Agent Learning Hub 소개
AI 에이전트라는 키워드는 자료가 폭발적으로 늘었지만, 막상 "어디서부터 어떻게 공부해야 진짜 작동하는 것을 만들 수 있을지" 결정하기는 점점 더 어려워졌습니다. Crew/Role-Play 풍의 데모는 인상적이지만 실제 운영에 옮기면 안정성이 떨어지고, 반대로 단순한 워크플로우만 다루던 글은 도구 사용·권한·평가·관측을 전혀 다루지 않습니다. Agent Learning Hub 는 이 간극을 줄이기 위해 Datawhale 멤버인 陈思州(jjyaoao)가 큐레이션한 AI 에이전트 학습 로드맵 저장소 입니다. 별도의 라이브러리나 SDK를 제공하지 않고, 단 하나의 README 파일만 유지하면서 읽고 따라 실행할 수 있는 todo list 형태로 학습 코스를 제시합니다.
저장소의 입장은 분명합니다. "역할극(role-play) 다중 에이전트 프레임워크에 노력을 몰빵하지 말라"는 것입니다. 대신 다섯 가지 우선순위를 명시합니다. Claude Code·Codex 같은 코딩 에이전트의 실제 코드베이스 작업 패턴, 도구 프로토콜·권한·상태·평가를 포함한 agent harness 엔지니어링, OpenClaw·Hermes 풍의 장시간 개인 에이전트, Skills·MCP·A2A·ACP 등 능력 재사용 프로토콜, 그리고 평가와 안전이 그것입니다.
본 게시물에서는 이 저장소가 제시하는 9단계 학습 코스 의 구조와, 각 단계에서 권장하는 자료·실습 산출물, 그리고 "읽기만 하는 학습"을 피하기 위해 권장하는 11단계 프로젝트 사다리(Project Ladder) 를 차례로 살펴봅니다. 또한 큐레이션된 외부 자료의 분류 체계와, README 한 장만 유지하는 운영 방식의 의미도 함께 정리합니다.
Agent Learning Hub의 학습 우선순위와 현재 흐름
Agent Learning Hub는 README 첫 머리에서 "지금 무엇을 학습해야 하는가(What To Learn Now)" 를 표 한 장으로 정리합니다. 노후화된 role-play 프레임워크 대신, 실제 생산성을 만들어내는 다섯 가지 방향에 집중하라는 메시지입니다.
| 우선순위 | 학습 대상 | 이유 |
|---|---|---|
| 1 | Claude Code / Codex 풍 coding agent | 실제 코드베이스, shell, 파일 편집, 테스트, 권한, 컨텍스트 압축 등 가장 좋은 엔지니어링 샘플 |
| 2 | Agent harness 엔지니어링 | 에이전트 능력의 상당 부분은 도구 프로토콜·권한·상태·피드백·재실행·CI·평가에서 나옴 |
| 3 | OpenClaw / Hermes 풍 personal agent | 장시간 운영, 로컬 우선, 크로스 앱, 기억, skills, 메시지 입구로 "개인용 운영체제"에 가까운 형태 |
| 4 | Skills / MCP / A2A / ACP | skills는 능력 재사용, MCP는 도구 연결, A2A는 에이전트 간 연결, ACP는 호스트 앱 연결 |
| 5 | Evaluation & Safety | eval·trace·권한 경계가 없는 에이전트는 데모일 뿐 |
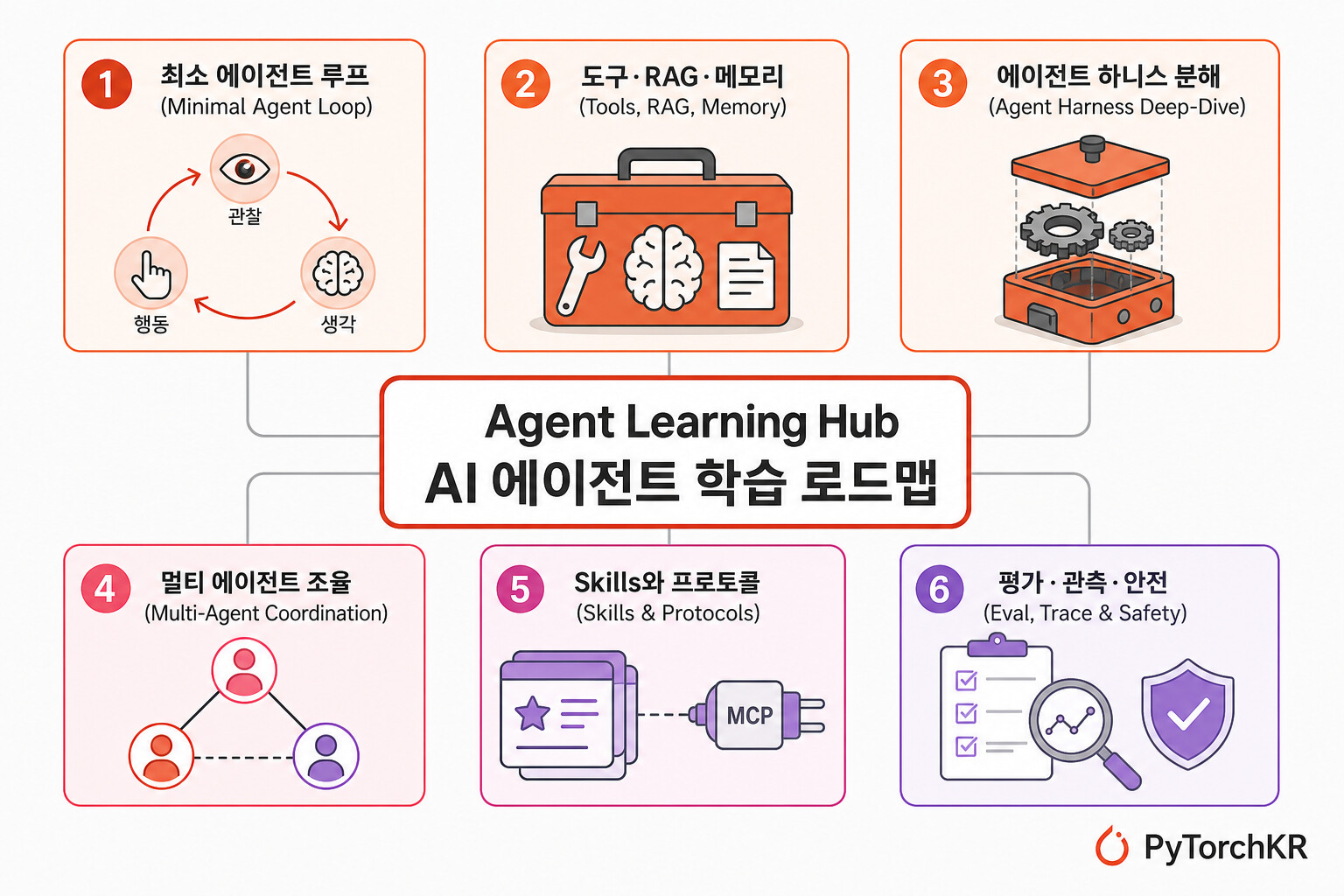
Agent Learning Hub의 9단계 학습 코스
저장소는 Stage 0 부터 Stage 8 까지 총 9개의 단계를 정의합니다. 각 단계는 체크박스로 표시된 todo list 와 마지막에 제출해야 하는 산출물(产出) 로 구성되어 있어, 단순히 읽고 끝내는 학습이 아니라 단계마다 한 가지를 실제로 만들어 두는 흐름을 강제합니다. 아래 단계별 링크는 모두 저장소 README의 해당 섹션 anchor로 연결됩니다.
- Stage 0: 에이전트가 무엇인지 이해하기: chatbot, workflow, agent, multi-agent의 차이를 구분하고
observe -> think -> act -> observe의 기본 루프를 머리에 각인합니다. Anthropic의 Building effective agents와 OpenAI의 A practical guide to building agents를 필수 자료로 지정합니다. 언제 에이전트를 쓰지 말아야 하는지 도 함께 다룹니다. 산출물은 "내 시나리오에 왜 에이전트가 필요한가"를 한 페이지로 설명하는 노트입니다. - Stage 1: 최소 에이전트 루프 만들기: LLM API 호출, 구조화된 JSON 출력, 도구 함수 정의와 tool call 파싱, 도구 실행 결과를 다시 모델에 주입하기, 그리고 최대 단계 수·타임아웃·에러 처리를 포함한 50~150줄 규모의 최소 에이전트를 만듭니다. OpenAI Function Calling, Gemini Function Calling, Claude Tool Use 공식 문서를 함께 읽기 자료로 제시합니다.
- Stage 2: 도구 사용·RAG·메모리: chunk·embed·retrieve, 검색·DB·파일·브라우저·코드 실행 도구 통합, 단기 컨텍스트와 장기 메모리 구분, 인용 출력, 그리고 도구 실패·빈 결과·중복 호출·환각 인용 처리까지 다룹니다. GPT Researcher, Open Deep Research, STORM, Khoj, Onyx, AnythingLLM, RAGFlow, mem0, Letta 같은 오픈소스 참조 프로젝트가 단계별로 매핑되어 있고, 산출물은 주제를 입력하면 자동으로 검색·요약·인용을 출력하는 자료 연구 보조 에이전트 입니다.
- Stage 3: 현대적 에이전트 하니스 한 가지를 깊게 분석: Claude Code 공식 문서와 learn-claude-code, claw0, hello-agents 같은 from-scratch 구현체 중 하나를 골라 디렉토리 구조·agent loop·tool registry·permission gate·session store·context compaction 을 분해합니다. 단순히 API 호출법을 외우는 게 아니라, 같은 작업을 "맨 agent loop" 과 "harness" 로 각각 구현해 그 차이를 직접 관찰하는 게 목표입니다.
- Stage 4: 멀티 에이전트는 마법이 아닌 조율: planner·executor·reviewer·critic·router 같은 역할, supervisor 또는 graph 기반 관리, 각 에이전트의 책임 경계와 입출력 스키마·정지 조건, 그리고 언제 단일 에이전트가 더 나은가 까지 다룹니다. 산출물은 research → write → review → revise 같은 소형 멀티 에이전트 시스템입니다.
- Stage 5: Skills, 프로토콜, 능력 패키징: Skill 과 Tool, Prompt, MCP 의 차이를 분리해 이해하고, 최소
SKILL.md와 스크립트·smoke test 를 직접 작성합니다. Claude Code Skills, OpenClaw Skills 의 구조와 트리거 메커니즘을 비교 학습하며, 산출물은 code-review·research-report·migration-helper·pdf-extraction·release-note-writer 같은 재사용 가능한 skill 한 개입니다. - Stage 6: 브라우저·컴퓨터 사용 에이전트: Playwright 또는 browser-use로 페이지 관찰·조작, 안전 제한, 변화 대응, 그리고 스크린샷·DOM·동작 로그 기록을 다룹니다. 참고 문헌으로 WebArena와 VisualWebArena 가 포함되어 있어, 공개 웹페이지만 다루는 안전한 브라우저 에이전트를 산출물로 요구합니다.
- Stage 7: 평가·관측·안전: 고정 테스트셋, 성공률·실패 원인·도구 호출 수·비용·지연 기록, trace 분석, 위험 도구에 대한 사람 확인, prompt injection·data exfiltration·tool abuse 등 리스크 식별까지 포함합니다. 산출물은 최소 20개 작업 × 기대 결과 × 실제 결과 × 실패 분류 가 포함된 eval 표입니다.
- Stage 8: 진짜 에이전트 출시: 사용자·작업·성공 기준이 명확하고, 로그·trace·재시도·타임아웃·비용 상한이 잡혀 있으며, 권한 경계와 사람 승인 메커니즘이 있고, CLI·Web app·Slack bot·GitHub Action 같은 배포 방식이 명시된 상태로 마무리합니다. 남이 그대로 clone 해서 돌릴 수 있는 에이전트 프로젝트 가 최종 산출물입니다.

Agent Learning Hub의 Project Ladder
이론을 읽는 것만으로는 에이전트 엔지니어링 감각이 잡히지 않는다는 전제 아래, 저장소는 Project Ladder라는 11단계 프로젝트 시리즈를 함께 제시합니다. 단계가 올라갈수록 다루는 시스템 컴포넌트의 수가 늘어나며, 각 레벨은 별도의 README가 있는 클론 가능한 형태로 마무리 하는 것을 목표로 합니다.
| Level | 프로젝트 | 무엇을 배우는가 |
|---|---|---|
| 1 | Calculator Agent | 최소 tool call 루프 |
| 2 | Web Research Agent | 검색, 필터, 인용, 요약 |
| 3 | PDF QA Agent | RAG, chunk, retrieval, citation |
| 4 | Coding Review Agent | diff 읽기, 위험 정렬, 테스트 제안 |
| 5 | Browser Agent | 페이지 관찰, 클릭, 추출, 실패 회복 |
| 6 | Claude Code-like Nano Agent | shell, 파일 편집, 권한, session, compaction |
| 7 | OpenClaw-like Gateway | channel, routing, session, memory, heartbeat |
| 8 | Reusable Skill Pack | SKILL.md, 스크립트, 템플릿, 트리거 조건, smoke test |
| 9 | Multi-Agent Writer | planner, writer, reviewer 협업 |
| 10 | Personal Agent | OpenClaw/Hermes 스타일 메모리, 스킬, 메시지 입구 |
| 11 | Production Harness | evals, trace, 권한, CI, runner, 재실행 |
다음 사람이 그대로 받아 돌릴 수 있는 수준까지 마감해야 한다는 기준이 학습 코스의 산출물 기준과 일치합니다. 9단계 학습 코스가 읽고 정리하는 축 이라면, Project Ladder는 만들고 공개하는 축 입니다.
Agent Learning Hub의 큐레이션 자료
학습 코스 뒤에는 Curated Resources 섹션이 따라옵니다. 공식 문서·블로그, 프로젝트 맵, Skills/Protocols/Tooling, 현대 에이전트 시스템, 레거시·옵션 프레임워크, 논문, GitHub 저장소, Thoughtful Blogs, Claude Code Study Path 까지 분류되어 있습니다.
특히 Project Map은 별 수가 아닌 학습 목적으로 프로젝트를 묶어 둔 점이 인상적입니다. Build From Scratch 레이어는 learn-claude-code, claw0, hello-agents를 묶고, Coding Agents 레이어는 Claude Code, OpenAI Codex, OpenCode, OpenHands, SWE-agent, pi를 함께 두어 비교 학습을 유도합니다. Personal / Always-On Agents 레이어에는 OpenClaw, Hermes Agent, CyberClaw가, Browser / Multimodal Agents 레이어에는 browser-use, UI-TARS-desktop이 묶여 있습니다.
Skills, Protocols, And Tooling 표는 Skills / MCP / A2A / ACP 의 역할을 한 줄씩으로 구분합니다. Skills 는 한 가지 작업 부류의 흐름 지식·스크립트·템플릿·합격 기준을 재사용 가능한 능력 패키지로 묶는 것, MCP 는 외부 도구·데이터소스 표준 연결, A2A 는 에이전트 간 발견·통신·협업, ACP 는 에디터·터미널·IDE 같은 호스트 앱과 에이전트 사이의 통합 인터페이스를 담당합니다.
Papers 섹션은 ReAct, Toolformer, Reflexion, Generative Agents, Voyager, AgentBench, WebArena, SWE-bench, SWE-agent 등 에이전트 연구의 기초가 되는 논문을 한자리에 모아 둡니다.
Agent Learning Hub의 학습 원칙
저장소의 Learning Principles 는 운영 관점을 한 줄로 정리합니다. "Build first, then read deeper. Prefer small reliable agents over impressive demos. Use tools with strict schemas. Add evals before you add more agents. Trace every important run. Treat multi-agent as a coordination problem. Keep humans in the loop for risky actions. Respect platform rules, copyrights, and data access boundaries."
이 원칙은 본 저장소의 유지 정책 과도 연결됩니다. README 한 장만 두고, 외부 PR로 자료를 보강하며, 트렌드를 따라 추가만 하는 게 아니라 오래된 프레임워크에 매몰되지 말 것 을 명시적으로 권고합니다.
Agent Learning Hub 사용법
저장소를 활용하는 가장 단순한 방법은 README를 그대로 학습 체크리스트로 사용하는 것입니다. 별도의 설치 단계가 없으며, GitHub에서 README를 열어 본인이 어느 단계인지 표시하고 산출물을 GitHub Issue나 자신의 저장소에 정리해 나가면 됩니다. 이미 LLM 애플리케이션 경험이 있다면 Stage 2 또는 Stage 3 부터 시작 해 agent loop·도구 사용·평가·엔지니어링을 보강하는 식의 진입이 권장됩니다.
# 저장소 자체에는 코드가 없으므로 단순 clone 으로 충분합니다
git clone https://github.com/datawhalechina/Agent-Learning-Hub.git
cd Agent-Learning-Hub
# README.md 를 학습 체크리스트로 사용
기여를 원한다면 저장소의 CONTRIBUTING.md를 따라 새로운 자료·논문·프로젝트 링크나 학습 단계 보강을 PR 형태로 제안할 수 있습니다.
라이선스
Agent Learning Hub는 MIT License 로 공개되어 있어, 학습 자료의 인용·재배포·번역에 큰 제약이 없습니다. 다만 README가 참조하는 외부 자료(공식 문서, 논문, 타 오픈소스)는 각자의 라이선스를 따르므로, 자료를 자신의 글이나 강의에 옮길 때는 출처를 함께 표기하는 것이 안전합니다.
 Agent Learning Hub 프로젝트 GitHub 저장소
Agent Learning Hub 프로젝트 GitHub 저장소
더 알아보기
-
AI 에이전트 프로토콜 개발자 가이드: MCP부터 A2A, UCP, AP2, A2UI, AG-UI까지 (feat. Google)
-
Anthropic, Claude에 업무 방식과 조직 환경에 맞게 직접 커스터마이징할 수 있는 Claude Agent용 Skills 기능 출시
-
Microsoft Agent Framework: Microsoft가 새롭게 공개한 Multi-Agent Framework (feat. Python, C#/.NET)
-
[Deep Research] Model Context Protocol(MCP) 개념 및 이해를 위한 학습 자료
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()