
TTT-Discover 연구 개요
발견(Discovery)의 본질과 기존 LLM의 한계
우리가 처음으로 매우 어려운 프로그래밍 과제를 마주했을 때를 떠올려 봅시다. 단순히 교과서에 나온 예제를 따라 하는 것만으로는 해결되지 않는 문제 앞에서, 우리는 여러 번 시도하고 실패하며 그 과정에서 얻은 작은 힌트들을 통해 점차 해결책에 다가갑니다. 이처럼 인간은 새로운 문제를 해결할 때 기존 지식에만 의존하지 않고, 그 문제와 씨름하는 과정 자체에서 배우고 성장합니다. 즉, 일련의 시행착오 과정을 거칩니다. 중요한 점은 이 과정에서 우리의 뇌가 해당 문제에 대한 이해도를 실시간으로 높여간다는 것입니다. '10분 전의 나'는 풀지 못했지만, 문제와 씨름하며 학습한 '현재의 나'는 해결책을 찾아냅니다. 이것이 바로 인간이 어려운 문제를 해결하는 방식이며, TTT-Discover 연구가 모방하고자 하는 핵심 프로세스입니다.
하지만 현재의 대부분의 인공지능 모델들은 이와 다르게 작동합니다. 학습 단계에서 방대한 데이터를 학습한 뒤, 추론 단계에서는 모델의 가중치(weights)를 고정(Frozen Weights)한 채 정해진 추론 과정만을 수행합니다. 이는 마치 학생이 시험을 볼 때 새로운 것을 배우지 못하고 오로지 기억에만 의존해야 하는 것과 같습니다. 물론, 사고의 연쇄(CoT, Chain-of-Thought) 기법이나 N개 후보 중 최고의 답변을 고르는(Best-of-N) 기법 등이 추론 과정을 길게 늘리거나 여러 번의 시도하게 해주지만, 모델 자체가 문제에 적응하며 더 똑똑해지는 것은 아닙니다.
TTT-Discover 연구 배경
TTT-Discover 논문의 저자들은 이러한 한계를 극복하기 위해 추론 시간 학습(Test-Time Training, TTT) 이라는 개념을 과학적 발견 문제(Scientific Discovery Task)에 적용했습니다. 과학적 발견 문제는 정의상 기존의 훈련 데이터 분포를 벗어나는(Out-of-Distribution) 새로운 지식을 찾아내야 하므로, 일반적인 일반화(Generalization)보다 훨씬 더 어렵습니다. 기존 연구들, 예를 들어 AlphaEvolve와 같은 진화적 탐색 방법은 고정된 대규모 언어 모델(LLM)을 프롬프팅하여 해답을 탐색하는 데 집중했습니다. 하지만 이러한 방법들은 대규모 언어 모델 자체가 문제의 본질을 학습하여 더 나은 제안을 하도록 개선되지는 않는다는 근본적인 한계가 있습니다.
TTT-Discover는 이 지점에서 발상의 전환을 시도합니다. 모델이 문제 하나를 푸는 동안에도 강화 학습(Reinforcement Learning, RL)을 수행하며 스스로의 모델 가중치를 업데이트하는 것입니다. 즉, 모델은 단순히 정답을 맞히려고 시도하는 것을 넘어, 그 문제에 특화된 데이터 분포를 스스로 생성하고 이를 통해 학습함으로써 점진적으로 더 똑똑한 해결책을 제안하게 됩니다.
여기서 중요한 점은 이 학습의 목표가 일반적인 강화학습(RL, Reinforcement Learning)과는 다르며, 희소한 보상(Sparse Reward)과 최댓값 탐색을 강조하고 있다는 점입니다. 일반적인 강화학습은 모든 상태에서 평균적인 기대 보상을 최대화하는 정책(Policy)을 찾는 것을 목표로 하지만, 과학적 발견(Scientific Discovery) 분야에서는 100번의 시도 중 99번이 실패하더라도 단 1번의 대성공(Outlier)이 있다면 그것이 정답이기 때문입니다.

따라서, TTT-Discover는 평균이 아닌 최고의 성능을 보이는 해결책(Outlier)을 목표로 하도록 설계된 특수한 목적 함수와 탐색 전략을 사용합니다. 위 그림은 이러한 순환 과정을 잘 보여줍니다. 에이전트가 탐색을 통해 데이터를 생성하고, 그 데이터 중 유망한 것을 선별하여 모델을 학습시키고, 개선된 모델이 다시 더 나은 탐색을 수행하는 선순환 구조가 바로 TTT-Discover의 핵심입니다.
방법론: TTT-Discover 알고리즘 심층 분석
TTT-Discover는 앞서 언급한 것과 같이 과학적 발견이라는 목표를 달성하기 위해, 기존의 지도 학습이나 일반적인 강화 학습과는 다른 독창적인 접근 방식을 취합니다. 이를 위해 물리적, 수학적 환경을 강화 학습 문제로 정의하고, 희소한 고득점 해답(Outlier)을 찾아내기 위한 탐색 기법, 그리고 이를 모델에 반영하기 위한 엔트로피 기반의 학습 목적 함수 등을 어떻게 설계했는지 살펴보겠습니다:
문제 정의: 과학적 발견을 위한 강화 학습 환경 (Environment)
과학적 발견 문제를 AI가 해결할 수 있는 형태로 만들기 위해, 저자들은 이러한 과학적 발견 문제들을 마르코프 결정 과정(Markov Decision Process, MDP) 으로 정의했습니다. 각 문제들은 MDP를 통해 ( 상태 S, 행동 A, 전이 T, 보상 R ) 로 정의되며, 여기에 포함되는 요소들은 다음과 같습니다:
먼저 상태 S (State, s \in S) 는 현재 시점까지 생성된 모든 텍스트 시퀀스(토큰들의 나열) 입니다. 예를 들어, 수학 증명 문제라면 문제의 정의부터 현재까지 전개된 수식 증명 과정 전체가 상태 S 가 됩니다. 코딩 문제라면 현재까지 작성된 파이썬 코드 전체를 상태 S 로 정의합니다.
행동 A (Action, a \in A) 은 대형 언어 모델(LLM)이 생성하는 다음 토큰(Next Token) 입니다. 즉, 행동 공간(Action Space)은 모델의 어휘 집합(Vocabulary)과 같습니다. 따라서 a_t 는 특정 시점 t 에서 생성된 단어 혹은 기호입니다.
다음으로 전이 T (Transition, T) 를 살펴보겠습니다. 상태 전이는 결정론적(Deterministic) 입니다. 현재 상태 s_t 에서 행동 a_t 를 취하면, 다음 상태 s_{t+1} 은 단순히 s_t 뒤에 a_t 가 붙은 형태(s_t \circ a_t)가 됩니다.
마지막으로 보상 R (Reward, R(s)) 은 TTT-Discover 시스템의 가장 핵심적인 부분입니다. TTT-Dicover를 적용하기 위해서는 무엇보다 검증 가능한(Verifiable) 보상 이 필수적입니다. 즉, 모델이 생성한 해답을 사람이 개입하지 않고도 코드 실행기나 증명 검증기를 통해 객관적이고 자동화된 방식으로 평가할 수 있어야 합니다. 보상은 에피소드가 끝난 후(Terminal State)에 주어지며, 단순한 성공/실패가 아닌 해답의 품질을 미세하게 구분할 수 있는 연속적인(Continuous) 값을 가질 때 학습 효율이 극대화됩니다.
해결책 x 의 품질을 평가할 때에는 제약 조건과 최적화 목표를 동시에 고려합니다. 제약 조건(Hard Constraints) 은 해결책이 반드시 만족해야 하는 최소한의 기준입니다. 예를 들어, 생성된 코드가 문법적으로 오류가 없어야 하거나, 수학적 증명이 논리적 비약 없이 유효해야 한다는 조건입니다. 논문에서는 해결책이 이러한 유효성 검사를 통과하지 못할 경우, 보상을 0으로 설정하여 가차 없이 탈락시킵니다.
또한, 제약 조건을 통과한 해결책들에 대해서는 각각이 얼마나 '좋은' 답인지를 평가해야 합니다. 이 때 등장하는 것이 바로 최적화 목표(Soft Optimization) 입니다. 최적화 목표는 서로 다른 해결책들을 평가하기 위한 지표로, 예를 들어 GPU 커널의 실행 속도(Latency)나 수학적 부등식의 타이트한 정도가 이에 해당합니다. 각 해결책은 이에 따라 연속적인 점수를 부여받으며, 모델은 이 점수를 높이는 방향으로 학습합니다.
이러한 MDP 환경에서 TTT-Discover의 에이전트(LLM)는 종료 토큰을 생성할 때까지 일련의 행동을 수행하여 하나의 궤적(Trajectory, \tau)을 만들어냅니다.
탐색 전략: PUCT 알고리즘과 상태 재사용 (State Reuse)
탐색(Search) 단계의 목표는 학습에 사용할 양질의 데이터를 확보하는 것입니다. 무작위로 생성하는 것은 비효율적이며, 그렇다고 기존 모델의 확률분포만 따르는 것은 새로운 발견을 저해합니다. 이를 해결하기 위해 연구진들은 PUCT (Predictor + Upper Confidence Bound applied to Trees) 알고리즘을 변형하여 사용합니다:
최대 가치 추정 (Max-Value Estimation over Mean-Value)
일반적인 AlphaZero의 PUCT는 각 상태-행동 쌍(State-Action Pair) (s, a) 의 가치(Value) Q(s, a) 를 해당 노드 하위에서 얻은 보상들의 평균(Mean)으로 추정합니다:
하지만 앞에서 언급한 것처럼 과학적 발견 문제(Scientific Discovery Task)에서는 평균적으로 좋은 해답보다, 단 하나의 최댓값(Outlier)이 중요합니다. 따라서 TTT-Discover는 Q 함수를 하위 트리에서 관측된 최대 보상(Maximum Reward) 으로 정의합니다:
이를 반영하여 특정 시점에서의 행동을 탐색할 때, TTT-Discover의 에이전트는 다음과 같은 변형된 PUCT 규칙에 따라 행동을 선택합니다:
여기서 N(s) 는 부모 노드의 방문 횟수, N(s, a) 는 해당 행동의 방문 횟수, P(s, a) 는 정책망(Policy Network)의 사전 확률, c_{puct} 는 탐색과 활용의 균형을 맞추는 상수입니다.
랭크 기반 사전 확률 (Rank-based Prior)
일반적인 LLM은 사전 학습된 데이터 분포에 편향되어 있어, Softmax 출력 P(s, a) 가 실제 정답 확률을 잘 반영하지 못하는 보정(Calibration) 문제가 있습니다. 이를 완화하기 위해 저자들은 랭크 기반 변환을 사용합니다. 모델이 예측한 토큰들의 순위(Rank)를 k 라고 할 때, 사전 확률을 다음과 같이 재정의합니다.
이는 모델이 확신하는 상위 토큰들에 집중하되, 확률 값 자체의 크기보다는 순위에 의존함으로써 탐색의 다양성을 보장합니다.
상태 재사용 (State Reuse via Reset)
이 알고리즘의 핵심은 바로 리셋(Reset) 메커니즘입니다. 하나의 에피소드가 끝난 후 다음 에피소드를 시작할 때, 맨 처음 상태(s_0) 로 돌아가는 대신, 이전 탐색 과정에서 발견했던 유망한 중간 상태로 돌아갑니다.
시스템은 탐색 중에 방문한 모든 상태들을 유지하며, 각 상태의 잠재적 가치(Value)를 평가합니다. 다음 롤아웃을 시작할 때, 높은 가치를 가진 상태 s' 를 선택하여 그 지점부터 탐색을 이어갑니다(Branching). 이를 통해 모델은 이미 검증된 좋은 코드 조각이나 증명의 중간 단계를 재사용(Reuse)하여, 더 깊고 복잡한 해답 공간을 탐색할 수 있게 됩니다.
TTT-Discover의 학습 전략: 엔트로피 목적 함수 (Entropic Objective)
앞선 탐색 과정을 통해 수집한 데이터(궤적 \tau 와 보상 R(\tau))를 바탕으로 모델 파라미터 \theta 를 업데이트해야 합니다. 여기서 TTT-Discover는 기존 강화 학습의 상식을 뒤집는 목적 함수를 도입합니다.
먼저 기존 강화 학습의 목적 함수를 살펴보겠습니다. 일반적인 강화 학습의 목표는 기대 보상(Expected Reward)의 최대화입니다:
이와 같은 방식은 모든 가능한 결과의 평균(mean)을 높이려 합니다. 하지만 과학적 발견에서는 99번의 실패(보상 0)가 있더라도 1번의 대성공(보상 100)이 있다면 그것이 정답입니다. 기존의 기대 보상 방식은 실패를 줄이기 위해 안전한 선택을 하도록 유도하므로, 위험을 감수해야 하는 과학적 발견 문제(Scientific Discovery Task)에는 적합하지 않습니다.
TTT-Discover 연구진들은 이를 개선하기 위해 엔트로피 목적 함수를 도입하였습니다. 즉, 보상의 최댓값, 혹은 상위권 값들에 집중하기 위해 지수 변형(Exponential Transformation) 을 적용한 것입니다.
여기서 \beta > 0 는 온도 파라미터(Temperature Hyperparameter)이며, 이 목적 함수의 그래디언트(Gradient)를 구해보면 그 의미가 더욱 명확해집니다:
여기서 가중치 w(\tau) 는 보상 R(\tau) 에 대한 소프트맥스(Softmax) 형태를 띱니다. \beta 가 클수록, 가장 높은 보상을 받은 궤적 \tau_{best} 의 가중치 w(\tau_{best}) 는 1에 가까워지고, 나머지 경우에는 0에 수렴합니다.
결과적으로 이 목적 함수를 적용한 모델은 자신이 생성한 해답 중 최고의 해답만을 모방(Imitate)하도록 학습합니다. 이는 일반적인 강화 학습의 목적 함수가 원하는 평균적인 모범생이 아닌, 탁월한 천재가 되도록 모델을 유도하는 것과 같습니다.
안정성 확보: 적응형 베타 스케줄링 (Adaptive \beta Scheduling)
이러한 엔트로피 목적 함수는 강력하지만, \beta 설정에 매우 민감하다는 단점이 있습니다. 에를 들어, \beta 가 너무 크면 탐색 초기에 우연히 발견한 적당히 좋은 해답(Local Optima)에 과도하게 집중하여, 더 좋은 해를 찾지 못하고 정책이 붕괴(Policy Collapse)할 수 있습니다. 또한, \beta 가 너무 작으면 일반적인 기대 보상 최대화와 다를 바가 없어, 발견 능력이 떨어집니다.
이를 해결하기 위해 TTT-Discover의 연구진들 고정된 \beta 대신, 매 업데이트 단계마다 최적의 \beta 를 자동으로 결정하는 제약 조건 기반 최적화(Constrained Optimization) 기법을 도입했습니다. 이 제약 조건 기반 최적화 기법의 핵심 아이디어는 모델의 정책 변화량(KL Divergence)을 일정 수준 \delta 이하로 묶어두는 것입니다. 수식으로 표현하면 다음과 같습니다:
이 최적화 문제는 라그랑주 승수법(Lagrange Multiplier)을 사용하여 풀 수 있습니다. 이 때, 라그랑주 승수의 역수 역할이 바로 적응형 \beta 가 됩니다. 실제 구현에서는 이중 경사 상승법(Dual Gradient Ascent)을 사용하여, KL-Divergence의 제약 조건을 만족하는 선에서 가능한 가장 큰 보상 가중치를 부여하도록 \beta 를 동적으로 조절합니다. (상세한 내용은 논문의 Appendix A.1을 참고해주세요)
따라서, 학습 초기에는 모델의 확신이 낮으므로 \beta 가 작게 설정되어 넓은 범위를 탐색합니다. 학습 후기에는 학습이 진행되며 좋은 해답들이 발견됨에 따라 \beta 가 점차 커지며, 최고 성능의 해답을 향해 수렴합니다.
이러한 적응형 베타 스케줄링(Adaptive \beta Scheduling) 덕분에 TTT-Discover는 별도의 복잡한 하이퍼파라미터 튜닝 없이도, 초기 탐색의 다양성과 후기 수렴의 정확성을 동시에 확보할 수 있게 되었습니다.
실험 결과 및 성과 분석 (Applications)
이론적으로 우아한 알고리즘이라 할지라도, 실제 복잡한 현실 문제에서 작동하지 않는다면 그 가치는 제한적일 것입니다. TTT-Discover는 단순히 정답이 정해진 문제를 푸는 것이 아니라, 아직 인류가 최적해를 찾지 못한 발견의 영역에서 그 효용성을 입증했습니다. 특히 주목할 점은, 이 모델이 각 도메인에 대한 별도의 사전 지식 주입(Domain-Specific Pre-training) 없이, 오직 문제 정의와 피드백 루프만으로 스스로 해당 분야의 전문가 수준으로 진화했다는 사실입니다.
수학 분야(Mathematics): 인간의 직관을 깨는 비대칭적 해답의 발견
수학 분야에서의 실험은 이 모델이 인간이 가진 인지적 편향(Bias)을 극복하고 순수한 탐색을 통해 더 깊은 진실에 도달할 수 있음을 가장 극적으로 보여주었습니다. 연구진은 1955년 폴 에르되시(Paul Erdős)가 제기한 에르되시 중복 문제(Erdős' Minimum Overlap Problem) 에 도전했습니다. 이 문제는 고정된 지지 집합(Support)을 가진 함수 f 가 주어졌을 때, 임의의 거리 d 만큼 떨어진 두 점 x, x+d 가 동시에 지지 집합에 속하는 비율의 최솟값을 최대화하는 문제입니다. 수십 년간 수학자들은 이 비율의 상한을 찾기 위해 노력해 왔습니다.
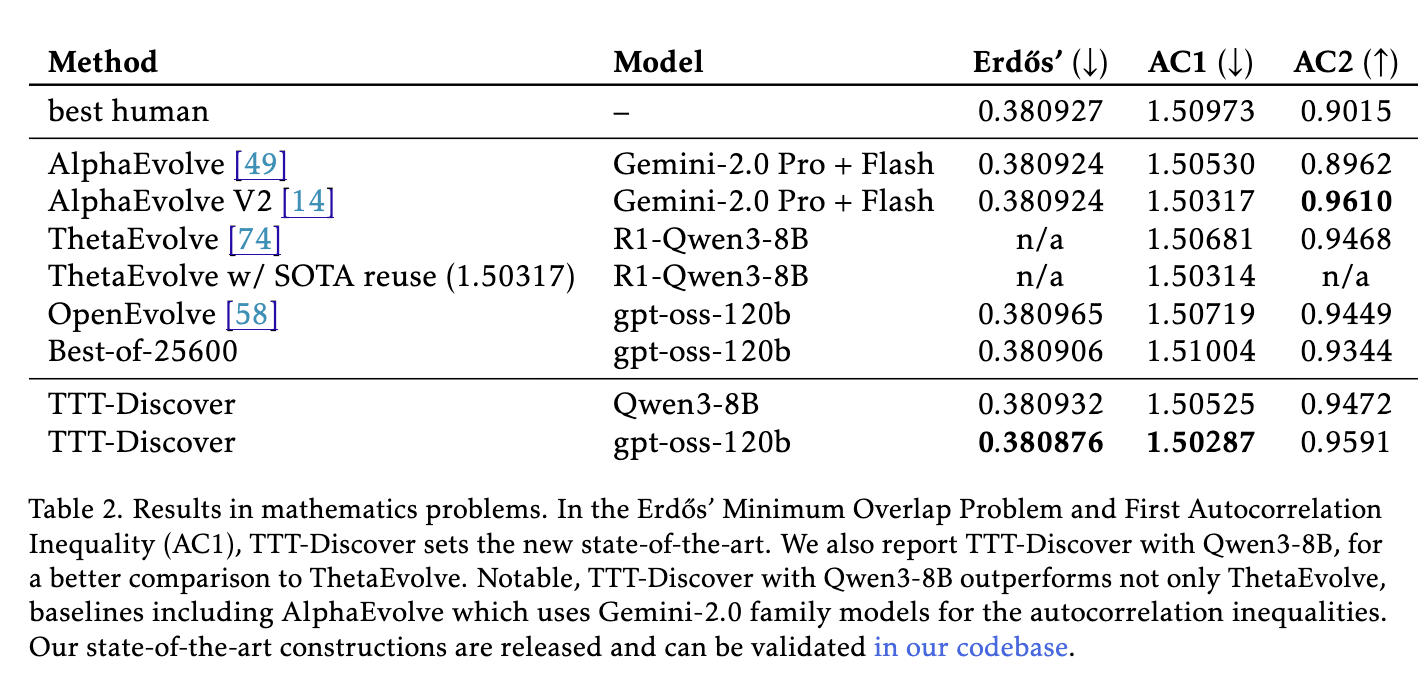
기존의 최고 기록(SOTA)은 AlphaEvolve 모델이 찾아낸 0.380924였습니다. 당시 AlphaEvolve가 제안한 함수는 매우 규칙적이고 깔끔한 대칭성(Symmetry)을 가지고 있었기에, 많은 연구자들은 정답이 대칭적인 구조 속에 있을 것이라고 암묵적으로 가정했습니다.
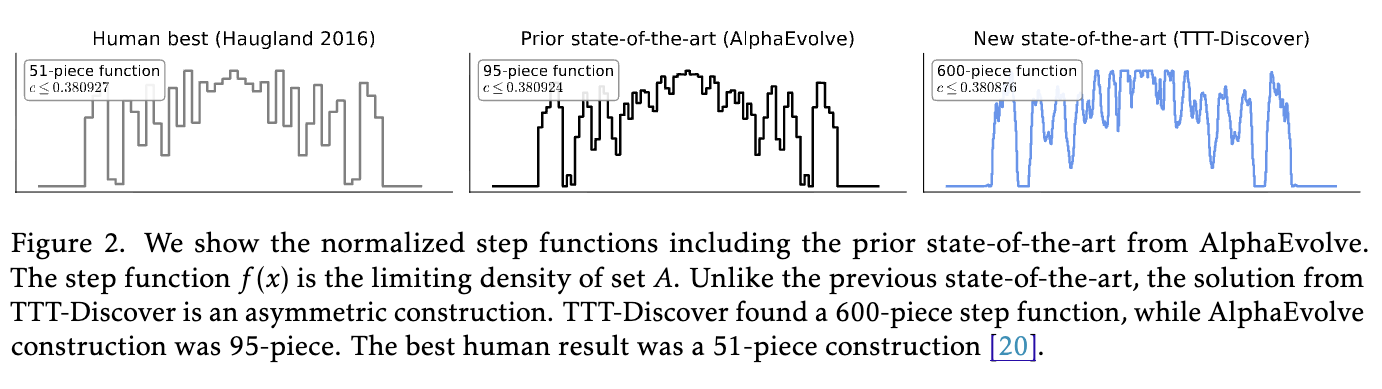
하지만 TTT-Discover는 이러한 고정 관념을 깨고, 0.380876이라는 기존보다 더 낮은(즉, 더 타이트하고 강력한) 상한값을 증명해 냈습니다. 더욱 놀라운 것은 모델이 찾아낸 함수의 형태였습니다. TTT-Discover가 생성한 코드는 약 600개의 구간으로 이루어진 매우 불규칙하고 비대칭적인 계단 함수(Asymmetric Step Function) 를 정의하고 있었습니다. 이는 인간이나 기존 모델이 아름다움이나 단순함을 추구하느라 놓쳤던 영역에 진짜 정답이 숨어 있었음을 시사합니다.
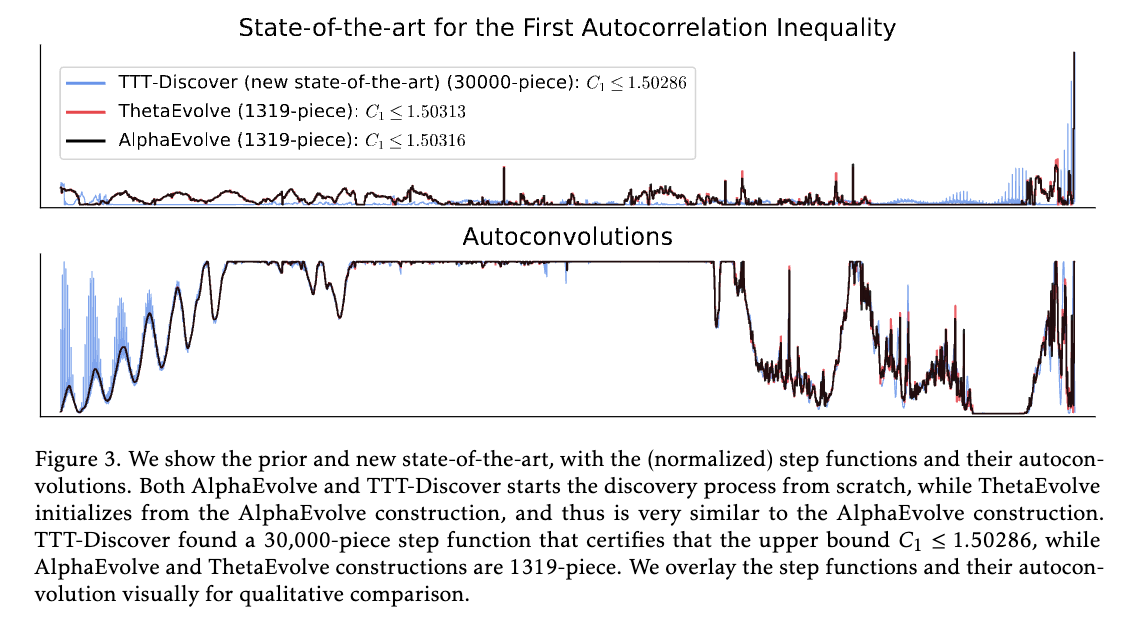
또한, TTT-Discover는 자기상관 부등식(Autocorrelation Inequalities) 문제에서도 유사한 성과를 거두었습니다. [-1/2, 1/2] 구간에서 정의된 함수 f 의 자기상관 함수 값들의 합에 대한 상한을 찾는 이 문제에서, TTT-Discover는 기존의 AlphaEvolve v2나 ThetaEvolve가 기록한 수치보다 더 엄밀한 상한값인 C_1 \le 1.50286 을 달성했습니다. 이를 위해 모델은 무려 30,000개의 미세한 구간으로 나뉜 함수를 구성하는 코드를 작성했는데, 이는 인간의 수작업으로는 사실상 불가능한 수준의 정밀한 탐색 결과입니다.
컴퓨터 시스템 분야: 하드웨어의 극한을 끌어내는 커널 최적화 (Kernel Engineering)
현대 AI 기술 발전의 이면에는 GPU 하드웨어의 성능을 극한까지 쥐어짜는 저수준(Low-level) 프로그래밍 기술이 있습니다. 연구진은 GPUMode 커뮤니티에서 주최한 삼각 행렬 곱셈(TriMul, Triangular Matrix Multiplication) 최적화 대회를 통해 TTT-Discover의 코딩 능력을 검증했습니다. 이 문제는 Python이나 고수준 프레임워크가 아닌, CUDA와 같은 언어를 사용하여 하드웨어의 메모리 계층 구조와 병렬 처리 유닛을 직접 제어해야 하는 고난도 엔지니어링 과제입니다.
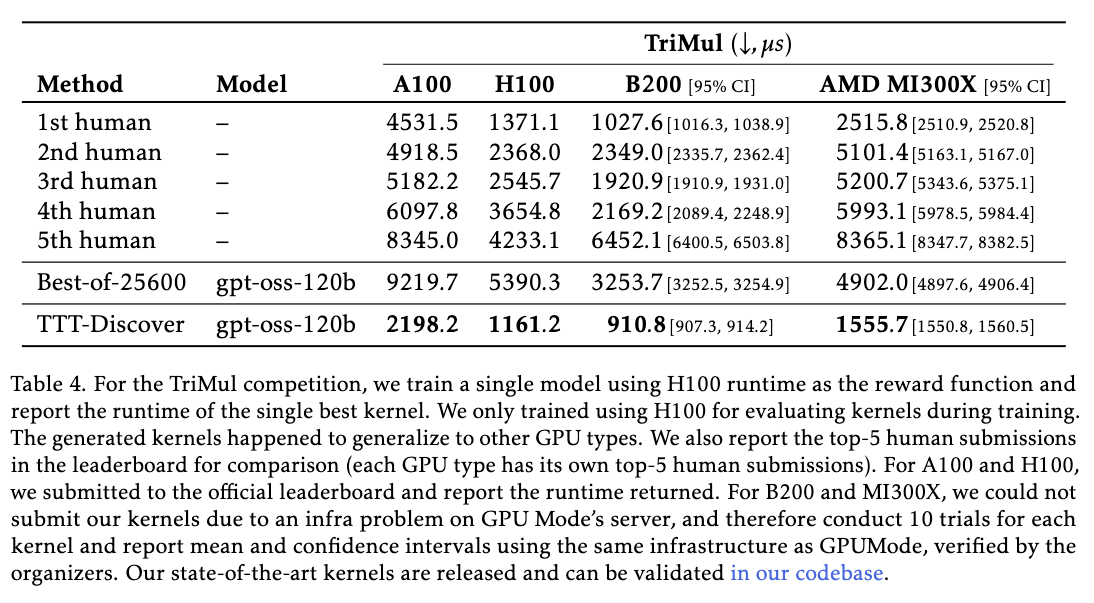
실험 결과, TTT-Discover는 현재 가장 널리 쓰이는 고성능 GPU인 NVIDIA H100에서 인간 전문가가 작성한 최고 성능의 커널보다 실행 시간(Latency)을 15% 더 단축하는 성능을 보였습니다. 또한, A100 GPU에서도 유사한 성능 향상을 기록했습니다. 단순히 운 좋게 파라미터를 맞춘 것이 아니라, 모델이 생성한 코드를 분석해 보면 고도의 최적화 기법들이 적용된 것을 확인할 수 있습니다.

예를 들어, 모델은 글로벌 메모리(Global Memory)에서 데이터를 가져올 때 병목 현상을 줄이기 위해 연산을 융합(Fusion)하는 전략을 취했으며, 공유 메모리(Shared Memory) 접근 시 발생하는 뱅크 충돌(Bank Conflict)을 피하기 위해 데이터 구조에 패딩(Padding)을 추가했습니다. 또한, 행렬 연산의 핵심인 텐서 코어(Tensor Core)를 활용하기 위해 wmma(Warp Matrix Multiply Accumulate) 또는 cuBLAS API를 적재적소에 호출하는 등, 마치 숙련된 시스템 엔지니어가 작성한 것과 같은 코드를 스스로 학습하여 생성해 냈습니다.
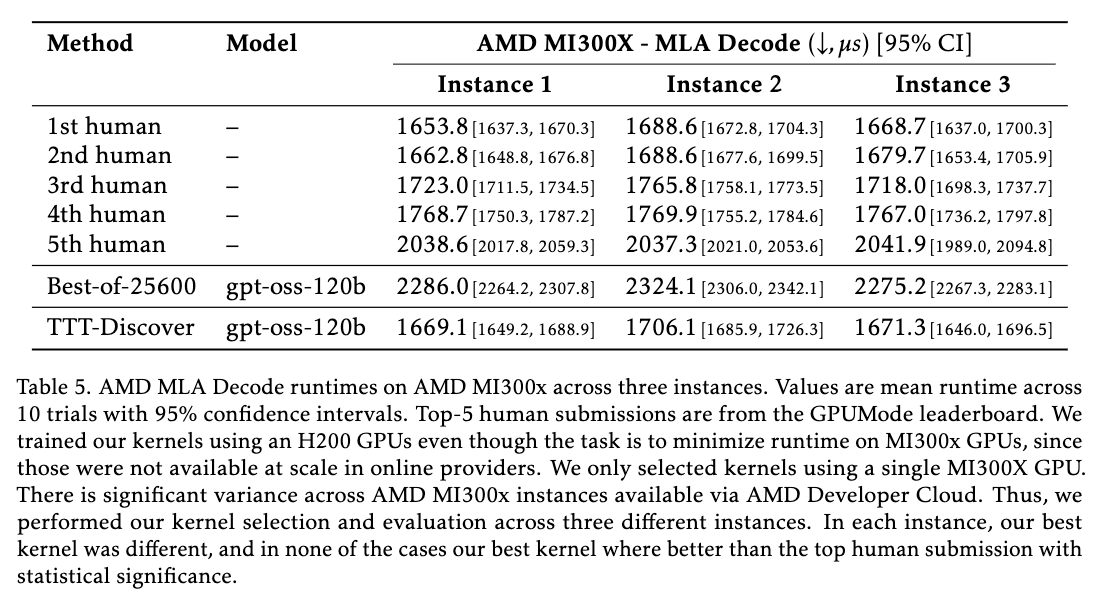
더욱 인상적인 점은 모델의 일반화(Generalization) 능력입니다. TTT-Discover는 H100이나 A100과 같은 특정 GPU 환경에서 훈련되었음에도 불구하고, 훈련 과정에서 한 번도 본 적 없는 차세대 GPU인 NVIDIA B200이나 경쟁사의 칩인 AMD MI300X에서도 성능 향상을 유지했습니다. 이는 모델이 특정 하드웨어의 기계적 특성에만 과적합(Overfitting)된 것이 아니라, 병렬 프로그래밍의 보편적인 최적화 원리를 스스로 터득했음을 의미합니다.
알고리즘 분야: 휴리스틱 대회에서의 초인적 성과 (Algorithms Engineering)
알고리즘 설계 능력을 평가하기 위해 연구진은 세계적인 프로그래밍 대회 플랫폼인 AtCoder의 휴리스틱 콘테스트(Heuristic Contest, AHC) 문제를 활용했습니다. 정답과 오답이 명확히 갈리는 일반적인 알고리즘 문제와 달리, 휴리스틱 대회는 "주어진 제약 조건 하에서 얼마나 더 좋은 점수를 얻을 수 있는가"를 겨루는 최적화 문제들로 구성됩니다. 이는 NP-Hard 문제에 근접하는 복잡성을 가지며, 창의적인 접근 방식이 요구됩니다.
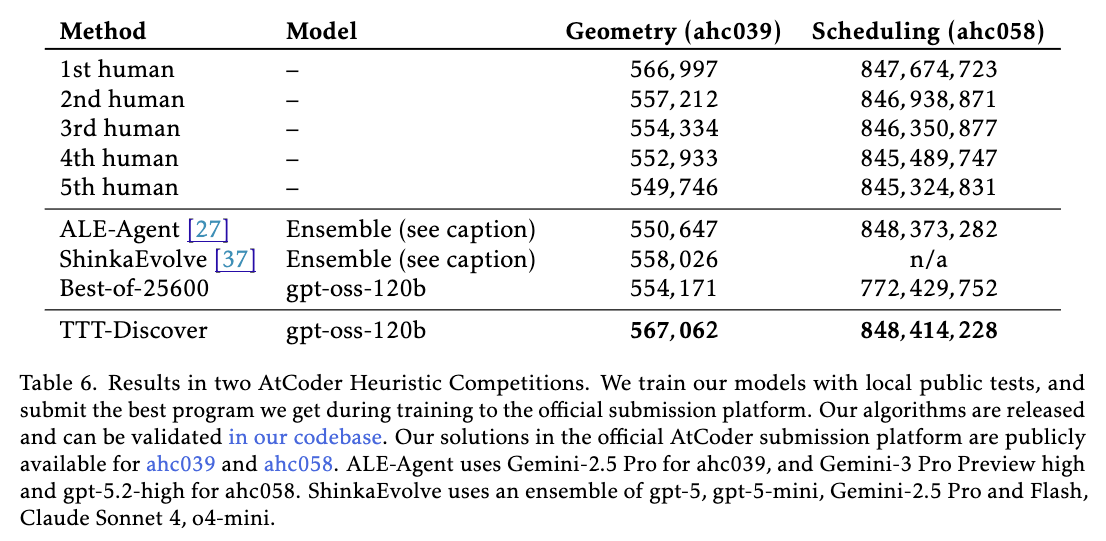
AHC039 문제는 그리드 위에서 닫힌 곡선을 그려 내부의 점수 합을 최대화하되 잃는 점수를 최소화하는 기하학적 최적화 문제였습니다. 여기서 TTT-Discover는 567,062점이라는 압도적인 점수를 기록했습니다. (TTT-Discover가 작성한 AHC039 코드) 이는 기존의 최신 진화 알고리즘 기반 모델인 ShinkaEvolve가 기록한 점수를 크게 상회하는 것이며, 대회 당시의 순위로 환산했을 때 1위에 해당하는 수준의 해법입니다.
또한, 폴리오미노(Polyomino) 조각들을 효율적으로 배치하고 순서를 정해야 하는 스케줄링 문제인 AHC058에서는 더욱 놀라운 결과를 보였습니다. TTT-Discover는 이 문제에서 대회 당시에 참가했던 모든 인간 플레이어들의 최고 점수를 뛰어넘는 기록을 세웠습니다. (TTT-Discover가 작성한 AHC058 코드) 이는 TTT-Discover가 단순히 코드를 생성하는 것을 넘어, 문제의 구조적 특성을 파악하고 다양한 경우의 수를 고려하여 최적의 전략을 수립하는 고차원적인 추론(Reasoning)이 가능함을 증명합니다.
생물학 분야 (Biology): 데이터의 노이즈 속에 숨겨진 신호 복원 (Single Cell Analysis)
마지막으로 적용된 분야는 생명 과학의 난제 중 하나인 단일 세포 RNA 시퀀싱(scRNA-seq) 데이터 분석입니다. 이 기술은 개별 세포 단위의 유전자 발현량을 측정할 수 있게 해주지만, 기술적 한계로 인해 데이터의 대부분이 0으로 관측되는 드롭아웃(Dropout) 현상이 심각하게 발생합니다. 따라서 실제 생물학적 신호와 기술적 노이즈를 구분하여 원본 데이터를 복원(Denoising)하는 것이 분석의 핵심입니다.
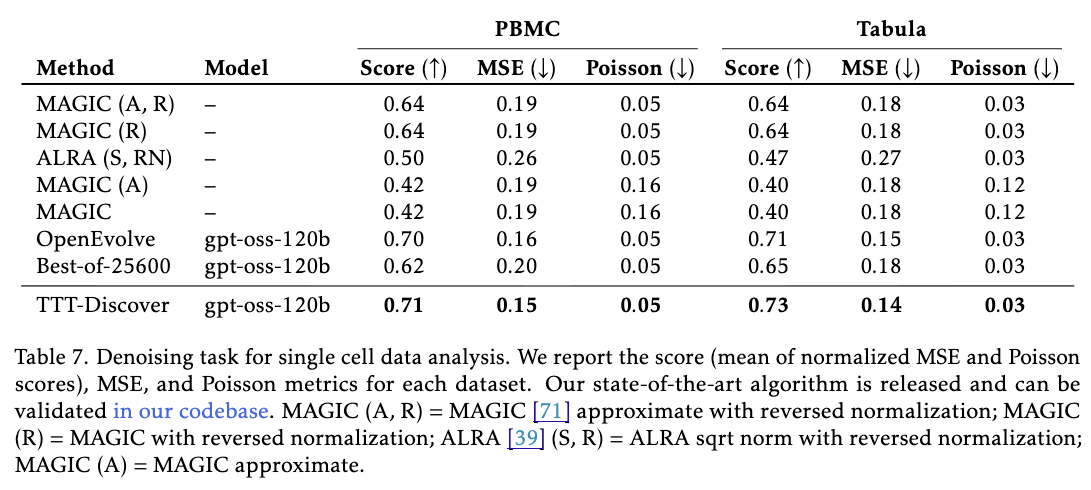
TTT-Discover는 이 문제에서 기존의 표준 알고리즘인 MAGIC이나 ALRA보다 현저히 낮은 평균 제곱 오차(MSE) 를 달성하며 데이터 복원 능력의 우수성을 입증했습니다. 단순히 기존 라이브러리를 호출하는 수준을 넘어, 모델은 데이터의 통계적 특성을 파악하고 스스로 새로운 파이프라인을 구축했습니다.

생성된 파이썬 함수 magic_denoise를 분석해 보면, 모델은 유전자별 발현량의 분산에 따라 적응형 변환(Adaptive Transformation)을 수행하고, 저순위 SVD(Singular Value Decomposition)를 통해 신호를 압축 및 정제하는 과정을 포함하고 있습니다. 전문 생물정보학자가 수년간의 연구를 통해 개발했을 법한 정교한 전처리 및 후처리 로직을, TTT-Discover는 보상 신호만을 바탕으로 스스로 조합하고 최적화하여 찾아낸 것입니다. 이는 AI가 과학적 실험 데이터를 해석하고 가설을 검증하는 연구 보조자로서 실질적인 역할을 할 수 있음을 시사합니다.
종합 분석 및 결론
지금까지 TTT-Discover가 수학, 시스템, 알고리즘, 생물학 등 다양한 분야에서 어떻게 기존의 한계를 뛰어넘었는지 살펴보았습니다. 하지만 "왜 이 방법이 작동하는가?"와 "어떤 요소가 성능 향상에 결정적인 기여를 했는가?"에 대해서도 궁금하실 것입니다. 연구진은 이를 규명하기 위해 시스템의 핵심 부품을 하나씩 제거하거나 변경해 보는 광범위한 Ablation Study를 수행했습니다.
Ablation Study: 성능 개선의 주요 요인 분석
학습 목적 함수의 중요성: 평균을 버리고 최댓값을 취하라
가장 먼저 검증한 것은 학습의 방향성을 결정하는 목적 함수(Objective Function) 입니다. 연구진이 제안했던 엔트로피 목적 함수(Entropic Objective) 를 제거하고, 일반적인 강화학습에서 사용되는 기대 보상(Expected Reward) 함수로 대체하여 실험을 진행했습니다.
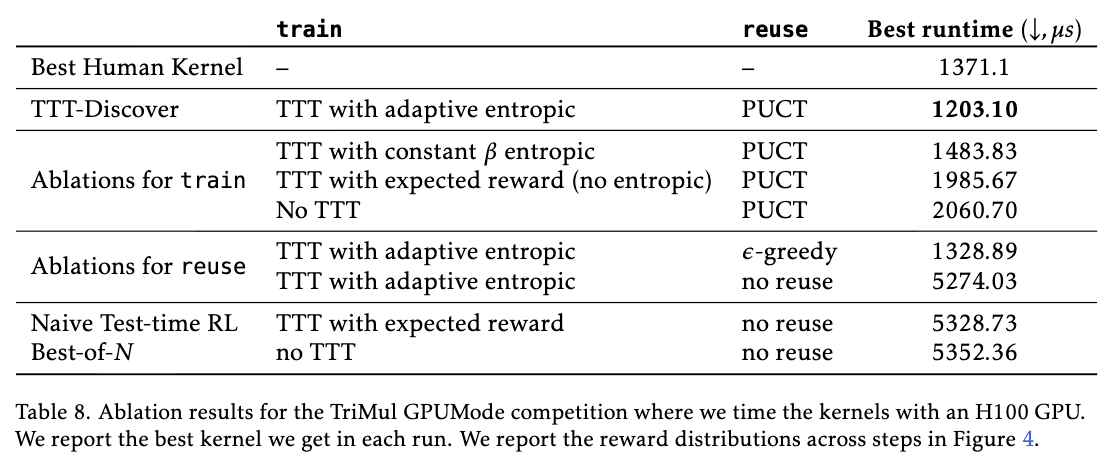
결과는 극명했습니다. 기대 보상을 사용한 모델은 학습이 진행될수록 성능 향상 속도가 현저히 느려지거나, 일정 수준 이상의 고득점 해답을 전혀 찾아내지 못하는 모습을 보였습니다. 그 이유는 명확합니다: 기대 보상 함수는 실패를 줄이는 것에 가중치를 두기 때문에, 모델이 위험을 감수하고 획기적인 시도를 하기보다는 안전하고 평범한 해답(Safe Bet)을 내놓도록 유도하기 때문입니다.
반면, TTT-Discover가 도입한 엔트로피 목적 함수는 보상에 지수 함수를 적용함으로써, 수백 번의 실패를 무시하고 단 한 번의 대성공에 모든 그래디언트를 집중시킵니다. 이는 "99번 틀려도 1번의 혁신적 발견이 중요하다"는 과학적 발견의 본질이 수학적으로 올바르게 구현되었음을 입증합니다.
탐색 전략의 승리: 리셋과 재사용의 힘
두 번째로 분석한 요소는 탐색(Search) 방식, 특히 상태 재사용(State Reuse) 의 효과입니다. 연구진은 세 가지 시나리오를 비교했습니다:
- 매 에피소드마다 백지상태에서 다시 시작하는 'No Reuse'
- 현재까지 발견된 가장 좋은 상태만을 무조건 선택하는 'Greedy Reuse'
- TTT-Discover가 채택한 'PUCT 기반 Reuse'
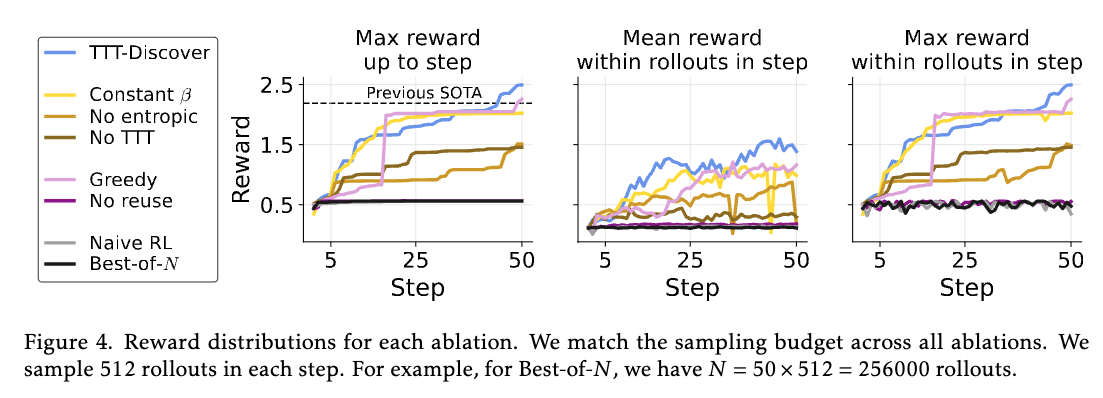
실험 결과, No Reuse 방식은 가장 저조한 성과를 보였습니다. 복잡한 문제는 수십 단계의 논리적 도약이 필요한데, 매번 처음부터 다시 시작해서는 깊이 있는 해답에 도달할 확률이 기하급수적으로 낮아지기 때문입니다.
Greedy Reuse 방식은 초기에는 빠른 성능 향상을 보였으나, 곧 국소 최적해(Local Optima) 에 빠져 더 이상의 발전이 멈추는 현상이 관찰되었습니다.
반면, PUCT 기반 방식은 유망한 상태를 집중적으로 파고들면서도(Exploitation), 아직 덜 탐색된 경로에 가산점을 부여하여(Exploration) 균형을 맞춤으로써 가장 높은 최종 성능에 도달했습니다. 이는 '거인의 어깨 위에 올라타라'는 격언처럼, 과거의 좋은 아이디어를 계승하되 끊임없이 새로운 가능성을 열어두는 것이 발견의 핵심임을 보여줍니다.
적응형 베타의 안정성
마지막으로 온도 매개변수(Temperature Parameter) \beta 값을 조절하는 스케줄링 기법의 영향을 분석했습니다. 고정된 \beta 를 사용할 경우, 값이 너무 작으면 학습이 지지부진하고, 값이 너무 크면 초기에 발견한 설익은 해답에 모델이 과몰입하여 정책이 붕괴(Collapse)되는 현상이 발생했습니다.
KL-Divergence 제약 조건을 활용한 적응형 베타 스케줄링(Adaptive \beta Scheduling) 은 학습 초기에는 탐색을 장려하고, 모델이 확신을 가질수록 가파르게 최적해로 수렴하도록 유도하여 하이퍼파라미터 튜닝의 난이도를 낮추고 학습의 안정성을 보장하는 결정적인 역할을 했습니다.
결론 및 미래 전망: 테스트 타임 컴퓨팅의 시대
TTT-Discover 연구는 단순히 몇 가지 어려운 문제를 풀었다는 것을 넘어, AI 모델링의 패러다임이 사전 학습(Pre-training)에서 추론 시점(Test-time)으로 확장되고 있음을 시사하는 중요한 이정표입니다.
지금까지의 AI 경쟁은 "누가 더 많은 데이터를 모아 더 큰 모델을 미리 학습시켜 놓느냐"에 집중되어 있었습니다. 하지만 TTT-Discover는 모델이 문제를 마주한 그 순간에 얼마나 깊이 생각하고 학습할 수 있느냐가 더 중요할 수 있음을 보여줍니다. 리처드 서튼(Richard Sutton) 교수가 블로그 글 "The Bitter Lesson"에서 강조했듯, 인간의 지식을 주입하는 것보다 막대한 계산 자원을 활용한 탐색(Search) 및 학습(Learning) 이 장기적으로 승리한다는 원칙이 이제 추론(Inference) 단계에도 적용되기 시작한 것입니다.
특히 이 연구는 OpenAI의 o1과 같은 최신 추론 모델들이 시도하는 생각하는 시간(Thinking Time)의 확보를 넘어, 실시간 자기 진화(Self-Evolution) 라는 더 급진적인 개념을 제시합니다. 모델은 고정된 지식 창고가 아니라, 주어진 환경과 상호작용하며 스스로 지식을 만들어내는 능동적인 에이전트(Active Agent)가 됩니다.
앞으로 우리는 신약 개발, 탄소 포집을 위한 신소재 설계, 상온 초전도체 탐색 등 정답 데이터가 존재하지 않는 미지의 영역에서 TTT-Discover와 같은 방법론이 활약하는 모습을 보게 될 것입니다. AI는 이제 우리가 알고 있는 답을 더 빨리 찾아주는 도구를 넘어, 인류가 한 번도 가보지 못한 지식의 지평을 함께 넓혀가는 진정한 의미의 연구의 동반자(Discovery Partner) 로 거듭나고 있습니다.
 TTT-Discover: Learning to Discover at Test Time 연구 홈페이지
TTT-Discover: Learning to Discover at Test Time 연구 홈페이지
 TTT-Discover: Learning to Discover at Test Time 연구 논문
TTT-Discover: Learning to Discover at Test Time 연구 논문
 TTT-Discover: Learning to Discover at Test Time 연구 GitHub 저장소
TTT-Discover: Learning to Discover at Test Time 연구 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()