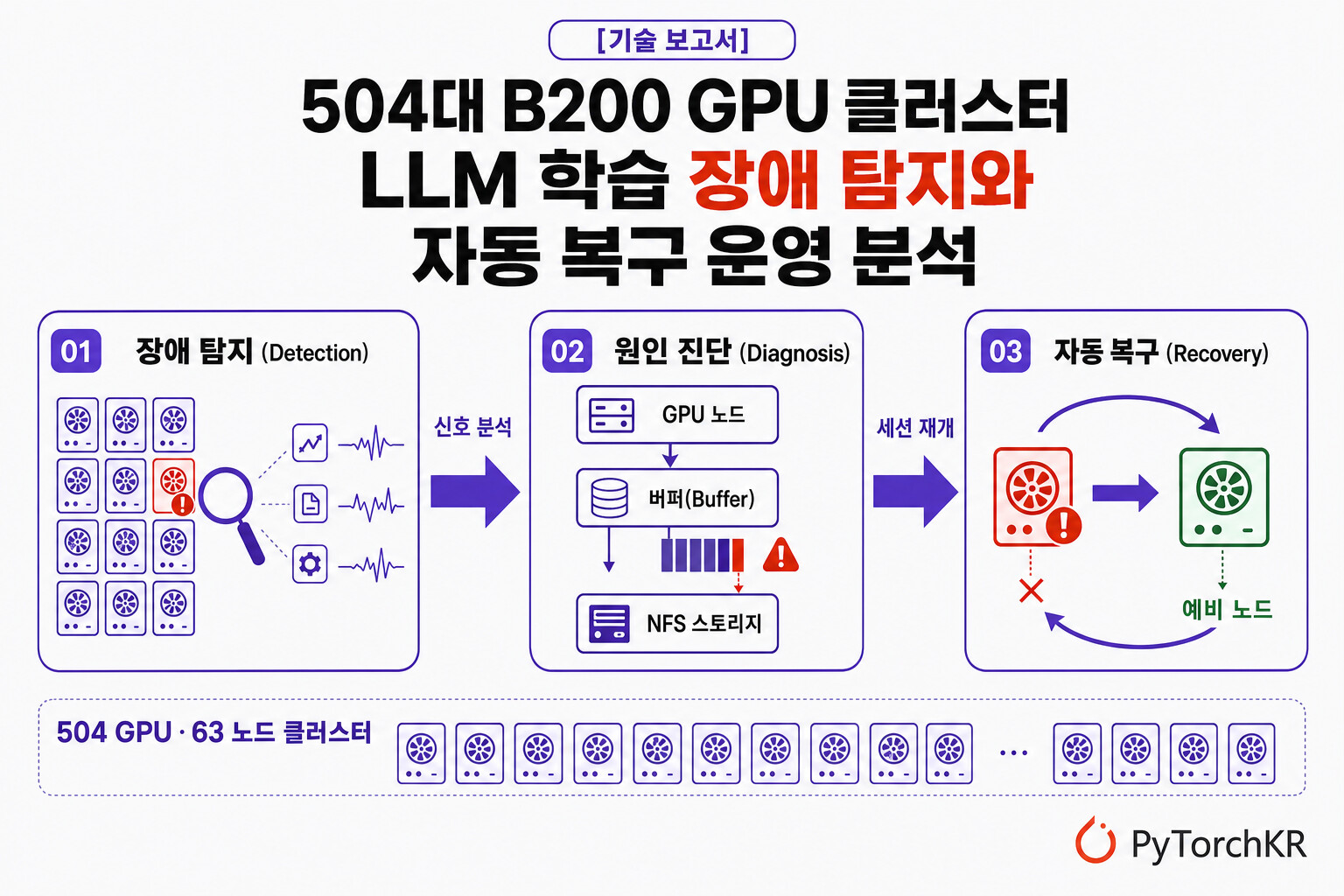
개요: 504대 규모 B200 GPU 클러스터의 LLM 학습 장애 탐지부터 자동 복구까지
수천 개의 GPU가 몇 주 동안 한 치의 오차도 없이 맞물려 돌아가야 하는 대규모 LLM 학습에서, 부품 하나의 고장은 더 이상 "예외"가 아니라 "일상"입니다. 이 기술 보고서는 504 개의 NVIDIA B200 GPU로 구성된 실제 프로덕션 클러스터를 55 일간 관측한 데이터를 바탕으로, LLM 사전학습 중에 발생하는 장애를 어떻게 탐지하고 진단하여 자동으로 복구하는지를 실증 분석한 보고서입니다.
대규모 학습을 한 번이라도 운영해 본 사람이라면, 모델 구조나 학습 알고리즘만큼이나 골치 아픈 것이 바로 "인프라가 멈추는 순간"이라는 사실을 잘 알고 있습니다. 학습 코드가 아무리 완벽해도, GPU 하나가 NVLink 오류로 떨어져 나가거나, 체크포인트를 저장하던 스토리지가 갑자기 느려지면, 60 개 노드가 한 몸처럼 동기화되어 돌아가던 학습 전체가 그 자리에서 멈춰 섭니다. 그런데도 정작 프로덕션 클러스터에서 이런 장애가 "어떤 신호를 남기고", "얼마나 자주 일어나며", "복구에 얼마나 걸리는지"를 정량적으로 공개한 자료는 의외로 드뭅니다.
이번에 소개하는 기술 문서(Technical Report)는 바로 그 빈 공간을 채웁니다. 래블업(Lablup)을 비롯해 SKT, Upstage, NVIDIA Korea, VAST Data 다섯 조직이 하나의 통합 모니터링 파이프라인을 공유하며 운영한 63 노드 B200 클러스터에서, 55 일간의 Prometheus 시계열 데이터와 224 회의 다중 노드 학습 작업 세션을 포함하는 73 일간의 운영 로그를 분석했습니다. 이 클러스터는 Upstage의 1{,}020 억 파라미터급 MoE 모델인 Solar Open 을 학습시킨 바로 그 환경이기도 합니다.
보고서 소개: 왜 "운영"이 곧 시스템 문제인가
10B 파라미터를 넘어서면, 학습은 분산 시스템 문제가 된다
모델 크기가 1{,}000 억 파라미터를 넘어서는 순간, 학습은 더 이상 하나의 알고리즘 작업이 아니라 수백 개의 GPU가 몇 주 동안 보조를 맞추는 장기 분산 시스템 작업이 됩니다. 이때 "기반 인프라는 안정적이다"라는 고전적인 가정은 더 이상 성립하지 않습니다.
실제로 같은 클러스터에서 진행된 Solar Open 학습은 다음과 같은 문제들을 겪었습니다. B200 도입 초기에는 Triton이 CUDA 13.0을 지원하지 않아 그래프 컴파일이 실패했고, FSDP2로 16 노드에서 60 노드로 확장하자 처리량(TPS)이 5{,}500 에서 4{,}267 로 떨어져 HSDP로 반복 튜닝해야 했습니다. 또한 I/O 락 경합 때문에 학습 초기화에만 8 시간 넘게 걸리는 데이터 로딩 병목도 발생했습니다. 이런 사례들은 대규모 학습이 중단, 재시작, 성능 변동을 당연히 포함하는 시스템 문제로 다뤄져야 함을 보여줍니다.
보고서는 대규모 AI 인프라가 직면하는 세 가지 도전 과제를 정리합니다:
-
낮은 자원 활용률: GPU는 비싸고 귀하지만, 정적 할당 정책과 보수적 운영 관행 탓에 실제 활용률은 낮은 수준에 머뭅니다. 마이크로소프트의 프로덕션 GPU 클러스터 분석에서 GPU 활용률 중앙값은 약 52\% 에 불과했습니다.
-
확장성과 안정성의 충돌: 클러스터 규모가 커질수록 하드웨어 장애, 네트워크 지연, 드라이버 오류의 빈도가 높아져 학습이 완전히 중단될 가능성이 커집니다. Meta는 Llama 3 의 $16$K GPU 사전학습 중 수백 건의 예기치 못한 중단을 겪었고, 대부분이 하드웨어 문제였다고 보고했습니다.
-
운영 복잡성: 프레임워크, 드라이버, 라이브러리 조합의 다양성이 환경 재현성을 해치고 실험 품질에 변동을 일으킵니다.
이러한 3가지 문제는 서로를 강화하기 때문에, 개별 대응이 아니라 인프라 차원의 통합적 접근이 필요합니다.
이 보고서가 던지는 질문: 탐지에서 복구까지
보고서의 제목인 "From Detection to Recovery"는 그 자체로 분석의 흐름을 압축합니다. 장애를 미리 탐지(Detection)할 수 있는가, 장애와 병목의 원인을 진단(Diagnosis)할 수 있는가, 그리고 장애가 일어난 뒤 얼마나 빠르고 안정적으로 복구(Recovery)할 수 있는가. 연구팀은 세 가지 정량 분석을 수행하여 네 가지 핵심 발견을 도출했습니다:
-
장애 전조 탐지: 751 개의 Prometheus 지표와 XID로 특정된 10 건의 GPU 장애를 통계 분석한 결과, 장애 유형 전반에 일관되게 지배적인 단일 지표는 없었습니다. 이는 여러 신호를 함께 보는 다중 신호 탐지(multi-signal detection) 전략의 필요성을 시사합니다.
-
체크포인트 I/O 풀스택 프로파일링: 523 개의 체크포인트 이벤트를 분석하여 GPU VRAM에서 NFS 서버까지의 저장과 로딩 경로를 추적했습니다. 재시작 로딩은 스토리지 최대 읽기 대역폭(700 GB/s)의 평균 21.5\%, 체크포인트 저장 버스트는 최대 쓰기 대역폭(250 GB/s)의 평균 16.0\% 에 머물렀습니다.
-
노드 제외 패턴 분석: 224 회의 다중 노드 학습 세션에서 63 개 노드 중 상위 3 개 노드가 전체 제외의 50\% 이상을 차지하는, 매우 집중된 분포가 나타났습니다.
-
자동 복구 심층 평가: 12 개의 자동 재시도 체인(총 73 회 시도)을 분석하여 체인 성공률 33.3\% 가 수동 복구의 12.5\% 보다 2.7\times 높음을 정량화했습니다.
대규모 학습에서 장애는 어떻게 나타나는가
장애는 예외가 아니라 구조적 특성이다
대규모 학습 환경에서 장애는 피할 수 없는 속성이며, 그 빈도는 클러스터 규모에 비례해 증가합니다. Meta는 최대 16{,}384 개의 H100 GPU로 Llama 3 405B 모델을 54 일간 사전학습하는 동안 419 건의 예기치 못한 중단을 겪었다고 보고했습니다. 한 추정에 따르면 현재의 GPU 고장률에서 100{,}000 개 규모의 클러스터는 약 30 분마다 한 번씩 장애를 경험하게 됩니다.
분산 학습에서는 소수 노드에서 시작된 결함이 클러스터 전체에 영향을 미칩니다. 다중 노드 학습은 워커들을 매 반복(iteration)마다 빡빡하게 동기화하므로, GPU 하나의 고장이나 통신 오류 한 건이 작업 전체를 중단시킬 수 있기 때문입니다. 이때 흔히 쓰이는 운영 대응이 노드 제외(node exclusion), 즉 특정 노드를 다중 노드 할당에서 빼는 것입니다. 노드 제외는 확인된 하드웨어 고장뿐 아니라 관측된 성능 저하, 그리고 운영자의 예방적 판단이 뒤섞인 결과이므로, 하드웨어 결함과 일대일로 대응하지는 않습니다.
보고서는 비교 기준점으로 바이트댄스(ByteDance)의 Minder 시스템이 약 1{,}500 노드(10{,}000 GPU 이상) 클러스터에서 정리한 장애 분류 체계를 인용합니다. 이 분류에서는 호스트 내부 하드웨어 장애가 55.8\% 로 가장 큰 비중을 차지하며, 그중에서도 ECC 오류가 38.9\% 로 가장 흔합니다.
| 분류 | 대표 장애 유형 | 비율 |
|---|---|---|
| 호스트 내부 HW | ECC 오류, PCIe 다운그레이드, NVLink 오류 등 | 55.8\% |
| 호스트 내부 SW | CUDA 런타임 오류, GPU 실행 오류, 체크포인트 I/O 오류 | 28.0\% |
| 호스트 간 NW | SSH 또는 VM 서비스 장애 등 | 6.0\% |
| 기타 | 분류되지 않은 이벤트 | 10.3\% |
이 클러스터는 시스템 전역 지표를 분석하는 Minder와 달리, NVIDIA GPU 드라이버가 dmesg 에 기록하는 XID 오류 코드 를 일차적 장애 탐지 수단으로 사용합니다. 각 XID 코드는 특정 장애 유형에 대응합니다(예: XID 79 = GPU 카드 탈락, XID 94 = ECC 오류, XID 145/149 = NVLink 오류). 두 시스템은 모니터링 방식과 인프라 구성이 다르므로 분류 범위가 완전히 겹치지는 않습니다. 예를 들어 이 클러스터는 HDFS가 아닌 NFS를 쓰고, PCIe 다운그레이드나 NIC 탈락처럼 XID를 발생시키지 않는 장애는 별도 모니터링이 필요해 이번 분석 범위에서 제외됩니다.
흥미롭게도, 55 일 관측 기간 동안 이 클러스터에 기록된 장애에서는 NVLink 오류(29.4\%)가 가장 흔했습니다. XID 코드가 NVLink 장애(XID 145/149)를 명시적으로 기록하는 반면, ECC 이벤트는 관측 기간이 짧아 표본이 작았던 점이 두 분포의 차이를 만들었습니다.
fail-stop과 fail-slow: 멈추는 고장과 느려지는 고장
위 분류는 GPU나 노드가 완전히 작동을 멈추는 fail-stop 장애를 강조합니다. 그러나 노드 제외 데이터는 두 번째 부류의 장애를 드러냅니다. gpu074, gpu119 같은 노드는 완전히 멈춘 것이 아니라 학습 속도가 떨어졌기 때문에 반복적으로 제외되었습니다. 이것이 바로 구성 요소가 작동은 하되 충분히 느려져 작업을 방해하는 fail-slow 장애입니다.
분산 학습은 매 반복마다 워커를 동기화하므로, 느린 노드 하나가 전체 학습을 지연시키는 낙오자(straggler) 문제를 일으킵니다. fail-slow는 명시적 오류 코드를 남기지 않는 경우가 많아 fail-stop보다 탐지하기가 훨씬 어렵습니다. 최근 연구들은 이 패턴이 광범위함을 보여줍니다. 한 연구는 10{,}000 개 이상 GPU 클러스터에서 대규모 학습 작업(512~1{,}024 GPU)의 59\% 가 fail-slow 낙오자를 겪었고 평균 작업 완료 지연이 34.59\% 에 달했다고 보고했으며, 다른 연구는 프로덕션 LLM 학습 작업의 42.5\% 가 낙오자의 영향을 받아 전체 GPU 시간의 10.4\% 를 낭비했다고 분석했습니다.
XID 코드는 곧 복구 전략이다
NVIDIA GPU는 하드웨어와 소프트웨어 오류를 XID 코드로 보고하며, 코드별로 근본적으로 다른 대응이 필요합니다. 따라서 코드를 정확히 분류하는 것이 장애 원인 규명의 전제 조건입니다. 이 분류는 Backend.AI의 장애 처리 전략에 그대로 반영됩니다. 하드웨어 조치가 필요한 XID(79, 119, 145, 149)는 노드 격리와 예비 노드로의 세션 이전을 유발하는 반면, 애플리케이션 수준 오류(31, 43, 94)는 해당 노드를 제외하지 않고 자동 재시도로 처리합니다. 이 "XID 코드를 복구 행동으로 매핑하는" 발상은 뒤에서 다룰 자동 복구 분석의 토대가 됩니다.
운영 인프라: 세션, 스케줄러, 그리고 다중 계층 모니터링
장애가 일상이라는 전제 위에서, 인프라는 두 가지 핵심 요구사항을 충족해야 합니다. 첫째는 탐지, 격리, 복구를 통한 장애 처리이고, 둘째는 세션 수준의 생명주기 관리입니다. 두 요구사항 모두 CPU가 아니라 GPU를 일차 스케줄링 자원으로 본다는 점을 전제합니다. 전통적인 CPU 중심 오케스트레이션은 이 가정을 하지 않습니다.
작업 세션 추상화: 컨테이너가 죽어도 학습은 살아남는다
딥러닝 학습은 옵티마이저 파라미터와 학습률 스케줄을 반복에 걸쳐 보존하는 상태 유지(stateful) 작업입니다. 장애가 발생하면 컨테이너는 파괴되지만, 학습 세션은 마지막 체크포인트까지의 모든 진행 상태를 유지해야 합니다. Backend.AI는 이 구분을 반영하여, 컨테이너 대신 스토리지 볼륨과 생명주기 상태를 한데 묶는 작업 세션(session) 을 핵심 관리 단위로 삼습니다.
이 구분은 자동 복구 분석에 직접 연결됩니다. 여기서 "재시작"은 처음부터 다시 시작하는 것이 아니라 체크포인트에서 이어받는 것을 뜻하므로, 복구 시간은 사실상 체크포인트 로딩 시간(중앙값 31 분)에 의해 결정됩니다.
Sokovan 스케줄러: 갱 스케줄링과 all-or-nothing
세션에 대한 GPU 할당은 Sokovan 스케줄러가 담당합니다. 노드 수준에서는 NUMA 인식 배치 정책으로 같은 NUMA 노드에서 GPU, CPU 코어, 메모리를 함께 할당하는데, 이렇게 자원을 같은 NUMA 노드에 모으면 NUMA 노드 간 메모리 접근을 피해 처리량을 최대 1.30\times 까지 높일 수 있습니다.
분산 학습에서 특히 중요한 것은 갱 스케줄링(gang scheduling) 입니다. 60 노드 학습 작업은 참여 노드를 모두 동시에 할당해야 하며, 부분 할당은 NCCL 초기화 중 교착 상태를 일으킵니다. Sokovan은 N 개 슬롯을 모두 할당하거나 요청 전체를 대기열에 넣는 all-or-nothing 방식으로, 일부만 할당된 작업이 나머지 슬롯을 기다리며 GPU를 놀리는 자원 단편화를 막습니다. 이 제약은 뒤에서 다룰 "60 노드 미만일 때 자동 재시도가 반복 실패하는" 구조적 원인과 직접 맞닿아 있습니다.
다중 계층 모니터링: GPU만 봐서는 전조를 놓친다
GPU 전용 모니터링(DCGM)만으로는 장애 전조를 포착하기 어렵습니다. NVIDIA DCGM은 GPU 온도, 전력, ECC 오류 같은 칩 수준 원격 계측을 제공하지만, XID 오류 코드는 GPU가 이미 멈춘 뒤에야 기록됩니다. 반면 시스템 수준 지표(TCP 소켓 할당, 커널 메모리, 인터럽트)와 스케줄러 수준 지표(비동기 작업 수, RPC 지연 시간)는 GPU 드라이버나 NCCL 통신 계층의 이상이 GPU 원격 계측에 나타나기 전에 표면화되는 경로를 제공합니다.
이 프로덕션 클러스터는 노드당 네 개의 Prometheus 호환 exporter를 돌리며 30 초 간격으로 지표를 수집합니다. 63 개 노드에 걸쳐 약 751 개의 고유 지표명이 수집되고, 이 중 분석에 사용된 활성 지표는 약 305 개였습니다. 55 일간 연속 수집한 원시 원격 계측 데이터는 압축 전 기준 약 126 GB에 달했으며, Prometheus 호환 시계열 데이터베이스인 VictoriaMetrics에 저장되었습니다.
조직의 경계를 넘어야 보이는 병목
이 보고서의 분석이 가능했던 토대는 다섯 조직이 공유한 통합 모니터링 파이프라인입니다. 애플리케이션, 스케줄러, 네트워크, 스토리지 계층의 상태를 하나의 공통 타임라인 위에서 조회하고 분석할 수 있었기에, 단일 지표 스트림만으로는 보이지 않던 원인들이 드러났습니다.
대표적인 사례가 운영 규모에서만 나타난 스토리지 I/O 병목 입니다. 60 노드 B200 구성으로 확장한 뒤, 몇 분이면 끝나야 할 VAST 스토리지로부터의 학습 초기화가 8 시간 넘게 걸리며 이론적 한계보다 훨씬 낮은 처리량에 머물렀습니다. 처음에는 어느 한 계층만 봐서는 원인을 설명할 수 없었습니다. 애플리케이션 로그에는 학습 초기화가 지연된다는 사실만, 스토리지 지표만으로는 어떤 접근 패턴이 문제인지 드러나지 않았습니다.
여러 계층의 지표를 같은 타임라인에서 상관 분석한 끝에, 병목은 애플리케이션이 의도한 큰 순차 I/O와 실제로 스토리지 계층에 도달한 잘게 쪼개진 작은 랜덤 I/O 사이의 간극 으로 좁혀졌습니다. 각 노드의 스토리지 NIC 수신율(약 4~10 GiB/s)은 따로 보면 평범했지만, 60 개 노드가 동시에 만들어 내는 종합 접근 패턴이 분산 메타데이터 서비스를 포화시킨 것입니다. 마치 창구 직원 한 명이 처리할 수 있는 손님은 충분한데, 60 개의 창구로 한꺼번에 잘게 나뉜 민원이 몰려들어 안내 데스크가 마비된 상황과 비슷합니다. 애플리케이션 측의 파일 샤딩(rank별로 분할된 Arrow 파일)과 스토리지 측의 비동기 삭제 및 readahead 튜닝을 결합한 결과, 초기화 시간은 8 시간 이상에서 8 분 미만으로 줄었습니다.
이 사례는 뒤따르는 분석의 방법론적 기준점을 제시합니다. 첫째, 2~4 노드 규모에서 관측한 성능 특성은 60 노드에서의 거동을 예측하지 못하므로, 소규모 사전 테스트는 구조적으로 불충분합니다. 둘째, 단일 팀의 고립된 모니터링은 이 규모에서 근본 원인을 규명하기에 역부족이며, 조직 간 공유 지표 파이프라인이 있어야 체계적 운영 분석이 가능해집니다.
첫 번째 분석: 장애 전조를 미리 탐지할 수 있는가
앞 사례가 장애가 드러난 뒤 원인을 규명한 이야기였다면, 이 절은 더 어려운 질문을 던집니다. 장애가 표면화되기 전에 이상을 탐지할 수 있을까요?
연구팀은 이벤트 수준의 장애 기록을 노드 \times 시점 수준으로 정제하여, 14 번의 클러스터 다운타임에 걸친 21 건의 장애를 식별했습니다. 이 중 XID 오류로 결함 노드와 발생 시각이 즉시 특정된 10 건을 분석 대상으로 삼았습니다. 나머지 11 건은 XID 기록이 없어 자동 위치 추적이 어려웠습니다.
핵심 아이디어는 단순하면서도 강력합니다. 60 개 노드가 동시에 같은 워크로드를 실행하므로, 이상 탐지를 "또래 분포로부터의 이탈"로 정의 할 수 있습니다. 즉 결함 노드의 지표가 나머지 59 개 건강한 노드의 분포에서 유의미하게 벗어나는지를 검정하는 것입니다.
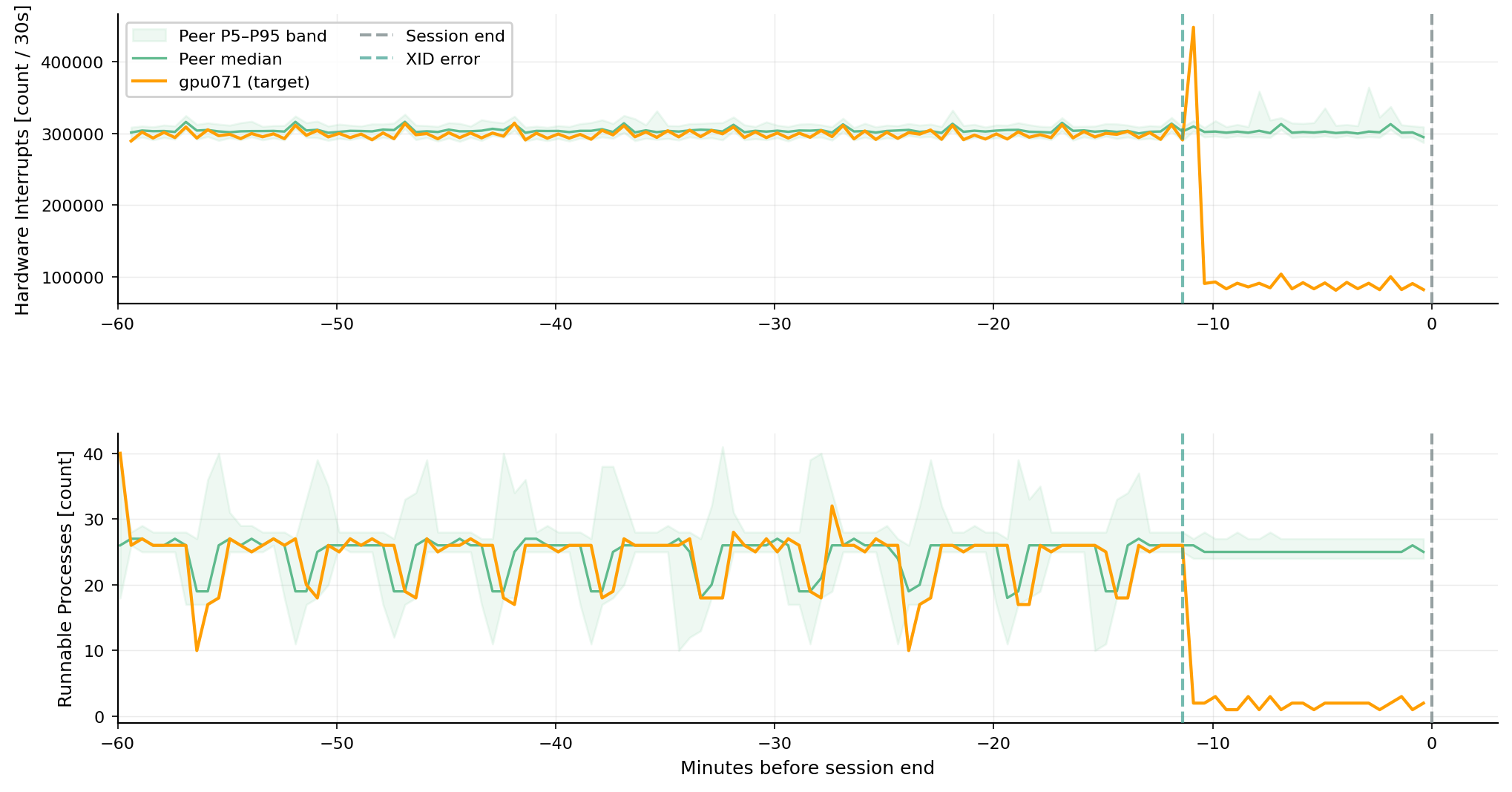
위 그림은 gpu071에서 발생한 NVLink + Bus Fault 사례(XID 145/149/79)를 보여줍니다. 위쪽 패널은 호스트 CPU가 처리한 인터럽트 수(node_intr_total)인데, 또래 노드들이 학습 내내 안정적인 반면 gpu071은 XID 시점에 약 $300$K에서 $70$K~$100$K로 급락합니다. 이는 NVLink 오류로 GPU가 버스에서 분리된 뒤 더 이상 인터럽트가 생성되지 않는 상황과 일치합니다. 아래쪽 패널인 실행 가능 프로세스 수(node_procs_running)는 XID 시점에 0 으로 떨어지는데, GPU가 멈추면서 학습 워커 프로세스 자체가 종료되었기 때문입니다.
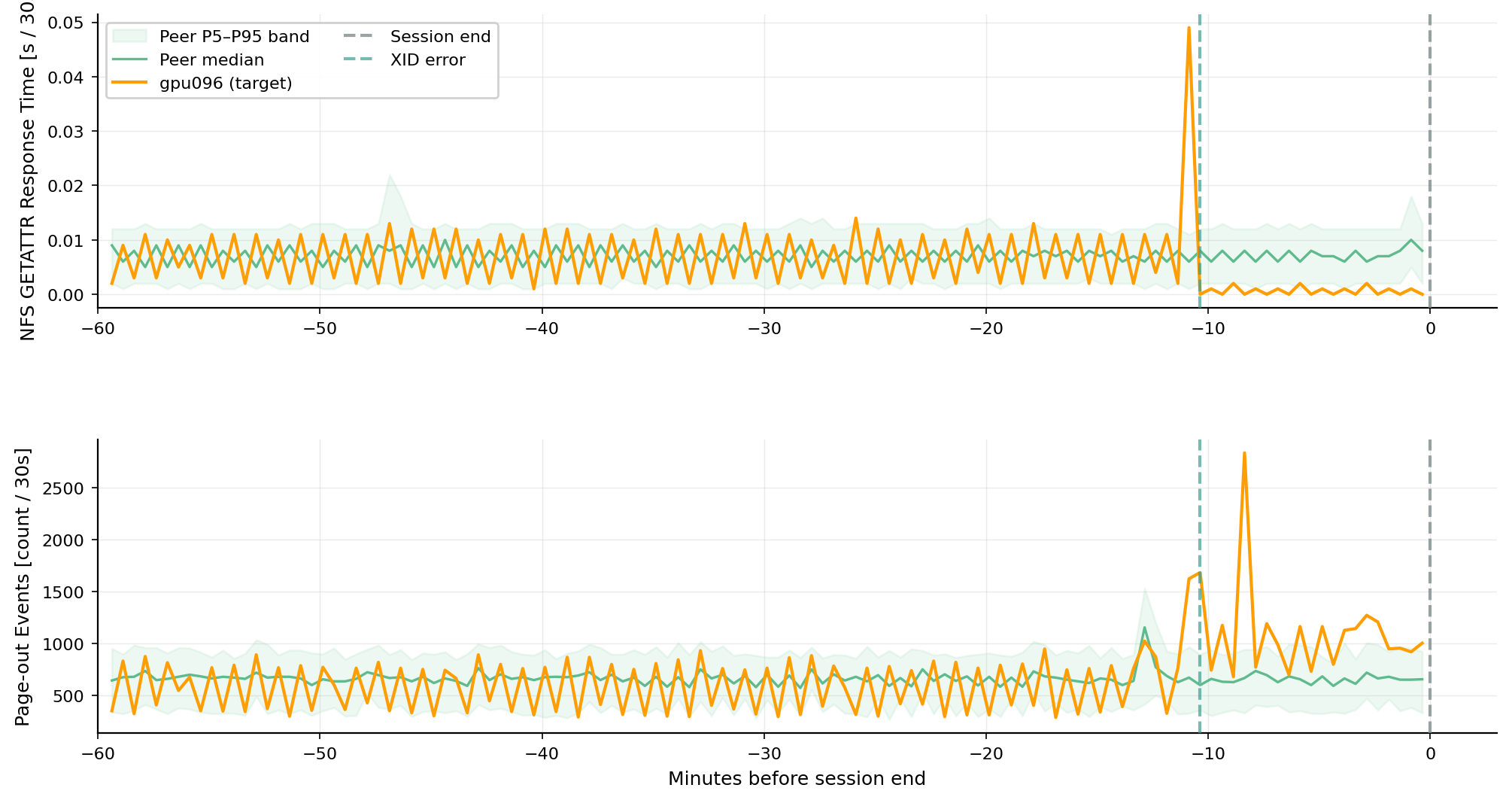
ECC 오류(XID 94)는 또 다른 신호를 남깁니다. gpu096 사례에서는 NFS GETATTR 요청의 응답 시간과 메모리에서 디스크로의 페이지 아웃(node_vmstat_pgpgout)이 XID 시점에 또래 대비 급증했습니다. 연구팀은 ECC 오류로 워커 프로세스가 비정상 종료된 직후, 파일 핸들 회수에 따른 NFS 재검증과 보유 중이던 더티 페이지의 라이트백 플러시 같은 커널 측 정리 작업이 두 지표를 동시에 끌어올렸을 것으로 추정합니다. 다만 정확한 인과 메커니즘은 이 데이터만으로는 단정할 수 없다고 솔직하게 밝힙니다.
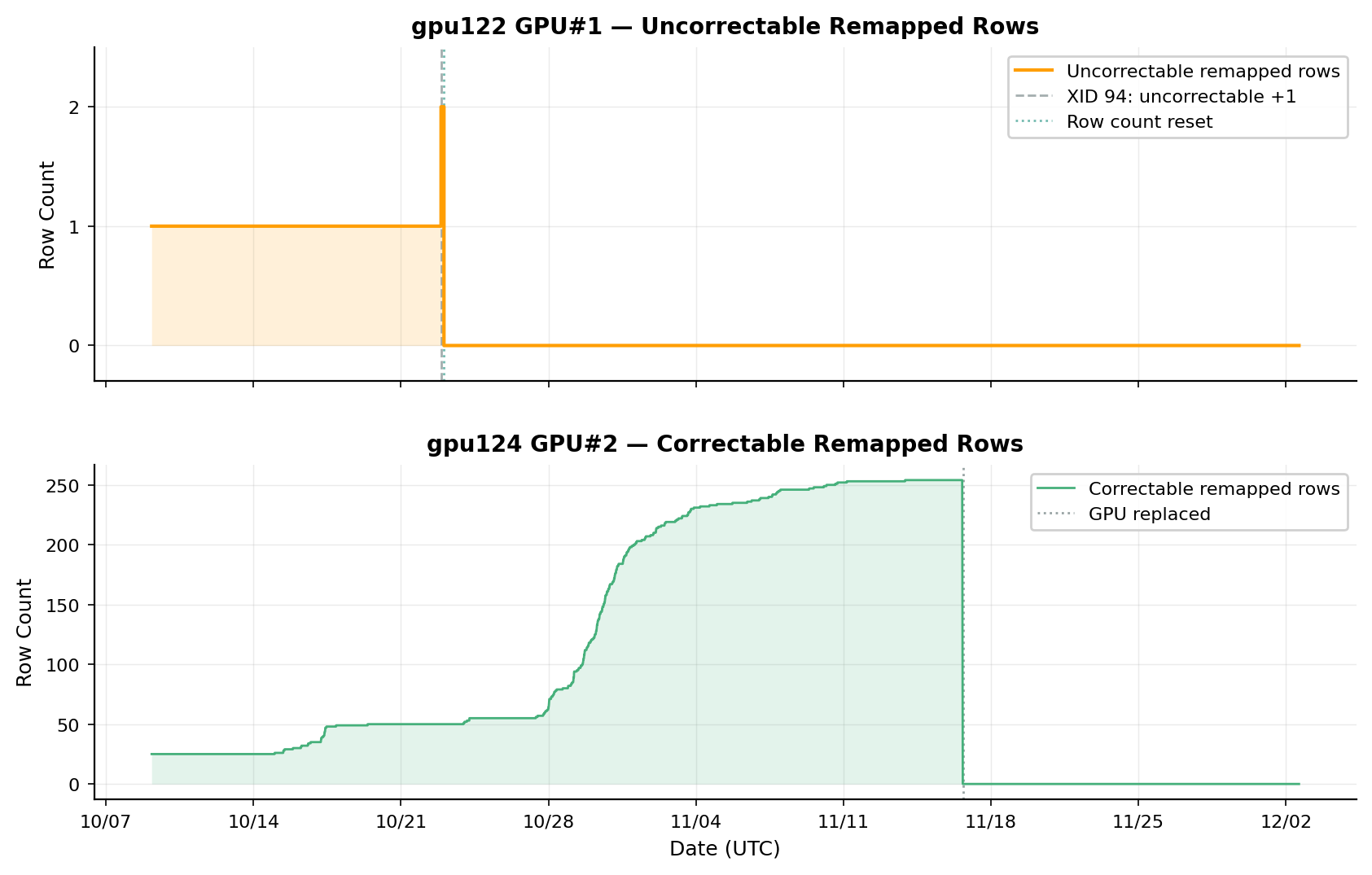
특히 흥미로운 것은 ECC 메모리의 행 재매핑(row remapping) 추세입니다. GPU 메모리에서 ECC 오류가 발생하면 결함 행이 예비 행으로 재매핑되는데, gpu124의 교정 가능(correctable) 재매핑은 55 일에 걸쳐 천천히 쌓이다가 10 월 말부터 일주일 만에 200 을 넘어 254 행에 도달했습니다. 이 기간에 XID 오류는 한 건도 발생하지 않았지만, GPU는 결국 호스트가 더 이상 인식하지 못해 교체되었습니다. NVIDIA는 교정 가능 오류를 무시해도 된다고 안내하지만, 빠르게 증가하는 추세 자체가 진행 중인 메모리 열화의 신호일 수 있다 는 점에서 모니터링의 가치가 드러나는 대목입니다.
같은 클러스터의 gpu122는 정반대 양상을 보였습니다. 교정 불가능(uncorrectable) 재매핑이 늘어난 시점에 곧바로 XID 94(ECC 오류)가 발생해 GPU가 멈췄는데, 뱅크당 교정 불가능 재매핑이 8 개에 이르면 ROW_REMAP_FAILURE 플래그가 떠 GPU 교체가 필요해지기 때문입니다. 같은 행 재매핑 지표라도 교정 가능/불가능 여부에 따라 한쪽은 느린 열화 추세로, 다른 한쪽은 즉각적인 정지로 갈린다는 점이 흥미롭습니다.
10 개 사례 전반에서, 모든 장애 유형에 일관되게 지배적인 단일 전조 지표는 없었습니다. 같은 XID 범주 안에서도, 심지어 같은 노드에서 재발한 경우에도 가장 강한 신호가 달랐습니다. 따라서 연구팀은 단일 지표에 의존하는 대신 다중 신호 전략(multi-signal strategy) 을 채택하며, XID 발생 이전 탐지율을 높이기 위해 다변량 시계열 패턴을 학습하는 후속 ML 모델링을 진행 중이라고 밝힙니다.
한 가지 솔직한 한계도 함께 짚습니다. 이 클러스터의 많은 장애에서 신호는 점진적으로 악화되지 않고 XID 시점에 급작스럽게 나타났으며, 이 급작스러운 발현(abrupt onset)이야말로 XID 이전 탐지를 어렵게 만드는 가장 큰 장벽입니다. 천천히 쌓이는 gpu124의 행 재매핑 같은 사례가 오히려 예외에 가깝습니다. 후속 ML 모델링이 노리는 지점도 바로 이 "전조가 거의 없는 장애"의 탐지율을 끌어올리는 것입니다.
두 번째 분석: 체크포인트 I/O는 어디서 시간을 잡아먹는가
체크포인트의 거동은 장애 시점에 잃는 진행분과 학습 재개에 필요한 시간을 동시에 결정합니다. 그렇다면 이 클러스터에서 체크포인트는 실제로 어떻게 동작하고, 병목은 어디에 있을까요?
학습은 세 단계로 나뉜다
연구팀은 GPU 활용률과 NFS I/O 패턴을 기준으로 시계열을 세 가지 학습 단계로 나눴습니다. 체크포인트를 저장하는 Save(종합 NFS 쓰기 >20 GB/s), 체크포인트와 데이터를 읽어 들이는 Load(GPU 활용률 <50\% 이면서 종합 NFS 읽기 >2 GB/s), 그리고 나머지 구간인 Training 입니다.
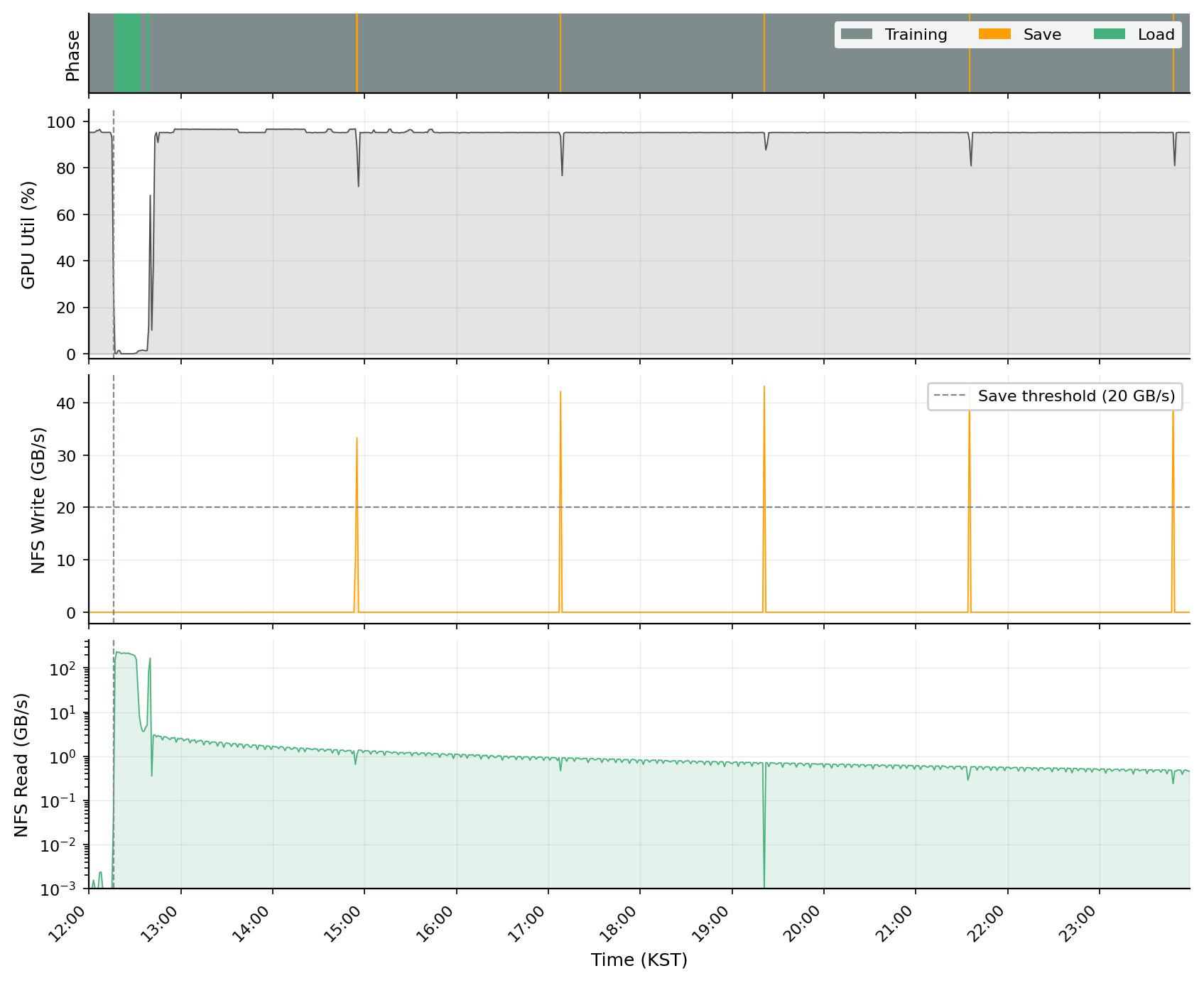
안정적인 학습 중에는 GPU 활용률이 99\% 이상으로 유지되지만, 약 2 시간 13 분 간격으로 짧은 하락이 관측됩니다. 이 하락은 NFS 쓰기 급증과 정확히 동기화되어 있어, 체크포인트 저장이 GPU 연산을 잠시 멈추게 한다 는 사실을 보여줍니다. 한편 세션 시작 시점에는 체크포인트와 학습 데이터 로딩 때문에 NFS 읽기가 종합 약 230 GB/s로 치솟고, 노드당 약 200 GB가 약 25 분에 걸쳐 페이지 캐시에 적재됩니다. 그 뒤로는 모든 데이터 접근이 페이지 캐시에서 처리되어 NFS 네트워크 트래픽이 사실상 0 으로 수렴합니다.
55 일간 NFS 쓰기 급증을 기준으로 자동 탐지된 체크포인트 이벤트는 총 523 개였습니다. 체크포인트 주기는 학습 구성에 따라 체계적으로 달라졌습니다. 시퀀스 길이 $4$K 사전학습 단계는 중앙값 2.23 시간, $32$K 컨텍스트 확장 단계는 3.32 시간, $100$K 단계는 1.36 시간이었습니다. 이 기간 NFS 스토리지 사용량은 약 450 TB에서 963 TB로 약 510 TB 증가했으며, 전체 용량 약 2{,}252 TB 대비 활용률은 20\% 에서 43\% 로 올라갔습니다.
체크포인트는 GPU에서 NFS까지 어떻게 흐르는가
체크포인트 저장과 로딩은 서로 정반대 방향의 데이터 경로를 따릅니다. 저장 시에는 GPU VRAM의 모델과 옵티마이저 상태가 CPU 측 스테이징 버퍼로 복사된 뒤 write() 호출과 커널 라이트백을 거쳐 NFS WRITE RPC로 스토리지에 기록됩니다. 30 초 모니터링 단위에서는 GPU 활용률 하락, 스테이징 버퍼 사용량 증가, 더티 페이지와 라이트백 증가, NFS 쓰기 트래픽 증가, 전송 계층 backlog 증가가 순서대로 관측됩니다.
이 스테이징 버퍼는 /dev/shm 에 학습 시작 시 미리 할당되어 저장마다 재사용됩니다. 60 노드는 두 그룹으로 나뉘는데, 48 개 노드는 약 48 GB, 12 개 노드는 약 9 GB의 /dev/shm 을 쓰고, 노드당 NFS 쓰기량도 각각 약 26 GB와 2 GB로 같은 패턴을 따릅니다. 결정적으로 write() 시스템 콜의 누적량과 NFS 서버가 수신한 양이 노드당 20.55 GB(클러스터 종합 1{,}295 GB)로 정확히 일치해, 저장된 모든 데이터가 write() 경로를 통과했음을 확인할 수 있습니다. 로딩은 이 경로를 거꾸로 거슬러 올라가는데, 일부 구간에서는 read() 양이 NFS 읽기 증가분보다 커서 이전 세션이 남긴 페이지 캐시가 재사용 되었음을 보여줍니다. 결국 재시작 로딩 시간은 네트워크 전송만이 아니라 페이지 캐시 적재, NFS/RPC 요청 처리, 학습 프레임워크의 체크포인트 복원 단계가 함께 결정합니다.
체크포인트 주기는 비용의 트레이드오프다
체크포인트 주기는 저장 오버헤드와 장애 시 잃는 진행분 사이의 직접적인 트레이드오프를 설정합니다. 자주 저장하면 잃는 작업은 줄지만 저장 오버헤드가 늘고, 주기가 길면 오버헤드는 줄지만 버려지는 학습량이 늘어납니다. 이 트레이드오프의 표준 기준점인 Young/Daly 모델 은 최적 주기를 T_{\text{opt}} = \sqrt{2\delta M} 로 제시합니다. 여기서 \delta 는 저장 소요 시간, M 은 평균 고장 간격(MTBF)입니다.
비정상 종료된 23 개의 W&B 실행을 분석한 결과, 장애당 평균 손실 시간은 0.98 시간, 총 손실은 약 22.6 시간이었습니다. MTBF는 24 개 실행의 총 학습 시간 1{,}294 시간을 23 건의 비정상 종료로 나눈 56.2 시간으로 추정되었습니다. 저장 소요 시간 \delta 는 단계별로 18~31.7 초로 매우 작아서, 주기를 짧게 가져가는 비용이 낮습니다. 실제로 $4$K와 $32$K 단계에서는 실제 주기가 이론적 최적의 약 3\times 였던 반면, $100$K 단계에서는 주기를 81.5 분(최적의 1.4\times)으로 줄여 총비용 1.82\% 를 이론적 최소값 1.72\% 에 0.10 퍼센트포인트 차이까지 근접시켰습니다.
재시작 로딩은 네트워크만의 문제가 아니다
재시작 로딩 시간은 복구 지연을 결정하는 일차적 요인입니다. 1 시간 이상 지속된 20 개 세션을 측정한 결과, 평균 로딩 시간은 33 분, 중앙값은 31 분이었습니다. 이 20 건의 재시작 로딩에서 평균 NFS 읽기 처리량은 150.8 GB/s로, 스토리지 최대 읽기 대역폭 700 GB/s의 21.5\% 에 해당합니다. 이벤트별 최대 읽기 처리량의 평균도 223.8 GB/s, 즉 32.0\% 에 그쳤습니다.
여기서 중요한 운영적 함의가 나옵니다. 관측된 읽기 처리량이 스토리지 최대 대역폭에 한참 못 미치므로, 네트워크만 200 Gbps에서 400 Gbps RoCE로 업그레이드해도 재시작 로딩 시간이 크게 줄어들 가능성은 낮다 는 것입니다. 그렇다면 시간은 어디서 새는 걸까요?
진짜 병목은 NFS/RPC 요청 대기에 있다
NFS 요청 시간은 대기 시간(queue time)과 응답 시간(response time)으로 나눌 수 있습니다. 대기 시간은 요청이 전송되거나 처리되기 전에 클라이언트나 전송 경로에서 기다리는 시간이고, 응답 시간은 요청을 보낸 뒤 응답을 받기까지의 시간입니다. 연구팀은 406 개의 체크포인트 저장 버스트와 20 개의 재시작 로딩 이벤트에서 요청당 시간을 산출했습니다.
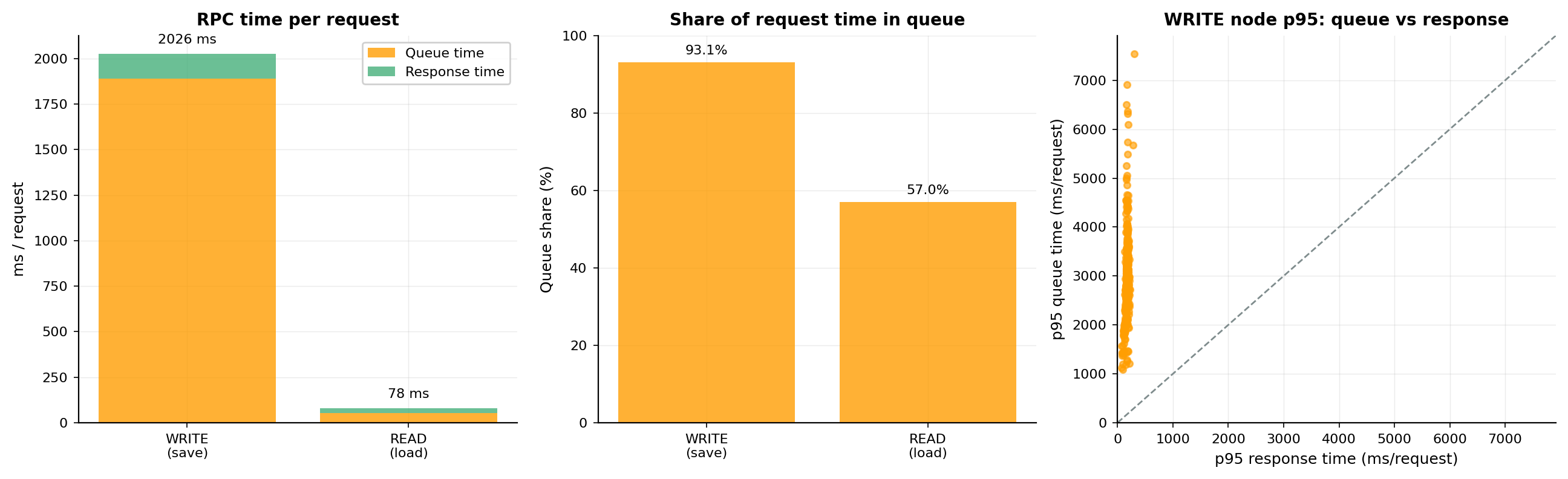
결과는 명확했습니다. 쓰기(WRITE) 요청은 평균 2.03 초가 걸렸는데, 이 중 1.89 초(93.1\%)가 대기 시간이고 응답 시간은 136 ms에 불과했습니다. 평균 WRITE RPC 크기는 요청당 1{,}021 KB로 NFS의 wsize 에 가까웠고, 메타데이터 연산은 평균 0.85\% 에 그쳤습니다. 다시 말해 저장 경로의 지배적 패턴은 작은 WRITE 요청이나 메타데이터 연산의 증가가 아니라, 많은 노드가 큰 WRITE RPC를 동시에 쏟아낸 뒤 쌓이는 대기 시간 이었습니다. 실제로 406 개 저장 버스트의 87.9\% 에서 최소 50 개 노드가 동시에 WRITE를 발행했고, 노드 p95 기준 WRITE 대기 시간은 요청당 평균 3{,}020 ms로 응답 시간 166 ms를 압도했습니다.
로딩 경로도 같은 대기 지배 패턴을 보이되 강도는 약합니다. 읽기(READ) 요청은 요청당 평균 440 KB였고, 평균 요청 시간 78.2 ms 중 54.2 ms(57.0\%)가 대기 시간이었습니다. 쓰기의 93.1\% 보다는 낮지만 여전히 응답 시간보다 대기 시간이 큽니다. 또한 20 건의 재시작 로딩 모두에서 로딩 후반부에 처리량이 떨어지는 구간이 나타났는데, READ 바이트와 요청 수가 줄면서도 대기 시간이 backlog와 함께 오르지는 않는 양상이라 복원 막바지가 남은 체크포인트 샤드와 일부 rank의 잔여 작업 때문에 지연 되는 것과 일치합니다.
상대적으로 보면, 30 초 평균 처리량은 저장 시 40.1 GB/s(16.0\%), 로딩 시 150.8 GB/s(21.5\%)였습니다. 결론적으로 체크포인트 I/O 경로에서 가장 먼저 들여다봐야 할 신호는 NFS/RPC 요청 대기와 전송 계층 backlog 라는 것입니다. 다만 이 데이터만으로는 대기 시간이 클라이언트 측 동시성 제한, nconnect 설정, 전송 계층 backlog, 백엔드 쓰기 처리 중 어디서 형성되는지 분리할 수 없으며, 이는 향후 과제로 남습니다.
세 번째 분석: 장애는 특정 노드에 집중되는가
이 절은 장애 대응을 두 가지 상호 보완적 관점에서 분석합니다. 먼저 장애가 어디서 재발하는지(노드 제외 패턴), 그다음 장애가 일어났을 때 시스템이 얼마나 효과적으로 복구하는지(자동 재시도)입니다.
상위 3개 노드가 전체 제외의 절반을 차지한다
노드 제외는 클러스터에 고르게 분포하지 않고 매우 집중되어 있습니다. 73 일간 224 회의 다중 노드 학습 세션에서, 같은 노드들이 60 노드 작업에서 반복적으로 빠졌습니다.
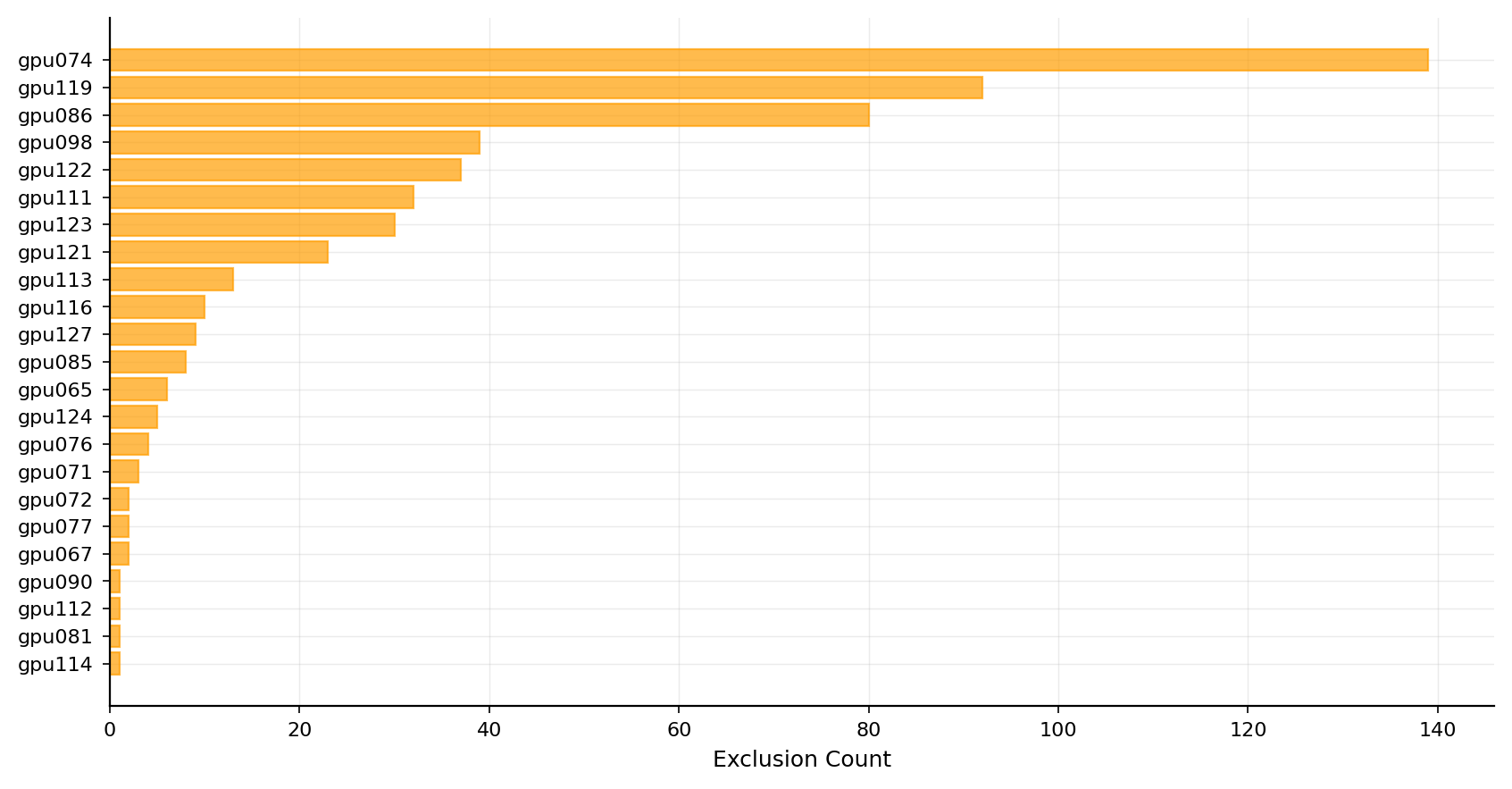
위 그림처럼 분포는 한쪽으로 쏠려 있습니다. 가장 많이 제외된 상위 3 개 노드(gpu074, gpu119, gpu086)가 전체 제외의 50\% 이상을 차지하는 반면, 대부분의 노드는 제외율이 5\% 미만이었습니다. 참고로 관측 기간 동안 60 노드 학습 세션의 시간 점유율은 약 96.6\% 였고, 가장 긴 세션은 222.9 시간(약 9.3 일) 동안 연속 실행되었습니다.
이 집중의 원인을 분석하기 위해, 연구팀은 60 노드 학습에서 제외된 시간이 같은 노드에 대한 단일 노드 세션 할당과 겹치는 비율을 계산했습니다. 이 비율은 운영자가 의도적으로 격리했는지(단일 노드 세션으로 점유), 아니면 스케줄러가 63 개 중 60 개를 고르는 과정에서 자연스럽게 선택되지 않았는지 를 구분하는 지표가 됩니다. 분석 결과 gpu074(100\%), gpu086(97\%), gpu116(99.6\%) 같은 상위 노드들은 거의 모든 제외 시간이 단일 노드 점유와 겹쳤습니다. 즉 운영자가 통신 지연이나 학습 속도 저하를 우려해 의도적으로 격리한 것입니다. 반면 gpu085(4\%)는 단일 노드 점유와 거의 겹치지 않아, 스케줄러의 무작위 비선택으로 자연스럽게 빠진 경우로 보입니다.
여기서 핵심 제약이 드러납니다. 클러스터에는 예비 노드가 단 3 개뿐이고, 이 예비 노드들이 문제 노드 격리에 쓰여 점유되는 경우가 잦아, 대규모 학습 작업의 실질적 노드 구성이 거의 고정된다는 점입니다.
자동 재시도: 12.5%에서 33.3%로
자동 재시도 분석은 장애 후 복구가 얼마나 빠르고 안정적으로 진행되는지를 평가합니다. Backend.AI FastTrack 은 재시도 활성화 여부, 최대 재시도 횟수, 재시도 지연이라는 세 가지 파라미터로 작업 수준 자동 재시도를 제공하며, 관측 기간에는 재시도가 활성화되어 있고 지연이 약 10 분으로 설정되어 있었습니다. 73 일간의 로그에서 같은 작업 이름으로 연속 실행된 세션을 "체인"으로 묶은 결과, 12 개의 체인(총 73 회 시도, 61 회 재시도)이 식별되었습니다.
자동 재시도는 매우 규칙적인 재시작 리듬을 만들어 냅니다. 자동 재시도의 세션 간 간격은 중앙값 11 분(IQR 10~11 분)으로, 10 분 재시도 지연에 정리와 재시작 오버헤드가 더해진 값과 일치합니다. 반면 수동 재시작은 중앙값이 2 분으로 더 짧지만 범위가 0~430 분으로 훨씬 넓어 운영상 예측이 어렵습니다. 이 대비는 사람의 대응이 느려질 수 있는 야간과 주말 에 특히 중요합니다. 자동 재시도는 정해진 일정대로 계속 작동하기 때문입니다.
성공률에서도 자동 재시도의 가치가 드러납니다. 같은 작업 이름 아래의 재시도 시퀀스가 최소 한 번이라도 학습에 도달한 비율인 체인 성공률은 33.3\%(12 개 중 4 개)였습니다. 이에 비해 수동으로 시작된 개별 세션은 12.5\%(104 개 중 13 개)만 학습에 도달해, 체인 성공률이 약 2.7\times 높았습니다. 성공한 4 개 체인 중 3 개는 단 한 번의 재시도로 복구되었고, 그중 하나는 RESTART_APP으로 분류되는 XID 94(ECC 오류) 사례로, 자동 재시도가 운영자 개입 없이 진행 상태를 복원할 수 있음을 보여줍니다.
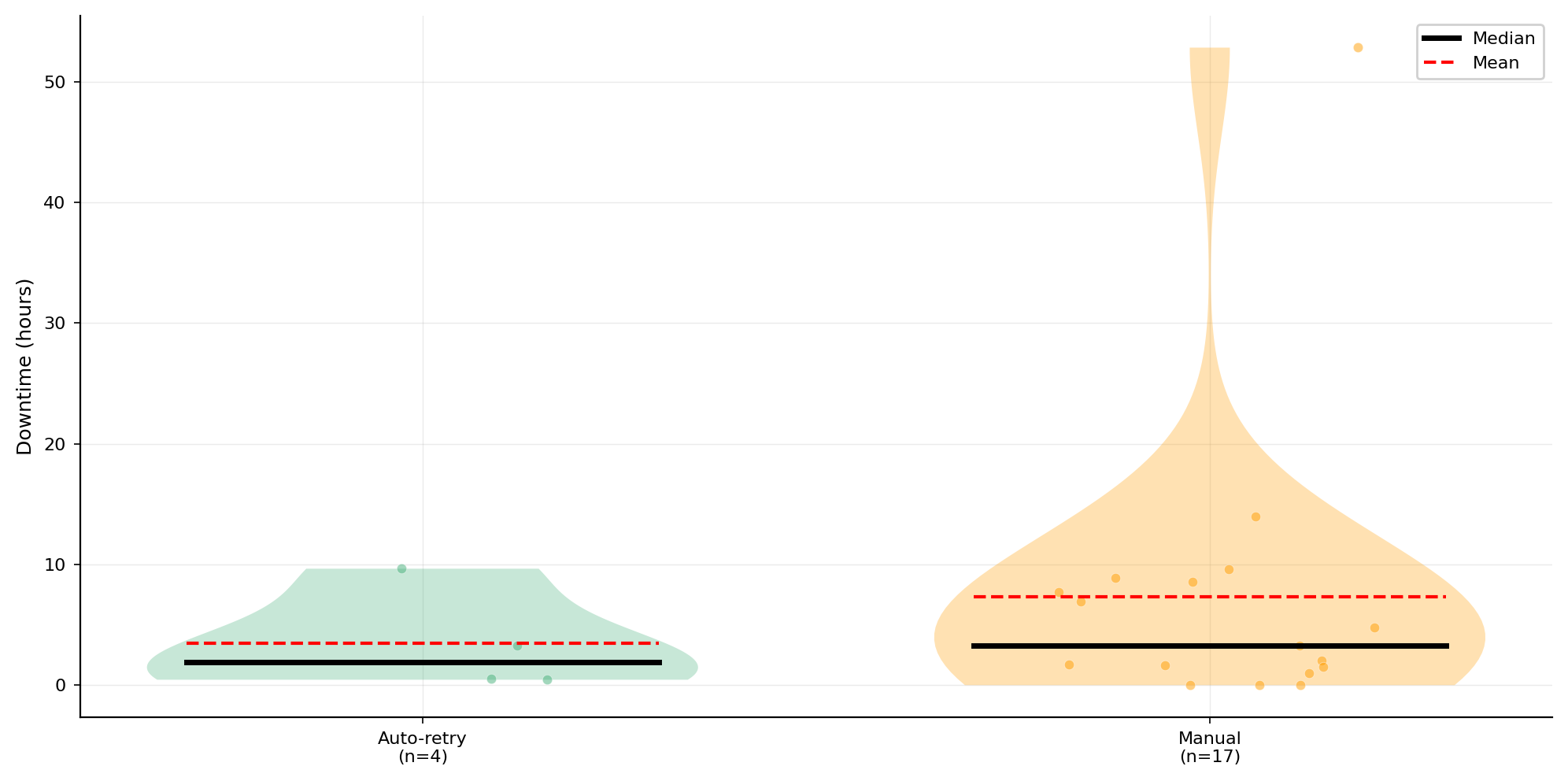
성공률 향상은 곧바로 다운타임 단축으로 이어집니다. 21 건의 복구 에피소드를 분석한 결과, 자동 재시도가 학습을 복원한 4 건의 다운타임 중앙값은 1.9 시간으로, 17 건의 수동 복구 중앙값 3.3 시간 대비 약 1.8\times 짧았습니다. 수동 복구의 분산이 0~53 시간으로 큰 것은, 야간이나 주말처럼 즉각 대응이 어려운 시간대에 장애가 발생한 경우를 반영합니다.
자동 재시도의 한계: 단순 재시작으로 풀리지 않는 것들
그러나 자동 재시도가 만능은 아닙니다. 12 개 체인 중 8 개(67\%)는 결국 실패했고, 대부분 NCCL 통신 오류 같은 소프트웨어나 네트워크 수준의 문제로, 단순 재시작으로는 해결되지 않았습니다. 특히 다운타임이 길었던 일부 에피소드(9.65 시간, 3.25 시간)는 자동 재시도 메커니즘 자체의 한계가 아니라 인프라 수준의 문제 때문이었습니다. 하드웨어 교체 후 GPU 라이선스가 갱신되지 않아 노드가 가용 자원 풀에 합류하지 못했고, 60 노드 요구사항을 충족할 수 없어 재시도가 몇 시간씩 실패한 것입니다. 이 문제는 이후 플로팅 라이선스 모델로 전환하여 해결되었습니다.
실패한 체인의 재시도 비용은 약 35 GPU-시간(전체 학습 시간의 2.7\%)이었습니다. 특히 한 체인은 25.4 시간의 성공적인 학습 후 30 번 연속으로 실패했는데, 이는 근본 문제를 해결하지 않은 채 같은 조건에서 반복 재시도하면 GPU 시간만 소모할 뿐 임을 잘 보여줍니다. 이 분석을 바탕으로 보고서는 세 가지 개선 방향을 제시합니다.
- 지수 백오프(exponential backoff): 재시도 간격을 점진적으로 늘려(10 분 \rightarrow 20 분 \rightarrow 40 분) 일시적 장애에는 빠른 초기 복구를 유지하면서 후반 재시도의 자원 소모를 줄입니다.
- XID 기반 분기: 해결 유형별로 재시도 전략을 차별화합니다. RESTART_APP 유형(XID 31, 43, 94)은 즉시 재시도, RESET_GPU 유형(XID 119, 145, 149)은 GPU 리셋 후 재시도, CONTACT_SUPPORT 유형(XID 79)은 재시도를 중단하고 운영자에게 알립니다.
- 우선순위 기반 세션 선점: 예비 노드가 3 개뿐인 상황에서 다중 노드 학습에 더 높은 우선순위를 주고, 재시도 중 낮은 우선순위의 단일 노드 세션을 자동 선점하거나 예비 노드 풀을 확장합니다.
한계와 향후 연구 방향
연구팀은 이 분석의 한계를 솔직하게 짚습니다. 우선 체크포인트 I/O 분석은 인프라 수준의 수치(저장 오버헤드, 장애당 손실 시간, 재시작 로딩 시간)를 정량화했지만, 이런 인프라 이벤트가 학습 처리량과 수렴 시간에 미치는 영향을 평가하려면 학습 프레임워크 내부의 추가 계측이 필요합니다. 또한 전조 분석은 사후적(retrospective)이며, 실시간 배포에는 거짓 양성 분포와 알림이 주는 운영 부담에 대한 별도 검증이 필요합니다. 분석된 장애가 10 건, 재시도 체인이 12 개로 표본이 작다는 점도 통계적 검정력을 제한합니다.
향후 연구로는 반복당 처리량(tokens/sec) 로깅을 통한 MFU 계산, NFS/RPC 경로 최적화, 다변량 시계열을 학습하는 전조 기반 예측 장애 관리, 그리고 FP8 같은 저정밀도 학습이 도입하는 새로운 장애 모드 분석이 제시됩니다. 특히 FP8은 처리량 향상을 약속하지만 수치적 안정성 측면에서 새로운 위험을 안고 있습니다. 한 연구는 약 2{,}000 억 토큰 학습 이후 치명적인 불안정을 보고하기도 했는데, Solar Open 프로젝트도 같은 B200 클러스터에서 FP8과 bfloat16 혼합 정밀도를 채택했습니다. 학습 발산이 cuDNN 버그, 수치적 한계, 하드웨어 결함 중 무엇에서 비롯되는지 자동으로 구별하는 장애 원인 규명 메커니즘은 인프라 관점의 열린 과제로 남아 있습니다.
결론: 대규모 학습 운영이 우리에게 남기는 세 가지 원칙
이 보고서가 네 가지 정량적 발견을 통해 궁극적으로 전하는 메시지는, 대규모 LLM 학습이 모델 설계만큼이나 인프라 설계에 진지한 분석적 관심을 기울여야 하는 시스템 문제라는 것입니다. 연구팀은 네 가지 발견을 세 가지 더 넓은 원칙으로 정리합니다.
첫째, 장애는 대규모 학습의 구조적 특성 입니다. 클러스터 규모와 장애 빈도의 수학적 관계, 그리고 $16$K GPU에서 54 일간 419 건의 중단이라는 운영 증거는 몇 시간마다 하드웨어 장애가 일어나는 것이 대규모 학습의 근본 속성임을 확인시켜 줍니다.
둘째, 학습 워크로드는 세션 수준 추상화 를 요구합니다. 상태 없는 단명 프로세스를 전제하는 컨테이너 오케스트레이션과 달리, 학습은 체크포인트 진행 상태를 추적하고 재시작이 아닌 재개를 가능하게 하는 추상화를 필요로 합니다.
셋째, GPU 스케줄링과 스토리지는 함께 설계 되어야 합니다. 스토리지 처리 경로를 맞추지 않은 채 GPU 용량만 공급하면, 운영 규모에서만 드러나는 성능 절벽이 생기기 때문입니다.
세 원칙 모두 조직 간 공동 운영 환경 위에서 비로소 관측 가능했다는 점은, 그 자체로 또 하나의 중요한 시사점입니다. 조직의 경계를 넘는 공유 지표 파이프라인이 없었다면, 여기서 정리한 운영 규모의 현상들은 애초에 직접 관측되지 못했을 것입니다. 모델의 크기 경쟁에 가려져 잘 드러나지 않던 "학습 인프라 운영"이라는 영역에, 이 보고서가 드물게 공개된 프로덕션 데이터로 한 줄기 빛을 비춰 준 셈입니다.
이 보고서가 분석한 Backend.AI 플랫폼과 all-smi 모니터링 도구는 오픈소스로 공개되어 있어, 관심 있는 분들은 직접 살펴보실 수 있습니다.
 From Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs 논문 (영문)
From Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs 논문 (영문)
From Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs (한국어)
 Backend.AI GitHub 저장소
Backend.AI GitHub 저장소
all-smi GitHub 저장소
더 읽어보기
-
Skills For Real Engineers: Matt Pocock이 정리한, 실전 엔지니어링을 위한 Claude Code 스킬 모음
-
MAI-Thinking-1 기술 보고서: 데이터 파이프라인부터 RL 인프라까지, 프런티어 모델 학습의 전 과정을 해부한 '힐 클라이밍 머신' (feat. Microsoft AI)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()