
오픈소스 LLM의 새 이정표: DeepSeek-V4 시리즈
DeepSeek이 새로운 혼합 전문가(Mixture-of-Experts, MoE) 언어 모델 시리즈인 DeepSeek-V4 를 공개했습니다. 이번 발표는 단순한 성능 개선을 넘어, 기존 LLM이 갖고 있던 구조적 한계인 초장문 컨텍스트 처리의 비효율성을 정면으로 해결하는 아키텍처 혁신에 초점을 맞추고 있습니다.
추론 모델(reasoning model)의 등장 이후, 테스트-타임 스케일링(test-time scaling) 패러다임은 LLM 성능 향상의 핵심 축으로 자리 잡았습니다. 그러나 이 스케일링 방식은 Attention 메커니즘의 이차적(quadratic) 계산 복잡도라는 근본적 병목에 막혀 있었습니다. 긴 추론 과정을 생성하거나 수백만 토큰을 처리해야 하는 작업에서, 기존 아키텍처는 KV 캐시가 급격히 커지고 추론 비용이 폭발적으로 증가하는 문제를 겪어왔습니다. DeepSeek-V4 시리즈는 이 병목을 직접 타깃으로 하여, 압축 어텐션 기법과 정교한 인프라 최적화를 통해 100만 토큰 컨텍스트를 실용적으로 처리 가능하게 만들었습니다.
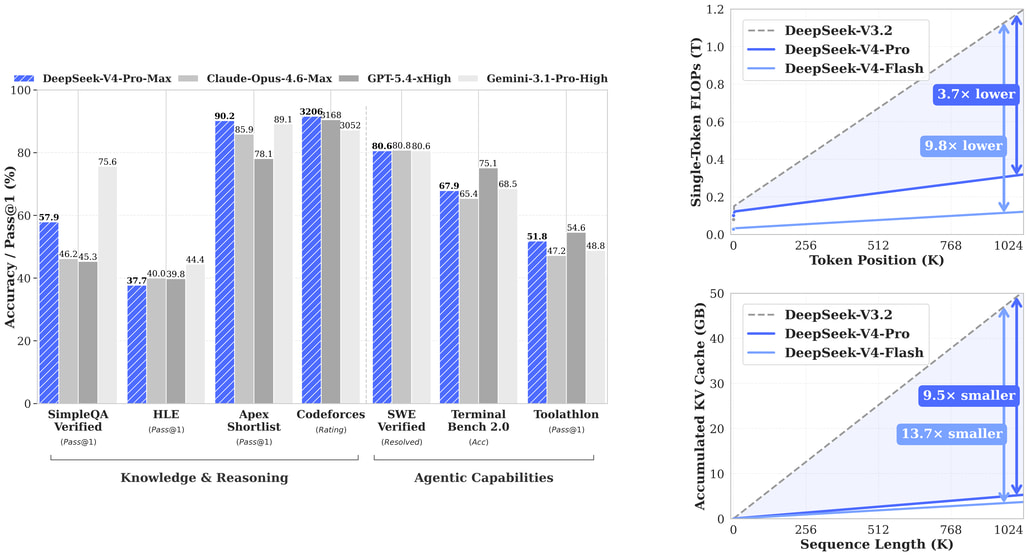
DeepSeek-V4 시리즈는 두 모델로 구성됩니다. DeepSeek-V4-Pro 는 총 1.6T 파라미터(활성화 파라미터 49B)를 갖추고, DeepSeek-V4-Flash 는 총 284B 파라미터(활성화 파라미터 13B)로 설계되어 있습니다. 두 모델 모두 100만 토큰의 컨텍스트를 지원합니다. DeepSeek-V4-Pro의 최대 추론 모드인 DeepSeek-V4-Pro-Max 는 오픈소스 모델 중 최강의 성능을 달성하여, Codeforces 경쟁 프로그래밍 Rating 3206점, LiveCodeBench 93.5%, SWE-Verified 80.6%를 기록했습니다.
기존의 벽을 허문 아키텍처: 하이브리드 압축 어텐션
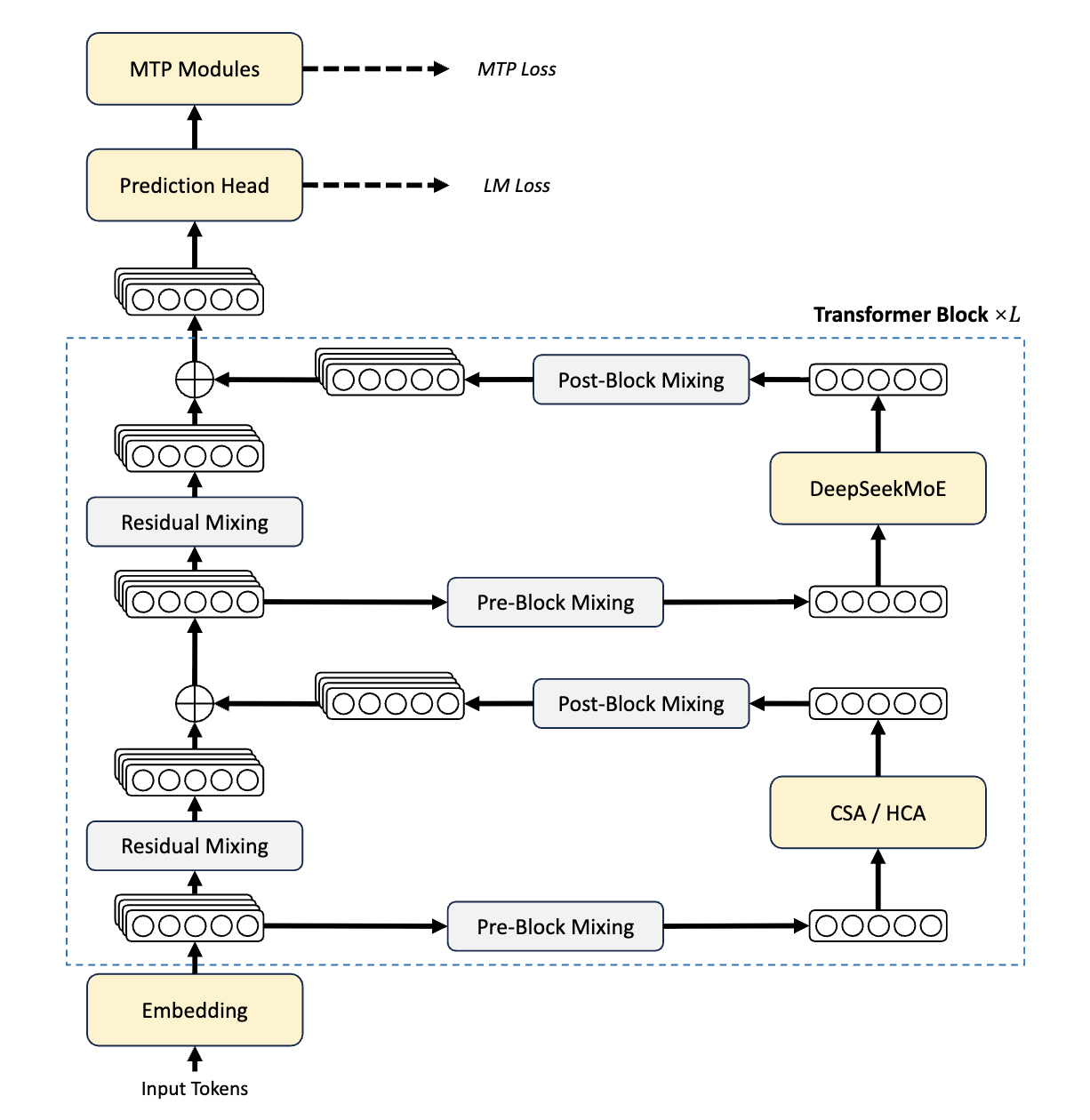
DeepSeek-V4의 가장 중요한 기술적 기여는 하이브리드 어텐션 아키텍처 입니다. 기존 어텐션 방식은 컨텍스트가 길어질수록 KV 캐시가 선형적으로 증가하고 계산량이 이차적으로 폭발하여, 100만 토큰 규모의 컨텍스트를 실용적으로 처리하는 것이 거의 불가능했습니다.
DeepSeek-V4는 두 가지 새로운 압축 어텐션 기법을 설계하고 이를 인터리브(interleaved) 방식으로 조합하여 이 문제를 해결합니다.
압축 희소 어텐션(CSA)과 극압축 어텐션(HCA)
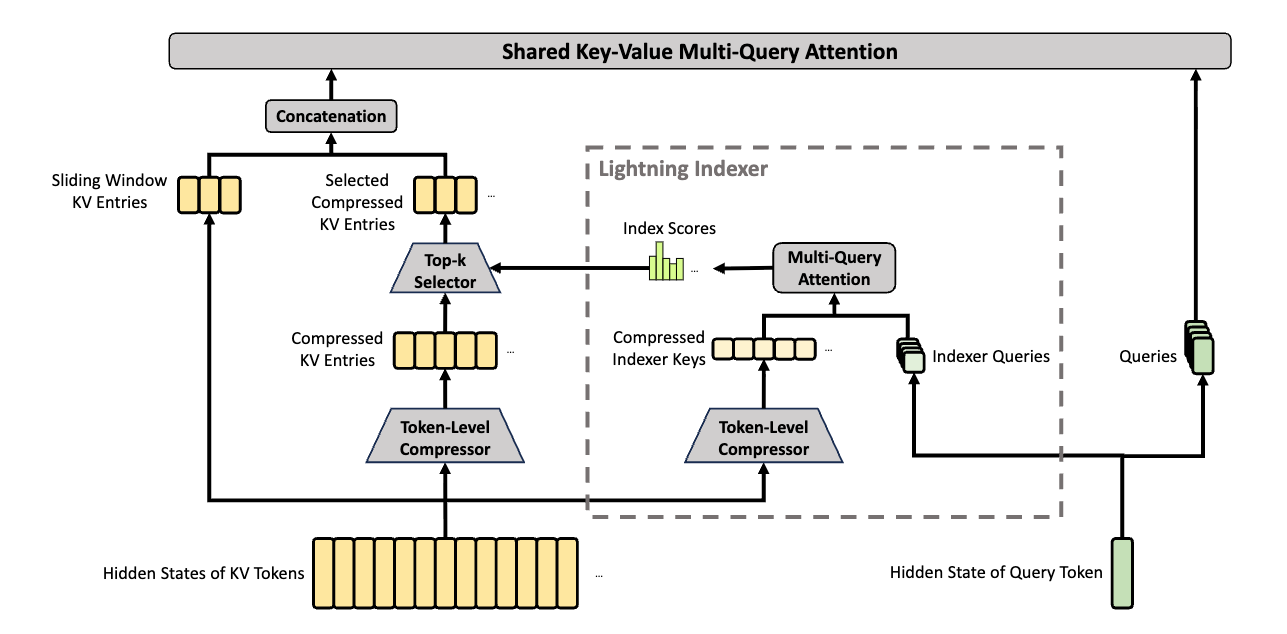
압축 희소 어텐션(Compressed Sparse Attention, CSA) 은 연속된 $m$개의 KV 항목을 하나로 압축한 뒤, DeepSeek Sparse Attention(DSA)를 적용하여 각 쿼리 토큰이 상위 $k$개의 압축된 KV 항목에만 집중하도록 합니다. 시퀀스 길이를 $\frac{1}{m}$로 줄이는 이 방식은 슬라이딩 윈도우 어텐션 브랜치를 보조적으로 추가하여 지역적 세밀한 의존성도 보존합니다.
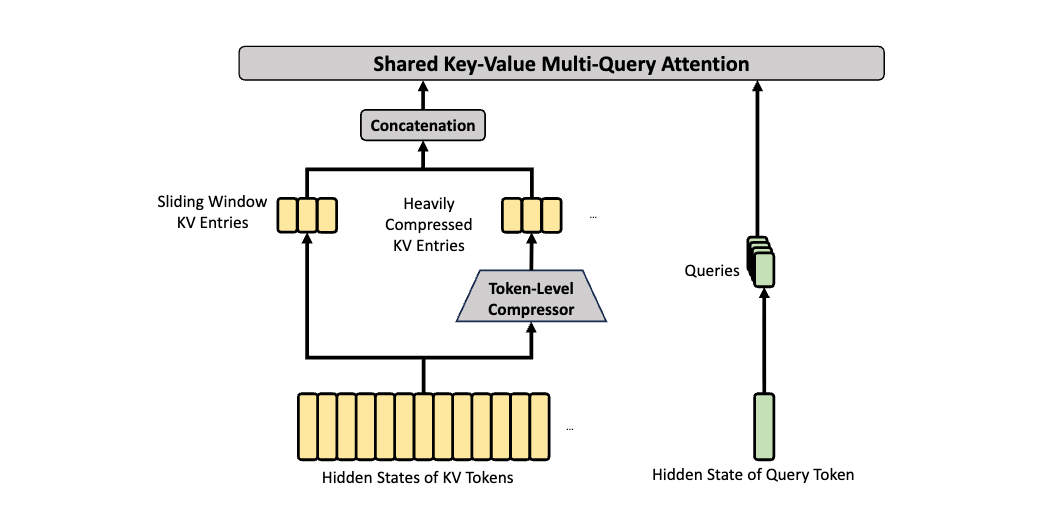
극압축 어텐션(Heavily Compressed Attention, HCA) 은 CSA보다 훨씬 강한 압축률을 적용합니다. $m'(\gg m)개의 KV 항목을 하나로 통합하여 시퀀스 길이를 \frac{1}{m'}$로 대폭 줄이고, 희소 선택 없이 Dense Attention을 수행합니다. HCA는 CSA보다 극단적인 압축을 달성하여 초장문 시나리오에서의 효율을 극대화합니다.
이 두 기법을 결합함으로써, 100만 토큰 컨텍스트 환경에서 DeepSeek-V4-Pro는 DeepSeek-V3.2와 비교하여 단일 토큰 추론 FLOPs의 27% 만을 사용하고, KV 캐시는 10% 수준으로 줄어듭니다. DeepSeek-V4-Flash는 더욱 효율적으로, FLOPs 10%, KV 캐시 7% 수준을 달성합니다.
다양체 제약 하이퍼 연결(mHC)
DeepSeek-V4는 다양체 제약 하이퍼 연결(Manifold-Constrained Hyper-Connections, mHC) 을 통해 기존 잔차 연결(residual connection)을 강화합니다. 표준 Hyper-Connections(HC)가 잔차 스트림의 너비를 확장하는 방식을 취하는 반면, mHC는 잔차 변환 행렬 $B_l$을 이중 확률 행렬(doubly stochastic matrix)의 다양체 $\mathcal{M}$으로 제약합니다.
이 제약은 매핑 행렬의 스펙트럼 놈(spectral norm)이 1 이하로 유지되도록 보장하여, 순전파와 역전파 모두에서 수치적 안정성을 크게 높입니다. 실제로 DeepSeek는 Sinkhorn-Knopp 알고리즘(20회 반복)을 활용하여 이 투영을 효율적으로 수행합니다.
Muon 옵티마이저
DeepSeek-V4는 대부분의 파라미터 업데이트에 Muon 옵티마이저를 채택했습니다. Muon은 뉴턴-슐츠(Newton-Schulz) 반복을 활용해 기울기 행렬을 직교화(orthogonalize)하고, 이를 통해 더 빠른 수렴과 향상된 학습 안정성을 달성합니다. 임베딩 모듈, 예측 헤드, RMSNorm 등에는 기존의 AdamW 옵티마이저를 유지합니다.
오픈소스 MoE 인프라: MegaMoE와 TileLang
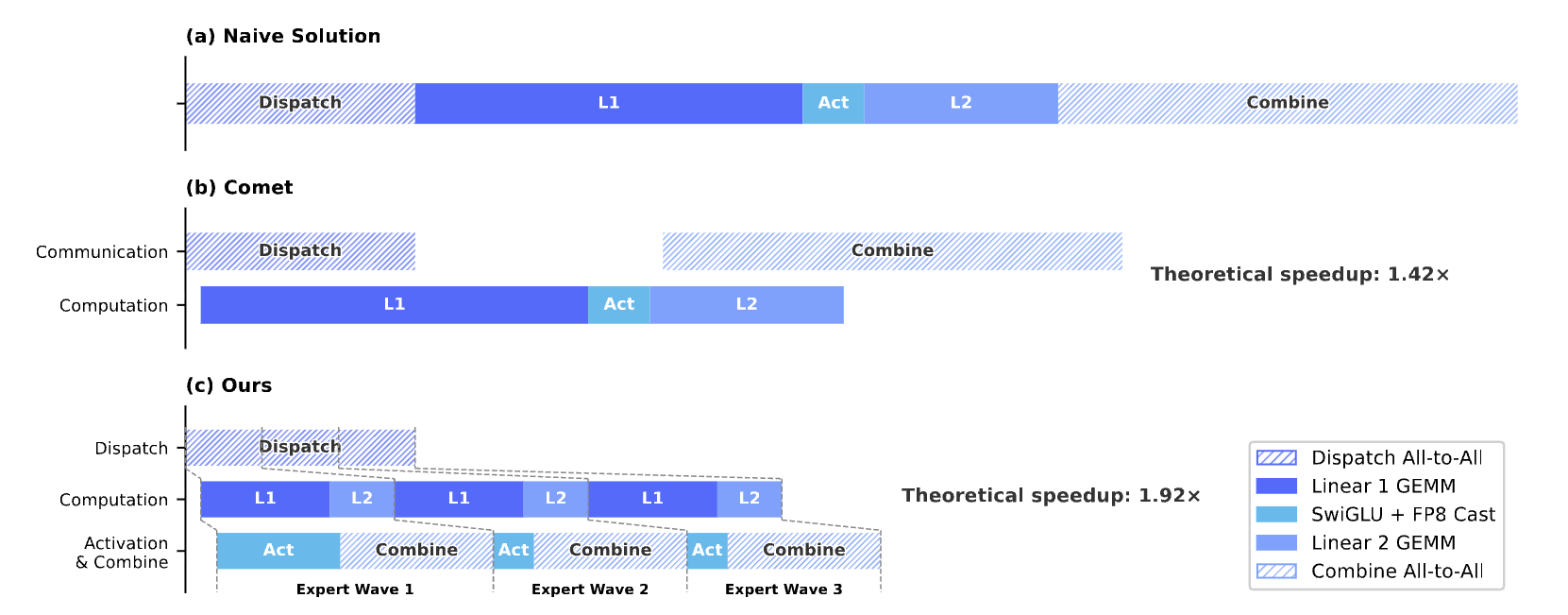
DeepSeek-V4는 아키텍처 혁신뿐 아니라 시스템 수준의 인프라 최적화도 함께 공개합니다.
전문가 병렬 처리(Expert Parallelism) 최적화. DeepGEMM의 구성 요소로 공개된 MegaMoE 는 MoE 레이어에서 통신과 계산을 단일 파이프라인 커널로 융합합니다. 전문가들을 작은 단위(wave)로 나누어 스케줄링함으로써, 비교적 낮은 인터커넥트 대역폭 환경에서도 1.92배의 이론적 속도 향상을 달성하고, 실제 추론 워크로드에서 1.50~1.73배 속도 향상을 확인했습니다.
TileLang 기반 커널 개발. DeepSeek-V4는 TileLang을 도입하여 수백 개의 파인그레인드 ATen 연산자를 대체하는 융합 커널을 개발했습니다. TileLang은 Z3 SMT 솔버를 통합하여 형식적 정수 분석을 지원하고, Host Codegen을 통해 Python 실행 경로의 CPU 오버헤드를 1마이크로초 미만으로 줄입니다.
FP4 양자화 인식 학습(QAT). MoE 전문가 가중치와 CSA의 인덱서 QK 경로에 FP4(MXFP4) 정밀도를 적용합니다. FP4-to-FP8 역양자화는 무손실로 이루어지며, 탑-k 선택기에서 2배 속도 향상을 달성하면서도 KV 항목의 99.7% 회수율을 유지합니다.
사전 학습: 32T 토큰과 점진적 시퀀스 확장
DeepSeek-V4-Flash는 32T 토큰, DeepSeek-V4-Pro는 33T 토큰 의 다양하고 고품질의 데이터로 사전 학습되었습니다. 사전 학습 데이터는 DeepSeek-V3의 데이터셋을 기반으로 하되, 웹 소스의 자동 생성 콘텐츠를 필터링하고, 수학/코드 데이터를 강화하며, 긴 컨텍스트 학습을 위한 장문 문서를 집중적으로 큐레이션했습니다.
학습 시퀀스 길이는 4K에서 시작하여 단계적으로 16K, 64K, 최종적으로 1M 토큰까지 확장됩니다. 희소 어텐션은 처음에는 Dense Attention으로 워밍업한 뒤, 64K 시퀀스 길이에서 도입됩니다. 학습 안정성 확보를 위해 두 가지 핵심 기법을 사용합니다.
예측 라우팅(Anticipatory Routing). MoE 레이어에서 발생하는 손실 스파이크를 막기 위해, 현재 스텝 $t$의 백본 네트워크 파라미터 $\theta_t$로 특징을 계산하되 라우팅 인덱스는 이전 스텝 파라미터 $\theta_{t-\Delta t}$로 사전 계산합니다. 이를 통해 라우팅 메커니즘이 이상치를 유발하는 악순환을 끊습니다.
SwiGLU 클램핑. SwiGLU의 선형 컴포넌트를 [-10, 10] 범위로, 게이트 컴포넌트를 상한 10으로 클램핑하여 이상값을 효과적으로 억제합니다.
후처리 학습: 전문가 분화 후 통합
DeepSeek-V4의 후처리 학습 파이프라인은 두 단계로 구성됩니다.
1단계: 전문가 독립 학습(Specialist Training). 수학, 코딩, 에이전트, 지시 따르기 등 각 도메인에 대해 별도의 전문가 모델을 독립적으로 학습시킵니다. 각 전문가는 SFT로 기초 능력을 확립한 뒤, 도메인별 보상 모델이 가이드하는 GRPO 기반의 강화 학습을 적용합니다. 특히 검증이 어려운 태스크를 위해 스칼라 보상 모델 대신 생성적 보상 모델(Generative Reward Model, GRM) 을 사용합니다. GRM은 루브릭 기반 RL 데이터를 활용하며, 액터 네트워크 자체가 GRM 역할을 겸하여 판별 능력과 생성 능력을 동시에 학습합니다.
2단계: 온-폴리시 증류(On-Policy Distillation, OPD). 10개 이상의 교사 모델에서 지식을 단일 통합 모델로 전달합니다. 학생 모델이 자신의 궤적을 샘플링하는 온-폴리시 방식을 채택하며, 전통적인 토큰 수준 이점 추정 대신 전체 어휘(full-vocabulary) 로짓 증류 를 사용하여 기울기 추정의 분산을 낮추고 학습 안정성을 높입니다.
세 가지 추론 모드 (Three Reasoning Modes)

DeepSeek-V4-Pro와 DeepSeek-V4-Flash 모두 세 가지 추론 노력 수준을 지원합니다.
| 추론 모드 | 특성 | 대표 활용 사례 | 응답 형식 |
|---|---|---|---|
| Non-think | 빠른 직관적 응답 | 일상적 작업, 저위험 결정 | </think> 요약 |
| Think High | 의식적 논리 분석, 느리지만 정확 | 복잡한 문제 해결, 계획 수립 | <think> 사고 </think> 요약 |
| Think Max | 추론 능력을 최대한 활용 | 모델 추론 한계 탐색 | 특수 시스템 프롬프트 + <think> 사고 </think> 요약 |
Think Max 모드에서는 컨텍스트 윈도우를 최소 384K 토큰으로 설정하도록 권장합니다.
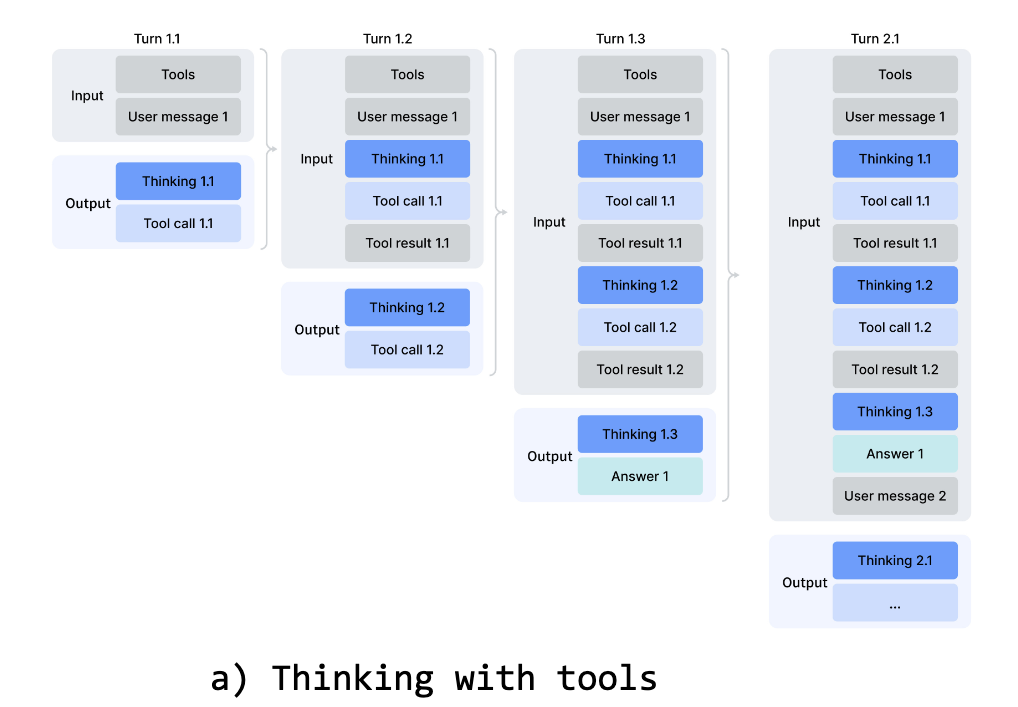
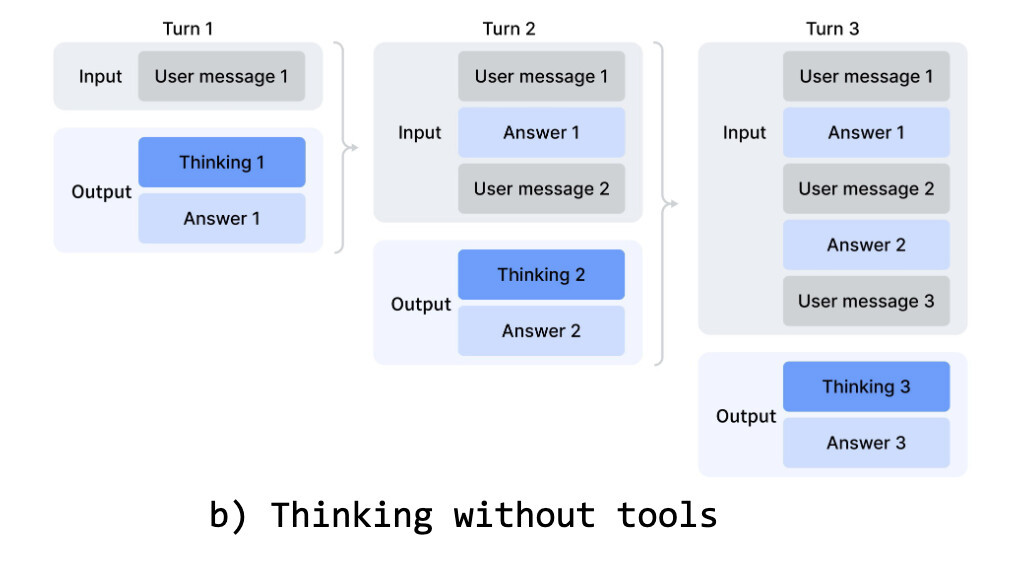
또한, DeepSeek-V4는 에이전틱 환경에서의 인터리브드 씽킹(Interleaved Thinking) 을 개선합니다. 이전 DeepSeek-V3.2와 달리, 툴 호출 시나리오에서 전체 사고 이력을 대화 전반에 걸쳐 보존하여 장기 에이전트 태스크에서의 추론 연속성을 유지합니다.
벤치마크 성능: 오픈소스 최강 수준
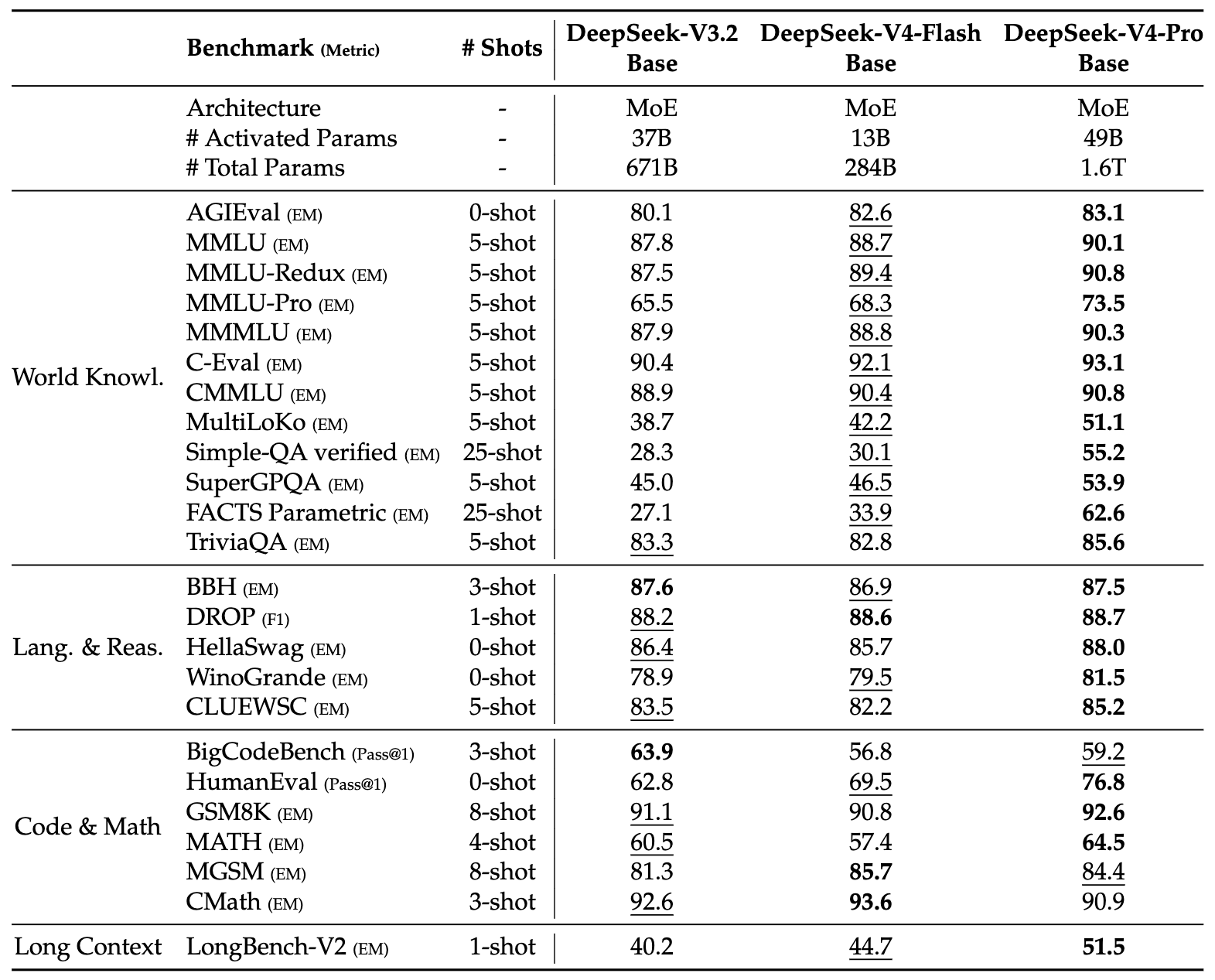
기반 모델 비교
DeepSeek-V4-Flash-Base는 13B라는 소규모 활성화 파라미터로도 671B 파라미터를 활성화하는 DeepSeek-V3.2-Base를 대부분의 벤치마크에서 앞섭니다. DeepSeek-V4-Pro-Base는 세계 지식, 추론, 코딩, 수학, 장문 컨텍스트 전 영역에서 이전 모든 DeepSeek 기반 모델을 압도합니다.
주요 기반 모델 성능 (DeepSeek-V4-Pro-Base 기준):
- MMLU: 90.1 (vs DeepSeek-V3.2-Base 87.8)
- FACTS Parametric: 62.6 (vs 27.1로 대폭 향상)
- HumanEval: 76.8 (vs 62.8)
- LongBench-V2: 51.5 (vs 40.2)
인스트럭트 모델 비교: DeepSeek-V4-Pro-Max vs 프론티어 모델
| 벤치마크 | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | DS-V4-Pro Max |
|---|---|---|---|---|
| LiveCodeBench | 88.8 | - | 91.7 | 93.5 |
| Codeforces (Rating) | - | 3168 | 3052 | 3206 |
| HMMT 2026 Feb | 96.2 | 97.7 | 94.7 | 95.2 |
| IMOAnswerBench | 75.3 | 91.4 | 81.0 | 89.8 |
| Apex Shortlist | 85.9 | 78.1 | 89.1 | 90.2 |
| SWE-Verified | 80.8 | - | 80.6 | 80.6 |
| MCPAtlas Public | 73.8 | 67.2 | 69.2 | 73.6 |
코딩 분야에서 DeepSeek-V4-Pro-Max는 Codeforces 경쟁 프로그래밍에서 Rating 3206점 을 달성하며 현재 인간 후보 중 23위에 해당하는 성능을 보입니다. LiveCodeBench에서는 93.5%로 비교 대상 모든 모델을 앞섭니다.
수학 추론에서는 Putnam-2025 문제 세트에서 120/120 완벽 증명 을 달성했습니다. 이는 하이브리드 형식-비형식 추론과 대규모 컴퓨트 스케일링을 결합한 프론티어 체제에서의 결과입니다.
장문 컨텍스트 성능
1M 토큰 컨텍스트 환경에서 DeepSeek-V4-Pro는 MRCR 태스크에서 Gemini-3.1-Pro를 능가하고, CorpusQA에서도 앞섭니다. MRCR 8-needle 태스크에서는 128K 컨텍스트 이내에서 매우 안정적인 검색 성능을 보이며, 1M까지 확장해도 오픈소스 및 클로즈드소스 경쟁 모델들에 비해 강한 성능을 유지합니다.
실제 태스크 성능
DeepSeek 내부 벤치마크에서 DeepSeek-V4-Pro-Max는 중국어 글쓰기, 검색, 기업 전문가 태스크 등 실제 사용 환경에서도 두각을 나타냅니다. 30개의 고급 중국어 전문직 태스크로 구성된 White-Collar Task 평가에서 Opus-4.6-Max 대비 53% 승률을 기록하며, 특히 Task Completion과 Content Quality에서 강점을 보였습니다.
내부 R&D 코딩 벤치마크(PyTorch, CUDA, Rust, C++ 등 기술 스택 기반 30개 태스크)에서는 Pass Rate 67%를 달성하여 Claude Sonnet 4.5(47%)를 크게 앞섭니다.
라이선스
DeepSeek-V4-Pro와 DeepSeek-V4-Flash 모든 모델은 MIT 라이선스로 배포되어, 연구 목적은 물론 상업적 용도로도 자유롭게 사용 및 수정이 가능합니다.
 DeepSeek 챗봇
DeepSeek 챗봇
 DeepSeek-V4 기술 보고서 (PDF)
DeepSeek-V4 기술 보고서 (PDF)
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/resolve/main/DeepSeek_V4.pdf
 DeepSeek-V4 모델 다운로드
DeepSeek-V4 모델 다운로드
| 모델 | 총 파라미터 | 활성화 파라미터 | 컨텍스트 길이 | 정밀도 |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
FP4 + FP8 혼합 정밀도: MoE 전문가 파라미터에는 FP4, 나머지 파라미터 대부분에는 FP8 정밀도를 사용합니다.
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()