cider 소개
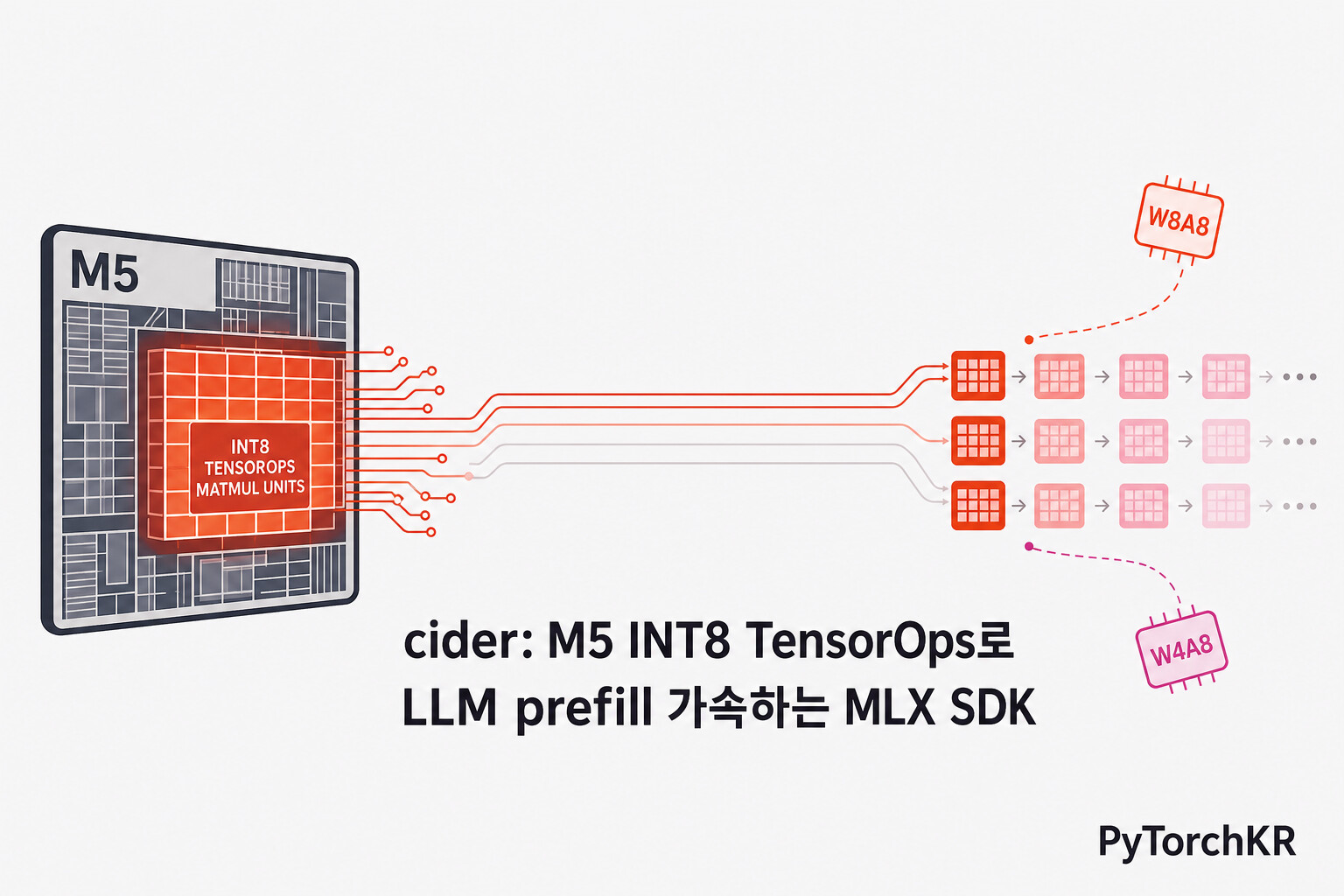
Apple Silicon M5는 INT8 TensorOps라는 전용 행렬 연산 유닛을 새로 도입하면서, 대규모 언어 모델(LLM) 추론에서 활용할 수 있는 저정밀 정수 연산 성능이 크게 향상되었습니다. 그러나 정작 macOS의 대표적인 머신러닝 프레임워크인 MLX에서는 양자화(Quantization) 경로가 가중치 전용(Weight-only) 방식으로 한정되어 있습니다. 즉, MLX의 QuantizedLinear는 INT8/INT4로 저장된 가중치를 다시 FP16으로 풀어 GEMM(General Matrix Multiplication)을 수행하기 때문에, INT8 TensorOps의 잠재력을 거의 활용하지 못합니다. 활성값(Activation)까지 INT8로 양자화해야 비로소 INT8 매트멀(MatMul) 자원을 끝까지 사용하는 W8A8(Weight 8bit, Activation 8bit) 경로가 열리는데, 표준 MLX 빌드는 이 경로를 제공하지 않습니다.
cider는 이 공백을 메우기 위해 등장한 MLX 확장 라이브러리입니다. Mininglamp AI Lab이 공개했으며, MLX 위에 온라인 활성값 양자화(Online Activation Quantization)와 자체 INT8 매트멀 커널을 추가하여 W8A8과 W4A8 추론 경로를 가능하게 합니다. 모든 커널은 MLX의 커스텀 프리미티브(Custom Primitives) 형태로 작성되어 MLX의 지연 평가(Lazy Evaluation)와 그래프 빌드 흐름에 자연스럽게 결합됩니다. 결과적으로 사용자는 MLX 코드를 거의 수정하지 않고도 양자화 경로를 끼워 넣을 수 있으며, 디코드(Decode) 시에는 토큰 단위로 작은 행렬-벡터 커널을, 프리필(Prefill) 시에는 큰 GEMM 커널을 자동으로 선택해 최대 처리량을 끌어내는 식으로 동작합니다.
또한 cider는 단순한 커널 라이브러리에 머무르지 않고, MLX 기반 비전-언어 모델 추론 스택인 mlx_vlm(검증 버전 0.4.3)에 대한 비파괴적 호환 패치도 포함하고 있습니다. Qwen3-VL 다중 이미지 추론 시 발생하던 RoPE 위치 처리 문제와 청크 프리필(Chunked Prefill) 관련 이슈를 수정하여, 비전 모델의 프리필 단계에서도 W8A8 경로의 성능 이득을 그대로 활용할 수 있습니다. 빌드 시스템은 조건부 컴파일을 채택하여 M5 이상 칩에서는 C++ 확장과 Metal 셰이더(Metal Shader)를 함께 컴파일하고, M4 이하 환경에서는 순수 파이썬 패키지로만 설치되어 호환성 문제 없이 함께 코드베이스를 공유할 수 있습니다.
cider의 양자화 모드와 적용 가능한 영역
cider는 MLX의 기존 양자화 모드를 보완하는 두 가지 모드를 새로 제공합니다.
| 모드 | 가중치(Weight) | 활성값(Activation) | 연산 경로 | 상태 |
|---|---|---|---|---|
| W8A8 | INT8 대칭 양자화(Symmetric) | INT8 토큰 단위(Per-token) | TensorOps matmul2d |
|
| W4A8 | INT4 패킹(uint8) | INT8 토큰 단위 | Unpack → TensorOps | |
| W4A16 | (MLX 내장) | (FP16) | MLX 기본 GEMM | 베이스라인 |
| W8A16 | (MLX 내장) | (FP16) | MLX 기본 GEMM | 베이스라인 |
W4A16과 W8A16은 MLX가 이미 네이티브로 지원하는 가중치 전용 모드이며, cider는 그 위에 활성값까지 INT8로 양자화하는 W8A8과 가중치를 INT4로 패킹한 채 활성값만 INT8로 다루는 W4A8을 채워 넣습니다. 후자는 메모리 사용량을 더 공격적으로 줄이면서도 INT8 TensorOps의 연산 자원을 그대로 사용하는 절충안입니다.
W8A8 모드는 다시 양자화 입자(Granularity)에 따라 세 가지 변형으로 나뉩니다.
Per-channel 양자화 : 출력 채널마다 하나의 스케일 값을 사용합니다. 가장 단순하고 가장 빠르며, prefill 속도가 약 1.8배까지 가속됩니다. 정밀도는 약간 손해를 볼 수 있어 모델 특성에 따라 정확도 검증이 필요합니다.
Per-group(gs=128) 양자화 : 128개 원소마다 스케일을 부여하여 정밀도와 속도의 균형을 맞춥니다. prefill은 약 1.5배 가속되며, 가중치 전용 양자화 대비 정확도 손실이 작습니다.
Per-group(gs=64) 양자화 : 64개 원소 단위로 스케일을 사용하여 정밀도를 가장 높게 유지합니다. prefill 가속은 약 1.3배 수준이지만, 양자화 민감도가 큰 모델에서 안정적입니다.
cider의 성능 측정 결과
저장소에는 Apple M5 Pro 환경에서 측정한 단일 연산자 지연 시간과 엔드투엔드 VLM 처리량 데이터가 함께 공개되어 있습니다. 큰 행렬 형상에서는 W8A8 per-channel(PC) 모드가 MLX의 w8a16 대비 1.5~1.9배 수준까지 빨라지는 것을 확인할 수 있습니다.
[N=10240, K=2560] 형상의 단일 행렬 곱 지연 시간(M은 시퀀스 길이, 단위는 ms):
| M | PC | PG | w8a16 | w4a16 | PC/w8a16 | PC/w4a16 |
|---|---|---|---|---|---|---|
| 1 | 0.27 | 0.26 | 0.26 | 0.18 | 0.96x | 0.67x |
| 128 | 0.34 | 0.39 | 0.49 | 0.44 | 1.43x | 1.28x |
| 1024 | 1.23 | 1.52 | 2.24 | 2.04 | 1.82x | 1.66x |
| 4096 | 4.41 | 5.65 | 8.12 | 7.72 | 1.84x | 1.75x |
| 8192 | 8.71 | 11.40 | 16.23 | 15.09 | 1.86x | 1.73x |
표에서 알 수 있듯, M=1(디코드 단계)에서는 W8A8가 큰 이점을 갖지 못하지만, 시퀀스가 길어질수록(prefill, batch inference) PC 모드의 가속 효과가 크게 부각됩니다. cider 내부의 CiderLinear는 이 특성을 자동으로 인지하여, seq_len > 1이면 W8A8 INT8 TensorOps 경로를, seq_len == 1이면 INT8 MV(Matrix-Vector) 커널을 선택합니다.
엔드투엔드 결과로는 Qwen3-VL-2B 기준으로 W8A8 per-channel 모드가 W8A16(가중치 전용 양자화) 대비 prefill 처리량을 약 50~60% 이상 향상시키며, 동시에 디코드 처리량은 W8A16과 유사한 수준을 유지합니다. 또한 Qwen3-8B와 Llama3-8B에 대한 정확도 검증(wikitext2 PPL)에서 W8A8 per-channel은 FP16 대비 0.05~0.13 perplexity 차이만 보이며, prefill 시간은 약 30% 단축되고 피크 메모리 사용량도 1.5GB 이상 줄어듭니다.
cider의 동작 방식과 자동 경로 선택
cider의 가장 큰 장점 중 하나는 사용자가 W8A8 경로의 복잡성을 거의 신경 쓰지 않아도 된다는 점입니다. 핵심 진입점인 convert_model은 모델의 선형 계층(Linear Layer)을 자동으로 CiderLinear로 교체합니다. 그리고 추론 시 CiderLinear는 시퀀스 길이를 보고 다음 두 경로 중 하나를 선택합니다.
seq_len > 1 (prefill) → W8A8 INT8 TensorOps GEMM 커널
seq_len == 1 (decode) → INT8 MV(Matrix-Vector) 커널
이러한 자동 경로 선택 덕분에, 동일한 모델 객체로 prefill 가속과 native에 가까운 decode 속도를 동시에 얻을 수 있습니다. 또한 VLM의 비전 트랜스포머(ViT) 부분은 양자화 시 정확도 저하가 큰 편이라, cider는 convert_model(model.language_model) 형태로 언어 모델만 선택적으로 양자화하는 권장 패턴을 안내합니다.
내부 구조도 깔끔하게 분리되어 있어, 직접 커널을 호출하거나 자체 양자화 도구를 결합하기 좋습니다.
cider/
├── cider/ # 파이썬 패키지
│ ├── ops.py # 프리미티브 래퍼와 양자화 헬퍼
│ ├── nn.py # CiderLinear, W4A8Linear (nn.Module)
│ ├── convert.py # convert_model() 고수준 API
│ └── kernels/ # 번들된 Metal 셰이더
│ ├── w8a8_matmul.metal # W8A8 GEMM (prefill, M>1)
│ ├── w8a8_int8_mv.metal # W8A8 per-channel MV (decode, M=1)
│ ├── w8a8_quantize.metal # 토큰 단위 활성값 양자화
│ ├── w4a8_matmul.metal # W4A8 GEMM (prefill)
│ ├── pergroup_int8_gemm.metal # Per-group GEMM (prefill)
│ └── pergroup_int8_mv.metal # Per-group MV (decode)
└── csrc/ # C++ MLX 프리미티브 (nanobind, M5+ 전용)
cider 설치와 사용법
cider는 Apple M5 이상에서 INT8 TensorOps C++ 확장을 빌드합니다. 그 외 환경에서는 순수 파이썬 패키지로만 설치되며, is_available()이 False를 반환하고 convert_model은 경고 로그를 출력하는 no-op로 동작합니다. 이 덕분에 동일한 코드베이스를 M4 이하 사용자와 공유해도 import 에러나 빌드 에러 없이 안전하게 동작합니다.
# Python 3.12+, MLX >= 0.31, nanobind >= 2.12, CMake >= 3.27 권장
pip install -e .
CI나 강제 빌드 옵션이 필요하면 환경 변수로 동작을 바꿀 수 있습니다.
CIDER_FORCE_BUILD=1 pip install -e . # 강제 빌드 (예: CI)
CIDER_FORCE_BUILD=0 pip install -e . # 강제 스킵
가장 간단한 사용 방식은 convert_model을 활용한 1줄 변환입니다.
from cider import convert_model, is_available
model, proc = load("path/to/model")
if is_available():
convert_model(model)
# CiderLinear 자동 경로 선택:
# seq_len > 1 → W8A8 INT8 TensorOps (prefill 가속)
# seq_len == 1 → INT8 MV 커널 (디코드는 native에 근접)
else:
pass # M4 이하에서는 표준 MLX 추론으로 동작
직접 계층 단위 API를 사용하면, 사전 양자화된 가중치를 받아 W8A8 또는 W4A8 선형 계층을 구성할 수 있습니다.
import numpy as np
import mlx.core as mx
from cider import W8A8Linear, W4A8Linear, is_available
from cider.ops import quantize_weight_int8
assert is_available(), "Apple M5+ 환경이 필요합니다"
# 가중치 준비
W = np.random.randn(4096, 4096).astype(np.float16)
# W8A8 선형 계층 (per-channel 스케일)
w_int8, scale = quantize_weight_int8(W)
layer = W8A8Linear(
w_int8=mx.array(w_int8), scale_w=mx.array(scale),
group_size=0, in_features=4096, out_features=4096,
)
x = mx.random.normal((32, 4096)).astype(mx.float16)
y = layer(x) # MLX 그래프만 빌드 (lazy)
mx.eval(y) # 실제 GPU 실행
# W4A8 선형 계층 (가중치 메모리 절반)
layer4 = W4A8Linear.from_weights(W)
y4 = layer4(x)
mx.eval(y4)
좀 더 저수준의 프리미티브 API도 노출되어 있어, 자체 트랜스포머 구현체에 cider를 직접 끼워 넣을 수 있습니다.
from cider import perchannel_linear, w4a8_linear, quantize_weight_int8, pack_weight_int4
# 오프라인 가중치 양자화
w_int8, scale = quantize_weight_int8(W_np)
packed_w4, scale4 = pack_weight_int4(W_np)
# 프리미티브 호출 (lazy mx.array 반환)
y = perchannel_linear(x, mx.array(w_int8), mx.array(scale))
y4 = w4a8_linear(x, mx.array(packed_w4), mx.array(scale4))
테스트는 Qwen3, Qwen3-VL, Llama3 계열 모델을 중심으로 검증되어 있고, 다른 아키텍처에서는 추가 적응이 필요할 수 있다고 안내하고 있습니다.
라이선스
cider는 MIT 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용·수정·배포할 수 있습니다. 동시에 MLX 자체와 Metal 셰이더 작성 가이드까지 포함하고 있어, 커스텀 INT8 GEMM을 직접 작성하려는 연구자에게도 좋은 학습 자료가 됩니다.
 cider GitHub 저장소
cider GitHub 저장소
 cider M5용 INT GEMM 작성 튜토리얼
cider M5용 INT GEMM 작성 튜토리얼
더 읽어보기
-
mlx-vlm: M5와 같은 Apple Silicon에 최적화된 MLX 기반 시각-언어 모델(VLM) 추론 및 파인튜닝 도구
-
turboquant-pytorch: Google의 TurboQuant를 PyTorch로 처음부터 직접 구현한 LLM KV 캐시 양자화 라이브러리
-
FastVLM: 고해상도에서도 빠르고 정확하게 동작하는 시각-언어 모델(VLM) 구현에 대한 연구 (feat. Apple)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()