
FastVLM 연구 소개
시각‑언어 모델(VLM)은 이미지와 텍스트를 동시에 이해하면서 질의응답, 이미지 캡션 생성, UI 내비게이션 보조 등 다양한 멀티모달 AI 응용에서 중심 기술로 부상했습니다. 특히 문서 이미지, 차트, 손글씨처럼 텍스트 정보가 풍부한 이미지를 처리할 때 높은 해상도의 입력은 정확도 향상에 필수적입니다. 그러나 ViT 계열 인코더는 고해상도 이미지 입력 시 시각 토큰 수가 폭발적으로 증가하고, 셀프-어텐션(self-attention) 계층을 통과하는 시간이 길어지면서 인코딩 지연과 LLM 프리필링(prefilling) 시간이 크게 늘어납니다. 이는 결과적으로 VLM의 응답 속도(Time‑to‑First‑Token, TTFT)에 영향을 미쳐 높은 정확도와 빠른 응답을 동시에 필요로 하는 온-디바이스(On-Device) 환경에서 본질적인 제약이 됩니다 .
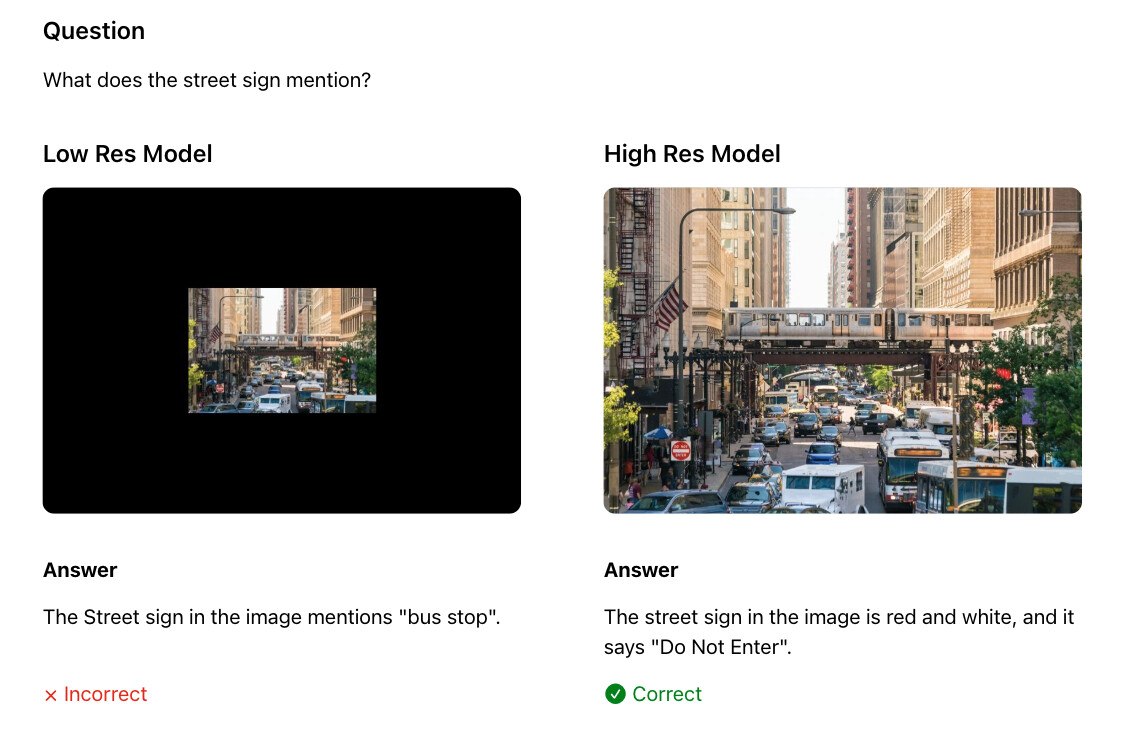
Apple은 이러한 문제에 대응하기 위해 FastVLM이라는 새로운 모델을 제안했습니다. FastVLM의 핵심 기술은 FastViTHD라는 하이브리드 비전 인코더(Hybrid Vision Encoder)로, 고해상도 이미지를 효율적으로 인코딩하면서도 적은 수의 고품질 시각 토큰을 생성하여 LLM에 전달합니다. 기존 방식처럼 복잡한 토큰 머징(Token Merging)이나 프루닝(Pruning) 없이도 간단한 구조만으로 높은 정확도와 빠른 처리 속도를 달성하는 것이 특징입니다. 이 모델은 Apple의 오픈소스 프레임워크인 MLX 기반으로 구현되어 있으며, iOS/macOS 환경에서 직접 실행 가능한 데모도 GitHub 저장소에서 제공됩니다.
기존 VLM 구조에서의 한계점
기존의 VLM은 크게 (1) CLIP 기반의 비전 백본(Vision Backbone), (2) 연결(Projection) 모듈, (3) 사전 학습된 LLM 디코더로 구성됩니다. CLIP 기반의 비전 인코더는 이미지를 시각 토큰(Visual Token)으로 변환한 뒤, 연결 모듈(Projection Module)이 LLM 임베딩 공간으로 정렬하여 언어 모델에 제공하여 시각 정보를 활용하도록 합니다. 이 때, 문맥 상 인식 성능(정확도)과 인코딩 속도는 입력 해상도, 백본 아키텍처, LLM 크기 등 요소들의 상호 영향에 결정됩니다 .
이전 하이브리드 구조인 FastViT과 MobileCLIP은 Full ViT보다 적은 파라미터와 빠른 응답 시간을 구현하면서도 충분한 정확도를 달성했습니다. 예를 들어, FastViT는 합성곱(Convolution)과 Transformer 블록을 결합한 하이브리드 구조로, ViT‑L/14 대비 시각 토큰 수를 4배 이상 줄이고, 응답 속도는 ViT 대비 4 ~ 5배 빠르면서도 정확도는 비슷하거나 더 높은 성능을 보여왔습니다. 그러나 고해상도 입력에서는 토큰 수 증가와 응답 속도(latency) 증가로 인해 효율성이 급격히 떨어져 최적의 선택이 아니었습니다.
이미지 해상도와 정확도-지연 시간 트레이드오프
특히, 입력 이미지 해상도가 높아질수록 세밀한 정보(예: 텍스트, 차트, UI 요소 등)를 정확히 인식할 수 있어 성능이 향상됩니다. 특히 문서 이미지나 차트, 손글씨처럼 텍스트가 풍부한 이미지를 처리할 때는 고해상도 입력이 필수입니다. 하지만 기존의 ViT 기반 인코더들은 입력 해상도가 높아질수록 다음과 같은 문제가 발생합니다:
-
인코딩 지연 증가: 고해상도 이미지일수록 처리할 토큰의 수가 증가하여, 입력 이미지를 인코딩하는 비전 인코더(Vision Encoder)의 처리 시간이 늘어납니다.
-
LLM 프리필링 시간 증가: 또한, 더 많은 시각 토큰이 생성되면서 LLM 입력 시간이 늘어납니다. 이는 전체적인 연산량을 증가시켜 전체 반응 시간이 크게 느려지게 됩니다.
이러한 두 요소들은 모델의 응답 속도(TTFT, Time-to-First-Token)에 영향을 미치며, FastVLM은 이러한 응답 속도를 기존 ViT 기반 모델 대비 최대 85배까지 단축할 수 있습니다. Apple은 이를 위해 인코더 구조 최적화에 집중하여 이를 보완한 FastViTHD 구조를 도입하였으며, 결과적으로 이미지 해상도와 LLM 규모 간의 Pareto-optimal curve를 통해 실질적인 최적 조합을 도출하였습니다.
FastVLM 모델의 구조
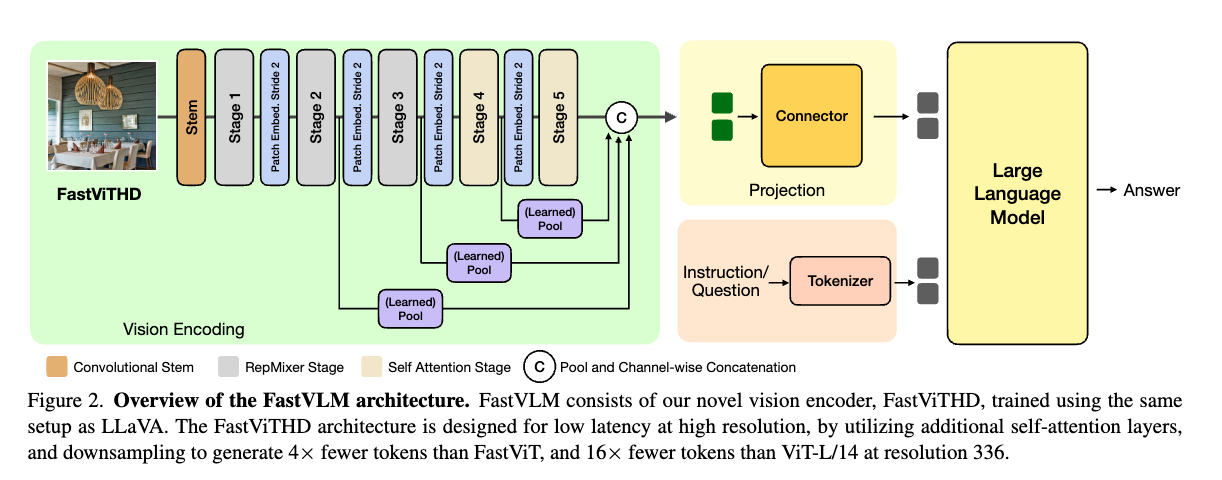
FastVLM 아키텍처는 다음 세가지의 주요 모듈로 구성됩니다:
- Vision Encoder (FastViTHD) : 고해상도 이미지를 효율적으로 인코딩
- Projection Layer (MLP Connector) : 시각 토큰을 LLM 임베딩 공간에 맞게 선형 변환
- LLM Decoder (예: Qwen2‑0.5B/1.5B/7B 또는 Vicuna‑7B) : 텍스트 출력을 생성
이미지가 FastViTHD를 통과하면 요약된 비주얼 토큰을 연결 모듈(Projection Module)을 통해 LLM 임베딩 공간으로 매핑한 뒤, LLM이 이 정보를 기반으로 텍스트 출력(예: 질문-답변)을 생성합니다. 각 세가지 모듈에 대해서 더 상세하게 살펴보면 다음과 같습니다:
Vision Encoder: FastViTHD
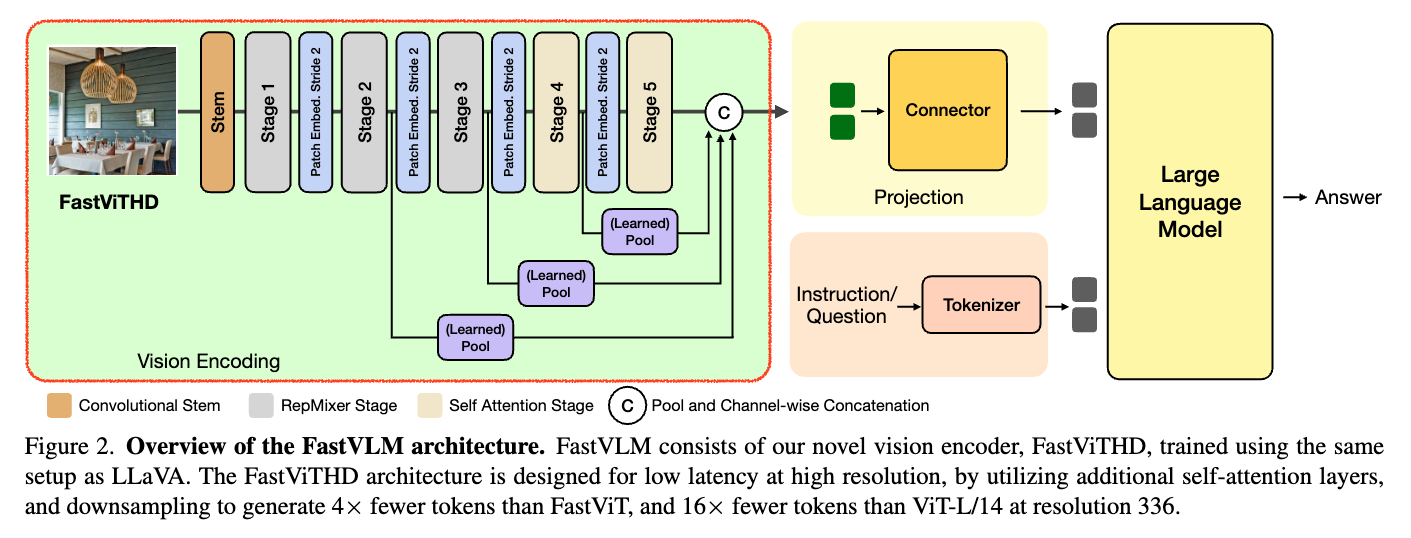
FastViTHD는 Apple이 제안한 FastVLM 시스템에서 가장 핵심적인 컴포넌트로, 고해상도 이미지 처리에서의 성능과 효율 사이의 균형을 혁신적으로 개선하기 위해 개발된 하이브리드 비전 인코더입니다. 기존 FastViT 구조의 장점을 계승하면서도, 고해상도 입력 이미지에서 발생하는 토큰 수 폭증 문제를 구조적으로 해결하는 데 초점을 맞추고 있습니다. 먼저 기존 ViT 및 FastViT 구조에 대해서 간략히 살펴본 뒤, FastViTHD에 대해서 살펴보겠습니다.
참고: ViT(Vision Transformer) 개요
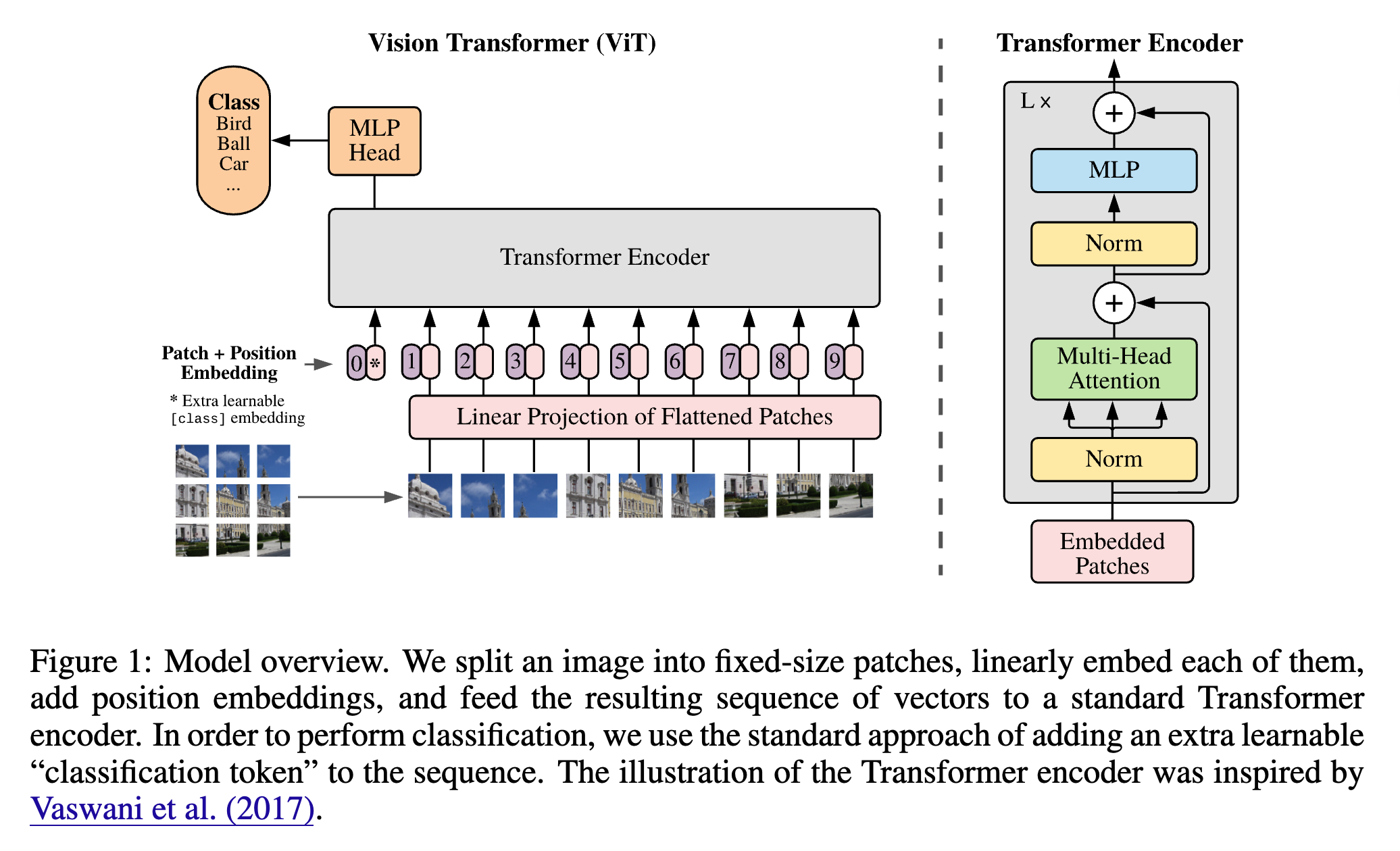
ViT(Vision Transformer)는 자연어 처리에서 혁신을 일으킨 Transformer를 컴퓨터 비전 분야에 적용한 모델입니다. ViT는 이미지를 작은 패치(patch) 단위로 나누고, 각 패치를 벡터로 변환한 뒤 순차적 토큰 시퀀스(sequence token)로 처리합니다. 이 패치는 일반적으로 16×16 픽셀 블록이며, 선형 임베딩과 위치 인코딩을 더해 Transformer의 입력으로 사용됩니다. 이후 여러 Transformer encoder layer(자가-어텐션 + FFN)가 반복 적용되어 패치 간의 전역 관계를 학습하며 이미지 전체의 의미를 캡처합니다.
ViT의 장점 중 하나는 이미지의 전역적 패턴이나 장기적 종속성을 효율적으로 인식할 수 있다는 점입니다. CNN처럼 국소적인 자원을 공유하는 대신 각 패치 간 모든 상호작용을 학습할 수 있어, 복잡한 시각적 맥락을 잘 이해합니다. 다만, 입력 패치 수가 많아질수록 self‑attention의 연산 비용이 O(n^2) 로 증가하므로, 고해상도 입력에서는 매우 비효율적입니다. 또한 대용량 데이터와 학습 리소스가 필요하며 학습 안정성 측면에서도 CNN보다 예민한 특성을 보입니다.
결국 ViT는 정확도 측면에서는 강점이 크지만, 실시간 시스템이나 모바일 환경에서 사용하기에는 연산량과 지연 시간(latency)이 문제됩니다. 고해상도 이미지를 처리할 경우, 패치 수 증가로 인해 메모리와 처리 시간 모두 비약적으로 증가하기 때문에 실용적 사용에 한계가 있습니다. (더 상세한 ViT 구조 및 동작 방식에 대해서는 Vision Transfromer 논문 및 Vision Transformer에 대한 시각적 설명 (A Visual Guide to Vision Transformers) 글을 참고해주세요.)
참고: FastViT 개요: ViT를 개선한 하이브리드 설계
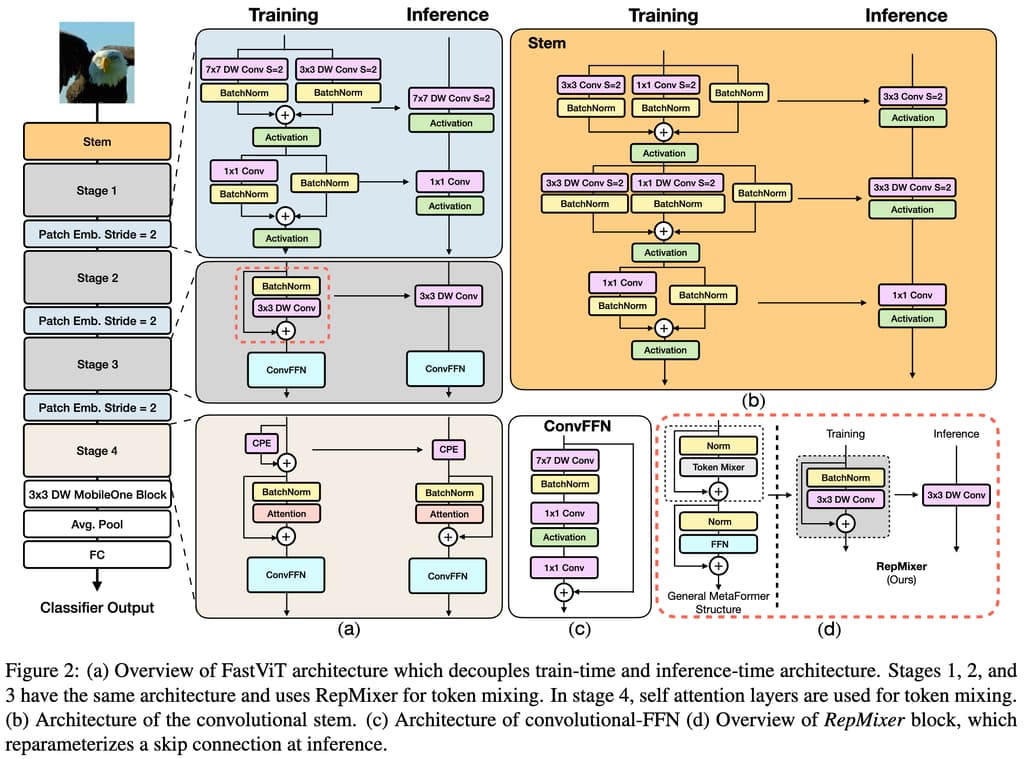
FastViT는 이번 FastVLM 연구를 주도한 Pavan Kumar Anasosalu Vasu가 제안(ICCV 2023, arXiv: 2303.14189)한 구조로, ViT의 전역 인식 능력을 유지하면서도 연산 효율성을 크게 향상시키기 위한 하이브리드 구조입니다. FastViT는 PoolFormer 구조를 기반으로 하되, 합성곱 기반 구조와 Transformer 블록을 결합해 속도와 정확도의 균형을 추구합니다 .
FastViT 모델의 핵심은 토큰 믹싱 연산자(token mixing operator)인 RepMixer입니다. RepMixer는 스킵 연결(skip connection)을 구조적으로 제거하고 깊이 분리 합성곱(depthwise convolution)을 사용하여, 추론(inference) 시 단일 합성곱 레이어로 변환 가능한 구조를 가집니다. 즉, 학습 시에는 복잡한 구조였지만, 추론 단계에서는 매우 간결한 합성곱으로 바뀌어 메모리 접근 비용을 줄이고 지연을 최소화합니다 .
또한, FastViT는 초기 단계(convolution stem 및 patch embedding)에서 사용하던 조밀한 k × k 합성곱(dense convolution)을 열 분해(factorized) 방식으로 바꾸고, 학습 시에만 유효한 학습-시점 과잉-파라미터화(train-time overparameterization) 기법을 활용해 정확도를 향상시키면서도 추론 시에는 이를 제거해 속도에 영향을 주지 않게 설계되었습니다.
이러한 구조적 선택 덕분에 FastViT는 모바일 환경 기준으로 PoolFormer 대비 3.5배, EfficientNet 대비 4.9배, ConvNeXt 대비 약 1.9배 빠른 속도를 구현하면서도 ImageNet Top‑1 정확도는 MobileOne 대비 약 4.2% 높다는 실험 결과를 냈습니다. 그러나 고해상도 입력에서는 여전히 프레임워크 상 패치 수 증가에 따른 효율 저하가 남아 있어, FastViTHD로 이어지는 개념적 토대가 되었습니다.
FastViTHD의 구조적 변화와 개선점
FastViTHD는 FastViT의 효율성과 구조적 직관성을 유지하면서도, 특히 고해상도 입력 이미지를 처리하기 위해 기존 구조가 갖는 효율성 저하를 근본적으로 해결하기 위해 하이브리드 인코더입니다. 주요 개선점은 다음과 같습니다:
가장 큰 차이는 토큰 수를 근본적으로 줄이기 위한 계층적 다운샘플링(hierarchical downsampling) 전략을 구조에 통합했다는 점입니다. FastViTHD는 총 5개의 계층으로 구성되며, 각 단계에서 해상도를 절반씩 줄이면서 이미지 정보를 요약합니다. 이로 인해 최종적으로 출력되는 시각 토큰의 수는 ViT-L/14 대비 최대 16배 적어지며, 고해상도 입력에서도 토큰 수가 폭발하지 않아 LLM의 프리필링 시간도 크게 줄어듭니다
다음으로는 FastViTHD는 마지막 두 단계만 Transformer 기반의 셀프-어텐션 메커니즘을 사용하고, 초기 단계에서는 합성곱 블록(convolution block)만을 사용해 연산량을 제한합니다. 이를 통해 적은 토큰 수로도 전역적, 지역적 정보(Global & Local Information)를 모두 효과적으로 포착할 수 있습니다.
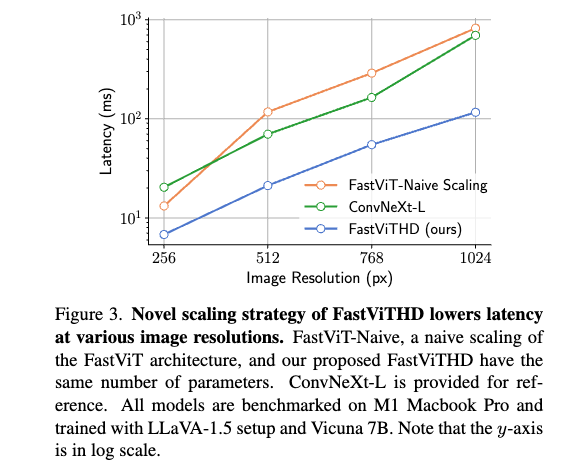
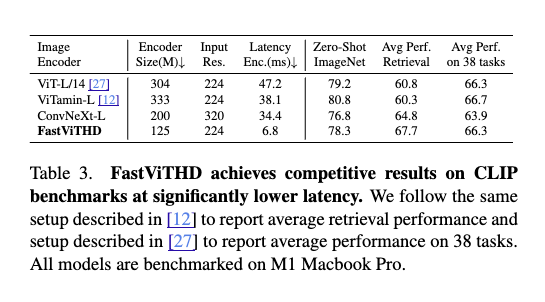
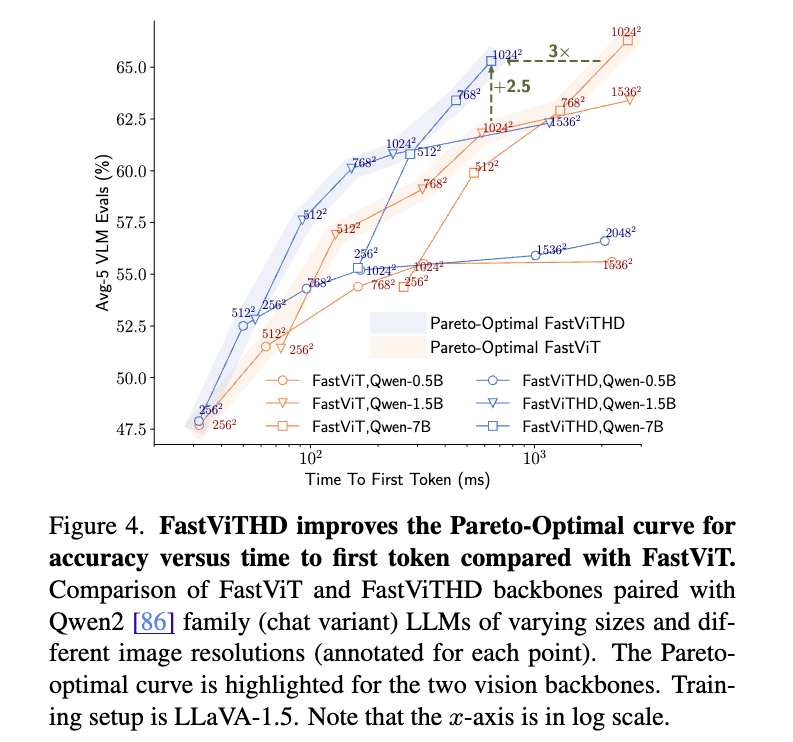
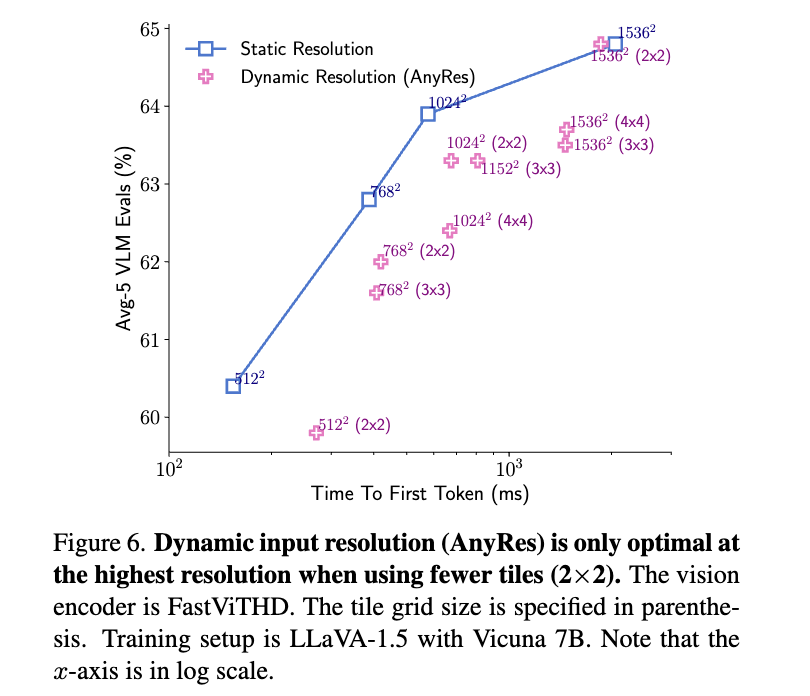
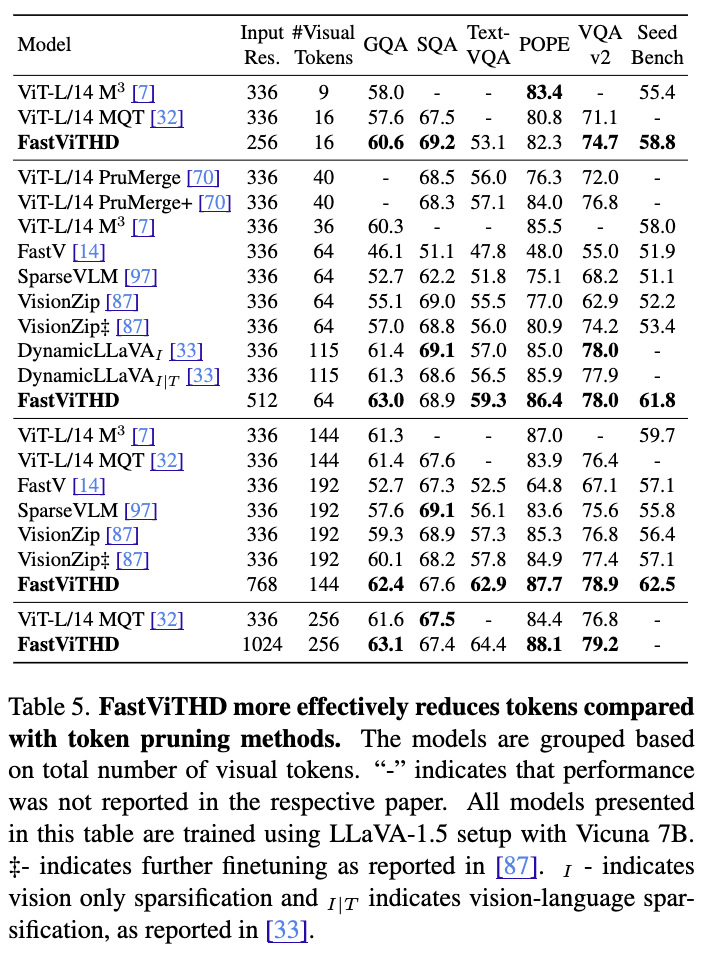
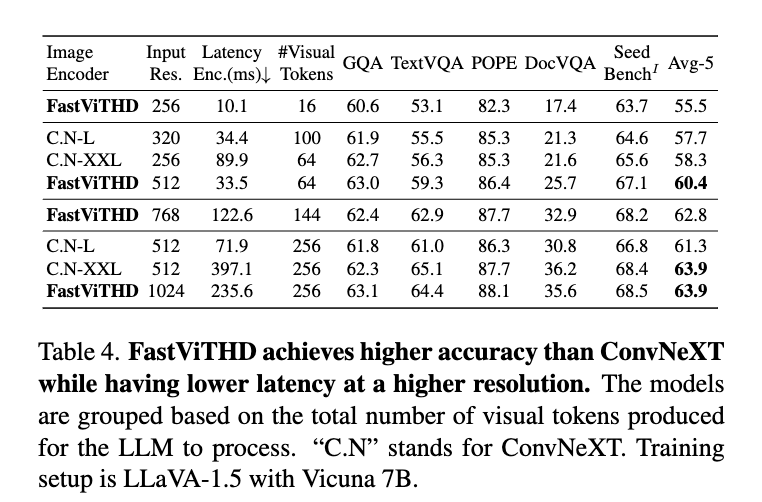
그 결과, 실험적으로 FastViTHD는 FastViT 대비 평균 2.3배 더 빠른 추론 속도를 나타냈으며, TextVQA, DocVQA, GQA 등 다양한 고해상도 멀티모달 벤치마크에서 높은 정확도를 유지했습니다. 이는 정확도-지연(Accuracy-Latency)의 Pareto-optimal trade-off 상에서 일관되게 우위에 있다는 의미입니다. 특히, FastViTHD는 토큰 프루닝(token pruning), 동적 타일링(dynamic tiling) 같은 후처리 기법(obsolete post‑processing)이 없이도 처음부터 적은 토큰 수로 고성능을 유지할 수 있도록 설계되었기에, 구현 복잡성도 낮고 유지보수도 효율적입니다.
Projection Layer (Connector)
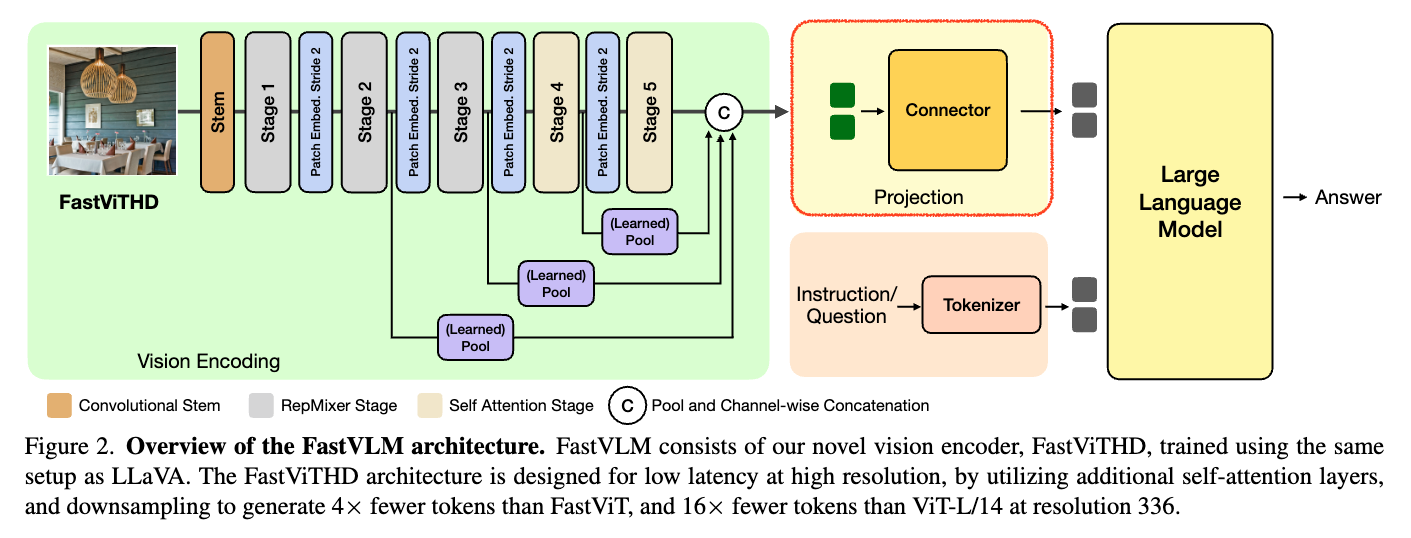
FastViTHD가 추출한 시각 정보는 그대로는 LLM이 이해할 수 없기 때문에, 이를 연결해주는 변환 모듈이 필요합니다. 이를 위해 FastVLM은 Projection Layer 또는 Connector라 불리는 MLP 기반의 간단한 네트워크를 사용합니다. 이 모듈은 Vision Encoder의 출력(시각 토큰)을 LLM이 사용하는 임베딩 공간에 맞게 선형적으로 투영(Projection)하는 역할을 수행합니다. 구조적으로는 매우 단순한 Multi-Layer Perceptron(MLP) 하나 또는 두 개의 층으로 이루어져 있으며, 복잡한 파라미터 없이도 효과적으로 정보를 변환할 수 있도록 설계되어 있습니다. 덕분에 이 Connector는 학습 속도도 빠르고, 계산량도 많지 않아 전체 시스템의 경량화에 기여합니다.
이 모듈은 FastVLM의 학습 절차에서도 중요한 역할을 담당합니다. 초기 단계에서 비전 인코더와 LLM을 고정시킨 채 이 Projection Layer만 학습하는데, 이는 서로 다른 두 모듈 간의 인터페이스를 조율하는 과정이라 볼 수 있습니다. 실제로 이 과정은 시스템 전체를 학습하는 것보다 훨씬 빠르고 안정적으로 수렴되며, 초기 실험에서도 성능 향상에 중요한 기여를 했습니다. 특히 다양한 LLM(예: Qwen2, Vicuna)과 조합하여도 연결성을 유지하는 범용성이 높아, FastVLM을 다양한 시나리오에 쉽게 확장할 수 있도록 돕는 중간 다리 역할을 수행합니다.
LLM Decoder
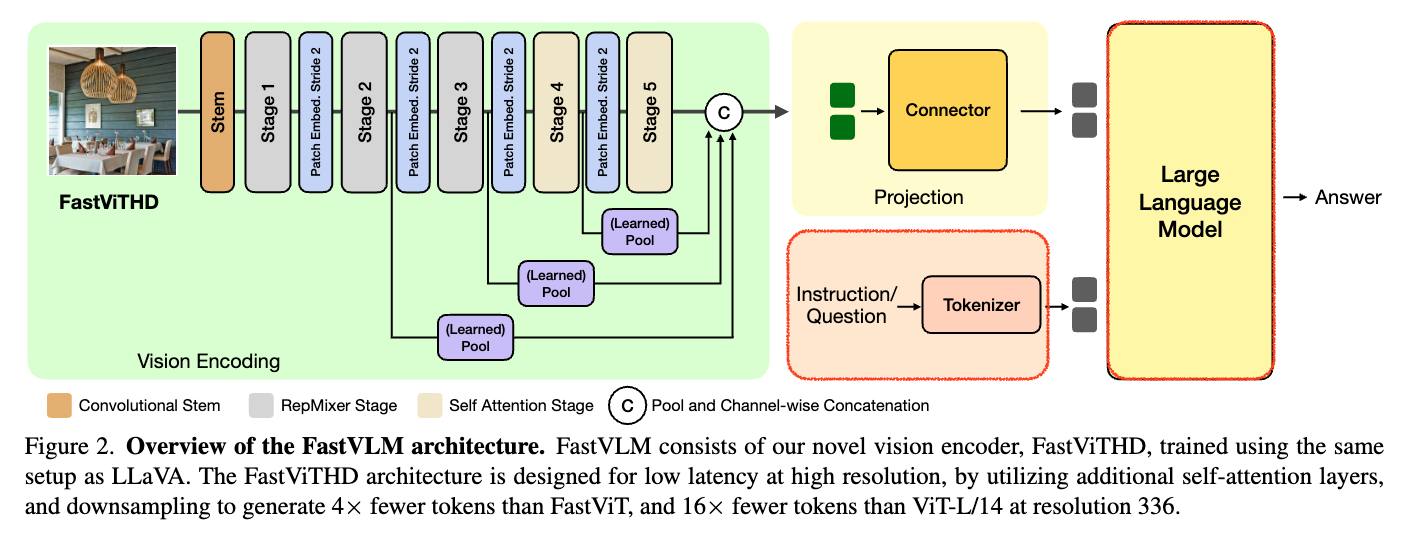
FastVLM의 마지막 단계는 텍스트 출력을 담당하는 언어 모델입니다. 여기서는 LLM(Large Language Model), 즉 거대한 사전 학습 언어 모델이 사용되며, FastViTHD와 Projection Layer를 통해 입력된 시각 정보를 기반으로 문장을 생성하거나 질문에 답합니다. FastVLM에서는 Qwen2, Vicuna 등 다양한 LLM이 사용되며, 이는 사용자의 요구나 성능 제약에 따라 유연하게 교체가 가능합니다. LLM은 이미 대규모 텍스트 데이터로 사전 학습된 상태에서 사용되기 때문에, 별도의 텍스트 생성 능력 자체를 학습할 필요는 없습니다. 대신, 시각 정보를 얼마나 정확히 이해하고 이를 맥락화하여 표현하느냐가 FastVLM 성능의 관건입니다.
LLM은 입력으로 주어진 시각 토큰들을 문맥 속에 배치한 후, 이를 기반으로 텍스트를 단계적으로 생성합니다. 예를 들어 사용자 질문이 “이 이미지에 무엇이 보이나요?“라면, LLM은 그 앞에 연결된 시각 토큰을 참조하여, “이 이미지는 노트북 화면과 키보드가 포함되어 있습니다” 같은 응답을 만들어냅니다. 이처럼 LLM은 FastViTHD의 요약 결과를 바탕으로 문장을 만들어내는 핵심 역할을 하며, 전체 아키텍처의 정보 흐름을 완결짓는 구성 요소입니다. FastVLM의 성능은 이 LLM의 능력에 크게 의존하며, 따라서 어떤 LLM을 선택하느냐에 따라 응답의 수준도 달라질 수 있습니다.
FastVLM의 학습 절차
FastVLM은 LLaVA‑1.5의 학습 단계를 따라 2단계(1단계: 프로젝터 학습 - 2단계: 전체 튜닝) 또는 3단계(해상도 스케일 조정 포함)의 학습 전략을 사용합니다. 또한, 1단계와 2단계 사이의 1.5단계에서는 해상도 적응을 위한 별도 사전학습을 통해 고해상도 이미지에 대한 적응성을 확보합니다. 이후, 3단계 학습에서는 CoT(Chain-of-Thought) 데이터 가반의 파인튜닝을 통해 복잡한 추론 과제를 더욱 잘 수행할 수 있도록 논리적 추론 성능을 향상시킵니다.
아래 학습 단계들은 각각 명확한 목적과 데이터 설정을 가지고 있으며, 전체 모델이 점진적으로 최적화되도록 설계되어 있습니다.
1단계: 연결 계층 사전 학습 (Connector Pretraining)
FastVLM의 학습은 전체 모델을 한꺼번에 학습하지 않고, 먼저 연결 계층(Projection Layer)만을 학습시키는 방식으로 시작됩니다. 이 단계에서는 Vision Encoder(FastViTHD)와 LLM은 모두 고정(frozen)된 상태로 유지되며, 중간에 위치한 Projection Layer만 학습 대상이 됩니다. 이렇게 하는 이유는 서로 독립적으로 사전 학습된 모듈(FastViTHD와 LLM)이 처음 만났을 때, 정보 표현 방식의 차이로 인해 발생할 수 있는 불일치를 조정하기 위함입니다. Projection Layer는 이런 차이를 중재하는 역할을 수행하기 때문에, 초기에는 이 부분만 따로 학습하는 것이 더 효과적입니다.
이 단계의 학습은 상대적으로 빠르고 효율적으로 진행되며, 전체 모델 학습에 비해 연산량도 적습니다. 학습 데이터셋으로는 LLaVA-558K Alignment Dataset을 사용하여 학습합니다. 이 데이터셋은 주로 텍스트가 풍부한 이미지 기반의 멀티모달 QA 데이터로, 텍스트와 이미지 쌍으로 구성된 질문-응답 형식으로 연결 모듈(Projection Modul)이 잘 동작하도록 합니다. 이 데이터는 CLIP 해상도 기반 이미지(예: 256×256)로 구성되어 있어 초기 연결 안정성을 확보하는 데 유용합니다.
이 과정을 통해 Projection Layer는 FastViTHD의 출력 구조와 LLM의 임베딩 구조 사이를 자연스럽게 연결할 수 있는 능력을 갖추게 됩니다. 일반적으로 이 초기 연결 학습만으로도 기본적인 문답 기능은 작동하기 시작하며, 이후 전체 모델 학습의 기반을 다지는 역할을 합니다.
1.5단계: 해상도 적응 사전 학습 (Resolution Alignment Pretraining)
1단계에 이어 선택적으로 진행되는 1.5단계는, 높은 해상도의 이미지를 모델이 보다 잘 처리할 수 있도록 도와주는 전처리 단계입니다. 많은 경우 FastViTHD는 사전 학습 당시 상대적으로 낮은 해상도의 이미지를 사용했기 때문에, 고해상도 이미지를 사용할 경우 적응력이 떨어질 수 있습니다. 이 단계에서는 비전 인코더만 미세 조정(Fine-tuning)하거나, Projection Layer와 함께 학습함으로써 고해상도 이미지에 대한 표현력과 일관성을 확보합니다.
학습 데이터셋으로는 총 15M 샘플의 시각 지시 데이터(Visual Instruction Data)가 사용됩니다. 이 데이터는 DataComp DR-1B에서 선별되었으며, OCR/문서/차트 이미지 및 UI 이미지 등을 포함한 텍스트가 풍부한 이미지 위주로 구성되어 있습니다. 이를 통해 모델은 고해상도에서도 일관된 표현력을 가질 수 있게 됩니다.
이 과정은 특히 문서 기반 이미지, OCR 벤치마크, UI 이미지 등 세부 요소가 많은 이미지에서 성능을 높이는 데 효과적입니다. 고해상도에 대한 적응 없이 바로 전체 튜닝을 진행할 경우, 오히려 성능이 저하되거나 학습이 불안정해질 수 있기 때문에, 이 중간 단계는 실용적인 안정성 확보에 기여합니다. 물론 이 단계는 필수가 아니라 선택적이며, 사용자의 목적에 따라 생략될 수도 있지만, 고성능을 목표로 할 경우 매우 유용한 전처리 단계입니다.
2단계: 전체 모델 미세 조정 (Full Fine-Tuning)
모든 준비가 끝나면 이 단계부터는 FastVLM 전체 모델을 전체적으로 학습합니다. 이때는 FastViTHD, Projection Layer, LLM 모두 학습이 가능한 상태로 설정되며, 다양한 멀티모달 데이터셋을 통해 모델이 실질적인 질의응답 능력, 추론 능력, 문맥 해석 능력을 갖추도록 합니다. 특히 CoT(Chain-of-Thought) 형태의 데이터, 즉 단순한 질문-답변이 아닌 중간 추론 단계를 포함한 복잡한 예제를 활용하여, 모델의 사고력 또는 연쇄 추론 능력도 향상시킵니다.
학습 데이터셋으로는 LLaVA-665K SFT(Supervised Fine-Tuning) 데이터셋을 활용합니다. 이 데이터셋은 해상도 1024×1024 수준의 이미지와 긴 텍스트 응답을 포함한 복잡한 질의응답 시나리오를 포함하며, 모델이 다양한 응용 환경에 적응할 수 있도록 학습됩니다.
이 전체 튜닝 단계는 많은 연산 자원을 필요로 하며, 학습 시간도 상대적으로 길지만, FastVLM의 최종 성능을 결정짓는 핵심적인 과정입니다. 다양한 해상도의 이미지, 다양한 길이의 텍스트, 다양한 질문 유형 등을 포괄적으로 학습하면서, FastVLM은 실제 서비스 또는 연구 환경에서 요구하는 수준의 멀티모달 처리 능력을 갖추게 됩니다. 최종 결과물은 일반적인 VLM 응용뿐만 아니라, 고해상도 문서 인식, 차트 분석, UI 이해 등 고정밀 응답이 요구되는 환경에서도 뛰어난 성능을 보이게 됩니다.
3단계: CoT 기반 추론 특화 학습 (Instruction Tuning with CoT Data)
마지막 단계에서는 보다 정교한 추론 과제에 특화된 학습이 이루어집니다. 여기서는 CoT가 포함된 고난도의 지침(instruction-following) 데이터셋이 활용되며, 모델이 단계적인 추론 능력과 세밀한 언어 응답을 학습하도록 구성됩니다. 이를 위해 총 6.5M에서 최대 12.5M 샘플의 CoT 데이터를 활용하여 논리적 추론 및 설명 가능한 응답 능력을 강화합니다. 이 데이터셋은 수학, 과학, 도표 해석 등 고난도의 멀티스텝 문제 해결을 위한 구조화된 질문 응답이 포함되며, 모델의 추론(reasoning) 능력을 실질적으로 향상시킵니다.
이 단계는 FastVLM이 단순 응답을 넘어, 설명 가능한 추론(explainable reasoning)을 수행할 수 있도록 하는 데 초점을 맞춥니다. 특히 수학 문제 풀이, 긴 맥락 내 문서 질의응답 등에서 뛰어난 성능 향상을 유도하며, 실제 응용 환경에서의 실용성을 높이는 데 기여합니다.
모델 성능 평가 및 비교 분석
저자들은 다양한 해상도, 비전 백본, LLM 크기 조합 하에서 FastVLM의 벤치마크 성능을 종합적으로 평가했습니다. 모든 실험은 MacBook Pro(M1 Max)에서 직접 수행되었으며, 모든 모델은 동일한 LLaVA-1.5 프레임워크 기반으로 학습되어 비교의 공정성을 유지했습니다.
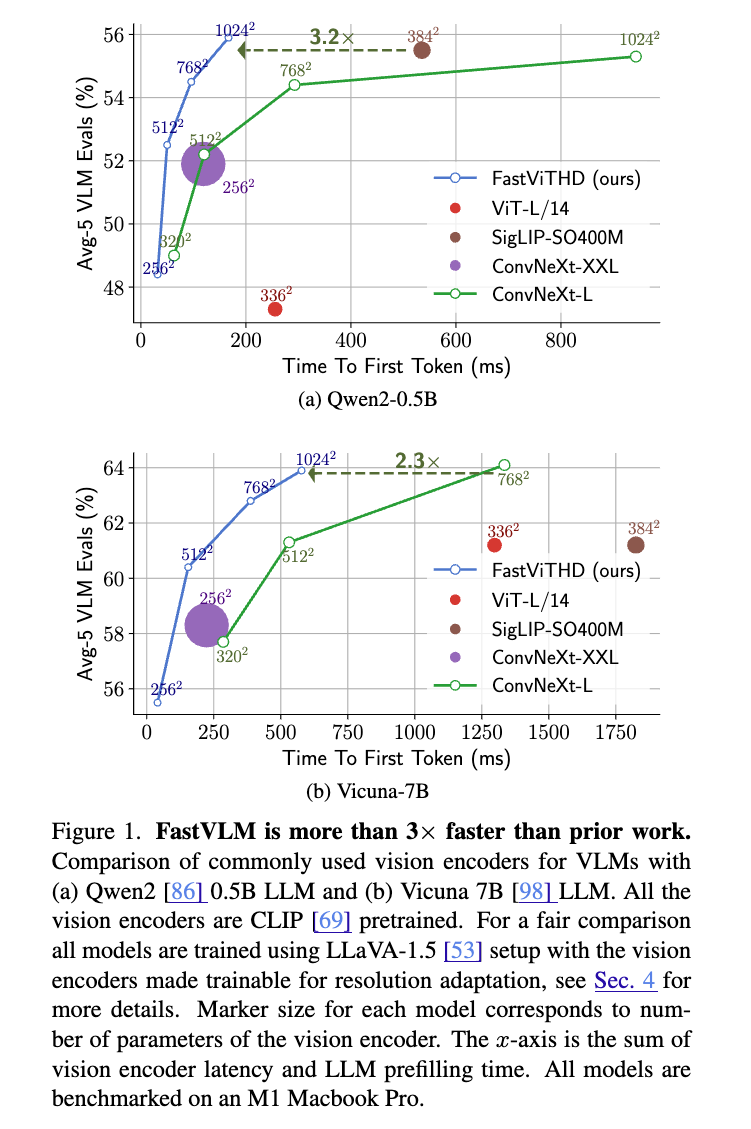
응답 속도와 정확도의 Pareto-Optimal 트레이드-오프(Trade-off): FastViTHD는 다양한 해상도에서 뛰어난 효율성과 정확도 균형을 보여주며, 기존 FastViT 및 ViT-L/14 대비 일관된 우위를 확보했습니다. 특히 1024×1024 해상도 입력 기준으로, FastVLM은 LLaVA-OneVision보다 85배 빠른 TTFT(Time to First Token)를 기록하면서도 동일한 Qwen2-0.5B LLM으로 더 높은 TextVQA 및 DocVQA 점수를 달성했습니다. 이는 고해상도 입력에서 Vision Encoder의 성능이 모델 전체 성능에 미치는 영향을 실증한 결과입니다.
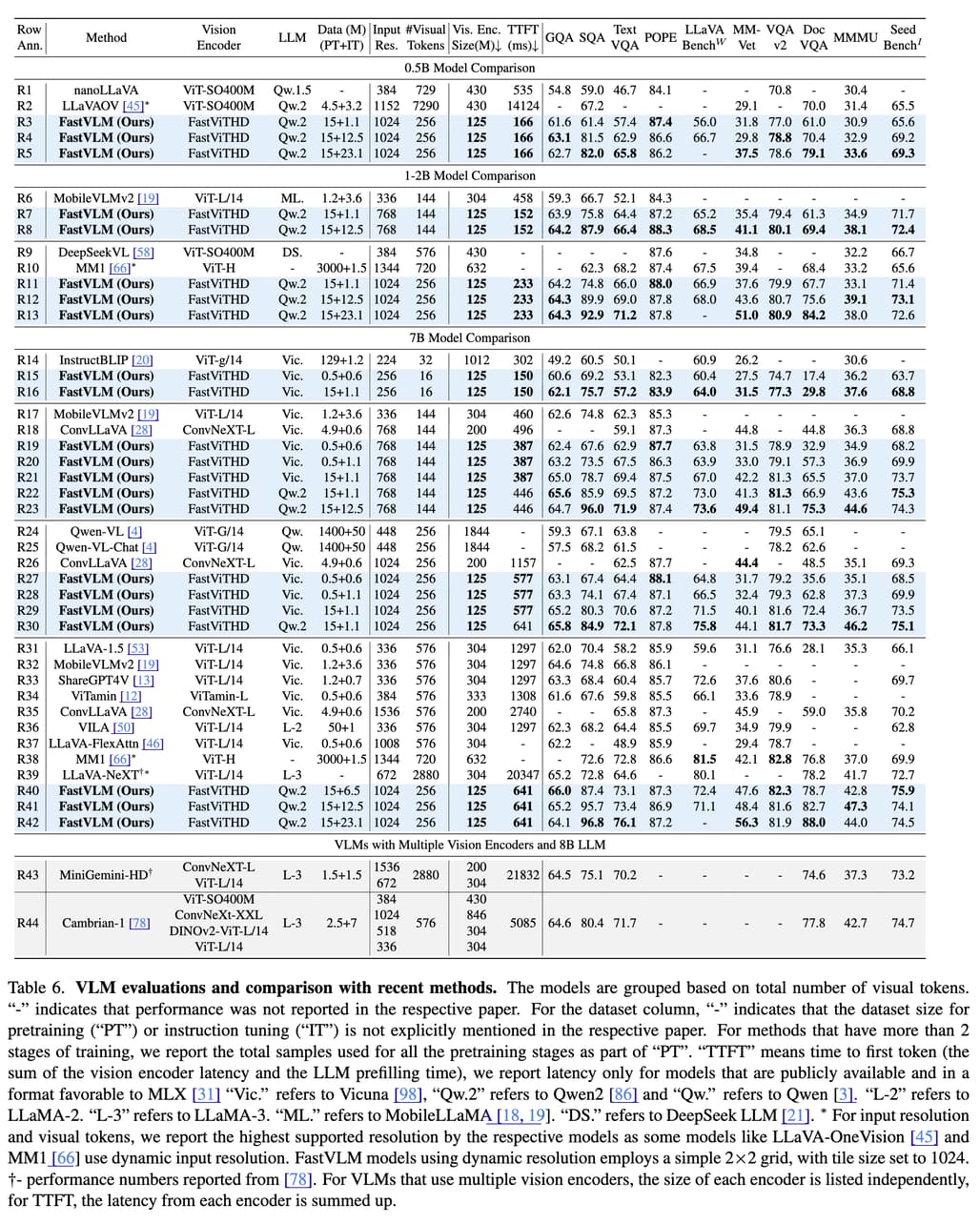
주요 벤치마크 비교 결과: 위 표와 같이 정리된 결과에 따르면, FastVLM은 다음과 같은 벤치마크에서 높은 성능을 보였습니다:
- TextVQA: FastVLM(R41)은 64.4%로, MM1 및 ConvLLaVA 대비 우수한 성능
- DocVQA: FastVLM(R41)은 88.0%로, FlorenceVL(82.1%)보다 뛰어난 정확도
- SeedBench: FastVLM(R41)은 74.5%로, 효율성과 정확도 모두 최상급
- ChartQA, InfoVQA 등 고해상도 기반의 분석에서도 일관된 성능 향상 확인
또한, FastVLM은 토큰 수가 적은 모델임에도 불구하고 동적 타일링(AnyRes) 및 토큰 프루닝(Token Pruning) 없이도 토큰 수가 적은 상태에서도 정확도를 유지하며 단순하고 직관적인 구조로 우수한 트레이드오프를 달성했습니다.
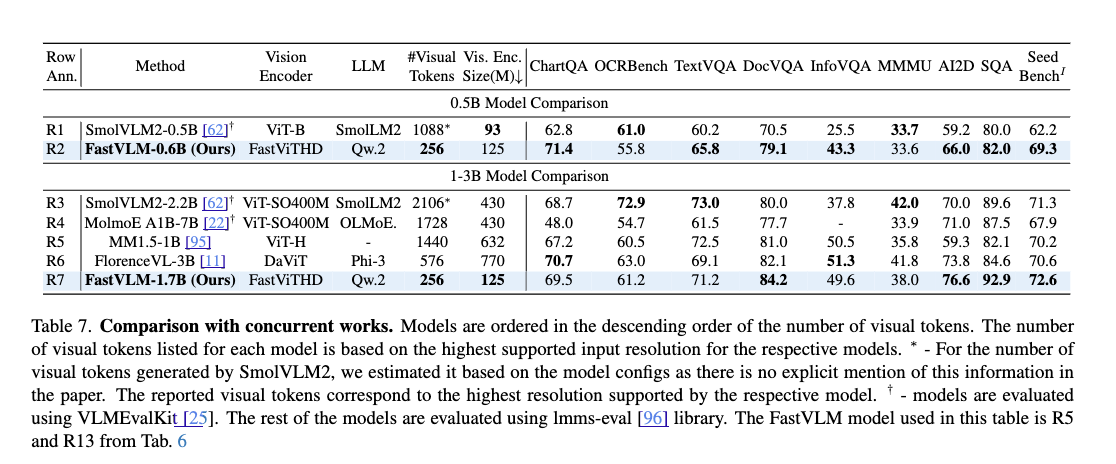
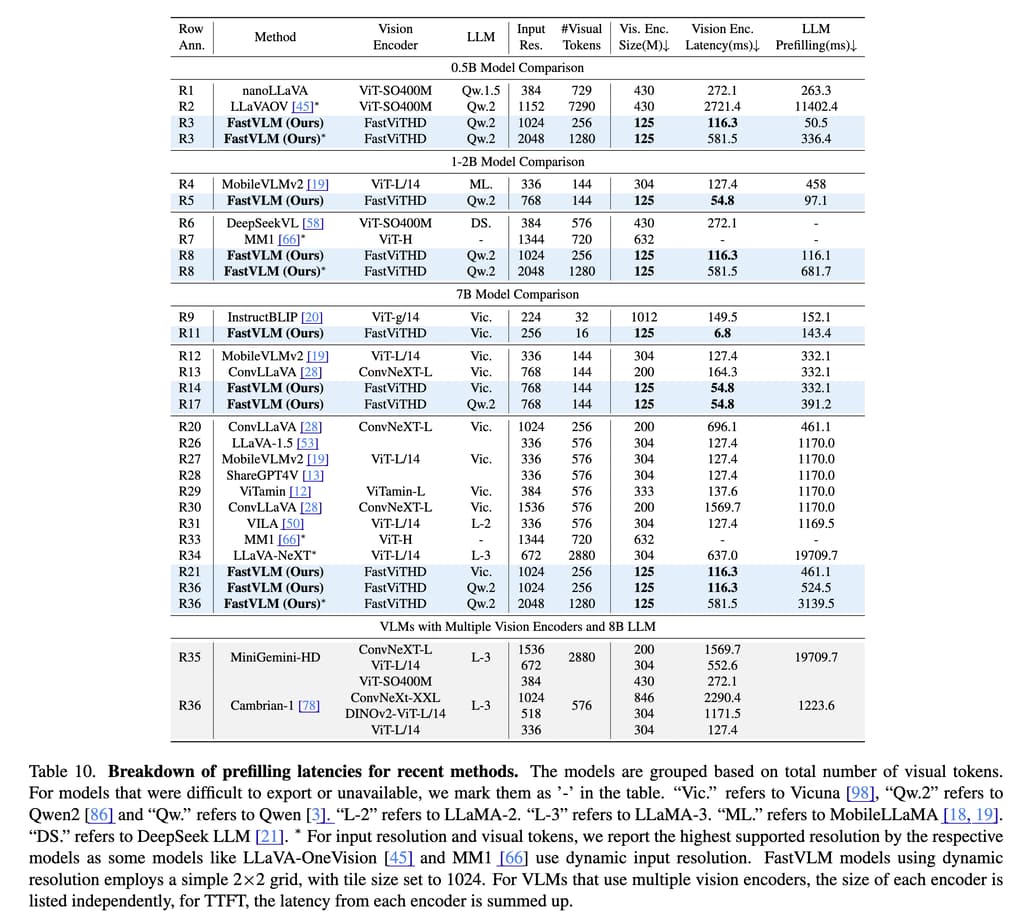
다양한 스케일의 LLM과 조합 실험: Qwen2 0.5B/1.5B/7B 및 Vicuna 7B LLM과 함께 실험한 결과, FastViTHD의 효과는 LLM 크기에 따라 달라지며, 고해상도 입력과 LLM의 조합에 따라 최적의 성능 지점이 달라진다는 사실도 실험적으로 증명되었습니다. 특히 FastViTHD는 Token 수가 적을 때 LLM의 프리필링 비용까지 줄일 수 있어, 전체 TTFT를 크게 줄이는 데 기여합니다.
결론
FastVLM은 고해상도 시각 입력에서도 빠르고 정확한 응답을 제공하는 차세대 VLM 아키텍처로, Apple이 제안한 FastViTHD 비전 인코더를 중심으로 설계되었습니다. 이 모델은 기존의 토큰 프루닝이나 타일링 없이도 처음부터 적은 수의 고품질 시각 토큰을 생성함으로써, 구조적 단순성과 고성능을 동시에 달성할 수 있는 경량 VLM 시스템의 새로운 가능성을 제시합니다.
실험적으로 FastVLM은 다양한 고해상도 멀티모달 벤치마크(TextVQA, DocVQA, SeedBench 등)에서 SOTA(SOTA: state-of-the-art)에 근접하거나 이를 능가하는 성능을 보였으며, 특히 TTFT 기준으로는 기존 모델 대비 수십 배 빠른 응답 속도를 기록했습니다. 이는 온디바이스 및 실시간 AI 환경에서도 매우 실용적인 모델이라는 점을 시사합니다.
FastVLM은 Apple의 MLX 기반으로 구현되어 iOS/macOS에서 직접 실행이 가능하며, GitHub를 통해 코드와 학습된 모델이 공개되어 있어 커뮤니티에서 쉽게 활용할 수 있습니다.
 FastVLM에 대한 연구 소개 블로그
FastVLM에 대한 연구 소개 블로그
FastVLM 연구 논문: FastVLM: Efficient Vision Encoding for Vision Language Models
 FastVLM 모델 GitHub 저장소
FastVLM 모델 GitHub 저장소
https://github.com/apple/ml-fastvlm
 FastVLM 모델 다운로드
FastVLM 모델 다운로드
| Model | Stage | PyTorch Checkpoint (url) |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| 3 | fastvlm_0.5b_stage3 | |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| 3 | fastvlm_1.5b_stage3 | |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| 3 | fastvlm_7b_stage3 |
더 읽어보기
-
Vision Transformer에 대한 시각적 설명 (A Visual Guide to Vision Transformers)
-
CatLIP: CLIP의 대조 학습(CL) 대비 2.7배 빠른 범주 학습(Categorical Learning) 기법에 대한 연구 (feat. Apple)
-
Molmo & PixMo: 공개된 가중치 모델(Molmo)과 데이터(PixMo)로 이루어진 최첨단 멀티모달 모델 (feat. AllenAI)
-
MM-LLMs: 멀티모달 대규모 언어 모델의 최근 발전에 대한 연구 (Recent Advances in MultiModal Large Language Models)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()