
DINOv3 소개
DINOv3는 Meta AI가 개발한 차세대 자기지도학습(Self-Supervised Learning, SSL) 기반 비전 모델로, 대규모 이미지 데이터에서 범용적으로 활용 가능한 고성능 시각 백본(vision backbone)을 제공합니다. 기존의 강력한 이미지 인코딩 모델들이 웹 캡션 같은 사람 손으로 작성된 메타데이터에 의존했던 것과 달리, DINOv3는 전혀 라벨이 없는 상태에서 이미지 데이터로부터 의미있는 시각 표현을 스스로 학습하는 자기 지도 학습(Self-Supervised Learning, SSL) 기반의 비전 모델입니다.이를 통해 라벨 수집이 어렵거나 불가능한 분야에서도 대규모 학습이 가능해졌습니다.
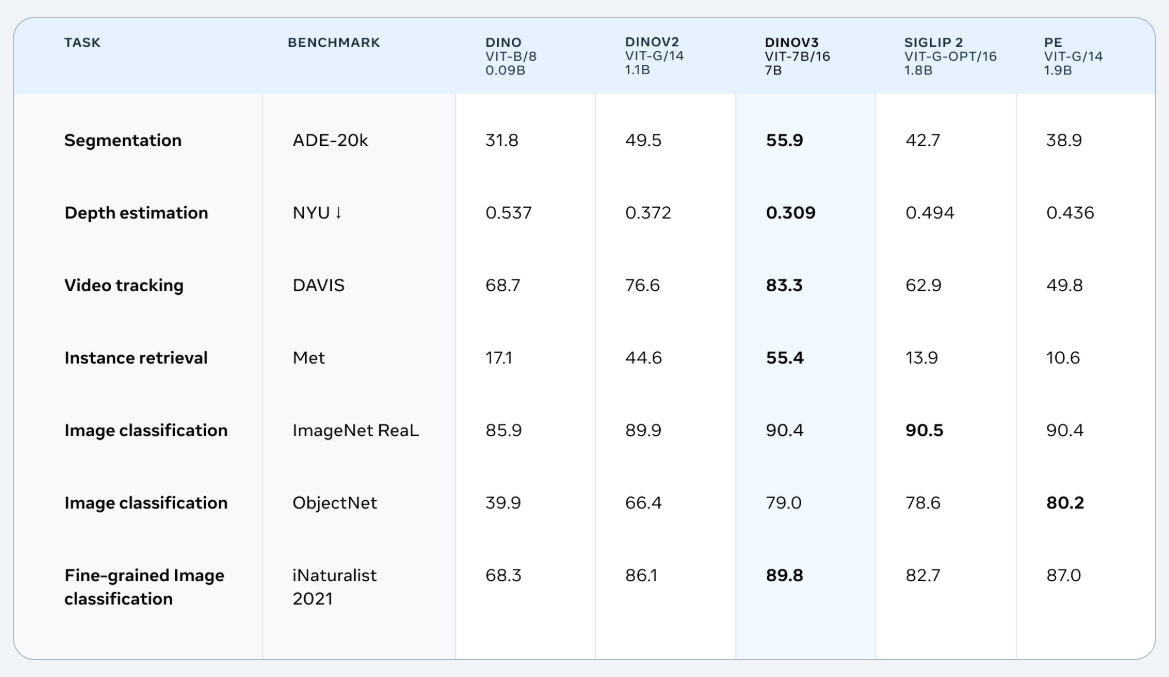
특히, DINOv3는 다양한 이미지 도메인에 걸쳐 범용적으로 사용 가능한 백본을 제공함으로써, 웹 이미지뿐만 아니라 위성, 의료, 산업용 이미지를 포함한 다양한 도메인에서 활용할 수 있으며, 이미지 분류, 객체 탐지, 시맨틱 분할, 비디오 객체 추적 등 폭넓은 비전 작업에서 최첨단 성능을 기록합니다. 17억 장의 이미지와 최대 70억 개의 파라미터로 학습하여 단일 백본으로도 밀집 예측(dense prediction) 작업에서 전문 모델을 초월하는 결과를 보여줍니다.
DINO 계열 모델과 자기 지도 학습(SSL)의 흐름
DINO는 2021년 공개된 첫 버전부터 Vision Transformer(ViT)를 기반으로, 학습자(학생)-참조자(교사)의 지식 증류(distillation) 메커니즘을 활용해 자기 지도 학습을 구현해왔습니다. DINOv2에서는 이미지 표현 학습을 보다 정제된 이미지 셋에서 수행하면서 범용성과 정확도를 개선했고, DINOv3는 이를 계승하여 더욱 큰 스케일과 강력한 백본으로 성능을 극대화한 버전입니다.
DINOv2도 자기지도학습 기반으로 높은 성능을 보여줬지만, DINOv3는 이를 한층 발전시켜 더 큰 모델 규모(7B 파라미터)와 12배 더 큰 학습 데이터셋을 사용했습니다. 성능 면에서도, 특히 시맨틱 분할, 객체 탐지, 깊이 추정 같은 밀집 예측 작업에서 DINOv2 대비 월등히 향상되었습니다.
또한 DINOv3는 CLIP 기반 모델(SigLIP 2, Perception Encoder 등)과 비교 시 다양한 이미지 분류 벤치마크에서 동등하거나 그 이상을 기록하며, 밀집 예측에서는 압도적인 우위를 보입니다. DINOv3는 라벨 없는 상태에서 학습했음에도, 라벨이 있는 약지도(weakly supervised) 모델보다 성능이 더 높다는 점이 특징입니다.
DINO 계열 모델들의 핵심은, 텍스트나 외부 라벨 없이 이미지 자체만으로도 강력한 표현을 학습할 수 있다는 점입니다. CLIP과 같은 텍스트-이미지 쌍 기반 모델과는 달리, DINO는 오직 이미지 간 유사도와 구조만으로 시각적 의미를 파악하고 학습합니다. 이를 위해서는 모델 아키텍처와 학습 기법 모두에서 섬세한 설계가 요구됩니다.
DINOv3 아키텍처 구성
DINOv3는 Vision Transformer(ViT)와 ConvNeXt 두 가지 백본 구조를 지원하며, 그 중에서도 ViT 기반이 주류입니다. 특히 ViT-g/14 모델은 약 70억 개의 파라미터를 가지며, 이는 ViT-H/14보다도 크고 CLIP ViT 모델을 능가하는 스케일입니다.
교사-학생 구조
- 학생(Student) 네트워크는 인코딩하고자 하는 입력 이미지를 다양한 증강 방식으로 변형된 뷰(views)로 처리합니다.
- 교사(Teacher) 네트워크는 EMA(Exponential Moving Average)를 통해 학생 네트워크의 가중치로부터 업데이트되며, 직접 학습되지 않습니다.
- Loss는 서로 다른 뷰들 간의 예측 일관성을 최대화하도록 설계됩니다. 이는 서로 다른 증강 이미지를 같은 것으로 인식하도록 모델이 스스로 학습하게 합니다.
입력 증강 및 멀티크롭 전략
- 입력 이미지는 다양한 해상도와 위치로 잘라진 여러 crop(예: 224×224, 96×96)으로 생성됩니다.
- 교사는 대형 crop만 사용하고, 학생은 대형 및 소형 crop을 함께 사용하여 더욱 강건한 표현을 유도합니다.
- 이러한 멀티크롭(multicropping)은 모델이 다양한 공간 및 시각 스케일에서 일관된 표현을 학습하도록 도와줍니다.
MLP Head
- 각 백본 출력 후에는 MLP 헤드가 붙어, 최종적으로 표현(feature embedding)을 생성합니다.
- 이 표현은 downstream task (분류, 분할 등)에 그대로 활용될 수 있습니다.
- MLP 헤드는 교사-학생 간 출력을 정렬시키는 핵심 위치입니다.
학습 방식과 최적화 전략
대규모 비지도 학습
DINOv3는 17억 개의 웹 이미지로 학습되었습니다. 이 이미지들은 라벨이 없으며, CLIP의 사전학습 이미지보다 4배 많고 품질도 뛰어납니다. 또한 단일 GPU로는 학습이 불가능하며, 대규모 클러스터에서 수 주간 학습됩니다.
성능을 끌어올린 최적화 기법
- Sharpness-Aware Minimization(SAM) 기법이 적용되어, 일반적인 SGD나 Adam보다 일반화 성능이 뛰어납니다.
- EMA decay 파라미터 조정으로 학생-교사 간 동기화를 세밀히 조절합니다.
- Cosine similarity loss 및 centering 기법을 통해 출력의 다양성과 안정성을 동시에 확보합니다.
DINOv3의 주요 특징
-
자기지도학습(SSL)과 대규모 학습: DINOv3의 핵심은 대규모 라벨 없는 데이터로부터 범용 시각 표현을 학습하는 능력입니다. 이를 통해 위성 이미지, 의료 영상, 산업용 데이터 등 라벨링이 어려운 데이터셋에서도 고성능 모델을 만들 수 있습니다. 예를 들어, 위성 이미지 기반 숲 캐노피 높이 추정에서 DINOv2 대비 오차를 4.1m → 1.2m로 줄였습니다.
-
파인튜닝 없이도 최첨단 성능: DINOv3는 백본 가중치를 고정(frozen)한 상태에서도 객체 탐지, 시맨틱 분할, 깊이 추정 같은 핵심 비전 작업에서 최첨단 성능을 기록합니다. 이는 다양한 애플리케이션에서 동일한 백본을 공유할 수 있어, 엣지 디바이스나 멀티태스크 환경에서 연산 효율성을 극대화합니다.
-
다양한 모델 크기 제공: Meta는 7B 모델뿐만 아니라, 경량화된 ViT-B, ViT-L, ConvNeXt(T/S/B/L) 구조로도 DINOv3를 distillation하여 공개했습니다. 이를 통해 모바일·임베디드 환경 등 자원 제약이 있는 환경에서도 활용할 수 있습니다.
-
실제 활용 사례
라이선스
DINOv3 모델은 Commercial License로 공개 및 배포되고 있습니다. 상업적 사용이 가능하지만, 세부 조건은 라이선스 문서를 반드시 확인해야 합니다.
 DINOv3 공식 홈페이지
DINOv3 공식 홈페이지
 Meta AI의 DINOv3 공개 블로그
Meta AI의 DINOv3 공개 블로그
DINOv3 논문
 DINOv3 GitHub 저장소
DINOv3 GitHub 저장소
https://github.com/facebookresearch/dinov3
 DINOv3 모델 다운로드
DINOv3 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()