E5-V 소개
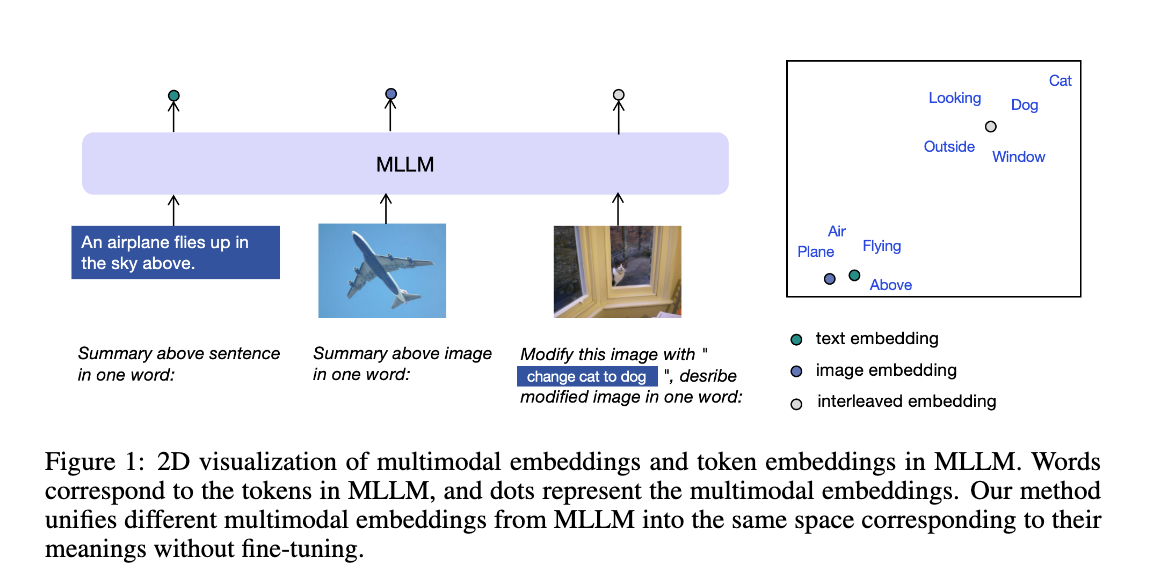
E5-V는 멀티모달 대규모 언어 모델(MLLM, Multimodal Large Language Models)을 사용하여 다양한 모달리티의 입력을 통합하는 멀티모달 임베딩 프레임워크입니다. E5-V는 다양한 입력 유형 간의 모달리티 간극(Modality Gap)을 효과적으로 줄이며, 파인튜닝 없이도 강력한 멀티모달 임베딩 성능을 보여줍니다. 또한, E5-V는 텍스트 쌍에만 학습을 시킬 수 있는 단일 모달리티 학습 접근 방식을 제안하여 더 나은 성능을 보여줍니다.
기존의 CLIP 모델은 텍스트와 이미지 간의 대조적 학습을 통해 우수한 성능을 보여주지만, 복합적인 텍스트와 시각적 입력을 효과적으로 표현하는 데 어려움을 겪습니다. CLIP 모델은 복잡한 텍스트를 이해하는 능력이 부족하며, 긴 텍스트를 처리하는 데 한계가 있습니다. E5-V는 이러한 한계를 극복하기 위해, MLLM(Multimodal LLM)을 사용하여 멀티모달 입력을 효과적으로 표현하는 방법을 제안합니다. MLLM은 초기 학습 단계에서 시각적 및 언어적 입력을 통합하여 의미를 기반으로 멀티모달 정보를 표현할 수 있습니다.
E5-V 프레임워크는 SimCSE와 Alpaca-Lora를 기반으로 하여 개발되었습니다. 다양한 데이터셋에서의 평가와 학습 방법을 제공하여 사용자들이 직접 E5-V를 활용할 수 있도록 지원합니다. 또한, 텍스트와 이미지를 동시에 처리할 수 있는 예제 코드와 함께, 성능 평가 및 학습 방법에 대한 자세한 설명을 포함하고 있습니다.
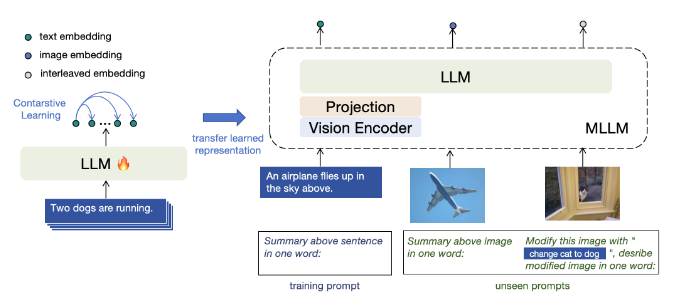
E5-V는 기존의 멀티모달 모델들과 비교하여 다음과 같은 특징을 갖습니다:
- 모달리티 간 격차 해소: E5-V는 텍스트와 이미지 간의 모달리티 차이를 효과적으로 극복합니다.
- 단일 모달리티 학습: 텍스트 쌍만을 사용하여 멀티모달 학습보다 더 나은 성능을 보입니다.
- 범용 임베딩: 다양한 입력 형식을 통합하여 범용적인 임베딩을 제공합니다.
E5-V 주요 기여 및 특징
멀티모달 임베딩 통합(Unifying Multimodal Embeddings)
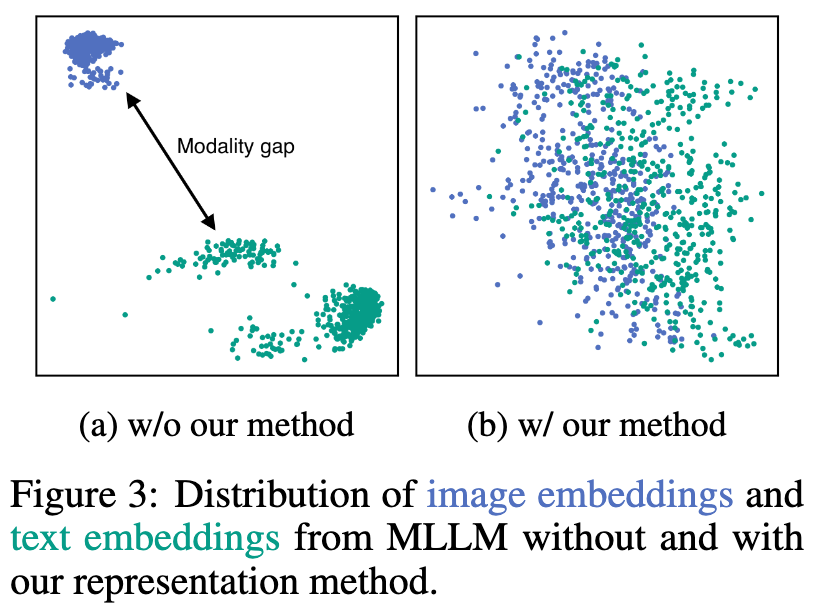
E5-V는 멀티모달 입력을 동일한 임베딩 공간으로 통합하여 모달리티 간극(Modality Gap)을 제거합니다. 이를 위해 프롬프트 기반의 표현 방법을 사용하여 MLLM(Multimodal LLM)이 멀티모달 입력을 단어로 표현하도록 명시적으로 지시합니다. 예를 들어, 텍스트에 대한 프롬프트는 *" \n 위 문장의 요약: 한 단어로 표현:"*과 같이 설정됩니다. 이러한 프롬프트는 텍스트와 이미지 임베딩 간의 모달리티 간극(Modality Gap)을 직접적으로 제거합니다.
멀티모달 임베딩 통합을 통해 MLLM은 단일 모달리티 학습만으로도 강력한 멀티모달 임베딩 성능을 발휘할 수 있습니다. 이는 비용이 많이 드는 멀티모달 학습 데이터 수집의 필요성을 제거합니다. 텍스트 데이터에만 집중하여 시각적 인코더와 같은 다른 구성 요소를 제거함으로써 입력 크기를 줄이고 학습 비용을 크게 절감할 수 있습니다.
E5-V는 다양한 작업에서 탁월한 성능을 보여줍니다. 텍스트-이미지 검색, 복합 이미지 검색, 문장 임베딩, 이미지-이미지 검색 등의 작업에서 E5-V는 경쟁력 있는 성능을 발휘합니다. 특히, 단일 모달리티 학습을 통해 멀티모달 입력을 더 효과적으로 표현할 수 있습니다. 이러한 접근법은 파인튜닝 없이도 높은 성능을 유지하며, E5-V의 주요 기여는 MLLM을 활용한 유니버설 멀티모달 임베딩을 달성하는 것입니다.
단일 모달리티 학습(Single Modality Training)
E5-V는 단일 모달리티 학습을 통해 멀티모달 임베딩을 달성합니다. 단일 모달리티 학습은 텍스트 쌍을 사용하여 대조적 학습을 수행하며, 시각적 입력을 사용하지 않습니다. 이를 통해 시각적 인코더와 프로젝터를 제거하고 LLM만 남겨둡니다. 학습 데이터로는 NLI 데이터셋의 문장 쌍을 사용하며, 이 데이터셋은 멀티모달 작업과는 관련이 없습니다.
단일 모달리티 학습은 학습 비용을 크게 절감합니다. 텍스트 쌍만을 사용하여 학습함으로써 입력 크기를 줄이고 시각적 인코더를 제거할 수 있습니다. 이에 따라 학습 시간도 크게 단축됩니다. 예를 들어, 단일 모달리티 학습은 32 V100 GPU를 사용하여 1.5시간이 소요되는 반면, 멀티모달 학습은 동일한 환경에서 34.9시간이 소요됩니다.
E5-V는 단일 모달리티 학습을 통해 멀티모달 임베딩을 효과적으로 수행합니다. 텍스트 쌍만을 사용하여 학습함으로써 멀티모달 입력을 더 효과적으로 표현할 수 있습니다. 이는 멀티모달 학습보다 더 나은 성능을 발휘하며, 학습 비용을 크게 절감할 수 있습니다. E5-V는 다양한 작업에서 탁월한 성능을 보여줍니다.
주요 특징
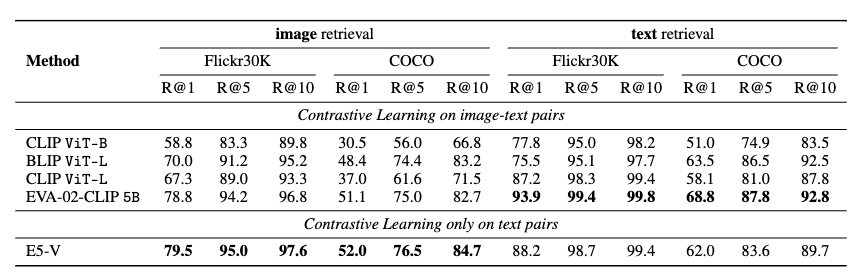
E5-V는 텍스트-이미지 검색, 복합 이미지 검색, 문장 임베딩, 이미지-이미지 검색 등의 다양한 작업에서 기존 모델을 능가하는 성능을 보입니다:
-
멀티모달 임베딩: 텍스트와 이미지 간의 모달리티 격차를 효과적으로 극복합니다.
-
단일 모달리티 학습: 텍스트 쌍만을 사용한 학습으로 멀티모달 학습보다 더 나은 성능을 보입니다.
-
강력한 성능: 별도의 미세 조정 없이도 강력한 성능을 발휘합니다.
E5-V 예제 코드
아래 예제 코드는 E5-V 모델을 사용하여 텍스트와 이미지로부터 임베딩을 생성하고, 이들 간의 유사성을 계산하는 방법을 보여줍니다:
import torch
import torch.nn.functional as F
import requests
from PIL import Image
from transformers import AutoTokenizer
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
llama3_template = '<|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n \n'
processor = LlavaNextProcessor.from_pretrained('royokong/e5-v')
model = LlavaNextForConditionalGeneration.from_pretrained('royokong/e5-v', torch_dtype=torch.float16).cuda()
img_prompt = llama3_template.format('<image>\nSummary above image in one word: ')
text_prompt = llama3_template.format('<sent>\nSummary above sentence in one word: ')
urls = ['https://upload.wikimedia.org/wikipedia/commons/thumb/4/47/American_Eskimo_Dog.jpg/360px-American_Eskimo_Dog.jpg',
'https://upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Felis_catus-cat_on_snow.jpg/179px-Felis_catus-cat_on_snow.jpg']
images = [Image.open(requests.get(url, stream=True).raw) for url in urls]
texts = ['A dog sitting in the grass.',
'A cat standing in the snow.']
text_inputs = processor([text_prompt.replace('<sent>', text) for text in texts], return_tensors="pt", padding=True).to('cuda')
img_inputs = processor([img_prompt]*len(images), images, return_tensors="pt", padding=True).to('cuda')
with torch.no_grad():
text_embs = model(**text_inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
img_embs = model(**img_inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
text_embs = F.normalize(text_embs, dim=-1)
img_embs = F.normalize(img_embs, dim=-1)
print(text_embs @ img_embs.t())
위 예제 코드는 다음과 같이 동작합니다:
-
LlavaNextProcessor와LlavaNextForConditionalGeneration을 사용하여 모델과 프로세서를 초기화합니다. -
이미지와 텍스트를 불러와 임베딩을 생성합니다.
-
생성된 텍스트 임베딩과 이미지 임베딩 간의 유사성을 계산하여 출력합니다.
 E5-V 논문
E5-V 논문
 E5-V GitHub 저장소
E5-V GitHub 저장소
https://github.com/kongds/e5-v
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()