[2026/01/26 ~ 02/01] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 개별 모델을 넘어선 "조직적 지능(Organizational Intelligence)"의 부상: 이번 주 가장 눈에 띄는 트렌드는 단일 AI 모델의 성능에 의존하기보다, 여러 에이전트를 구조화하여 시스템 전체의 신뢰성을 높이려는 시도입니다. "If You Want Coherence, Orchestrate a Team of Rivals" 논문은 인간의 기업 조직처럼 상반된 인센티브를 가진 에이전트 팀을 구성해 오류를 90% 이상 차단하는 아키텍처를 제시했습니다. 또한, Agent Drift 연구는 장기 상호작용에서 발생하는 에이전트의 행동 저하를 '안정성 지수(ASI)'로 정량화하고 이를 관리하는 방법론을 제안했습니다. 이는 AI를 단일 도구가 아닌, 관리와 통제가 가능한 하나의 '조직'으로 바라보기 시작했음을 의미합니다.
개별 모델을 넘어선 "조직적 지능(Organizational Intelligence)"의 부상: 이번 주 가장 눈에 띄는 트렌드는 단일 AI 모델의 성능에 의존하기보다, 여러 에이전트를 구조화하여 시스템 전체의 신뢰성을 높이려는 시도입니다. "If You Want Coherence, Orchestrate a Team of Rivals" 논문은 인간의 기업 조직처럼 상반된 인센티브를 가진 에이전트 팀을 구성해 오류를 90% 이상 차단하는 아키텍처를 제시했습니다. 또한, Agent Drift 연구는 장기 상호작용에서 발생하는 에이전트의 행동 저하를 '안정성 지수(ASI)'로 정량화하고 이를 관리하는 방법론을 제안했습니다. 이는 AI를 단일 도구가 아닌, 관리와 통제가 가능한 하나의 '조직'으로 바라보기 시작했음을 의미합니다.
![]() "추론 시점(Test-Time)"의 학습과 동적 최적화를 통한 성능 한계 돌파: 모델이 학습된 상태로 고정되지 않고, 실제 문제를 푸는 순간(추론 시점)에 실시간으로 진화하는 기술들이 주목받고 있습니다. TTT-Discover는 추론 단계에서 강화학습을 수행하여 과학적 난제나 알고리즘 설계에서 새로운 최첨단(SOTA) 기록을 세우는 성과를 보였으며, G2RL은 모델 내부의 그래디언트 기하학을 활용해 추론 과정에서 스스로 탐색 방향을 가이드합니다. 아울러 Deep Delta Learning은 표준 잔차 연결을 데이터 의존적인 기하학적 변환으로 대체하여 복잡한 비선형 동역학을 더 유연하게 모델링합니다. 이러한 '추론 중 진화'는 고정된 모델이 해결하지 못했던 초난도 문제 해결의 열쇠가 되고 있습니다.
"추론 시점(Test-Time)"의 학습과 동적 최적화를 통한 성능 한계 돌파: 모델이 학습된 상태로 고정되지 않고, 실제 문제를 푸는 순간(추론 시점)에 실시간으로 진화하는 기술들이 주목받고 있습니다. TTT-Discover는 추론 단계에서 강화학습을 수행하여 과학적 난제나 알고리즘 설계에서 새로운 최첨단(SOTA) 기록을 세우는 성과를 보였으며, G2RL은 모델 내부의 그래디언트 기하학을 활용해 추론 과정에서 스스로 탐색 방향을 가이드합니다. 아울러 Deep Delta Learning은 표준 잔차 연결을 데이터 의존적인 기하학적 변환으로 대체하여 복잡한 비선형 동역학을 더 유연하게 모델링합니다. 이러한 '추론 중 진화'는 고정된 모델이 해결하지 못했던 초난도 문제 해결의 열쇠가 되고 있습니다.
![]() 비용 효율 극대화: "소형 모델(SLM)"의 반란과 하드웨어 병목 해결: 거대 모델(LLM)의 고비용 구조를 탈피하여, 작지만 강력한 시스템을 구축하려는 실용적 연구가 활발합니다. ToolOrchestra는 8B 수준의 가벼운 오케스트레이터 모델이 도구를 효율적으로 관리하여 GPT-5보다 2.5배 높은 효율로 복잡한 시험을 통과할 수 있음을 입증했습니다. 또한, Small Language Models for Efficient Agentic Tool Calling은 특정 도메인에 특화된 파인튜닝을 통해 350M 규모의 아주 작은 모델이 대형 모델의 도구 호출 성능을 능가할 수 있음을 보여주었습니다. 이러한 흐름은 LLM Inference Hardware 논문에서 지적한 메모리 대역폭 문제를 해결하려는 하드웨어적 접근과 맞물려, AI의 실질적인 상용화 문턱을 낮추고 있습니다.
비용 효율 극대화: "소형 모델(SLM)"의 반란과 하드웨어 병목 해결: 거대 모델(LLM)의 고비용 구조를 탈피하여, 작지만 강력한 시스템을 구축하려는 실용적 연구가 활발합니다. ToolOrchestra는 8B 수준의 가벼운 오케스트레이터 모델이 도구를 효율적으로 관리하여 GPT-5보다 2.5배 높은 효율로 복잡한 시험을 통과할 수 있음을 입증했습니다. 또한, Small Language Models for Efficient Agentic Tool Calling은 특정 도메인에 특화된 파인튜닝을 통해 350M 규모의 아주 작은 모델이 대형 모델의 도구 호출 성능을 능가할 수 있음을 보여주었습니다. 이러한 흐름은 LLM Inference Hardware 논문에서 지적한 메모리 대역폭 문제를 해결하려는 하드웨어적 접근과 맞물려, AI의 실질적인 상용화 문턱을 낮추고 있습니다.
일관성을 원한다면 경쟁 팀을 조율하라: 조직 지능의 다중 에이전트 모델 / If You Want Coherence, Orchestrate a Team of Rivals: Multi-Agent Models of Organizational Intelligence
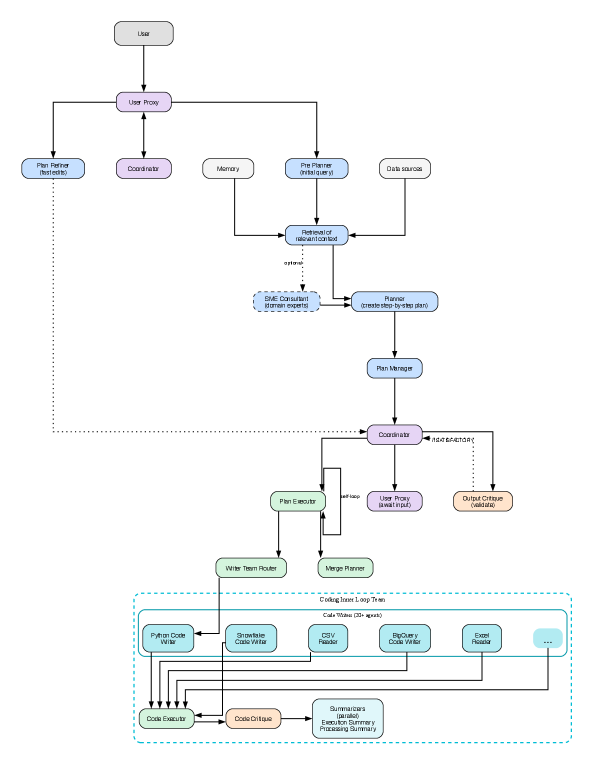
논문 소개
AI 에이전트는 복잡한 작업을 신속하게 수행할 수 있는 능력을 지니고 있지만, 그들의 지능은 인간과 마찬가지로 오류가 발생할 수 있는 한계를 가지고 있다. 이러한 문제는 잘못된 의사소통, 체계적 편향, 그리고 내부 독백의 부족에서 비롯된다. 본 연구에서는 독립적인 AI 에이전트 팀을 구성하여 일반적인 기업 조직 구조를 재사용하는 방안을 제안한다. 각 팀은 공통의 목표를 가지고 있으나 상반된 인센티브를 통해 운영되며, 이를 통해 최종 제품의 오류를 포착하고 최소화할 수 있다.
제안된 시스템은 완벽한 구성 요소를 필요로 하지 않으며, 불완전한 구성 요소의 신중한 조정을 통해 신뢰성을 달성할 수 있음을 보여준다. 이 시스템은 전문화된 에이전트 팀(계획자, 실행자, 비평가, 전문가)으로 구성되어 있으며, 원격 코드 실행기를 통해 데이터 변환과 도구 호출을 분리하여 조정된다. 에이전트는 도구를 직접 호출하는 대신 원격으로 실행되는 코드를 작성하고, 관련 요약만이 에이전트의 컨텍스트로 반환된다. 이러한 방식은 원시 데이터와 도구 출력이 컨텍스트 창을 오염시키지 않도록 하여 인식과 실행 간의 명확한 분리를 유지한다.
본 연구는 사용자 노출 이전에 90% 이상의 내부 오류 차단을 달성하면서도 허용 가능한 지연 거래를 유지하는 성과를 보여준다. 또한, 이 시스템은 다중 사용자 상호작용과 사후 감사 메커니즘을 포함하여 AI 시스템의 조직 신뢰성을 증명하는 데 기여한다. 이러한 접근 방식은 다중 에이전트 시스템의 설계 및 운영에 있어 중요한 혁신을 제공하며, 다양한 도메인에서의 적용 가능성을 제시한다.
논문 초록(Abstract)
AI 에이전트는 빠른 속도로 복잡한 작업을 수행할 수 있지만, 우리가 지금까지 고용한 모든 인간과 마찬가지로 그들의 지능은 오류가 발생할 수 있습니다. 의사소통의 오류는 인식되지 않으며, 시스템적 편향에 대한 대책은 없고, 내적 독백은 거의 기록되지 않습니다. 우리는 그들의 실수 때문에 그들을 해고하러 온 것이 아니라, 그들을 고용하고 안전하고 생산적인 작업 환경을 제공하기 위해 왔습니다. 우리는 공통의 기업 조직 구조를 재사용할 수 있다고 주장합니다: 독립적인 AI 에이전트 팀이 엄격한 역할 경계를 가지고 공통의 목표를 가지고 작업하되, 상반된 인센티브를 가질 수 있습니다. 경쟁하는 팀으로서 여러 모델이 최종 제품 내의 오류를 포착하고 최소화할 수 있으며, 이는 행동의 속도에 대한 작은 비용으로 가능합니다. 본 논문에서는 완벽한 구성 요소를 획득하지 않고도 불완전한 구성 요소의 신중한 조정을 통해 신뢰성을 달성할 수 있음을 보여줍니다. 이 논문은 실제로 이러한 시스템의 아키텍처를 설명합니다: 명확한 목표를 가진 조직으로 구성된 전문 에이전트 팀(계획자, 실행자, 비평가, 전문가)이 있으며, 데이터 변환과 도구 호출을 추론 모델과 분리하여 원격 코드 실행기를 통해 조정됩니다. 에이전트가 도구를 직접 호출하고 전체 응답을 수신하는 대신, 원격으로 실행되는 코드를 작성하며, 관련 요약만 에이전트의 맥락으로 반환됩니다. 원시 데이터와 도구 출력이 맥락 창을 오염시키지 않도록 함으로써, 시스템은 인식(계획하고 추론하는 두뇌)과 실행(무거운 데이터 변환 및 API 호출을 수행하는 손) 간의 깨끗한 분리를 유지합니다. 우리는 이 접근 방식이 사용자 노출 이전에 90% 이상의 내부 오류 차단을 달성하면서도 수용 가능한 지연 거래를 유지함을 보여줍니다. 우리의 추적 조사에 따르면, 우리는 정확성을 달성하고 기존 기능에 영향을 주지 않으면서 점진적으로 능력을 확장하기 위해 비용과 지연을 거래하고 있습니다.
AI Agents can perform complex operations at great speed, but just like all the humans we have ever hired, their intelligence remains fallible. Miscommunications aren't noticed, systemic biases have no counter-action, and inner monologues are rarely written down. We did not come to fire them for their mistakes, but to hire them and provide a safe productive working environment. We posit that we can reuse a common corporate organizational structure: teams of independent AI agents with strict role boundaries can work with common goals, but opposing incentives. Multiple models serving as a team of rivals can catch and minimize errors within the final product at a small cost to the velocity of actions. In this paper we demonstrate that we can achieve reliability without acquiring perfect components, but through careful orchestration of imperfect ones. This paper describes the architecture of such a system in practice: specialized agent teams (planners, executors, critics, experts), organized into an organization with clear goals, coordinated through a remote code executor that keeps data transformations and tool invocations separate from reasoning models. Rather than agents directly calling tools and ingesting full responses, they write code that executes remotely; only relevant summaries return to agent context. By preventing raw data and tool outputs from contaminating context windows, the system maintains clean separation between perception (brains that plan and reason) and execution (hands that perform heavy data transformations and API calls). We demonstrate the approach achieves over 90% internal error interception prior to user exposure while maintaining acceptable latency tradeoffs. A survey from our traces shows that we only trade off cost and latency to achieve correctness and incrementally expand capabilities without impacting existing ones.
논문 링크
대규모 언어 모델 추론 하드웨어의 도전 과제 및 연구 방향 / Challenges and Research Directions for Large Language Model Inference Hardware


논문 소개
대규모 언어 모델(LLM) 추론은 어려운 작업입니다. 기본적인 트랜스포머 모델의 자기 회귀 디코드 단계는 LLM 추론을 학습과 근본적으로 다르게 만듭니다. 최근 AI 트렌드로 인해 주요 도전 과제는 계산보다는 메모리와 인터커넥트에 있습니다. 이러한 도전 과제를 해결하기 위해 네 가지 아키텍처 연구 기회를 제시합니다: HBM과 유사한 대역폭을 가진 10배 메모리 용량을 위한 고대역폭 플래시, 높은 메모리 대역폭을 위한 메모리 근처 처리 및 3D 메모리-로직 스태킹, 그리고 통신 속도를 높이기 위한 저지연 인터커넥트입니다. 본 연구는 데이터 센터 AI에 중점을 두지만, 모바일 장치에 대한 적용 가능성도 검토합니다.
논문 초록(Abstract)
대규모 언어 모델(LLM) 추론은 어렵습니다. 기본 트랜스포머 모델의 자가 회귀 디코드 단계는 LLM 추론을 학습과 근본적으로 다르게 만듭니다. 최근 AI 트렌드로 인해 메모리와 상호 연결성이 주요 도전 과제가 되며, 계산 능력보다는 이 두 가지가 더 중요해졌습니다. 이러한 도전 과제를 해결하기 위해 우리는 네 가지 아키텍처 연구 기회를 강조합니다: HBM과 유사한 대역폭을 가진 10배 메모리 용량을 위한 고대역폭 플래시; 높은 메모리 대역폭을 위한 메모리 근처 처리 및 3D 메모리-로직 스태킹; 그리고 통신 속도를 높이기 위한 저지연 상호 연결. 우리의 초점은 데이터센터 AI에 있지만, 모바일 장치에 대한 적용 가능성도 검토합니다.
Large Language Model (LLM) inference is hard. The autoregressive Decode phase of the underlying Transformer model makes LLM inference fundamentally different from training. Exacerbated by recent AI trends, the primary challenges are memory and interconnect rather than compute. To address these challenges, we highlight four architecture research opportunities: High Bandwidth Flash for 10X memory capacity with HBM-like bandwidth; Processing-Near-Memory and 3D memory-logic stacking for high memory bandwidth; and low-latency interconnect to speedup communication. While our focus is datacenter AI, we also review their applicability for mobile devices.
논문 링크
효율적인 에이전트 도구 호출을 위한 소형 언어 모델: 목표 지향적 파인튜닝으로 대형 모델을 능가하다 / Small Language Models for Efficient Agentic Tool Calling: Outperforming Large Models with Targeted Fine-tuning
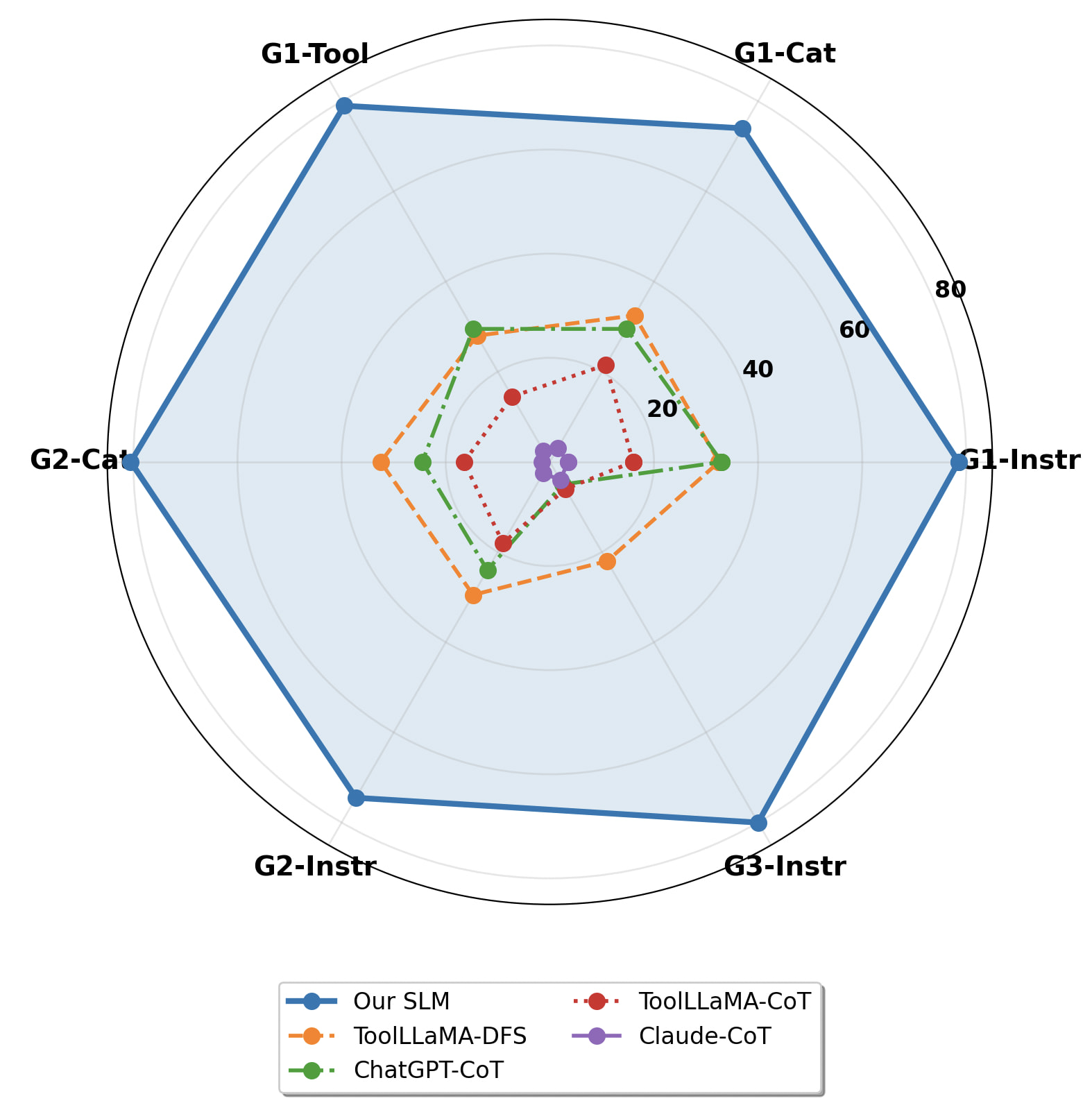
논문 소개
생성적 인공지능의 채택이 증가함에 따라, 모델의 비용 최적화와 운영 효율성은 기업의 지속 가능성과 접근성을 결정짓는 중요한 요소로 자리 잡고 있다. 대규모 언어 모델(LLM)은 다양한 작업에서 뛰어난 성능을 보여주지만, 그 방대한 계산 요구 사항으로 인해 일상적인 기업 사용에는 경제적 부담이 따른다. 이러한 문제를 해결하기 위해 소규모 언어 모델(SLM)의 가능성을 탐구하는 연구가 필요하다. 본 연구에서는 LLM 기반의 워크플로우를 최적화된 SLM으로 대체할 수 있는 가능성을 조사하며, 문서 요약, 질의 응답 및 구조화된 데이터 해석과 같은 전통적으로 LLM이 처리하던 작업을 수행하기 위해 도메인 적응된 SLM을 훈련하였다.
특히, facebook/opt-350m 모델을 단일 에폭으로 Hugging Face TRL(Transformer Reinforcement Learning)에서 Supervised Fine-Tuning(SFT) 트레이너를 사용하여 파인튜닝하였다. 실험 결과, 파인튜닝된 SLM은 ToolBench 평가에서 77.55%의 패스율을 기록하며, ChatGPT-CoT(26.00%), ToolLLaMA-DFS(30.18%), ToolLLaMA-CoT(16.27%)와 같은 기준 모델을 크게 초과하는 성과를 보였다. 이러한 결과는 SLM의 신중한 설계와 목표 지향적 훈련이 생성적 AI의 대규모 통합을 가능하게 하며, 비용 효율적인 솔루션을 제공할 수 있음을 입증한다.
본 연구는 LLM의 운영적 도전 과제를 해결하고, SLM의 효율성을 극대화하는 방법론을 제시함으로써, AI 기술의 접근성을 높이고 기업이 정교한 AI 기능을 부담 없이 배포할 수 있는 길을 열어준다. SLM의 목표 지향적 파인튜닝 접근 방식은 기존의 매개변수-성능 트레이드오프를 극복할 수 있는 혁신적인 방법을 제시하며, 향후 연구에서는 이러한 접근 방식의 일반화 가능성을 탐구할 필요가 있다.
논문 초록(Abstract)
조직들이 생성적 AI의 채택을 확대함에 따라, 모델 비용 최적화와 운영 효율성이 지속 가능성과 접근성을 결정하는 중요한 요소로 부각되고 있습니다. 대규모 언어 모델(LLM)은 다양한 작업에서 인상적인 능력을 보여주지만, 그 방대한 계산 요구 사항으로 인해 일상적인 기업 사용에는 비용이 prohibitive합니다. 이러한 제한은 특정 애플리케이션에서 비교 가능한 성능을 제공하면서 인프라 오버헤드를 대폭 줄일 수 있는 소규모 언어 모델(SLM)의 탐색을 촉진합니다 (Irugalbandara et al., 2023). 본 연구에서는 LLM 기반 워크플로우를 최적화된 SLM으로 대체하는 가능성을 조사합니다. 우리는 문서 요약, 질의 응답, 구조화된 데이터 해석과 같은 전통적으로 LLM이 처리하던 대표적인 작업을 수행하기 위해 도메인에 적합한 SLM을 학습시켰습니다. 실험의 일환으로, 우리는 Hugging Face TRL(Transformer Reinforcement Learning)을 사용하여 facebook/opt-350m 모델(단일 에포크만)을 파인튜닝하는 과정을 조사했습니다. OPT-350M 모델은 2022년 메타 AI에 의해 OPT(오픈 사전학습 트랜스포머) 모델 가족의 일환으로 출시되었습니다. 유사한 연구들은 350M 매개변수 규모의 모델조차도 지시 튜닝 파이프라인에 의미 있게 기여할 수 있음을 보여줍니다 (Mekala et al., 2024). 실험 결과, 우리의 파인튜닝된 SLM은 ToolBench 평가에서 77.55%의 통과율을 기록하며, ChatGPT-CoT(26.00%), ToolLLaMA-DFS(30.18%), ToolLLaMA-CoT(16.27%)를 포함한 모든 기준 모델을 크게 초월하는 뛰어난 성능을 달성했습니다. 이러한 결과는 SLM의 신중한 설계와 목표 지향적 훈련이 채택 장벽을 크게 낮출 수 있음을 강조하며, 생성적 AI를 생산 시스템에 비용 효율적으로 대규모 통합할 수 있는 가능성을 열어줍니다.
As organizations scale adoption of generative AI, model cost optimization and operational efficiency have emerged as critical factors determining sustainability and accessibility. While Large Language Models (LLMs) demonstrate impressive capabilities across diverse tasks, their extensive computational requirements make them cost-prohibitive for routine enterprise use. This limitation motivates the exploration of Small Language Models (SLMs), which can deliver comparable performance in targeted applications while drastically reducing infrastructure overhead (Irugalbandara et al., 2023). In this work, we investigate the feasibility of replacing LLM-driven workflows with optimized SLMs. We trained a domain-adapted SLM to execute representative tasks traditionally handled by LLMs, such as document summarization, query answering, and structured data interpretation. As part of the experiment, we investigated the fine-tuning of facebook/opt-350m model (single epoch only) using the Hugging Face TRL (Transformer Reinforcement Learning), specifically the Supervised Fine-Tuning (SFT) trainer. The OPT-350M model was released by Meta AI in 2022 as part of the OPT (Open Pretrained Transformer) family of models. Similar studies demonstrate that even models at the 350M parameter scale can meaningfully contribute to instruction-tuning pipelines (Mekala et al., 2024). Experimental results demonstrated that our fine-tuned SLM achieves exceptional performance with a 77.55% pass rate on ToolBench evaluation, significantly outperforming all baseline models including ChatGPT-CoT (26.00%), ToolLLaMA-DFS (30.18%), and ToolLLaMA-CoT (16.27%). These findings emphasize that thoughtful design and targeted training of SLMs can significantly lower barriers to adoption, enabling cost-effective, large-scale integration of generative AI into production systems.
논문 링크
딥 델타 학습 / Deep Delta Learning

논문 소개
딥 잔차 네트워크의 효율성은 아이덴티티 숏컷 연결에 크게 의존하고 있으며, 이는 소실 그래디언트 문제를 완화하는 데 효과적입니다. 그러나 이러한 메커니즘은 피처 변환에 대해 엄격한 가산적 귀납적 편향을 부여하여 복잡한 상태 전이를 모델링하는 데 한계를 지니고 있습니다. 이러한 문제를 해결하기 위해, 본 논문에서는 Deep Delta Learning (DDL)이라는 새로운 아키텍처를 제안합니다. DDL은 아이덴티티 숏컷을 학습 가능한 데이터 의존적 기하학적 변환으로 조절하는 델타 연산자를 도입하여 표준 잔차 연결을 일반화합니다.
델타 연산자는 아이덴티티 행렬의 랭크 1 섭동으로 정의되며, 반사 방향 벡터와 게이팅 스칼라로 매개변수화됩니다. 이 연산자는 네트워크가 동적으로 아이덴티티 매핑, 직교 투영 및 기하학적 반사 간의 보간을 가능하게 하여, 복잡한 비선형 동역학을 모델링할 수 있는 능력을 부여합니다. 또한, 잔차 업데이트를 동기화된 랭크 1 주입으로 재구성함으로써, 네트워크는 오래된 정보의 삭제와 새로운 피처의 기록을 조절하는 동적 스텝 크기를 설정할 수 있습니다. 이러한 접근은 레이어별 전이 연산자의 스펙트럼을 명시적으로 제어할 수 있게 하여, 안정적인 학습 특성을 유지하면서도 복잡한 데이터 패턴을 효과적으로 학습할 수 있도록 합니다.
본 논문에서 제안하는 델타 잔차 블록은 하우스홀더 행렬을 일반화하여, 상수 계수 2를 학습 가능한 데이터 의존적 스칼라 게이트로 대체합니다. 이로 인해 네트워크는 피처 차원에서 공간적으로 작용하는 델타 연산자를 통해 보다 유연한 상태 전이를 구현할 수 있습니다. 동적 게이팅 메커니즘은 상태 피처의 투영 후 시그모이드 함수를 통해 범위를 조절하여, 기하학적 해석을 풍부하게 합니다.
결론적으로, Deep Delta Learning은 기존 딥 잔차 네트워크의 한계를 극복하고, 복잡한 비선형 동역학을 모델링할 수 있는 혁신적인 방법론을 제시합니다. 이러한 접근은 다양한 응용 분야에서 성능 향상에 기여할 것으로 기대되며, 딥 러닝 연구의 새로운 방향을 제시합니다.
논문 초록(Abstract)
딥 잔차 네트워크의 효능은 본질적으로 항등 단축 연결에 기반하고 있습니다. 이 메커니즘은 소실 그래디언트 문제를 효과적으로 완화하지만, 특성 변환에 대해 엄격한 가산적 귀납적 편향을 부과하여 네트워크가 복잡한 상태 전이를 모델링하는 능력을 제한합니다. 본 논문에서는 Deep Delta Learning (DDL)이라는 새로운 아키텍처를 소개합니다. 이는 학습 가능한 데이터 의존적 기하학적 변환으로 항등 단축을 조절하여 표준 잔차 연결을 일반화합니다. 이 변환은 델타 연산자(Delta Operator)라고 하며, 항등 행렬의 1차 랭크 섭동으로 구성되며, 반사 방향 벡터 \mathbf{k}(\mathbf{X}) 와 게이팅 스칼라 β(\mathbf{X}) 로 매개변수화됩니다. 우리는 이 연산자의 스펙트럼 분석을 제공하며, 게이트 β(\mathbf{X}) 가 항등 매핑, 직교 투영 및 기하학적 반사 간의 동적 보간을 가능하게 함을 보여줍니다. 또한, 우리는 잔차 업데이트를 동기화된 1차 랭크 주입으로 재구성하며, 여기서 게이트는 오래된 정보를 지우고 새로운 특성을 기록하는 동적 스텝 크기로 작용합니다. 이러한 통합은 네트워크가 레이어별 전이 연산자의 스펙트럼을 명시적으로 제어할 수 있게 하여 복잡하고 비단조적인 동역학을 모델링하면서 게이티드 잔차 아키텍처의 안정적인 학습 특성을 유지할 수 있도록 합니다.
The efficacy of deep residual networks is fundamentally predicated on the identity shortcut connection. While this mechanism effectively mitigates the vanishing gradient problem, it imposes a strictly additive inductive bias on feature transformations, thereby limiting the network's capacity to model complex state transitions. In this paper, we introduce Deep Delta Learning (DDL), a novel architecture that generalizes the standard residual connection by modulating the identity shortcut with a learnable, data-dependent geometric transformation. This transformation, termed the Delta Operator, constitutes a rank-1 perturbation of the identity matrix, parameterized by a reflection direction vector \mathbf{k}(\mathbf{X}) and a gating scalar β(\mathbf{X}). We provide a spectral analysis of this operator, demonstrating that the gate β(\mathbf{X}) enables dynamic interpolation between identity mapping, orthogonal projection, and geometric reflection. Furthermore, we restructure the residual update as a synchronous rank-1 injection, where the gate acts as a dynamic step size governing both the erasure of old information and the writing of new features. This unification empowers the network to explicitly control the spectrum of its layer-wise transition operator, enabling the modeling of complex, non-monotonic dynamics while preserving the stable training characteristics of gated residual architectures.
논문 링크
더 읽어보기
보상 강제화: 보상 분포 일치 증류를 통한 효율적인 스트리밍 비디오 생성 / Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation

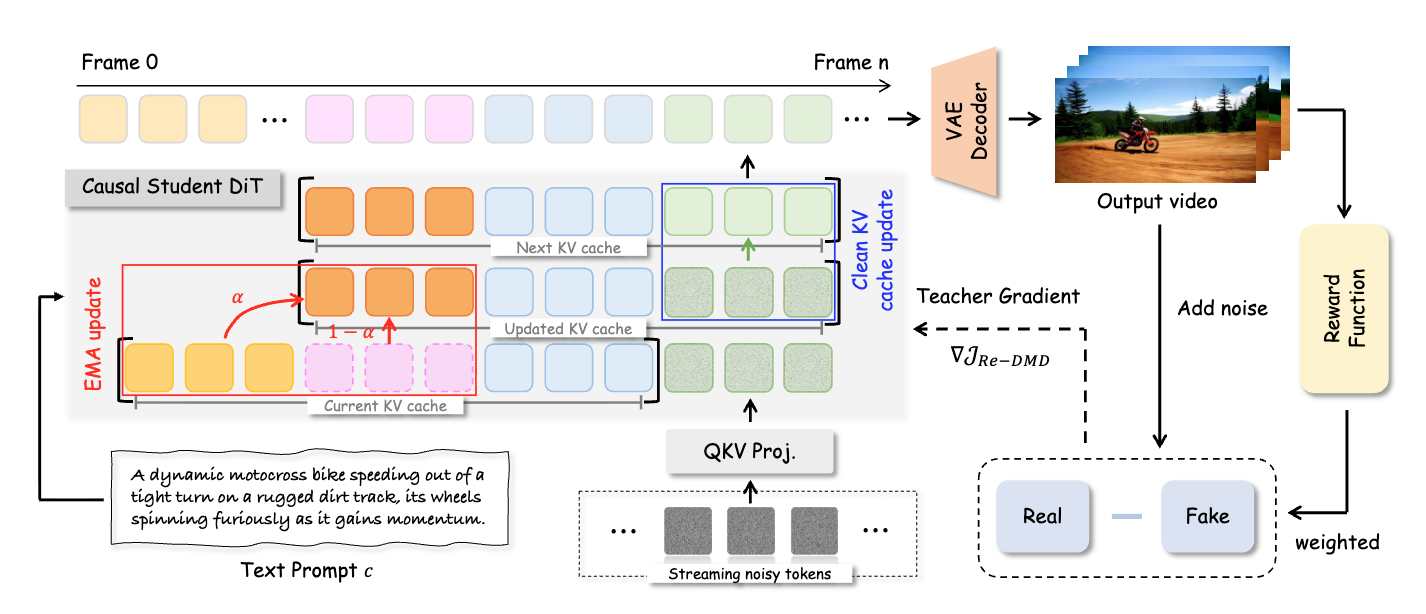
논문 소개
효율적인 스트리밍 비디오 생성은 상호작용적이고 동적인 세계를 시뮬레이션하는 데 필수적이다. 기존의 비디오 생성 방법들은 초기 프레임을 싱크 토큰으로 활용하여 슬라이딩 윈도우 어텐션을 통해 비디오 확산 모델을 증류하지만, 이로 인해 비디오 프레임이 정적 토큰에 지나치게 의존하게 되어 초기 프레임이 복사되고 동작 역학이 저하되는 문제가 발생한다. 이러한 문제를 해결하기 위해 제안된 Reward Forcing 프레임워크는 두 가지 주요 설계를 포함하고 있다.
첫째, EMA-Sink는 초기 프레임에서 초기화된 고정 크기 토큰을 유지하고, 슬라이딩 윈도우를 벗어나는 토큰을 지수 이동 평균으로 융합하여 지속적으로 업데이트한다. 이 방법은 추가적인 계산 비용 없이 장기적인 맥락과 최근의 동작을 포착하여 초기 프레임 복사를 방지하고 긴 시간 일관성을 유지하는 데 기여한다. 둘째, Re-DMD(Rewarded Distribution Matching Distillation)는 교사 모델로부터 동작 역학을 더 효과적으로 증류하기 위한 새로운 방법론이다. 기존의 분포 일치 방법은 모든 훈련 샘플을 동등하게 취급하여 동적 콘텐츠를 우선시하는 모델의 능력을 제한하는 반면, Re-DMD는 비전-언어 모델에 의해 평가된 높은 동적 샘플을 우선시하여 모델의 출력 분포를 높은 보상 영역으로 편향시킨다. 이로 인해 데이터 충실도를 유지하면서도 동작 품질을 크게 향상시킬 수 있다.
논문에서는 정량적 및 정성적 실험을 통해 Reward Forcing이 표준 벤치마크에서 최첨단 성능을 달성하고, 단일 H100 GPU에서 23.1 FPS로 고품질 스트리밍 비디오 생성을 가능하게 함을 입증하였다. 이러한 혁신적인 접근은 기존 방법의 한계를 극복하고, 비디오 생성의 동작 품질을 향상시키는 데 중요한 기여를 하고 있다.
논문 초록(Abstract)
효율적인 스트리밍 비디오 생성은 상호작용적이고 동적인 세계를 시뮬레이션하는 데 중요합니다. 기존 방법은 초기 프레임을 싱크 토큰으로 사용하여 어텐션 성능을 유지하고 오류 축적을 줄이는 슬라이딩 윈도우 어텐션을 가진 몇 단계 비디오 디퓨전 모델을 증류합니다. 그러나 비디오 프레임은 이러한 정적 토큰에 지나치게 의존하게 되어 초기 프레임이 복사되고 움직임의 역동성이 감소하는 결과를 초래합니다. 이를 해결하기 위해 우리는 두 가지 주요 설계를 갖춘 새로운 프레임워크인 보상 강제(Reward Forcing)를 소개합니다. 첫째, 우리는 초기 프레임에서 초기화된 고정 크기 토큰을 유지하고 슬라이딩 윈도우를 나갈 때 퇴출된 토큰을 지수 이동 평균을 통해 융합하여 지속적으로 업데이트하는 EMA-Sink를 제안합니다. 추가적인 계산 비용 없이 EMA-Sink 토큰은 장기적인 맥락과 최근의 역동성을 모두 포착하여 초기 프레임 복사를 방지하면서 장기 일관성을 유지합니다. 둘째, 교사 모델로부터 움직임 역동성을 더 잘 증류하기 위해 우리는 새로운 보상 분포 일치 증류(Rewarded Distribution Matching Distillation, Re-DMD)를 제안합니다. 일반적인 분포 일치는 모든 훈련 샘플을 동일하게 취급하여 모델이 동적 콘텐츠에 우선순위를 두는 능력을 제한합니다. 대신, Re-DMD는 비전-언어 모델에 의해 평가된 더 큰 역동성을 가진 샘플에 우선순위를 두어 모델의 출력 분포를 높은 보상 영역으로 편향시킵니다. Re-DMD는 데이터 충실도를 유지하면서 움직임 품질을 크게 향상시킵니다. 우리는 정량적 및 정성적 실험을 포함하여 보상 강제가 표준 벤치마크에서 최첨단 성능을 달성하고 단일 H100 GPU에서 23.1 FPS로 고품질 스트리밍 비디오 생성을 가능하게 함을 보여줍니다.
Efficient streaming video generation is critical for simulating interactive and dynamic worlds. Existing methods distill few-step video diffusion models with sliding window attention, using initial frames as sink tokens to maintain attention performance and reduce error accumulation. However, video frames become overly dependent on these static tokens, resulting in copied initial frames and diminished motion dynamics. To address this, we introduce Reward Forcing, a novel framework with two key designs. First, we propose EMA-Sink, which maintains fixed-size tokens initialized from initial frames and continuously updated by fusing evicted tokens via exponential moving average as they exit the sliding window. Without additional computation cost, EMA-Sink tokens capture both long-term context and recent dynamics, preventing initial frame copying while maintaining long-horizon consistency. Second, to better distill motion dynamics from teacher models, we propose a novel Rewarded Distribution Matching Distillation (Re-DMD). Vanilla distribution matching treats every training sample equally, limiting the model's ability to prioritize dynamic content. Instead, Re-DMD biases the model's output distribution toward high-reward regions by prioritizing samples with greater dynamics rated by a vision-language model. Re-DMD significantly enhances motion quality while preserving data fidelity. We include both quantitative and qualitative experiments to show that Reward Forcing achieves state-of-the-art performance on standard benchmarks while enabling high-quality streaming video generation at 23.1 FPS on a single H100 GPU.
논문 링크
더 읽어보기
툴오케스트라: 효율적인 모델 및 도구 오케스트레이션을 통한 지능 향상 / ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration


논문 소개
ToolOrchestra는 작은 오케스트레이터가 다양한 모델과 도구를 효율적으로 관리하여 지능의 상한을 높이고 복잡한 문제를 해결하는 방법론이다. 대규모 언어 모델(LLM)은 강력한 일반화 능력을 지니고 있지만, Humanity's Last Exam (HLE)와 같은 심층적이고 복잡한 문제를 해결하는 데에는 여전히 한계가 있다. 본 연구는 이러한 한계를 극복하기 위해 작은 오케스트레이터를 훈련하여 도구 사용의 효율성을 개선하고 지능을 높이는 것을 목표로 한다.
ToolOrchestra는 강화학습(RL) 기법을 활용하여 결과, 효율성, 사용자 선호를 고려한 보상 구조를 설계한다. 이를 통해 개발된 Orchestrator는 80억 개의 파라미터를 가진 모델로, 이전의 도구 사용 에이전트보다 더 높은 정확도를 낮은 비용으로 달성하며, 주어진 쿼리에 대해 사용자 선호에 맞춰 도구를 조정한다. HLE에서 Orchestrator는 37.1%의 점수를 기록하여 GPT-5의 35.1%를 초과하며, 2.5배 더 효율적인 성능을 보여준다.
또한, Orchestrator는 tau2-Bench와 FRAMES 데이터셋에서도 GPT-5를 큰 차이로 초과하며, 약 30%의 비용만을 사용하여 성능을 발휘한다. 이러한 결과는 다양한 도구를 경량 오케스트레이션 모델과 결합하는 것이 기존 방법보다 더 효율적이고 효과적임을 입증한다. Orchestrator는 여러 메트릭에서 성능과 비용 간의 최상의 균형을 이루며, 보지 못한 도구에 대해서도 강력하게 일반화되는 특성을 보인다.
ToolOrchestra는 실용적이고 확장 가능한 도구 증강 추론 시스템의 개발에 기여할 수 있는 가능성을 제시하며, AI/ML 분야에서 도구 사용의 효율성을 높이는 새로운 접근 방식을 제공한다. 이러한 연구 결과는 향후 연구에 중요한 기초 자료로 활용될 수 있을 것이다.
논문 초록(Abstract)
대규모 언어 모델은 강력한 일반화 능력을 가지고 있지만, 인류의 마지막 시험(HLE)과 같은 깊고 복잡한 문제를 해결하는 것은 개념적으로 도전적이며 계산 비용이 많이 듭니다. 우리는 다른 모델과 다양한 도구를 관리하는 소형 오케스트레이터가 지능의 상한을 끌어올리고 어려운 에이전트 작업을 해결하는 데 효율성을 향상시킬 수 있음을 보여줍니다. 우리는 지능형 도구를 조정하는 소형 오케스트레이터를 훈련하기 위한 방법인 ToolOrchestra를 소개합니다. ToolOrchestra는 결과, 효율성 및 사용자 선호를 고려한 보상을 사용하여 강화 학습을 명시적으로 적용합니다. ToolOrchestra를 사용하여 우리는 80억 개의 매개변수를 가진 Orchestrator 모델을 생성하였으며, 이는 이전의 도구 사용 에이전트보다 낮은 비용으로 더 높은 정확도를 달성하고 주어진 쿼리에 대해 어떤 도구를 사용할지에 대한 사용자 선호에 맞추어 조정됩니다. HLE에서 Orchestrator는 37.1%의 점수를 달성하여 GPT-5(35.1%)를 초과하며, 2.5배 더 효율적입니다. tau2-Bench와 FRAMES에서 Orchestrator는 비용의 약 30%만 사용하면서도 GPT-5를 넉넉히 초과합니다. 광범위한 분석 결과, Orchestrator는 여러 지표에서 성능과 비용 간의 최상의 균형을 달성하며, 보지 못한 도구에 대해서도 강력하게 일반화됩니다. 이러한 결과는 다양한 도구를 경량 오케스트레이션 모델과 결합하는 것이 기존 방법보다 더 효율적이고 효과적임을 보여주며, 실용적이고 확장 가능한 도구 증강 추론 시스템을 위한 길을 열어줍니다.
Large language models are powerful generalists, yet solving deep and complex problems such as those of the Humanity's Last Exam (HLE) remains both conceptually challenging and computationally expensive. We show that small orchestrators managing other models and a variety of tools can both push the upper bound of intelligence and improve efficiency in solving difficult agentic tasks. We introduce ToolOrchestra, a method for training small orchestrators that coordinate intelligent tools. ToolOrchestra explicitly uses reinforcement learning with outcome-, efficiency-, and user-preference-aware rewards. Using ToolOrchestra, we produce Orchestrator, an 8B model that achieves higher accuracy at lower cost than previous tool-use agents while aligning with user preferences on which tools are to be used for a given query. On HLE, Orchestrator achieves a score of 37.1%, outperforming GPT-5 (35.1%) while being 2.5x more efficient. On tau2-Bench and FRAMES, Orchestrator surpasses GPT-5 by a wide margin while using only about 30% of the cost. Extensive analysis shows that Orchestrator achieves the best trade-off between performance and cost under multiple metrics, and generalizes robustly to unseen tools. These results demonstrate that composing diverse tools with a lightweight orchestration model is both more efficient and more effective than existing methods, paving the way for practical and scalable tool-augmented reasoning systems.
논문 링크
더 읽어보기
LLM의 자율 탐색 유도 가능성: 그래디언트 기반 강화학습을 통한 LLM 추론 개선 / Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning

논문 소개
대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 강화학습(Reinforcement Learning, RL) 접근법은 최근 연구에서 중요한 주제로 부각되고 있다. 그러나 기존의 탐색 메커니즘은 LLM이 실제로 학습하는 방식과 일치하지 않는 한계를 지니고 있다. 엔트로피 보너스와 외부 의미 비교기는 표면적인 다양성을 유도하지만, 최적화 과정에서의 업데이트 방향에 대한 보장을 제공하지 않는다. 이러한 문제를 해결하기 위해 제안된 G^2RL(Gradient-guided Reinforcement Learning) 프레임워크는 모델의 고유한 1차 업데이트 기하학을 활용하여 탐색을 주도한다.
G^2RL 은 각 응답에 대해 모델의 최종 레이어에서 파생된 시퀀스 수준의 특징을 구성하고, 이를 통해 정책이 어떻게 재형성될지를 측정한다. 이 과정에서 새로운 그래디언트 방향을 도입하는 경로에는 제한된 보상을 부여하고, 중복되거나 비정상적인 업데이트는 강조되지 않도록 설계되어 있다. 이러한 접근은 탐색 신호가 모델의 내부 구조와 자연스럽게 정렬되도록 하여, PPO(Proximal Policy Optimization) 스타일의 안정성과 KL(Kullback-Leibler) 제어를 유지한다.
G^2RL 은 Qwen3 모델(1.7B 및 4B)에서 수학 및 일반 추론 벤치마크(MATH500, AMC 등)에서 성능을 일관되게 향상시키며, 특히 단일 샘플 정확도와 다중 샘플 커버리지에서 개선된 결과를 보여준다. 실험 결과, G^2RL 은 탐색을 더 직교적이고 종종 반대 방향으로 확장하면서도 의미적 일관성을 유지하는 것으로 나타났다. 이는 G^2RL 이 정책의 고유한 업데이트 공간을 기반으로 탐색을 안내함으로써, 더 효과적이고 신뢰할 수 있는 학습을 가능하게 한다는 것을 시사한다.
이 연구는 LLM의 탐색 메커니즘을 개선하고, 모델의 내부 기하학을 활용한 새로운 접근법을 제시함으로써, 강화학습 분야에 중요한 기여를 하고 있다. G^2RL 은 기존의 외부 신호에 의존하지 않고, 모델 자체의 구조를 활용하여 탐색의 효율성을 극대화하는 혁신적인 방법론으로 자리 잡을 것으로 기대된다.
논문 초록(Abstract)
강화학습은 대규모 언어 모델의 추론 능력을 강화하는 데 필수적이지만, 현재의 탐색 메커니즘은 이러한 모델이 실제로 학습하는 방식과 근본적으로 일치하지 않습니다. 엔트로피 보너스와 외부 의미 비교기는 표면적인 변화를 유도하지만, 샘플링된 경로가 최적화를 형성하는 업데이트 방향에서 다르다는 보장을 제공하지 않습니다. 우리는 G^2RL 을 제안합니다. G^2RL 은 탐색이 외부 휴리스틱이 아닌 모델 자체의 1차 업데이트 기하학에 의해 주도되는 그래디언트 유도 강화학습 프레임워크입니다. 각 응답에 대해 G^2RL 은 표준 순방향 패스에서 거의 비용 없이 얻을 수 있는 모델 최종 레이어의 민감도를 기반으로 시퀀스 수준의 특징을 구성하고, 샘플링된 그룹 내에서 이러한 특징을 비교하여 각 경로가 정책을 어떻게 재형성할지를 측정합니다. 새로운 그래디언트 방향을 도입하는 경로는 제한된 곱셈 보상을 받는 반면, 중복되거나 비다양한 업데이트는 강조되지 않아, PPO 스타일의 안정성과 KL 제어와 자연스럽게 일치하는 자기 참조 탐색 신호를 생성합니다. Qwen3 기본 1.7B 및 4B 모델에서 수학 및 일반 추론 벤치마크(MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) 전반에 걸쳐 G^2RL 은 엔트로피 기반 GRPO 및 외부 임베딩 방법에 비해 pass@1, maj@16, pass@k를 일관되게 개선합니다. 유도된 기하학을 분석한 결과, G2RL은 의미적 일관성을 유지하면서도 상당히 더 직교적이고 종종 반대 방향의 그래디언트 방향으로 탐색을 확장함을 발견하였으며, 이는 정책의 자체 업데이트 공간이 대규모 언어 모델 강화학습에서 탐색을 안내하는 데 훨씬 더 충실하고 효과적인 기반을 제공함을 보여줍니다.
Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G^2RL , a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G^2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G^2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G^2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.
논문 링크
사전학습된 대규모 언어 모델의 위치 임베딩을 제거하여 맥락 확장하기 / Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
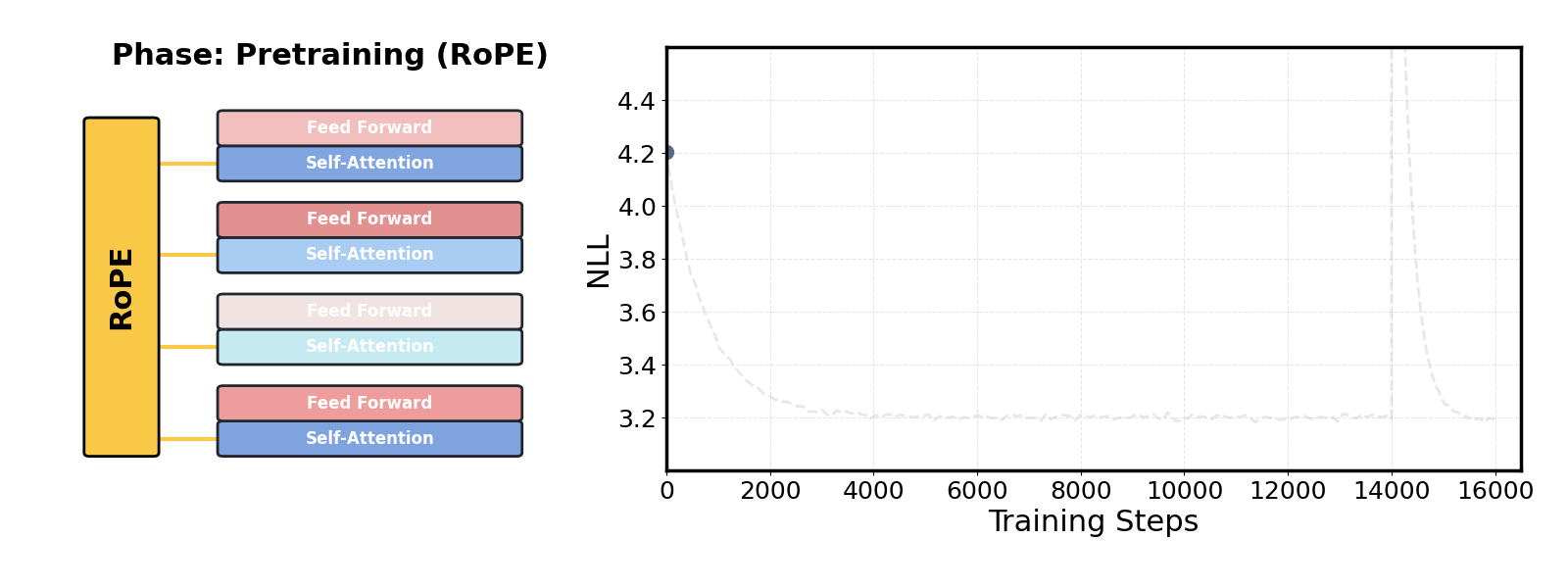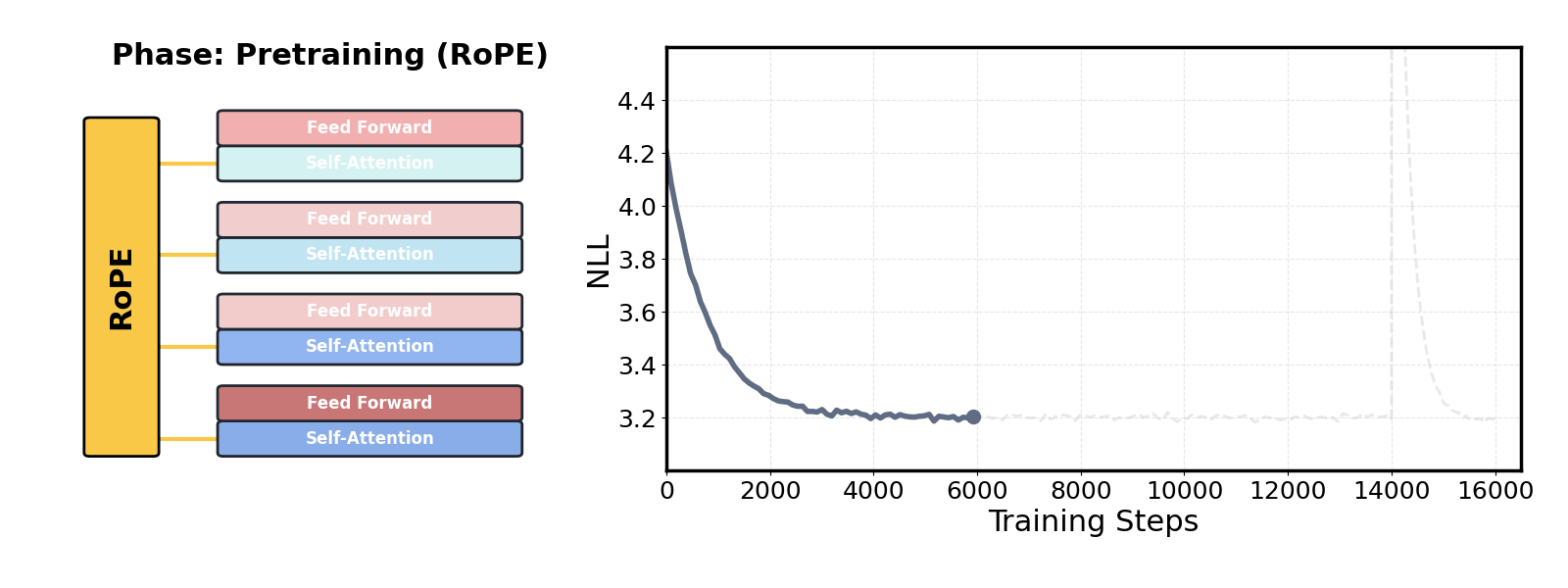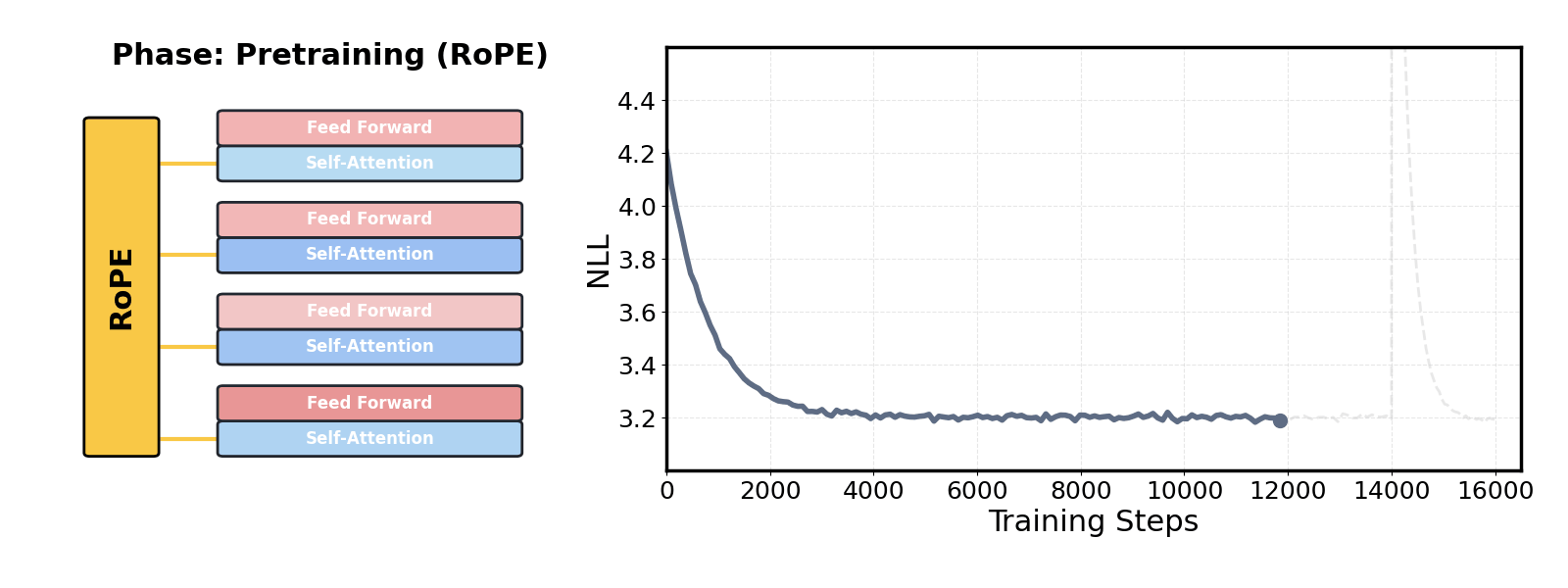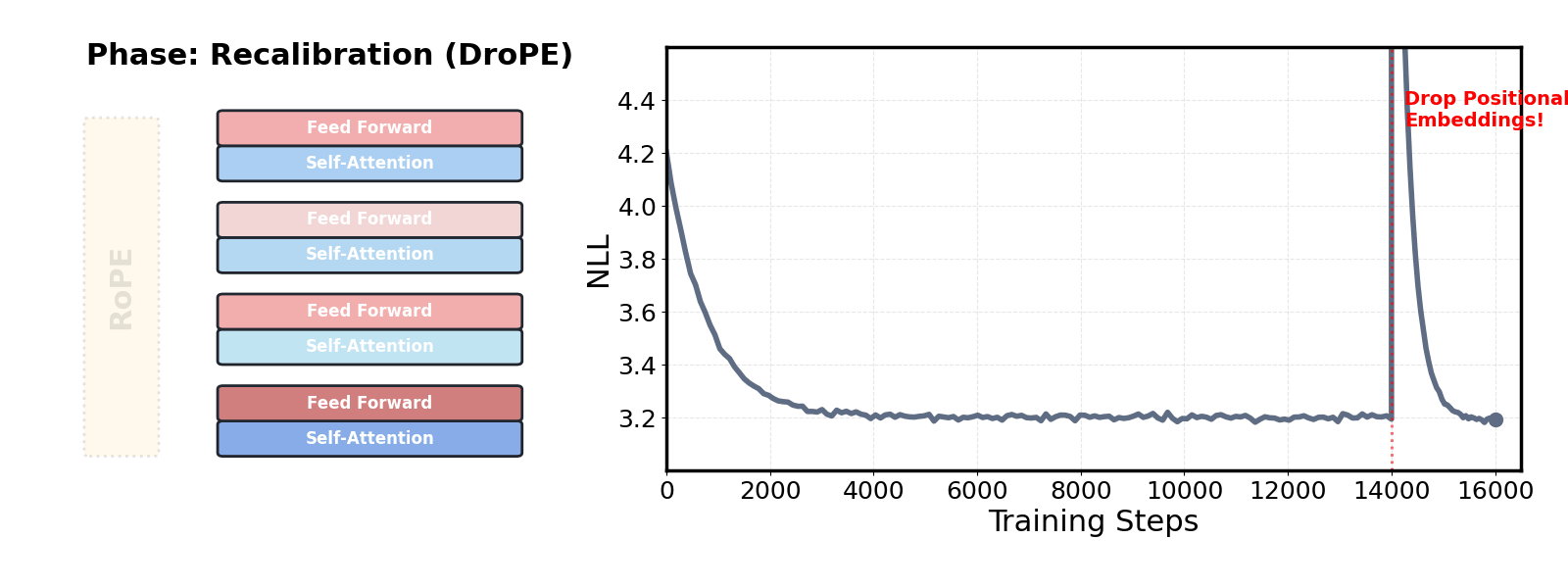
논문 소개
사전학습된 대규모 언어 모델(LLM)의 맥락 확장은 최근 자연어 처리 분야에서 중요한 연구 주제로 부각되고 있습니다. 기존의 접근 방식은 모델의 사전학습 시퀀스 길이를 초과하는 경우 비싼 파인튜닝을 요구하여, 긴 문맥을 처리하는 데 있어 실질적인 한계를 지니고 있었습니다. 이러한 문제를 해결하기 위해 제안된 DroPE(Dropping Positional Embeddings) 방법론은 위치 임베딩(PEs)을 제거함으로써 모델의 맥락 확장을 가능하게 합니다.
DroPE는 세 가지 주요 관찰에 기반하여 개발되었습니다. 첫째, 위치 임베딩은 사전학습 과정에서 중요한 역할을 하며, 모델의 수렴을 촉진하는 유도 편향을 제공합니다. 둘째, 이러한 위치 정보에 대한 과도한 의존은 테스트 시점에서 보지 못한 길이의 시퀀스에 대한 일반화를 방해합니다. 셋째, 위치 임베딩은 효과적인 언어 모델링에 필수적이지 않으며, 사전학습 후 짧은 재조정 단계를 통해 안전하게 제거할 수 있습니다.
이 연구는 DroPE를 통해 긴 맥락 파인튜닝 없이도 제로샷(zero-shot)으로 맥락을 확장할 수 있음을 입증하였습니다. 실험 결과, DroPE는 다양한 모델과 데이터셋에서 일관되게 우수한 성능을 보여주며, 기존의 회전 위치 임베딩(RoPE) 스케일링 방법을 능가하는 성과를 달성하였습니다. 이러한 결과는 DroPE가 언어 모델의 일반화 능력을 향상시키고, 사전학습된 모델의 원래 능력을 손상시키지 않으면서도 새로운 시퀀스 길이에 적응할 수 있는 가능성을 제시합니다.
DroPE는 LLM의 맥락 확장 문제를 해결하는 데 있어 중요한 이정표가 될 수 있으며, 향후 연구에서 이 방법을 기반으로 한 다양한 응용 가능성을 탐구할 수 있는 기회를 제공합니다. 이 논문은 사전학습된 LLM의 활용성을 높이는 혁신적인 접근 방식을 제시하며, 자연어 처리 분야의 발전에 기여할 것으로 기대됩니다.
논문 초록(Abstract)
지금까지, 사전학습 시퀀스 길이를 초과하는 비싼 파인튜닝은 언어 모델(LM)의 맥락을 효과적으로 확장하기 위한 필수 요건이었습니다. 본 연구에서는 훈련 후 언어 모델의 위치 임베딩을 제거하는 방법(DroPE)을 통해 이 주요 병목 현상을 해결합니다. 우리의 간단한 방법은 세 가지 주요 이론적 및 경험적 관찰에 의해 동기 부여됩니다. 첫째, 위치 임베딩(PE)은 사전학습 동안 중요한 귀납적 편향을 제공하여 수렴을 크게 촉진하는 중요한 역할을 합니다. 둘째, 이 명시적 위치 정보에 대한 과도한 의존은 인기 있는 PE 스케일링 방법을 사용할 때조차도 보지 못한 길이의 시퀀스에 대한 테스트 시간 일반화를 방해하는 원인이 됩니다. 셋째, 위치 임베딩은 효과적인 언어 모델링에 필수적인 요구 사항이 아니며, 짧은 재조정 단계를 거친 후 사전학습 후 안전하게 제거할 수 있습니다. 경험적으로, DroPE는 긴 맥락 파인튜닝 없이도 매끄러운 제로샷 맥락 확장을 제공하며, 원래 훈련 맥락에서의 능력을 손상시키지 않고 사전학습된 LM을 신속하게 적응시킵니다. 우리의 발견은 다양한 모델과 데이터셋 크기에서 일관되게 나타나며, 이전의 전문화된 아키텍처와 확립된 회전 위치 임베딩 스케일링 방법을 훨씬 능가합니다.
So far, expensive finetuning beyond the pretraining sequence length has been a requirement for effectively extending the context of language models (LM). In this work, we break this key bottleneck by Dropping the Positional Embeddings of LMs after training (DroPE). Our simple method is motivated by three key theoretical and empirical observations. First, positional embeddings (PEs) serve a crucial role during pretraining, providing an important inductive bias that significantly facilitates convergence. Second, over-reliance on this explicit positional information is also precisely what prevents test-time generalization to sequences of unseen length, even when using popular PE-scaling methods. Third, positional embeddings are not an inherent requirement of effective language modeling and can be safely removed after pretraining, following a short recalibration phase. Empirically, DroPE yields seamless zero-shot context extension without any long-context finetuning, quickly adapting pretrained LMs without compromising their capabilities in the original training context. Our findings hold across different models and dataset sizes, far outperforming previous specialized architectures and established rotary positional embedding scaling methods.
논문 링크
더 읽어보기
에이전트 드리프트: 다중 에이전트 대규모 언어 모델 시스템에서의 행동 저하 정량화 / Agent Drift: Quantifying Behavioral Degradation in Multi-Agent LLM Systems Over Extended Interactions

논문 소개
다중 에이전트 대규모 언어 모델(LLM) 시스템에서의 행동 저하 현상인 Agent Drift를 정량화하기 위한 연구가 진행되었다. 이 연구에서는 에이전트의 행동, 결정 품질 및 상호 에이전트 간 일관성이 장기 상호작용을 통해 어떻게 점진적으로 저하되는지를 분석하고, 이를 정량화하기 위한 새로운 지표인 **Agent Stability Index (ASI)**를 도입하였다. ASI는 응답 일관성, 도구 사용 패턴, 추론 경로 안정성 및 상호 에이전트 동의율 등 12개 차원에서 드리프트를 평가하는 복합 지표로, 이를 통해 시스템의 행동 저하를 체계적으로 모니터링할 수 있다.
연구에서는 342개의 드리프트 사례를 분석하여 드리프트 패턴을 의미적 드리프트, 조정 드리프트, 행동 드리프트로 세분화하였다. 이러한 패턴은 에이전트의 출력이 원래 작업 의도에서 이탈하거나, 다중 에이전트 간의 합의 메커니즘이 저하되는 경우, 또는 새로운 전략이나 행동 패턴이 개발되는 경우로 나뉜다. 드리프트가 방치될 경우, 작업 완료 정확도가 크게 감소하고 인간의 개입 요구가 증가할 수 있음을 시뮬레이션 기반 분석을 통해 확인하였다.
이 연구는 드리프트를 완화하기 위한 세 가지 전략을 제안하였다. 첫째, **에피소드 메모리 통합(EMC)**은 에이전트의 상호작용 기록을 주기적으로 압축하여 학습을 증류하고 중복된 맥락을 제거한다. 둘째, **드리프트 인식 라우팅(DAR)**은 에이전트 안정성 점수를 고려하여 위임 결정을 수정하고 드리프트가 발생한 에이전트에 대해 초기화 절차를 수행한다. 셋째, **적응형 행동 고정(ABA)**은 초기 기간의 예시를 기반으로 한 프롬프트 보강을 통해 드리프트 메트릭에 따라 동적으로 가중치를 조정한다.
이러한 전략들은 통제된 시뮬레이션 실험을 통해 평가되었으며, 모든 전략이 통계적으로 유의미한 성과를 보였다. 특히, 적응형 행동 고정 전략은 70.4%의 드리프트 감소를 기록하여 가장 효과적인 방법으로 나타났다. 이 연구는 다중 에이전트 LLM 시스템의 행동 저하를 정량화하고 이를 완화하기 위한 기초 방법론을 확립하여, 기업 배치 신뢰성과 AI 안전 연구에 중요한 기여를 하고 있다.
논문 초록(Abstract)
다중 에이전트 대규모 언어 모델(LLM) 시스템은 복잡한 작업 분해 및 협업 문제 해결을 위한 강력한 아키텍처로 등장하였습니다. 그러나 이들의 장기적인 행동 안정성은 아직 충분히 검토되지 않았습니다. 본 연구에서는 에이전트 드리프트(agent drift)라는 개념을 소개하며, 이는 장기 상호작용 시퀀스에서 에이전트의 행동, 의사결정 품질 및 에이전트 간 일관성이 점진적으로 저하되는 현상으로 정의됩니다. 우리는 드리프트 현상을 이해하기 위한 포괄적인 이론적 프레임워크를 제시하며, 세 가지 뚜렷한 형태인 의미 드리프트(원래 의도에서의 점진적 이탈), 조정 드리프트(다중 에이전트 합의 메커니즘의 붕괴), 행동 드리프트(원치 않는 전략의 출현)를 제안합니다. 또한, 우리는 응답 일관성, 도구 사용 패턴, 추론 경로 안정성, 에이전트 간 합의 비율 등 12개 차원에서 드리프트를 정량화하기 위한 새로운 복합 지표 프레임워크인 에이전트 안정성 지수(ASI)를 도입합니다. 시뮬레이션 기반 분석 및 이론적 모델링을 통해, 통제되지 않은 에이전트 드리프트가 작업 완료 정확도의 상당한 감소와 인간 개입 요구의 증가로 이어질 수 있음을 보여줍니다. 우리는 에피소드 메모리 통합, 드리프트 인식 라우팅 프로토콜, 적응형 행동 고정이라는 세 가지 완화 전략을 제안합니다. 이론적 분석에 따르면 이러한 접근 방식은 시스템 처리량을 유지하면서 드리프트 관련 오류를 상당히 줄일 수 있습니다. 본 연구는 생산 에이전틱 AI 시스템에서 에이전트 드리프트를 모니터링, 측정 및 완화하기 위한 기초적인 방법론을 확립하며, 이는 기업 배포 신뢰성과 AI 안전 연구에 직접적인 영향을 미칩니다.
Multi-agent Large Language Model (LLM) systems have emerged as powerful architectures for complex task decomposition and collaborative problem-solving. However, their long-term behavioral stability remains largely unexamined. This study introduces the concept of agent drift, defined as the progressive degradation of agent behavior, decision quality, and inter-agent coherence over extended interaction sequences. We present a comprehensive theoretical framework for understanding drift phenomena, proposing three distinct manifestations: semantic drift (progressive deviation from original intent), coordination drift (breakdown in multi-agent consensus mechanisms), and behavioral drift (emergence of unintended strategies). We introduce the Agent Stability Index (ASI), a novel composite metric framework for quantifying drift across twelve dimensions, including response consistency, tool usage patterns, reasoning pathway stability, and inter-agent agreement rates. Through simulation-based analysis and theoretical modeling, we demonstrate how unchecked agent drift can lead to substantial reductions in task completion accuracy and increased human intervention requirements. We propose three mitigation strategies: episodic memory consolidation, drift-aware routing protocols, and adaptive behavioral anchoring. Theoretical analysis suggests these approaches can significantly reduce drift-related errors while maintaining system throughput. This work establishes a foundational methodology for monitoring, measuring, and mitigating agent drift in production agentic AI systems, with direct implications for enterprise deployment reliability and AI safety research.
논문 링크
TTT-Discover: 추론 시점의 학습을 통한 발견 / Learning to Discover at Test Time

논문 소개
AI를 활용하여 과학적 문제에 대한 새로운 최첨단 솔루션을 발견하는 방법을 제안하는 본 연구는, 기존의 고정된 대규모 언어 모델(LLM)을 사용하는 접근 방식의 한계를 극복하고자 합니다. 연구의 핵심은 테스트 시간에 강화학습을 통해 LLM이 특정 문제에 대한 경험을 바탕으로 지속적으로 학습할 수 있도록 하는 것입니다. 이를 통해 평균적으로 여러 좋은 솔루션을 생성하는 것이 아니라, 특정 문제에 대해 하나의 뛰어난 솔루션을 목표로 합니다. 이러한 방법론은 테스트 시간 학습을 통한 발견(TTT-Discover)으로 명명되며, 연속 보상을 가진 문제에 중점을 두고 있습니다.
TTT-Discover는 이전에 발견된 상태들의 아카이브를 유지하고, 각 상태에 대한 보상을 기록하는 상태 아카이브와, PUCT(상태-행동 선택 규칙)를 기반으로 최적의 상태를 선택하는 상태 선택 규칙을 포함합니다. 또한, 부모 상태를 확장하고 자식 상태의 보상을 관찰하여 보상을 업데이트함으로써 각 상태의 보상을 지속적으로 개선할 수 있습니다. 이러한 구성 요소들은 TTT-Discover가 특정 문제에 대한 최적의 솔루션을 찾는 데 기여합니다.
본 연구는 수학, GPU 커널 엔지니어링, 알고리즘 설계, 생물학 등 다양한 분야에서 TTT-Discover의 성능을 평가하였으며, 각 문제에서 새로운 최첨단 결과를 달성했습니다. 특히, 에르되시의 최소 겹침 문제, GPU 모드 커널 경쟁, AtCoder 알고리즘 대회, 단일 세포 분석의 노이즈 제거 문제에서 뛰어난 성과를 보였습니다. 모든 결과는 전문가의 검토를 거쳤으며, 공개적으로 사용할 수 있는 코드로 재현 가능합니다.
TTT-Discover는 기존의 최상의 결과가 폐쇄형 프론티어 모델을 요구한 것과 달리, 공개 모델인 OpenAI gpt-oss-120b를 사용하여 달성되었습니다. 연구의 결과는 AI가 특정 문제에 대한 최적의 솔루션을 찾는 데 어떻게 기여할 수 있는지를 보여주며, 향후 연구에서는 다양한 문제에 대한 적용 가능성을 탐색하고 TTT-Discover의 성능을 더욱 향상시키기 위한 방법을 모색할 것입니다.
논문 초록(Abstract)
AI를 사용하여 과학 문제에 대한 새로운 최첨단 솔루션을 어떻게 발견할 수 있을까요? AlphaEvolve와 같은 테스트 시간 스케일링에 대한 이전 연구는 고정된 대규모 언어 모델(LLM)을 통해 검색을 수행합니다. 우리는 테스트 시간에 강화 학습을 수행하여 LLM이 테스트 문제에 특정한 경험으로 계속 학습할 수 있도록 합니다. 이러한 형태의 지속적 학습은 평균적으로 많은 좋은 솔루션을 생성하는 것이 아니라 하나의 훌륭한 솔루션을 생산하는 것을 목표로 하며, 다른 문제로 일반화하는 것이 아니라 이 특정 문제를 해결하는 것이기 때문에 매우 특별합니다. 따라서 우리의 학습 목표와 검색 서브루틴은 가장 유망한 솔루션을 우선시하도록 설계되었습니다. 우리는 이 방법을 테스트 시간 학습 발견(Test-Time Training to Discover, TTT-Discover)이라고 부릅니다. 이전 연구를 따라 우리는 연속 보상을 가진 문제에 집중합니다. 우리는 수학, GPU 커널 엔지니어링, 알고리즘 설계 및 생물학 등 시도한 모든 문제에 대한 결과를 보고합니다. TTT-Discover는 거의 모든 문제에서 새로운 최첨단을 설정합니다: (i) 에르되시의 최소 겹침 문제와 자기상관 부등식; (ii) GPUMode 커널 경쟁(이전 기술보다 최대 2배 빠름); (iii) 과거 AtCoder 알고리즘 대회; (iv) 단일 세포 분석에서의 노이즈 제거 문제. 우리의 솔루션은 전문가나 주최자에 의해 검토됩니다. 모든 결과는 공개 모델인 OpenAI gpt-oss-120b로 달성되었으며, 이전의 최상의 결과가 폐쇄형 최전선 모델을 요구한 것과 달리, 우리의 공개 코드로 재현할 수 있습니다. 우리의 테스트 시간 학습은 Thinking Machines의 API인 Tinker를 사용하여 수행되며, 문제당 비용은 몇 백 달러에 불과합니다.
How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM. We perform reinforcement learning at test time, so the LLM can continue to train, but now with experience specific to the test problem. This form of continual learning is quite special, because its goal is to produce one great solution rather than many good ones on average, and to solve this very problem rather than generalize to other problems. Therefore, our learning objective and search subroutine are designed to prioritize the most promising solutions. We call this method Test-Time Training to Discover (TTT-Discover). Following prior work, we focus on problems with continuous rewards. We report results for every problem we attempted, across mathematics, GPU kernel engineering, algorithm design, and biology. TTT-Discover sets the new state of the art in almost all of them: (i) Erdős' minimum overlap problem and an autocorrelation inequality; (ii) a GPUMode kernel competition (up to 2\times faster than prior art); (iii) past AtCoder algorithm competitions; and (iv) denoising problem in single-cell analysis. Our solutions are reviewed by experts or the organizers. All our results are achieved with an open model, OpenAI gpt-oss-120b, and can be reproduced with our publicly available code, in contrast to previous best results that required closed frontier models. Our test-time training runs are performed using Tinker, an API by Thinking Machines, with a cost of only a few hundred dollars per problem.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()