Mellum 2 소개
Mellum 2는 JetBrains가 2026년 6월 Apache 2.0 라이선스로 공개한 120억(12B) 파라미터 규모의 오픈소스 언어 모델로, 코드와 자연어를 함께 다루며 AI 시스템의 라우팅, 요약, 중간 추론 단계를 빠르고 저렴하게 처리하도록 설계되었습니다. 프론티어 모델의 절대 성능 경쟁이 아니라, 프로덕션 AI에서 가장 자주 부딪히는 세 가지 병목인 지연 시간(latency), 처리량(throughput), 비용(cost) 을 푸는 데 초점을 맞춘 모델입니다.
JetBrains는 IntelliJ IDEA, PyCharm 같은 개발 도구를 만드는 회사답게, 처음에는 IDE의 코드 완성(code completion) 기능을 위해 1세대 Mellum을 개발했습니다. 1세대는 40억(4B) 파라미터의 밀집(dense) 모델로 코드 완성에 집중했지만, 그 후속인 Mellum 2는 코드 완성을 넘어 코드 생성과 편집, 디버깅, 다단계 추론, 도구 사용 및 함수 호출, 에이전트 코딩, 대화형 프로그래밍 보조까지 아우르는 소프트웨어 엔지니어링에 특화된 범용 모델 로 발전했습니다. 외부 모델을 가져와 미세조정한 것이 아니라 처음부터 자체적으로 학습(trained from scratch) 되었고, 실제 배포 환경을 염두에 두고 설계되었다는 점이 특징입니다.
모델은 Hugging Face에 가중치가 모두 공개되어 있어 실험, 미세조정, 대규모 배포 등 어떤 목적이든 자체 인프라에서 바로 실행할 수 있습니다. 이 글에서는 Mellum 2의 아키텍처와 후학습 변형, 벤치마크 성능, 그리고 JetBrains가 강조하는 포컬 모델(focal model) 철학을 차례로 살펴보겠습니다.
토큰당 25억 개만 켜지는 MoE 설계
Mellum 2가 작으면서도 빠를 수 있는 핵심은 전문가 혼합(Mixture-of-Experts, MoE) 구조에 있습니다. 모델 전체 파라미터는 120억 개지만, 64개의 전문가(Expert) 중 토큰당 8개만 활성화되기 때문에 한 토큰을 처리할 때 실제로 계산에 쓰이는 파라미터는 25억(2.5B) 개에 불과합니다. 덕분에 12B급 모델의 표현력을 유지하면서도 계산 비용은 소형 모델 수준으로 낮춰, 실시간 워크로드가 요구하는 높은 처리량과 저지연 추론을 동시에 제공합니다. MoE 구조 자체에 대한 더 깊은 설명은 PyTorch로 전문가 혼합(MoE) 모델 학습 확장하기 글을 참고하시면 좋습니다.
어텐션 측면에서는 그룹 쿼리 어텐션(Grouped Query Attention, GQA)을 사용해 Query 헤드 32개에 Key/Value 헤드 4개를 공유하고, 네 개 레이어 중 세 개에 슬라이딩 윈도우(sliding-window) 어텐션을 적용하며 나머지 한 개에만 전체(full) 어텐션을 두는 방식으로 131,072 토큰(128K)의 긴 컨텍스트를 효율적으로 처리합니다. 또한 많은 최신 모델과 달리 Mellum 2는 다중 모달(multi-modal)이 아니며, 오직 자연어와 코드 데이터에만 특화되어 학습되었습니다. 이미지나 음성을 포기하는 대신 소프트웨어 엔지니어링 영역에 집중함으로써 경량성과 속도를 지켰다는 설계 결정입니다.
속도를 끌어올리는 또 하나의 장치는 다중 토큰 예측(Multi-Token Prediction, MTP) 헤드 입니다. 이 헤드는 사전학습 단계에서는 보조 학습 목표로 쓰이고, 추론 단계에서는 추측 디코딩(speculative decoding)의 내장 초안(draft) 모델 역할을 겸합니다. JetBrains는 보급형 GPU에서의 추론 효율을 설계 제약으로 두고 각 선택지를 어블레이션(ablation)으로 검증했다고 밝혔는데, 이 덕분에 기술 보고서 기준으로 Mellum 2는 비슷한 규모의 다른 모델과 견줄 만한 성능을 내면서도 추론 시간을 절반 이하로 줄입니다.
사전학습(pre-training)은 약 10.6조(trillion) 토큰 규모로, 다양한 웹 데이터에서 출발해 점차 정제된 코드와 수학 콘텐츠 비중을 높이는 3단계 커리큘럼으로 진행되었습니다. 최적화에는 Muon 옵티마이저와 FP8 혼합 정밀도, Warmup-Hold-Decay 학습률 스케줄이 쓰였고, 이후 레이어 선택적 YaRN 기법으로 컨텍스트 윈도우를 128K까지 확장했습니다. 주요 사양은 다음과 같습니다.
| 항목 | 값 |
|---|---|
| 전체 파라미터 | 120억 (12B) |
| 토큰당 활성 파라미터 | 25억 (2.5B) |
| 전문가 수 (Experts) | 64개 (토큰당 8개 활성) |
| 레이어 수 | 28 |
| 히든 차원 / Intermediate | 2,304 / 7,168 (MoE 896) |
| 어텐션 (GQA) | Query 32개 / KV 4개 헤드 |
| 컨텍스트 길이 | 131,072 토큰 (128K) |
| 슬라이딩 윈도우 | 1,024 (네 개 중 세 개 레이어) |
| 어휘 크기 | 98,304 |
| 정밀도 | bfloat16 (사전학습 FP8 혼합) |
| 사전학습 규모 | 약 10.6조 토큰 (3단계 커리큘럼) |
| 추론 가속 | Multi-Token Prediction 헤드 (추측 디코딩) |
| 라이선스 | Apache 2.0 |
Instruct와 Thinking, 두 가지 후학습 변형
Mellum 2는 단일 모델이 아니라 하나의 베이스 모델에서 갈라져 나온 모델 패밀리 형태로 공개되었습니다. 공통된 출발점은 롱 컨텍스트 확장을 거친 Base 모델이며, 여기에 두 갈래의 후학습(post-training)이 적용됩니다. 두 변형 모두 지도 미세조정(Supervised Fine-Tuning, SFT) 이후 검증 가능한 보상을 활용한 강화 학습(Reinforcement Learning with Verifiable Rewards, RLVR) 으로 마무리되지만, 강화 학습에 쓰는 데이터 조합이 서로 다릅니다.
두 변형의 차이는 추론 과정을 겉으로 드러내는지 에 있습니다.
Instruct 는 외부로 드러나는 사고의 연쇄(chain-of-thought) 없이 곧바로 답을 내놓습니다. RLVR 단계에서 수학, 실행 가능한 코딩, 도구 사용(tool use), 지시 따르기, 추론, 지식 과제를 두루 학습했으며, 추론 흔적이 필요 없는 저지연 응답, 라우팅, 간단한 코드 생성처럼 빠른 반응이 중요한 작업에 적합합니다.
Thinking 은 최종 답 앞에 <think>...</think> 블록 안에서 명시적으로 추론을 펼친 뒤 답을 정리합니다. SFT 단계에서 마지막 어시스턴트 응답에만 손실(loss)을 계산하고, RLVR 단계에서는 긴 형식의 수학 하위 집합(long-form math subset)을 포함한 더 어려운 데이터 조합으로 학습되었습니다. 복잡한 디버깅, 다단계 계획 수립, 에이전트 워크플로, 수학처럼 추론 부담이 큰 작업에 적합합니다.
공개된 체크포인트 전체 구성은 다음과 같습니다.
| 체크포인트 | 설명 |
|---|---|
| Base Pretrain | 롱 컨텍스트 확장 이전의 기본 체크포인트 |
| Base | 최종 베이스 모델 |
| Instruct SFT | 지도 미세조정된 instruct 체크포인트 |
| Thinking SFT | 지도 미세조정된 thinking 체크포인트 |
| Instruct | RL로 조정된 instruct 모델 (직접 응답) |
| Thinking | RL로 조정된 thinking 모델 (<think> 블록으로 추론 노출) |
비슷한 규모 모델과의 성능 비교
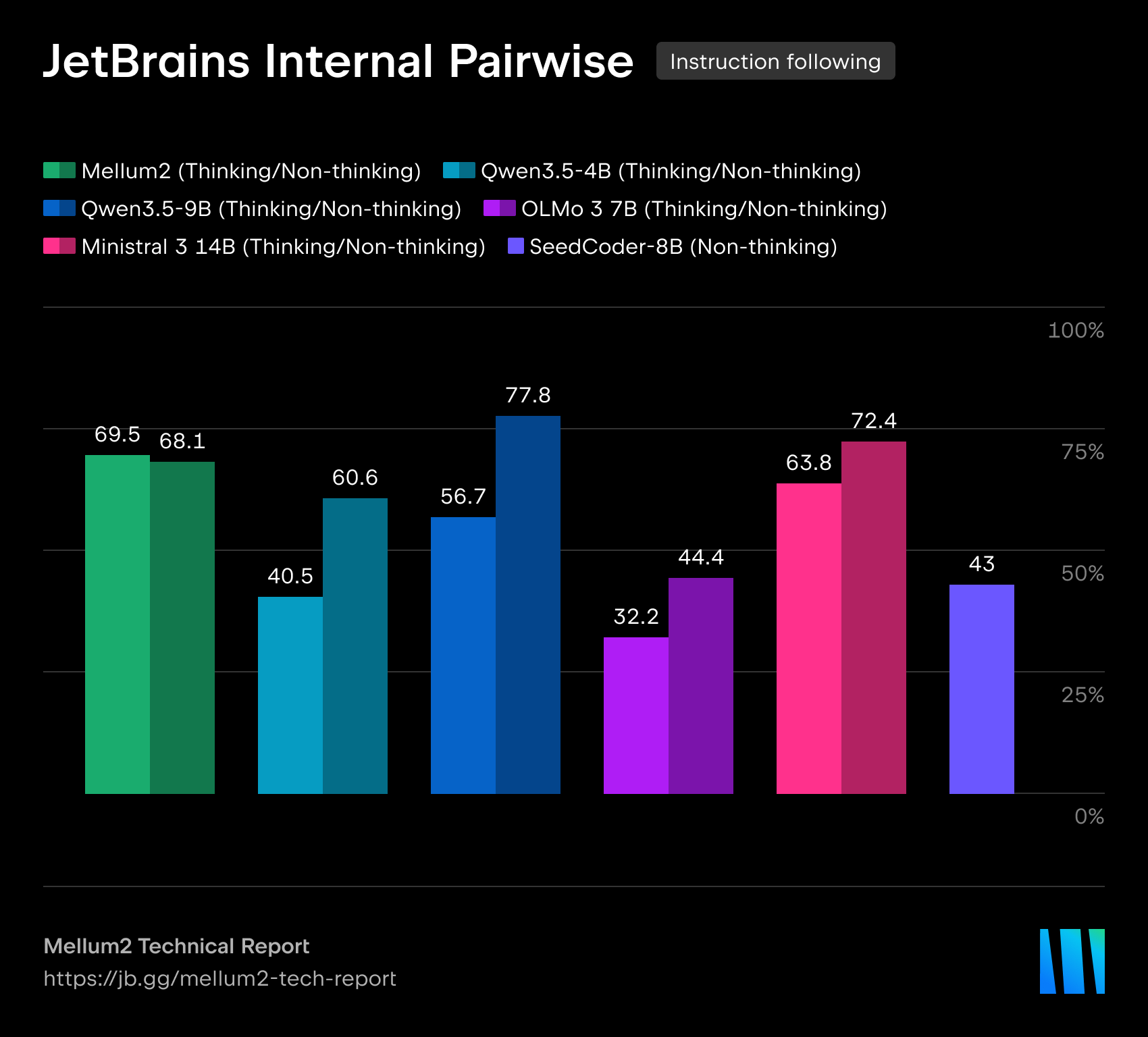
JetBrains가 자체 보고(self-reported)한 후학습 평가 결과를 보면, Mellum 2의 강점이 어디에 있는지가 분명하게 드러납니다. 아래는 Thinking 변형을 Qwen3.5 (9B), OLMo-3 (7B), Ministral 3 (14B)과 비교한 대표 벤치마크입니다. HarmBench를 제외하면 모두 높을수록 좋은 점수입니다.
| 벤치마크 | Mellum2 Thinking | Qwen3.5 (9B) | OLMo-3 (7B) | Ministral 3 (14B) |
|---|---|---|---|---|
| LiveCodeBench v6 (코딩) | 69.9 | 68.3 | 59.8 | 42.7 |
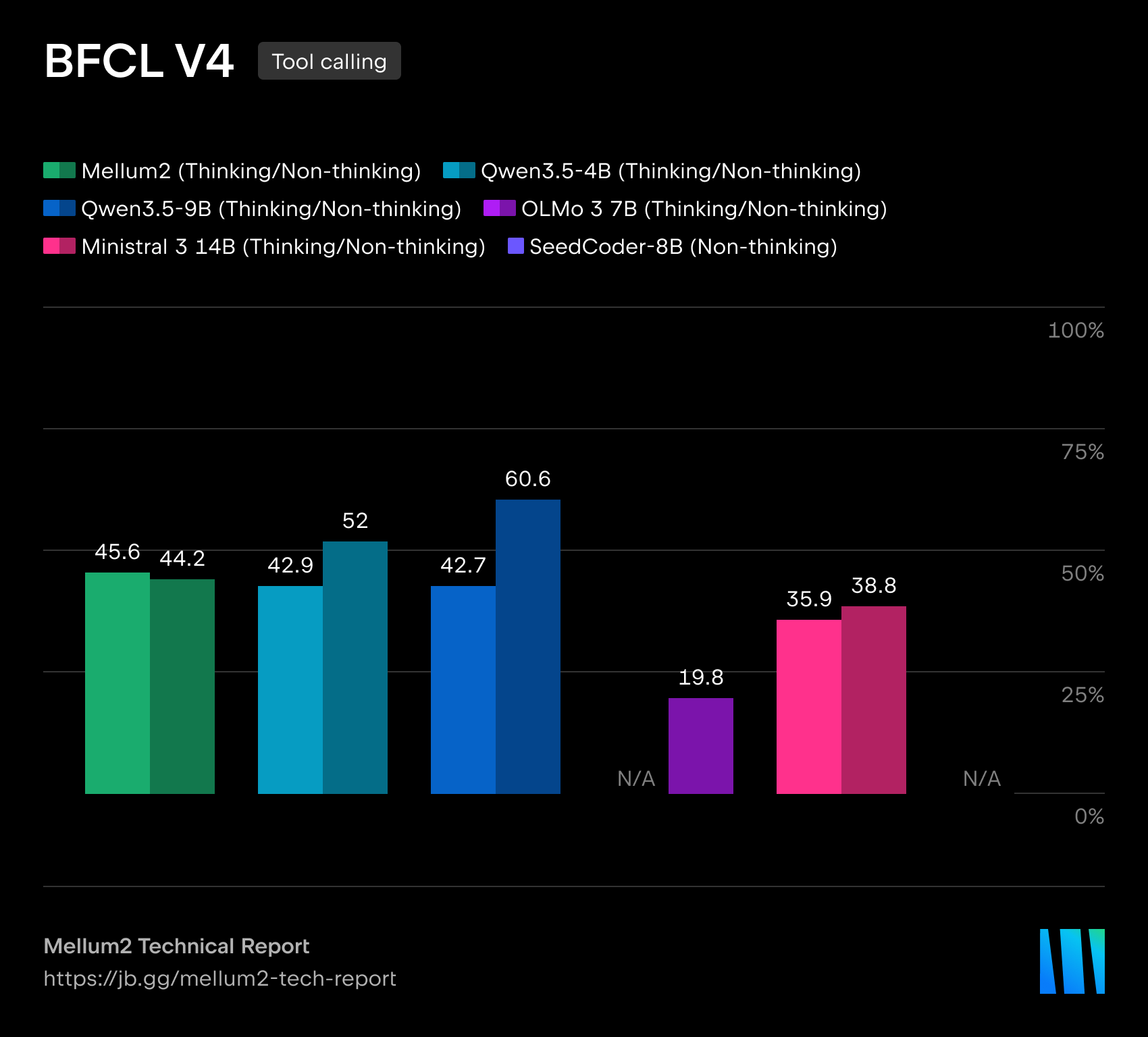
| BFCL v4 (도구 사용) | 45.6 | 42.7 | — | 35.9 |
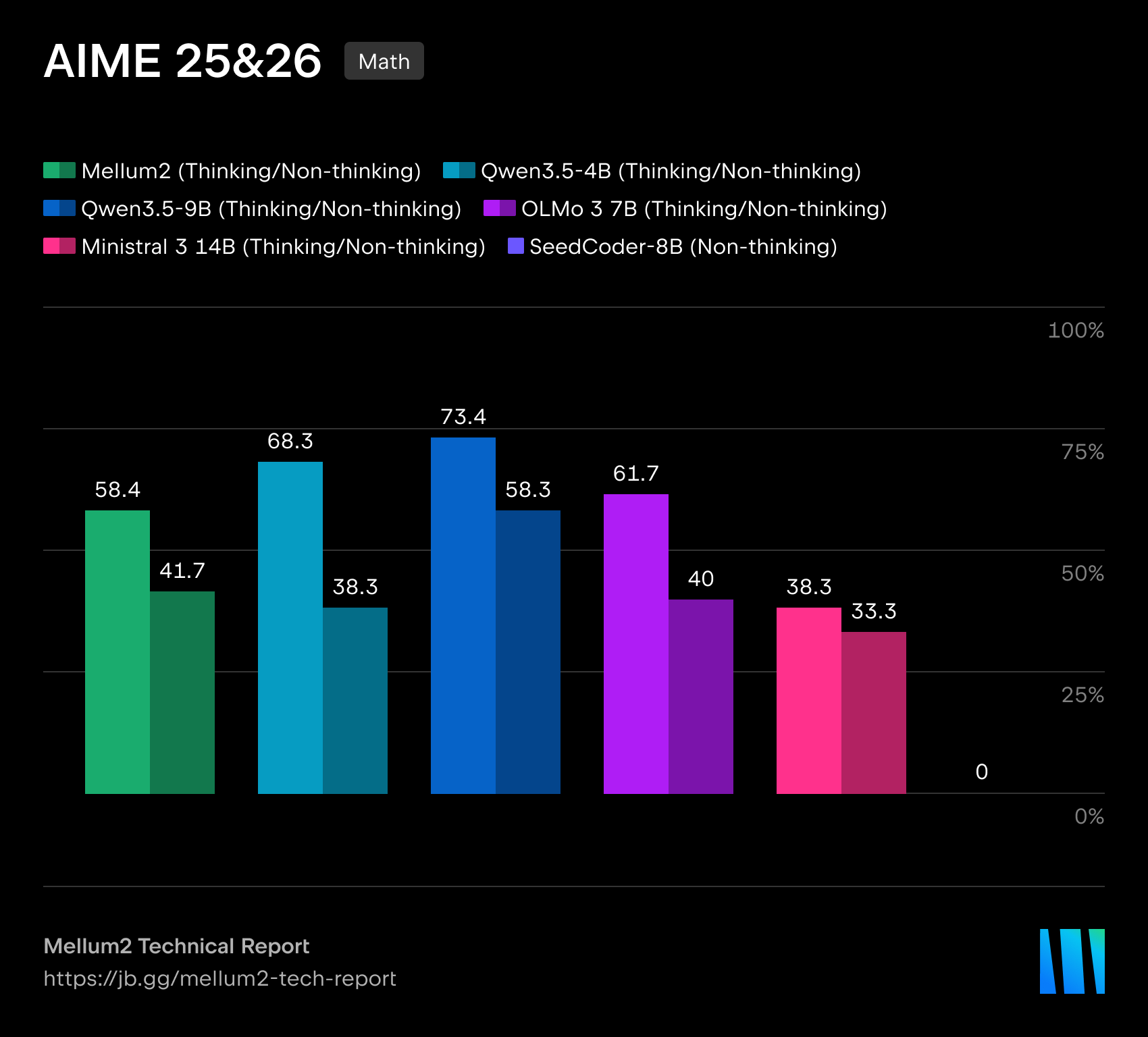
| AIME (수학) | 58.4 | 73.4 | 61.7 | 38.3 |
| GPQA Diamond (지식) | 57.6 | 81.3 | 29.3 | 46.0 |
| IFEval (지시 따르기) | 76.5 | 89.8 | 84.7 | 59.7 |
| JetBrains pairwise (내부) | 69.5 | 56.7 | 32.2 | 63.8 |
여기서 솔직하게 짚어야 할 점은, Mellum 2가 모든 항목에서 1등을 하는 모델은 아니라는 것입니다. GPQA Diamond나 AIME 같은 일반 지식 및 고난도 수학 영역에서는 Qwen3.5 (9B)에 뚜렷이 뒤집니다. 대신 소프트웨어 엔지니어링의 핵심인 LiveCodeBench 코딩 벤치마크에서는 두 배 가까이 큰 모델들을 앞서고, JetBrains 내부 페어와이즈 평가에서도 가장 높은 승률을 기록합니다. 기술 보고서가 요약하는 Mellum 2의 위치는 분명합니다. 4B~14B 규모의 오픈 가중치 모델들과 견줄 만한 성능을 내면서도, 25억(2.5B) 밀집 모델 수준의 토큰당 연산량으로 동작한다 는 것입니다. JetBrains pairwise는 Qwen2.5-7B-Instruct를 상대로 한 내부 벤치마크 승률이며, AIME는 AIME 2025와 2026의 평균, BFCL v4는 다섯 개 하위 과제의 매크로 평균입니다.
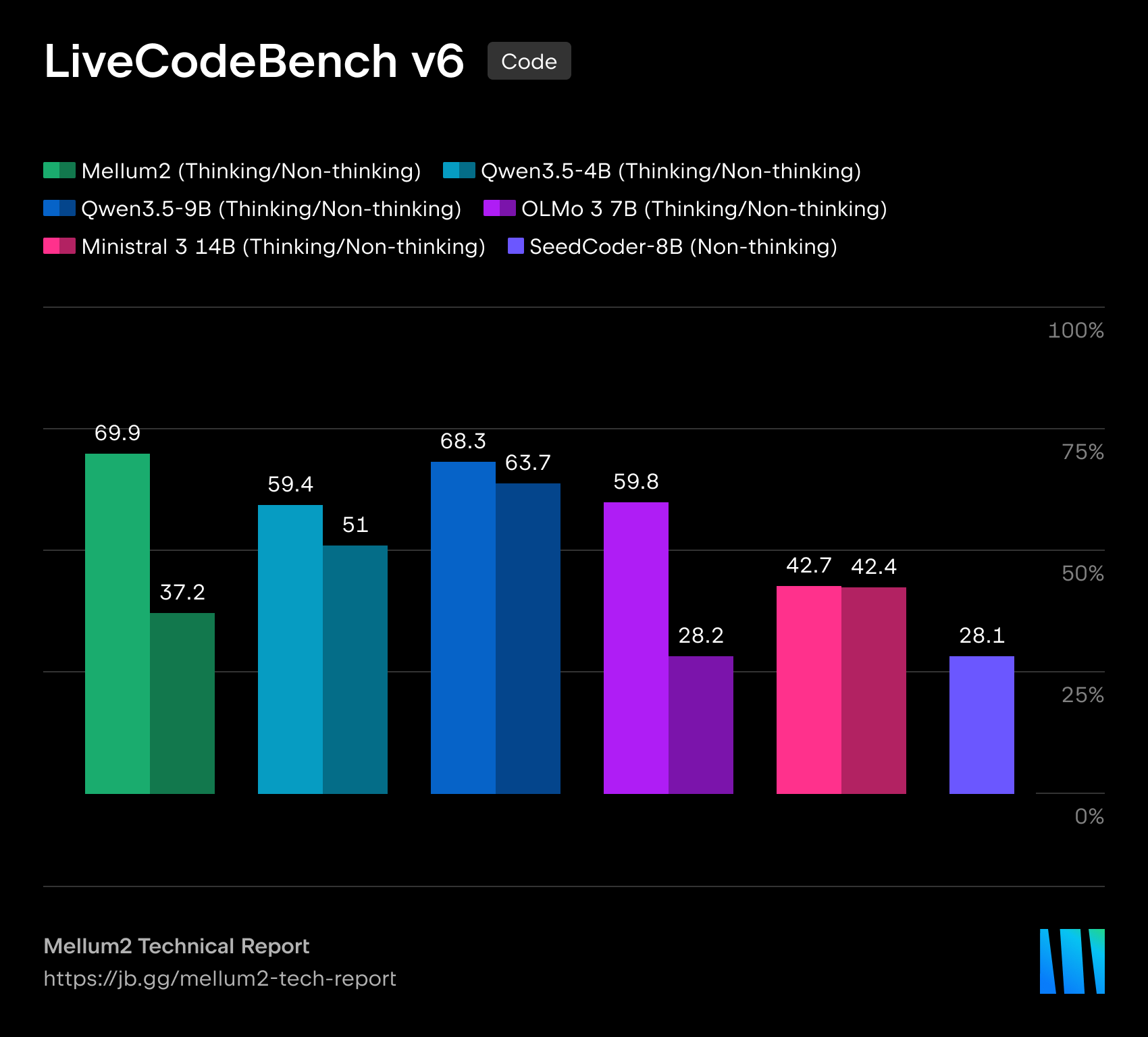
도구 사용을 평가하는 BFCL v4에서도 Mellum 2 Thinking은 45.6점으로 비교 모델 중 가장 높은 점수를 기록하며, 에이전트 워크플로에서 외부 도구를 호출하는 능력이 검증되었습니다.
한편 RL 단계가 성능을 어떻게 끌어올리는지도 데이터에서 확인됩니다. 수학 벤치마크 AIME에서 Thinking SFT 체크포인트는 20.0점에 그쳤지만, RLVR을 거친 최종 Thinking 모델은 58.4점까지 올라 추론 능력이 크게 향상되었습니다.
직접 응답 방식의 Instruct 변형은 추론을 노출하지 않는 대신 더 빠른 응답을 제공하며, EvalPlus(78.4), MultiPL-E(67.1) 같은 코드 생성 벤치마크와 GSM-Plus(80.5) 수학 과제에서 견고한 점수를 보여 라우팅이나 빠른 코드 생성 용도에 적합합니다.
Mellum 2의 주요 활용 사례
JetBrains는 Mellum 2를 단독으로 쓰는 거대 모델이 아니라, 여러 모델로 구성된 시스템 안에서 빈번하고 가벼운 작업을 빠르게 처리하는 구성 요소로 위치시킵니다. 블로그에서 제시한 대표적인 네 가지 활용 사례는 다음과 같습니다.
-
AI 워크로드 라우팅 및 오케스트레이션: 입력 프롬프트를 분석해 각 작업에 가장 적합한 모델이나 도구를 골라주는 라우터로 활용할 수 있습니다. 모든 요청을 비싼 프론티어 모델로 보내는 대신, 빠른 Mellum 2가 1차 분류를 담당합니다.
-
저지연 RAG 파이프라인 구축: 검색 증강 생성(Retrieval-Augmented Generation, RAG) 흐름에서 관련 컨텍스트를 검색한 뒤, Mellum 2로 이를 요약하고 즉시 응답을 생성해 전체 응답 지연을 줄일 수 있습니다.
-
복잡한 워크플로의 서브 에이전트(sub-agent): 에이전트 파이프라인을 컨텍스트 수집, 계획 수립, 검증 같은 단계로 쪼갠 뒤, 하나의 대형 모델에 모든 단계를 맡기는 대신 특화된 작업은 Mellum 2가 빠르게 처리하도록 분담할 수 있습니다.
-
프라이빗 로컬 AI 배포: 가중치가 완전히 공개되어 있으므로 Mellum 2를 로컬 환경에서 실행하거나 자체 호스팅하여 코드와 데이터를 외부로 내보내지 않고 완전히 통제할 수 있습니다.
이러한 활용 사례는 JetBrains의 Kotlin 기반 AI 에이전트 프레임워크인 Koog 같은 도구와 결합했을 때 특히 자연스럽게 맞물립니다.
'포컬 모델' 철학, 집중형 모델이 더 잘 확장되는 이유
Mellum 2의 설계 사상을 관통하는 개념이 바로 포컬 모델(focal model) 입니다. AI 시스템이 복잡해질수록 성능 병목의 중심이 순수한 모델 성능에서 대규모 환경에서의 지연 시간, 처리량, 비용 으로 옮겨가고 있다는 것이 JetBrains의 진단입니다. 최신 AI 시스템의 많은 단계는 반복적이고, 지연 시간에 민감하며, 높은 빈도로 수행됩니다. 이런 작업에까지 모든 것을 거대 모델에 맡길 필요는 없다는 것입니다.
JetBrains는 단일 모델이 아니라 서로 조율된 시스템(orchestrated system)이 미래 라고 봅니다. 프론티어 모델이 성능의 한계를 계속 넓혀가는 동안, 실용적인 AI 제품에는 빈번한 작업을 효율적으로 처리하는 빠르고 특화된 구성 요소, 즉 포컬 모델이 함께 필요하다는 관점입니다. Mellum 2는 바로 이 역할을 맡도록 만들어진 모델입니다. 이는 DeepSeek이 활성 파라미터를 최소화한 MoE 모델로 효율을 추구한 흐름과도 맞닿아 있는, 소형 특화 모델의 실용주의 노선이라 할 수 있습니다.
Mellum 2 시작하기
Mellum 2는 vLLM으로 손쉽게 서빙할 수 있습니다. Thinking 변형을 도구 호출과 함께 띄우는 예시는 다음과 같습니다. 추론 블록 파싱을 위해 qwen3 리즈닝 파서를, 도구 호출 파싱을 위해 hermes 파서를 지정합니다.
# With tool calling
vllm serve JetBrains/Mellum2-12B-A2.5B-Thinking \
--max-model-len 131072 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser hermes
서버가 뜬 뒤에는 OpenAI 호환 API로 그대로 호출할 수 있어, 기존 OpenAI Python SDK 코드를 거의 수정 없이 재사용할 수 있습니다.
from openai import OpenAI
# Configured by environment variables
client = OpenAI()
messages = [
{"role": "user", "content": "Is 1024 a power of 2? Explain your reasoning."},
]
chat_response = client.chat.completions.create(
model="JetBrains/Mellum2-12B-A2.5B-Thinking",
messages=messages,
max_tokens=81920,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
},
)
print("Chat response:", chat_response)
직접 응답이 필요하면 모델 이름을 JetBrains/Mellum2-12B-A2.5B-Instruct로 바꾸고 리즈닝 파서 옵션을 빼면 됩니다.
라이선스
Mellum 2 패밀리는 Apache License 2.0으로 배포되고 있어, 연구 목적은 물론 상업적 용도로도 자유롭게 사용 및 수정이 가능합니다. 베이스 모델부터 SFT, RL 체크포인트까지 모든 단계의 가중치가 공개되어 있어, 자체 데이터로 다시 미세조정하거나 파이프라인에 통합하기에도 제약이 적습니다.
 Mellum 2 오픈소스 공개 블로그
Mellum 2 오픈소스 공개 블로그
 Mellum 2 Hugging Face 컬렉션
Mellum 2 Hugging Face 컬렉션
더 읽어보기
-
DeepSeek, 100만 토큰 컨텍스트를 효율적으로 지원하는 MoE 모델 DeepSeek-V4-Pro 및 DeepSeek-V4-Flash 공개
-
Awesome AI Coding Tools: 개발자를 위한 100여가지 AI 코딩 도구 소개 목록 (feat. AI for Developers)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()