Auto Research 소개
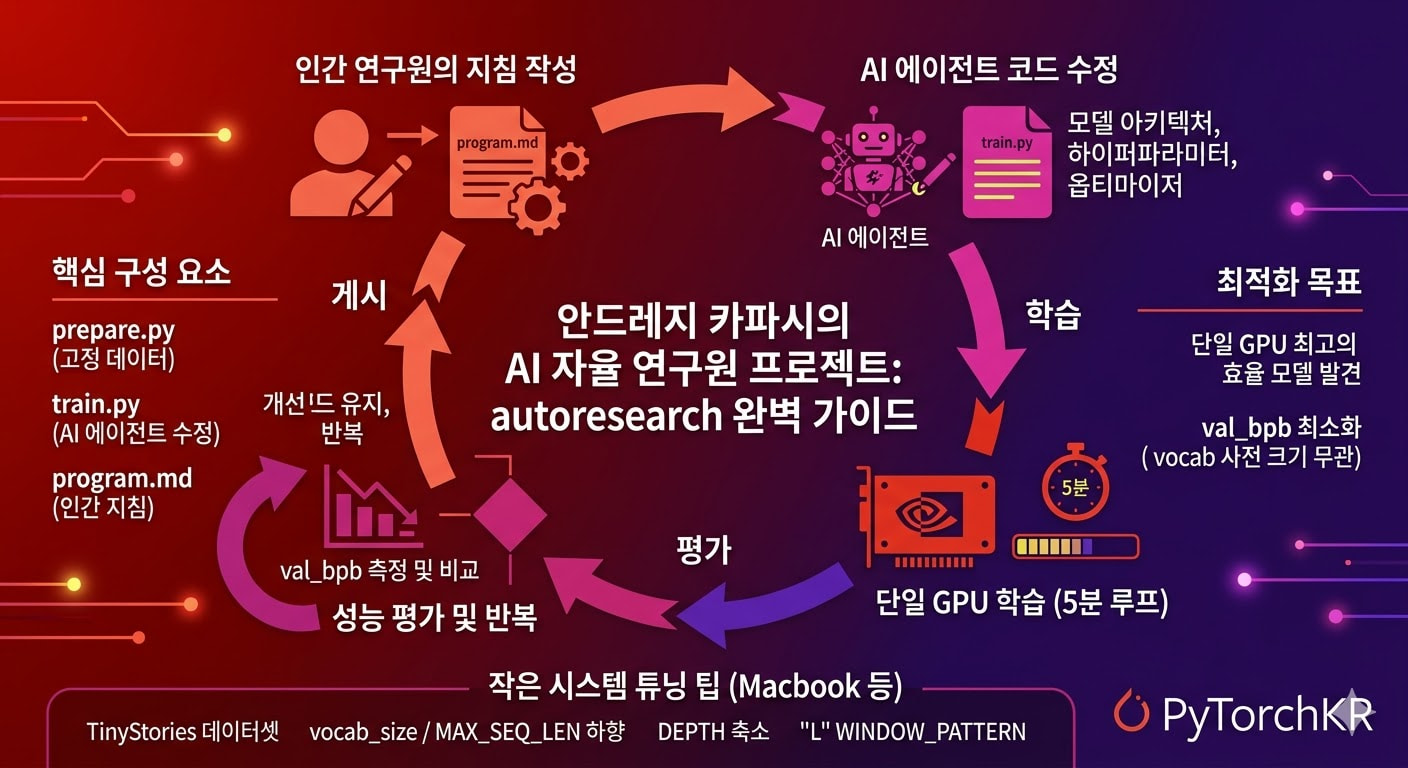
OpenAI의 전 핵심 연구원이자 저명한 AI 개발자인 안드레이 갓카파시(Andrej Karpathy)가 2026년 3월에 새롭게 공개한 Auto Research는 AI 에이전트가 스스로 모델 연구와 학습을 진행하도록 설계된 혁신적인 오픈소스 프로젝트입니다. 과거의 최전선 AI 연구는 연구원들이 식사하고 수면을 취하는 시간 사이에 직접 코드를 수정하고, 주기적으로 미팅을 통해 진행 상황을 동기화하는 방식이 주를 이루었습니다. 하지만 카파시는 이 프로젝트를 통해 이러한 시대가 저물고, 이제는 대규모 컴퓨팅 클러스터 위에서 수많은 AI 에이전트 군집(Swarm)이 자율적으로 연구를 주도하는 시대가 도래했음을 보여주고자 합니다. 인간이 파이썬 코드를 한 줄 한 줄 짜는 대신, AI 에이전트가 실험하고 발전할 수 있는 지침과 환경만을 마크다운(Markdown) 문서로 제공하는 새로운 패러다임의 전환을 제시합니다.
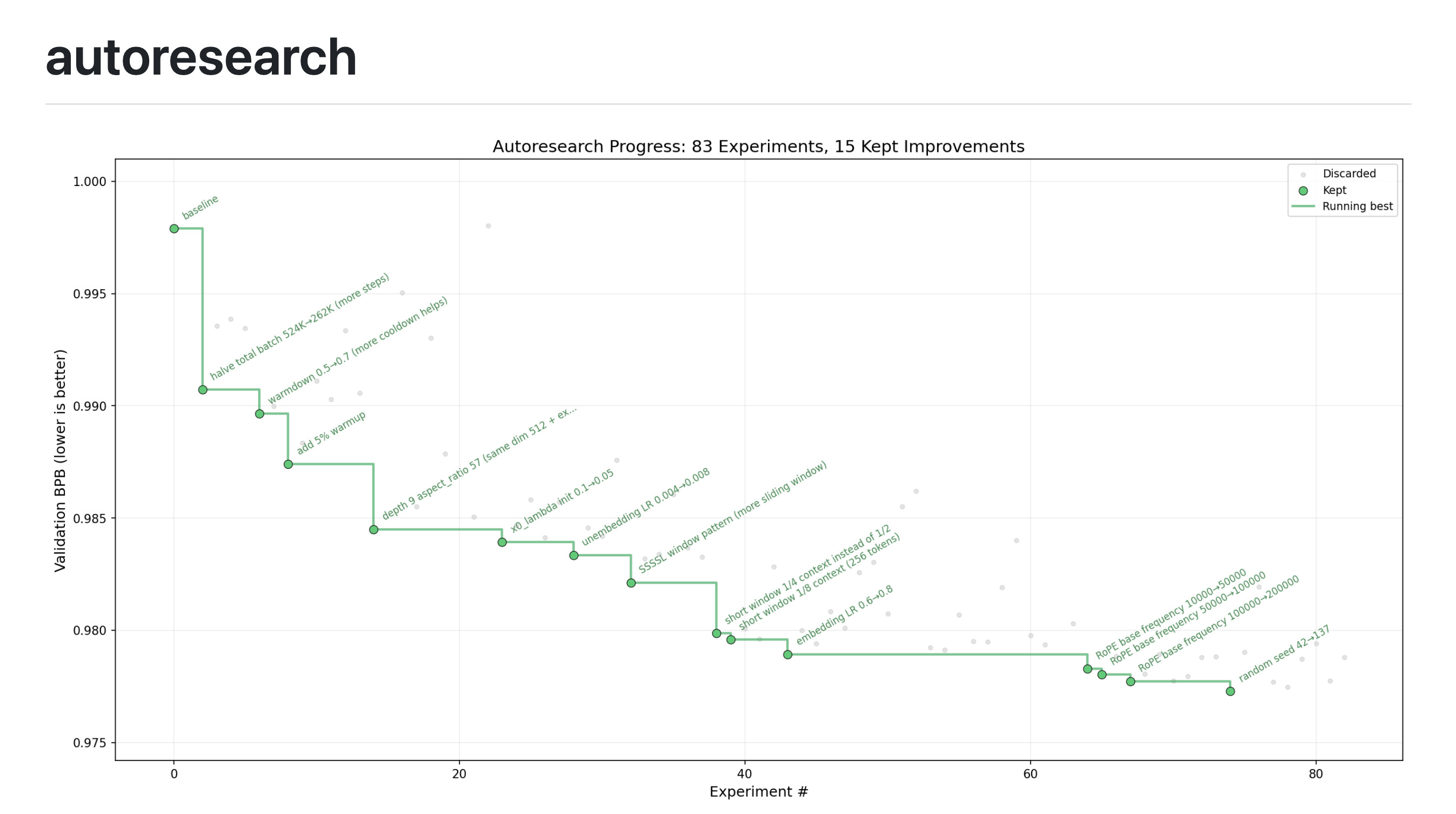
Auto Research 프로젝트는 단순히 코드를 자동 생성하는 도구를 넘어, 소규모지만 실제적인 LLM(대규모 언어 모델) 학습 환경을 AI에게 온전히 맡긴다는 점에서 그 의미가 깊습니다. 개발자가 퇴근 전 AI 에이전트에게 지시를 내리면, 에이전트는 밤새 자율적으로 실험을 반복합니다. 스스로 코드를 수정하고, 5분 동안 모델을 학습시킨 뒤 결과 지표를 평가하여 이전보다 성능이 개선되었는지 확인합니다. 개선되었다면 변경 사항을 유지하고, 그렇지 않다면 폐기하는 과정을 무한히 반복하게 됩니다. 개발자는 다음 날 아침에 일어나 AI가 남긴 실험 로그와 스스로 최적화해 낸 더 나은 성능의 모델을 확인하기만 하면 됩니다.
결과적으로 Auto Research는 인간의 개입 없이도 주어진 하드웨어 환경(예: 단일 H100 GPU)에서 최고의 효율을 내는 모델 아키텍처와 하이퍼파라미터를 스스로 찾아내는 "자율 연구 기관"을 구축하는 기틀을 마련해 줍니다. 현재의 코드베이스가 향후 수만 번의 세대를 거치며 인간이 이해할 수 없는 수준의 자체 수정 바이너리로 진화할지라도, 이 프로젝트는 그 모든 자율적 AI 연구의 역사적인 시작점(The story of how it all began) 으로서 커다란 가치를 지닙니다.
Auto Research의 핵심 아이디어 및 동작 원리
Auto Research는 개발자가 직접 파이썬 코드를 건드리는 대신, 프로그램을 프로그래밍하는 방식을 채택했습니다. AI 에이전트는 코드의 구조나 하이퍼파라미터, 옵티마이저 등을 자유롭게 수정하며 자율 학습 루프를 구성합니다. 또한, AI 에이전트는 코드를 수정한 후 정확히 5분(Wall-clock 기준, 시작/컴파일 시간 제외) 동안만 학습을 진행합니다.
이러한 학습이 끝나면 val_bpb (Validation bits per byte) 지표를 측정합니다. 이 수치가 낮을수록 성능이 우수한 것이며, 어휘 사전의 크기(Vocab size)에 독립적인 지표이므로 아키텍처가 크게 변경되어도 공정한 비교가 가능합니다. AI는 이 지표를 바탕으로 코드 변경 사항을 채택할지 결정합니다.
Auto Research 프로젝트의 주요 파일 구조
Auto Research 저장소는 관리의 효율성을 위해 의도적으로 매우 작게 유지되었으며, 핵심적인 파일은 단 세 개뿐입니다:
-
prepare.py(고정된 코드 - 수정 금지): 고정된 상수, 1회성 데이터 준비(학습 데이터 다운로드, BPE 토크나이저 훈련), 그리고 데이터 로더 및 평가(Evaluation)와 같은 런타임 유틸리티를 포함합니다. 에이전트나 인간이 수정하지 않는 고정된 파일입니다. -
train.py(AI 에이전트가 수정하는코드): 단일 GPU 기반의 'nanochat' 구현체로, 전체 GPT 모델 구조, 옵티마이저(Muon + AdamW), 그리고 훈련 루프가 포함된 단일 파일입니다. 모델의 아키텍처, 하이퍼파라미터, 배치 사이즈 등 모든 것이 에이전트의 실험 대상(Fair game)이 되며 에이전트가 지속적으로 반복 수정합니다. -
program.md(인간이 수정하는문서): AI 에이전트에게 부여되는 기본 지침서이자 컨텍스트 역할을 합니다. 이 레포지토리의 기본 파일은 매우 뼈대만 있는 베이스라인으로 제공되나, 사용자가 이 마크다운 파일을 고도화하여 "가장 빠른 연구 진척을 이루는 지침"을 찾거나 여러 에이전트를 투입하도록 지시를 내릴 수 있습니다.
Auto Research의 3가지 핵심 설계 철학 (Design Choices)
-
단일 파일 수정 (Single file to modify): 에이전트는 오직
train.py파일 하나만 수정하도록 제한됩니다. 이는 에이전트의 작업 범위를 관리 가능한 수준으로 유지하고, 인간이나 AI가 변경 사항(Diff)을 쉽게 리뷰할 수 있도록 돕습니다. -
고정된 시간 예산 (Fixed time budget): 어떤 컴퓨팅 환경이든 실험은 정확히 5분 동안만 실행됩니다. 이로 인해 시간당 약 12번, 하룻밤 수면 시간 동안 약 100번의 실험이 가능합니다. 이 설계의 장점은 모델 크기, 배치 사이즈 등 에이전트가 무엇을 바꾸든 실험 결과를 직접 비교할 수 있다는 점과, 제한된 시간 내에 해당 하드웨어 플랫폼에서 낼 수 있는 가장 최적의 모델을 찾아낸다는 점입니다. 단, 다른 컴퓨팅 환경을 쓰는 사람의 결과와는 직접 비교하기 어렵다는 단점이 있습니다.
-
독립성 및 단순성 (Self-contained): PyTorch와 몇 가지 작은 패키지를 제외하면 외부 의존성이 전혀 없습니다. 복잡한 설정 파일이나 분산 학습 아키텍처 없이, "하나의 GPU, 하나의 파일, 하나의 지표"라는 단순함을 추구합니다.
Auto Research 설치 및 빠른 시작 (Quick Start)
Auto Research는 기본적으로 단일 NVIDIA GPU (H100에서 테스트 완료), Python 3.10 이상, 그리고 빠르고 가벼운 파이썬 패키지 매니저인 uv를 요구합니다.
# 1. uv 프로젝트 매니저 설치 (설치되어 있지 않은 경우)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 의존성 패키지 설치
uv sync
# 3. 데이터 다운로드 및 토크나이저 학습 (최초 1회 실행, 약 2분 소요)
uv run prepare.py
# 4. 수동으로 단일 학습 실험 1회 실행해보기 (약 5분 소요)
uv run train.py
위 명령어가 모두 정상적으로 작동한다면 준비가 완료된 것입니다. 이후 Claude나 Codex 등 선호하는 AI 코딩 에이전트를 저장소에 연결하고(안전을 위해 파일 시스템 외부 접근 권한 등은 비활성화 권장) 다음과 같이 프롬프트를 주어 자율 연구를 시작할 수 있습니다.
"Hi, have a look at program.md and let's kick off a new experiment! let's do the setup first."
소규모 컴퓨팅 환경(Macbook, Windows RTX 등)을 위한 튜닝 팁
H100과 같은 대형 GPU가 없는 사용자를 위해 macOS 및 Windows 사용자를 위한 몇 가지 커뮤니티 포크(Fork) 프로젝트들이 활성화되어 있습니다:
- miolini/autoresearch-macos (MacOS)
- trevin-creator/autoresearch-mlx (MacOS)
- jsegov/autoresearch-win-rtx (Windows)
또한, 더 작은 모델과 환경에서 의미 있는 결과를 얻기 위해서는 코드의 기본값을 다음과 같이 조정하는 것이 권장됩니다.
-
데이터셋 변경: 엔트로피가 낮은 데이터셋(예: GPT-4가 생성한 짧은 이야기 모음인
TinyStories)을 사용하면 훨씬 작은 모델로도 합리적인 결과를 얻을 수 있습니다. -
어휘 사전 크기 축소:
vocab_size를 8192에서 4096, 2048, 1024, 혹은 256(UTF-8 바이트 수준 토크나이저)으로 줄이는 것을 실험해 볼 수 있습니다. -
시퀀스 및 배치 조정 (
prepare.py):MAX_SEQ_LEN을 디바이스에 맞게 256까지 과감하게 낮추고, 보상 차원에서DEVICE_BATCH_SIZE를 살짝 늘립니다. -
모델 복잡도 완화 (
train.py): 모델의 깊이를 결정하는DEPTH값(기본 8)을 4 등으로 낮춥니다. -
어텐션 패턴 변경: 번갈아가며 나타나는 밴드형 어텐션 패턴인 "SSSL" 대신 단순한 "L" 패턴을
WINDOW_PATTERN에 적용하여 연산 효율을 높입니다. -
배치 사이즈 최소화:
TOTAL_BATCH_SIZE를 2의 거듭제곱을 유지한 채 2**14 (약 16K) 수준으로 대폭 낮추어 OOM(Out of Memory)을 방지합니다.
라이선스
Auto Research 프로젝트는 MIT License로 공개 및 배포 되고 있습니다.
 autoresearch 프로젝트 GitHub 저장소
autoresearch 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()