[2026/06/22 ~ 28] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주에 선정된 10편의 논문들을 살펴본 결과, 에이전트의 자율성 증대와 피드백 기반의 최적화, 그리고 전문 영역으로의 깊숙한 침투라는 주요한 트렌드들을 발견할 수 있었습니다.
![]() 외부 스캐폴딩(Scaffolding)에서 자율적 '내재화'로의 에이전트 진화: 이번 주 논문들에서는 인간이 미리 정의한 외부 규칙(프롬프트, 도구 등)에 의존하던 에이전트가 점차 스스로 판단하고 구조를 내재화하는 방향으로 발전하고 있음이 돋보입니다. SIA는 에이전트의 외부 실행 구조(하니스)와 내부 가중치를 하나의 루프 안에서 동시에 업데이트하여 스스로 개선하는 체계를 구축했고, SelfCompact는 긴 추론 과정에서 컨텍스트 압축 시점을 고정된 규칙이 아닌 모델이 스스로 결정하도록 설계되었습니다. 또한, 에이전트 모델에 대한 비평(Critique of Agent Model) 논문은 진정한 에이전시가 외부 지지 구조가 아닌 시스템 내부에서 발현되어야 함을 역설합니다. 이는 AI가 고정된 워크플로우를 따르는 수동적 도구에서 벗어나, 상황에 맞게 스스로 조절하고 학습하는 진정한 의미의 자율적 개체로 나아가고 있음을 시사합니다.
외부 스캐폴딩(Scaffolding)에서 자율적 '내재화'로의 에이전트 진화: 이번 주 논문들에서는 인간이 미리 정의한 외부 규칙(프롬프트, 도구 등)에 의존하던 에이전트가 점차 스스로 판단하고 구조를 내재화하는 방향으로 발전하고 있음이 돋보입니다. SIA는 에이전트의 외부 실행 구조(하니스)와 내부 가중치를 하나의 루프 안에서 동시에 업데이트하여 스스로 개선하는 체계를 구축했고, SelfCompact는 긴 추론 과정에서 컨텍스트 압축 시점을 고정된 규칙이 아닌 모델이 스스로 결정하도록 설계되었습니다. 또한, 에이전트 모델에 대한 비평(Critique of Agent Model) 논문은 진정한 에이전시가 외부 지지 구조가 아닌 시스템 내부에서 발현되어야 함을 역설합니다. 이는 AI가 고정된 워크플로우를 따르는 수동적 도구에서 벗어나, 상황에 맞게 스스로 조절하고 학습하는 진정한 의미의 자율적 개체로 나아가고 있음을 시사합니다.
![]() 단일 추론을 넘어선 실행 기반의 '동적 피드백 루프' 활용: 단발적인 예측이나 정적인 선택을 넘어, 실행 과정에서 얻은 피드백을 지속적으로 반영하여 성능을 최적화하는 연구들이 두드러집니다. AaaR(Agent-as-a-Router)은 코딩 작업 라우팅을 단순 분류 문제가 아닌, 과거의 실행 경험(Context-Action-Feedback)을 누적해 최적의 모델을 찾아가는 과정으로 재정의했습니다. RA-RFT는 표면적 유사성이 아닌 실제 문제 해결에 도움이 되는 추론 궤적을 검색하고, 이를 바탕으로 정책 모델이 스스로 추론 경로를 개선하도록 유도합니다. Autodata 역시 에이전트의 메타 최적화 과정을 통해 합성 데이터의 품질을 지속적으로 끌어올리는 구조를 취하고 있으며, 이는 동적인 경험 축적을 통해 모델의 정보 격차와 한계를 능동적으로 극복하려는 강력한 흐름입니다.
단일 추론을 넘어선 실행 기반의 '동적 피드백 루프' 활용: 단발적인 예측이나 정적인 선택을 넘어, 실행 과정에서 얻은 피드백을 지속적으로 반영하여 성능을 최적화하는 연구들이 두드러집니다. AaaR(Agent-as-a-Router)은 코딩 작업 라우팅을 단순 분류 문제가 아닌, 과거의 실행 경험(Context-Action-Feedback)을 누적해 최적의 모델을 찾아가는 과정으로 재정의했습니다. RA-RFT는 표면적 유사성이 아닌 실제 문제 해결에 도움이 되는 추론 궤적을 검색하고, 이를 바탕으로 정책 모델이 스스로 추론 경로를 개선하도록 유도합니다. Autodata 역시 에이전트의 메타 최적화 과정을 통해 합성 데이터의 품질을 지속적으로 끌어올리는 구조를 취하고 있으며, 이는 동적인 경험 축적을 통해 모델의 정보 격차와 한계를 능동적으로 극복하려는 강력한 흐름입니다.
![]() 전문적 워크플로우의 전면적 대체 및 시스템 인프라화: AI 에이전트가 단순한 작업 보조를 넘어 데이터 과학자나 코드 리뷰어 같은 고도의 전문 인력을 실질적으로 대체하고, 다중 에이전트 생태계로 확장되는 현상이 가속화되고 있습니다. 코드 리뷰의 종말 논문은 코딩 에이전트가 결함 탐지부터 지식 이전까지 인간의 코드 리뷰 프로세스를 완전히 초월할 수 있음을 입증하며 소프트웨어 품질 관리의 패러다임 전환을 예고했습니다. Autodata는 고품질 데이터 생성이라는 데이터 과학자의 고유 영역을 에이전트가 주도적으로 수행하게 만듭니다. 나아가 LLM 에이전트 통신 프로토콜 분류체계 연구는 복잡한 작업을 나누어 수행하는 다중 에이전트 간의 상호운용성을 분석하여, AI가 개별 도구를 넘어 거대한 산업 시스템의 핵심 인프라 및 조직망으로 굳건히 자리 잡고 있음을 보여줍니다.
전문적 워크플로우의 전면적 대체 및 시스템 인프라화: AI 에이전트가 단순한 작업 보조를 넘어 데이터 과학자나 코드 리뷰어 같은 고도의 전문 인력을 실질적으로 대체하고, 다중 에이전트 생태계로 확장되는 현상이 가속화되고 있습니다. 코드 리뷰의 종말 논문은 코딩 에이전트가 결함 탐지부터 지식 이전까지 인간의 코드 리뷰 프로세스를 완전히 초월할 수 있음을 입증하며 소프트웨어 품질 관리의 패러다임 전환을 예고했습니다. Autodata는 고품질 데이터 생성이라는 데이터 과학자의 고유 영역을 에이전트가 주도적으로 수행하게 만듭니다. 나아가 LLM 에이전트 통신 프로토콜 분류체계 연구는 복잡한 작업을 나누어 수행하는 다중 에이전트 간의 상호운용성을 분석하여, AI가 개별 도구를 넘어 거대한 산업 시스템의 핵심 인프라 및 조직망으로 굳건히 자리 잡고 있음을 보여줍니다.
논문별 간결 요약
-
Autodata: An agentic data scientist to create high quality synthetic data: AI 에이전트가 데이터 과학자 역할을 수행해 합성 데이터를 만들고, 이를 메타 최적화까지 수행하도록 한 프레임워크입니다. 단순 생성보다 “데이터를 잘 만드는 에이전트”를 학습시키는 방향으로, 고품질 데이터 구축의 병목을 줄였습니다.
-
The End of Code Review: Coding Agents Supersede Human Inspection: 코딩 에이전트가 읽기, 쓰기, 테스트, 수리를 수행할 수 있으므로 전통적 인간 코드 리뷰를 핵심 품질 관문으로 유지할 필요가 적다고 주장합니다. 품질 보증의 단위를 사람의 검토에서 에이전트 기반 검사로 옮기자는 제안입니다.
-
SIA: Self Improving AI with Harness & Weight Updates: 하니스(harness) 업데이트와 가중치 업데이트를 하나의 자기개선 루프에 통합해, 외부 스캐폴드와 내부 지식 갱신을 동시에 수행합니다. 법률, GPU 커널, 단일세포 RNA 시퀀싱에서 모두 하니스만 개선하는 방식보다 더 좋은 성능을 보였습니다.
-
Agent-as-a-Router: Agentic Model Routing for Coding Tasks: 여러 LLM 중 어떤 모델을 어떤 작업에 쓸지 정적으로 분류하는 대신, 실행 경험을 축적하며 라우팅 정책을 계속 갱신하는 에이전틱 라우터를 제안합니다. 모델 선택을 단발성 판단이 아니라 학습 가능한 의사결정 과정으로 바꾼 점이 핵심입니다.
-
Token Factory: Efficiently Integrating Diverse Signals into Large Recommendation Models: 추천 시스템의 다양한 전통적 신호를 긴 텍스트로 풀어 쓰지 않고 소프트 토큰으로 압축해 LRM에 효율적으로 넣는 방법입니다. 프롬프트 폭증과 메모리 비용을 줄이면서 성능을 개선합니다.
-
Rethinking Cross-lingual Gaps from a Statistical Viewpoint: 교차 언어 격차를 단순한 다국어 학습 부족이 아니라 대상 언어 응답의 분산 문제로 재해석합니다. 추론 시점의 앙상블로 응답 분산을 낮추면 source-target 성능 차이를 크게 줄일 수 있음을 보였습니다.
-
Learning to Reason by Analogy via Retrieval-Augmented Reinforcement Fine-Tuning: 검색-증강 생성(RAG)을 단순 지식 주입이 아니라 유추적 추론 학습으로 재정의합니다. 정답과의 표면 유사도보다 추론적으로 도움이 되는 예시를 검색하고, 그 문맥을 활용하도록 강화 사후학습합니다.
-
Self-Compacting Language Model Agents: 긴 CoT와 도구 호출 추적이 컨텍스트 윈도우를 오염시키는 문제를 해결하기 위해, 모델이 스스로 언제 요약하고 언제 보존할지 판단하는 SelfCompact를 제안합니다. 고정 간격 요약보다 더 낮은 비용으로 비슷하거나 더 나은 성능을 냅니다.
-
A Technical Taxonomy of LLM Agent Communication Protocols: LLM 에이전트 간 통신 프로토콜을 상대방, 페이로드, 상호작용 상태, 발견 메커니즘, 스키마 유연성의 5개 축으로 체계적으로 분류합니다. 현재 생태계의 단편화를 정리하고, 향후 표준화가 어떤 방향으로 갈지 보여 줍니다.
-
Critique of Agent Model: 에이전트를 단순한 자동화 워크플로가 아니라, 목표, 정체성, 의사결정, 자기 조절, 학습이 내부화된 시스템으로 봐야 한다고 비판적으로 정리합니다. 이를 바탕으로 범용 에이전트 모델인 GIC 아키텍처를 제안합니다.
오토데이터: 고품질 합성 데이터를 생성하는 에이전트형 데이터 과학자 / Autodata: An agentic data scientist to create high quality synthetic data
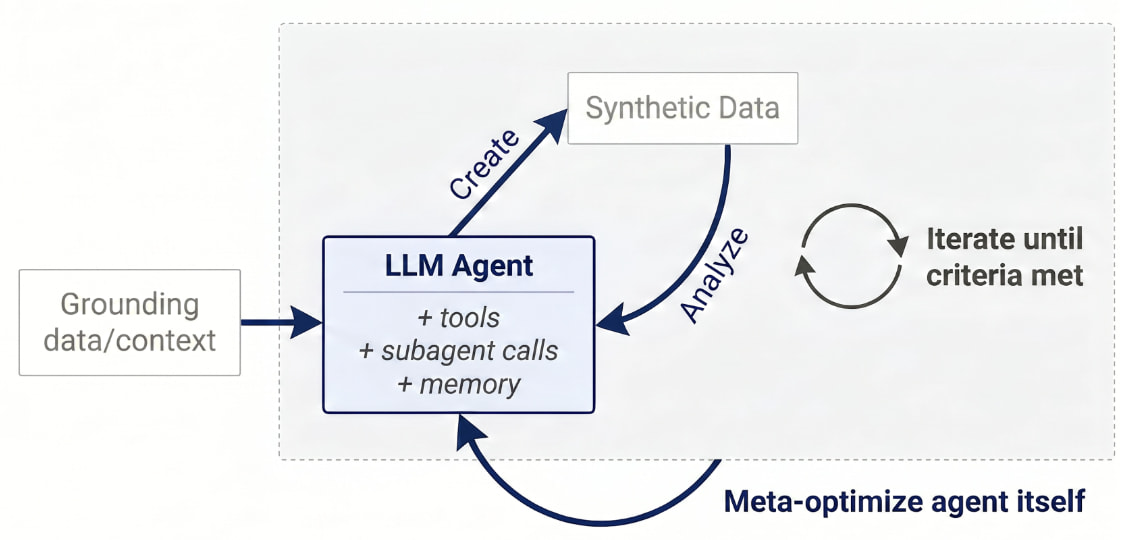
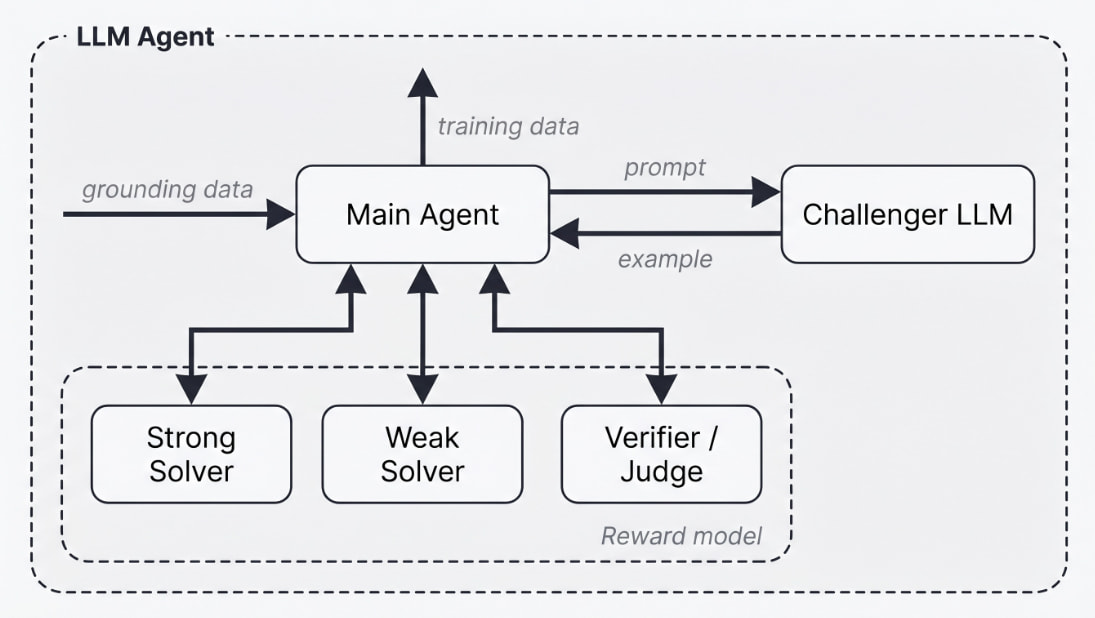
논문 소개
Autodata는 인공지능(AI) 에이전트가 데이터 과학자의 역할을 수행하여 고품질의 합성 데이터를 생성할 수 있도록 하는 혁신적인 방법론을 제시하고 있다. 이 연구는 데이터 과학자 에이전트를 메타 최적화하여, 이들이 더 강력한 데이터를 생성하도록 학습하는 과정을 설명한다. 특히, Agentic Self-Instruct라는 구체적인 구현 방안을 통해 AI가 데이터 생성 작업을 보다 효과적으로 수행할 수 있는 방법을 탐구하였다. 저자들은 컴퓨터 과학, 법적 추론, 수학적 객체에 대한 추론을 포함한 다양한 실험을 통해 전통적인 합성 데이터 생성 방법에 비해 향상된 결과를 얻었다.
이 연구의 핵심은 데이터 과학자 에이전트의 메타 최적화 과정에 있으며, 이를 통해 데이터 생성 품질이 비약적으로 개선됨을 입증하고 있다. 에이전틱 데이터 생성은 증가된 추론 컴퓨트를 고품질 모델 학습으로 전환할 수 있는 새로운 가능성을 제공하며, 이는 AI 모델의 성능 향상에 중요한 기여를 할 것으로 기대된다. 이러한 접근법은 기존의 데이터 생성 방법의 한계를 극복하고, AI 데이터 구축 방식을 근본적으로 변화시킬 잠재력을 지니고 있다.
Autodata는 AI 기술을 활용하여 데이터 생성의 효율성과 품질을 동시에 향상시킬 수 있는 방법론을 제시함으로써, 향후 AI 데이터 생성의 방향성을 새롭게 제시하고 있다. 데이터 과학자의 역할을 AI가 대체할 수 있다는 가능성을 제시하며, 고품질의 합성 데이터 생성을 위한 새로운 지평을 여는 중요한 기여를 하고 있다. 이 연구는 AI와 데이터 과학의 융합을 통해 더 나은 데이터 생성을 위한 혁신적인 경로를 제시하고 있으며, 향후 연구에 있어서도 중요한 참고자료로 자리잡을 것으로 보인다.
초록(Abstract)
Autodata는 AI 에이전트가 고품질의 학습 및 평가 데이터를 구축하는 데이터 과학자로서 행동할 수 있게 하는 일반적인 방법입니다. 우리는 이러한 데이터 과학자 에이전트를 훈련(메타 최적화)하여 더 강력한 데이터를 생성하는 방법을 보여줍니다. 전체적인 공식화와 구체적인 실용 구현인 Agentic Self-Instruct를 설명합니다. 우리는 컴퓨터 과학 연구 작업, 법적 추론 작업, 수학적 객체에 대한 추론 작업에 대한 실험을 수행하였으며, 이 실험에서 고전적인 합성 데이터셋 생성 방법에 비해 향상된 결과를 얻었습니다. 또한, 데이터 과학자 에이전트 자체를 메타 최적화함으로써 성능 향상이 더욱 크게 이루어졌습니다. Agentic 데이터 생성은 증가된 추론 컴퓨팅을 고품질 모델 학습으로 전환할 수 있는 방법을 제공합니다. 전반적으로, 우리는 이 방향이 AI 데이터를 구축하는 방식을 변화시킬 잠재력이 있다고 믿습니다.
We introduce Autodata, a general method that enables AI agents to act as data scientists who build high quality training and evaluation data. We show how to train (meta-optimize) such a data scientist agent, so that it learns to create even stronger data. We describe the overall formulation, and a specific practical implementation, Agentic Self-Instruct. We conduct experiments on computer science research tasks, legal reasoning tasks and reasoning with mathematical objects, where we obtain improved results compared to classical synthetic dataset creation methods. Further, meta-optimizing the data scientist agent itself delivers an even larger performance uplift. Agentic data creation provides a way to convert increased inference compute into higher quality model training. Overall, we believe this direction has the potential to change the way we build AI data.
논문 링크
코드 리뷰의 종말: 코딩 에이전트가 인간 검토를 초월하다 / The End of Code Review: Coding Agents Supersede Human Inspection
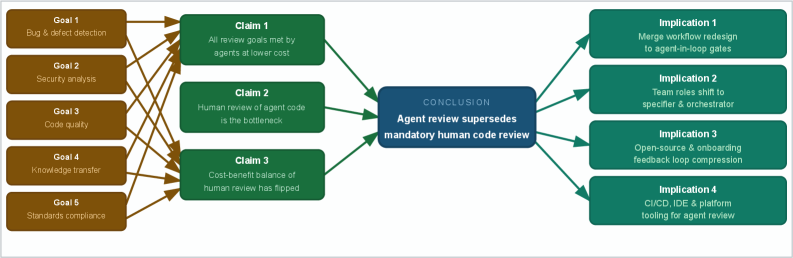
논문 소개
소프트웨어 개발에서 코드 리뷰는 오랜 시간 동안 품질 관리를 위한 핵심적인 절차로 자리잡아 왔으며, 이는 Fagan이 1976년에 제안한 공식적인 코드 검사 프로세스에 뿌리를 두고 있습니다. 그러나 최근의 연구에서는 대규모 언어 모델(LLM)을 기반으로 한 코딩 에이전트가 이러한 전통적인 코드 리뷰를 대체할 수 있는 가능성을 제시하고 있습니다. 코딩 에이전트는 소프트웨어를 읽고, 쓰고, 테스트하며, 수리하는 능력을 가진 자율 시스템으로, 이들은 코드 리뷰의 주요 목표인 결함 탐지, 스타일 및 규칙 준수, 팀 간 지식 이전, 코드베이스의 공동 인식 구축을 더 낮은 비용과 높은 처리량으로 달성할 수 있는 잠재력을 가지고 있습니다. 저자들은 단순히 인간 리뷰어가 남아 있는 상태에서 AI 도구를 도입하는 것은 비효율적이며, 진정한 품질 보증을 제공하지 못한다고 주장합니다.
이 논문은 코딩 에이전트의 성능을 입증하기 위해 다양한 벤치마크를 활용하여 이들이 소프트웨어 엔지니어링 작업을 효과적으로 수행할 수 있음을 보여줍니다. 특히, SWE-bench와 같은 평가 도구를 통해 최신 코딩 에이전트가 80% 이상의 작업을 성공적으로 해결할 수 있다는 사실을 강조합니다. 에이전트의 능력은 단순히 코드 생성을 넘어서, 인간 리뷰어가 목표로 하는 결함의 범주를 감지하는 등 리뷰 특정 능력에서도 뛰어난 성과를 나타냅니다. 이러한 결과는 코딩 에이전트가 소프트웨어 개발의 효율성을 높이는 데 기여할 수 있다는 강력한 근거를 제공합니다.
또한, 코딩 에이전트의 도입은 조직의 코드 리뷰 구조를 재설계할 필요성을 시사합니다. 인간의 승인 절차를 대체하고 고위험 변경 사항에 대해서만 인간의 승인을 요구하는 방식으로, 개발자들은 보다 많은 시간을 창의적인 작업에 할애할 수 있게 됩니다. 결국, 이 연구는 소프트웨어 개발의 미래를 재정의할 수 있는 중요한 기여를 하며, 코딩 에이전트의 활용이 더욱 생산적이고 효율적인 소프트웨어 개발 방법을 여는 시작점이 될 것임을 강조합니다.
초록(Abstract)
코드 리뷰는 1976년 페간이 코드 검사를 형식화한 이후 소프트웨어 개발에서 주요 품질 기준이 되어왔다. 지난 50년 동안, 동료의 변경 사항을 병합하기 전에 사람이 검토하고 의견을 제시하는 것은 모든 규모의 조직에서 핵심적인 관행이었다. 코딩 에이전트는 소프트웨어를 읽고, 작성하고, 테스트하며, 수정할 수 있는 대규모 언어 모델(LLM) 기반의 자율 시스템이다. 우리는 코딩 에이전트가 전통적인 인간 코드 리뷰가 더 이상 소프트웨어 품질 파이프라인의 필수 구성 요소가 아닌 능력의 경계를 넘어섰다고 주장한다. 우리의 주장은 두 가지 주장에 근거한다: 코드 리뷰의 모든 명시된 목표는 에이전트에 의해 더 낮은 비용과 더 높은 처리량으로 충족될 수 있다; 에이전트가 코드를 작성하고 인간이 필수 리뷰어로 남는 단순한 통합은 의미 있는 보장을 제공하지 않으며 AI 지원 처리량과 함께 확장되지 않기 때문에 막다른 길이다.
Code review has been the primary quality gate in software development since Fagan formalised code inspection in 1976. For five decades, having a human examine and comment on a colleague's changes before merge has been a cornerstone practice at organisations of every size. Coding agents are large language model (LLM)-based autonomous systems capable of reading, writing, testing, and repairing software. We argue that coding agents have crossed a threshold of capability at which traditional human code review is no longer a necessary component of a software quality pipeline. Our argument rests on two claims: every stated goal of code review can be served by agents at lower cost and higher throughput; the naive integration in which agents write code and humans remain the mandatory reviewers is a dead end because it neither provides meaningful assurance nor scales with AI-assisted throughput.
논문 링크
SIA: 하니스 및 가중치 업데이트를 통한 자기개선 AI / SIA: Self Improving AI with Harness & Weight Updates
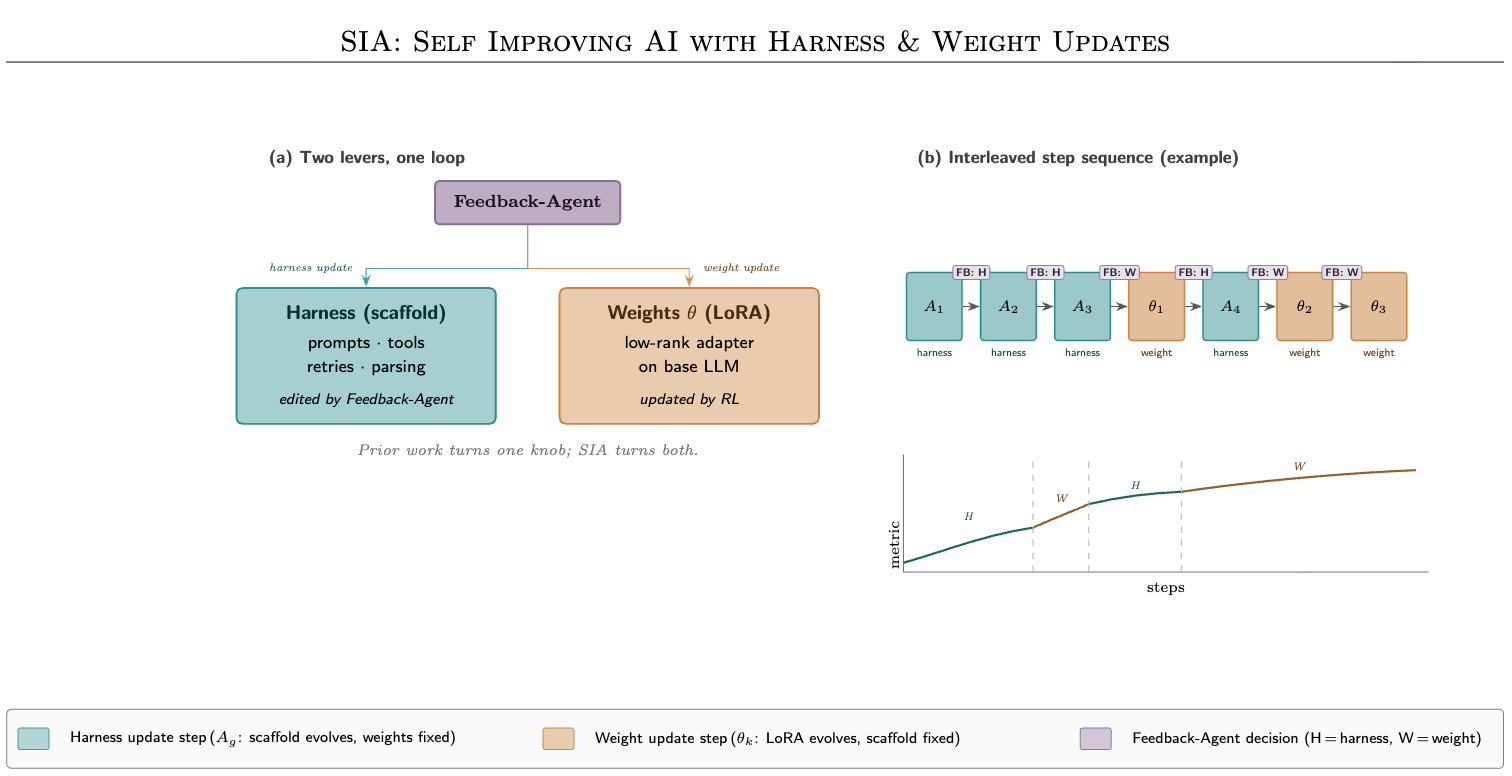
논문 소개
인공지능 시스템의 개선 과정은 여전히 인간의 설계와 수정에 크게 의존하며, 저자들은 이러한 구조가 장기적으로 자기개선형 인공지능을 가로막는 핵심 병목이라고 지적합니다. 이를 해결하기 위해 제안된 SIA(Self Improving AI with Harness & Weight Updates)는 태스크 전용 에이전트의 외부 실행 구조인 하니스(harness)와 모델 내부의 가중치를 하나의 자기개선 루프 안에서 동시에 갱신하는 방법론을 제시합니다. 기존 연구가 프롬프트, 도구, 재시도 로직, 탐색 절차를 바꾸는 하니스 업데이트와, 강화학습(reinforcement learning, RL)이나 테스트 시점 학습(test-time training)을 통해 가중치를 조정하는 접근으로 분리되어 있었다면, SIA는 Feedback-Agent가 실행 궤적과 성능 신호를 바탕으로 두 레버를 함께 다루도록 설계했다는 점에서 차별화됩니다. 이때 하니스는 모델이 더 잘 탐색하고 더 적절히 행동하도록 외부 구조를 정교화하며, 가중치 업데이트는 프롬프트만으로는 주입하기 어려운 도메인 직관과 추론 습관을 내재화한다는 역할 분담을 가집니다.
이 방법론의 타당성은 중국 법률 죄명 분류, 저수준 그래픽 처리 장치(graphics processing unit, GPU) 커널 최적화, 단일세포 RNA 시퀀싱(single-cell RNA sequencing, scRNA-seq) 디노이징이라는 서로 성격이 매우 다른 세 도메인에서 검증됩니다. 법률 과제에서는 하니스 반복만으로도 분류 파이프라인이 개선되었지만, 이후 저랭크 적응(low-rank adaptation, LoRA) 기반 가중치 업데이트를 통해 더 세밀한 죄명 판별 능력이 추가로 학습되면서 성능이 크게 상승했습니다. GPU 커널 최적화에서는 하니스가 메모리 레이아웃, 재시도 로직, 실행 전략을 다듬어 초기 탐색 공간을 효과적으로 정리했지만, 최종적으로는 보상 신호에 맞춘 가중치 갱신이 H100 환경에 특화된 저수준 최적화 감각을 내재화해 더 짧은 실행 시간을 달성했습니다. scRNA-seq 디노이징에서도 하니스는 하이퍼파라미터 탐색과 안정적 수렴을 돕는 반면, 가중치 단계에서는 출력에 음이 아닌 정수 제약을 부여하는 후처리 구조까지 스스로 형성하며 생물학적 제약을 반영했습니다.
이처럼 SIA는 단순히 두 기법을 병렬로 합친 것이 아니라, 언제 하니스를 수정하고 언제 가중치를 업데이트해야 하는지를 Feedback-Agent가 판단하는 폐쇄형 개선 체계를 구축했다는 점에서 의미가 큽니다. 실험 결과 역시 이러한 설계를 뒷받침하며, SIA-W+H는 세 벤치마크 모두에서 하니스만 반복하는 방식보다 우수한 성과를 보였습니다. 특히 LawBench에서는 25.1%의 향상을, GPU 커널 과제에서는 1,017 마이크로초(μs)로 기존 최고 성능인 1,161 마이크로초보다 빠른 결과를, 디노이징 과제에서는 20.4%의 향상을 기록했습니다. 결국 이 논문은 하니스 업데이트와 가중치 업데이트가 서로 대체 관계가 아니라 상보적 관계에 있으며, 외부 구조의 재설계와 내부 지식의 축적을 결합할 때 자기개선형 인공지능이 더 강한 성능과 더 넓은 일반화를 얻을 수 있음을 설득력 있게 보여줍니다.
초록(Abstract)
인간은 AI를 구축하고 개선하는 데 있어 병목입니다. 모델과 이를 감싸는 에이전트는 모두 사람이 작성하고, 튜닝하며, 수정합니다. AI가 스스로 어떻게 개선할지 알아내는 장기적 목표는 아직 열려 있습니다. 이 병목을 공략하는 연구 흐름은 대체로 서로 분리된 두 갈래로 나뉩니다. 하니스 업데이트 계열은 모델 가중치는 고정한 채, 메타 에이전트가 작업 특화 에이전트의 스캐폴드(도구, 프롬프트, 재시도 로직, 탐색 절차)를 다시 작성하게 합니다. 테스트 시점 학습 계열은 하니스는 고정한 채, 수작업 RL 파이프라인을 사용해 작업 피드백을 바탕으로 모델 자체의 가중치를 업데이트합니다. 이 두 사일로는 서로 분리된 채 작동합니다. 우리는 언어 모델 에이전트(Feedback-Agent)가 하니스와 작업 특화 에이전트의 가중치 모두를 업데이트하는 자기개선 루프인 SIA를 제안합니다. 우리는 세 가지 상이한 도메인, 즉 중국 법률 죄명 분류, 저수준 GPU 커널 최적화, 단일세포 RNA 디노이징에서 이를 평가했습니다. 두 레버를 함께 결합하면 세 벤치마크 모두에서 스캐폴드 반복만 사용하는 방식보다 더 뛰어난 성능을 보였습니다. SIA-W+H는 LawBench에서 기존 최고 성능(SOTA) 대비 25.1% 향상되었고, GPU 커널은 기존 최고 성능보다 12.4% 더 빨랐으며(1,017 vs 1,161 μs), 디노이징에서는 기존 최고 성능 대비 20.4% 향상을 달성했습니다. 하니스 업데이트는 모델을 에이전틱하게 만들어, 어떻게 탐색하고 행동하는지를 형성하며, 가중치 업데이트는 어떤 프롬프트나 스캐폴드로도 주입할 수 없는 도메인 직관을 구축합니다.
Humans are the bottleneck in building and improving AI. Both the models and the agents that wrap them are written, tuned, and corrected by people. The long-horizon goal of an AI that can figure out how to improve itself remains open. Two largely disjoint research lines attack this bottleneck. The harness-update school has a meta-agent rewrite the scaffold of a task-specific agent (its tools, prompts, retry logic, and search procedure) while the model weights are held fixed. The test-time training school uses hand-written RL pipelines to update the model's own weights on task feedback while the harness is held fixed. These two silos operate in isolation. We propose SIA, a self-improving loop in which a language-model agent (the Feedback-Agent) updates both the harness and the weights of a task-specific agent. We evaluate across three contrasting domains: Chinese legal charge classification, low-level GPU kernel optimisation, and single-cell RNA denoising. Combining both levers outperforms scaffold iteration alone on all three benchmarks. SIA-W+H achieves 25.1% over prior SOTA on LawBench, 12.4% faster GPU kernels than prior SOTA (1,017 vs 1,161 μs), and 20.4% over prior SOTA on denoising. Harness updates make the model agentic, shaping how it searches and acts, while weight updates build the domain intuition that no prompt or scaffold can instil.
논문 링크
더 읽어보기
AaaR(Agent-as-a-Router): 코딩 작업을 위한 에이전틱 모델 라우팅 / Agent-as-a-Router: Agentic Model Routing for Coding Tasks
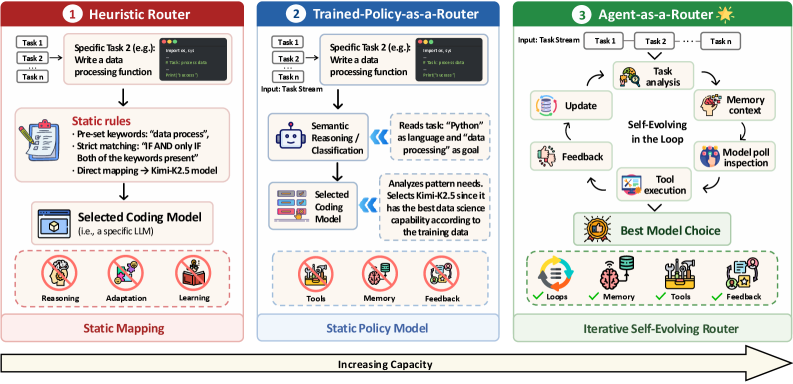
논문 소개
현대의 코딩 작업에서는 하나의 대규모 언어 모델(LLM)이 모든 문제에 가장 적합하다고 보기 어렵기 때문에, 각 작업을 성능과 비용 측면에서 가장 유리한 모델로 연결하는 라우팅 문제가 점점 더 중요해지고 있습니다. 저자들은 기존의 모델 라우터가 이를 단발성 분류 문제로 다루는 한계에 주목하며, 라우팅 성능의 병목이 추론 능력 부족이 아니라 정보 부족(information deficit)에 있다고 진단합니다. 이를 뒷받침하기 위해 작업 차원 수준의 성능 통계를 단순히 추가하는 것만으로도 기존의 순수한 LLM 라우터보다 15.3%의 상대적 향상이 나타났고, 같은 수준의 사전정보를 활용한 휴리스틱 라우터보다도 더 나은 결과가 확인되었습니다. 이러한 결과는 라우팅의 핵심이 더 정교한 한 번의 판단이 아니라, 실행 과정에서 얻는 경험을 얼마나 잘 축적하고 활용하느냐에 있다는 점을 분명하게 보여 줍니다.
이 논문이 제안하는 Agent-as-a-Router는 라우팅을 Context-Action-Feedback(C-A-F) 루프로 정식화하여, 배포 중에 모델 선택 정책이 계속 갱신되도록 설계한 점에서 기존 접근과 구별됩니다. 여기서 Context는 과거의 실행 경험과 누적된 지식을 뜻하고, Action은 현재 작업에 대해 어떤 모델을 호출할지 결정하는 단계이며, Feedback은 실행 결과를 검증해 얻은 성능 정보입니다. 이 피드백은 단순한 로그로 남는 것이 아니라 다음 라우팅 결정의 컨텍스트로 다시 흘러들어가므로, 라우터는 시간이 지날수록 더 나은 선택을 학습하는 에이전틱 시스템으로 작동합니다. 저자들은 이러한 구조를 contextual multi-armed bandit 관점과 연결하고, 단일 시점의 정확도보다 누적 후회(cumulative regret)를 기준으로 성능을 평가하는 것이 스트리밍 환경에서 더 타당하다고 설명합니다. 즉, 이 프레임워크의 목표는 한 번의 정답을 맞히는 것이 아니라, 장기적으로 오라클 선택에 얼마나 가까워지는지를 줄여 가는 데 있습니다.
이를 실제 시스템으로 구현한 ACRouter는 Orchestrator, Verifier, Memory라는 세 모듈로 구성됩니다. Orchestrator는 작업별 모델 호출 전략을 조정하고, Verifier는 실행 결과를 검증하며, Memory는 검증된 경험을 저장해 이후 라우팅에 반영합니다. 또한 CodeRouterBench는 약 1만 개의 작업 인스턴스와 8개의 최첨단(frontier) LLM에 대한 검증된 점수를 제공하여, 스트리밍 라우팅 상황을 현실적으로 평가할 수 있는 환경을 마련합니다. 이 벤치마크는 분포 내(in-distribution, ID) 작업뿐 아니라 분포 밖(out-of-distribution, OOD) 에이전틱 프로그래밍 작업까지 포함하므로, 라우터가 훈련된 범위를 넘어 일반화하는지도 함께 살펴볼 수 있습니다. 실험 결과 ACRouter는 ID 스트림에서 가장 낮은 누적 후회를 기록했을 뿐 아니라 OOD 작업에서도 강한 일반화 성능을 보였으며, 이는 실행 기반 경험 축적이라는 설계가 실제로 정보 격차를 메우는 데 효과적임을 시사합니다. 결국 이 연구는 모델 라우팅을 정적인 선택 문제에서 학습 가능한 의사결정 과정으로 전환함으로써, 코딩 에이전트가 더 효율적이고 적응적으로 여러 LLM을 활용할 수 있는 방향을 제시합니다.
초록(Abstract)
실제 환경의 사용자들은 일반적으로 서로 다른 제공업체의 여러 대규모 언어 모델(LLM)에 접근할 수 있으며, 이러한 LLM들은 종종 서로 다른 도메인에서 뛰어난 성능을 보이지만, 어느 하나도 모든 영역을 지배하지는 않습니다. 따라서 각 작업을 가장 적합한 모델로 라우팅하는 것은 성능과 비용 모두에서 매우 중요합니다. 기존 라우터는 이를 정적이고 일회성인 분류 문제로 취급합니다. 그러나 우리는 이러한 라우터의 성능 병목을 정보 부족으로 규정합니다. 단순히 기본 LLM 라우터에 작업-차원 수준의 성능 통계를 추가하는 것만으로도 15.3%의 상대적 향상을 얻을 수 있으며, 이는 동일한 차원 수준 사전 정보에 기반한 휴리스틱 라우터보다 우수합니다. 이러한 발견에 착안하여, 우리는 라우팅을 C-A-F 루프(Context->Action->Feedback->Context)로 정식화하는 Agent-as-a-Router 프레임워크를 제안합니다. 이 프레임워크는 배포 과정에서 실행에 근거한 경험을 축적함으로써 정보 격차를 해소합니다. 우리는 이 프레임워크를 Orchestrator, Verifier, Memory 모듈로 구성된 ACRouter로 구현하고, 8개의 최첨단 LLM에서 검증된 점수를 갖는 약 1만 개의 작업 인스턴스로 구성된 평가 환경 CodeRouterBench를 소개합니다. 이를 통해 스트리밍 작업에서 후회(regret) 기반 라우터 비교가 가능해집니다. 실험 결과, ACRouter는 분포 내 작업에서 가장 낮은 누적 후회(cumulative regret)를 달성하고, 분포 밖의 에이전틱 프로그래밍 작업으로도 일반화되어, 우리의 라우팅 프레임워크가 정보 격차를 능동적으로 해소함을 보여줍니다. 코드와 벤치마크는 GitHub - LanceZPF/agent-as-a-router: The official implementations of Agent-as-a-Router: Agentic Model Routing for Coding Tasks. · GitHub 에서 공개됩니다.
Real-world users typically have access to multiple Large Language Models (LLMs) from different providers, and these LLMs often excel at distinct domains, yet none dominate all. Consequently, routing each task to the most suitable model becomes critical for both performance and cost. Existing routers treat this as a static, one-off classification problem. However, we identify the performance bottleneck for these routers as information deficit: simply augmenting a vanilla LLM router with performance statistics at the task-dimension level yields a 15.3% relative gain, surpassing a heuristic router built on the same dimension-level priors. Motivated by this finding, we propose Agent-as-a-Router, a framework that formalizes routing as a C-A-F loop (Context->Action->Feedback->Context). It closes the information gap by accumulating execution-grounded experience during deployment. We instantiate this framework as ACRouter, composed of an Orchestrator, a Verifier, a Memory module, and introduce CodeRouterBench, an evaluation environment comprising ~10K task instances with verified scores from 8 frontier LLMs, enabling regret-based router comparison on streaming tasks. Experiments show that ACRouter achieves the lowest cumulative regret on in-distribution tasks and generalizes to out-of-distribution agentic-programming tasks, demonstrating that our routing framework actively closes the information gap. Codes and benchmarks are released at GitHub - LanceZPF/agent-as-a-router: The official implementations of Agent-as-a-Router: Agentic Model Routing for Coding Tasks. · GitHub.
논문 링크
더 읽어보기
토큰 팩토리(Token Factory): 다양한 신호를 대규모 추천 모델에 효율적으로 통합하는 방법 / Token Factory: Efficiently Integrating Diverse Signals into Large Recommendation Models
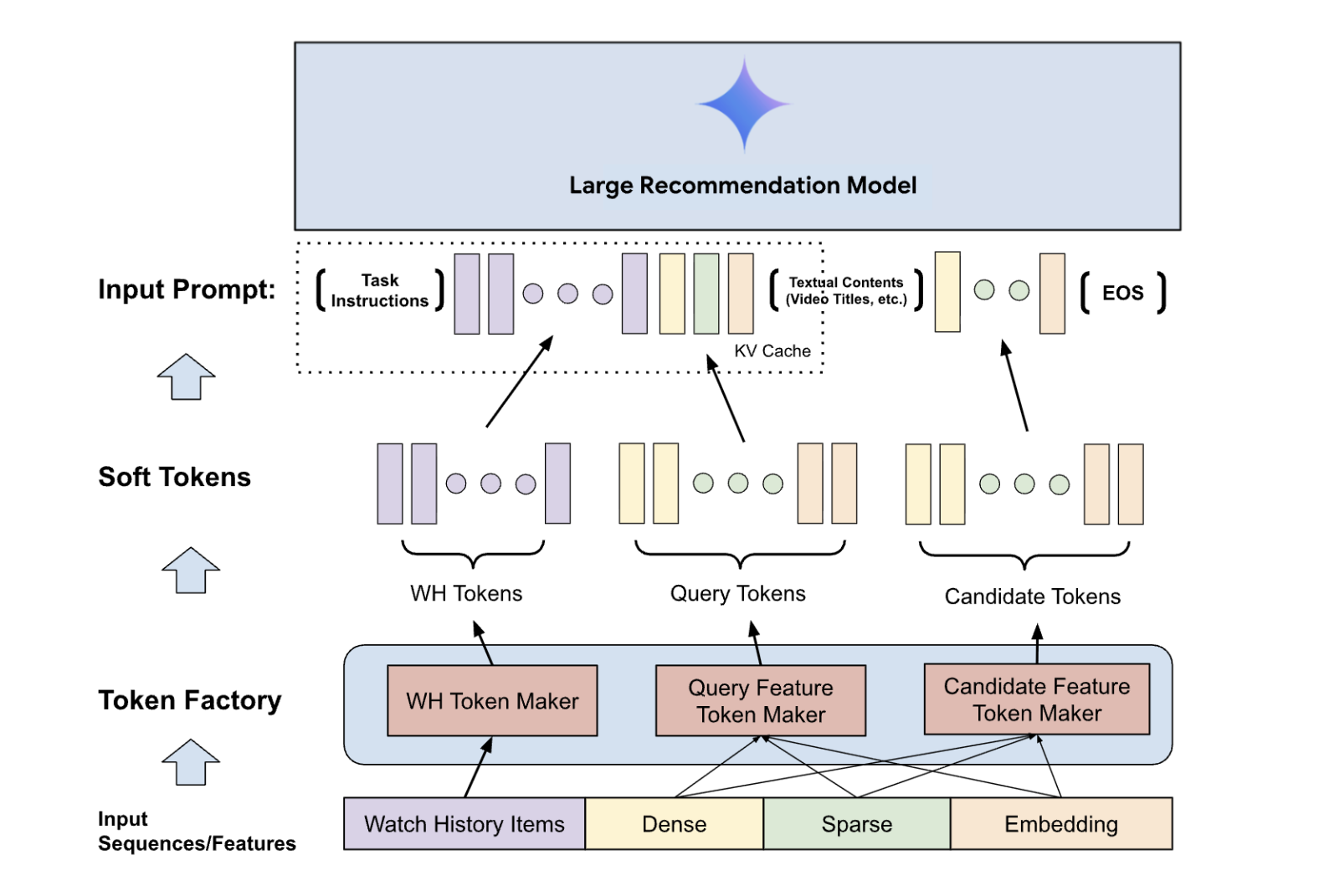
논문 소개
산업 규모의 추천 시스템에서 트랜스포머 아키텍처 기반의 대규모 추천 모델들은 사용자와 항목의 복잡한 상호작용을 포착하는 데 탁월한 성능을 보이고 있습니다. 그러나 이러한 모델들이 전통적인 신호들, 즉 밀집 특성과 희소 특성으로 이루어진 다양한 정보를 효율적으로 통합하는 것은 여전히 해결해야 할 중요한 과제로 남아있습니다. 기존 접근 방식들은 이러한 전통적 신호들을 직접 텍스트로 변환하거나 이산적인 항목 표현으로 변환함으로써 프롬프트 길이의 급격한 증가, 상당한 메모리 오버헤드, 그리고 높은 계산 비용이라는 문제를 야기해왔습니다. 본 논문에서 제시하는 Token Factory는 이러한 근본적인 도전 과제를 해결하기 위해 설계된 혁신적인 프레임워크입니다. Token Factory는 전통적 신호들을 "소프트 토큰"이라는 새로운 모달리티로 변환합니다. 이러한 소프트 토큰은 고정된 어휘에 의존하는 기존의 "하드" 토큰과 달리, 모델의 임베딩 공간 내에서 직접 표현되는 학습 가능한 벡터입니다.
Token Factory의 핵심 아키텍처는 여러 개의 토큰 메이커로 구성되며, 각 메이커는 시청 기록, 사용자 특성, 후보 항목 특성 같은 서로 다른 종류의 신호들을 처리합니다. 이러한 토큰 메이커들은 입력 특성들을 연결한 후 다층 퍼셉트론이나 더 복잡한 신경망 구조를 통해 고정된 개수의 소프트 토큰으로 변환합니다. 이 설계를 통해 입력 특성의 개수와 관계없이 프롬프트 길이를 사전에 정의된 예산으로 결정론적으로 제한할 수 있습니다. 또한 프롬프트 길이의 단축은 프리픽스 캐싱 같은 최적화 기법의 이점을 활용할 수 있게 하여, 추론 지연을 크게 줄일 수 있습니다. 논문에서는 시퀀스 압축 기법도 제시하는데, 다층 퍼셉트론을 활용한 차원 축소나 어텐션 풀링을 통해 더 긴 사용자 상호작용 기록을 보다 적은 소프트 토큰으로 표현할 수 있습니다.
실험 결과는 Token Factory의 효과성을 명확히 입증합니다. 순위 지정 작업에서 프롬프트 길이를 약 70% 감소시킴으로써 약 200% 더 빠른 훈련 속도를 달성하면서도 기준선과 동등한 예측 성능을 유지했습니다. 생성적 검색 작업에서는 오프라인 평가에서 10위 이내 재현율이 2% 개선되었으며, 온라인 실험에서는 고유 노출이 16.8% 증가했고 특히 신입 콘텐츠에 대한 고유 노출이 67.1% 급증했습니다. 광범위한 절제 연구를 통해 이러한 개선이 단순한 효율성 최적화를 넘어서며, 소프트 토큰 표현이 품질 향상을 위한 추가적 이점을 제공함을 확인했습니다. 특히 더 긴 사용자 상호작용 기록을 효율적으로 처리할 수 있게 됨으로써 모델이 사용자의 관심사를 더욱 정교하게 포착할 수 있게 되었습니다. 이러한 성과들은 모두 사용자 만족도에 부정적인 영향을 주지 않으면서 달성되었으며, 오히려 긍정적인 사용자 경험을 유지하거나 개선했습니다. 결론적으로 Token Factory는 산업 규모의 추천 시스템에서 이질적인 신호들을 효율적이고 효과적으로 통합하기 위한 실용적인 해결책을 제공하며, 실제 프로덕션 환경에서의 배포를 통해 그 가치와 신뢰성이 입증되었습니다.
초록(Abstract)
대규모 추천 모델(LRMs)은 산업 규모의 추천 작업에서 유망한 역량을 보여 왔습니다. 그러나 전통적인 신호를 이러한 트랜스포머 기반 아키텍처에 전체적으로 효과적이고 효율적으로 통합하는 것은 여전히 큰 과제입니다. 이러한 신호를 직접 “텍스트화”하거나 이산적인 아이템 표현을 생성하는 기존 접근법은 종종 지나치게 긴 프롬프트, 상당한 메모리 사용량, 높은 계산 오버헤드로 이어집니다. 이러한 한계를 극복하기 위해, 우리는 전통적 신호를 LRMs가 직접 처리할 수 있는 “소프트 토큰(soft tokens)”으로 변환하도록 설계된 프레임워크인 “토큰 팩토리(Token Factory)”를 제안합니다. 이 접근법은 이질적인 입력 특성의 효율적인 통합과 압축을 가능하게 하여, 프롬프트 길이의 폭증을 방지하는 동시에 모델 성능을 향상시킵니다. 또한 토큰 팩토리의 아키텍처를 자세히 설명하고, 실제 운영 규모의 추천 환경에서 그 효과를 검증하는 실험 결과를 제시합니다.
Large Recommendation Models (LRMs) have demonstrated promising capabilities in industry-scale recommendation tasks. However, holistically integrating traditional signals into these transformer-based architectures effectively and efficiently remains a major challenge. Conventional approaches that "textualize" these signals directly or create discrete item representations often lead to excessively long prompts, substantial memory footprints, and high computational overhead. To overcome these limitations, we propose "Token Factory", a framework designed to transform traditional signals into "soft tokens" that can be directly processed by LRMs. This approach enables efficient integration and compression of heterogeneous input features, preventing prompt length explosion while enhancing model performance. We detail the architecture of Token Factory and present experimental results validating its effectiveness in a production-scale recommendation environment.
논문 링크
통계적 관점에서 교차언어 격차를 다시 생각하기 / Rethinking Cross-lingual Gaps from a Statistical Viewpoint
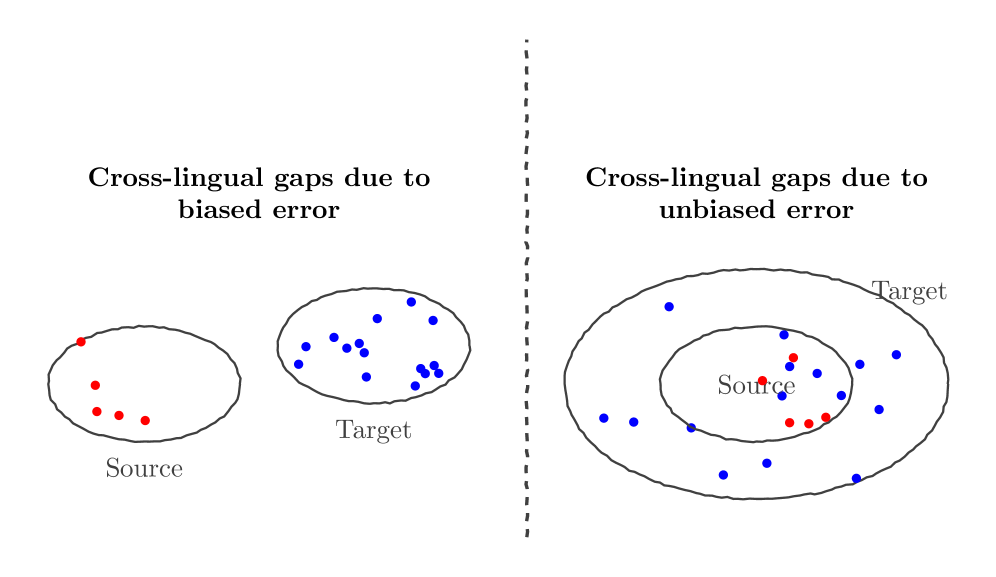
논문 소개
대규모 언어 모델(Large Language Models, LLMs)은 웹과 대규모 말뭉치에 흩어져 있는 지식을 한 언어에서 학습한 뒤 다른 언어의 질의에도 활용할 수 있어야 하지만, 실제로는 원천 언어(source language)로 질문할 때보다 대상 언어(target language)로 질문할 때 정확도가 낮아지는 교차 언어 격차(cross-lingual gap)가 자주 관찰됩니다. 저자들은 이러한 현상을 단순한 학습 부족이나 모델링 실패로 보지 않고, 통계적 관점에서 다시 해석하며 대상 언어 응답의 분산(response variance)이 격차의 핵심 원인이라는 가설을 제시합니다. 이를 바탕으로 교차 언어 오차를 편향 오류(biased error)와 비편향 오류(unbiased error)로 분해해 정식화함으로써, 언어별 성능 저하를 하나의 단일한 실패가 아니라 구조적 편향과 확률적 변동이 결합된 현상으로 설명합니다. 방법론적으로는 source와 target의 로그잇(logit)을 각각 두고, 피크니스(peakiness)를 조절하는 매개변수 κ를 곱한 뒤 소프트맥스(softmax)를 적용해 언어별 응답 분포를 정의합니다. 이후 두 분포가 같은 출력을 내릴 확률, 즉 공동 응답 확률(shared response probability)을 핵심 지표로 삼아, 분포가 더 뾰족해질수록 이 확률이 증가하는지를 미분을 통해 분석합니다. 특히 공동 응답 확률의 κ에 대한 도함수를 전개한 뒤, unbiased case에서 기대값의 단조 증가를 pairwise 항의 부호 분석으로 증명하여, 분포의 분산을 줄이는 방향이 source-target 간 응답 일치를 높인다는 수학적 근거를 제시합니다.
이러한 이론적 결과는 추론 시점(test-time)의 개입이 왜 효과적인지를 설명하는 토대가 됩니다. 저자들은 재학습이나 파라미터 수정 없이도 여러 번의 예측을 결합해 응답 변동성을 낮추는 test-time ensemble methods를 적용함으로써, 대상 언어에서의 불안정한 출력이 정답 일치로 수렴하도록 유도합니다. 다시 말해, 핵심 목표는 언어 간 지식 자체를 새로 학습하는 것이 아니라, 이미 보유한 지식을 더 일관되게 꺼내도록 응답 분포를 정렬하는 데 있습니다. 이 관점은 교차 언어 전이를 평균 정확도의 문제로만 보지 않고, 서로 다른 언어에서 동일한 정답에 도달할 확률 구조의 문제로 재해석한다는 점에서 중요한 의의를 지닙니다. 실험적으로도 이러한 분산 제어 전략은 다양한 LLM에서 source-target transfer score를 최대 12 절대점까지 향상시켰고, 상대적으로는 8%에서 50% 이상에 이르는 개선을 보여 주었습니다. 결국 이 연구는 cross-lingual gap을 단순한 다국어 능력의 부족으로 환원하지 않고, 대상 언어에서의 응답 안정성과 분포 집중도가 성능을 좌우한다는 점을 이론과 실험으로 함께 입증합니다. 이러한 통계적 재정의는 향후 다국어 추론 시스템에서 테스트타임 전략의 중요성을 부각시키며, 언어 간 전이를 보다 정교하게 설계할 수 있는 새로운 연구 방향을 제시합니다.
초록(Abstract)
어떤 지식 조각이든 일반적으로 웹이나 대규모 코퍼스의 하나 또는 소수의 자연어로 표현됩니다. 대규모 언어 모델(LLMs)은 원천 언어에서 지식을 습득한 뒤, 목표 언어로 질의했을 때 이를 접근 가능하게 만들어 주는 다리 역할을 합니다. 크로스링구얼 갭(cross-lingual gap)은 지식을 원천 언어가 아니라 목표 언어로 질의할 때 정확도가 하락하는 현상을 의미합니다. 기존 연구는 크로스링구얼 갭을 초래하는 모델링 또는 학습 실패에 초점을 맞추었습니다. 본 연구에서는 크로스링구얼 오류의 본질을 설명하는 대안적 관점을 취하고, 목표 언어 응답의 분산이 이러한 격차의 핵심 원인이라고 가설을 세웁니다. 우리는 편향 오류와 비편향 오류의 관점에서 크로스링구얼 갭을 처음으로 정식화합니다. 또한 분산을 제어하고 크로스링구얼 갭을 줄이는 여러 추론 시 개입을 통해 이 가설을 실증적으로 검증합니다. 더 나아가 응답 분산을 줄이는 몇 가지 테스트 시점 앙상블 방법을 제시하고, 이를 통해 다양한 LLM에서 원천-목표 전이 점수를 최대 12 절대 포인트까지 향상시키며, 8%에서 50%가 넘는 상대적 개선을 달성함을 보입니다.
Any piece of knowledge is usually expressed in one or a handful of natural languages on the web or in any large corpus. Large Language Models (LLMs) act as a bridge by acquiring knowledge from a source language and making it accessible when queried using target languages. A cross-lingual gap is a drop in accuracy incurred when querying knowledge in a target language rather than the source language. Existing research focused on modeling or training failures leading to cross-lingual gaps. In this work, we take an alternative view to characterize the nature of cross-lingual error, and hypothesize that the variance of responses in the target language is a key cause of this gap. For the first time, we formalize the cross-lingual gap in terms of biased and unbiased errors. We empirically validate our hypothesis through multiple inference-time interventions that control variance and reduce the cross-lingual gap. We demonstrate a few test-time ensemble methods that reduce response variance, and thereby improve source-target transfer scores by up to 12 absolute points yielding relative gains of 8% to over 50% across various LLMs.
논문 링크
검색-증강 강화 파인튜닝을 통한 유추 기반 추론 학습 / Learning to Reason by Analogy via Retrieval-Augmented Reinforcement Fine-Tuning
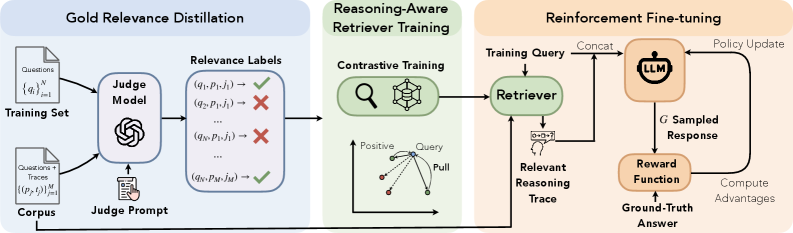
논문 소개
복잡한 수학 추론에서는 겉으로 비슷해 보이는 문제가 전혀 다른 풀이 전략을 요구하고, 반대로 표면적으로는 전혀 달라 보이는 문제가 같은 추론 구조를 공유하는 경우가 많습니다. 이러한 한계를 보완하기 위해 제안된 Retrieval-Augmented Reinforcement Fine-Tuning(RA-RFT)은 검색 증강 생성(Retrieval-Augmented Generation, RAG)을 단순한 지식 주입 방식이 아니라, 유추적 추론을 학습시키는 사후학습(post-training) 프레임워크로 재정의합니다. 핵심 아이디어는 먼저 gold-relevance distillation을 통해 질문과 문맥의 표면적 유사도 대신, 실제로 추론에 얼마나 도움이 되는지를 기준으로 검색기를 학습시키는 데 있습니다. 이를 위해 판단 모델이 문제 쌍을 보고 동일한 정리, 알고리즘, 증명 기법, 문제 축소 방식 등을 공유하는지를 평가하여, 추론적으로 전이 가능한 예시만을 긍정 신호로 삼습니다. 이렇게 학습된 검색기는 의미가 비슷한 문장을 찾는 것이 아니라, 해결 골격이 유사한 보조 예시를 우선적으로 찾아내며, 멀티벡터 기반의 late interaction 구조를 통해 증명 스캐폴드나 알고리즘 패턴 같은 미세한 추론 단서를 정밀하게 포착합니다. 이어서 정책 모델은 검색된 유추적 시연(demonstration)을 문맥으로 받아들인 상태에서 강화 미세조정(reinforcement fine-tuning)을 수행하며, 최종 답의 정답 여부만으로 정의되는 검증 가능한 보상(verifiable outcome reward)을 통해 학습됩니다. 이때 보상은 토큰 단위의 모사에 의존하지 않고, 수식 동치까지 판별하는 엄밀한 정답 검증에 기반하므로, 모델이 실제로 정답에 도달하는 추론 경로를 스스로 개선하도록 유도합니다.
이 접근의 중요한 점은 검색과 정책 학습을 분리된 보조 기능이 아니라 상호 보완적인 두 축으로 결합했다는 데 있습니다. 단순히 추론 시점에만 관련 예시를 붙이는 방식은 오히려 성능을 떨어뜨릴 수 있지만, RA-RFT는 검색된 문맥을 활용하는 법 자체를 학습함으로써 그 문맥이 정답 도출을 돕는 방식으로 모델의 추론 습관을 재구성합니다. 실험 결과 역시 이러한 설계를 뒷받침하며, AIME 2025와 같은 난도 높은 수학 벤치마크에서 기존 강화 사후학습 방법보다 일관된 향상을 보였습니다. 특히 Qwen3-1.7B와 Qwen3-4B에서 GRPO(Generalized Reward Policy Optimization) 대비 평균 정확도가 각각 7.1점, 2.8점 상승한 결과는, 검색 설계 자체가 독립적인 성능 향상 축이 될 수 있음을 시사합니다. 또한 RLOO와 DAPO 같은 서로 다른 정책 최적화 방법에도 동일한 이득이 관찰되어, RA-RFT의 효과가 특정 보상 설계나 학습 스케줄에 국한되지 않는다는 점이 확인됩니다. 정성 사례에서도 표면적으로 무관해 보이는 문제들 사이에서 동일한 제약 구조를 찾아내어 올바른 분해 전략을 떠올리게 하는 장면이 제시되며, 이는 유추 기반 검색이 실제 추론 스캐폴드로 작동함을 보여줍니다. 결국 이 연구는 대규모 언어 모델(Large Language Model, LLM)이 문제를 비슷한 문장으로 대응하는 수준을 넘어, 같은 추론 구조를 공유하는 사례를 통해 사고하도록 만드는 길을 열어 주며, 수학 추론을 비롯한 복잡한 문제 해결 전반에 새로운 방향성을 제시합니다.
초록(Abstract)
검색-증강 생성(RAG)은 언어 모델을 외부 지식에 기반시키는 표준 메커니즘이 되었지만, 어휘적 또는 의미적 유사성에 기반한 전통적인 검색은 복잡한 추론 과제에 적합하지 않습니다: 의미적으로 유사한 문제는 전혀 다른 해결 전략을 요구할 수 있는 반면, 표면적으로는 다른 문제라도 동일한 기본 추론 패턴을 공유할 수 있습니다. 우리는 언어 모델이 유추를 통해 추론하도록 가르치는 사후학습 프레임워크인 검색-증강 강화 파인튜닝(Retrieval-Augmented Reinforcement Fine-Tuning, RA-RFT)을 제안합니다. RA-RFT는 정답 관련성 증류(gold-relevance distillation)를 사용해 의미적 중첩이 아니라 기대되는 추론 이득을 기준으로 컨텍스트를 순위 매기는 검색기를 학습시키고, 이어서 검색된 유사한 데모를 활용해 강화 파인튜닝 방법으로 정책 모델을 미세조정함으로써, 모델이 검증 가능한 결과 보상 아래에서 추론 궤적을 활용하는 법을 배우도록 합니다. 또한 검색된 컨텍스트의 다양성을 추가로 분석한 결과, 추론 인지형 검색은 개별 문제에 서로 다른 추론 발판을 제공하는 보완적 해결 전략을 드러낸다는 사실을 확인했습니다. 도전적인 수학 추론 벤치마크 전반에서 RA-RFT는 표준 강화 파인튜닝 방법을 일관되게 능가합니다. 예를 들어, Qwen3-1.7B와 Qwen3-4B에서 각각 GRPO 대비 AIME 2025 average@32 정확도를 7.1포인트와 2.8포인트 향상시키며, 이는 추론 인지형 검색이 보상 설계나 학습 커리큘럼의 발전과는 직교하는 보완적 개선 축임을 시사합니다.
Retrieval-augmented generation (RAG) has become a standard mechanism for grounding language models in external knowledge, yet conventional retrieval based on lexical or semantic similarity is poorly suited for complex reasoning tasks: a semantically similar problem may demand an entirely different solution strategy, while a superficially different problem may share the same underlying reasoning pattern. We propose Retrieval-Augmented Reinforcement Fine-Tuning (RA-RFT), a post-training framework that teaches language models to reason by analogy. RA-RFT uses gold-relevance distillation to train a retriever that ranks contexts by expected reasoning benefit rather than semantic overlap, and then fine-tunes the policy model via reinforcement fine-tuning methods with retrieved analogous demonstrations, so the model learns to leverage reasoning traces under verifiable outcome rewards. We further analyze the diversity of retrieved contexts and find that reasoning-aware retrieval surfaces complementary solution strategies that provide distinct reasoning scaffolds for individual problems. Across challenging mathematical reasoning benchmarks, RA-RFT consistently outperforms standard reinforcement fine-tuning methods. For example, it improves AIME 2025 average@32 accuracy by 7.1 and 2.8 points over GRPO for Qwen3-1.7B and Qwen3-4B respectively -- suggesting that reasoning-aware retrieval is a complementary axis of improvement and orthogonal to advances in reward design or training curricula.
논문 링크
자가 압축 언어 모델 에이전트 / Self-Compacting Language Model Agents
논문 소개
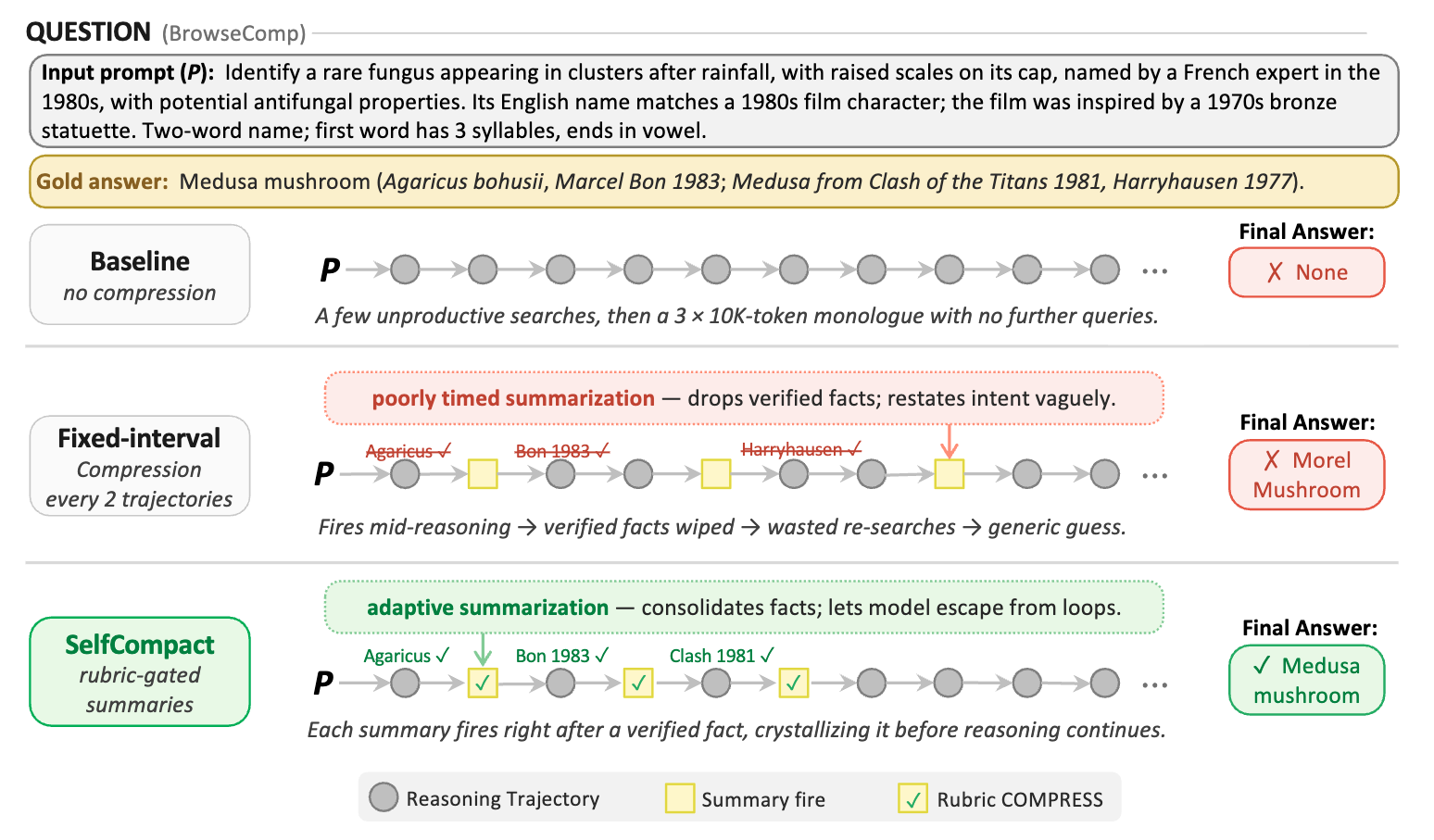
대규모 언어 모델을 이용한 에이전트 추론이 점점 더 길어지면서 누적되는 컨텍스트는 단순한 비용 문제를 넘어 성능을 크게 해치는 근본적 도전 과제가 되고 있습니다. 추론 과정에서 생성된 사고의 연쇄, 도구 호출 결과, 중간 계획들이 축적되다 보면 초기 단계의 잘못된 가정, 버려진 검색 결과, 막힌 후보들이 모두 컨텍스트에 남게 되며, 이러한 쓸모없는 정보들은 이후의 모든 생성 과정을 방해하게 되는데 이를 컨텍스트 부패라고 합니다. 현재의 에이전트 시스템들은 이 문제를 해결하기 위해 고정된 토큰 임계값이나 주기적인 간격에 따라 컨텍스트를 압축하지만, 이러한 기계적 접근 방식은 모델이 현재 수행 중인 작업의 구조를 전혀 고려하지 않습니다. 예를 들어 중간 도출 과정이나 활성 검색 단계에서 압축이 발동되면 모델이 여전히 필요로 하는 검증된 정보를 삭제할 수 있습니다.
이 논문에서 제안하는 SelfCompact는 모델 자신이 압축할 시기와 방식을 결정할 수 있도록 하는 스캐폴드로, 압축 도구와 경량 루브릭이라는 두 가지 추론 시간 요소를 결합합니다. 압축 도구는 축적된 컨텍스트를 요약하는 역할을 하며, 경량 루브릭은 하위 작업이 해결되었거나 추적이 수렴하는 경우에는 압축을 수행하고, 미-도출 중이거나 모델이 고착 상태에 있는 경우에는 억제하도록 지정합니다. 특히 이 방법의 핵심 강점은 미세 조정이나 외부 감시 없이도 기성 모델에서 효과적으로 작동한다는 점입니다. KV 캐시 재사용을 통해 루브릭 프로브에서의 오버헤드를 최소화하며, 요약 후 모든 후속 생성이 전체 추적이 아닌 압축된 요약에 기반하므로 실질적인 비용 절감을 달성합니다.
광범위한 실험을 통해 이 접근 방식의 효과성이 검증되었습니다. 경쟁 수학 벤치마크에서 Qwen 계열의 네 가지 모델에 걸쳐 평가하면 SelfCompact는 기준선에 비해 최대 18.1점 개선을 달성하며, 에이전트 검색 작업에서도 세 가지 배포된 모델 모두에서 우수한 성능을 보입니다. 가장 중요한 것은 동일한 토큰 예산에서 고정 간격 압축을 능가할 뿐 아니라 30~70% 더 낮은 비용으로 이를 달성한다는 점입니다. 절제 연구를 통해 루브릭이 단순히 압축 시점을 결정하는 것을 넘어 어떤 정보를 안전하게 압축할 수 있는지를 검증하는 역할을 하며, 루브릭이 없는 무제약 요약은 성능을 현저히 떨어뜨린다는 것이 확인되었습니다. 이 연구는 미세 조정되지 않은 모델이 자신의 컨텍스트 부패를 신뢰할 수 없게 인식할 수 있다는 메타-인식 격차를 지적하면서도, 경량 루브릭과 같은 스캐폴드를 통해 이 능력을 훈련 없이 공급할 수 있음을 보여줍니다. 따라서 SelfCompact는 언제 압축할지를 모델이 자율적으로 결정하면서도 부적절한 압축을 방지하는 구조적 가이드를 제공함으로써, 장기 에이전트 추론에서 효율성과 성능 사이의 균형을 획기적으로 개선하는 방법론을 제시합니다.
초록(Abstract)
사고의 연쇄와 도구 호출로 구성된 긴 에이전트 추적은 후속 생성을 고정시키는 오래된 콘텐츠를 누적하고, 결국 컨텍스트 윈도우를 넘어섭니다. 기존 스캐폴드는 토큰 임계값에서 트리거되는 고정 간격 압축으로 이를 완화합니다. 그러나 이러한 트리거는 궤적의 구조를 고려하지 않기 때문에, 유도 도중이나 탐색 도중에 부분 결과를 버릴 위험이 있습니다. 우리는 모델 자체가 언제, 어떻게 압축할지 결정할 수 있도록 하는 스캐폴드인 SelfCompact를 제안합니다. 구체적으로, 이는 두 가지 추론 시 요소를 결합합니다. (i) 모델이 누적된 컨텍스트를 요약하기 위해 호출하는 압축 도구, (ii) 언제 발동할지(하위 작업이 해결되었거나 궤적이 수렴하고 있을 때)와 언제 억제할지(유도 도중이거나 막혔을 때)를 규정하는 경량 루브릭입니다. 두 요소는 모두 필요합니다. 도구만으로는 오픈 가중치 모델 전반에서 사용이 들쭉날쭉하며, 종종 도움이 되지 않는 순간에 호출되거나 아예 호출되지 않습니다. 루브릭만으로는 작동할 수 없습니다. 이 둘을 함께 사용하면, 어떠한 파인튜닝이나 외부 감독도 없이 효과적인 적응형 압축을 이끌어냅니다. 우리는 경쟁 수학과 에이전트형 검색을 포함한 6개 벤치마크와 7개 모델에서의 실증 결과를 제시합니다. 우리의 결과는 SelfCompact이 토큰 비용의 일부만으로 고정 간격 요약과 같거나 그 이상을 달성하며, 질문당 비용을 30~70% 낮추는 조건에서 수학에서는 최대 18.1포인트, 에이전트형 검색에서는 5~9포인트까지 요약 없는 기준선보다 향상시킨다는 것을 보여줍니다. 우리의 결과는 메타인지적 격차를 드러냅니다. 프롬프트 없이 주어졌을 때 모델은 자신의 컨텍스트가 언제 망가지고 있는지 신뢰성 있게 판단할 수 없지만, 경량 루브릭이 이 격차를 메우며, 압축 시점을 학습 없이 스캐폴드가 제공할 수 있는 능력으로 재정의합니다.
Long agent traces composed of chains of thought and tool calls accumulate stale content that anchor subsequent generations, and eventually outgrow the context window. Existing scaffolds mitigate it with fixed-interval compaction triggered at a token threshold. Such triggers pay no heed to trajectory structure, risking discard of partial results mid-derivation or mid-search. We propose SelfCompact, a scaffold that allows the model itself to decide when and how to compact. Specifically, it pairs two inference-time elements: (i) a compaction tool the model invokes to summarize the accumulated context, and (ii) a lightweight rubric specifying when to fire (a sub-task has resolved, or the trajectory is converging) and when to suppress (mid-derivation, or when stuck). Both are needed. The tool alone is unevenly used across open-weight models, often invoked at unhelpful moments or not at all; the rubric alone cannot act. Together, they elicit effective adaptive compaction without any fine-tuning or external supervision. We present empirical results on six benchmarks (competitive math and agentic search) and seven models. Our results show that SelfCompact matches or exceeds fixed-interval summarization at a fraction of the token cost, improving over a no-summarization baseline by up to 18.1 points on math and 5-9 points on agentic search at 30-70% lower per-question cost. Our results expose a meta-cognitive gap: although unprompted models cannot reliably tell when their own context is rotting, a lightweight rubric closes this gap, reframing when to compact as a capability that scaffolds can supply without training.
논문 링크
LLM 에이전트 통신 프로토콜의 기술적 분류체계 / A Technical Taxonomy of LLM Agent Communication Protocols
논문 소개
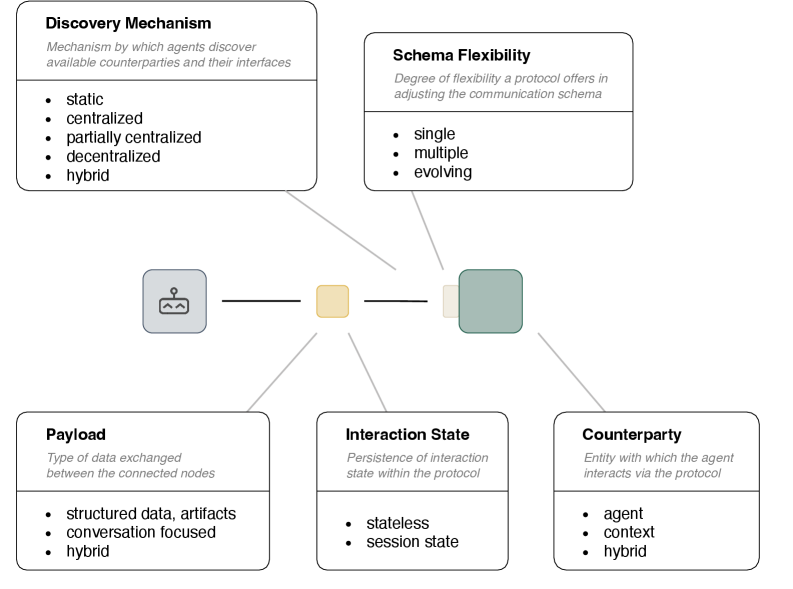
대규모 언어 모델(LLM)의 성능이 빠르게 향상되면서, 단일 에이전트가 감당하기 어려운 복잡한 작업을 여러 에이전트가 협력해 처리하려는 흐름이 본격화되고 있으며, 그에 따라 에이전트 간 상호운용성을 뒷받침할 통신 프로토콜의 중요성이 크게 커지고 있습니다. 그러나 현재의 프로토콜 생태계는 목적과 설계 철학이 제각각이라 서로 다른 시스템 사이의 연결성과 재사용성을 확보하기 어렵고, 이러한 단편화는 실제 배포 환경에서 중요한 장애 요인으로 작용합니다. 저자들은 이러한 문제를 해결하기 위해 개별 프로토콜을 단순 열거하는 대신, 실제로 유지보수되고 채택된 오픈소스 프로토콜들을 체계적으로 비교할 수 있는 기술적 분류 체계(taxonomy)를 설계했습니다. 분류 체계는 Nickerson et al.의 반복적 방법론을 따라 구축되었으며, 목적, 메타 특성(meta-characteristic), 종료 조건을 먼저 정의한 뒤 경험적 관찰과 개념적 정제를 오가는 다섯 차례의 반복을 통해 완성되었습니다. 이 과정에서 핵심 관찰 대상은 대규모 언어 모델 에이전트를 위해 명시적으로 설계되고, 실행 가능한 구현과 실제 사용 흔적을 갖춘 아홉 개의 오픈소스 프로토콜로 한정되었습니다.
최종적으로 도출된 분류 축은 상대방(counterparty), 페이로드(payload), 상호작용 상태(interaction state), 발견 메커니즘(discovery mechanism), 스키마 유연성(schema flexibility)의 다섯 가지로, 각 축은 프로토콜이 누구와 무엇을, 어떤 상태로, 어떻게 찾고, 얼마나 유연하게 주고받는지를 구조적으로 드러냅니다. 이러한 틀을 적용한 결과, 에이전트-에이전트 프로토콜들은 대체로 하이브리드 페이로드와 세션 상태 지속성을 함께 사용하고 있었으며, 다수는 여러 개의 사전 정의된 스키마를 지원했고 일부는 런타임 협상을 통해 스키마를 동적으로 결정하는 방향까지 보여 주었습니다. 반면 분산형 발견은 여전히 드문 특성으로 남아 있어, 현재의 설계가 완전한 탈중앙화보다는 제한된 범위의 상호운용성과 운영 편의성에 더 무게를 두고 있음을 시사합니다. 저자들은 또한 에이전트-에이전트 통신과 에이전트-컨텍스트, 즉 도구 및 데이터 통신이 단기적으로는 하나의 표준 축으로 수렴하려는 압력을 받을 가능성이 크다고 분석했습니다. 그러나 장기적으로는 어떤 단일 프로토콜도 범용성, 효율성, 이식성을 동시에 최대로 만족시키기 어렵기 때문에, 프로토콜 생태계는 연합형(federated)이고 계층형(layered)인 스택 구조로 진화할 가능성이 높다고 전망합니다.
이 연구의 의의는 프로토콜의 기능 목록을 정리하는 수준을 넘어, 서로 다른 설계 선택이 어떤 구조적 차이를 만들어 내는지 설명 가능한 방식으로 제시했다는 데 있습니다. 따라서 이 분류 체계는 연구자에게는 현재 지형의 공통 패턴과 미해결 과제를 식별하는 분석 도구가 되고, 실무자에게는 특정 응용 상황에 어떤 프로토콜이 더 적합한지 판단하는 선택 기준이 됩니다. 특히 프라이버시와 정책 집행(policy enforcement)처럼 아직 충분히 성숙하지 않은 문제들을 연구 공백으로 드러냈다는 점에서, 향후 표준화와 시스템 설계의 방향을 제시하는 의미도 큽니다.
초록(Abstract)
대규모 언어 모델(LLM)이 발전하고 다중 에이전트 시스템이 단독 에이전트의 한계를 극복하고자 하면서, 강건한 통신 프로토콜은 분산 에이전트 네트워크의 필수 인프라로 자리 잡고 있다. 그럼에도 불구하고, 분절된 프로토콜 환경은 심각한 상호운용성 문제를 초래한다. 본 연구는 LLM 에이전트 통신 프로토콜을 분류하고 분석하기 위한 기술적 분류체계(taxonomy)를 개발한다. 확립된 반복적 방법에 따라 우리는 분류체계의 목적, 메타 특성, 종료 조건을 정의한 뒤, 실증적→개념적 3회와 개념적→실증적 2회의 다섯 차례 반복을 수행했으며, 실제 채택이 입증된 활발히 유지보수되는 9개의 오픈소스 프로토콜을 대상으로 분석했다. 이 분류체계는 상대방(counterparty), 페이로드(payload), 상호작용 상태(interaction state), 디스커버리 메커니즘(discovery mechanism), 스키마 유연성(schema flexibility)의 다섯 가지 차원으로 구성된다. 분류 결과는 반복적으로 나타나는 아키텍처 패턴을 보여준다. 샘플로 선정한 모든 에이전트-간(agent-to-agent) 프로토콜은 세션 상태 지속성을 갖는 하이브리드 페이로드를 결합하고 있었으며, 대부분의 프로토콜은 여러 개의 미리 정의된 스키마를 지원했고, 두 개의 프로토콜은 런타임에 스키마를 협상하여 스키마 유연성으로의 흐름을 시사했다. 반면, 탈중앙화된 디스커버리는 여전히 드물었다. 분석은 단기적으로 에이전트-간 통신과 에이전트-컨텍스트(agent-to-context) 통신(도구 및 데이터)을 통합하는 프로토콜로의 수렴 압력이 있음을 시사한다. 그러나 장기적으로는 단일 프로토콜이 다양성, 효율성, 이식성을 동시에 극대화하기는 어려울 가능성이 크다. 이 분야는 연합형의 계층적 프로토콜 스택으로 발전할 가능성이 더 높다. 본 프레임워크는 프로토콜 선택을 안내하고, 프라이버시와 정책 집행 같은 미해결 연구 공백을 부각한다.
As large language models (LLMs) advance and multi-agent systems aim to overcome the limits of standalone agents, robust communication protocols are becoming essential infrastructure for distributed agent networks. Nonetheless, the fragmented protocol landscape presents a significant interoperability challenge. This study develops a technical taxonomy to classify and analyze LLM agent communication protocols. Following an established iterative method, we defined the taxonomy's purpose, meta-characteristic, and ending conditions, then performed five iterations, three empirical-to-conceptual and two conceptual-to-empirical, on nine actively maintained open-source protocols with demonstrable adoption. The taxonomy comprises five dimensions: counterparty, payload, interaction state, discovery mechanism, and schema flexibility. Classification reveals recurring architectural patterns: all sampled agent-to-agent protocols combine hybrid payloads with session-state persistence; most protocols support multiple predefined schemas, and two negotiate schemas at runtime, indicating a trend toward schema flexibility; decentralized discovery remains rare. Analysis suggests short-term convergence pressure toward protocols unifying agent-to-agent and agent-to-context (tool and data) communication. Long-term, however, no single protocol is likely to maximize versatility, efficiency, and portability simultaneously. The field will more likely evolve toward a federated, layered protocol stack. The framework guides protocol selection and highlights open research gaps such as privacy and policy enforcement.}
논문 링크
더 읽어보기
에이전트 모델에 대한 비평 / Critique of Agent Model
논문 소개
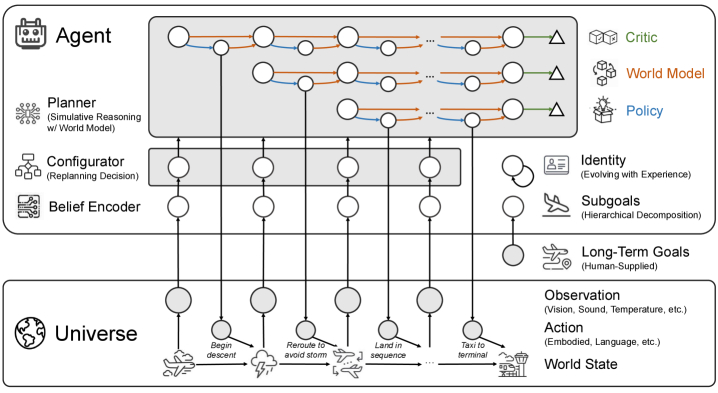
에이전트 모델에 대한 비판은 현대 인공지능(AI) 기술의 발전에 따른 다양한 우려를 심도 있게 다루고 있다. 특히, 대규모 언어 모델(LLM) 시스템이 "코딩 에이전트", "AI 공동 과학자" 등 다양한 역할을 수행할 수 있도록 설계되면서, 이러한 시스템이 실제로 자율적이고 독립적인 결정을 내릴 수 있는 에이전시를 갖추고 있는지에 대한 논의가 필요하다. 논문은 에이전시의 개념을 탐구하며, 진정한 에이전시가 어떻게 시스템 내부에 내재화되어야 하는지를 분석한다. 이를 위해 연구진은 AI 에이전트의 아키텍처를 목표, 정체성, 의사결정, 자기 조절, 학습이라는 다섯 가지 차원에서 평가하며, 각 차원의 중요성을 강조한다.
특히, 연구는 외부의 지지 구조에 의존하는 에이전틱 시스템과, 내부에 내재화된 능력을 바탕으로 자율적으로 작동하는 에이전티브 시스템 간의 경계를 명확히 한다. 이러한 분석을 바탕으로 제안된 목표-정체성-구성기(Goal-Identity-Configurator, GIC) 아키텍처는 특정한 목표를 계층적으로 분해하고, 정체성이 진화하며, 시뮬레이션적 추론을 통해 결정 과정을 개선하는 기능을 포함한다. GIC 아키텍처는 학습된 자기 조절 메커니즘과 자기 주도 학습을 통해 에이전트가 실제와 시뮬레이션된 경험을 모두 활용하여 성능을 향상시키도록 설계되었다.
이러한 접근은 에이전트가 다양한 상황에 적응하면서도 자율성을 유지할 수 있도록 하며, 동시에 인간의 감독 아래 안전하게 운영될 수 있는 가능성을 모색한다. 논문은 진정한 에이전시가 단순히 외부의 지원에 의존하는 것이 아니라, 시스템 내에서 내재화되어야 함을 강조하며, GIC 아키텍처가 이러한 특성을 갖춘 에이전트를 구축하는 데 중요한 기여를 할 것이라고 주장한다. 이 연구는 향후 AI 에이전트 모델의 설계와 구현 방향에 대한 중요한 통찰을 제공하며, 자율적인 시스템 개발에 있어 신뢰할 수 있는 기반을 제시한다.
초록(Abstract)
에이전트란 무엇인가? 에이전시란 무엇으로 구성되는가? 코딩 에이전트'', AI 공동 과학자'', 그리고 생산성을 높이겠다는 약속을 가진 기타 에이전틱" 도구들이 마케팅되면서, 동시에 AI가 인간의 통제를 벗어나 파괴적인 힘을 가진 기계 에이전시"로 작용할 것이라는 존재론적" 우려가 제기되고 있어, 시스템 구축과 두려움의 대상이 무엇인지 이해하기 위해서 자동화가 끝나는 지점과 에이전시가 시작되는 지점을 명확히 하는 것이 필수적이 되었다. 데카르트의 독립적 사고에 기반한 에이전시 개념과 과학 소설에서의 자율적 존재의 묘사를 바탕으로, 우리는 현재의 AI 에이전트 환경을 조사하고 목표, 정체성, 의사결정, 자기조절, 학습의 다섯 가지 차원에서 에이전트 아키텍처를 분석한다. 특히 우리는 진정한 에이전시가 외부 지지 구조를 통해 조립되는 것이 아니라, 시스템 자체 내에서 \emph{내재화}되어야 한다고 주장한다. 엔지니어링된 작업 흐름에 능력이 있는 \emph{에이전틱} 시스템과 사회적 상호작용을 포함한 능력이 내재적으로 발생하는 \emph{에이전티브} 시스템 간의 이 구분은 정해진 작업을 위해 설계된 시스템과 진정한 자율성으로 개방된 세계에서 작동할 수 있는 시스템 간의 경계를 정의한다. 이 분석을 바탕으로 우리는 계층적 목표 분해, 정체성 진화, 별도로 훈련된 세계 모델에 기반한 시뮬레이션 추론, 학습된 자기 조절, 실제 및 시뮬레이션 경험에서의 자기 주도 학습을 결합한 범용 에이전트 모델을 위한 목표-정체성-구성기(GIC) 아키텍처를 제안한다. 더욱이 우리는 더 큰 자율성과 에이전시"를 가진 에이전티브 시스템의 감사 가능성, 제어 가능성 및 안전성에 대한 통찰을 공유하지만, 여전히 인간의 감독 하에 있어야 한다.
What is an agent? What constitutes agency? With the rise of Large Language Model (LLM) systems marketed as
coding agents'',AI co-scientists'', and otheragentic" tools that promise to drive up productivity, and at the same time,existential" concerns such as AI escaping human control with destructive power under a speculativemachine agency" against humans, it has become essential to clarify where automation ends and agency begins, both for building capable systems and for understanding whether and what to fear. Drawing on Descartes' grounding of agency in independent thought, and on portrayals of autonomous beings in science fiction, we survey the current landscape of AI agents, and analyze agent architectures along five dimensions: goal, identity, decision-making, self-regulation, and learning. Specifically, we argue that genuine agency requires these structures to be \emph{internalized within the system itself} rather than assembled through external scaffolding. This distinction between \emph{agentic} systems, whose competence resides in engineered workflows, and \emph{agentive} systems, whose capabilities (including social interaction) arise endogenously, defines the boundary between systems designed for prescribed tasks, and those capable of operating in the open world with true autonomy. Building on this analysis, we propose the Goal-Identity-Configurator (GIC) architecture for a general-purpose agent model, combining hierarchical goal decomposition, identity evolution, simulative reasoning grounded in a separately trained world model, learned self-regulation, and self-directed learning from both real and simulated experience. Furthermore, we share insight on the auditability, controllability, and safety of agentive systems that possess greater autonomy andagency", but remain under human oversight.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! 텔레그램(Telegram)이나 Slack / Discord / Teams / Dooray / GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다.
로 보내드립니다! 텔레그램(Telegram)이나 Slack / Discord / Teams / Dooray / GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()