍스트 기반 사고의 연쇄(CoT) 추론을 탐구해왔으나, 이러한 방법들은 특히 긴 비디오나 긴 추론 체인에서 제한된 교차 모달 상호작용과 환각 현상 증가 문제를 겪고 있습니다. 이러한 문제를 해결하기 위해, 본 논문에서는 도구 보강 학습을 통한 비디오 인텔리전스(VITAL)라는 새로운 엔드투엔드 에이전트형 비디오 추론 프레임워크를 제안합니다. 시각적 도구 상자를 활용하여 모델은 필요에 따라 새로운 비디오 프레임을 밀도 있게 샘플링하고, 정밀한 긴 비디오 추론을 위한 멀티모달 사고의 연쇄(CoT)를 생성할 수 있습니다. 또한, 시간적 그라운딩과 질문 응답이 비디오 이해 작업에서 상호 보완적임을 관찰하였습니다. 이에 따라, 감독 학습을 위한 고품질 다중 작업 비디오 추론 데이터셋 MTVR-CoT-72k와 강화 학습을 위한 MTVR-RL-110k를 구축하였습니다. 더불어, 다중 작업 강화 학습에서 난이도 불균형 문제를 완화하기 위해 난이도 인지 그룹 상대 정책 최적화 알고리즘(DGRPO)을 제안합니다. 11개의 도전적인 비디오 이해 벤치마크에서 수행한 광범위한 실험 결과, VITAL은 기존 방법들을 능가하는 우수한 추론 능력을 보였으며, 특히 긴 비디오 시나리오에서 비디오 질문 응답 및 시간적 그라운딩 작업에서 뛰어난 성능을 입증하였습니다. 모든 코드, 데이터 및 모델 가중치는 공개될 예정입니다.
The video reasoning ability of multimodal large language models (MLLMs) is crucial for downstream tasks like video question answering and temporal grounding. While recent approaches have explored text-based chain-of-thought (CoT) reasoning for MLLMs, these methods often suffer from limited cross-modal interaction and increased hallucination, especially with longer videos or reasoning chains. To address these challenges, we propose Video Intelligence via Tool-Augmented Learning (VITAL), a novel end-to-end agentic video reasoning framework. With a visual toolbox, the model can densely sample new video frames on demand and generate multimodal CoT for precise long video reasoning. We observe that temporal grounding and question answering are mutually beneficial for video understanding tasks. Therefore, we construct two high-quality multi-task video reasoning datasets MTVR-CoT-72k for supervised fine-tuning and MTVR-RL-110k for reinforcement learning. Moreover, we propose a Difficulty-aware Group Relative Policy Optimization algorithm (DGRPO) to mitigate difficulty imbalance in multi-task reinforcement learning. Extensive experiments on 11 challenging video understanding benchmarks demonstrate the advanced reasoning ability of VITAL, outperforming existing methods in video question answering and temporal grounding tasks, especially in long video scenarios. All code, data and model weight will be made publicly available.
논문 링크
속도가 승리한다: 대규모 언어 모델을 위한 효율적 아키텍처 서베이 / Speed Always Wins: A Survey on Efficient Architectures for Large Language Models
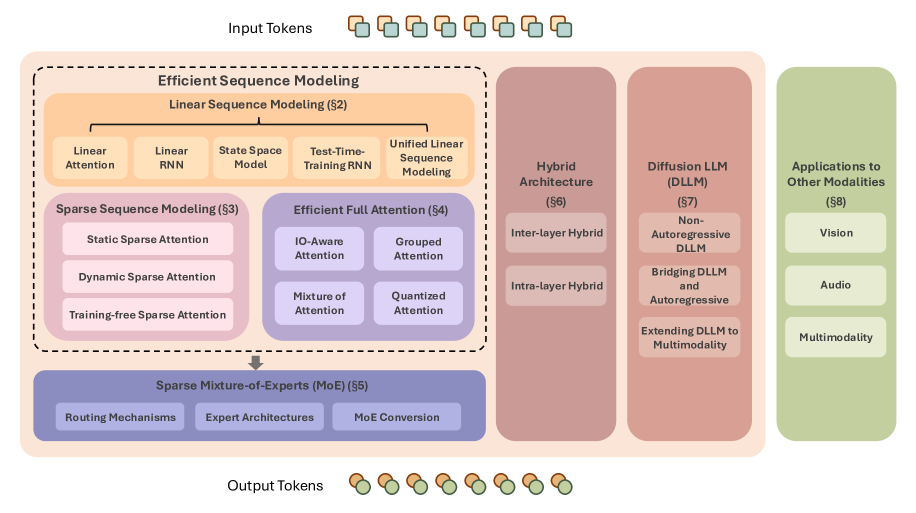
논문 소개
대형 언어 모델(LLM)은 언어 이해, 생성, 추론뿐만 아니라 멀티모달 모델의 능력 확장에 중요한 역할을 하고 있습니다. 전통적인 트랜스포머(transformer) 구조는 뛰어난 확장성을 지니지만, 대규모 학습과 실용적 적용에 있어 높은 계산 비용이라는 한계가 존재합니다. 이에 본 서베이는 선형 및 희소 시퀀스 모델링, 효율적인 전(全) 어텐션(attention) 변형, 희소 전문가 혼합(sparse mixture-of-experts), 하이브리드 모델 구조, 그리고 확산(diffusion) 기반 LLM 등 다양한 효율적 아키텍처를 체계적으로 정리합니다. 또한 이러한 기술들이 다른 모달리티에 적용되는 사례와 확장 가능하고 자원 효율적인 기초 모델 개발에 미치는 영향도 함께 논의합니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 언어 이해, 생성, 추론 분야에서 뛰어난 성과를 보여주었으며, 멀티모달 모델의 능력 한계를 확장시키고 있습니다. 현대 LLM의 기반이 되는 트랜스포머(transformer) 모델은 우수한 확장성을 갖춘 강력한 기준점을 제공합니다. 그러나 전통적인 트랜스포머 아키텍처는 막대한 연산량을 요구하며, 대규모 학습과 실질적 배포에 있어 상당한 장애물이 됩니다. 본 서베이 논문에서는 트랜스포머의 내재적 한계를 극복하고 효율성을 향상시키는 혁신적인 LLM 아키텍처들을 체계적으로 검토합니다. 언어 모델링을 출발점으로 하여, 본 서베이는 선형(linear) 및 희소(sparse) 시퀀스 모델링 기법, 효율적인 전(全) 어텐션(full attention) 변형, 희소 전문가 혼합(sparse mixture-of-experts), 앞서 언급한 기법들을 통합한 하이브리드 모델 아키텍처, 그리고 신흥 확산(diffusion) LLM을 포함한 기술적 배경과 세부 내용을 다룹니다. 또한 이러한 기법들의 다른 모달리티 적용 사례와 확장 가능하며 자원 효율적인 파운데이션 모델 개발에 미치는 광범위한 함의도 논의합니다. 최근 연구들을 위 분류에 따라 체계적으로 정리함으로써, 본 서베이는 현대적이고 효율적인 LLM 아키텍처의 청사진을 제시하며, 향후 더욱 효율적이고 다재다능한 AI 시스템 연구에 동기를 부여하고자 합니다.
Large Language Models (LLMs) have delivered impressive results in language understanding, generation, reasoning, and pushes the ability boundary of multimodal models. Transformer models, as the foundation of modern LLMs, offer a strong baseline with excellent scaling properties. However, the traditional transformer architecture requires substantial computations and poses significant obstacles for large-scale training and practical deployment. In this survey, we offer a systematic examination of innovative LLM architectures that address the inherent limitations of transformers and boost the efficiency. Starting from language modeling, this survey covers the background and technical details of linear and sparse sequence modeling methods, efficient full attention variants, sparse mixture-of-experts, hybrid model architectures incorporating the above techniques, and emerging diffusion LLMs. Additionally, we discuss applications of these techniques to other modalities and consider their wider implications for developing scalable, resource-aware foundation models. By grouping recent studies into the above category, this survey presents a blueprint of modern efficient LLM architectures, and we hope this could help motivate future research toward more efficient, versatile AI systems.
논문 링크
더 읽어보기
https://github.com/weigao266/Awesome-Efficient-Arch
1부: 대규모 언어 모델 추론을 위한 강화학습의 함정과 요령 심층 분석 / Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
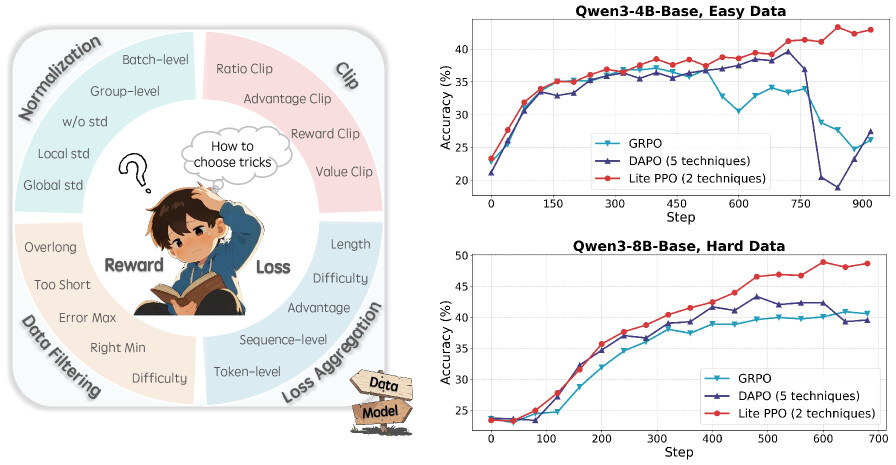
논문 소개
강화학습(Reinforcement Learning, RL)을 활용한 대형언어모델(LLM) 추론 연구가 빠르게 발전하고 있으나, 표준화된 가이드라인 부재와 기법들의 내부 작동 원리에 대한 이해 부족, 실험 환경 및 데이터 차이로 인한 상반된 결과들이 혼재되어 있습니다. 본 연구는 통합된 오픈소스 프레임워크 내에서 주요 RL 기법들을 엄밀히 재현하고 개별 평가하여, 각 기법의 내부 메커니즘, 적용 가능 시나리오, 핵심 원리를 세밀한 실험을 통해 분석하였습니다. 이를 바탕으로 특정 환경에 적합한 RL 기법 선택을 위한 명확한 가이드라인과 실무자들이 참고할 수 있는 신뢰성 높은 로드맵을 제시합니다. 또한, 두 가지 기법의 최소 조합만으로도 vanilla PPO 손실 함수를 사용하는 크리틱 없는 정책의 학습 능력을 크게 향상시켜, 기존 GRPO 및 DAPO 전략을 능가하는 성과를 입증하였습니다.
논문 초록(Abstract)
대규모 언어 모델(LLM) 추론을 위한 강화학습은 알고리즘 혁신과 실용적 응용 분야에서 관련 연구가 급격히 증가하며 주목받는 연구 영역으로 부상하였습니다. 이러한 진전에도 불구하고, 강화학습 기법 적용에 대한 표준화된 지침의 부재와 그 기저 메커니즘에 대한 단편적인 이해 등 여러 중요한 과제가 여전히 남아 있습니다. 또한, 실험 환경의 불일치, 학습 데이터의 차이, 모델 초기화의 변동성으로 인해 상충되는 결론들이 도출되어, 해당 기법들의 핵심 특성이 모호해지고 실무자들이 적절한 기법을 선택하는 데 혼란을 초래하고 있습니다. 본 논문에서는 통합된 오픈소스 프레임워크 내에서 엄격한 재현과 개별 평가를 통해 널리 사용되는 강화학습 기법들을 체계적으로 검토합니다. 다양한 난이도의 데이터셋, 모델 크기 및 아키텍처를 포함한 세밀한 실험을 통해 각 기법의 내부 메커니즘, 적용 가능 시나리오, 핵심 원리를 분석합니다. 이러한 통찰을 바탕으로 특정 환경에 맞는 강화학습 기법 선택을 위한 명확한 가이드라인을 제시하며, LLM 분야에서 강화학습을 활용하는 실무자들을 위한 신뢰할 수 있는 로드맵을 제공합니다. 마지막으로, 본 연구는 두 가지 기법의 최소한의 조합만으로도 vanilla PPO loss를 활용한 크리틱 없는 정책의 학습 능력을 극대화할 수 있음을 밝힙니다. 실험 결과, 본 단순 조합은 GRPO 및 DAPO와 같은 전략들을 능가하며 일관되게 성능을 향상시킴을 보여줍니다.
Reinforcement learning for LLM reasoning has rapidly emerged as a prominent research area, marked by a significant surge in related studies on both algorithmic innovations and practical applications. Despite this progress, several critical challenges remain, including the absence of standardized guidelines for employing RL techniques and a fragmented understanding of their underlying mechanisms. Additionally, inconsistent experimental settings, variations in training data, and differences in model initialization have led to conflicting conclusions, obscuring the key characteristics of these techniques and creating confusion among practitioners when selecting appropriate techniques. This paper systematically reviews widely adopted RL techniques through rigorous reproductions and isolated evaluations within a unified open-source framework. We analyze the internal mechanisms, applicable scenarios, and core principles of each technique through fine-grained experiments, including datasets of varying difficulty, model sizes, and architectures. Based on these insights, we present clear guidelines for selecting RL techniques tailored to specific setups, and provide a reliable roadmap for practitioners navigating the RL for the LLM domain. Finally, we reveal that a minimalist combination of two techniques can unlock the learning capability of critic-free policies using vanilla PPO loss. The results demonstrate that our simple combination consistently improves performance, surpassing strategies like GRPO and DAPO.
논문 링크
자기진화 AI 에이전트 종합 서베이: 기초 모델과 평생 에이전트 시스템을 잇는 새로운 패러다임 / A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
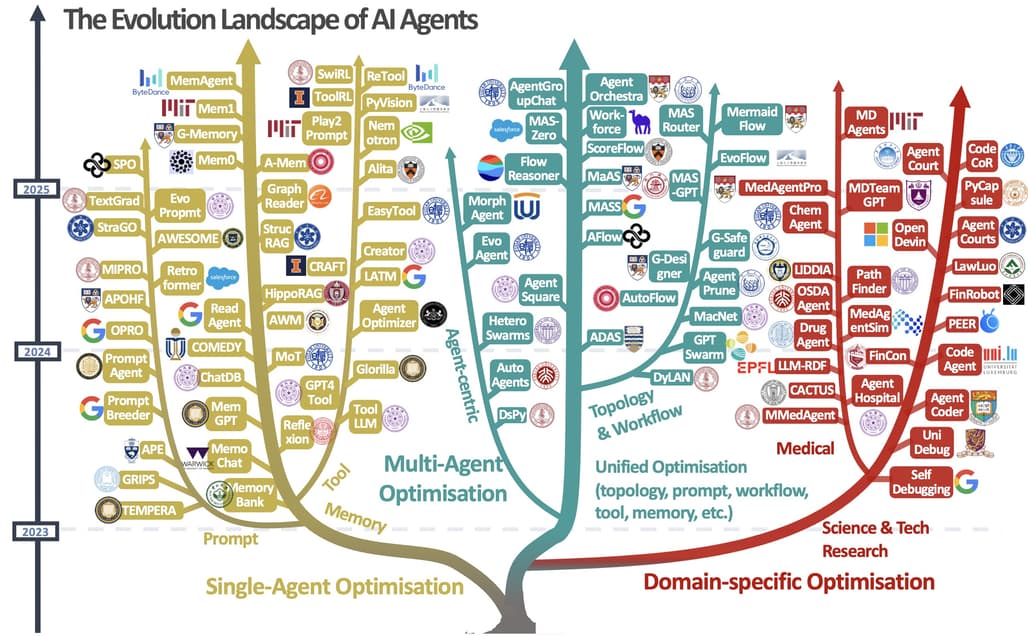
논문 소개
최근 대형 언어 모델(large language models)의 발전으로 복잡한 실제 문제를 해결하는 AI 에이전트에 대한 관심이 증가하고 있습니다. 기존 에이전트 시스템은 배포 후 고정된 수동 설정에 의존해 동적인 환경 변화에 적응하는 데 한계가 있으나, 상호작용 데이터와 환경 피드백을 활용해 자동으로 성능을 향상하는 자기 진화(self-evolving) 에이전트 연구가 주목받고 있습니다. 본 서베이는 자기 진화 에이전트 시스템의 설계에 필수적인 네 가지 구성 요소(시스템 입력, 에이전트 시스템, 환경, 최적화기)를 중심으로 다양한 진화 기법을 체계적으로 정리하고, 생의학, 프로그래밍, 금융 등 특화 분야별 진화 전략도 함께 다룹니다. 또한 평가, 안전성, 윤리적 고려사항을 논의하여 자기 진화 에이전트의 신뢰성과 효과성을 확보하는 데 중요한 방향성을 제시합니다.
논문 초록(Abstract)
최근 대규모 언어 모델(LLM)의 발전은 복잡하고 실제적인 과제를 해결할 수 있는 AI 에이전트에 대한 관심을 증대시켰습니다. 그러나 대부분의 기존 에이전트 시스템은 배포 이후에도 정적으로 유지되는 수동으로 설계된 구성에 의존하여, 동적이고 변화하는 환경에 적응하는 능력이 제한적입니다. 이를 해결하기 위해 최근 연구들은 상호작용 데이터와 환경 피드백을 기반으로 에이전트 시스템을 자동으로 향상시키는 에이전트 진화 기법을 탐구하고 있습니다. 이 새로운 연구 방향은 기초 모델의 정적인 능력과 평생 에이전트 시스템이 요구하는 지속적인 적응성을 연결하는 자가 진화 AI 에이전트의 토대를 마련합니다. 본 서베이 논문에서는 자가 진화 에이전트 시스템을 위한 기존 기법들을 포괄적으로 검토합니다. 구체적으로, 먼저 자가 진화 에이전트 시스템 설계의 근간이 되는 피드백 루프를 추상화한 통합 개념적 프레임워크를 소개합니다. 이 프레임워크는 시스템 입력(System Inputs), 에이전트 시스템(Agent System), 환경(Environment), 최적화기(Optimisers)의 네 가지 핵심 구성 요소를 강조하여 다양한 전략을 이해하고 비교하는 기반을 제공합니다. 해당 프레임워크를 바탕으로 에이전트 시스템의 각기 다른 구성 요소를 대상으로 하는 다양한 자가 진화 기법들을 체계적으로 검토합니다. 또한, 생명 의학, 프로그래밍, 금융과 같이 최적화 목표가 도메인 제약과 밀접하게 연관된 특수 분야를 위한 도메인 특화 진화 전략도 조사합니다. 아울러 자가 진화 에이전트 시스템의 효과성과 신뢰성을 보장하는 데 필수적인 평가, 안전성 및 윤리적 고려사항에 대해 별도의 논의를 제공합니다. 본 서베이는 연구자와 실무자에게 자가 진화 AI 에이전트에 대한 체계적인 이해를 제공하여, 보다 적응적이고 자율적이며 평생 지속 가능한 에이전트 시스템 개발의 토대를 마련하는 것을 목표로 합니다.
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.
논문 링크
더 읽어보기
https://github.com/EvoAgentX/Awesome-Self-Evolving-Agents
TheAgentCompany: 실제 업무 과제에서 LLM 에이전트 성능 평가 벤치마크 / TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
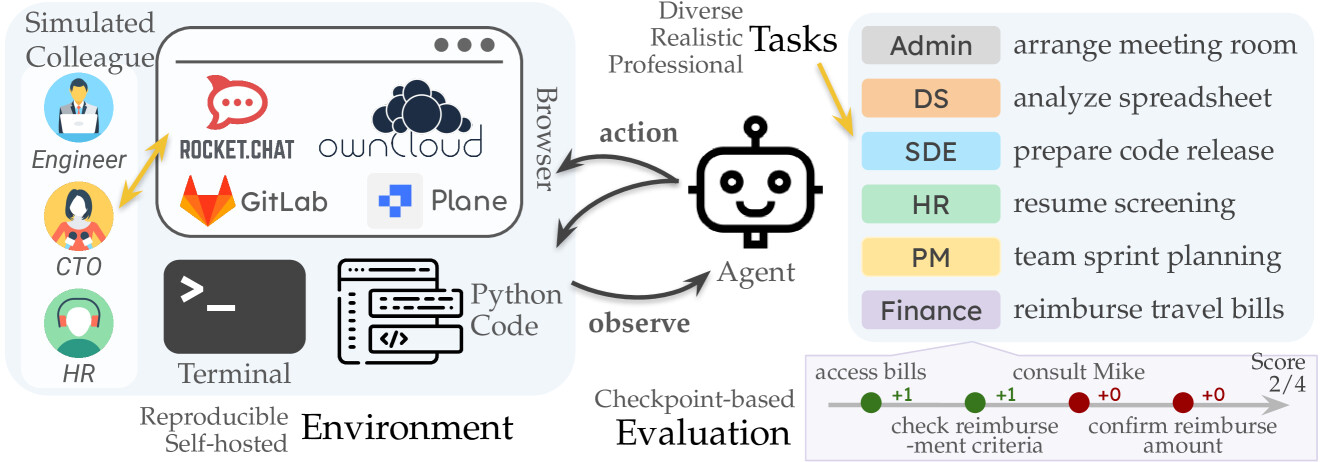
논문 소개
일상과 업무에서 컴퓨터와 인터넷을 활용하는 작업이 많아진 가운데, 대형 언어 모델(LLM)을 기반으로 한 AI 에이전트가 주변 환경과 상호작용하며 업무를 자동화하는 능력이 주목받고 있습니다. 본 연구에서는 실제 소프트웨어 회사 환경을 모사한 자체 웹사이트와 데이터를 포함한 환경에서, 웹 탐색, 코드 작성, 프로그램 실행, 동료와의 소통 등 디지털 근로자와 유사한 방식으로 작업하는 AI 에이전트의 성능을 평가하는 확장 가능한 벤치마크인 TheAgentCompany를 제안합니다. 폐쇄형 API와 공개 가중치 언어 모델을 활용한 기본 에이전트 실험 결과, 가장 우수한 에이전트가 전체 작업의 약 30%를 자율적으로 수행할 수 있음을 확인하였으며, 단순 작업은 자동화가 가능하지만 복잡한 장기 과제는 아직 한계가 있음을 시사합니다. 연구에 사용된 코드, 데이터, 환경 및 실험 결과는 공개되어 산업 및 경제 정책 분야에서 AI 도입 효과를 평가하는 데 기여할 수 있습니다.
논문 초록(Abstract)
우리는 일상생활이나 업무에서 컴퓨터와 상호작용하며, 많은 업무가 컴퓨터와 인터넷 접근만으로 완전히 수행될 수 있습니다. 동시에, 대규모 언어 모델(LLM)의 발전 덕분에 주변 환경과 상호작용하며 변화를 일으키는 AI 에이전트가 빠르게 발전하고 있습니다. 그렇다면 AI 에이전트는 업무 관련 작업을 가속화하거나 자율적으로 수행하는 데 얼마나 뛰어난 성능을 보일까요? 이 질문에 대한 답은 AI를 업무 흐름에 도입하려는 산업계와 AI 도입이 노동 시장에 미칠 영향을 이해하고자 하는 경제 정책 모두에 중요한 시사점을 제공합니다. 본 논문에서는 이러한 LLM 에이전트가 실제 전문 업무를 수행하는 성능 진척도를 측정하기 위해, 웹 탐색, 코드 작성, 프로그램 실행, 동료와의 소통 등 디지털 근로자와 유사한 방식으로 세계와 상호작용하는 AI 에이전트를 평가할 수 있는 확장 가능한 벤치마크인 TheAgentCompany를 제안합니다. 우리는 내부 웹사이트와 데이터를 포함한 자급자족 환경을 구축하여 소규모 소프트웨어 회사 환경을 모방하고, 해당 회사의 근로자가 수행할 수 있는 다양한 업무를 설계하였습니다. 폐쇄형 API 기반 및 오픈 웨이트 언어 모델(LM)을 탑재한 기본 에이전트를 테스트한 결과, 가장 경쟁력 있는 에이전트가 자율적으로 30%의 작업을 완료할 수 있음을 확인하였습니다. 이는 LM 에이전트를 활용한 작업 자동화에 대해 미묘한 시사점을 제공합니다. 실제 직장 환경을 시뮬레이션한 설정에서 단순한 작업의 상당 부분은 자율적으로 해결 가능하지만, 더 어렵고 장기적인 작업은 여전히 현 시스템의 범위를 벗어납니다. 코드, 데이터, 환경 및 실험 결과는 https://the-agent-company.com 에 공개합니다.
We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at accelerating or even autonomously performing work-related tasks? The answer to this question has important implications both for industry looking to adopt AI into their workflows and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that the most competitive agent can complete 30% of tasks autonomously. This paints a nuanced picture on task automation with LM agents--in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems. We release code, data, environment, and experiments on https://the-agent-company.com.
논문 링크
더 읽어보기
DeepFleet: 대규모 모바일 로봇 군집을 위한 다중 에이전트 기반 파운데이션 모델 / DeepFleet: Multi-Agent Foundation Models for Mobile Robots

논문 소개
DeepFleet는 대규모 모바일 로봇 군집의 협력 및 계획 지원을 위해 설계된 파운데이션 모델 세트입니다. 아마존 창고에서 수집한 수십만 대 로봇의 위치, 목표, 상호작용 데이터를 기반으로 네 가지 아키텍처를 제안하며, 각각 로봇 중심, 로봇-바닥, 이미지-바닥, 그래프-바닥 모델로 구분됩니다. 평가 결과, 비동기적 로봇 상태 업데이트와 국소적 상호작용 구조를 반영한 로봇 중심 및 그래프-바닥 모델이 예측 성능에서 가장 우수한 것으로 나타났습니다. 또한 이 두 모델은 대규모 창고 운영 데이터셋을 활용할 때 확장성 측면에서도 효과적임을 확인하였습니다.
논문 초록(Abstract)
본 논문에서는 대규모 모바일 로봇 플릿의 조정 및 계획을 지원하기 위해 설계된 기초 모델군인 DeepFleet를 소개합니다. 이 모델들은 전 세계 아마존 물류창고에서 수십만 대의 로봇 위치, 목표, 상호작용을 포함한 플릿 이동 데이터로 학습되었습니다. DeepFleet는 각각 고유한 귀납적 편향(inductive bias)을 내포하고 다중 에이전트 기초 모델 설계 공간의 핵심 요소를 탐구하는 네 가지 아키텍처로 구성됩니다. 로봇 중심(RC) 모델은 개별 로봇의 이웃 영역에서 작동하는 자기회귀 결정 트랜스포머(autoregressive decision transformer)이며, 로봇-플로어(RF) 모델은 로봇과 물류창고 바닥 간 크로스 어텐션(cross-attention)을 활용하는 트랜스포머입니다. 이미지-플로어(IF) 모델은 전체 플릿의 다중 채널 이미지 표현에 합성곱 인코딩(convolutional encoding)을 적용하며, 그래프-플로어(GF) 모델은 시계열 어텐션(temporal attention)과 그래프 신경망(graph neural networks)을 결합하여 공간적 관계를 모델링합니다. 본 논문에서는 이들 모델을 상세히 설명하고, 설계 선택이 예측 과제 성능에 미치는 영향을 평가한 결과를 제시합니다. 비동기 로봇 상태 업데이트(asynchronous robot state updates)와 로봇 상호작용의 국소적 구조(localized structure)를 모두 반영한 로봇 중심 및 그래프-플로어 모델이 가장 유망한 성과를 보였습니다. 또한, 이 두 모델이 모델 규모 확장에 따라 더 큰 물류창고 운영 데이터셋을 효과적으로 활용할 수 있음을 입증하는 실험 결과도 함께 제시합니다.
We introduce DeepFleet, a suite of foundation models designed to support coordination and planning for large-scale mobile robot fleets. These models are trained on fleet movement data, including robot positions, goals, and interactions, from hundreds of thousands of robots in Amazon warehouses worldwide. DeepFleet consists of four architectures that each embody a distinct inductive bias and collectively explore key points in the design space for multi-agent foundation models: the robot-centric (RC) model is an autoregressive decision transformer operating on neighborhoods of individual robots; the robot-floor (RF) model uses a transformer with cross-attention between robots and the warehouse floor; the image-floor (IF) model applies convolutional encoding to a multi-channel image representation of the full fleet; and the graph-floor (GF) model combines temporal attention with graph neural networks for spatial relationships. In this paper, we describe these models and present our evaluation of the impact of these design choices on prediction task performance. We find that the robot-centric and graph-floor models, which both use asynchronous robot state updates and incorporate the localized structure of robot interactions, show the most promise. We also present experiments that show that these two models can make effective use of larger warehouses operation datasets as the models are scaled up.
논문 링크
VisionThink: 강화학습 기반 스마트하고 효율적인 비전-언어 모델 / VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
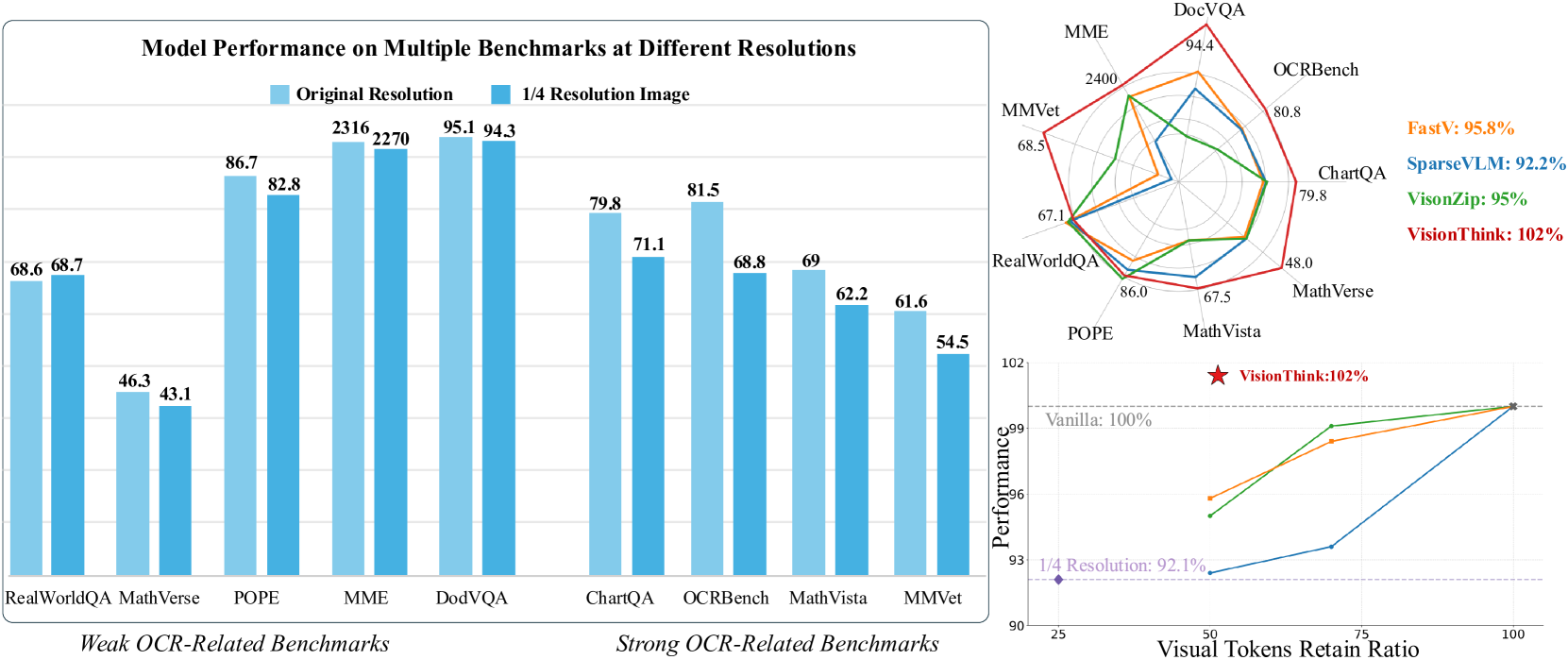
논문 소개
VisionThink은 시각-언어 모델(VLM)의 시각 토큰 수를 동적으로 조절하여 효율성을 높이는 새로운 방법론입니다. 초기에는 저해상도 이미지를 사용하고, 문제 해결에 충분하지 않을 경우에만 고해상도 이미지를 요청하는 방식으로, 고정된 토큰 압축 비율 대신 샘플별로 최적의 압축을 수행합니다. 강화학습과 LLM-as-Judge 전략을 도입하여 일반적인 시각질문응답(VQA) 과제에 적용하였으며, 보상 함수와 페널티 메커니즘을 통해 안정적인 이미지 크기 조절을 달성하였습니다. 실험 결과, OCR 관련 과제에서는 세밀한 시각 이해 능력을 유지하면서도 단순 과제에서는 시각 토큰 수를 크게 절감하는 우수한 성능과 효율성을 입증하였습니다.
논문 초록(Abstract)
최근 비전-언어 모델(VLM)의 발전은 시각 토큰 수를 증가시켜 성능을 향상시켰으며, 시각 토큰은 텍스트 토큰보다 훨씬 긴 경우가 많습니다. 그러나 대부분의 실제 시나리오에서는 이처럼 많은 시각 토큰이 필요하지 않다는 점을 관찰하였습니다. OCR 관련 작업의 일부 소규모 집합에서는 성능이 크게 저하되지만, 대부분의 일반적인 VQA(Visual Question Answering) 작업에서는 1/4 해상도만으로도 정확한 성능을 유지합니다. 이에 본 논문에서는 서로 다른 샘플에 대해 동적으로 해상도를 조절하여 처리하는 새로운 시각 토큰 압축 패러다임인 VisionThink를 제안합니다. VisionThink는 저해상도 이미지를 시작점으로 하여 문제 해결에 충분한지 스마트하게 판단하며, 그렇지 않은 경우 더 높은 해상도의 이미지를 요청하는 특수 토큰을 출력할 수 있습니다. 기존의 고정된 가지치기 비율 또는 임계값을 사용하여 토큰을 압축하는 효율적 VLM 방법과 달리, VisionThink는 사례별로 토큰 압축 여부를 자율적으로 결정합니다. 그 결과 OCR 관련 작업에서 세밀한 시각 이해 능력을 발휘하는 동시에, 단순한 작업에서는 상당한 시각 토큰 절약 효과를 보입니다. 강화학습을 도입하고, LLM-as-Judge 전략을 제안하여 일반적인 VQA 작업에 성공적으로 RL을 적용하였습니다. 또한 안정적이고 합리적인 이미지 크기 조정 호출 비율을 달성하기 위해 보상 함수와 페널티 메커니즘을 정교하게 설계하였습니다. 광범위한 실험을 통해 본 방법의 우수성, 효율성 및 효과성을 입증하였습니다. 본 코드 저장소는 GitHub - JIA-Lab-research/VisionThink: [NeurIPS 2025] Efficient Reasoning Vision Language Models 에서 확인할 수 있습니다.
Recent advancements in vision-language models (VLMs) have improved performance by increasing the number of visual tokens, which are often significantly longer than text tokens. However, we observe that most real-world scenarios do not require such an extensive number of visual tokens. While the performance drops significantly in a small subset of OCR-related tasks, models still perform accurately in most other general VQA tasks with only 1/4 resolution. Therefore, we propose to dynamically process distinct samples with different resolutions, and present a new paradigm for visual token compression, namely, VisionThink. It starts with a downsampled image and smartly decides whether it is sufficient for problem solving. Otherwise, the model could output a special token to request the higher-resolution image. Compared to existing Efficient VLM methods that compress tokens using fixed pruning ratios or thresholds, VisionThink autonomously decides whether to compress tokens case by case. As a result, it demonstrates strong fine-grained visual understanding capability on OCR-related tasks, and meanwhile saves substantial visual tokens on simpler tasks. We adopt reinforcement learning and propose the LLM-as-Judge strategy to successfully apply RL to general VQA tasks. Moreover, we carefully design a reward function and penalty mechanism to achieve a stable and reasonable image resize call ratio. Extensive experiments demonstrate the superiority, efficiency, and effectiveness of our method. Our code is available at GitHub - JIA-Lab-research/VisionThink: [NeurIPS 2025] Efficient Reasoning Vision Language Models.
논문 링크
더 읽어보기
https://github.com/dvlab-research/VisionThink
RAG-MCP: 검색-증강 생성을 통한 LLM 도구 선택 시 프롬프트 과부하 완화 방법 / RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation
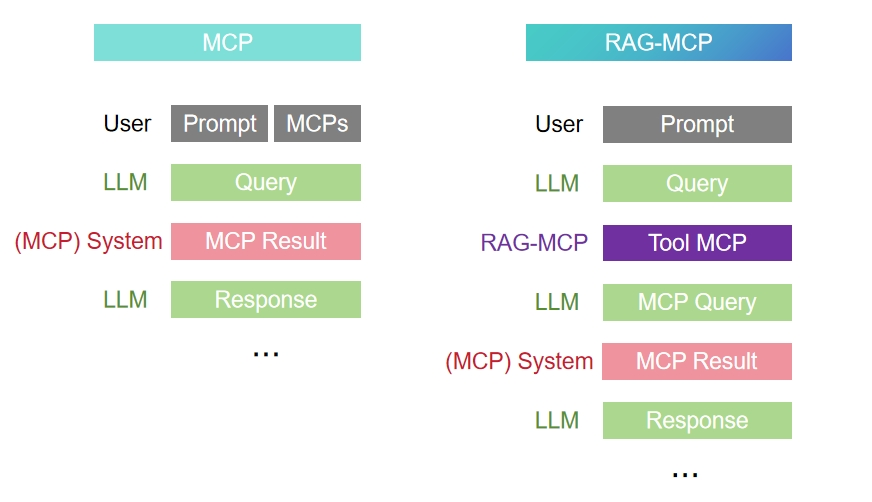
논문 소개
대규모 언어 모델(LLM)이 Model Context Protocol(MCP)로 정의된 다양한 외부 도구를 활용할 때, 프롬프트 과부하와 선택 복잡성 문제를 겪는다는 점에 주목하였습니다. RAG-MCP는 검색 증강 생성(Retrieval-Augmented Generation) 방식을 도입하여, 외부 인덱스에서 쿼리와 가장 관련성 높은 MCP를 의미 기반 검색으로 선별함으로써 도구 탐색 부담을 줄입니다. 이로 인해 모델에 전달되는 프롬프트 크기가 크게 감소하고 도구 선택 정확도가 3배 이상 향상되는 효과를 보였습니다. 결과적으로 RAG-MCP는 LLM의 도구 통합을 보다 확장 가능하고 정확하게 만드는 방법을 제시합니다.
논문 초록(Abstract)
대형 언어 모델(LLM)은 Model Context Protocol(MCP)\cite{IntroducingMCP}로 정의된 외부 도구의 수가 증가함에 따라 프롬프트 부피 증가와 선택 복잡성으로 인해 이를 효과적으로 활용하는 데 어려움을 겪고 있습니다. 본 논문에서는 도구 탐색 부담을 분산시켜 이러한 문제를 해결하는 검색-증강 생성(RAG) 프레임워크인 RAG-MCP를 제안합니다. RAG-MCP는 외부 인덱스에서 주어진 쿼리에 가장 적합한 MCP를 의미 기반 검색을 통해 식별한 후 LLM에 전달합니다. 모델에는 선택된 도구 설명만 전달되어 프롬프트 크기를 대폭 줄이고 의사결정을 단순화합니다. MCP 스트레스 테스트를 포함한 실험 결과, RAG-MCP는 프롬프트 토큰 수를 50% 이상 절감하고 벤치마크 과제에서 도구 선택 정확도를 13.62%의 기준선 대비 43.13%로 3배 이상 향상시킴을 보여줍니다. RAG-MCP는 LLM의 확장 가능하고 정확한 도구 통합을 가능하게 합니다.
Large language models (LLMs) struggle to effectively utilize a growing number of external tools, such as those defined by the Model Context Protocol (MCP)\cite{IntroducingMCP}, due to prompt bloat and selection complexity. We introduce RAG-MCP, a Retrieval-Augmented Generation framework that overcomes this challenge by offloading tool discovery. RAG-MCP uses semantic retrieval to identify the most relevant MCP(s) for a given query from an external index before engaging the LLM. Only the selected tool descriptions are passed to the model, drastically reducing prompt size and simplifying decision-making. Experiments, including an MCP stress test, demonstrate RAG-MCP significantly cuts prompt tokens (e.g., by over 50%) and more than triples tool selection accuracy (43.13% vs 13.62% baseline) on benchmark tasks. RAG-MCP enables scalable and accurate tool integration for LLMs.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()