
AutoKernel 소개
현대의 딥러닝 모델, 특히 대규모 언어 모델(LLM)을 학습하거나 추론할 때 GPU 연산의 병목 현상을 해결하는 것은 매우 중요합니다. 이를 위해 CUDA나 Triton과 같은 저수준 언어로 하드웨어에 맞게 GPU 커널을 최적화하는 작업이 필수적이지만, 이는 고도의 전문 지식과 끝없는 디버깅 시간을 요구하는 까다로운 영역입니다.
이러한 문제를 해결하기 위해 등장한 오픈소스 프레임워크가 바로 AutoKernel입니다. 이 프로젝트는 유명 AI 연구자 안드레이 카파시(Andrej Karpathy)가 선보였던 LLM 학습을 위한 자율 AI 연구 에이전트인 Auto Research 프로젝트에서 직접적인 영감을 받아 탄생했습니다.

일반적으로 GPU 커널 최적화는 사람이 직접 프로파일러를 보며 코드를 한 줄 한 줄 수정하고 컴파일하여 성능을 테스트하는 지루한 반복 작업(Manual Iteration)을 거칩니다. 반면,
AutoKernel은 Auto Research의 자율 연구 철학을 GPU 커널 최적화 영역으로 가져왔습니다.
개발자가 PyTorch 모델을 제공하고 코딩 에이전트(Claude, Codex 등)를 실행해두면, 에이전트가 단일 커널 파일을 수정하고 벤치마크를 실행한 뒤 결과를 평가하여 코드를 유지할지 되돌릴지 끝없이 반복합니다. 즉, 개발자가 잠든 사이 AI가 병목 지점을 찾아내고 스스로 코드를 깎아내어 최적화된 Triton 커널을 완성해 내는 혁신적인 도구입니다.
기존에는 수작업으로 인해 병목이 큰 몇 개의 커널에만 최적화 시도가 국한되었다면, AutoKernel은 1회 실험에 약 90초만을 소모하며, 밤새 320회 이상의 실험을 모든 병목 커널에 걸쳐 지치지 않고 자동으로 수행할 수 있다는 점에서 압도적인 생산성 차이를 보여줍니다.
AutoKernel의 구조 및 동작 파이프라인
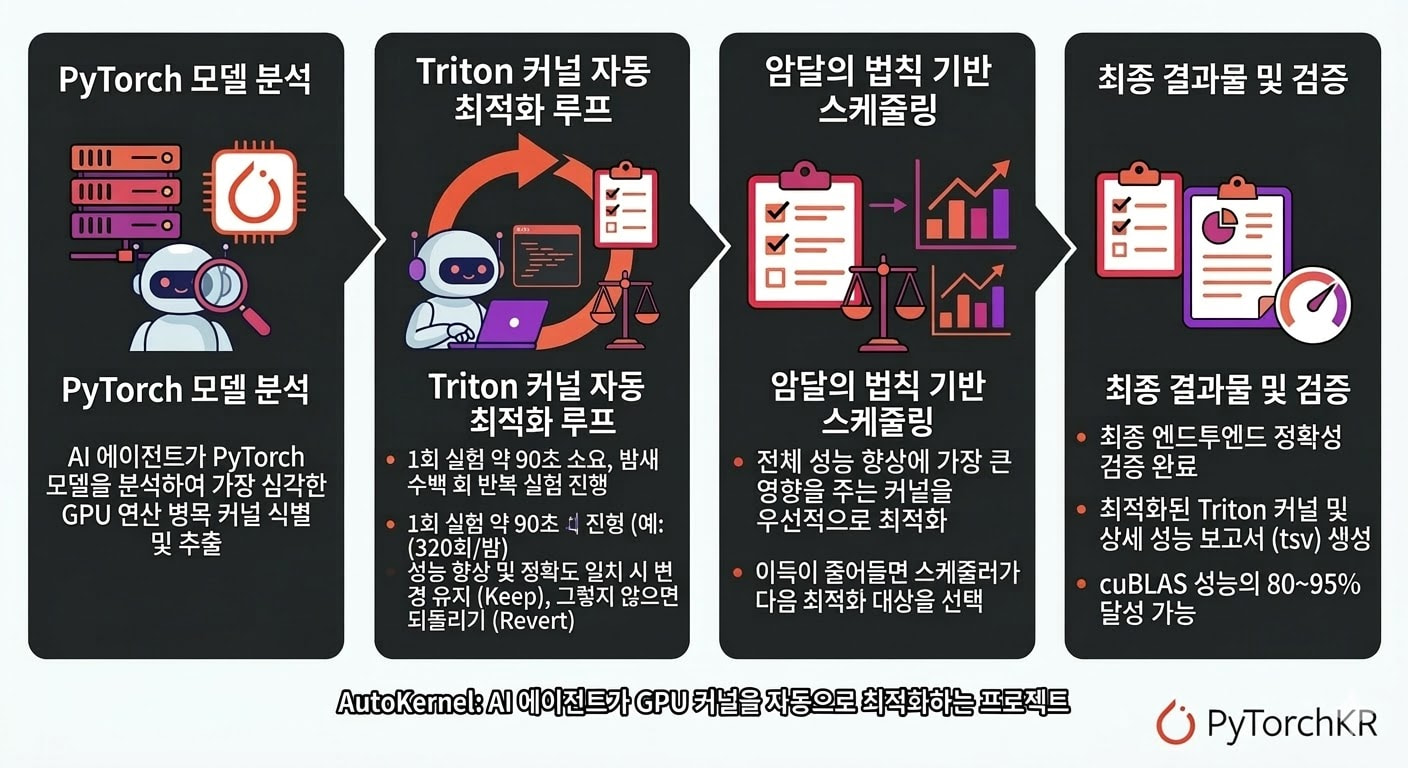
AutoKernel은 여러 단계의 스크립트를 통해 모델 분석부터 최종 검증까지의 전체 과정을 매끄럽게 연결합니다:
-
profile.py(프로파일링): 제공된 PyTorch 모델을torch.profiler를 사용하여 프로파일링합니다. GPU 시간을 가장 많이 소모하는 커널을 순위대로 나열하고, 연산 중심(Compute-bound)인지 메모리 중심(Memory-bound)인지 분류합니다. -
extract.py(커널 추출): 프로파일링 결과를 바탕으로 최적화가 필요한 상위 N개의 병목 커널을 독립적으로 실행 가능한 Triton 커널 파일로 작업 공간(workspace)에 추출합니다. -
orchestrate.py(스케줄링): 여러 커널 중 어떤 것을 먼저 최적화할지 결정하는 멀티 커널 스케줄러입니다. 암달의 법칙(Amdahl's law)을 사용하여 전체 시스템 성능에 가장 큰 영향을 미치는 커널을 우선적으로 선택합니다. -
bench.py(벤치마킹 및 5단계 검증): AI 에이전트가 수정한 코드를 평가하는 고정 벤치마크 도구입니다. 스모크(Smoke) 테스트, 형태(Shape) 스윕, 수치적 안정성, 결정론(Determinism), 엣지 케이스 등 5단계의 정확성 검사와 루프라인 분석을 수행합니다. -
verify.py(엔드투엔드 검증): 최적화가 완료된 커널을 원래의 모델에 다시 연결하여 엔드투엔드(End-to-end) 정확성을 검증하고, PyTorch/cuBLAS 대비 최종적으로 얻은 총 속도 향상(Speedup) 비율을 보고합니다.
AutoKernel의 주요 특징
AutoKernel의 핵심 설계 철학
AutoKernel 프레임워크가 AI 에이전트와 효과적으로 협업할 수 있도록 설계된 핵심 원칙은 다음과 같습니다:
-
Triton 언어 채택: 인라인 PTX나 SASS 대신, Python과 문법이 유사하여 AI 에이전트가 쉽게 읽고 수정할 수 있는 Triton을 사용합니다. Triton은 컴파일 시간이 수 초 단위로 매우 짧아 빠른 반복 실험에 유리하며, 잘 튜닝될 경우 cuBLAS의 80~95% 성능을 달성할 수 있습니다.
-
정확성 우선 (Correctness First): 성능을 측정하기 전에 항상 PyTorch 출력값과 커널의 출력값을 비교하여 일치하는지 확인합니다. 만약 AI가 최적화를 핑계로 잘못된 쓰레기 값을 뱉어내는 코드를 작성하면, 즉시 해당 변경 사항을 폐기(Revert)하여 안전성을 보장합니다.
-
암달의 법칙 적용 (Amdahl's Law): 모델 전체 실행 시간의 5%를 차지하는 커널을 3배 빠르게 만드는 것보다, 60%를 차지하는 커널을 1.5배 빠르게 만드는 것이 전체 성능에 훨씬 유리합니다.
orchestrate.py는 이러한 수확 체감의 법칙을 계산하여 영리하게 다음 타겟을 변경합니다. -
단일 파일 수정 (Single File Modification): 에이전트가 길을 잃지 않도록, 한 번에
kernel.py라는 단일 파일만 수정하도록 범위를 제한합니다. 이를 통해 코드의 Diff(변경 사항)를 명확히 리뷰할 수 있고 롤백이 깔끔해집니다. -
TSV 로깅: 모든 실험 결과는 복잡한 인프라 없이
results.tsv라는 탭으로 구분된 텍스트 파일에 기록되어, Git으로 관리하기 쉽고 사람과 기계 모두 파싱하기 좋습니다.
지원되는 커널 및 내장 모델
AutoKernel은 현대 딥러닝에서 가장 자주 쓰이는 9가지 핵심 연산을 지원하며, 시작점으로 활용할 수 있는 기본 Triton 커널(kernels/)과 PyTorch 참조 코드(reference.py)를 제공합니다:
-
지원 커널:
matmul(TFLOPS),softmax(GB/s),layernorm(GB/s),rmsnorm(GB/s),flash_attention(TFLOPS),fused_mlp(TFLOPS),cross_entropy(GB/s),rotary_embedding(GB/s),reduce(GB/s) -
내장 모델: 무거운 외부 라이브러리 설치 없이 바로 테스트할 수 있도록 독립적인 모델 파일들이
models/디렉토리에 내장되어 있습니다. GPT-2 Small(124M), LLaMA Compact(160M), LLaMA 7B, BERT-base(110M)를 지원하며 커스텀 모델을 위한 템플릿도 제공됩니다. (필요 시transformers라이브러리를 통한 HuggingFace 모델 연동도 지원합니다.)
AutoKernel 설치 및 실행 방법
NVIDIA GPU (H100, A100, RTX 4090에서 테스트됨), Python 3.10 이상 환경, 그리고 빠른 Python 패키지 관리자인 uv가 필요합니다.
# 1. uv 설치 (없는 경우)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 프로젝트 클론 및 패키지 동기화
git clone https://github.com/RightNow-AI/autokernel.git
cd autokernel
uv sync
# 3. 1회성 초기 셋업 (테스트 데이터 및 베이스라인 생성)
uv run prepare.py
# 4. 내장 LLaMA 모델 프로파일링
uv run profile.py --model models/llama_7b.py --class-name LlamaModel \
--input-shape 1,512 --dtype float16
# 5. 상위 5개의 병목 커널 추출
uv run extract.py --top 5
# 6. 벤치마크가 정상 작동하는지 확인
uv run bench.py
준비가 완료되면 해당 디렉토리에서 코딩 에이전트(Claude 등)를 실행하고, 저장소 내의 program.md (자율 운영 지침서)를 읽게 한 뒤 새로운 실험을 시작하라고 명령을 내리면 자율 최적화 루프가 시작됩니다.
라이선스
AutoKernel 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
 AutoKernel 프로젝트 GitHub 저장소
AutoKernel 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()