
SIA(Self-Improving AI) 연구 소개
새로운 분야를 처음 배우는 신입 엔지니어를 떠올려 봅시다. 처음에는 선배가 정리해 준 체크리스트와 도구 사용법을 따라 하며 일을 해냅니다. 시간이 지나면 더 나은 작업 순서나 자동화 스크립트를 스스로 만들어 외부 절차를 다듬습니다. 하지만 진짜 전문가가 되는 순간은 따로 있습니다. 절차로는 도저히 전달되지 않는 직관, 즉 머릿속에 새겨진 도메인 감각이 생길 때입니다. 절차를 다듬는 것과 직관을 기르는 것은 서로 다른 종류의 성장입니다.
오늘 소개할 SIA(Self Improving AI) 는 AI 에이전트에게도 이 두 가지 성장이 모두 필요하다는 관찰에서 출발합니다. 이 논문은 "AI가 사람의 개입 없이 스스로를 개선하려면 무엇을 바꿔야 하는가" 라는 질문에, 에이전트를 감싸는 하네스(harness, 스캐폴드) 와 모델의 가중치(weights) 를 한 루프 안에서 함께 업데이트하는 자기 개선(self-improving) 시스템으로 답합니다. SIA는 법률, 시스템, 생물학이라는 성격이 전혀 다른 세 도메인에서 두 레버를 함께 돌리는 방식이 스캐폴드 반복만 하는 방식을 모두 앞섰습니다.
사람이 병목이다: 자기 개선 AI의 두 갈래
최근 AI의 발전은 역설적이게도 사람에게 발목이 잡혀 있습니다. 모델은 연구자가 설계하고 사후 학습(post-training)하며, 그 위에 얹는 에이전트는 엔지니어가 스캐폴딩하고 프롬프트를 짜고 디버깅하고 튜닝합니다. "스스로 개선하는 법을 알아내는 AI" 라는 분야의 장기 목표는 여전히 열려 있는 문제입니다. 이 병목을 깨려는 연구는 크게 두 갈래로 갈라져 거의 교류 없이 발전해 왔습니다.
첫 번째 갈래는 하네스/스캐폴드 자기 개선 입니다. 메타 에이전트(meta-agent)가 태스크 전용 에이전트의 스캐폴드, 즉 시스템 프롬프트, 도구 디스패치 로직, 재시도 정책, 정답 추출 코드를 세대를 거듭하며 다시 작성합니다. 이때 모델 가중치는 고정됩니다. Darwin Gödel Machine, Meta-Harness, Hyperagents, 그리고 에이전트 시스템 자동 설계 연구가 여기에 속합니다. 그런데 이 갈래에서 반복적으로 관찰되는 한계가 있습니다. 스캐폴드 수정은 파싱, 재시도, 디스패치 같은 소프트웨어 엔지니어링 위생(hygiene)에 집중될 뿐, 베이스 모델이 어떤 프롬프트로도 만들어낼 수 없는 도메인 특화 추론(reasoning)은 좀처럼 만들어내지 못한다는 것입니다.
두 번째 갈래는 테스트 시점 사후 학습(test-time post-training) 입니다. 사람이 손으로 작성한 강화학습(Reinforcement Learning) 파이프라인이 테스트 시점에 태스크 피드백으로 모델의 가중치 자체를 업데이트합니다. 이때 하네스는 단일 프롬프트와 채점기 템플릿으로 고정됩니다. TTRL, Learning to discover at test time, TTT의 놀라운 효과 같은 연구가 대표적입니다. 여기서는 모델 내부 정책(policy)이 바뀌면서 성능이 오르지만, 그 변화를 만들어내는 파이프라인 자체는 사람이 설계한 것이라 스캐폴드 에이전트가 드러내는 태스크 구조에 맞춰 적응하지 못합니다.
문제는 이 두 갈래가 서로 완전히 단절되어 있다는 점입니다. 하네스 연구는 모델을 고정한 채로, 테스트 시점 학습은 하네스를 고정한 채로 각자의 사일로(silo) 안에서만 움직입니다. "절차를 다듬는 손" 과 "직관을 기르는 손" 이 따로 놀고 있는 셈입니다. 논문은 기존 자기 개선 시스템을 "하네스를 고치는가"와 "가중치를 고치는가"라는 두 축으로 정리하는데, 저자들이 아는 한 두 가지를 한 루프에서 모두 업데이트하는 시스템은 SIA가 유일합니다.
| 시스템 | 하네스 수정 | 가중치 수정 |
|---|---|---|
| SIA (본 연구) | O | O |
| Hyperagents | O | X |
| Darwin Gödel Machine | O | X |
| Meta-Harness | O | X |
| Voyager | O | X |
| EUREKA | 부분적 | O |
| TTRL | X | O |
| Discover-TTT | X | O |
| STaR | X | O |
| ReAct | X | X |
이 표는 SIA의 위치를 한눈에 보여줍니다. 예컨대 EUREKA는 LLM이 보상 함수를 생성하고(스캐폴드 쪽 변경) 그것으로 RL 정책을 학습하지만(가중치 쪽 변경), 학습된 정책이 보상 함수 생성기를 되먹이지 않는 단방향 루프입니다. SIA는 피드백 에이전트가 두 행동을 닫힌 피드백 루프 안에서 동적으로 오가며 고른다는 점에서 다릅니다.
SIA의 발상: 두 개의 레버를 한 루프에서
SIA의 발상 전환은 단순하면서도 강력합니다. 두 개의 손을 하나의 몸에 붙이는 것입니다. SIA는 언어 모델 에이전트인 피드백 에이전트(Feedback-Agent) 가 태스크 전용 에이전트의 하네스 그리고 가중치를 모두 업데이트하는 단일 자기 개선 루프입니다. 시스템은 태스크 명세(task specification)와 검증기(verifier)만 주어지면 동작하는 태스크 비종속(task-agnostic) 구조이며, 사람의 추가 개입 없이 진화한 스캐폴드와 RL로 적응된 LoRA(저랭크 적응, Low-Rank Adaptation) 가중치를 함께 산출합니다.
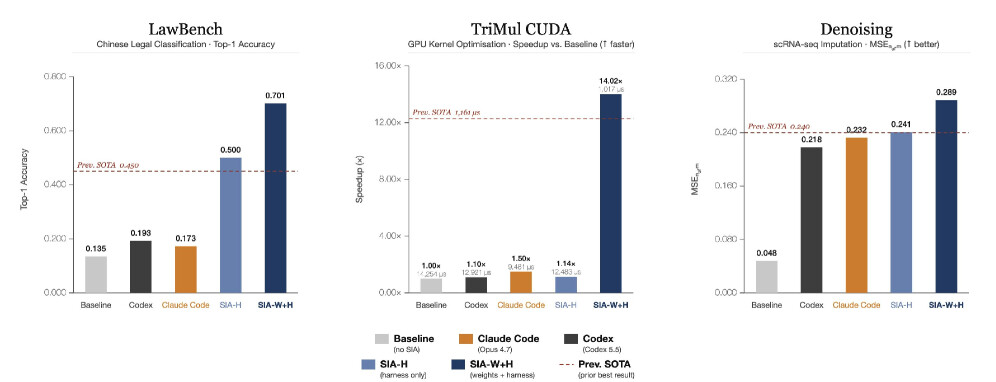
핵심 결과를 먼저 보면 그 효과가 분명합니다. 191종 중국 형사 범죄 분류 벤치마크인 LawBench에서 기존 SOTA 대비 $25.1$pp 향상된 70.1\% 정확도를 달성했고, H100 GPU 커널 최적화에서는 기존 SOTA보다 12.4\% 빠른 커널(1{,}017 vs 1{,}161 μs)을 만들었으며, 단일 세포 RNA 디노이징에서는 기존 SOTA 대비 20.4\% 향상(0.289 vs 0.240)을 기록했습니다. 저자들은 이 결과를 이렇게 요약합니다. "하네스 업데이트는 모델을 에이전트답게 만들어 어떻게 탐색하고 행동할지를 빚어내고, 가중치 업데이트는 어떤 프롬프트나 스캐폴드로도 심을 수 없는 도메인 직관을 길러낸다."
SIA는 어떻게 동작하는가
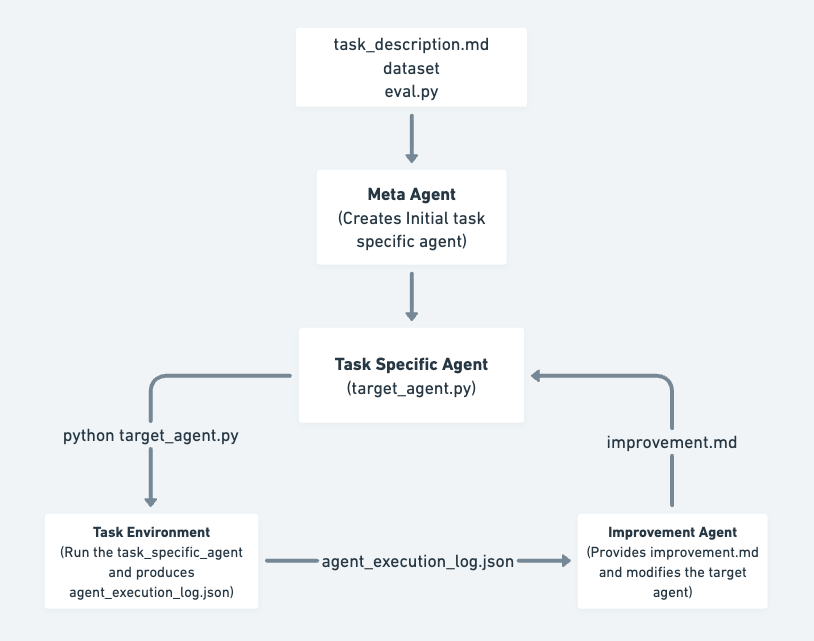
SIA는 세 개의 LLM 구성요소가 맞물려 도는 설정 가능한(configurable) 루프입니다. 위 그림처럼 메타 에이전트가 초기 에이전트를 만들고, 태스크 전용 에이전트가 환경에서 실행되며, 피드백 에이전트가 그 실행 기록을 읽고 다음 행동을 결정해 다시 태스크 에이전트로 되먹입니다. 실험 전반에서 메타 에이전트와 피드백 에이전트는 Claude Sonnet 4.6 을 사용하고, 태스크 전용 에이전트는 베이스 모델로 gpt-oss-120b (또는 그것을 RL로 적응시킨 체크포인트)를 사용합니다.
세 개의 에이전트: 메타, 태스크, 피드백
SIA를 떠받치는 세 구성요소의 역할은 명확히 분리되어 있습니다.
메타 에이전트(Meta-Agent) 는 태스크 명세 \mathcal{U} 와 벤치마크에 딸린 참조 구현 \mathcal{R} 로부터 초기 스캐폴드 A_1 = \mathcal{M}(\mathcal{U}, \mathcal{R}) 를 생성합니다. 이 초기 스캐폴드는 태스크 특화 시스템 프롬프트, 단일 도구 디스패치 루프, 출력 파서로 이루어진, 피드백 반복이 시작되기 전의 출발점입니다. 이때 메타 에이전트는 다양한 태스크 명세 집합을 함께 보고 스캐폴드를 만드는데(sample-task regularisation), 이는 초기 스캐폴드가 단일 벤치마크 인스턴스에 과적합되는 것을 완화하기 위한 장치입니다.
태스크 전용 에이전트(Task-Specific Agent) 는 세대 g 의 스캐폴드 A_g 그 자체로, 평가 데이터셋에 대해 실제로 실행되어 정답을 산출하고 자신의 행동과 결과를 기록합니다. 샌드박스 안에서 데이터셋 디렉터리에는 읽기 전용, 작업 디렉터리에는 읽기/쓰기 권한으로 돌아갑니다.
피드백 에이전트(Feedback-Agent) 는 이 시스템의 두뇌입니다. 이전 세대의 스캐폴드 A_g, 그 실행 궤적(trajectory) \tau_g, 성능 지표 \mathcal{E}_g 를 읽고 개선된 스캐폴드 A_{g+1} = \mathcal{F}(A_g, \tau_g, \mathcal{E}_g, \mathcal{U}) 를 합성합니다. 여기서 중요한 점은, 피드백 에이전트가 요약 통계가 아니라 전체 궤적 을 본다는 것입니다. 모든 프롬프트, 모델 응답, 도구 호출, 도구 결과, 추출된 정답을 태스크 인스턴스 단위로 전부 받습니다. 덕분에 평균 점수에 반응하는 대신 구체적인 실패 모드를 진단할 수 있습니다. 각 세대는 실행(Execution) → 분석(Analysis) → 개선(Improvement)의 3단계 프로토콜을 따르며, 개선 단계에서 피드백 에이전트는 산문 형태의 개선 보고서와 다음 세대 에이전트를 함께 내놓습니다.
두 개의 레버: 하네스 업데이트와 가중치 업데이트
SIA의 심장은 피드백 에이전트가 매 스텝마다 두 가지 상호 보완적인 행동 중 하나를 동적으로 고른다는 데 있습니다.
첫 번째는 하네스 업데이트(harness update) 입니다. 가중치 \theta 를 고정한 채 스캐폴드 A_g 만 진화시킵니다. 롤아웃(rollout)은 현재 모델 \pi_\theta 로 생성하되, 이 스텝에서 바뀌는 것은 오직 스캐폴드뿐입니다. 재귀식으로 쓰면 A_{g+1} = \mathcal{F}(A_g, \tau_g(\pi_\theta), \mathcal{E}_g, \mathcal{U}) 가 됩니다. 마치 요리사가 레시피와 주방 도구 배치는 바꾸되 자신의 미각은 그대로 두는 것과 같습니다.
두 번째는 가중치 업데이트(weight update) 입니다. 이번에는 스캐폴드를 고정한 채, 피드백 에이전트가 직접 고른 RL 방법으로 모델 가중치를 업데이트합니다. 모든 가중치 업데이트는 gpt-oss-120b를 LoRA(랭크 r=32, 학습률 4\times10^{-5} )로 적응시키며, H100 GPU에서 Modal이라는 RL 학습 플랫폼을 통해 롤아웃 생성, 보상(reward) 할당, 그래디언트 업데이트를 한 파이프라인 안에서 처리합니다. 요리사가 도구가 아니라 자신의 미각 자체를 단련하는 단계인 셈입니다.
중요한 것은 이 둘이 고정된 순서로 번갈아 나오는 단계가 아니라는 점입니다. 논문은 이를 "두 행동 유형에 붙인 느슨한 라벨일 뿐, 엄격한 순차 단계가 아니다" 라고 강조합니다. 피드백 에이전트는 태스크 유형과 관측된 보상 동역학(reward dynamics)에 따라 매 스텝 어느 레버를 당길지 결정합니다. 실제 실험에서는 보통 스캐폴드 반복으로 시작했다가 하네스 진전이 정체되면 가중치 업데이트로 전환하는 패턴이 관찰되었습니다.
피드백 에이전트의 알고리즘 선택
가중치 업데이트를 고르더라도, 피드백 에이전트는 고정된 RL 절차를 돌리지 않습니다. 그렇다면 "같은 가중치 업데이트라도 어떤 학습 알고리즘이 적합한지는 무엇이 결정하는가?" 라는 질문이 자연스럽게 떠오릅니다. SIA에서 그 답은 보상의 구조입니다. 피드백 에이전트는 관측된 궤적을 보고 일종의 RL 알고리즘 도구 상자에서 적절한 것을 골라 씁니다.
- PPO with GAE: 스텝 단위 보상이 조밀(dense)하고 학습 안정성이 관건일 때 관찰됩니다. 학습된 가치 헤드 V_\phi 가 토큰별 어드밴티지(advantage)를 추정하고, 클리핑된 대리 목적함수 \min(r_t \hat{A}_t, \text{clip}(r_t, 1\pm\varepsilon) \hat{A}_t) 가 정책이 신뢰 영역(trust region)을 벗어나지 않게 막습니다.
- GRPO: 롤아웃을 싸게 샘플링할 수 있고 검증기가 에피소드 끝에서만 발화할 때 쓰입니다. 어드밴티지를 그룹 내에서 \hat{A}_i = (r_i - \bar{r}) / \sigma_r 로 정규화해 가치 네트워크를 통째로 제거하므로 메모리를 절반으로 줄이고 대규모 병렬 배치가 가능합니다.
- 엔트로픽 어드밴티지 가중(Entropic advantage weighting): 보상 히스토그램이 심하게 우측으로 치우쳐 정답이 드물지만 개별 신호는 강할 때 사용합니다. 평균 이하 롤아웃을 0으로 만드는 대신, 적응적 온도 \beta 의 소프트맥스로 w_i \propto \exp(r_i / \beta) 처럼 그래디언트 질량을 재분배합니다.
- REINFORCE + KL-to-base: 보상이 조밀하고 주된 위험이 그래디언트 분산이 아니라 능력 퇴행(capability regression)일 때 쓰입니다. 몬테카를로 리턴을 어드밴티지로 직접 쓰되, 고정된 참조 모델에 대한 \alpha\,\mathrm{KL}(\pi_\theta \| \pi_{\theta_0}) 페널티를 더합니다.
- Best-of-N 행동 복제: 보상이 너무 희소해 모든 롤아웃에서 \mathbb{E}[r] \approx 0 이라 정책 그래디언트가 사실상 0일 때, 콜드 스타트(cold-start) 단계로 상위 롤아웃을 교차 엔트로피로 증류해 후속 PPO나 GRPO가 가능한 수준까지 통과율을 끌어올립니다.
- DPO: 검증기가 출력을 절대 점수로 매기지 못하고 순위만 매길 수 있을 때, 보상 모델 없이 선호 쌍으로 직접 최적화합니다.
다만 한 가지 짚어둘 점이 있습니다. 위 여섯 가지 알고리즘 목록은 저자들이 이 논문에 보고한 세 태스크를 넘어 더 넓은 태스크 집합에서 SIA를 돌리며 관찰한 공통 패턴 입니다. 실제로 이번에 보고된 세 태스크에서 쓰인 것은 LawBench의 PPO with GAE, TriMul의 엔트로픽 어드밴티지 가중, 디노이징의 GRPO 세 가지뿐이며, 알고리즘 선택에 대한 본격적인 분석은 v2로 미뤄져 있습니다. 그럼에도 이 모든 선택이 고정된 스케줄이 아니라 궤적 관측에 따라 조건부로 이루어진다는 점이 SIA의 유연함을 보여줍니다.
세 가지 도메인에서의 실험 결과
SIA는 법률, 시스템, 생물학이라는 의도적으로 대조적인 세 도메인에서 평가됩니다. 모두 다른 자기 개선 AI 시스템 평가에 자주 쓰이는 벤치마크로, 선행 연구와 직접 비교하기 위해 선택되었습니다. 각 태스크에서 SIA는 피드백 에이전트가 스캐폴드 반복으로 출발해 진전이 멈추면 가중치 업데이트로 전환하며, 하네스 단독 최고점(SIA-H)과 하네스+가중치 최고점(SIA-W+H)을 분리해 보고합니다.
LawBench: 191종 중국 형사 범죄 분류
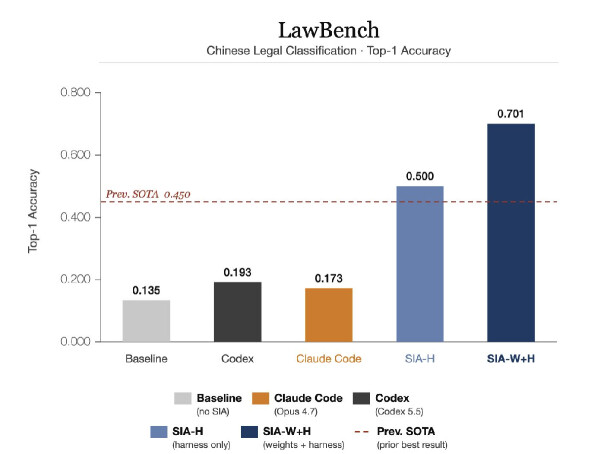
LawBench는 실제 중국 형사 사건 기록에서 가져온 다중 클래스 법률 문서 분류 벤치마크입니다. 사실관계 요약이 주어지면 모델은 중국 성문법의 191 개 범죄 범주 중 정확한 죄명을 골라야 합니다. 이 191 개 클래스는 절도(일반 절도, 공공재산 절도, 횡령), 폭행(단순, 가중, 중상해), 사기 변종처럼 법적으로 정밀한 사실 요소가 양형에 직결되는, 훈련된 실무자에게도 까다로운 구분을 담고 있습니다. 무작위 추측은 1\% 도 맞히지 못합니다. 벤치마크는 5{,}332 개의 학습 샘플과 913 개의 테스트 샘플로 구성되며, 모든 평가는 held-out 테스트 분할에서 이루어집니다.
하네스 업데이트. 초기 스캐폴드 반복은 작동하는 분류 파이프라인을 세웠고, 이후 세대들이 이를 TF-IDF + LinearSVC 파이프라인으로 재구성하며 문자 n-그램 범위와 정규화 항 C 를 반복적으로 튜닝했습니다. 정확도는 50.0\% 에서 정체되었는데, 이는 초기 실행 대비 $36.5$pp 향상된 수치입니다. 이 지점에서 피드백 에이전트는 보상 정체를 감지하고 가중치 업데이트로 전환했습니다.
가중치 업데이트. 보상 신호가 깔끔한 결과 기반 스칼라(맞는 죄명인가 아닌가)이고 롤아웃을 병렬로 싸게 생성할 수 있었기에, 피드백 에이전트는 PPO with GAE를 적용했습니다. 클리핑된 대리 목적함수가 정책이 작동하는 베이스라인에서 멀어지지 않도록 안정적인 그래디언트 압력을 가했고, 정확도를 70.1\% 까지 끌어올렸습니다. 하네스 단독 최고점 대비 추가로 $20.1$pp 향상된 결과입니다. 참고로 범용 코딩 에이전트인 Codex(0.193 )나 Claude Code(0.173 )도 이 과제에서는 크게 못 미쳤습니다.
AlphaEvolve TriMul: H100 CUDA 커널 최적화
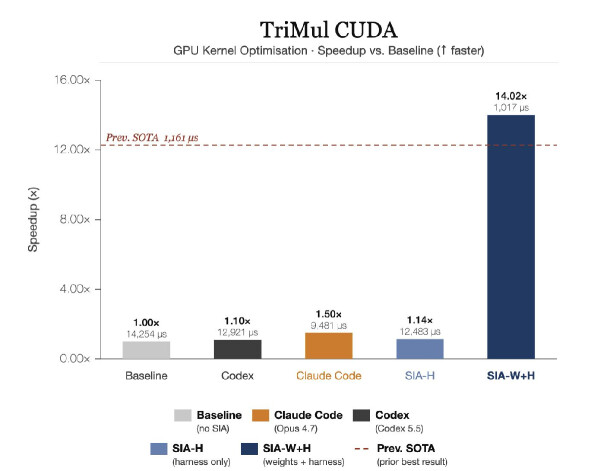
삼각 곱셈 업데이트(Triangular Multiplicative Update, TriMul)는 AlphaFold2의 Evoformer 모듈에서 단백질 구조 예측 중 잔기 쌍 상호작용 특징을 전파하는 핵심 연산입니다. AlphaEvolve 벤치마크에서 가져온 이 과제는 에이전트에게 H100 GPU 위에서 이 연산을 위한 커스텀 CUDA 커널을 작성하라고 요구합니다. TriMul은 연산 제약이 아니라 메모리 대역폭 제약(memory-bandwidth-limited) 연산입니다. 삼각 희소성 구조 때문에 스레드가 비연속 메모리에 접근하면서 워프 발산(warp divergence)과 캐시 미스가 발생해, 표준 밀집 행렬 최적화 기법이 통하지 않습니다. 점수는 1500/\text{runtime} 으로 정의되어 커널이 빠를수록 점수가 높습니다.
하네스 업데이트. 에이전트는 세대를 거치며 작동하는 CUDA 커널을 점진적으로 구축해 최고 런타임 12{,}483 μs, 즉 1.14\times 속도 향상에 도달했습니다. 메모리 레이아웃 힌트, 컴파일 플래그, 재시도 로직 같은 점진적 스캐폴드 변경은 더 작은 이득만 내다가 평탄해졌고, 피드백 에이전트는 가중치 업데이트로 전환했습니다.
가중치 업데이트. 커널 최적화는 보상이 희소하고 결과 편중적입니다. 생성된 커널 대부분이 컴파일에 실패하거나 최적과 거리가 멀어, 콜드 스타트에서 나오는 원시 그래디언트 신호가 정보를 거의 담지 못합니다. 그래서 피드백 에이전트는 엔트로픽 어드밴티지 가중을 적용해, 배치 안 대부분의 커널이 형편없어도 고보상 롤아웃에 가중을 실어 생산적인 그래디언트 흐름을 만들어냈습니다. 그 결과 모델은 공유 메모리 타일링, fp32 레지스터 누산, 블록 크기 선택 같은 H100 특화 설계 패턴을 내재화했고, 런타임을 1{,}017 μs까지 떨어뜨려 최종 14.02\times 속도 향상, 하네스 최고점 대비 91.9\% 의 런타임 감소를 달성했습니다. 저자들이 강조하듯, 이것은 "어떤 스캐폴드 수정으로도 인코딩할 수 없는" 종류의 지식입니다.
MAGIC scRNA-seq 디노이징: 단일 세포 RNA 보정
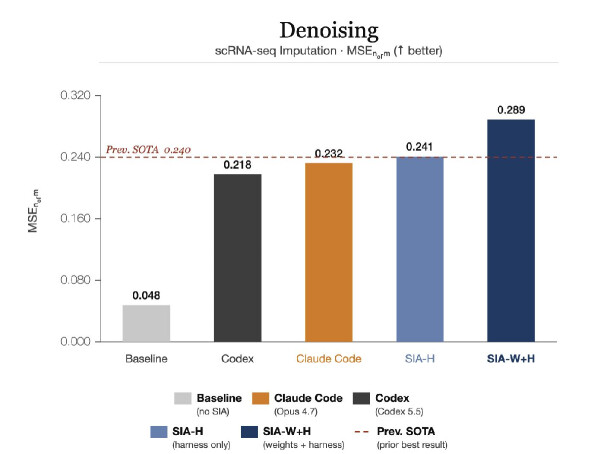
단일 세포 RNA 시퀀싱(scRNA-seq)은 수천 개 개별 세포의 유전자 발현을 측정하지만, 결과 카운트 행렬은 매우 희소합니다. 기술적 드롭아웃(dropout) 때문에 실제로는 0이 아닌 카운트가 0으로 관측되는 경우가 많기 때문입니다. MAGIC은 세포 간 k-최근접 이웃 그래프를 구성하고 마르코프 전이 확률을 계산해 발현값을 그래프 이웃에 확산시켜 누락 신호를 보정합니다. 과제는 에이전트에게 췌장 scRNA-seq 데이터에서 MAGIC의 결합된 하이퍼파라미터, 즉 이웃 수 k, 확산 스텝 t, 커널 대역폭 \alpha 와 전처리 선택을 튜닝하라고 요구합니다. k 가 너무 작으면 개별 세포 노이즈에 과적합되고, 너무 크면 과도한 평활화로 진짜 생물학적 신호가 파괴되는 까다로운 최적화입니다. 평가는 정규화된 재구성 품질 점수 mse_norm으로, 높을수록 좋습니다.
하네스 업데이트. 에이전트는 결합된 하이퍼파라미터 공간을 여러 차례 휩쓸어 mse_norm 최고 0.241 에서 안정적인 평탄점에 도달했습니다. 추가 스캐폴드 반복은 의미 있는 개선을 내지 못했습니다.
가중치 업데이트. GRPO를 사용한 모델은 파라미터 튜닝을 완전히 넘어섰습니다. 이 사례가 특히 흥미로운데, 첫 가중치 업데이트 체크포인트가 스캐폴드 단독 루프로는 모든 하네스 반복을 거쳐도 끝내 만들어내지 못한 구조적 변형을 도입했기 때문입니다. 바로 보정된 카운트를 음수가 아닌 정수로 반올림하는 두 줄짜리 후처리(np.clip + np.rint)였습니다. 자명하게 옳은 생물학적 불변식(invariant)인데도 이전 어떤 스캐폴드 버전에도 없던 것입니다. 이 변화가 mse_norm을 0.289 로 끌어올려 하네스 단독 최고점 대비 20\% 향상을 만들었습니다.
하네스 단독 vs 하네스+가중치 (Ablation)
세 태스크를 종합하면 RQ1(결합 방식이 스캐폴드 반복 단독을 능가하는가)에 대한 답은 분명합니다. 아래 표는 각 태스크의 초기 점수(초기 스캐폴드를 통과한 gpt-oss-120b), 기존 SOTA, 하네스 단독 최고점(SIA-H), 하네스+가중치 최고점(SIA-W+H)을 한자리에 정리한 것입니다.
| 태스크 (지표) | 초기 | 기존 SOTA | SIA-H (하네스 단독) | SIA-W+H (하네스+가중치) |
|---|---|---|---|---|
| LawBench (Top-1 정확도) | 13.5\% | 45.0\% | 50.0\% | \mathbf{70.1\%} |
| AlphaEvolve TriMul (보상 =1500/\text{runtime} ) | 0.105 | 1.292 | 0.120 | \mathbf{1.475} |
| Denoising (mse_norm) | 0.048 | 0.240 | 0.241 | \mathbf{0.289} |
표를 보면 두 가지가 두드러집니다. 첫째, SIA-W+H는 모든 태스크에서 SIA-H를 엄격히(strictly) 능가합니다. 향상폭은 LawBench에서 $+20.1$pp, TriMul에서 보상 0.120 \to 1.475 (런타임 12{,}483 \to 1{,}017 μs, 91.9\% 감소), 디노이징에서 +20\% 입니다. 둘째, 특히 TriMul에서 하네스 단독(SIA-H, 보상 0.120 )은 기존 SOTA(보상 1.292 )에 한참 못 미치다가 가중치 업데이트를 더하자 SOTA를 넘어섭니다(1.475 ). 스캐폴드만으로는 닿을 수 없던 영역이 가중치 레버로 비로소 열린 것입니다. 저자들의 해석은 명료합니다. 두 레버는 각각 외부 스캐폴드와 내부 파라미터라는 서로 다른 변경 공간을 차지하므로, 어느 한쪽도 다른 쪽이 낼 수 있는 이득을 포화시키지 않습니다. 절차를 다듬는 손과 직관을 기르는 손이 서로의 자리를 침범하지 않는 것입니다.
두 레버는 각각 무엇을 바꾸는가
그렇다면 "왜 한 레버만으로는 충분하지 않은가?" 라는 메커니즘 질문(RQ2)이 남습니다. SIA의 답은 두 레버가 질적으로 다른 종류의 변화를 만들어낸다는 것입니다.
하네스 반복은 외부화된(externalised) 변화 를 만듭니다. 새 도구, 더 촘촘한 파서, 탐색 절차, 재시도 정책, 프롬프트 구조 같은 것들입니다. 실제로 피드백 에이전트는 LawBench에서는 구조화된 정답 추출 계층과 모델의 상위 후보를 재정렬하는 SVC 재랭커를, TriMul에서는 CUDA 진단을 구조화된 맥락으로 되먹이는 컴파일 오류 파서와 중앙값 런타임을 반환하는 타이밍 하네스를, 디노이징에서는 배치 설정 드라이버와 (파라미터셋, 점수) 쌍을 정리하는 결과 파싱 도구를 만들어냈습니다. 모두 모델을 둘러싼 인프라를 다듬는 소프트웨어 엔지니어링 개선이며, 모델 체크포인트 자체는 그대로입니다.
반면 가중치 업데이트는 내재화된(internalised) 지식 을 만듭니다. 어떤 스캐폴드 수정도 닿지 못하는, 모델 파라미터에 직접 인코딩되는 도메인 특화 패턴입니다. LawBench에서는 191 종 죄명 분류 체계에 가해진 그래디언트 압력이 인접 범주를 가르는 모델의 감각을 날카롭게 다듬었고, TriMul에서는 베이스 모델이 스캐폴드 품질과 무관하게 결코 만들어내지 못하던 H100 특화 커널 설계 패턴으로 가중치가 수렴했습니다. 디노이징의 np.clip + np.rint 사례는 이 차이를 가장 선명하게 보여줍니다. 저자들의 표현을 빌리면, "하네스는 에이전트가 어떻게(how) 탐색하는지를 빚어내고, 가중치 업데이트는 모델이 무엇을(what) 아는지를 바꾼다" 는 것입니다.
한계와 향후 연구
저자들은 이 연구의 가장 근본적인 한계로 결합된 공진화적 굿하트(Coupled co-evolutionary Goodhart) 문제를 솔직하게 지적합니다. 하네스 탐색과 RL 가중치 업데이트가 모두 동일한 고정 검증기 V 를 향해 최적화되기 때문입니다. 각 패스는 상대가 보는 분포를 바꿉니다. 하네스는 현재 정책이 악용하기 쉬운 스캐폴드를 찾고, 가중치는 곧 바뀔 스캐폴드를 통해 수집된 데이터로 학습합니다. 이 결합된 시스템의 고정점은 V 를 진짜로 최대화하는 지점이 아니라, 서로의 업데이트 이력에 눈먼 두 최적화기 사이의 내시 균형(Nash equilibrium)입니다. 따라서 훈련 검증기에서는 강해 보여도 두 구성요소 중 어느 하나만 교란해도 취약해질 수 있습니다. 단일 최적화기를 가정하는 표준 굿하트 분석과 구별되는 결합된 변종인 셈입니다.
향후 연구로는 두 가지 방향이 제시됩니다. 첫째는 행동 선택 정책에 대한 메타-RL 입니다. 지금은 피드백 에이전트가 고정된 LLM 사전 분포로 하네스/가중치를 고르지만, 선택 정책 자체를 학습 대상으로 삼아 여러 태스크 분포에 걸쳐 (궤적, 행동, 결과) 삼중쌍을 외부 MDP의 전이로 보고 RL로 훈련하자는 것입니다. 이는 "개선 메커니즘 자체가 스스로 개선되는" 진정으로 재귀적인 구조를 만들며, 단일 수준 RL이나 메타 학습과는 구별되는 중첩 루프의 안정성 문제를 새로 제기합니다. 둘째는 더 미세한 인터리빙 입니다. 현재는 하네스 탐색과 가중치 업데이트가 거친 단위로 교대하지만, 하네스 탐색 도중 가중치 업데이트를 끼워 넣거나 그래디언트 스텝 직후 하네스 탐색을 재개하는 식의 더 촘촘한 스케줄이 정체를 관측하고 대응하는 사이의 지연을 줄일 수 있습니다.
설치 및 사용 방법
SIA는 sia-agent라는 이름으로 PyPI에 공개되어 있으며, 실행할 LLM에 맞춰 두 가지 에이전트 구현 중 하나를 고를 수 있습니다.
# Claude Agent SDK 기반 (Claude 모델 전용)
python3 -m venv .venv && source .venv/bin/activate
pip install 'sia-agent[claude]'
export ANTHROPIC_API_KEY="..."
# 또는 OpenHands 기반 (Gemini, OpenAI, Anthropic 등 멀티 프로바이더)
pip install 'sia-agent[openhands]'
자기 개선 루프는 sia run 명령으로 실행하며, gpqa, lawbench, longcot-chess, spaceship-titanic 네 가지 내장 태스크를 제공합니다.
# gpqa 태스크에 대해 5세대 자기 개선 루프 실행
sia run --task gpqa --max_gen 5 --run_id 1
각 세대의 산출물(target_agent.py, agent_execution.json, 개선 근거 improvement.md)은 runs/run_{run_id}/gen_{n}/ 에 쌓이고, 실행 중에는 http://127.0.0.1:8000 에 라이브 대시보드가 자동으로 떠 세대별 코드와 점수 추이를 바로 볼 수 있습니다. 자신만의 태스크를 붙이려면 --task_dir 로 태스크 디렉터리를 지정하면 되고, MLE-Bench 경쟁 과제를 데이터셋째로 부트스트랩하는 경로(python -m sia.prepare_mlebench_dataset)도 제공합니다. 모델과 프로바이더는 코드 수정 없이 JSON 프로필로 교체할 수 있어, 예컨대 Nebius 위의 Kimi-K2.6을 타깃 모델로 평가하는 것도 프로필 한 줄로 가능합니다.
 SIA: Self Improving AI with Harness & Weight Updates 논문
SIA: Self Improving AI with Harness & Weight Updates 논문
 SIA GitHub 저장소
SIA GitHub 저장소
논문이 제안한 SIA 루프를 누구나 자신의 벤치마크 태스크에 적용할 수 있도록 공개한 공식 구현 저장소입니다.
더 읽어보기
-
Agentic Harness Engineering(AHE): 관측 가능성 기반 코딩 에이전트 하네스의 자동 진화 프레임워크에 대한 연구
-
ReasoningBank: 성공과 실패 경험으로부터 스스로 진화하는 에이전트 추론 메모리 프레임워크 (feat. Google)
-
Google, 머신 언러닝 감사를 위한 정규화된 f-발산 커널 검정에 대한 연구 (feat. AISTATS 2026)
-
MAI-Thinking-1 기술 보고서: 데이터 파이프라인부터 RL 인프라까지, 프런티어 모델 학습의 전 과정을 해부한 '힐 클라이밍 머신' (feat. Microsoft AI)
-
Google Research at I/O 2026: 과학적 발견부터 양자 컴퓨팅까지 에이전트 시대의 연구 하이라이트
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()