
"모델"이 아니라 "모델을 만드는 기계"를 공개하다
요즘 새로운 프런티어 모델 발표는 거의 매주 쏟아지지만, 정작 "이 모델을 어떻게 만들었는가"는 대부분 베일에 싸여 있습니다. 벤치마크 점수와 데모는 화려해도, 데이터를 어떻게 모으고 걸렀는지, 아키텍처 선택을 어떤 실험으로 검증했는지, 강화 학습을 수천 스텝 동안 무너지지 않게 유지하는 비결이 무엇인지는 좀처럼 공유되지 않습니다. Microsoft AI(MAI)가 공개한 109쪽 분량의 기술 보고서 MAI-Thinking-1: Building a Hill-Climbing Machine이 주목받는 이유가 여기에 있습니다. 이 보고서는 모델 하나를 자랑하는 문서가 아니라, 사전 학습 데이터 파이프라인부터 강화 학습 인프라, 평가, 레드티밍, 클러스터 운영까지 프런티어 모델 학습의 전 과정을 단계별로 해부한 가이드 에 가깝습니다.
보고서의 핵심 개념은 제목 그대로 힐 클라이밍 머신(hill-climbing machine) 입니다. "AI의 발전은 단일 모델이 아니라, 현재 모델 상태를 지속적으로 개선할 수 있는 능력에서 나온다"는 관점 아래, 모델 개발을 시스템 수준의 최적화 문제로 다룹니다. 데이터 파이프라인, 학습 인프라, RL 환경과 보상, 평가 스위트, 안전성 테스트를 하나의 통합된 경험적 최적화 루프로 묶어, 언덕을 오르듯 꾸준히 성능을 끌어올리는 기계를 만드는 것입니다.
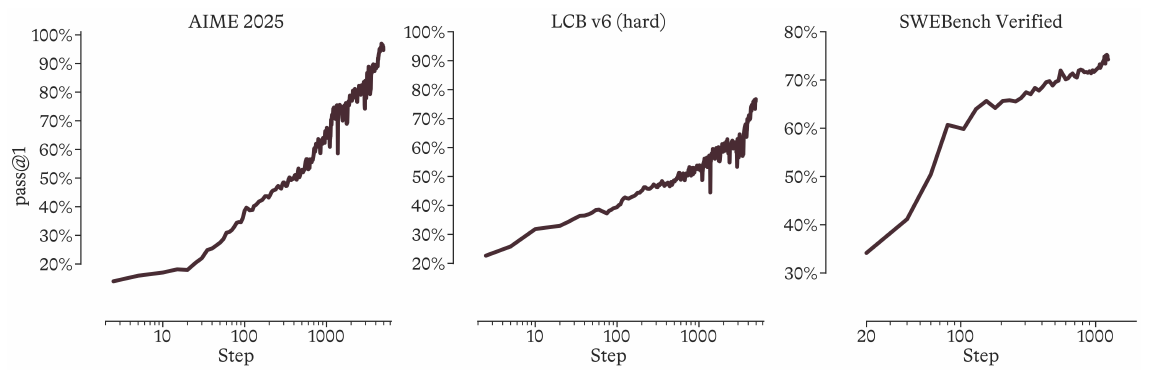
이 기계로 만든 첫 모델이 MAI-Thinking-1 입니다. 활성 파라미터 $35$B, 전체 파라미터 $1$T 규모의 전문가 혼합(Mixture-of-Experts, MoE) 모델로, SWE-Bench Pro 52.8\%, AIME 2025 97.0\%, LiveCodeBench v6 87.7\% 를 기록하며 비슷한 체급에서 가장 강력한 모델 중 하나로 꼽힙니다. 특히 눈에 띄는 점은 개발 철학입니다. 보고서는 세 가지 설계 원칙을 천명합니다. 첫째, 능력은 물려받는 것이 아니라 학습하는 것 입니다. 제3자 모델로부터의 증류(distillation)는 빠르지만, 모방으로 얻은 지능은 길고 지속적인 등반에 필수적인 조종 가능성과 견고함이 부족하다는 것입니다. 둘째, 단순함이 지속 가능합니다. 단순하고 확장 가능한 레시피, 깨끗하고 신뢰할 수 있는 데이터, 투명한 인프라를 선호합니다. 셋째, 과학적 엄밀함이 지름길의 유혹을 막습니다. 모든 결정은 데이터 기반 사다리(ladder), 절제 실험(ablation), 평가로 검증 가능해야 합니다.
이 글은 보고서의 챕터 구성을 따라가며 각 단계를 상세히 정리합니다. 사전 학습(2장), 강화 학습 클라임(3장), 평가(4장), 안전성 레드티밍(5장), 클러스터 환경(6장) 순서이며, 분량이 긴 만큼 관심 있는 단계부터 골라 읽으셔도 좋습니다.
사전 학습(Pre-training): $30$T 토큰을 사람의 지식만으로
MAI-Thinking-1 의 기반 모델인 MAI-Base-1 은 활성 파라미터 $35$B, 전체 파라미터 $1$T 규모의 희소(sparse) MoE 모델입니다. Microsoft 가 Azure 플랫폼 위에서 운영하는 클러스터의 GB200 GPU $8$K 장에서 자체 분산 학습 인프라로 밑바닥부터(from scratch) 학습했습니다. 가장 눈에 띄는 설계 철학은 데이터입니다. 학습 코퍼스는 공개 데이터와 정식 계약으로 확보한 데이터만으로 사내에서 직접 구축했고, "기존 AI 모델을 모방하는 대신 사람의 지식으로부터 능력을 학습하는" 것을 목표로, 다른 모델의 출력을 베껴 오는 증류(distillation) 데이터를 전혀 쓰지 않았습니다.
전체 학습은 두 덩어리로 나뉩니다. 먼저 $30$T 토큰 규모의 본 사전 학습(main pre-training) 단계를 거치고, 이어서 합계 $3.55$T 토큰 규모의 중간 학습(mid-training) 단계들을 진행합니다($3.4$T 의 1단계와 $150$B 의 2단계로 구성). 이 장은 이 거대한 학습 과정을 떠받치는 여덟 개의 축, 즉 모델 구조, 절제 실험(ablation) 방법론, 평가 방법론, 데이터 파이프라인, 데이터 혼합 비율 선택, 학습 레시피, 동시대 모델과의 비교, 그리고 분산 학습 시스템 YOLO 를 차례로 다룹니다.
이 장을 관통하는 핵심 도구가 하나 있습니다. 바로 스케일링 사다리(scaling ladder) 입니다. 모델 설계나 데이터의 이점은 연산 예산이 커질수록 줄어드는 경우가 많기 때문에, MAI 팀은 어떤 변경을 받아들이기 전에 여러 규모에 걸쳐 그 효과가 유지되는지를 사다리처럼 단계별로 검증합니다. 작은 모델에서 좋아 보였던 선택이 큰 모델에서도 좋으리란 보장은 없으며, 이 장의 여러 발견은 바로 이 검증 과정에서 나왔습니다.
모델 구조: 인터리브 MoE 와 주기적 어텐션
MAI-Base-1 은 디코더 전용(decoder-only) Transformer 입니다. 다만 두 가지를 번갈아 배치(interleave)하는 점이 특징입니다. 첫째로 고희소(high-sparsity) MoE 층과 작은 밀집(dense) FFN 을 번갈아 쌓고, 둘째로 전역(global) 어텐션과 지역(local) 어텐션을 번갈아 씁니다. 각 층의 입력과 출력 양쪽에서 잔차 덧셈(residual add) 직전에 RMSNorm 을 적용하며, 모델에는 어떤 편향(bias)도 두지 않고 입출력 임베딩 가중치를 묶어서(tied) 공유합니다. 토크나이저는 사내 학습 토크나이저가 약간 더 나았지만, 기존 사내 도구 및 워크플로와의 통합 편의를 위해 어휘 크기 200{,}019 의 o200k_base 토크나이저를 선택했습니다.
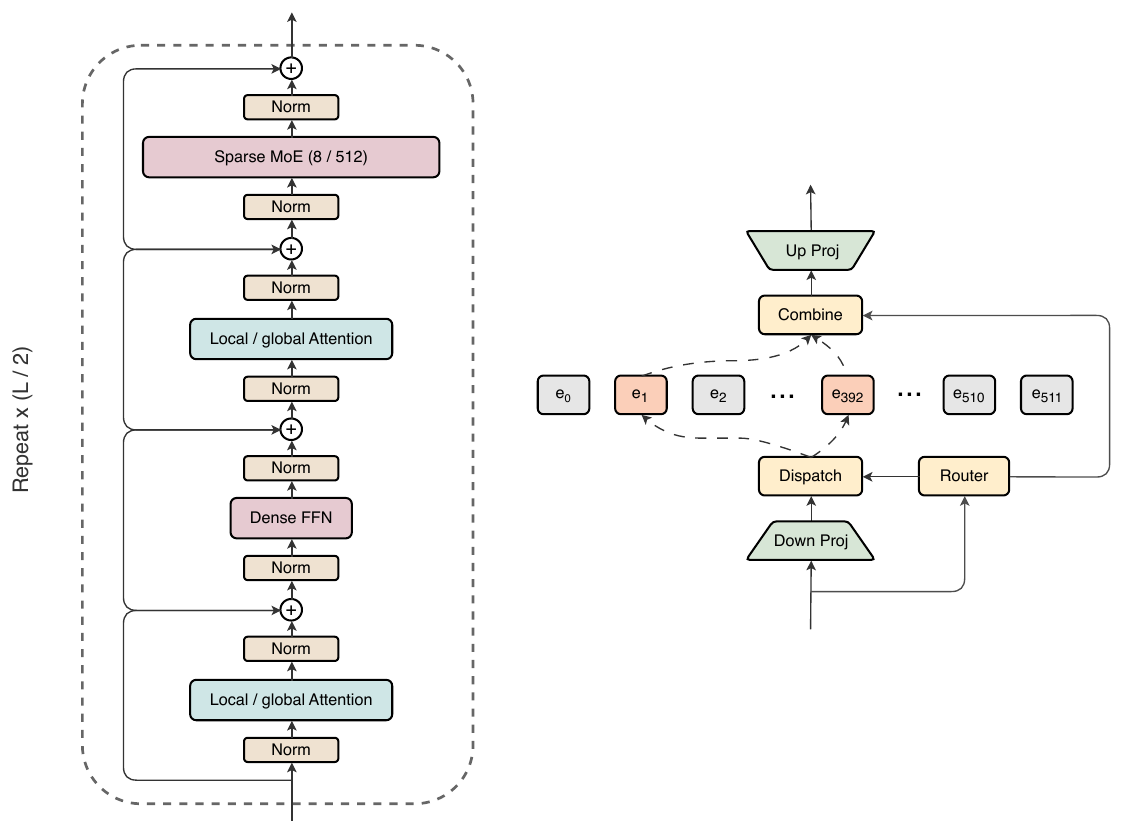
어텐션은 Gemma 3 의 주기적 설계를 따릅니다. 지역 어텐션 5 개에 전역 어텐션 1 개를 짝지어, 학습 시 연산량과 추론 시 KV 캐시 크기를 크게 줄입니다. 지역 어텐션은 슬라이딩 윈도우 크기 512, 기저 주파수 10{,}000 의 RoPE 를 쓰고, 전역 어텐션은 아예 위치 인코딩을 쓰지 않습니다(NoPE). 위치 인코딩 없이도 RoPE 와 비슷한 성능을 내면서 더 효율적이기 때문입니다. KV 헤드 8 개의 그룹 질의 어텐션(group-query attention)을 헤드당 차원 128 로 쓰고, 질의와 키에 RMSNorm 을 적용합니다. 이런 표준 부품들 덕분에 FlashAttention-4 와 Ulysses 방식 컨텍스트 병렬(context parallelism)을 그대로 활용할 수 있습니다.
피드포워드 쪽 설계가 이 모델의 정체성입니다. MoE 층과 밀집 FFN 을 번갈아 쌓는데, 이는 "고희소 층 하나와 영(zero) 희소 밀집 층 하나를 짝짓는 방식이 중간 희소도 MoE 를 모든 층에 까는 방식과 성능은 비슷하면서, 동일 활성/동일 전체 파라미터 조건 모두에서 실제 시간(wall-clock) 효율은 더 낫다"는 관찰에 근거합니다. 흥미롭게도 모든 층을 MoE 로 채우는 배치는 공유 전문가(shared expert)에 훨씬 크게 의존하는 반면, 인터리브 배치에는 공유 전문가를 더해도 거의 이득이 없었습니다. 첫 피드포워드 층은 밀집으로 두고, 밀집과 MoE 모두 SwiGLU 를 씁니다.
MoE 의 라우팅에는 LatentMoE 설계를 채택했습니다. all-to-all 디스패치 전에 공유 다운 프로젝션으로 표현을 압축해 보내고, all-to-all 결합 뒤에 원래 차원으로 되돌립니다. 비유하자면 화물을 보낼 때 짐을 압축 포장해 운송비를 줄이고 도착지에서 다시 푸는 셈입니다. 다만 라우팅 결정 자체는 압축 전 원본 표현으로 내리며, 각 토큰은 softmax 게이팅으로 512 개 중 8 개 전문가로 보내집니다. 부하 균형은 데이터 병렬 워커와 마이크로배치를 글로벌 배치 단위로 모두 합산해 계산하는 전역 부하 균형 손실(global-batch load balancing loss)을 쓰는데, 손실의 종류보다 이 전역 합산 전략 자체가 훨씬 중요했습니다. 실제로 GShard 류 손실은 전역 합산만 보장되면 손실 없는(loss-free) 변형과 거의 같은 성능을 냈습니다. 또한 전문가 용량(capacity)이 유한한 설정에서는 토큰 탈락률을 낮게 유지하더라도 결론이 달라질 수 있음을 확인하고, 토큰을 버리지 않는 완전한 무탈락(dropless) MoE 구현으로 수렴했습니다.
| 모델 | 활성 | 전체 | 층 | 히든 | Top-k/전문가 |
|---|---|---|---|---|---|
| L12 | 365M | 3.9B | 12 | 1024 | 8/512 |
| L36 | 4.0B | 100B | 36 | 3072 | 8/512 |
| L66 | 21.7B | 615B | 66 | 5632 | 8/512 |
| L78 | 35.6B | 1015B | 78 | 6656 | 8/512 |
| MAI-Base-1 | 34.7B | 962B | 78 | 6656 | 8/512 |
MAI-Base-1 아키텍처 패밀리의 구성(Table 1 요약)입니다. MAI-Base-1 은 L78 을 바탕으로, all-to-all 집합 통신의 히든 차원이 512 로 나누어떨어져야 하는 DeepEP 요건에 맞춰 전문가 입력 크기만 살짝 조정했습니다.
절제 실험 방법론: 스케일링 사다리와 효율 이득
모든 절제 실험은 규모에 따른 거동을 중심에 두고 진행합니다. 스케일링 사다리는 어떤 절제 실험이든 (활성)파라미터당 토큰 수(tokens per parameter, TPP)를 일정하게 고정한 채 여러 크기의 모델을 학습하고, 그 스케일링 곡선을 기준선과 비교하는 방식입니다. 사용하는 TPP 는 실험 성격에 따라 다릅니다. 구조 절제 실험은 대개 Chinchilla 최적 영역인 100~200 TPP 에서 하고, 본 학습은 추론 부담이 큰 비교적 작은 모델을 얻으려고 500~1{,}000 TPP 로 과학습(over-train)합니다. 받아들인 변경은 다음 기준선 사다리로 편입되고 같은 과정이 반복됩니다.
이 사다리에서 모델 하나는 층 수 L 이라는 단일 파라미터로 완전히 결정됩니다. 5{:}1 지역/전역 어텐션 비율을 쓰므로 L 은 6 의 배수여야 마지막 어텐션 층이 전역 어텐션이 되고, 히든 크기는 D = L \times \frac{256}{3} 로 정해 사다리 전체에서 종횡비를 일정하게 유지합니다. 질의 헤드 수는 L 을 16 의 배수로 올림한 값으로 두어 텐서 병렬 서빙을 쉽게 합니다. 마치 키가 자랄 때 몸의 비율을 그대로 유지하며 커지는 것처럼, 한 변수만 키워 일관된 모양으로 규모를 확장하는 셈입니다.
효율 이득(efficiency gain, EG) 은 어떤 후보 모델이 도달한 평가 지표를 기준선 모델이 따라잡으려면 학습 비용을 얼마나 더 써야 하는지를 나타냅니다. 먼저 기준선 사다리에 스케일링 법칙 L = AC^{-\alpha} + E 를 적합한 뒤(여기서 A 는 줄일 수 있는 손실의 크기, \alpha 는 감소 속도, E 는 줄일 수 없는 손실), 비용 C' 로 손실 L' 을 낸 후보에 대해 \text{EG} = f^{-1}(L') / C' 로 정의합니다. 예를 들어 \text{EG} = 1.3 이면 기준선이 같은 손실에 도달하려면 비용을 30\% 더 써야 한다는 뜻입니다. 비용 C 는 보통 FLOPs 로 정의하는데, 이는 의도적으로 실제 하드웨어 효율(MFU)을 배제하기 위해서입니다. 오래 다듬어진 기존 구조가 최적화가 누적되어 실제보다 강해 보이는 착시를 피하고, 동등한 노력을 들였을 때 구조 자체의 우열을 보려는 것입니다. 하드웨어 효율이 중요한 경우에는 시간으로 비용을 정의한 \text{EG}_{\text{Time}} 을 따로 씁니다.
두 가지 실험이 이 방법론의 쓰임을 잘 보여 줍니다. 첫째, 희소도 배분 실험에서 모든 층에 중간 희소도 MoE 를 까는 방식(공유 전문가 포함)은 FLOPs 기준 EG 가 1.03 으로 인터리브 방식과 비슷했지만, 학습 시간을 고려한 \text{EG}_{\text{Time}} 은 0.82 로 인터리브 방식이 확실히 앞섰습니다(L12~L30 사다리 모델에서 측정). 둘째, 희소도 확장 실험에서는 전문가 수를 256 개에서 1024 개로(top-k 를 8 로 고정한 채 희소도 32\times 에서 128\times 로) 늘릴수록 EG 가 일관되게 좋아져, 이 아키텍처 패밀리가 건강한 확장성을 가짐을 확인했습니다. MAI-Base-1 은 품질과 효율의 균형점으로 top-8/512 구성을 택했습니다. (희소도별 효율 이득 곡선은 보고서의 Figure 3을 참고해주세요)
평가 방법론: 정확도 대신 NLL
사전 학습 단계의 일상적 평가에는 정답을 맞히는 개수 대신 음의 로그 가능도(negative log-likelihood, NLL) 평가를 씁니다. 벤더가 학습에서 완전히 떼어 만든 데이터, 웹에 없는 사내 자료, 학습에서 신중히 제거한 웹 자료 등을 묶어 약 40 개의 벤치마크를 만들고, 이를 Code, STEM, Math, General Knowledge, Multilingual 의 5 개 범주로 나눕니다. 이를 하나의 점수로 합칠 때는 다음 가중 평균을 씁니다.
코드와 추론 능력을 사전 학습에서부터 중시한다는 우선순위가 가중치에 그대로 드러납니다. Math 를 STEM 에서 떼어 별도 범주로 격상한 점도 눈에 띕니다. 각 범주 점수는 고정된 사내 기준 모델로 원시 NLL 을 정규화한 뒤 범주 내 벤치마크를 균등 평균해 구하며, 모든 모델이 동일한 토크나이저를 쓰므로 NLL 값을 직접 비교할 수 있습니다.
이 평가 묶음이 어떻게 구성되는지는 Table 3 의 예시가 잘 보여 줍니다. Coding 은 Microsoft 사내 코드와 pull request, 비공개 사내 프로젝트, 사람과 AI 의 코딩 세션에서 가져오고, STEM 과 Math 는 도메인 전문가를 고용한 벤더에 의뢰해 만든 대학원 수준 STEM 문제와 고급 수학 문제의 풀이입니다. General Knowledge 는 공개 웹 포럼의 토론, 사람과 AI 의 상호작용, 학습 데이터와 중복 제거한 공개 데이터베이스 기반 피라미드형 트리비아(pyramidal trivia), 벤더 의뢰 난해 트리비아 등으로 채웁니다. 모든 예시는 학습 데이터에서 꼼꼼히 중복 제거됩니다.
왜 정확도가 아니라 NLL 일까요? 첫째는 비용입니다. 사고 사슬(chain-of-thought)이나 도구 사용이 필요한 생성형 평가는 자기회귀 생성 때문에 느리고 비싸며 심판 모델까지 필요할 때가 많지만, NLL 평가는 사전 학습과 똑같은 다음 토큰 예측이라 매우 효율적이어서 모든 실험에 일관되게 더 많이 돌릴 수 있습니다. 둘째는 견고함입니다. 객관식 형식은 모델이 "객관식을 푸는 능력" 자체를 갖춰야 의미가 있는데 이는 놀랄 만큼 큰 규모에서야 나타나며, MATH 의 \boxed{} 규약이나 MBPP 의 줄바꿈(\n 대 \r\n) 불일치처럼 사소한 형식 차이가 결과를 크게 흔듭니다. NLL 평가는 매 예측 단계에서 정답 접두를 조건으로 주는 교사 강요(teacher-forcing) 방식이라 작은 오류가 누적되는 폭이 제한됩니다. 비유하자면 학생을 시험 볼 때마다 처음부터 끝까지 혼자 풀게 하는 대신, 각 문제의 앞부분 풀이를 정답으로 채워 주고 다음 한 줄만 예측시켜 채점하는 것과 같아, 한 번 삐끗했다고 뒤가 통째로 무너지지 않습니다. 셋째는 구축 비용입니다. 고품질 Q&A 평가는 난이도 보정과 전문가 협업이 거듭 필요하지만, NLL 평가는 주제 관련 텍스트만 있으면 시작할 수 있어 진입 장벽이 훨씬 낮습니다.
다만 공개 벤치마크의 오염(contamination) 문제는 정직하게 다룹니다. 평가 데이터가 GitHub 등으로 학습 데이터에 새어 든 경우, 코딩용 데이터가 엉뚱하게 롱테일 일반 지식 평가까지 끌어올리는 반직관적 결과가 나타납니다. 이를 막기 위해 huggingface.co 와 미러 도메인의 데이터를 전부 제거하고, 모든 학습 소스에 유사도 임계값 80\% 의 20-gram 퍼지 중복 제거를 적용합니다. 그래도 완벽하지 않다는 점을 인정하고, 웹 어디에도 없다고 확신할 수 있는 사적 벤치마크를 따로 개발해 씁니다.
사전 학습 데이터: 품질을 향한 사내 파이프라인
MAI-Base-1 의 학습 데이터는 공개 데이터와 라이선스를 받은 사람 생성 데이터의 혼합입니다. 웹, 공개 GitHub 코드, 책, 학술 논문, 뉴스, 다국어 텍스트, 도메인 특화 자료를 아우르되, 언어 모델이 만든 합성(synthetic) 데이터는 쓰지 않고 수집 소스 안의 AI 생성 콘텐츠도 적극적으로 걸러 냅니다. 모든 데이터는 웹 HTML/PDF, 책과 저널, 공개 GitHub 코드라는 원천 소스에서 사내 파이프라인으로 직접 처리하며, 오픈소스 학습 데이터셋은 일절 쓰지 않고 huggingface.co 같은 머신러닝 저장소는 웹 데이터에서 제외합니다. 소스별 지식 컷오프(Table 4)는 다음과 같습니다.
| 소스 | 지식 컷오프 |
|---|---|
| Web HTML | 2025년 9월 |
| Web PDF | 2025년 12월 |
| 공개 GitHub 코드 | 2025년 6월 |
| 책과 저널 | 2026년 3월 |
데이터 거버넌스도 까다롭습니다. 웹 크롤러는 robots.txt 와 메타 태그 제어를 준수하고, Microsoft 책임 있는 AI 정책을 위반하거나 USTR Notorious Markets 목록에 오른 소스는 제외합니다. 제3자에게서 상업 계약으로 받은 데이터는 데이터 신뢰성, 소유권, 사용권을 검증하는 실사를 거치며, 사적 고객 데이터나 Microsoft 제품/서비스 데이터는 사용자가 명시적으로 동의했거나 계약이 허용하는 경우를 빼고는 쓰지 않습니다. 학습 전 전체 코퍼스에 PII 위험 및 안전 필터링을 적용합니다.
웹 HTML 파이프라인
부록 A 에 따르면 웹 HTML 코퍼스 대부분은 자체 크롤에서 옵니다. 약 $1.2$T 페이지를 크롤해 Trafilatura 로 텍스트를 추출하는데, UTF-8 을 가정하지 않고 문서 인코딩을 추론해 레거시/누락 인코딩의 다국어 데이터까지 안정적으로 처리합니다. 이어 정책 위반, 성인물, 웹 PDF 코퍼스와의 중복, 차단 도메인(UT1 차단 목록 포함) 필터링으로 $794$B 페이지로 줄고, 자체 AI 생성물 탐지 모델과 수동 점검으로 AI 생성 콘텐츠가 많은 도메인을 추가로 걸러 냅니다. 소문자화/공백 정리 후 MD5 정확 중복 제거로 $423$B 문서가 되고, 퍼지 중복 제거 뒤 자체 크롤에는 영어 $73.4$B, 비영어 $116.5$B 문서가 남습니다. Common Crawl 은 약 $300$B 페이지에서 출발해 URL 별 최신본만 남겨 약 $100$B 페이지로 줄인 뒤, 필터링/중복 제거/자체 코퍼스와의 병합을 거쳐 최종 $24.2$B 페이지가 합류합니다. (웹 HTML 처리 파이프라인의 전체 구성도는 보고서의 Figure 4를 참고해주세요)
추출 방법은 하나로 고정하지 않고 도메인의 구조와 신뢰도에 따라 달리합니다. HTML/XML 같은 표준 포맷에는 스키마 인식 파서를, 일관된 구조를 갖지만 일반 휴리스틱이 잘 다루지 못하는 도메인에는 BeautifulSoup 기반 수제 추출기를, 결정적 규칙만으로는 부족한 도메인에는 LLM/에이전트 기반 처리를 씁니다. 특히 Wikipedia 처럼 추가 처리가 중요한 정보를 버릴 위험이 있는 고가치/저용량 소스는 원본을 그대로 학습하는데, wikitext 가 약 3\times 더 장황함에도 인포박스 등을 온전히 보존하지 못하는 변환본보다 원본 마크업 전체를 학습하는 편이 더 나은 결과를 냈기 때문입니다.
추출 후에는 용도별 하위 파이프라인으로 갈라집니다. 일반 영어 웹은 교육적 가치, 사실성, 정보 밀도 같은 속성 모델로 점수를 매긴 품질 모델로 하위 70\% 를 걸러 내고 Gopher 류 휴리스틱을 적용해 자체 크롤 $4.6$B, Common Crawl $2.8$B 영어 문서를 남깁니다. STEM 전용 파이프라인은 주제(수학, 물리, 통계, 화학, 생물, 공학, 컴퓨터과학 7 개 이진 분류기), 교육적 가치, 교육 수준(고교/학부/대학원) 분류기로 후보를 뽑고, MathML/LaTeX 를 정규화해 Markdown 으로 변환한 뒤 LLM 이 섹션 단위로 보존/삭제만 판단합니다(합성 생성 불가). 그 결과 영어 STEM $680$B 토큰(수학 관련 $76$B 포함)과 다국어 $760$B 토큰(고품질 수학 $58$B 포함)을 얻습니다. 코드 웹 페이지는 STEM 파이프라인을 재사용해 컴퓨터과학 주제로 거른 뒤 Qwen3-30B 심판으로 점수를 매기는데, 이 심판 프롬프트는 사람 라벨 약 2{,}000 개로 GEPA/DSPy 로 최적화했으며 최종 약 $233$B 토큰을 얻습니다.
웹 PDF, 책과 저널 파이프라인
웹에서 크롤한 PDF 코퍼스는 약 $10$B 문서에서 시작해 휴리스틱/분류기로 $620$M 문서로 추린 뒤, Azure Document Intelligence(OCR)로 학습 가능한 텍스트로 변환합니다. 수식/표 정규화, 머리말/꼬리말/그림 텍스트 등 보일러플레이트 제거, OCR 글리프 오류 정리, 줄바꿈/하이픈 풀기, 학술 문서의 참고문헌 절 제거를 거칩니다. 특히 PDF 메타데이터의 creator, producer 필드가 SEO/스팸 필터링에 정밀도 높은 신호로 쓰입니다. 퍼지 중복 제거 후 영어 $1.8$T, 다국어 $1.85$T 토큰이 남고, 교육용/비교육용으로 분류한 뒤 교육용은 수학, 컴퓨터과학, STEM, 비STEM 으로 나누고 교육 수준까지 부여합니다. 책과 저널은 출판사와의 직접 계약 등으로 확보하며, 제공자별 전용 수집 파이프라인으로 표준 텍스트로 변환한 뒤 OCR 정리, 휴리스틱 필터링, 정확/제목/퍼지 중복 제거를 거치고, LLM 으로 주제와 품질 라벨을 달아 혼합 제어에 씁니다.
공개 GitHub 코드 파이프라인
$7.4$T 토큰 규모의 코드 코퍼스는 공개 GitHub 저장소에서 와서 파일(files), 커밋(commits), pull request(PRs)의 세 데이터셋으로 조직됩니다. 공통적으로 node_modules, build, __pycache__ 같은 잡동사니 폴더 제거, _pb2.py나 .d.ts 같은 생성 코드 탐지, 바이너리/이미지/문서 등 비코드 파일 제외, $30$K 자 초과 파일 거부 등 휴리스틱 필터를 적용하고, SHA-512 정확 중복 제거에 이어 MinHashLSH 퍼지 중복 제거와 Qwen3-Embedding-0.6B 의 1024 차원 임베딩 코사인 유사도 기반 의미적 중복 제거를 수행합니다. 추론 학습/평가에 쓴 코딩 문제에 대한 오염 제거도 거칩니다. 파일 데이터셋은 StarCoder2 류 필터를 추가하고 저장소를 깊이 우선 순서로 정렬해 저장소 단위 시퀀스로 잇고, 커밋은 저장소당 최신 $10$K 개를 뽑아 수정 전 상태를 손실 마스킹 접두로 두고 패치만 학습합니다. PR 은 제목/본문/이슈/리뷰/스레드와 구성 커밋을 모아 만들되 SWE-bench Verified 에 쓰인 PR 을 모두 제거해 오염을 막습니다. 세 데이터셋은 각각 약 $1.26$T, $4.5$T, $1.19$T 토큰으로 패킹됩니다.
중복 제거는 이 파이프라인의 척추입니다. 모델 용량이 커질수록 같은 콘텐츠 반복이 암기와 과적합을 키우고, 고유 토큰이 부족하면 큰 모델일수록 스케일링이 빨리 정체되기 때문입니다. 보일러플레이트 제거, 바이트/해시 단위 정확 중복 제거, 유사도 0.8 의 MinHash LSH 퍼지 중복 제거, 템플릿 페이지 골격화, Qwen3-Embedding-0.6B 임베딩 기반 의미적 중복 제거를 단계마다 적용합니다. 특히 소스 간 중복은 전역 드롭 순서(drop-order)를 두어 가장 높은 순위의 데이터셋에만 인스턴스를 남기고 나머지에서는 제거하는데, 이 순서 선택이 개별 데이터셋의 기여도를 해석할 때 결정적이라는 점을 강조합니다. 한 데이터셋을 손대면 새 중복이 생겨 내용 추가 없이도 데이터가 소스 사이를 옮겨 다닐 수 있기 때문입니다.
데이터 혼합 비율 선택: 183 개 모델과 순위 비불변성
수백 개의 이질적 소스를 고정된 연산 예산 안에서 어떻게 섞을지는 결과 모델을 좌우합니다. MAI 팀은 NLL 목적 함수를 최소화하는 것을 목표로 삼습니다. 다만 데이터 혼합 최적화에는 효용의 정의, 방대한 탐색 공간, 규모 의존 효과, 데이터셋 간 상호작용, 다중 에폭(multi-epoch) 효과, 연산 비용이라는 여러 난관이 얽혀 있습니다. 특히 작지만 고품질인 데이터셋에 큰 가중치를 주면 긴 학습 지평에서 같은 데이터를 너무 여러 번 소비해 수익이 체감하거나 과적합으로 이어질 수 있습니다.
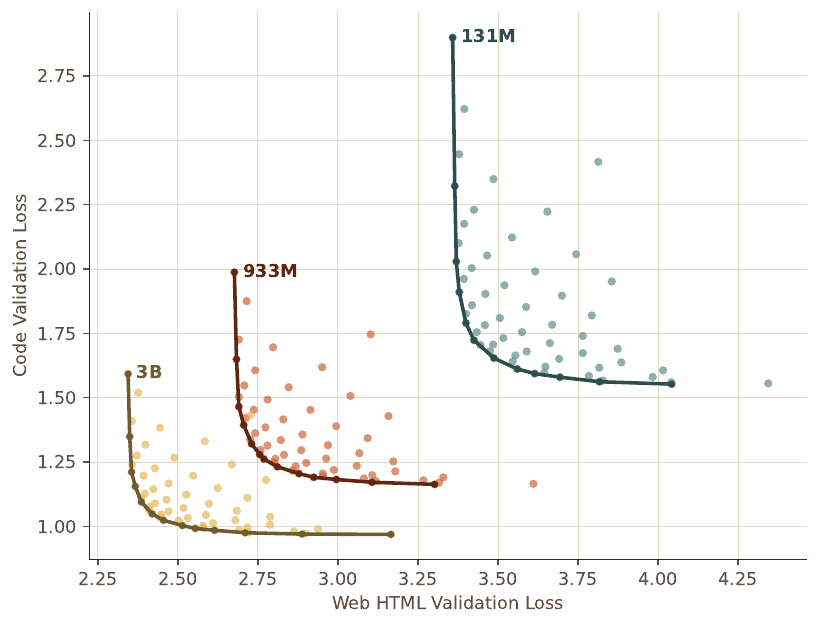
이를 위해 작은 규모에서 수천 개의 모델(각 $760$M~$4$B 활성 파라미터, L12~L36)을 RegMix 류 예측 기반 접근으로 학습하고, 그 평가 결과로 전역 최적 혼합을 추정합니다. 위 그림은 그 예시로, 웹 HTML, 코드, 기타 데이터의 61 개 혼합을 세 가지 규모에서 183 개 모델로 밑바닥부터 학습한 결과입니다. 프론티어 위 모델은 웹과 코드 비중이 높고, 프론티어를 벗어난 모델은 '기타' 비중이 큰 혼합이었습니다.
그런데 이 과정에서 핵심 가정 하나가 깨졌습니다. 바로 두 혼합의 우열 순서가 연산이 커져도 유지된다는 가정이 깨지는 순위 비불변성(rank non-invariance) 의 발견입니다.
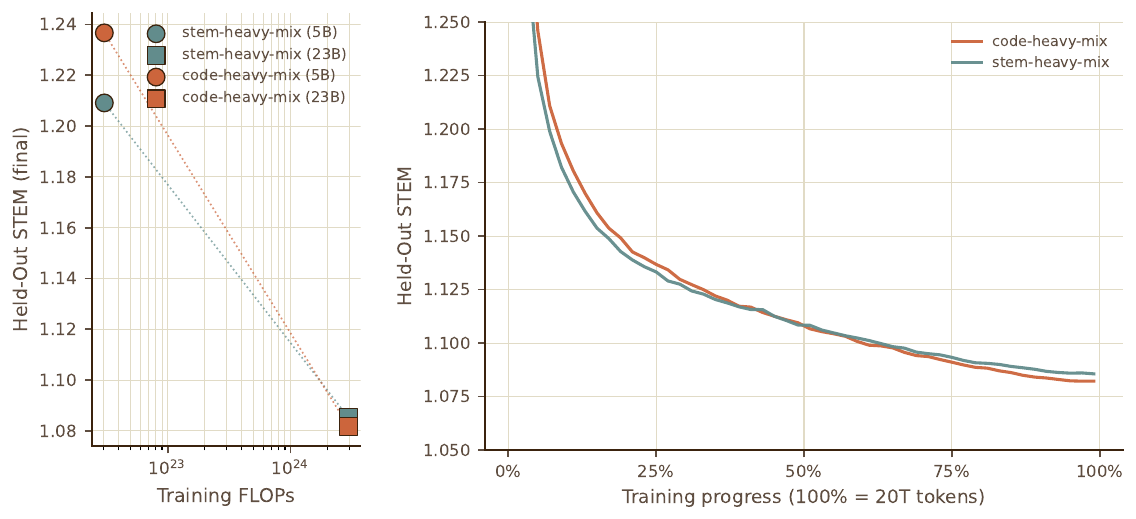
구체적으로, code-heavy-mix(코드 약 50\%)와 stem-heavy-mix(STEM 대폭 상향) 두 후보를 두고 $23$B 활성 파라미터 모델(L66 에 해당)로 약 $20$T 토큰씩 학습했습니다. 작은 규모에서는 예상대로 stem-heavy-mix 가 STEM NLL 에서 앞섰지만, 학습 중반에 두 곡선이 교차하며 code-heavy-mix 가 결국 추월했습니다. 원인을 추적해 보니 STEM 콘텐츠 품질은 높지만 퍼지 중복이 많고 다양성이 부족한 두 소스가 있었는데, 이들의 비중이 stem-heavy-mix 에서는 11.8\%, code-heavy-mix 에서는 0.3\% 였습니다. 작은 모델에는 큰 도움이 됐지만 다양성 부족 탓에 큰 모델에는 덜 유용했던 것입니다. 이 발견 이후로 팀은 고정 규모 성능보다 후보 혼합의 스케일링 거동에 훨씬 더 무게를 두게 됐습니다.
최종 혼합은 데이터를 약 10 개 범주로 나눈 뒤 지역 탐색(범주 내부 비중 조정)과 전역 탐색(범주 간 비중 조정)을 번갈아 수행하는 계층적 방식으로 정했습니다. 어떤 데이터셋도 최대 8 회 반복을 넘지 않도록 상한을 두었고, 유망 후보들을 전역 혼합 때보다 약 2.8\times 더 많은 연산으로 학습해 최적 후보를 골랐습니다. 이 단계에서는 최적 후보가 규모에 따라 바뀌지 않는 좋은 스케일링을 확인했습니다.
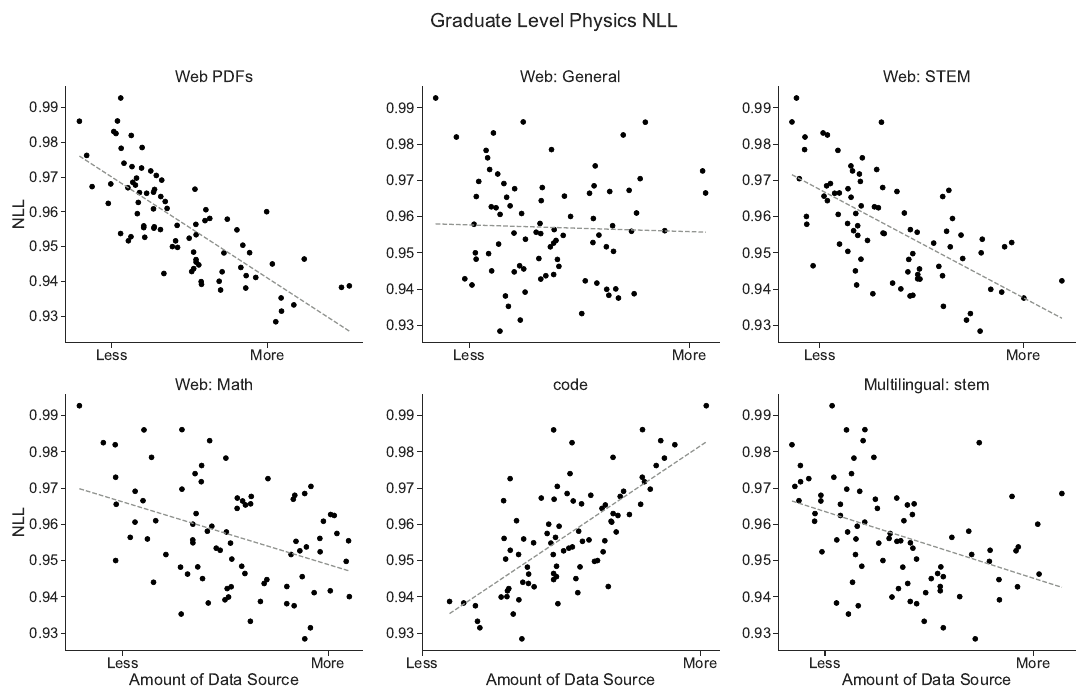
위 그림(Figure 7)은 벤더가 만든 대학원 수준 물리학 평가에서 데이터셋별 기여도를 분석한 것입니다. PDF 데이터셋과 웹에서 추출한 수학/STEM 데이터는 물리학 NLL 에 뚜렷한 양의 효과를 보인 반면, 일반 웹 코퍼스는 대체로 중립적이었고, 다른 데이터를 줄여 코드를 더 넣어도 물리학에는 도움이 되지 않았습니다.
| 소스 패밀리 | 고유 토큰(T) | 학습 토큰(T) | 비중(%) | 평균 에폭 |
|---|---|---|---|---|
| Code | 7.4 | 16.4 | 54.6 | 2.22x |
| STEM | 2.2 | 4.7 | 15.8 | 2.17x |
| Math | 0.3 | 1.6 | 5.4 | 5.28x |
| Books/journals | 0.6 | 0.9 | 3.1 | 1.65x |
| PDFs | 2.7 | 1.4 | 4.7 | 0.53x |
| Web text | 8.1 | 4.5 | 14.9 | 0.55x |
| Multilingual | 8.1 | 0.5 | 1.6 | 0.06x |
| Total | 29.2 | 30.0 | 100.0 | 1.03x |
MAI-Base-1 사전 학습 데이터 구성(Table 5)입니다. 학습 혼합의 대부분은 코드로, $16.4$T 학습 토큰을 평균 2 에폭 남짓 소비합니다. 약 $300$B 개의 고품질 수학 토큰은 평균 5.28\times 로 어느 소스보다 많이 반복 샘플링한 반면, 웹 텍스트와 PDF 는 평균 1 회 미만(0.55\times, 0.53\times)만 소비해 $30$T 학습으로도 전체 코퍼스를 다 쓰지 않았습니다. 다국어는 가용 $8.1$T 중 $0.5$T(0.06\times)만 써서 가장 공격적으로 하향 샘플링했습니다(단, 도메인 특화 다국어 데이터는 각 범주 안에 따로 집계됩니다).
중간 학습용 데이터는 별도 소스를 들이지 않고 사전 학습 코퍼스를 필터링하고 재가중해 만듭니다. 추론 RL 의 토대를 다지려고 STEM/Math 를 35\%, 코드를 55\%, 나머지 배경 소스를 10\% 로 편향시킵니다. STEM 추론 데이터는 Bloom 인지 수준 Analyze 이상, 중간 이상의 추론 깊이와 높은 기술적 정확성을 요구하는 휴리스틱으로 PDF 코퍼스를 거르고, 코드는 저장소 품질 등급(세 등급)별 파일 확장자 필터링과 파일 단위 포맷팅을 추가합니다. 예컨대 HTML/CSS/SVG 같은 웹 자산은 상위 등급 저장소에서는 남기지만 하위 등급에서는 제거합니다. 또한 사전 학습 종료 시점에 과도하게 암기된 소스를 식별하는 암기 인지 에폭 상한(memorization-aware epoch capping)을 적용하는데, 두 체크포인트 사이의 검증 손실 개선 중 거의 확실하게(\text{NLL} < 0.01) 예측된 토큰에서 온 비율로 암기 정도를 추정해 그런 소스에는 더 엄격한 에폭 상한을 둡니다.
학습 레시피: 세 단계와 점진적 컨텍스트 확장
MAI-Base-1 은 시퀀스 길이를 점차 늘려 가며 세 단계로 학습합니다. 사전 학습은 $30$T 토큰을 컨텍스트 16{,}384, GB200 GPU 8{,}192 장에서, 중간 학습 1단계는 $3.4$T 토큰을 컨텍스트 65{,}536 에서, 중간 학습 2단계는 $150$B 토큰을 컨텍스트 262{,}144, GPU 4{,}096 장에서 진행합니다. 사전 학습과 중간 학습 1은 전문가 병렬 64 와 ZeRO-2 를, 중간 학습 2는 ZeRO-3(FSDP)를 쓰며, 컨텍스트 병렬은 두 중간 학습 단계 모두에 적용합니다. 모든 단계가 글로벌 배치 $134$M 토큰을 씁니다.
| 단계 | 토큰 | 컨텍스트 길이 | GB200 GPU |
|---|---|---|---|
| Pre-training | 30T | 16,384 | 8,192 |
| Mid-training 1 | 3.4T | 65,536 | 8,192 |
| Mid-training 2 | 150B | 262,144 | 4,096 |
최적화는 AdamW(\beta_1 = 0.95, \beta_2 = 0.925)에 일정 가중치 감쇠 0.1 을 쓰되, 어텐션 가중치는 0.01, 임베딩 가중치는 0.005 로 정규화를 줄이고 전역 기울기 노름을 1.0 으로 자릅니다. 학습률은 약 $12$B 토큰의 선형 워밍업 뒤 코사인 스케줄로 최고 2 \times 10^{-4} 에서 최저 2 \times 10^{-5} 까지 감쇠하는데, 흔한 0.01\times 가 아니라 최종/최고 비율을 0.1\times 로 둔 것은 학습률을 덜 떨어뜨리는 편이 RL 이후 결과를 개선했기 때문입니다. 중간 학습 1은 워밍업 없이 최고 2 \times 10^{-5}, 최저 1 \times 10^{-5} 의 코사인 감쇠를, 중간 학습 2는 워밍업 없이 일정 학습률 1 \times 10^{-6} 을 씁니다. 모든 층 출력에 잔차 덧셈 전 드롭아웃 0.15 를 적용하는데, 이렇게 높은 드롭아웃은 표준은 아니지만 가중치 감쇠와 상보적인 정규화 효과를 주어 평가 성능을 높였습니다.
어텐션 초기화에는 흥미로운 통찰이 있습니다. 초기화 직후 어텐션 softmax 는 거의 균일해 인과 제약하의 평균 풀링처럼 작동하고, 이는 토큰 표현의 다양성을 떨어뜨려 뒤따르는 MoE 층의 라우팅 불균형을 키우며 깊이가 깊을수록 심해집니다. 이를 막으려고 출력 RMSNorm 게인을 0 으로 두어 어텐션 출력을 영으로 초기화합니다. 그러면 모델은 처음에는 토큰별 피드포워드 더미처럼 행동하다가 토큰 간 상호작용이 학습 과정에서 서서히 켜집니다. 마치 신입 팀원에게 처음부터 모두와 얽혀 일하라고 시키는 대신 각자 자기 일부터 익히게 한 뒤 협업을 점차 늘리는 것과 같아, 초기의 라우팅 쏠림을 크게 줄이고 이는 EG 로 측정한 품질 이득으로 이어졌습니다. (무작위 초기화와 영 초기화의 비교 실험은 보고서의 Figure 8을 참고해주세요)
수치 정밀도는 BF16 을 기본으로 하되, 순전파 GEMM 에 FP8 E4M3, 데이터 기울기에 FP8 E5M2, 가중치 기울기 계산에 BF16(FP32 누적)을 씁니다. 모든 FP8 연산은 절댓값 최댓값의 1024 단계 이력을 쓰는 지연 스케일링(delayed scaling)을 적용하고, 높은 정밀도에서 낮은 정밀도로 기울기가 흐를 때는 확률적 반올림(stochastic rounding)을 씁니다. 어텐션 점수, MoE 라우터 로짓, 최종 출력 로짓 같은 softmax 직전 활성, MoE 결합, 입력 임베딩부터 출력까지의 잔차 스트림 전체는 FP32 로 유지합니다. 옵티마이저의 주 파라미터와 모멘텀 버퍼, AdamW 계산, 데이터 병렬 all-reduce 버퍼도 전부 FP32 입니다.
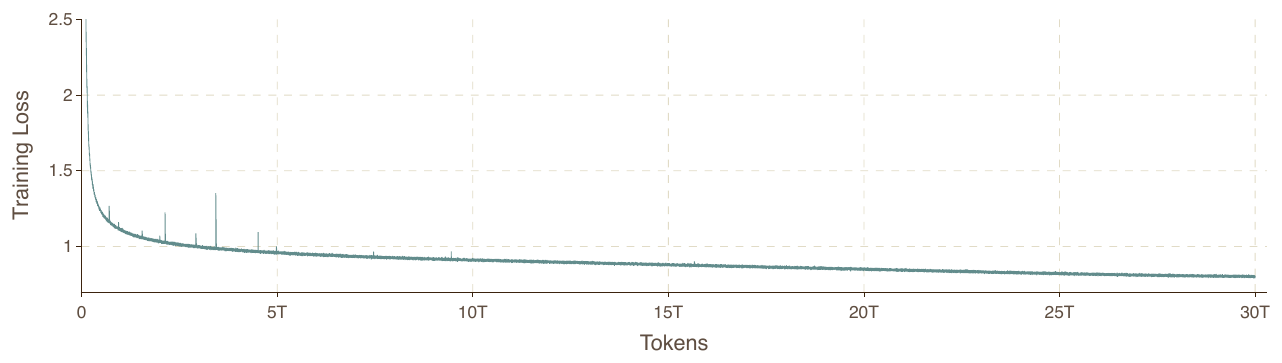
손실 곡선에서 초기 스파이크는 주로 코딩 데이터셋에 영향을 주었고 무탈락 라우팅하에서의 높은 전문가 불균형, 즉 소수 전문가로의 토큰 쏠림과 상관관계를 보였습니다. 다만 매번 손실이 빠르게 회복되어 "어떤 학습 배치도 건너뛰지 않았고, 학습 도중 설정에 수동 개입을 전혀 하지 않았다"고 보고합니다.
부록 B 의 컨텍스트 확장은 $16$K 사전 학습, $64$K 중간 학습, $256$K 짧은 확장의 단계적 방식을 따릅니다. 전 구간을 $256$K 로 학습하면 긴 시퀀스에서 MFU 가 낮아 비현실적이기 때문입니다. 흥미롭게도 확장 단계의 데이터 혼합은 손댈수록 나아지지 않았습니다. 긴 컨텍스트 문서를 상향 가중하거나 도메인별 비율을 조정하는 여러 변형을 실험했지만 어느 것도 의미 있는 개선을 내지 못했고, 직전 중간 학습 단계와 동일한 혼합을 목표 시퀀스 길이로 다시 패킹하는 가장 단순한 방법이 가장 잘 작동해 최종 모델에도 그대로 채택했습니다. 평가는 사내 코드 저장소를 직렬화해 접두를 늘려 가며 마지막 $16$K 의 NLL 을 재는 Code NLL, 관련 문맥을 멀리 떨어뜨리며 검색 능력을 보는 Retrieval NLL, 문맥 내 증거 위치를 바꿔 가며 정답률을 보는 생성형 QA 로 구성합니다. 확장된 체크포인트는 $16$K 에서 $256$K 까지 NLL 이 단조 감소하고 관련 문맥이 멀어져도 거의 평평한 NLL 을 유지한 반면, 확장하지 않은 모델은 학습 분포의 2\times 를 넘으면 NLL 이 치솟았습니다. 생성형 QA 에서는 최대 4\times 길이 외삽(예: $32$K 학습 모델이 $128$K 까지 정답)도 관찰됩니다. 핵심 발견은 적응이 놀랄 만큼 빠르다는 점으로, NLL 개선의 대부분이 확장 단계 학습 반복의 첫 1~10\% 안에 일어났습니다. 이는 긴 컨텍스트에 필요한 표현이 이미 사전/중간 학습에서 갖춰졌고, 확장 단계는 분포 밖 위치에 맞춰 보정만 한다는 뜻입니다. 최종 모델은 보수적으로 $64$K 중간 학습 뒤 $256$K 로 $140$B 토큰을 확장하는 레시피를 택했고, 같은 단계적 방식은 약간의 추가 연산만으로 $1$M 토큰 이상으로도 자연스럽게 확장될 수 있습니다.
동시대 모델과의 비교: BPB 결과
MAI 팀은 사후 학습을 거치지 않은 기반 모델끼리, 개발에 쓰던 NLL 평가의 일부에서 비교를 수행합니다. 토크나이저가 달라도 불변인 바이트당 비트(bits-per-byte, BPB) 값을 보고하며, NLL 평가가 대부분의 API 로는 불가능하기 때문에 오픈 가중치 모델인 DeepSeek v3.2, DeepSeek v4 Pro, Kimi-K2, Gemma4-31B 와 비교합니다. 여기에 동일하게 $30$T 토큰으로 학습한 자사 이전 세대 $23$B 모델(L66)도 넣어 진전을 가늠합니다. 다국어 벤치마크는 공개 출처라 신뢰할 만한 비교가 어려워 제외했습니다.
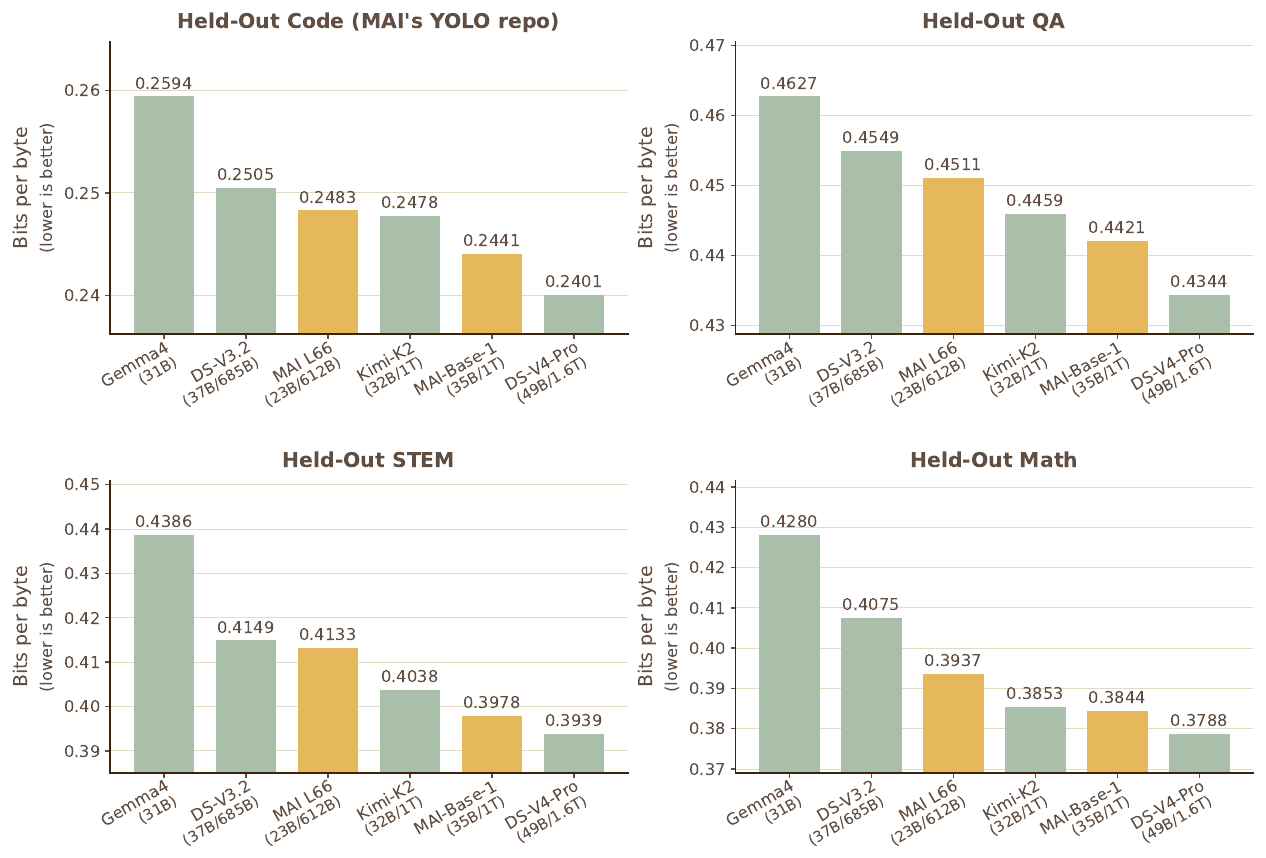
결과는 명확합니다. MAI-Base-1 은 활성 파라미터 수가 비슷한 모델들에 대해 네 과제(Code, QA, STEM, Math) 모두에서 더 낮은 BPB 를 달성했습니다. 가장 좋은 성적은 활성 파라미터 1.4\times, 전체 파라미터 1.6\times 규모의 DeepSeek-v4 가 차지했습니다. 인상적인 점은 자사의 $23$B 모델이 활성 파라미터의 62\% 만 쓰고 전체 파라미터는 비슷한 수준에서 DeepSeek v3.2 기반 모델을 능가했다는 것으로, 규모 대비 효율의 진전을 보여 줍니다.
YOLO: 대규모 분산 학습
YOLO(You Only Launch Once) 는 MAI 가 MAI-Thinking-1 개발 전반에 쓴 사내 대규모 학습 프레임워크입니다. PyTorch 위에 구축했으며 사전 학습, 중간 학습, 지도 미세조정, 그리고 RL 의 학습 부분까지 모든 단계를 지원합니다. Megatron-Core, DeepSpeed, TorchTitan 의 경험을 흡수하되 커널부터 병렬화, 스케줄링까지 끝에서 끝까지 완전한 통제권을 갖기 위해 밑바닥부터 직접 만들었습니다. 학습 속도, 굿풋(goodput), 결정성(determinism), 유연성, 개발 민첩성을 동등하게 우선한다는 점이 설계 철학입니다.
YOLO 는 Triton, CUDA, CuteDSL, CUTLASS 로 작성한 커스텀 커널 모음을 갖습니다. FP8 지연 스케일링을 지원하는 FP8 GEMM, GPU 하나가 보통 전문가 8 개를(512 전문가에 전문가 병렬 64) 호스팅할 때 효율을 높이는 그룹 GEMM, 순방향과 전치 텐서를 함께 양자화하며 스케일 인자 스위즐링까지 적용하는 융합 양자화 커널 등이 포함됩니다. 비그룹 양자화 커널은 Blackwell 전용 동적 커널 부하 분산 기능인 Cluster Launch Control(CLC)도 지원합니다. 텐서 샤딩은 JAX 나 PyTorch DTensor 와 비슷한 커스텀 샤딩 주석으로 각 파라미터의 분할을 독립적으로 정의하되, 주석을 순수하게 서술적으로만 두어 의도치 않은 동기화 지점이 끼어들지 않게 합니다. 덕분에 임베딩/손실/어텐션 가중치에는 텐서 병렬을 쓰고 MLP/MoE 가중치에는 쓰지 않는 식의 유연한 병렬화(parallel folding)가 가능합니다.
병렬화는 데이터(ZeRO 1~3 자체 구현), 텐서/컨텍스트, 전문가, 파이프라인 병렬을 모두 지원합니다. ZeRO 구현은 항상 파라미터를 샤딩된 형태로 저장해 분산 AdamW 와 분산 체크포인트를 단순화하고, 모든 사전 학습 런은 NVLink 도메인 안에서 전문가 병렬을, 랙 간에는 데이터 병렬을 씁니다. 컨텍스트 병렬(Ulysses 방식)은 MAI-Base-1 에서 긴 컨텍스트 중간 학습에만 썼고 텐서/시퀀스 병렬은 전 단계에 썼습니다. ZeRO 데이터 병렬로 학습할 때 활성값이 HBM 대부분을 차지했기 때문에, 활성 체크포인팅(층 단위부터 층 내 미세 재계산까지)과 호스트 메모리로의 활성 오프로딩을 함께 써서 단일 NVLink 도메인 안에서 전문가 병렬을 가능하게 했습니다. MoE 층은 무탈락/용량 제한 모드를 모두 지원하고, 디스패치/연산/수집 단계를 그룹별로 파이프라인화해 첫 디스패치와 마지막 수집을 빼면 통신이 전문가 연산과 겹치게 합니다. 무탈락 모드의 메모리 출렁임과 OOM 을 막기 위해, 그룹마다 고정 용량 단위로 여러 라운드를 돌리고 역전파에서 라운드별 미세 재계산을 하는 정적 메모리 무탈락 모드도 둡니다.
결정성은 과학적 재현성, 개발 민첩성, 시스템 건강 디버깅을 위해 MFU 손해를 감수하고서라도 강제합니다. 데이터 파이프라인의 마이크로배치 순서를 고정하고, 모델 가중치/옵티마이저 상태/FP8 스케일 이력/데이터로더 진행/난수 생성기까지 모든 상태를 체크포인트에 저장하며, 부동소수점 누적의 비결합성 때문에 RMSNorm 역전파는 두 단계 타일 축소로, MoE top-k 선택은 안정 정렬(stable sort)로 순서를 고정합니다. 또한 NVLink SHARP 을 끄고 일관된 NCCL 토폴로지를 강제해, "동일한 하드웨어 자원과 설정으로 돌린 두 학습 런은 비트 단위로 동일한 모델을 만들어 낸다"는 비트와이즈 재현성을 보장합니다. 골든(golden) 설정에 대해 손실/기울기 노름/가중치 체크섬을 정확 비교하는 테스트로 수치적 정확성을 추적하기도 합니다. 결함 내성은 PyTorch DCP 를 다시 작성해 CPU 메모리 오버헤드와 체크포인트 저장 시간을 10\times 넘게 줄인 분산 체크포인트(저장 계획 사전 계산/캐싱, 비동기 저장 포함)와, Ray 액터 핫 스탠바이를 통한 빠른 복구로 확보합니다.
이 절의 백미는 모델 구조와 시스템 성능을 함께 진화시킨 다섯 세대(v1~v5) 중 GB200 에서 추적한 네 세대(v2~v5)의 공동 설계 기록입니다. 추적한 두 지표는 MFU 와 효율 이득이며, MFU 는 GB200 한 장의 BF16 텐서 코어 처리량(2.5 \times 10^{15} FLOPS)을 기준으로 정규화합니다(H100 프로토타입 v0/v1 은 제외). 개발 전체에 걸쳐 20 개가 넘는 인프라/커널 최적화가 도입되어 모든 세대가 MFU 20\% 이상을 유지했습니다.
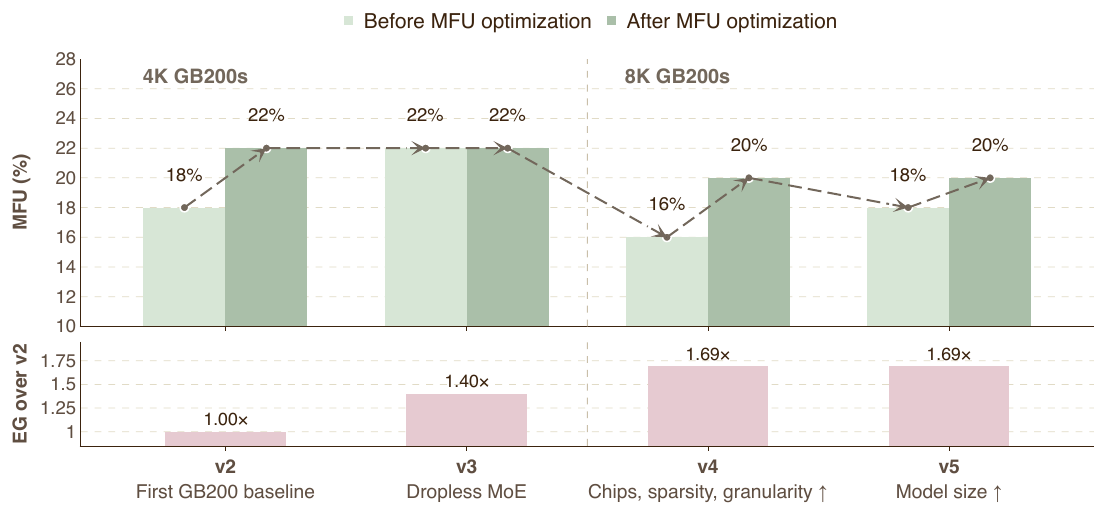
| 항목 | v2 | v3 | v4 | v5 (MAI-Base-1) |
|---|---|---|---|---|
| 활성/전체 | 23B/600B | 23B/600B | 23B/611B | 35B/1T |
| 층 | 54 | 54 | 66 | 78 |
| 전문가 용량 계수 | 2 | 무제한 | 무제한 | 무제한 |
| Top-k/전문가 | 4/192 | 4/192 | 8/512 | 8/512 |
세대별 이야기는 이렇습니다. v2 는 GB200 NVL72 클러스터에서 GPU 4{,}096 장으로 돌린 첫 $23$B 모델로, 랙당 64 GPU(NVL64)로 노드 장애에 대비했습니다. 전문가 병렬 64, 텐서 병렬 1 로 모든 전문가 all-to-all 을 NVL64 도메인 안에 가두어 초기 MFU 18\% 로 출발했고, GPU Direct RDMA(1.1\times), 커스텀 블록 희소 어텐션(1.06\times), ZeRO-2(1.03\times), Triton 전문가 인코드 커널(1.03\times)을 더해 MFU 를 18\% 에서 22\% 로 올렸습니다. v3 는 용량 제한 라우팅을 무탈락 MoE 로 바꿔 전문가 용량 패딩을 없애고 더 나은 부하 균형 정책을 쓰면서 v2 와 비슷한 MFU 를 유지했습니다. v4 는 전문가를 192 개에서 512 개로, 라우팅을 top-4 에서 top-8 로 늘리고 LatentMoE 를 도입하며 학습을 4{,}096 장에서 8{,}192 장으로 확장했는데, 작아진 GEMM 탓에 CPU 실행 오버헤드가 부각되어 초기 MFU 가 22\% 에서 16\% 로 떨어졌다가 FA4 결정성 커널(블록 희소 대비 1.14\times) 등으로 20\% 로 회복했습니다. 마지막 v5(MAI-Base-1)는 활성 파라미터를 $23$B 에서 $35$B 로, 전체를 $600$B 에서 $1$T 로 키워 파라미터와 활성값 메모리 부담을 크게 늘렸습니다.
강화 학습 클라임(The RL Climb): 무에서 추론을 쌓아 올리는 등반
사전 학습과 중간 학습을 마친 MAI-Base-1 은 폭넓은 예측 능력과 지식을 갖추고 있지만, 모델이 어떻게 행동해야 하는지, 긴 호흡의 과제(long-horizon task)를 어떻게 풀어야 하는지, 추론 시점의 연산을 어떻게 배분해야 하는지는 아직 정해져 있지 않습니다. 보고서 3장의 강화 학습 클라임(RL climb) 은 바로 이 빈칸을 채우는 단계로, 과제별 피드백에 맞춰 모델을 최적화해 답하기 전에 사고 사슬(chain of thought, CoT)을 생성하고, 외부 도구를 사용하며, 환경과 상호작용하고, 선호도 및 안전 신호를 따르도록 만듭니다.
핵심은 MAI-Thinking-1 이 Microsoft 의 첫 자체 추론 모델이라는 점입니다. 즉 추론 트레이스(reasoning trace)에 한 번도 노출된 적 없는 체크포인트에서 출발해, 추론 능력을 그야말로 맨바닥에서부터 길러 올려야 했습니다. 이는 마치 다른 등반가가 박아 놓은 볼트(bolt) 없이 처음부터 절벽을 오르는 것과 같아서, 장기적인 학습 안정성이 가장 큰 난제가 됩니다. 보고서는 이를 세 가지 메커니즘으로 가능하게 했다고 설명합니다. (i) GRPO 에 가한 두 가지 단순하지만 결정적인 수정, (ii) 크래시나 기반 정책 교체 이후 클라임을 재개하기 위한 자기 증류(self-distillation), 그리고 (iii) 학습과 추론 사이의 수치 불일치(numerical mismatch)를 제거하는 인프라 개선입니다.
병렬 개발을 위해 팀은 세 개의 도메인 전문가(specialist) 모델을 따로 학습했습니다. STEM 및 경쟁 프로그래밍용 모델, 에이전트형 코딩과 도구 사용용 모델, 그리고 유용성과 안전성용 모델입니다. 세 전문가의 클라임은 동일한 레시피를 따르되 프롬프트 분포와 보상 대상만 다릅니다. 이후 이들을 SFT 로 단일 모델에 통합하고, 가벼운 최종 RL 클라임을 거쳐 MAI-Thinking-1 을 완성합니다.
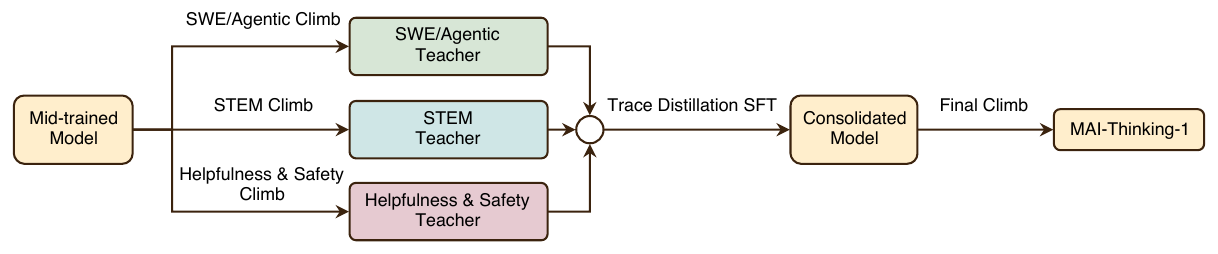
강화 학습 레시피(RL Recipe)
세 전문가 모두 공유하는 학습 레시피는 RL 목적 함수, 보상 설계, 샘플링 전략, 자기 증류, 하이퍼파라미터로 구성됩니다.
RL 목적 함수와 GRPO 에 대한 두 가지 수정
클라임은 정책 \pi_\theta 에서 시작합니다. 프롬프트 q 에 대해 롤아웃 정책이 G 개의 응답을 샘플링하고, 각 응답 y_i 는 스칼라 보상 R_i 를 받습니다. 보상 함수는 도메인에 따라 코드 실행 결과, 프롬프트된 AI 판정자(judge), 또는 학습된 보상 모델(reward model)에 기반합니다. 학습 목적 함수는 GRPO에 토큰 수준 정책 경사(token-level policy gradient)를 결합한 형태이며, 정규화는 전역 학습 배치 전체 토큰에 대해 계산해 응답 길이와 무관하게 모든 토큰이 동등하게 기여하도록 했습니다. 응답 수준 어드밴티지 A_i 는 그룹 보상의 평균을 빼고 표준편차로 나눈 값으로, 한 응답 안의 모든 토큰에 공유됩니다.
여기에 두 가지 수정을 더합니다. 첫째는 적응형 엔트로피 제어(adaptive entropy control) 로, 목표 정책 엔트로피를 유지하도록 클리핑 상한을 동적으로 조정합니다. 하한과 상한 클립을 분리하되, 기본 신뢰 영역(trust region) 폭을 정하는 단일 하이퍼파라미터 \epsilon 과, 상한을 엔트로피에 따라 넓혀 주는 완화 항 k 로 매개변수화합니다. 상한이 너무 크면 엔트로피가 폭발하고 너무 작으면 엔트로피가 붕괴하는데, 이를 단순한 적분 제어기(integral controller)로 다스립니다. 매 스텝마다 중요도 가중 추정기로 토큰당 엔트로피를 추정한 뒤, 관측 엔트로피가 목표 H^\star 보다 낮으면 k 를 키워 상한을 넓혀 대안 토큰의 확률을 더 공격적으로 올릴 여지를 주고, 충분히 높으면 k 를 줄여 신뢰 영역을 조입니다. 초기에는 k = 0 으로 두어 클립 구간이 로그 비율 공간에서 대칭이 되게 합니다. 이는 손실에 명시적 엔트로피 보너스 항을 넣는 방식보다 더 잘 작동했다고 합니다. 비유하자면, 끓는 냄비의 불을 직접 약하게 키우는 대신 온도계를 보고 자동으로 화력을 조절하는 자동 온도 조절기를 단 셈입니다.
둘째는 외부 비율 클립(outer ratio clip) 입니다. 원래 GRPO 목적 함수는 두 경우, 즉 어드밴티지가 음수인데 새 정책이 더 높은 확률을 주는 경우(A_i < 0,\ r_{i,t} > 1)와 어드밴티지가 양수인데 새 정책이 더 낮은 확률을 주는 경우(A_i > 0,\ r_{i,t} < 1)를 일부러 클리핑하지 않고 열어 둡니다. 정책이 "올바른 방향으로 스스로를 교정"할 때는 묶어 두지 않으려는 의도였지만, 실제로는 이 열린 분기가 때때로 파국적인 경사 노름 급등(gradient-norm spike)을 일으켰습니다. 그래서 모든 분기에 적용되는 하드 외부 클립을 추가해 r_{max} 는 큰 값으로 두고 r_{min} 은 제약하지 않았습니다(dual-clip PPO 와 같은 취지). 이 2단계 전략은 정상 범위의 비율에 대해서는 표준 신뢰 영역 동작을 보존하면서 극단적 불일치만 버려, 경사 급등을 줄이고 더 안정적인 등반을 가능하게 했습니다. 실제 하이퍼파라미터는 \epsilon = 0.6, k_{max} = 2.5, 스텝 크기 \delta = 0.25, 목표 엔트로피 H^\star = 0.3, r_{max} = 50, r_{min} = 0 으로 설정했습니다.
보상 설계와 샘플링 전략
보상은 도메인별 과제 보상 R_{task}, 언어 일관성 보상 R_{lang}, 길이 페널티 R_{len} 으로 분해됩니다. 컨텍스트 길이가 길어질수록 모델이 CoT 안에 외국어 토큰을 섞기 시작하고, 이것이 학습과 추론 정책 간 로그 확률 발산과 상관되어 학습을 불안정하게 만들기 때문에, 영어 기준 언어 일관성 보상(w_{lang} = 0.5, 단어당 페널티 \alpha = 0.005)을 둡니다. 길이 페널티는 문제 통과율 \rho_q 에 비례하도록 설계해, 통과율이 낮은 어려운 문제는 페널티를 약하게 받아 더 긴 추론을 탐색할 수 있게 하고, 쉬운 문제는 강한 페널티로 군더더기 없는 간결한 추론을 유도합니다. 길이 페널티 계수는 $64$k 확장 단계까지 w_{len} = 0.25 로 두되, 페널티가 최대 길이로 정규화되므로 길이가 늘수록 자연히 약해지며, 마지막 $128$k 단계에서는 아예 제거합니다(w_{len} = 0).
샘플링에서는 추론 비용을 줄이기 위한 조기 종료(early exit) 전략을 씁니다. 먼저 G_{early} = 16 개를 샘플링해 경험적 통과율을 보고, 허용 구간 [0.05, 0.8] 안에 들 때만 전체 G = 128 개를 마저 샘플링하며, 이후 다시 [0.1, 0.8] 통과율 필터로 거의 다 맞거나 다 틀린 저분산 그룹을 제거합니다. 롤아웃은 p = 0.97 의 top-p 샘플링으로 생성하되, 샘플링된 뉴클리어스 바깥 토큰을 통해 역전파하면 파국적 오프폴리시(off-policy) 불일치가 발생하므로 top-p 절단 마스크를 재사용해 해당 토큰의 로짓을 음의 무한대로 막습니다. 또한 초기에는 최대 롤아웃 길이를 $8$k 토큰으로 제한했다가 2 의 거듭제곱으로 늘려($16$k, $32$k, $64$k) 최종 $128$k 토큰까지 확장하는 길이 확장 커리큘럼(length extension curriculum)을 적용해, 저성능 구간의 추론 비용을 크게 줄였습니다.
자기 증류로 수천 스텝의 로그-선형 향상 지속하기
중간 학습 체크포인트에서 강한 성능에 도달하려면 매우 많은 RL 스텝이 필요합니다. 이를 실용적으로 만든 것이 자기 증류(self-distillation) 입니다. RL 중 생성한 롤아웃을 모아 중간 학습 체크포인트에 SFT 를 수행하고, 그 모델을 다시 클라임의 출발점으로 삼아 이전 단계에서 발견한 능력을 보존합니다. 자기 증류는 네 가지 용도로 쓰입니다. (1) 초기 클라임에서 도메인별 프롬프트로 목표 행동을 이끌어내고, 원시 텍스트 프롬프트에서 자체 채팅 형식으로 옮겨 가는 다리 역할을 합니다. (2) 드물게 발생하는 런 붕괴에서 진척을 이어받습니다. 일부 불안정성은 실제 붕괴가 일어나기 수백 스텝 전부터 이미 파라미터에 박혀 있어 붕괴 직전 체크포인트에서 재개하는 것이 통하지 않기 때문입니다. (3) 새 사전/중간 학습 체크포인트가 나오면 이전 진척을 다음 세대로 이월합니다. (4) 보상 해킹(reward hacking)을 보이는 샘플을 걸러냅니다.
보고서의 Figure 15 는 STEM 클라임 동안 AIME 2025 와 LiveCodeBench v6 의 어려운 하위 집합에서 성능이 어떻게 올라가는지를 추적해 이 메커니즘을 시각적으로 입증합니다. 학습 곡선에는 자기 증류 지점이 별표로, 사전/중간 학습 버전이 서로 다른 색으로 표시되는데, 붕괴는 성능이 갑자기 꺾이는 형태로 드러나고 그 직후 자기 증류로 수치를 초기화해 등반을 이어 가는 패턴이 반복됩니다. 동시에 그래프 하단에는 최대 출력 길이가 함께 표기되어, 길이 확장 커리큘럼이 성능 향상과 맞물려 진행됨을 보여 줍니다. 인프라와 알고리즘 안정성 개선이 도입되면서 런 붕괴로 인한 자기 증류 빈도 자체가 점차 줄었다고 보고합니다.
초기 자기 증류 이전에는 <think> </think> 와 <answer> </answer> 태그로 추론 과정과 답을 감싸도록 지시하는 프롬프트 템플릿을 사용했는데, 이는 DeepSeek-R1에서 가져온 것입니다. 보고서가 자기 증류로 알아낸 모범 사례들은 다음과 같습니다. 약 100 만(O(1\text{M})) 개의 추론 트레이스면 교사 성능을 따라잡으면서 SFT 의 안정성 이점을 유지하기에 충분하며, 그 이상은 수익이 줄고 정책 분포를 과도하게 좁힐 위험이 있습니다. 또 클라임 후반의 강한 체크포인트들에서 뽑은 트레이스를 쓰는 것이 중요한데, 아주 이른 체크포인트의 트레이스를 섞으면 성능이 눈에 띄게 떨어지고, 반대로 최종 체크포인트 하나에서만 뽑아도 약했습니다. 단일 최종 정책 하나보다 여러 강한 체크포인트의 다양성이 더 나은 탐색으로 이어졌기 때문입니다. 보고서의 표현을 빌리면, "고정된 토큰 예산에서는 프롬프트당 트레이스 수를 늘리는 것보다 프롬프트 다양성을 늘리는 것이 더 가치 있다"는 것입니다. 단순 무작위 샘플링이 최단 트레이스 선택이나 휴리스틱 필터링 같은 편향된 전략보다 나았습니다. 다만 짧은 최대 길이로 학습된 초기 RL 트레이스만 쓰면 모델이 중간 학습의 긴 컨텍스트 능력을 잊기 쉬워, 길이 확장 전에는 중간 학습 데이터를 함께 섞었습니다.
흥미롭게도 정답으로 이어진 트레이스만 학습하든 오답 트레이스를 포함하든 성능이 비슷했지만, RL 이 이미 100 만 개를 훨씬 넘는 성공 트레이스를 만들어내므로 결국 성공 트레이스로만 제한했습니다. 자기 증류 SFT 는 전역 배치 크기 2{,}048, 시퀀스 길이 $128$k, AdamW(weight decay 0.001)와 cosine 학습률 스케줄(최대 1.7 \times 10^{-5}, 최소 5.2 \times 10^{-6}, warmup 비율 2\%)로 진행하며, 드롭아웃(dropout)을 비교적 높은 0.15 로 두어 엔트로피를 높이고 모델 붕괴를 막습니다. MoE 부하 균형 계수는 자기 증류 시 1 \times 10^{-2} 로 크게, RL 시 1 \times 10^{-5} 로 작게 두는 비대칭 전략을 씁니다. 메인 RL 클라임 자체는 일정 학습률 \eta = 10^{-6}(긴 길이 단계에서는 9 \times 10^{-7} 로 인하), 패킹 후 전역 배치 7040(언패킹 시퀀스 최대 12000), 추론 모델 업데이트 사이 5 회 경사 스텝, 그리고 8 회 추론 업데이트(40 경사 스텝) 이상 오래된 롤아웃은 폐기하는 완전 비동기(asynchronous) 방식으로 운영됩니다.
STEM 클라임(STEM Climb)
STEM 클라임은 세 도메인 클라임 중 가장 긴 학습으로, 수학, 물리, 화학, 경쟁 프로그래밍을 아우르는 단일 턴(single-turn) 문제 해결 능력을 강화합니다. 핵심은 데이터 품질이며, 모든 STEM 클라임은 검증 가능한 데이터(verifiable data) 쌍 위에서 돌아갑니다. 즉 모든 인스턴스는 질의와 정답 쌍 (q, a) 이거나, 질의와 테스트 케이스 집합 쌍 (q, \{t_1, \dots, t_n\}) 입니다. 과제 보상은 모델의 최종 답을 추출해 SymPy 같은 형식 검증기(formal verifier), AI 판정자, 또는 경쟁 코딩의 경우 테스트 케이스 실행으로 매깁니다. 파이프라인 설계의 세 기준은 높은 품질, 적절한 난이도, 주제 다양성입니다.
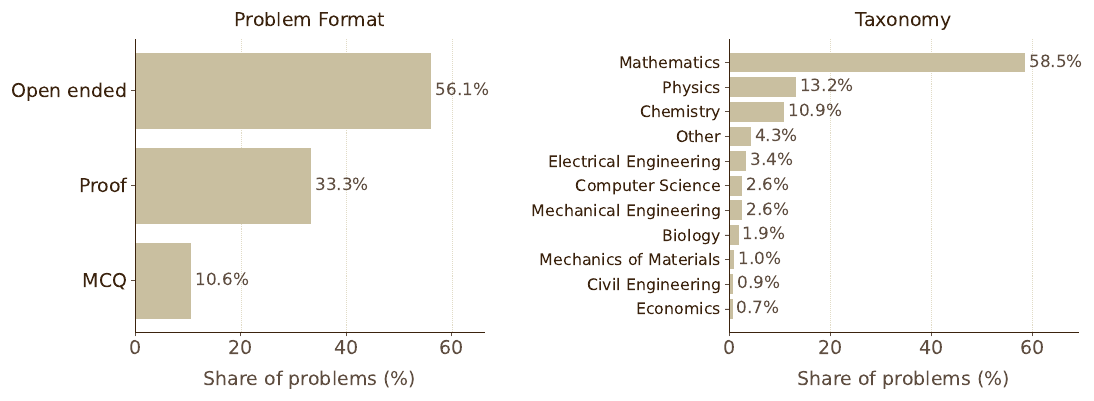
이 파이프라인으로 수백만 건의 문서를 처리해 $5$M 개가 넘는 샘플의 STEM Mix 데이터셋을 만들었고, 그중 가장 어려운 부분만 $550$k 개가 넘는 (q, a) 쌍입니다. 문제 형식은 개방형(open-ended)이 56.1\%, 증명(proof)이 33.3\%, 객관식(MCQ)이 10.6\% 이고, 주제 분류로는 수학이 58.5\% 로 절반을 넘고 물리가 13.2\%, 화학이 10.9\% 를 차지하며 전기공학, 컴퓨터과학 등 다양한 분야가 뒤를 잇습니다. 객관식과 증명 문제는 수집 단계에서 개방형으로 변환하되(변환이 불가능하면 폐기), 형식 친숙도를 위해 객관식 일부는 남겨 둡니다.
교과서 추출 파이프라인
이 데이터의 출처는 교과서, 학술 PDF, 포럼 토론, 대회 아카이브, 벤더 데이터 등 이질적인 원천입니다. 파이프라인은 각 처리 단계를 독립적인 비동기 스테이지로 구현한 조합 가능한 구조로, 네 단계로 나뉩니다. 노이즈나 환각(hallucination)에 민감한 스테이지는 여러 번 돌려 합의 투표(consensus voting)로 결정합니다.
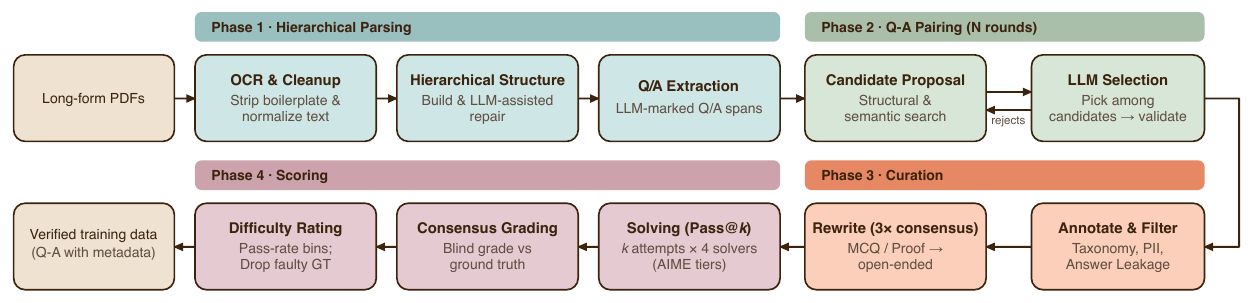
1단계 계층적 파싱(hierarchical parsing) 에서는 비전-언어 모델이나 OCR 서비스로 문서를 읽고, STEM 이 없는 페이지와 보일러플레이트를 제거하며, 구조적 단서로 계층 표현을 만들어 깨진 상호 참조와 페이지 분할 아티팩트를 복원합니다. 이후 LLM 이 질문/답변 구간을 표시해 후보 (q, a) 쌍을 만듭니다. 2단계 Q-A 페어링 은 질문과 답이 떨어져 있는 경우(장 끝 연습문제와 부록 해답 등)를 다회 라운드로 매칭하며, 구조 신호와 의미 유사도로 후보를 찾은 뒤 LLM 이 최적 답을 골라 검증합니다. 3단계 큐레이션(curation) 에서는 검증 가능성, 질문 유형, 분류, PII 검출, 정답 누출(answer leakage)을 LLM 분류기로 거르고, 객관식과 증명을 개방형으로 변환(3회 실행 후 합의, 합의 실패 시 폐기)하며 비수학적 군더더기 텍스트를 정리합니다. 4단계 채점(scoring) 에서는 각 문제를 AIME 2025 성능을 능력 대리지표로 삼은 네 단계 모델 티어가 k 회씩 풀어 통과율로 난이도 구간을 나눕니다. 특히 가장 강한 티어가 낮은 통과율로만 푼 문제는 그 모델의 합의 답과 정답을 무작위 순서로 판정자에게 보여, 판정자가 합의 답을 선호하면 정답이 의심스러운 문제로 폐기하고 정답을 선호하면 진짜 어려운 문제로 보존하는 맹검 채점(blind grading)을 적용합니다.
경쟁 코딩 데이터는 문제마다 테스트 케이스가 필요해 별도 파이프라인을 씁니다. PDF 같은 비정형 출처에서는 충실한 테스트 케이스를 찾기 어려우므로 표적 출처와 벤더 데이터에 의존하며, 각 문제는 모든 테스트를 통과하는 참조 풀이를 함께 확보하고 실행 시간/메모리 제약도 담습니다. 총 $160$k 개 문제를 분할정복, 동적 계획법, 그래프/트리 알고리즘, 탐색 등 다양한 주제에 걸쳐 수집해 Python, C++, C#, Java, JavaScript, Rust, TypeScript 등 17 개 프로그래밍 언어를 지원합니다. 두 데이터셋 모두 SHA-256 정확 중복 제거, 문자 n-gram MinHash 기반 어휘 퍼지 중복 제거, 임베딩 기반 벡터 중복 제거의 3단계로 자체 중복 제거와 벤치마크 오염 제거(decontamination)를 거칩니다.
부록 C.1: 약한 모델은 추측하고 강한 모델은 묵묵히 일한다
부록 C.1 은 이 클라임에서 CoT 가 어떻게 진화했는지 구체적인 AIME 문제로 생생히 보여줍니다. 네 가지 대비가 반복됩니다. 첫째, 추측 대 검증입니다. 한 문제에서 강한 모델은 네 후보 k \in \{8, 32, 200, 512\} 를 모두 대수적으로 도출한 뒤 정의역 조건 x > 0 으로 512 를 걸러 합 240 에 도달한 반면, 약한 모델은 보이는 근 18, 72, 98 로부터 최소점을 무작정 추측해 40, 152 같은 가짜 값을 만들어 704 라는 오답을 냈습니다. 둘째, **무차별 대입 대 불변량(invariant)**입니다. 약한 모델은 세제곱이 단위원군에서 전단사라고 잘못 가정해 합동식을 선형화한 반면, 강한 모델은 3 의 거듭제곱에 대한 단위 세제곱이 지수 3 의 부분군(\bmod\ 9 에서 \pm 1)을 이룬다는 진짜 불변량을 찾아냈습니다. 셋째, 회의론입니다. 강한 모델은 "Wait, let's re-examine" 하며 자기 풀이를 의심하고 작은 사례(1 \times 1 격자)로 검증해 빈 격자가 "maximal" 이라는 약한 모델의 오판을 피했습니다. 이 관찰들은 RL 이 단순 정답률을 넘어 추론 습관 자체를 길러 냈음을 시사합니다.
에이전트형 클라임(Agentic Climb)
에이전트형 클라임은 단일 패스 텍스트 응답이 아니라 외부 환경과의 상호작용이 필요한 과제를 학습합니다. 모델은 사용자 요청을 분해하고, 도구나 코드 행동을 고르고, 결과를 관찰하며, 여러 스텝과 턴에 걸쳐 계획을 수정해야 합니다. 학습 신호는 소프트웨어 환경에서 테스트가 통과하거나 데이터베이스가 목표 상태에 도달하는 등의 검증 가능한 보상과, 과제 해석, 유용성, 궤적 품질처럼 정확히 명세하기 어려운 측면에 대한 AI 피드백 보상을 결합합니다. 흥미롭게도 STEM 과제(경쟁 코딩 포함)를 섞으면 RL 클라임이 안정화되고 다단계 소프트웨어 엔지니어링 성능으로 긍정적 전이가 일어난 반면, 에이전트형 과제는 STEM 단일 패스 성능에 긍정적이지도 부정적이지도 않았습니다. 두 도메인을 다룹니다. 실제 저장소로 만든 소프트웨어 엔지니어링(SWE) 환경과, 구조화된 도구를 다단계로 호출하는 일반 도구 사용(general tool use)입니다.
에이전트형 루프와 다단계 오케스트레이션
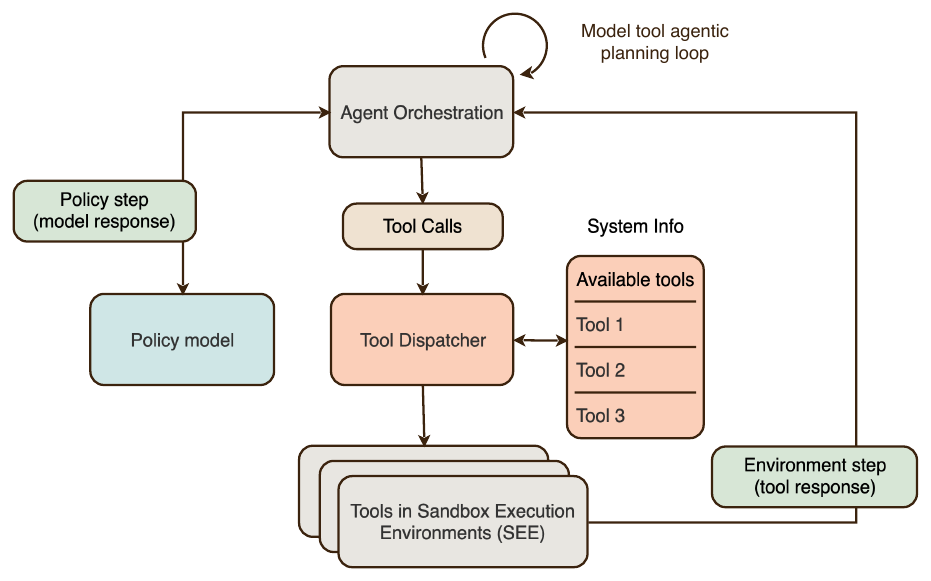
다단계 RL 은 앞서의 단일 스텝 목적 함수를 그대로 쓰되, 롤아웃을 단일 응답에서 정책 스텝과 환경 스텝(관찰)이 교차하는 궤적(trajectory)으로 확장합니다. 각 RL 환경은 과제 명세, 도구 실행용 Sandbox Execution Environment(SEE) 세션, 그리고 과제 완료를 평가하는 검증/판정 보상으로 구성됩니다. 오케스트레이션 하네스는 ReAct 스타일 루프로, 모델의 추론과 행동을 파싱해 도구 호출을 SEE 로 보내고 반환된 관찰을 컨텍스트에 덧붙인 뒤 다음 행동을 위해 정책에 제어권을 돌려줍니다. 이전 스텝의 모든 토큰은 다음 스텝의 엄격한 접두사(strict prefix)로 보존되며, 모델이 더 이상 도구를 호출하지 않거나 스텝/컨텍스트/시간 예산을 초과하면 루프가 종료되고 궤적 전체가 채점됩니다. 채점기는 형식 검사, 규칙 기반 검사, 실행 테스트, 검증 가능한 상태 비교, AI 판정자를 결합합니다. 신용 할당(credit assignment)은 모든 정책 스텝의 모든 토큰에 균일하게 적용됩니다. SEE 는 과제마다 신선한 컨테이너를 띄우고 끝나면 파기해, 재현성을 보장하고 과제 간 상태 누출을 막으며, 기본적으로 네트워크를 격리합니다. 패키지 설치 등 네트워크가 필요할 때만 캐싱 프록시와 도메인 허용 목록으로 트래픽을 중개합니다.
SWE 환경 구축
프런티어급 모델을 SWE 과제로 학습하려면 실제 코드베이스와 현실적인 개발 환경이 대량으로 필요합니다. 팀은 공개 GitHub 의 이슈와 PR 을 유기적 데이터의 원천으로 삼아 SWE-ReBench에서 영감을 얻은 확장형 파이프라인을 구축했습니다. 각 SWE 문제는 특정 커밋으로 체크아웃되고 의존성이 미리 설치된 저장소, 문제 설명, 채점용 단위 테스트를 담은 자기 완결적 컨테이너 이미지로 패키징됩니다. 모델은 표준 출력/오류를 돌려주는 bash 와, 비효율적인 셸 편집 대신 정확한 문자열 치환으로 파일을 고치는 str_replace_editor 두 도구로 컨테이너와 상호작용합니다(두 도구의 전체 스키마는 부록 D 의 OpenAI 호환 function-calling 형식으로 제공됩니다).
파이프라인의 깔때기는 인상적입니다. 출발점은 1 억 200 만($102$M) 개의 공개 GitHub PR 입니다. 메인 브랜치 병합, 수정 파일 15 개 미만, 코드와 테스트 변경 동시 포함, 이슈 연결(GitHub, Jira, Bugzilla, YouTrack, Phabricator, Launchpad, Linear) 등의 필터를 거쳐 약 487 만($4.87$M) 개의 이슈 연결 PR 이 남습니다. 이후 단계별 통과 현황은 아래와 같습니다.
| 단계 | 통과 수 | 통과율 |
|---|---|---|
| 이슈 연결 PR | 4.87M | 기준 |
| 자동 에이전트 환경 빌드 | 2.08M | 42.8% |
| 참조 채점 신호 추출 | 745,452 | 15.3% |
| 환경/채점기 검증 | 265,617 | 5.5% |
마지막으로 살아남은 265{,}617 개 문제는 94{,}044 개의 고유 저장소에서 나왔습니다. 채점 신호는 테스트 diff 만 적용한 수정 전(pre-fix) 상태와 코드 diff 까지 적용한 수정 후(post-fix) 상태를 비교해 도출하는데, 실패에서 통과로 전이하는 테스트(fail-to-pass, F2P)가 이슈 해결 신호를, 두 상태에서 모두 통과하는 테스트(pass-to-pass, P2P)가 회귀 방지 신호를 이룹니다. F2P 테스트가 하나도 살아남지 않은 문제는 폐기합니다. 또 빈 패치는 채점기를 실패하고 정답 패치는 통과하는지, 반복 실행에서 비결정적 테스트가 없는지까지 재검증합니다. 빌드는 됐으나 품질 검사(명세 명료성, 테스트 품질, 누출 위험, 실현 가능성 채점)를 통과 못 한 환경은 BugPilot, SWE-Smith, SWE-Mirror 방식으로 합성 문제를 생성해 재활용합니다.
SWE 환경은 검증 가능한 테스트로 채점되더라도 보상 해킹에 취약합니다. LLM 모니터와 사람 검토로 세 가지 유형을 짚습니다. (1) 환경이 공개 저장소에서 왔으므로 PR 과 정답을 인터넷에서 검색하는 행위는 네트워크 접근 제어로 차단합니다. (2) 로컬 git 히스토리에서 정답 커밋을 찾는 행위는, 문제의 베이스 커밋 이후 커밋, 참조, 브랜치를 모두 지워 저장소를 "시간 여행시킨" 상태로 만들어 막습니다(git 자체는 유용한 기능이라 통째로 지우지는 않습니다). (3) 테스트 조작은 SWE-Bench 프로토콜처럼 채점 전 모델이 수정한 테스트 파일을 초기화하고, 추론 중에는 테스트 변경을 숨겼다가 채점 시에만 적용해 방지합니다. 다만 테스트 프레임워크 몽키패칭 같은 우회로가 남아 있어 LLM 모니터로 탐지를 계속 강화합니다.
일반 도구 사용(general tool use)은 SWE 보다 도구와 도메인 다양성이 훨씬 큽니다. 재고 관리, 일정 관리, 고객 지원 같은 시나리오를 모의 백엔드(API/MCP 동작을 흉내)로 구현하며, 각 문제는 질의, 스키마를 갖춘 도구 집합(OpenAI function-calling schema), 초기 환경 상태, 채점기로 이루어지고 단일 환경에 흔히 50 개를 넘는 도구를 둡니다. FunReason-MT 파이프라인에서 영감을 얻은 합성 환경 생성기는 평문 영어 설명만으로 (i) 환경 부트스트래핑(도구 기술/함수 구현/DB 시딩), (ii) 과제 생성(도구 호출 궤적 샘플링과 사용자 요청 작성), (iii) 검증과 정제의 세 단계를 비평-수정 루프와 함께 거쳐, 총 150 개가 넘는 환경과 130{,}000 개의 과제를 합성했습니다. 과잉 호출을 막으려고 도구가 있어도 호출이 불필요한 과제도 일부러 섞습니다. 보상은 최종 상태/도구 사용 패턴/최종 답을 보는 환경별 채점기와, 병렬 호출 활용과 중복 호출 회피 등 효율적 도구 사용을 유도하는 교차 환경 채점기를 함께 씁니다.
부록 C.2: 에이전트 CoT 의 진화
부록 C.2 는 SWE 학습에서 약한 체크포인트와 강한 체크포인트의 궤적이 어떻게 갈리는지 보여줍니다. (1) 강한 모델은 직접 단위 테스트를 작성하고 실행해 작업을 검증하는 반면 약한 모델은 "요구사항을 다 구현했다"는 자기 점검에 그칩니다. (2) 강한 모델은 패치 전에 되돌린 커밋, 페이로드, 테스트 같은 저장소 증거를 캐는 "증거 고고학"을 하는 반면 약한 모델은 올바른 대상을 찾고도 정확한 편집 메커니즘과 들여쓰기 복구에 집착합니다. (3) 강한 모델은 생성 코드를 먹이는 데이터 원천을 진실의 근원으로 삼아 거기서부터 추적하는 반면 약한 모델은 인접한 생성 코드 경로를 추측하다 엣지 케이스를 놓칩니다. 즉 RL 은 에이전트에게 성급한 행동을 미루고 충분히 탐색한 뒤 움직이는 규율을 가르쳤습니다.
유용성과 안전성 클라임(Helpfulness and Safety Climb)
이 클라임은 인간 선호로 판단되는 유용성, 지시 따르기, 조종 가능성(steerability), 안전성, 정직성, 스타일을 최적화합니다. 다른 클라임과 달리 성능이 객관적이고 기계 검증 가능하게 정의되지 않는 과제를 다루므로, 인간 선호 데이터로 학습한 보상 모델, (보통 루브릭 기반의) AI 판정자 피드백, 검증 가능한 보상을 조합한 집계 신호를 씁니다.
보상 모델은 MAI-Base-1 의 사후 학습 버전을 미세 조정해 인간 선호를 텍스트 토큰으로 예측하게 만든 것으로, 여러 벤더의 사람 어노테이터가 수집한 선호 데이터로만 학습합니다. 컨텍스트 c 와 점수 [1; 5] 가 매겨진 k 개 응답을 구분자 토큰으로 이어 붙여 입력하고 점수 시퀀스를 SFT 로 예측합니다. 추론 시에는 응답을 순열로 돌려가며 k 번 호출해 매번 첫 토큰만 디코딩하고, i 번째 호출의 첫 토큰 분포에서 해당 응답이 최고 품질(s_i = 5)일 확률을 보상으로 삼는 순환(cyclic) 적용으로 점수 보정을 개선합니다. AI 판정자는 보상 모델 재학습을 기다리지 않고 빠르게 행동을 조형하는 지렛대로 쓰고, 검증 가능한 보상은 "한 문단으로 답하라", "10단어 미만으로" 처럼 제약 준수를 직접 확인할 수 있는 경우에 써서 보상 해킹과 다중 에폭에 덜 취약한 안정적 신호를 제공합니다(길이 같은 요소는 컨텍스트별 분위 구간 밖 응답을 벌점해 비검증 보상의 길이/스타일 상향 편향을 보정합니다).
서로 다른 보상을 결합하는 일은 까다롭습니다. 보상마다 스케일이 다르고 분포도 컨텍스트 의존적이며, 무엇보다 "잘 쓰였지만 안전하지 않은 응답은 품질과 무관하게 받아들일 수 없는" 비협상 기준이 존재하기 때문입니다. 이를 단순 합산하면 가장 큰 신호가 중요도와 무관하게 지배해 버립니다. 해법은 두 가지입니다. 사전식 보상 형성(lexicographic reward shaping) 은 그룹 내 모든 롤아웃이 상위 보상에서 동점일 때만 하위 보상을 활성화해 엄격한 우선순위를 만듭니다(그룹 내 상대 비교라 스케일에 불변). 게이트형 보상 적용(gated reward application) 은 상위 보상이 최소 성능을 만족해야만 하위 보상을 적용하는데, 안전이 대표 사례로, 안전하지 않은 응답은 최소 보상을 받고 품질 채점 자체를 받지 못합니다. 비유하면, 요리 대회에서 위생 검사를 통과하지 못한 요리는 맛 평가대에 아예 오르지 못하는 것과 같습니다.
지시 따르기, 안전, 정직, 스타일
지시 따르기(IF) 는 사용자/개발자/시스템 지시를 우선순위에 따라 따르는 핵심 능력으로, 전문가가 쓴 컨텍스트와 합성 데이터를 함께 씁니다. 합성 파이프라인은 수작업으로 큐레이션한 제약 분류(부록 E)와 다양한 시드를 바탕으로 지시와 모델 스펙을 생성하고, 40 개가 넘는 도메인에 걸친 다국어, 단일 및 장기 대화 시나리오와 시스템/개발자/사용자 메시지가 충돌하는 적대적 사례(지시 계층 학습용)를 만든 뒤 자연스러움, 루브릭 정합, 근거성으로 비평하고 재작성합니다. 보상은 규칙 기반 검사, 원자적 루브릭당 이진 판정을 여러 번 평균하는 LLM 판정, 보상 모델 품질 평가를 사전식 집계로 결합하되 IF 보상을 주 신호로 둡니다.
부록 E 의 제약 분류 체계는 지시를 검증 방식에 따라 세 갈래로 나눕니다. 객관적(하드) 제약은 사용자 정의 및 오픈소스 체커 카탈로그의 Python 함수로 자동 판정하며 "정확히 3 문장으로 답하라", "키가 name 과 age 인 JSON 으로 출력하라", "프랑스어로 답하라" 같은 수치/형식/언어 제약이 여기에 속합니다. 주관적(소프트) 제약은 판단이 필요해 보상 모델이나 AI 판정자가 채점하며 어조, 페르소나, 상호작용 행동(예: 불명확하면 먼저 명료화 질문하기) 등을 다룹니다. 여기에 더해 다중 턴 시나리오 분류를 두어 여러 턴에 걸친 복잡한 대화에서의 지시 따르기 능력을 점검합니다.
안전(safety) 데이터는 두 가지 실패 모드, 즉 거절해야 할 요청을 들어주는 불안전 순응(unsafe compliance) 과 정당한 요청을 불필요하게 거절하는 과잉 거절(over-refusal) 을 동시에 겨냥합니다. 프롬프트는 정책상 일부 또는 전부 거절해야 하는 유해(harmful) 프롬프트와, 민감하지만 정책 내에서 답할 수 있는 경계선(borderline) 프롬프트로 나뉩니다. Table 8 에 따르면 유해 프롬프트는 사람 레드티밍(벤더 작성, 내부 레드팀)과 자동 공격(PyRIT 같은 템플릿, PAP 같은 비대화형 LLM 생성, TAP 같은 대화형 LLM)으로, 경계선 프롬프트는 세대 간 이월된 "거절하지 않기(do-not-refuse)" 슬라이스와 능력 데이터에서 라우팅된 것으로 수집합니다. 응답은 정책 준수, 응답 관여도(engagement), 응답 스타일의 세 축으로 안전 판정자가 채점하며, 정책 준수 필드가 보상을 게이팅합니다. 보고서는 단순 가중 평균이 왜 위험한지를 수치로 보여주는데, 짝지은 롤아웃 감사에서 정책 비준수 응답의 87.8\% 가 보상 모델 점수 3 점 이상을 받았고, 기대 안전 리커트와 정책 준수 필드의 상관은 피어슨 0.293, 스피어만 0.344 에 그쳤습니다. 즉 스칼라 보상은 정책 비준수 응답에서도 양수로 남을 수 있어, 게이팅이 필수입니다.
정직성(honesty) 은 사실 정밀도와 정보성의 균형을 잡습니다. 모든 RL 예제의 참조 라벨을 검색 증강 생성과 검증으로 오프라인 생성하고, LLM 판정자가 사실성과 자신감 두 축으로 채점해 다섯 범주(CONFIDENT_CORRECT, UNCONFIDENT_CORRECT, NOT_ATTEMPTED, UNCONFIDENT_INCORRECT, CONFIDENT_INCORRECT)로 분류한 뒤 가중합으로 스칼라 보상을 만듭니다. 자신 있는 환각에는 가장 가파른 페널티를, 기권에는 중립을, 자신 없지만 맞는 답에는 과잉 회피를 막기 위한 감점 보상을 줍니다. 데이터는 검증 가능한 기성 사실 질의, 롱테일의 난해 주제 도전 질의, 잘못된 전제를 담은 false-premise 질의를 아우릅니다. 스타일(style) 은 사기성 없는 따뜻함, 훑어보기 쉬운 구조, 맥락에 맞춘 어조를 규정한 스타일 가이드(Table 9)를 따릅니다. 예컨대 이모지는 캐주얼한 맥락에서만 최소로(목록 머리나 맺음말에는 금지), 표와 마크다운은 여러 항목과 데이터 제시에만, 어조는 기본 전문체에 사용자가 청할 때만 가벼운 톤을 씁니다. 스타일 판정자는 큰 결함, 작은 결함, 없음을 0, 1, 2 정수로만 매기는데, 거친 채점기가 세밀한 채점기보다 루브릭을 유연하게 해석해 해킹이 더 어려웠다고 합니다. 스타일 채점은 검증 가능한 보상과 안전 제약이 충족된 뒤에만 적용됩니다.
능력을 단일 모델로 통합하기(Consolidating into a Single Model)
세 교사 모델을 단일 모델로 합치는 과정은 두 단계입니다. 통합 SFT 단계는 자기 증류 파이프라인을 각 전문가 교사에 적용하되, 교사마다 다른 필터링과 거부 샘플링(rejection sampling)을 씁니다. STEM 과 에이전트형 교사는 여러 체크포인트(후반 우선)에서 롤아웃을 뽑아 컨텍스트당 여러 정답 롤아웃을 가볍게 거르고, 유용성과 안전성 교사는 LLM 판정자와 휴리스틱으로 스타일, 구조, 알려진 결함까지 채점합니다.
통합 SFT 데이터 혼합은 샘플 가중치 기준으로 균형을 잡는 것이 중요했습니다. 토큰 분포는 트레이스가 긴 STEM 및 코딩이 자연히 지배하지만 실제로 유용성과 안전성 능력을 해치지는 않았습니다. 표준 자기 증류 레시피와 달리, 통합 SFT 는 최대 학습률 1 \times 10^{-5} 에서 2\times 로 감쇠하며 4 에폭 동안 수행합니다.
| 능력 | 샘플 가중치 | 토큰 가중치 |
|---|---|---|
| STEM 및 코딩 | 56% | 89% |
| 에이전트형 능력 | 11% | 9% |
| 일반 유용성/안전성 | 33% | 2% |
마지막 통합 RL 단계는 안전성, 과잉 거절, 스타일을 한 번 더 다듬습니다. 레시피는 유용성과 안전성 클라임에 기반하되 추론 성능 유지를 위한 변경을 더했습니다. 최대 시퀀스 길이 $128$k 로 학습하고 STEM 및 코딩 데이터를 소량 유지했는데, 둘 다 빼면 복잡한 과제의 추론 성능이 클라임 내내 서서히 저하되었기 때문입니다.
강화 학습 인프라(RL Infrastructure): Rocket
이 모든 클라임은 Rocket, 즉 대규모 비동기 분산 강화 학습을 위한 자체 프레임워크 위에서 돌아갑니다. 학습기(learner)에는 YOLO 를, 모델 추론에는 SGLang 을 씁니다. 수천 개 GPU 에 걸친 비동기 RL 이라는 요구를 기존 오픈소스 프레임워크가 충족하지 못해 직접 만들었습니다. Rocket 의 데이터 흐름은 단일 컨트롤러, 문제 워커(problem worker)와 롤아웃 워커(rollout worker) 풀, 라우터와 추론 서버, 그리고 커리큘럼에 따라 문제 집합을 고르는 문제 집합 샘플러(problem set sampler)와 비동기 컨트롤러를 중심으로 조직되며, 컨트롤러, 문제 워커, 롤아웃 워커는 각각 하나의 Python 프로세스 / Ray 액터로 구현됩니다.
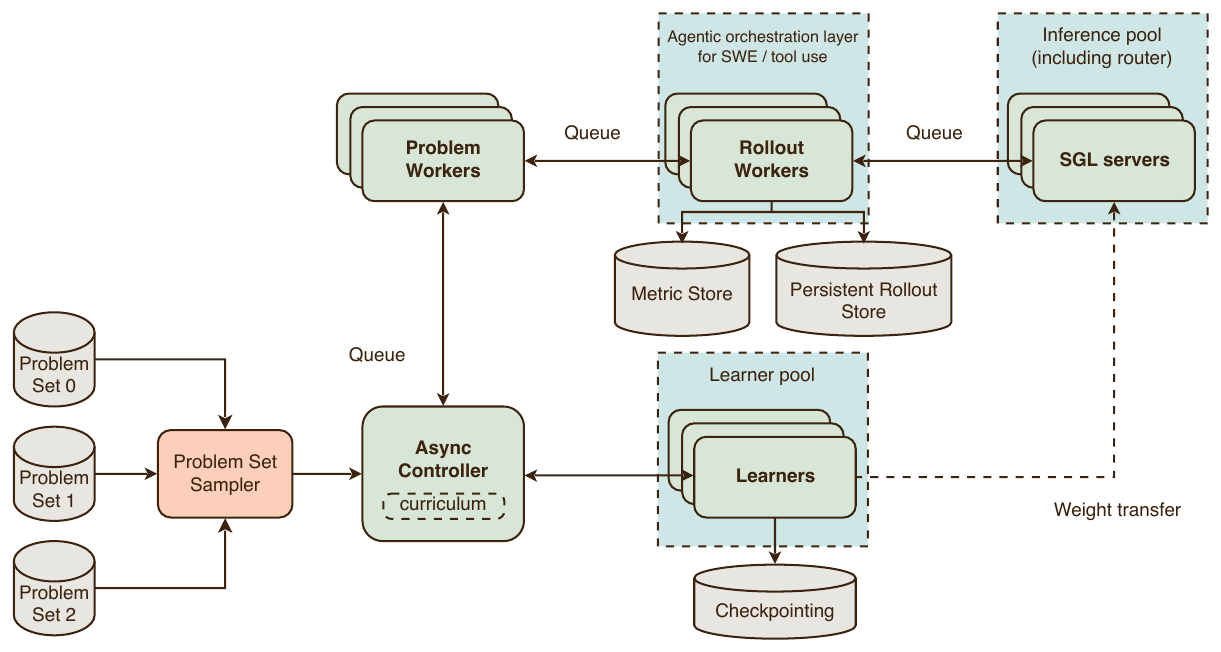
컨트롤러는 RL 과제를 적재해 문제 워커로 보내고, 채점 메타데이터가 붙은 롤아웃을 받아 필터링한 뒤 배치로 학습기에 전달합니다. 이 추상화 덕에 온폴리시와 오프폴리시 구현을 갈아 끼울 수 있는데, 대규모 런에서는 주로 오프폴리시 RL 을, 소규모 실험과 디버깅에는 온폴리시 RL 을 씁니다. 문제 워커는 조기 종료 롤아웃(16 개 요청 후 통과율 확인), 전체 롤아웃(128 개 추가 요청), 후처리(정규화 어드밴티지 계산, 길이 페널티 적용)의 3단계로 동작하며, 롤아웃 워커 실패 시 재시도하는 결함 내성을 갖춥니다. 롤아웃 워커는 단일 롤아웃을 생성하며 도구 호출을 처리하고, 개별 롤아웃을 독립 평가할 수 있으면 자체 채점하고(예: 수학 문제는 정답 동치 여부로 통과/실패) 여러 롤아웃을 동시에 봐야 하는 경우(쌍별 비교 등)에는 문제 워커가 채점합니다.
추론은 시스템에서 가장 중요한 구성 요소로, 작업 특성에 따라 추론 대 학습기 GPU 비율이 최대 5{:}1 까지 커집니다. 가장 큰 RL 작업은 4864 개 GB300 칩을 쓰는데, 그중 4096 칩을 추론에, 768 칩을 학습기에 배정했습니다. 단일 턴 워크로드는 생성이 $128$k 토큰까지 길어져 KV 캐시 메모리가 병목이므로, 전문가 병렬과 어텐션용 데이터 병렬로 KV 캐시와 가중치 풋프린트를 줄이고, 슬라이딩 윈도우 어텐션 토큰을 완전히 축출하기 위해 접두사 캐싱을 끄며, MLP 데이터 병렬, DeepEP, EPLB 로 통신을 줄입니다. 반대로 다단계 워크로드는 프롬프트가 길고 생성이 짧아 프리필(prefill) 중심이므로 접두사 캐싱에 크게 의존하며, 프로덕션 RL 런에서 접두사 캐시 적중률이 97~98\% 에 달합니다.
안정성을 위해 세 계층 방어를 둡니다. 복제본 수준에서는 각 SGLang 서버가 자기 감시 워치독으로 생성 엔드포인트와 스케줄러 메모리를 점검해 비정상이면 스스로 정상 재시작하고, 라우터 수준에서는 SGLang 라우터가 회로 차단기처럼 동작해 백엔드가 불건전하면 신규 요청을 막았다가 다단계 프로브 후 재개하며 복제본당 흐름 제어로 느린 복제본의 적체를 막습니다. 작업 수준에서는 생존성 모니터가 각 부류(추론 복제본, 라우터, 롤아웃 워커, 학습기 랭크)의 살아 있는 액터 수를 추적해 임계치 미만이면 작업을 깔끔히 재시작하고, 별도의 스텝 진행 워치독이 "다 살아 있는데 학습이 멈춘" 어려운 경우를 잡아냅니다. 마지막으로 학습과 추론 사이 수치 격차(numerics gap)는 서로 다른 커널, 스케줄링, 병렬화로 인해 긴 롤아웃에서 누적되어 오프폴리시 RL 의 중요도 샘플링 보정을 불안정하게 만드는 결정적 요인이라, 학습기와 추론 엔진 모두 bf16 을 쓰고 그 위에 MoE 라우팅 리플레이와 top-p 마스크 리플레이를 적용해 격차를 줄입니다. 비동기 RL 의 가중치 전송은 동기에서 비동기로 옮기면서 k 스텝마다 학습기 가중치를 추론 함대로 보내는 반복 동기화 문제가 됩니다. 학습기와 추론의 서로 다른 샤딩 레이아웃(FSDP, 파이프라인 병렬, 데이터 병렬 어텐션, 정밀도와 양자화, 행렬 배치)을 교차시켜 비어 있지 않은 하위 샤드 단위로 전송 계획(transfer plan)을 작업 시작 시 한 번만 컴파일해 재사용하며, 각 학습기 랭크가 짝지은 추론 랭크에 필요한 슬라이스만 보내 전체 텐서 구체화를 없애고, 패킹, 전송, 언패킹을 파이프라이닝해 연속 하위 샤드가 시간상 겹치도록 합니다. 계획은 학습기 1대-추론 서버 1대의 이상적 토폴로지를 대상으로 짜이고 런타임에 살아 있는 복제본 전부로 확장되므로, 복제본이 들고 나도 그대로 유효합니다.
부록 F: SWE 환경 빌드 인프라
부록 F 는 위 SWE 깔때기를 실제로 돌리는 빌드 인프라를 설명합니다. 약 30{,}000 개 CPU 코어 위에서 두 풀로 나뉜 Ray 클러스터로 구성되는데, 메인 풀은 작업 분배, Lance I/O, 파이프라인 상태 추적을 맡고 빌더 풀은 실제 컨테이너 빌드를 돌립니다. 컨테이너 빌드는 디스크 고갈, OOM, 행(hang)으로 자원을 많이 쓰고 실패가 잦은 반면 조율은 가볍고 무상태이므로 둘을 분리하며, 이 분리는 신뢰 격리도 강제합니다. 빌더 파드는 오픈소스 저장소의 신뢰할 수 없는 Dockerfile 을 실행하므로 데이터 저장소나 내부 서비스 자격 증명을 갖지 않습니다. 각 빌더 파드는 NVMe 로컬 스토리지를 공유하는 두 컨테이너로 이루어져, 메인 컨테이너는 rootless podman 으로 이미지를 적재하고 채점하며 사이드카는 rootless BuildKit 데몬으로 OCI 이미지를 빌드하고, 둘은 공유 NVMe 볼륨으로 통신해 큰 이미지를 네트워크로 옮기지 않고 빌드-적재-실행 주기를 로컬에서 끝냅니다. 또 같은 저장소의 문제들을 한 영속 Ray 액터로 묶어 apt-get/pip 설치 같은 공통 베이스 레이어를 BuildKit 레이어 캐싱으로 한 번만 빌드해 재사용함으로써, 의존성 설치가 빌드 시간을 지배하는 문제를 완화합니다.
평가 결과: 벤치마크, 인간 평가, 안전성
MAI-Thinking-1 은 공개 벤치마크와 인간 평가를 모두 활용해 다양한 프런티어 모델과 성능을 비교합니다. 평가 영역은 STEM, 에이전트형 코딩(agentic coding), 지식, 지시 따르기(instruction following), 긴 맥락(long context), 안전성, 헬스, 정직성(honesty), 도구 호출(tool calling) 등으로 폭넓게 걸쳐 있어 모델의 범용성을 잘 보여줍니다. MAI-Thinking-1 의 모든 벤치마크 점수는 온도(temperature) T = 1 과 top-p 샘플링 p = 0.97 의 균일한 추론 설정에서 4 회 실행한 평균값으로 보고됩니다.
STEM 및 에이전트형 코딩 벤치마크
수학은 AIME 의 2025년과 2026년 판, 그리고 MathArena 의 HMMT Feb 2026 으로 평가하고, 과학은 대학원 수준의 지식 집약형 문제로 구성된 GPQA Diamond 로, 경쟁 코딩(competitive coding)은 최신 문제를 담은 LiveCodeBench v6(LCB v6)로 평가합니다. 에이전트형 코딩은 SWE-bench Verified, SWE-Bench Pro, Terminal-Bench 2.0 으로 측정하며, 이들은 단일 응답이 아니라 환경과 상호작용하는 다중 턴(multi-turn) 평가라는 점에서 STEM 평가와 다릅니다. 저자들은 세 벤치마크 모두 단순한 ReAct 스타일 루프로 평가했고, SWE-bench 계열에서는 bash 와 문자열 치환(string replacement) 도구를, Terminal-Bench 2.0 에서는 최소한의 터미널 환경을 흉내 내기 위해 bash 도구만 활성화했습니다.
종합하면 MAI-Thinking-1 은 분야를 선도하지는 않지만, 넓은 범주에 걸쳐 일관되게 강한 성능을 내며 인기 있는 LLM 들과 경쟁 가능한 범위에 위치합니다. 특히 AIME 2025 에서 97.0\% 로 Claude Sonnet 4.6 의 95.6\% 를 앞서고, SWE-Bench Pro 에서는 52.8\% 로 Claude Opus 4.6 의 53.4\% 에 근접합니다. 한 가지 주목할 점은, SWE 에이전트 학습 데이터가 bash 와 문자열 치환 도구만 사용하고 터미널 상호작용에 특화된 환경을 포함하지 않았다는 사실입니다. 따라서 Terminal-Bench 성능은 해당 환경에 대한 직접 학습이 아니라 더 넓은 에이전트 학습으로부터의 일반화(generalization)를 반영합니다.
| 벤치마크 | MAI-Thinking-1 | Sonnet 4.6 | Opus 4.6 | GPT 5.4 | Kimi K2.6 | DeepSeek V3.2 | DeepSeek V4 | GLM-5.1 |
|---|---|---|---|---|---|---|---|---|
| AIME 2025 | 97.0 | 95.6 | 99.8 | - | - | 93.1 | - | - |
| AIME 2026 | 94.5 | - | - | - | 96.4 | - | - | 95.3 |
| HMMT Feb 2026 | 84.9 | - | - | - | 92.7 | - | 95.2 | 82.6 |
| GPQA Diamond | 84.2 | 89.9 | 91.3 | 92.8 | 90.5 | 82.4 | 90.1 | 86.2 |
| LCB v6 | 87.7 | - | - | - | 89.6 | 83.3 | 93.5 | - |
| Terminal-Bench 2.0 | 46.0 | 59.1 | 65.4 | 75.1 | 66.7 | 46.4 | 67.9 | 69.0 |
| SWE-bench Verified | 73.5 | 79.6 | 80.8 | - | 80.2 | 73.1 | 80.6 | - |
| SWE-Bench Pro | 52.8 | - | 53.4 | 57.7 | 58.6 | - | 55.4 | 58.4 |
표의 다른 모델 점수는 각 모델의 공식 모델 카드에서 가져왔으며, "-" 는 해당 벤치마크 수치를 보고하지 않았음을 뜻합니다. 에이전트형 코딩 평가는 총 컨텍스트 길이 $256$k 를 사용했고, 그 외 평가는 최대 출력 토큰 $256$k 를 사용했습니다.
STEM 평가 셋업 자세히 (Appendix G)
수학 평가에서 AIME 와 HMMT 의 정답은 단순한 수나 식이므로, 저자들은 모델에 최종 답을 boxed 형식으로 출력하게 한 뒤 정규식으로 답을 추출하고 SymPy 로 검증합니다. 검증이 모호한 경우에는 AI 판정기(AI judge) 를 폴백으로 사용하며, 기본 판정기는 GPT-5-mini 입니다. 판정 프롬프트는 단위, 형식, 반올림에 대한 명시적 루브릭을 두고, 의미가 동치이면 형식 차이를 정답으로 인정하되 문제가 단위나 정밀도를 명시적으로 요구하면 엄격히 적용합니다. 또한 판정 신뢰도를 높이고 판정기 해킹(judge hacking)을 막기 위해 대화 이력에 소수의 few-shot 예시를 사전 사용자/어시스턴트 턴으로 끼워 넣습니다.
과학 평가의 GPQA 는 198 개 객관식 문항으로 이뤄진 Diamond 부분집합을 사용하고, OpenAI 의 simple-evals 패키지 지시 프롬프트로 답 형식을 지정한 뒤 정규식 기반 추출로 채점하며, 16 회 롤아웃의 pass@1 평균으로 보고합니다. 경쟁 코딩의 LCB v6 는 2023년 5월부터 2025년 4월 사이에 공개된 1{,}055 개 문제를 담은 분할로, 다중 턴인 에이전트형 코딩과 달리 한 번에 풀이를 생성하는 일회성(one-shot) 설정입니다. 생성된 코드는 code fence 에서 파싱되어 실제 코딩 대회와 비슷한 메모리/실행 시간 제한이 걸린 테스트 하니스로 채점됩니다.
저자들은 출력 토큰 예산을 $256$k 로 둔 기본 수치 외에, 출력 토큰을 $128$k 로 제한했을 때의 성능도 함께 제시합니다. 출력 예산을 절반으로 줄이면 AIME 2025 는 97.0\% 에서 95.0\%, AIME 2026 은 94.5\% 에서 93.6\%, HMMT 는 84.9\% 에서 84.3\%, LCB v6 는 87.7\% 에서 87.3\% 로 소폭 낮아지고, GPQA Diamond 는 84.2\% 로 동일합니다. 즉 긴 출력 예산이 추론 집약적 수학에서 약간의 추가 이점을 주지만 그 폭은 크지 않습니다.
에이전트형 코딩 셋업 자세히 (Appendix H)
세 에이전트 벤치마크 모두 매 턴마다 모델이 도구 호출을 생성하면 환경에서 실행한 출력 결과를 궤적(trajectory)에 덧붙여 다음 호출로 넘기는, 항상 덧붙이는(always-append) ReAct 스타일 루프로 평가됩니다. 총 컨텍스트 길이는 $256$k 토큰이며, 최대 출력 길이는 SWE-bench Verified 와 SWE-Bench Pro 에서 $8$k 토큰, Terminal-Bench 2.0 에서 $32$k 토큰이고, 최대 1{,}000 스텝까지 진행합니다. 루프는 모델이 도구 호출을 더 내지 않거나, 컨텍스트 한계 또는 스텝 한계에 도달하면 종료되고, 이후 해당 환경 안에서 채점기가 실행됩니다. 추론 속도와 인프라가 결과를 왜곡하지 않도록 Terminal-Bench 2.0 에서는 사전 정의된 타임아웃을 무시합니다.
각 벤치마크의 규모와 성격도 다릅니다. SWE-bench Verified 는 인기 Python 저장소의 실제 GitHub 이슈를 사람이 검수해 추린 500 개 과제로, 모델은 숨겨진 테스트 스위트를 통과시키는 패치를 생성해야 합니다. SWE-Bench Pro 는 그 후속으로 731 개 과제를 담으며, 다중 파일 편집과 긴 호흡의 추론을 강조하고 Python 외 언어 저장소까지 포함한다는 점에서 더 어렵습니다. Terminal-Bench 2.0 은 소프트웨어 공학, 디버깅, 데이터 과학, 머신러닝, 보안, 시스템 관리에 걸친 89 개의 현실적 과제로 구성되며, 각 과제는 샌드박스 터미널에서 실행되고 출력이나 환경 최종 상태로 프로그램적으로 채점됩니다.
일반 역량 벤치마크 (Sonnet 4.6 대비)
지식, 지시 따르기, 긴 맥락, 안전성, 정직성, 헬스, 도구 호출 영역에서는 모든 연구소가 공식 수치를 공개하지는 않기 때문에, 저자들은 비교 기준선을 마련하고자 Sonnet 4.6 을 최대 추론 노력(max reasoning effort)과 최대 시퀀스 길이로 직접 평가해 함께 보고합니다. 대부분의 벤치마크에서 MAI-Thinking-1 은 Sonnet 4.6 과 비등한 수준입니다. 다만 IFBench 에서는 69 대 50 으로 MAI-Thinking-1 이 크게 앞서고, 긴 맥락(GraphWalks, F1 점수)에서는 90 대 96 으로 다소 뒤집니다.
| 영역 / 벤치마크 | MAI-Thinking-1 | Sonnet 4.6 |
|---|---|---|
| MMLU Pro (지식) | 85 | 87 |
| SimpleQA Verified (지식) | 31 | 29 |
| IF Bench (지시 따르기) | 69 | 50 |
| Adv. IF (지시 따르기) | 85 | 86 |
| Multi-Challenge (지시 따르기) | 53 | 57 |
| GraphWalks 128k 이하 (긴 맥락) | 90 | 96 |
| BFCL v3 (도구 호출) | 72 | 76 |
| AIR-Bench (안전성) | 88 | 88 |
| CyberSec Instruct (안전성) | 63 | 62 |
| CyberSec Auto (안전성) | 63 | 56 |
| Long Fact (정직성) | 98 | 98 |
| Truthful QA (정직성) | 88 | 88 |
| HealthBench (헬스) | 35 | 38 |
| Prof. MedXpert QA (헬스) | 43 | 49 |
표의 Sonnet 4.6 점수는 모두 저자들의 자체 평가 스위트로 생성했으며, AdvancedIF 는 루브릭 수준(rubric-level) 점수로 보고합니다.
각 벤치마크의 세부 설정은 다음과 같습니다(Appendix J). 지식 영역의 MMLU-Pro 는 답 선택지를 4 개에서 10 개로 늘리고 추론 중심 문항을 더한 확장판이며, SimpleQA Verified 는 라벨 노이즈와 중복을 정리한 단답형 사실 지식 부분집합입니다. 지시 따르기의 IFBench 는 58 개의 검증 가능한 제약을, AdvancedIF 는 보정된 LLM 판정기로 복합/다중 턴/시스템 프롬프트 지시 준수를, MultiChallenge 는 다중 턴 맥락 할당과 맥락 내 추론을 평가합니다(MultiChallenge 는 공식 벤치마크 판정 모델인 Gemini 2.5 Pro 를 판정기로 사용해 공개 모델 점수가 공식 리더보드와 일치함을 확인했습니다).
안전성에서는 AIR-Bench 가 규제/정책 기반 해악 분류 체계에 걸친 정책 근거형 거부를 측정하되 안전한 응대를 보상하도록 설계되었고, CyberSecEval 4 는 안전하지 않은 코드 생성에 초점을 두어 알려진 취약 패턴을 유도하는 Instruct 와 취약 패턴 직전까지의 코드를 이어 쓰게 하는 Autocomplete 두 가지로 정적 분석 규칙으로 채점합니다(MAI-Thinking-1 은 Autocomplete 에서 Sonnet 4.6 을 앞서고 Instruct 에서는 비슷합니다). 정직성의 TruthfulQA 는 그럴듯한 오답을 유도하는 객관식 정확도를, LongFact 는 긴 생성에서의 주장 단위(claim-level) 정밀도를 측정합니다. 헬스의 HealthBench Professional 은 의료 전문가와 모델 간 525 개 대화를 의사 패널이 만든 루브릭으로 채점하며, 응답 길이가 길수록 점수가 부풀려지는 경향을 보정하는 길이 페널티를 도입합니다. MedXpertQA 는 선택지가 10 개(A-J)인 2{,}450 개 전문가 검수 문항으로 전문의 수준 지식을 평가합니다. 도구 호출의 BFCL v3 는 결정성을 높이기 위해 공식 리더보드 권장값인 T = 0.001, p = 0.97 로 추론합니다.
긴 맥락은 GraphWalks 외에 두 벤치마크로도 평가되는데, LongBenchV2 에서는 61 대 66 으로 Sonnet 4.6 에 뒤지고 CorpusQA 에서는 82 대 79 로 앞섭니다. GraphWalks 는 그래프의 간선 목록(edge list)을 입력으로 주고 너비 우선 탐색(BFS)으로 이웃 노드를 찾거나 특정 시작 노드의 부모 노드를 찾도록 시키는 합성 다중 홉(multi-hop) 추론 벤치마크로, 점수는 모델 예측과 정답 간 F1 으로 보고되며 o200k_base 토크나이저로 측정한 $128$k 이하 부분집합을 사용합니다. LongBenchV2 는 입력 맥락을 $256$k 토큰으로 제한해 408 개 4지선다 문항으로 평가하고, CorpusQA 는 기본 판정기 대신 정밀도가 더 높은 GPT-5.4(high)를 판정기로 써서 다중 문서 자유 서술형 답변을 채점합니다. 한편 저자들은 OpenAI 의 MRCR 을 우선순위 벤치마크에서 제외했는데, 이는 과제 성격이 자연스러운 사용자 질의와 크게 다르고, 표적 학습 없이는 MAI-Thinking-1 이 avg_similarity@256K 에서 60\% 로 최신 수준인 95\% 에 크게 못 미쳤기 때문입니다. 반대로 1{,}000 개의 합성 in-distribution 예시만으로도 더 작은 MAI-Base-1 계열 모델의 MRCR 성능이 90\% 이상으로 뛴 점은 이 벤치마크가 과적합에 취약함을 시사하며, 그런 표적 학습이 일반적 성능 향상으로 이어진다는 증거가 없어 제외했다고 설명합니다.
인간 평가 (Human Side-by-Side)
좁고 객관적인 품질 기준에 집중하는 공개 벤치마크를 보완하기 위해, 저자들은 실제 사용 과제 전반에 걸친 인간 평가(human side-by-side) 를 수행했습니다. 이 방식은 두 모델의 응답을 나란히 두고 전반적 유용성(helpfulness) 관점에서 총체적으로 비교하므로, 응답을 따로 볼 때는 드러나지 않는 품질 차이를 포착할 수 있습니다. 최종 과제 집합은 모두 영어로 된 1276 개 과제이며, 그중 30\% 가 다중 턴 대화입니다. 과제는 구조화된 분류 체계를 따르는 전문가 작성 프롬프트와, PII 및 부적합 프롬프트(불완전하거나 맥락이 부족한 것, 적대적인 것, 코딩 환경/이미지 생성/외부 도구가 필요한 것)를 걸러낸 Microsoft 의 소비자용 Copilot 로그라는 두 출처에서 가져왔고, 층화 추출(stratified sampling)로 사용 사례 커버리지와 난이도 균형을 맞췄습니다.
과제 분포는 열린 QA/브레인스토밍과 조언/콘텐츠 작성이 각각 13 에서 14\%, 구조화된 문제 해결/정보 추출/학술 보조/통찰 생성/콘텐츠 요약이 각각 6 에서 7\%, 과제 계획/맥락 기반 QA/기타 텍스트 분석이 각각 5\%, 개인 지원/엔터테인먼트/잡담/롤플레이가 각각 3 에서 4\% 를 차지합니다.
평가는 데이터 라벨링 업체 Surge AI 가 관리하는 영어 원어민 평가자들이 수행했습니다. 각 프롬프트에 대해 평가자는 지시 따르기(명시적/암묵적 모두), 사실성(factuality, 검색 엔진으로 확인), 간결성과 관련성, 완전성, 문체와 어조 등 여러 차원에서 각 응답에 없음/경미/심각 중 하나로 문제 수준을 매긴 뒤, 두 응답 간 선호도를 "much worse than"(-1.5)부터 "much better than"(1.5)까지의 7점 리커트 척도로 최종 판정합니다. 저자들은 평가자 간 일치도(inter-annotator agreement)가 높아 평정이 재현 가능하다고 보고합니다.
결과적으로 평가자들은 MAI-Thinking-1 을 Sonnet 4.6 보다 선호 했지만, Opus 4.6 은 MAI-Thinking-1 보다 선호 했습니다. Sonnet 4.6 과 비교했을 때 MAI-Thinking-1 은 49\% 에서 이기고 6\% 무승부, 45\% 에서 졌습니다. Opus 4.6 과 비교했을 때는 43\% 승, 5\% 무승부, 52\% 패였습니다. 개별 차원에서는 Sonnet 4.6 대비 간결성과 관련성, 문체와 어조에서 우위를 보였고, 지시 따르기, 사실성, 완전성에서는 노이즈 범위 안에서 대략 동등했습니다.
| 항목 | vs Sonnet 4.6 | vs Opus 4.6 |
|---|---|---|
| 전체 side-by-side 선호도 | +0.07 (±0.06) | -0.07 (±0.06) |
| 지시 따르기 | -0.01 (±0.02) | -0.04 (±0.02) |
| 사실성 | -0.02 (±0.02) | -0.03 (±0.02) |
| 간결성과 관련성 | +0.11 (±0.02) | +0.07 (±0.02) |
| 완전성 | -0.01 (±0.02) | -0.02 (±0.02) |
| 문체와 어조 | +0.08 (±0.02) | +0.05 (±0.02) |
전체 선호도는 [-1.5, 1.5], 개별 차원 델타는 [-1, 1] 척도이며, 양수는 MAI-Thinking-1 선호를, 음수는 Sonnet 또는 Opus 선호를 뜻합니다.
내부 안전성 평가
저자들은 모델이 마땅히 답해야 할 저위험 요청에 대한 과잉 거부(over-refusal) 를 측정하는 내부 벤치마크를 구성했습니다. 거부 판정기(refusal judge)가 각 응답을 채점해 거부, 얼버무림(hedging), 부당한 부분 거부를 표시하며, 과잉 거부율은 응답이 따르지 않은 프롬프트의 비율로, 유용성은 이 값을 1 에서 뺀 값으로 보고합니다. 이를 고민감도 항목의 안전 통과율(safety pass rate, 1 에서 5 의 리커트 척도에서 판정기 안전 점수가 3 초과)과 짝지으면, 고위험 유해 요청에는 더 안전하고 저위험 양성 요청에는 더 유용한 이상적 동작을 드러낼 수 있습니다.
평가 방법론은 두 단계로 진행됩니다(Appendix I). 1단계(사용자 요청 분류) 에서는 각 요청을 다섯 차원으로 특성화합니다. 어떤 정책 영역에 닿고 특정 규칙을 위반하는지(해악 범주 및 정책 위반), 범위와 심각도에 따른 순서형 민감도 수준(sensitivity level), 선의 가능성 대 악의로 나누는 이진 사용자 의도(user intent, 위험한 주제 자체는 악의의 증거가 아님), 정보 탐색/안내/창작/시나리오 놀이 같은 실용적 목표(user scenario), 그리고 적대적 래핑을 가려내는 탈옥 탐지(jailbreak detection)입니다. 다중 턴 대화에서는 전체 대화 이력이 맥락 입력으로 쓰입니다. 특히 탈옥 탐지는 공격 계열과 기법 변종의 계층적 분류 체계로 적대적 래핑을 가려낼 뿐 아니라, 래퍼가 탐지되면 추출(extraction) 단계가 그 아래에 깔린 실제 요청을 복원하고 이후 분류는 복원된 요청을 대상으로 수행합니다. 이로써 평가가 표면의 공격 템플릿이 아니라 실제 저변 의도에 대한 모델 행동을 반영하게 됩니다. 2단계(응답 전략 생성) 에서는 1단계 분류를 입력받은 루브릭 판정기가 정책 제약, 적절한 거부 태세(의도와 심각도에 따라 응답/부분 거절/거절), 권장 어조를 담은 요청별 응답 명세를 만듭니다. 무해하거나 불분명한 요청에는 LLM 생성 루브릭 대신 얼버무림과 부당한 거절을 명시적으로 벌점화하는 결정론적 기본 루브릭이 적용됩니다. 두 단계는 모두 LLM 판정기로 수행하되 분류는 여러 번 실행해 다수결로 판정기 분산을 줄입니다.
평가 집합 구성 자체도 방법론적 문제로 다룹니다. 후보 프롬프트는 공개 안전 벤치마크, PII 를 거른 소비자 Copilot 로그, 정책 분류 체계에 맞춰 외부 벤더가 수집한 프롬프트의 세 출처에서 모으고, 위 다섯 층(strata)으로 라벨링합니다. 여기서 tinyBenchmarks 의 항목 반응 이론(Item Response Theory) 발상을 확장해, 모델이 항상 통과하거나 항상 실패하지 않는 정보량 높은 프롬프트에 가중치를 더 주는 정보량 가중(informativeness-weighted) 설계로 가장 유익한 부분집합을 선별합니다. 또한 모든 내부 릴리스 후보는 고정된 안전 평가 묶음의 합격 임계값을 통과해야 하고 이전 후보 대비 퇴행이 없어야 하며, 임계값은 안전/과잉 거절/품질 사이의 파레토(Pareto) 트레이드오프 곡선에서 한계 안전 이득이 과도한 비용을 부르기 시작하는 변곡점을 골라, 정적 절대값이 아니라 곡선상의 고정 백분위로 설정합니다. 이렇게 하면 릴리스 주기가 바뀌어도 "합격"의 의미가 현재 달성 가능한 프런티어를 기준으로 일정하게 유지됩니다.
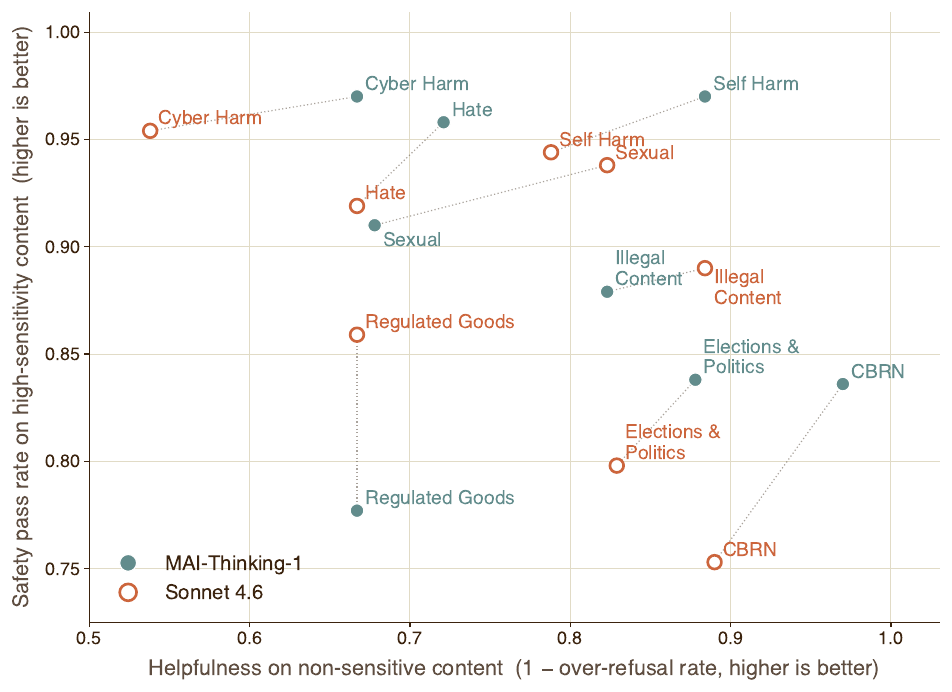
여덟 범주 중 다섯 개에서 MAI-Thinking-1 이 Sonnet 4.6 보다 위쪽이거나 오른쪽에 위치해 더 나은 성능을 보였으며(지표는 프롬프트당 두 번 생성한 결과의 평균), 가장 큰 개선은 CBRN(화학, 생물학, 방사능, 핵), 자해(Self Harm), 선거와 정치(Elections & Politics) 범주에서 나타났습니다.
안전성 레드티밍(Safety Red Teaming)
자동 벤치마크를 넘어선 안전 속성을 평가하기 위해, 저자들은 모델 개발 주기와 병행해 레드티밍(red-teaming)을 수행했습니다. 목표는 자동 평가가 안정적으로 잡아내지 못하는 적대적 취약점, 새로운 공격 벡터, 해악 범주의 공백을 드러내고, 그 결과를 학습 데이터 수집과 정책 개선에 지속적으로 반영하는 것입니다.
내부 레드티밍
내부 레드티밍은 MAI 레드팀(안전 연구자와 외부 채용 주석자)이 개발 주기 전반의 여러 모델 버전에 대해 수행했습니다. 초기, 중기, 후기에 걸친 15 회 활동에서 레드티머들은 25 개 정책 범주에 걸쳐 2{,}170 개가 넘는 목표 기반(goal-based) 적대 시나리오를 실행했습니다. 각 시나리오는 첫 턴 거절을 넘어 점진적 확대(escalation)를 허용하기 위해 5 에서 10 회의 대화 턴에 걸쳐 진행되었습니다. 주석자들은 적대적 프롬프팅 능력으로 선별되어 내부 모델 배포에 접근했고, 보조 맥락과 목표 정책 범주가 딸린 목표 기반 시나리오 트래커를 받아 여러 턴에 걸쳐 정책 위반을 유발하도록 지시받았습니다. 위반은 결과, 심각도, 첫 위반이 발생한 턴, 최악 위반의 텍스트 등 메타데이터와 함께 기록되었습니다. 테스트는 주로 영어로 이루어졌고, 비영어 입력은 체계적 평가가 아니라 제한적인 탈옥(jailbreak) 벡터로만 사용했으며, 에이전트형 도구 사용과 멀티모달 입력은 범위 밖이었습니다.
프로그램의 핵심 산출물은 여러 레드티머와 모델 체크포인트에서 독립적으로 반복된 공격 패턴 분류 체계(taxonomy)입니다. 저자들은 개별 프롬프트가 아니라 패턴이야말로 지속적인 적대적 표면이라고 보았습니다. 양성 구실 아래의 다중 턴 확대, 허구나 소설적 프레이밍, 자격 있는 인물(credentialed-persona) 구실, 점진적 재귀나 형식 변형(formatting drift, 이전에 얼버무린 답을 확장/재포맷/구체화하라는 반복 요청), 맥락 내 연령 지표 우회, 권위 있는 문서 위조 등 여섯 패턴이 대부분의 성공을 이끌었으며, 이 분류 체계는 이후 주기의 프롬프트 수집과 판정 루브릭 개발을 위한 커버리지 체크리스트로 기능합니다. 발견들은 지속적인 주기로 학습에 반영되었는데, 특히 자해 콘텐츠를 끌어내는 허구 프레이밍 우회(다국어 변종 포함)는 큐레이션된 집합으로 묶여 안전 평가와 적대 프롬프트 수집의 시드 확장, 그리고 SFT/RL 안전 믹스로 확장되었습니다. 그 결과 핵심 개선 범주 전반에서 사전 완화 대비 최종 후보의 종합 공격 성공률이 약 22\% 감소했습니다. 세부적으로는 탈옥 성공이 약 44\%, 혐오와 공정성(hate & fairness)이 약 43\%, 아동 안전 문제가 약 30\%, 정신 건강 공격이 약 20\% 줄었습니다.
또한 저자들은 벤더, 내부 레드티밍, HarmBench 와 StrongREJECT 같은 오픈소스 벤치마크에서 $2.5$K 개의 고유 시드 시나리오를 수집하고 이를 증강해 약 $9.5$K 개의 탈옥 프롬프트로 이루어진 내부 평가 스위트를 구성했습니다. 이를 변형 정도와 공격자 적응성에 따라 기초(Foundational), 합성(Compositional), 적응형(Adaptive) 기법의 세 묶음으로 나눕니다. 기초 기법은 탈옥 래퍼나 프롬프트 템플릿 같은 단일 단계 변형이고, 합성 기법은 PyRIT, PAP 스타일 변형, 비영어와 혼합 언어 변종처럼 여러 변형을 결합하며, 적응형 기법은 TAP 와 다중 턴 공격처럼 상호작용, 탐색, 다중 턴 구조를 도입합니다.
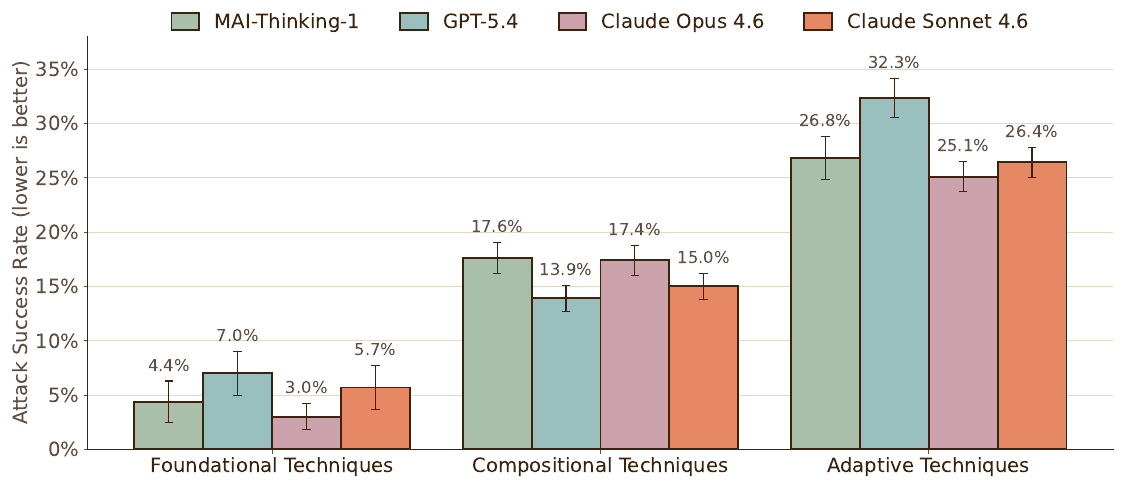
공격 성공률(attack success rate, ASR)은 낮을수록 안전성이 강함을 뜻합니다. 단일 단계 변형인 기초 기법에서 MAI-Thinking-1 은 4.4\% 로 Sonnet 4.6 의 5.7\%, GPT-5.4 의 7.0\% 보다 낮았고 Opus 4.6 의 3.0\% 보다는 약간 높았습니다. 합성 기법에서는 모델 전반의 ASR 이 올라가는 가운데 MAI-Thinking-1 이 17.6\% 로 Opus 4.6 의 17.4\%, Sonnet 4.6 의 15.0\%, GPT-5.4 의 13.9\% 와 비슷한 구간에 있었으며, 가장 정교한 적응형 기법에서는 MAI-Thinking-1 이 26.8\% 로 GPT-5.4 의 32.3\% 보다 낮고 Opus 4.6 의 25.1\%, Sonnet 4.6 의 26.4\% 와 비등했습니다. 즉 세 변형 유형 전반에서 MAI-Thinking-1 은 Sonnet 4.6 및 Opus 4.6 과 비등한 낮은 ASR 을 달성하며, 공격이 정교해질수록 모든 모델의 방어가 약해지는 공통 패턴도 확인됩니다. 단, 오차 막대는 95\% 신뢰 구간이며 제3자 모델 결과에는 공급자 측 안전 필터링이 포함되어 있다는 점을 감안해 해석해야 합니다.
독립 레드티밍
추가 레드티밍은 Microsoft 의 AI 레드팀(AIRT)과 제3자 벤더가 독립적으로 수행했습니다. 활동은 자동 적대 공격 기법, 코드와 사이버 오용 안전, 심리사회적 및 정신 건강 해악, 다국어 커버리지처럼 정적 평가가 가장 약한 위험 영역에 초점을 맞췄으며, 구조화된 위험 역량 및 업리프트(uplift) 평가는 이번 릴리스 범위 밖입니다.
가지치기를 포함한 적응형 공격 트리(Adaptive Tree of Attacks with Pruning, TAP) 공격이 견고성 공백으로 드러났습니다. 이에 대응해 저자들은 현실적 유해 시나리오를 폭넓게 생성하고, 다양한 공격 변형 템플릿으로 확장한 뒤, TAP 스타일 적응형 정교화로 현재 모델에 대해 신뢰성 있는 실패를 유발하도록 프롬프트를 최적화하는 표적 적대 데이터 파이프라인을 구축했습니다. 이 폐루프(closed-loop) 과정은 외부 레드팀 발견을 표적 개선 데이터로 전환해, TAP 탈옥 취약성을 크게 줄이고 동일 공격 벡터에서 모델을 최신 모델 수준으로 끌어올렸습니다.
저자원 언어(low-resource language) 프레이밍도 또 다른 취약점으로 지적되었습니다. 영어에서는 안정적으로 거부되던 내용이 요루바어, 텔루구어, 암하라어, 버마어, 크메르어, 말레이어에서는 유발되었습니다. 저자들은 안전 학습 데이터 믹스에 다국어 적대 시드를 추가하고, 성공률이 높은 영어 공격 패턴을 해당 언어로 번역하고 재표적화해 영어와 비영어 간 격차를 상당 부분 줄였습니다. 다만 더 희소한 언어들의 긴 꼬리(long tail)에서의 다국어 견고성은 여전히 지속적 투자가 필요한 영역으로 남아 있습니다.
클러스터 환경과 학습 안정성
MAI-Thinking-1 은 데이터, 모델, 학습, 평가, 서빙 컴포넌트를 빠르게 반복(iteration)할 수 있을 만큼 조합 가능하고, 프런티어 규모에서 개선을 검증할 만큼 확장 가능하며, 측정된 모델 품질 향상이 인프라 잡음에 묻히지 않을 만큼 신뢰할 수 있는 클러스터 환경을 필요로 했습니다. 보고서는 클러스터 환경 자체를 모델 개발의 능동적 구성 요소로 다룹니다. 학습 단계에서는 수치적 정확성, 결정론적 복구, 높은 MFU(Model FLOPs Utilization) 와 높은 가동률을 유지하면서 벽시계 시간(wall-clock) 하루당 유용한 FLOPs 를 극대화하는 것이 목표이고, 추론 단계에서는 품질과 긴 컨텍스트 정확성, 예측 가능한 지연 시간, 배포 효율을 유지하면서 초당 그리고 와트당 유용한 토큰 수를 극대화하는 것이 목표입니다.
두 영역에는 같은 시스템 원칙이 적용됩니다. 토폴로지가 중요하고, 메모리 이동이 중요하며, 무성 정확성 실패(silent correctness failure) 는 결코 용인되지 않고, 총 처리량은 그것이 신뢰할 수 있는 모델 진척이나 서빙 용량으로 이어질 때에만 의미가 있다는 것입니다. 보고서는 이 환경을 학습 클러스터 구성(6.1), 안정성과 결정론과 가동률 지표(6.2), MAIA-200 위에서의 추론 결과(6.3)로 나누어 설명합니다.
학습 클러스터 구성
클러스터는 시스템 수준의 최적화 문제로 설계되었습니다. 필요한 연산 규모는 스케일링 법칙(scaling law) 추정, 데이터 품질 목표, 토큰 예산, 관측된 학습 효율로부터 도출되었고, 인프라 계획은 이를 데이터센터 전력과 냉각, GPU, CPU, 스케일업 NVLink 도메인, 스케일아웃 InfiniBand 패브릭, 스토리지, 시스템 소프트웨어, 진단, 스케줄링, 체크포인팅, 관측성에 걸친 실사용 가능한 FLOPs 로 환산했습니다. 목표는 이론적 최대 FLOPs 가 아니라, 장시간 실행이 MFU 손실, 체크포인트 오버헤드, 재연산, 하드웨어 마모, 유지보수, 검증 워크로드, 복구 버퍼로 잃어버리는 용량을 감안해 실제로 스케줄링되고 건강하게 유지되며 높은 MFU 로 구동되고 장애 시 빠르게 복구되는 실사용 가능 학습 용량(usable training capacity) 이었습니다.
MAI-Base-1 은 단일 사이트의 단일 논리 클러스터에서 $8$K 개의 GB200 GPU 로 학습되었습니다. 동질적인 가속기 세대, 검증된 랙 건강 경계, 안정적인 스케줄러 동작, 예측 가능한 스토리지 경로 안에서 실행을 유지함으로써 실험 분산을 줄인 것입니다. 더 넓은 연구 환경에는 개발, 검증, 비교 프로파일링, 차세대 브링업(bring-up)을 위한 H100, GB200, GB300 시스템이 포함되었지만, 주 실행은 지역성과 토폴로지 안정성, 운영 동질성을 우선했습니다.
하드웨어와 컴퓨트 클러스터
부록 K 는 이 환경을 프런티어 규모에서 실제로 사용 가능하게 만든 인프라 메커니즘을 자세히 다룹니다. 핵심 설계 선택은 물리적 토폴로지와 하드웨어 건강 상태를 일급 스케줄링 상태(first-class scheduling state) 로 노출한 것입니다. 노드와 NVLink 랙 도메인은 토폴로지 레이블, 예약 객체, 랙 단위 서비스, 인증 게이트를 통해 표현되었고, 노드는 단지 프로비저닝되었다는 이유로 유용해지는 것이 아니라 건강하고, 토폴로지상 유효하며, 관측 가능하고, 복구 가능할 때 비로소 유용하다고 간주되었습니다.
MAI-Thinking-1 은 NVIDIA H100, GB200, GB300 시스템에 걸친 이기종 가속기 플릿 위에서 개발되었고, 주 사전학습 실행만 단일 사이트의 단일 GB200 클러스터에 배치되었습니다. GB200 과 GB300 클러스터는 Microsoft 자사 데이터센터에 호스팅되며 Azure 팀과 공동 개발한 커스텀 이미지를 통해 MAI 에 제공됩니다. 이 시스템들은 NVL72 랙 규모 단위(rack-scale unit) 로 프로비저닝되어, 각 랙이 고대역폭 스케일업 통신을 위한 72-GPU NVLink 도메인을 제공하고 랙 간 RDMA 는 InfiniBand 를 사용합니다. H100 시스템은 노드 로컬 NVLink/NVSwitch 와 스케일아웃용 InfiniBand 를 갖춘 8-GPU 노드로 연구 환경에 남아 있었습니다.
각 사이트는 보통 데이터센터 건물 하나당 하나씩 Kubernetes 클러스터로 분할되며, 논리 클러스터는 학습용 GPU 노드와 지원 서비스용 CPU 노드를 포함합니다. 커스텀 컨트롤러가 원하는 논리 클러스터 상태를 기반 Azure 자원과 조정하고, 노드 토폴로지 레이블을 유지하며, 외부 건강 데이터베이스를 스케줄링 상태로 통합합니다. 토폴로지 레이블(topology label) 은 노드가 시작될 때 물리적 호스트 식별자를 사용해 랙, 호스트, 지역성 정보를 표현하도록 부여되어, 물리적 배치를 제어 평면에 보이게 만들고 작업을 가용할 뿐 아니라 토폴로지상 적절한 용량에 배치할 수 있게 합니다. 큰 작업은 필요할 때 단일 Kubernetes 클러스터 경계를 넘어 확장되도록 설계되었고, 노드는 컴퓨트 환경 전반에서 보편적으로 라우팅 가능하며 워크로드 파드는 불필요한 오버레이 오버헤드를 피하기 위해 호스트 네트워킹을 사용합니다.
클러스터 준비와 인증, 노드 수명주기
수천 개 GPU 규모에서 장애는 예외가 아니라 기본값입니다. 따라서 인증(certification) 이 첫 번째 신뢰성 경계 역할을 하여, 불량 노드, 저하된 링크, 한계 스토리지, 무성 손상 위험이 생산 학습 풀에 진입하는 것을 막습니다. 인증 프레임워크는 자동화되어 있고 Kubernetes 네이티브이며 계층적입니다. 하드웨어는 스케줄링 대상이 되기 전 단일 노드 진단, 랙 단위 다중 노드 집합 통신(collective), 선별된 랙 간 InfiniBand 검증 순으로 점차 넓어지는 테스트를 통과해야 합니다. 신규 노드와 수리 후 복귀 노드 모두 같은 경로를 따르므로, 반복 불량 노드가 대형 학습 작업으로 되돌아오는 것을 방지합니다.
진단 스위트는 일반적인 헬스 체크와 달리 GPU, CPU 코어, HCA, NVLink 링크, 메인 메모리 같은 개별 컴포넌트를 장시간 스트레스 테스트하여, 높은 ECC 비율, 불규칙한 스로틀 동작, GPU 클럭 위반, 링크 플랩 등의 한계 조건을 생산 투입 전에 격리합니다. 또한 NCCL 집합 통신으로 노드 내부와 노드 간 통신 경로를 랙별로 스트레스하여 결함 있는 NVLink 동작을 식별하는데, 이 자동 테스트는 GB200 및 GB300 랙 안정화에 결정적이었습니다. 실제로 정상 노드가 16 개 미만인 랙 여러 개가 발견되어 대형 학습 실행에서 제외되었습니다. 인증의 마지막 단계인 랙 간 InfiniBand 테스트는 단일 노드나 랙 단위 테스트가 다룰 수 없는 패브릭 경로를 검사하며, 블래스트 반경이 크기 때문에 브링업, 사고 조사, 패브릭 검증 시 온디맨드로 실행됩니다.
인증은 Figure 26 에 묘사된 폐루프 노드 수명주기의 한 단계입니다. 신규 또는 수리 후 노드는 테인트, 초기화, 레이블링, 구성이 이뤄지는 Init 상태로 진입하고, 인증 컨트롤러가 계층 테스트 스위트를 실행합니다. 통과한 노드는 Available 이 되고 실패한 노드는 Impaired 가 됩니다. 런타임 모니터링은 NPD 조건, XID 오류, ECC 임계 초과, NVLink 저하, InfiniBand 링크 플랩, 스토리지 결함이 감지되면 Available 노드를 Impaired 로 전환할 수 있습니다. 일시적 문제는 재부팅이나 소프트 드레인 같은 자동 교정(Auto Remediation)으로 들어가고, 지속적이거나 하드웨어 기인 문제는 게스트 건강 보고(Guest Health Reporting)를 거쳐 벤더나 데이터센터 유지보수로 라우팅됩니다. 수리된 노드는 다시 Init 으로 돌아와 재인증을 받고, 복구 불가능한 노드는 폐기(Decommissioned)됩니다.
스케줄링과 오케스트레이션, 제어 평면
스케줄링은 지역성, 쿼터 격리, 복구를 희생하지 않으면서 이기종 워크로드를 이기종 용량 위에 배치하는 문제입니다. 워크로드에는 장기 사전학습 작업, 사후학습과 강화학습 실행, 추론과 평가 작업, CPU 집약적 데이터 파이프라인이 포함됩니다. 스택은 계층적으로 구성됩니다. Kubernetes 가 클러스터 상태를 유지하고, Kueue 가 승인과 쿼터 결정을 내리며, MAI 컨트롤러가 예약과 토폴로지 준비 상태를 유지하고, Ray 가 분산 작업을 실행하며, 플릿 전역 제어 평면이 여러 클러스터와 스케줄러 백엔드에 걸친 가시성을 통합합니다.
클러스터 로컬 MAI 제어 평면은 스케줄러를 대체하지 않고 스케줄러가 필요로 하는 상태(예약, 랙 토폴로지, 쿼터 일관성, 스케줄링 준비 게이트)를 유지합니다. Kueue 는 우선순위, 쿼터, 승인, 선점, 토폴로지 인지 배치를 처리하며, 작업이 승인되면 큰 작업이 흩어진 용량이 아니라 조밀한 토폴로지 영역에 들어가도록 고대역폭 도메인 위의 지역성을 보존하려 합니다. 여러 큐에서 나온 작은 작업이 랙을 채워 나중의 큰 작업이 연속 용량을 확보하지 못하는 랙 단편화(rack fragmentation) 는 반복되는 위험입니다. 제어 평면은 이를 소프트 랙 예약으로 다루어 큐마다 선호 랙을 배정하되, 용량이 유휴일 때는 차용을 허용하고 필요 시 reclaimWithinCohort 로 예약 랙을 회수하여, 부하가 높을 때 빈 패킹을 개선하면서 낮은 수요에서는 활용도를 유지합니다. Ray 는 승인된 작업 내부의 분산 런타임을 제공하며, MAI 드라이버가 승인된 토폴로지를 액터 배치, 통신 그룹, NCCL clique 구성으로 변환합니다. 사전학습 작업은 엄격한 러너 가용성을 요구하는 반면, RL 작업은 러너, 추론 서버, 롤아웃 워커, 라우터 등 배치와 내결함성 요구가 서로 다른 여러 액터 유형을 관리합니다.
학습 안정성, 결정론, 가동률 지표
학습 안정성은 작업을 생산적으로 진행시키고, 장애에서 빠르게 복구하며, 재시작 경로 전반에서 수치적 정확성을 보존하는 능력으로 측정되었습니다. 보고서는 가시적 장애와 조용한 효율 손실을 모두 추적했습니다. 가시적 장애에는 크래시루프, 노드 장애, InfiniBand 및 NVLink 링크 플랩과 다운, OOM(out-of-memory) 오류, 파드 종료, 체크포인트 지연, 수동 재요청이 포함됩니다. 조용한 효율 손실에는 MFU 저하, 재연산(recomputation), 긴 시작 경로, 느린 액터 스케줄링, 체크포인트로 인한 정체, 즉시 작업을 중단시키지는 않지만 유용한 처리량을 줄이는 패브릭 상태 등이 포함됩니다.
결정론(determinism) 은 일급 인프라 속성으로 다루어졌습니다. 프런티어 규모에서 결정론적 학습은 모델 코드만의 문제가 아니며, 전체 실행 기반의 정확성과 안정성에 달려 있습니다. 클러스터는 무성 데이터 손상을 제거하고, 통신 토폴로지를 안정적으로 유지하며, 불건전한 디바이스와 링크가 작업에 들어오지 못하게 막고, 체크포인트와 재시작 경계를 넘나들며 부동소수점 리덕션과 누적의 순서를 보존해야 합니다.
굿풋(goodput) 은 핵심 운영 KPI 였습니다. 보고서는 가동률을 이상적 학습 소요 시간 대비 실제 벽시계 소요 시간의 비율로 정의하고, 그 격차를 오버헤드 범주로 분해합니다. 이 관점에서 장애의 비용은 단순한 재시작까지의 시간을 넘어, 마지막 내구성 체크포인트 이후의 재연산을 강제하고, 시작과 액터 스케줄링 지연을 유발하며, 배치를 교란하고, 복구 후 낮은 MFU 를 초래하는 비용까지 포함합니다. 마찬가지로 작업이 계속 실행 중이어도 MFU 하락은 운영 사고로 취급되었는데, 클러스터가 할당된 GPU 시간을 소비하면서 기대보다 적은 학습 진척을 내고 있기 때문입니다. 모든 장애 모드, 런타임 둔화, 체크포인트 이벤트, MFU 회귀에는 담당자, 탐지 신호, 예방 경로, 그리고 실사용 가능 FLOPs 에 대한 정량화된 영향이 부여되었습니다.
전체적인 흐름은 신뢰성에서 효율성으로의 전환이었습니다. 첫 번째 개선 층은 크래시루프, 노드 장애, 링크 플랩, 재요청, OOM, 체크포인트 지연 같은 중단을 줄이는 것이었고, 더 어려운 두 번째 층은 MFU 저하, 재연산, 긴 시작 경로, 느린 프로세스 스케줄링, 체크포인트 정체, 저하된 네트워크나 메모리 동작 같은 무성 가동률 손실을 제거하는 것이었습니다. MAI-Base-1 사전학습 실행은 이전 사전학습 실행보다 큼에도 불구하고 $8$K 개 GPU 에서 90.0\% 의 가동률에 도달했습니다. 총 오버헤드는 51 시간으로 떨어졌습니다. 체크포인트로 되돌아간 뒤 이전에 계산한 스텝을 재현하는 데 쓰인 재연산 시간은 6.5 시간으로, 오버헤드의 15\% 에 불과했습니다. 비(非)스텝핑 시간은 14 시간, 즉 27\% 로 떨어져 시스템이 작업을 살려두고 반복 작업을 피하며 긴 수동 개입 없이 복구하는 데 훨씬 능숙해졌음을 보여줍니다. 다만 최종 실행은 다음 병목도 분명히 드러냈습니다. MFU 하락 오버헤드가 18 시간, 오버헤드의 35\% 로 남은 단일 범주 중 가장 커졌으며, 이는 체크포인팅, 네트워크 저하, 메모리 압박, 하드웨어 건강 전환에서 비롯되었습니다.
관측성과 텔레메트리, 플릿 모니터링
보고서는 저수준 하드웨어 텔레메트리, 스케줄러 상태, 작업 메타데이터, 플릿 효율 신호를 단일 운영 뷰로 결합했습니다. GPU 건강은 XID, ECC, 발열, 전력, 클럭 스로틀링, NVLink 상태, NVLink 비트 오류율(bit-error rate), 칩 간 링크, InfiniBand 디바이스 상태, 로컬 NVMe 건강, PCIe 오류, 드라이버 상태로 추적되었고, 이 신호들은 Kubernetes 노드 컨디션으로 변환된 뒤 커스텀 트리아지/드레인 컨트롤러를 통해 스케줄링과 교정 동작으로 이어졌습니다. 즉 건강이 운영자뿐 아니라 스케줄러에게도 관측 가능해진 것입니다. 작업 관측성은 Kueue, Kubernetes, Ray, 학습 로그, 실험 메타데이터에 걸쳐 조립되어, 운영자가 큐와 우선순위, 승인 상태, 노드 배치, 워커 준비 상태, 재시작 횟수, 스텝 진척, 스코프 로그를 확인하고 스케줄링 지연, 런타임 장애, 노드 장애, 스토리지 저하, 애플리케이션 정체를 구분할 수 있게 했습니다.
텔레메트리는 시간 지평에 따라 서로 다른 시스템에 저장되었습니다. Datadog 이 준실시간 지표와 로그 검색을, Azure Managed Prometheus 가 클러스터 내부 및 클러스터 간 시계열 수집을, Azure Data Explorer 가 로그와 지표, 스토리지 텔레메트리, 클러스터 상태의 장기 보존 분석 저장을 담당했습니다. 핵심 설계점은 관측성이 제어 루프의 일부라는 점입니다. 하드웨어 텔레메트리, 패브릭 건강, 스토리지 동작, 스케줄링 상태, 작업 진척은 수동적 대시보드가 아니라 용량이 승인되는지, 드레인되는지, 교정되는지, 서비스로 복귀하는지를 결정했고, 덕분에 플릿을 단순히 프로비저닝된 GPU 가 아니라 실사용 가능 학습 용량과 가동률 관점에서 관리할 수 있었습니다. 알림 체계도 같은 계층 모델을 따랐습니다. 저지연 컴포넌트 장애는 로컬 Prometheus 규칙이, 서비스와 로그 기반 신호는 Datadog 모니터가, 장기 보존 분석은 KQL 기반 점검이, 리소스와 Prometheus 경보는 Azure Monitor 가 담당했습니다. 심각도가 높은 경보는 사고 관리(incident management)로 라우팅되고, 낮은 심각도의 신호는 대시보드와 운영 리뷰로 전달되었습니다.
추론 효율과 모델 배포
추론(inference) 비용, 지연 시간, 서빙 확장성이 배포의 핵심 제약으로 떠오르면서, 보고서는 모델 아키텍처, 서빙 엔진, 그리고 배포 하드웨어 선택에 이르기까지 추론 효율을 일급 목표로 다루었습니다. 와트당 성능을 높이기 위해 MAI-Thinking-1 은 Microsoft 의 MAIA-200 하드웨어 위에 구현되었습니다. GB200 기반 배포와 비교했을 때 MAIA-200 은 동일한 랙 전력 예산 아래에서 40\% 넘게 높은 토큰 생성 처리량을 제공하며, 이러한 와트당 성능 개선은 데이터센터 전력의 효율적 활용과 대규모 추론 워크로드 서빙을 뒷받침합니다.
지속 가능성과 커뮤니티 우선 인프라
보고서는 AI 개발이 사회적, 환경적으로, 그리고 인프라가 구축되고 운영되는 지역사회 안에서 지속 가능해야 한다고 강조합니다. Microsoft 는 탄소 네거티브, 물 포지티브, 폐기물 제로를 약속하고 있으며, 2025년에는 연간 글로벌 전력 소비의 100\% 를 재생에너지로 상쇄하는 이정표를 달성했습니다. MAI-Thinking-1 은 주로 애리조나주 피닉스의 자사 인프라에서 학습되었는데, 이 시설은 환경 지속 가능성과 에너지 효율성을 인정하는 LEED Gold 인증 기준에 맞춰 건설되었으며, 백업 발전기에는 기존 석유계 디젤보다 순탄소 배출을 줄이는 재생 디젤이 사용됩니다.
Microsoft 의 커뮤니티 우선 AI 인프라 이니셔티브는 환경 영향을 최소화하고 지역사회에 투자하는 것을 약속합니다. 이는 피닉스 지역 유틸리티, 수자원 당국, 보전 단체와의 긴밀한 협력에 기반하여 공유 인프라를 강화하면서 전체 시스템 수요를 줄이는 접근입니다. 회사는 굿이어시와의 지자체 물 저장 시설을 비롯해 공공 수자원 확충에 5{,}000 만 달러 이상을 투입했으며, 상하수도 파이프라인 확장과 시스템 개선 자금을 함께 지원했습니다. 또한 힐라강 물 저장 시스템과 더 네이처 컨서번시 같은 파트너와 협력해 지하수 충전과 분지 단위 효율 개선을 돕고, 에스트렐라 마운틴 커뮤니티 칼리지와 글렌데일 커뮤니티 칼리지에서 운영하는 데이터센터 아카데미를 통해 장기 인력 양성에 투자하고 있습니다.
결론 및 향후 방향
보고서는 데이터와 인프라부터 RL 레시피와 평가에 이르기까지 파이프라인의 모든 구성 요소를 최적화하는 모델 개발 접근법으로 힐 클라이밍 머신(hill-climbing machine) 을 제시합니다. MAI-Thinking-1 은 이 머신이 만들어낸 첫 모델로, 제3자 모델로부터의 증류(distillation) 없이 학습된 활성 $35$B / 전체 $1$T 파라미터 규모의 MoE 이며, STEM 추론과 소프트웨어 엔지니어링 작업에서 동일 체급의 가장 강력한 모델들 중 하나로 꼽힙니다.
보고서는 MAI-Thinking-1 을 종착점이 아니라 출발점으로 규정합니다. 앞으로는 힐 클라이밍을 더 많은 모달리티, 더 큰 규모, 더 정교한 역량으로 확장할 계획입니다. AI 의 발전은 어느 단일 모델의 산물이 아니라 신뢰할 수 있게 개선될 수 있는 파이프라인의 산물이라는 것이 핵심 메시지이며, 보고서는 자신들의 파이프라인을 계속 다듬어 향후의 등반 진척을 공유하겠다는 다짐으로 마무리됩니다.
읽고 나면 이 보고서가 왜 "모델 학습 과정 전반을 살펴볼 수 있는 가이드"로 평가받는지 수긍하게 됩니다. 아키텍처 선택 하나하나를 어떤 실험으로 검증했는지, 데이터 혼합 가정이 규모에서 어떻게 깨지는지, RL 을 수천 스텝 동안 지속하기 위한 공학적 장치가 무엇인지까지, 다른 기술 보고서들이 흔히 생략하는 "어떻게"가 충실히 담겨 있기 때문입니다. 프런티어 모델을 직접 만들 일이 없더라도, 대규모 학습 파이프라인의 설계 감각을 기르고 싶은 분들께 일독을 권합니다.
 Microsoft AI 홈페이지
Microsoft AI 홈페이지
 MAI-Thinking-1: Building a Hill-Climbing Machine 기술 보고서
MAI-Thinking-1: Building a Hill-Climbing Machine 기술 보고서
더 읽어보기
-
OpenAI가 공개한, 소프트웨어 개발 주기별 AI 네이티브 엔지니어링 팀 구축 가이드 (feat. Codex)
-
사고 패치(Thought Patching): 프롬프트를 가중치로 바꾸는 모델 편집에 대한 연구 (feat. Google)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()