
Engram 소개
DeepSeek AI와 베이징 대학교(Peking University) 연구진이 공동으로 개발하여 발표한 Engram은 대규모 언어 모델(LLM)의 효율성을 극대화하기 위해 고안된 혁신적인 아키텍처 모듈입니다. 현재 대규모 언어 모델(LLM) 연구의 주류는 모델의 파라미터 크기를 키우되 연산량은 억제하는 MoE(Mixture-of-Experts) 방식, 즉, 조건부 연산(Conditional Computation) 에 집중되어 있습니다.
하지만 Engram 연구진은 기존 트랜스포머(Transformer) 구조가 지식이나 패턴을 단순히 조회(Lookup)하는 고유 기능이 결여되어 있다는 근본적인 문제에 주목했습니다. 이로 인해 모델은 단순한 사실이나 관용구를 기억해 내는 데에도 값비싼 신경망 연산을 수행하며 비효율적인 시뮬레이션을 해야만 했습니다.
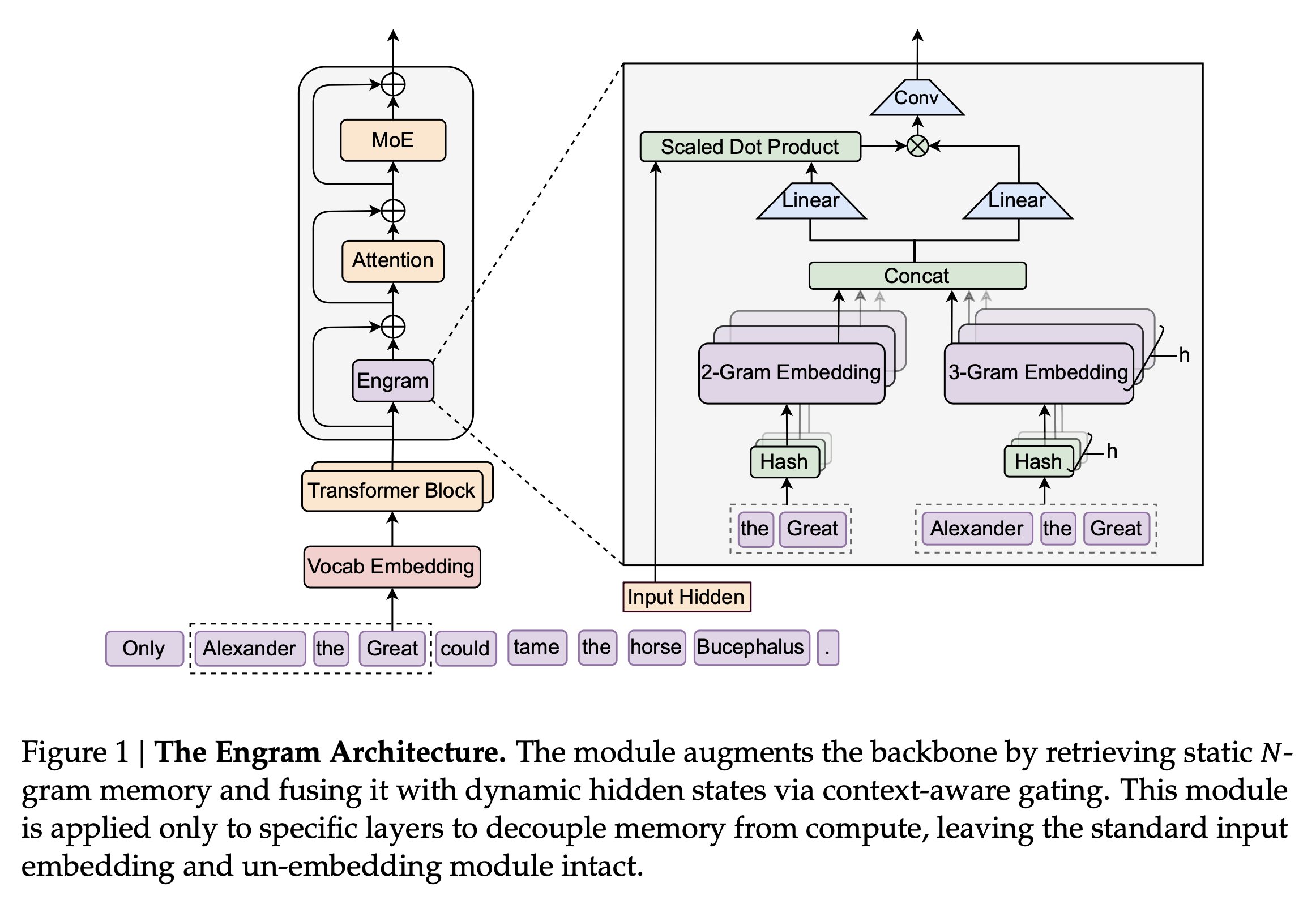
Engram은 이러한 문제를 해결하기 위해 조건부 메모리(Conditional Memory) 라는 새로운 희소성의 축(New Axis of Sparsity)을 제시합니다. 이 기술은 고전적인 자연어 처리 기법인 N-gram을 현대적인 신경망 아키텍처에 맞게 재해석하여, O(1) 의 시간 복잡도로 필요한 정보를 즉시 찾아낼 수 있는 메커니즘을 구현했습니다. 이를 통해 모델은 연산 자원을 낭비하지 않고도 방대한 정적 지식에 접근할 수 있게 되며, 남는 연산 능력은 더 복잡한 추론과 논리에 집중할 수 있게 됩니다.
MoE(조건부 연산)와 Engram(조건부 메모리)의 균형
Engram은 기존의 MoE(Mixture-of-Experts) 아키텍처를 대체하는 것이 아니라, MoE 구조와 상호 보완적인 관계에서 모델의 성능을 극대화하도록 설계되었습니다. MoE가 입력 토큰에 따라 필요한 전문가 네트워크(Expert Network)만 활성화하여 동적 논리(Dynamic Logic) 처리에 집중한다면, Engram은 입력된 텍스트 패턴에 매칭되는 정적 임베딩을 찾아내어 고정된 지식(Fixed Knowledge)을 제공하는 역할을 수행합니다.
Engram 연구진은 이 두 가지 희소성 메커니즘 사이의 최적 배분을 찾기 위해 희소성 할당(Sparsity Allocation) 문제를 정의하고 실험을 진행했습니다. 연구 결과, 총 파라미터와 연산량(FLOPs)이 고정된 상태에서, 순수하게 MoE만 사용하는 것보다 전체 희소 파라미터 예산의 약 20%~25% 가량을 Engram 메모리에 할당하고 나머지를 MoE에 할당했을 때 모델의 성능이 가장 뛰어난 U자형 스케일링 법칙(U-shaped Scaling Law) 이 발견되었습니다.
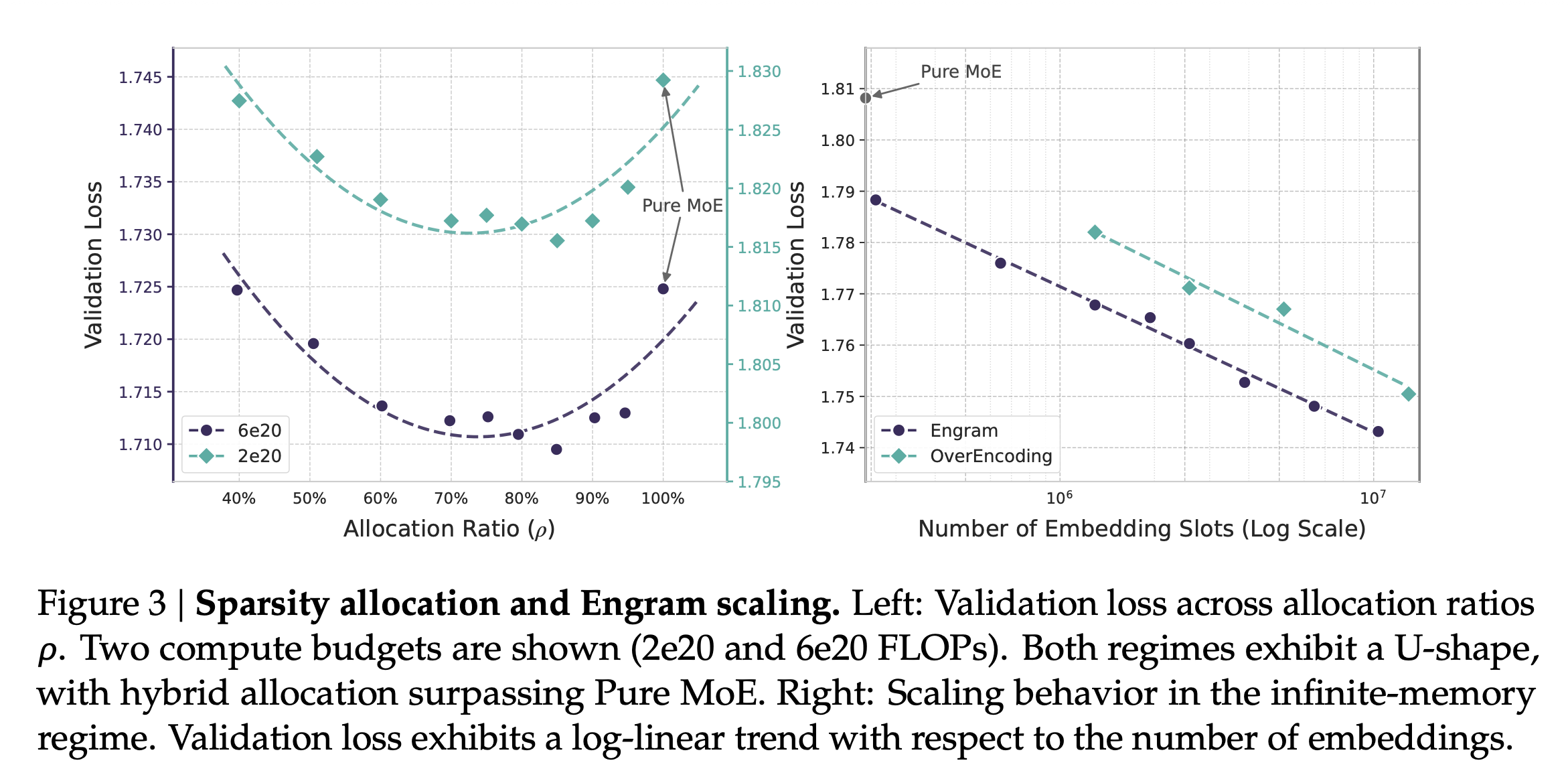
이러한 결과는 단순한 조회 메커니즘인 Engram이 모델의 핵심 구성 요소로서 신경망 연산과 조화를 이룰 때 비로소 강력한 시너지를 발휘함을 의미합니다.
Engram의 구조 및 동작
Engram 모듈은 트랜스포머 백본(Transformer Backbone) 내에 삽입되어 정적 패턴 저장소와 동적 연산을 구조적으로 분리합니다. 전체 프로세스는 크게 조회(Retrieval) 와 융합(Fusion) 의 두 단계로 나뉘며, 현대적인 최적화 기술들이 대거 적용되었습니다.
희소 조회 (Sparse Retrieval)와 토크나이저 압축
입력 시퀀스가 들어오면 Engram은 먼저 텍스트에서 연속된 N개의 토큰(N-gram)을 추출합니다. 이때 기존 토크나이저가 'Apple'과 'apple'을 서로 다른 ID로 처리하여 메모리를 낭비하는 문제를 해결하기 위해, 텍스트를 정규화(Normalization)하여 의미적으로 동일한 토큰들을 하나의 정규 ID(Canonical ID)로 매핑하는 토크나이저 압축(Tokenizer Compression) 기술을 적용했습니다. 이 과정을 통해 128k 크기의 어휘 집합에서 약 23%의 실질적인 어휘 공간 절감 효과를 얻었습니다.
압축된 N-gram은 거대한 임베딩 테이블(Embedding Table)에서 정보를 찾는 키(Key)로 사용됩니다. 그러나 모든 가능한 N-gram 조합을 저장하는 것은 불가능하므로, 연구진은 멀티 헤드 해싱(Multi-Head Hashing) 기법을 도입했습니다. 각 N-gram은 K 개의 서로 다른 해시 함수를 거쳐 임베딩 테이블의 인덱스로 변환되며, 이를 통해 충돌을 최소화하면서도 결정론적인 O(1) 조회를 수행합니다. 최종적으로 조회된 벡터들은 연결(Concatenation)되어 하나의 메모리 벡터 e_t 를 형성합니다.
문맥 인식 게이팅 (Context-Aware Gating)
단순히 조회된 정적 임베딩 e_t 는 현재 문맥과 무관한 정보이거나 해시 충돌로 인한 노이즈를 포함할 수 있습니다. 이를 해결하기 위해 Engram은 어텐션 메커니즘에서 영감을 받은 문맥 인식 게이팅을 수행합니다.
현재 시점의 히든 스테이트 h_t 가 Query 역할을 하고, 조회된 메모리 $e_t$가 Key 와 Value 역할을 하여 게이팅 스칼라 값 $\alpha_t$를 계산합니다.
이 수식에 따라, 만약 조회된 메모리가 현재 문맥()과 의미적으로 일치하지 않으면 값은 0에 수렴하여 노이즈를 차단합니다. 반대로 문맥에 적합한 정보라면 강하게 활성화되어 모델에 통합됩니다.
마지막으로, 깊이별 합성곱(Depthwise Convolution)을 통해 지역적인 수용 영역(Receptive Field)을 넓히고 비선형성을 강화한 뒤 잔차 연결(Residual Connection)을 통해 백본에 더해집니다.
Engram 성능 평가 및 주요 성과
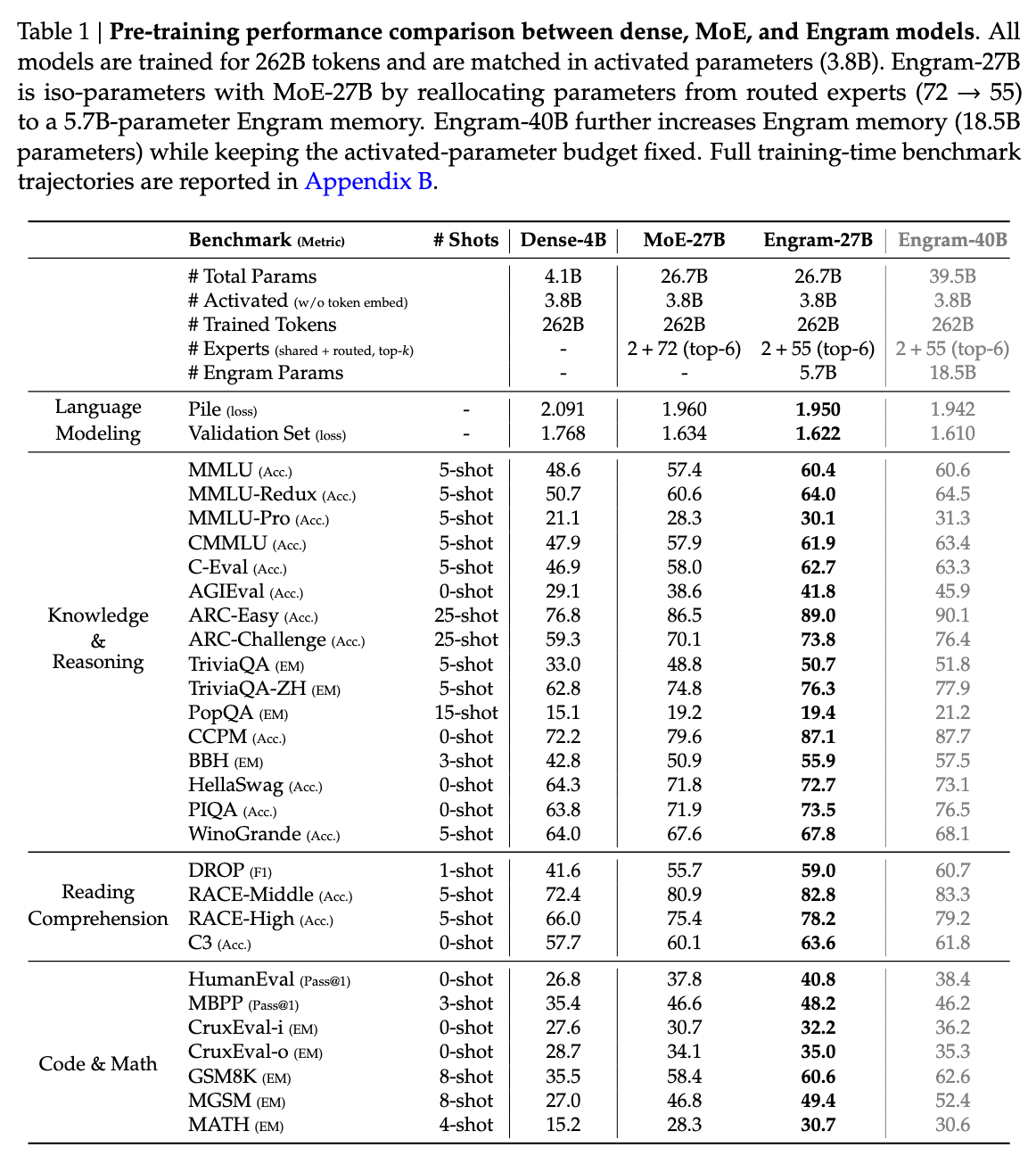
Engram 연구진은 262B 토큰 규모의 데이터셋으로 학습한 27B 규모의 모델을 구축하여 성능을 검증했습니다. 공정한 비교를 위해 베이스라인 모델인 MoE-27B와 파라미터 수 및 연산량(Iso-FLOPs)을 엄격하게 통제했습니다.
실험 결과, Engram-27B는 지식 집약적인 벤치마크인 MMLU(+3.0점), CMMLU(+4.0점)에서 예상대로 우수한 성능을 보였습니다. 더 놀라운 점은, 단순히 지식을 기억하는 것을 넘어 일반적인 추론 능력을 평가하는 BBH(+5.0점), ARC-Challenge(+3.7점)와 코딩 및 수학 능력을 평가하는 HumanEval(+3.0점), MATH(+2.4점) 벤치마크에서도 MoE 베이스라인을 크게 앞섰다는 것입니다.
이러한 벤치마크 결과는 Engram이 단순 암기 도구가 아니라 모델의 전반적인 지능을 향상시키는 데 기여함을 시사합니다.
메커니즘 분석: 유효 깊이의 증가
Engram의 성능 향상의 원인을 규명하기 위해 연구진은 LogitLens와 CKA(Centered Kernel Alignment) 분석을 수행했습니다. 분석 결과, 일반적인 LLM은 초반 레이어에서 'Diana'와 'Princess'를 조합하여 'Diana, Princess of Wales'라는 개체를 인식하는 식의 단순한 특성 조합(Feature Composition)에 많은 연산력을 소모합니다.
반면 Engram 모델은 이러한 정적 패턴 재구성을 Engram 모듈이 대신 처리해 줌으로써, 모델의 초기 레이어부터 정답에 가까운 예측을 내놓는 등 예측 수렴 속도가 빨라졌습니다.
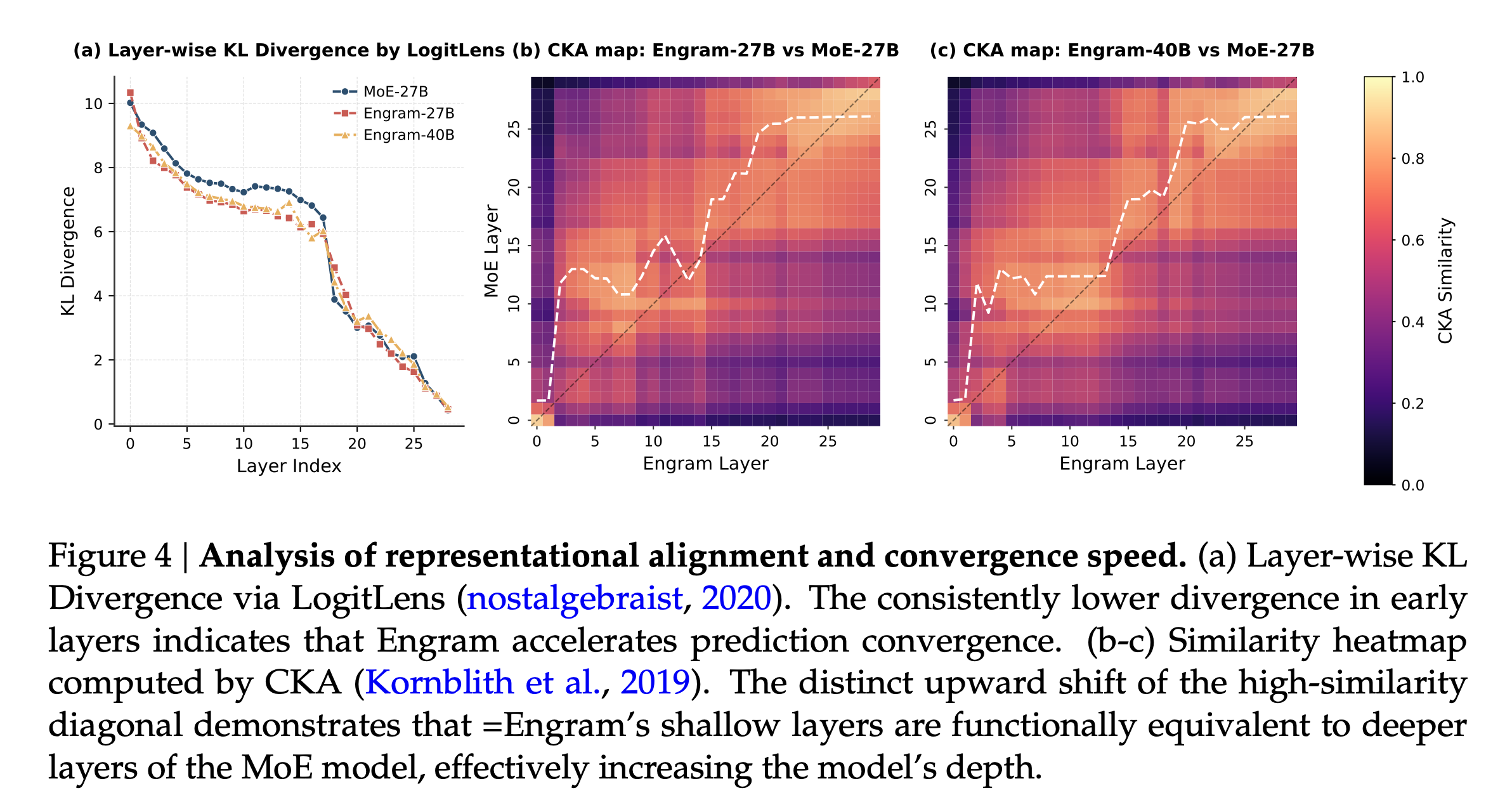
특히 CKA 유사도 히트맵(Similarity Heatmap)을 분석해 보면, Engram 모델의 5번째 레이어가 MoE 모델의 12번째 레이어와 유사한 표현(Representation)을 갖는 것으로 나타났습니다.
이는 Engram이 모델의 유효 깊이(Effective Depth) 를 실질적으로 증가시켜, 모델이 더 깊은 레이어를 복잡한 추론과 고차원적인 사고에 온전히 할애할 수 있게 만들었음을 증명합니다.
긴 문맥(Long Context) 처리 능력
Engram의 구조적 이점은 긴 문맥을 처리할 때 더욱 빛을 발합니다. 국소적인 단어 패턴이나 의존성 처리를 Engram이 전담하게 되면서, 트랜스포머의 어텐션 메커니즘은 전체 문맥을 아우르는 전역적인 정보(Global Context) 처리에 집중할 수 있게 됩니다.
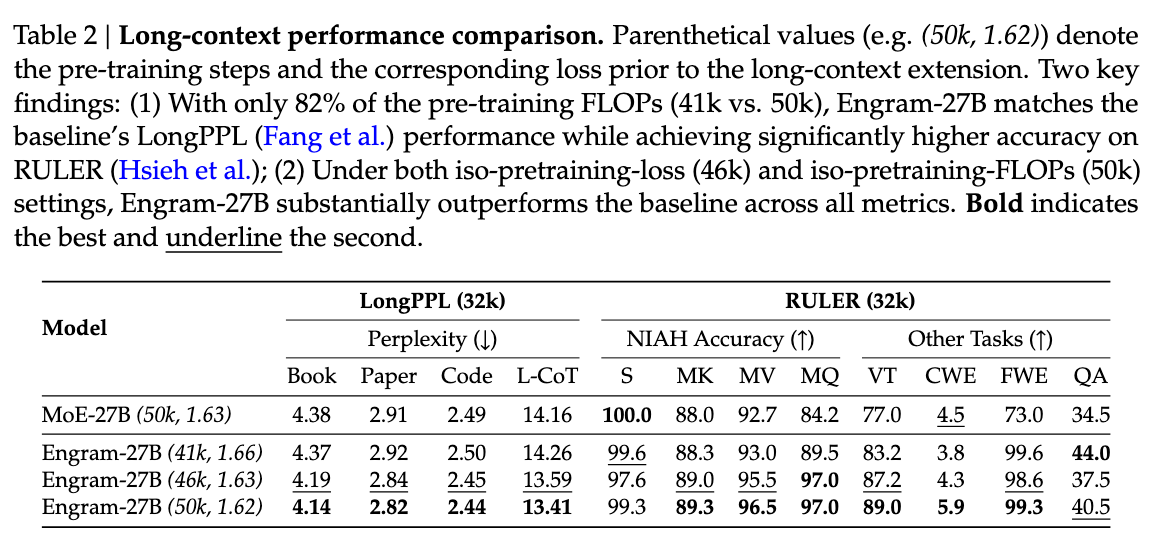
32k 길이의 긴 문맥 훈련(Long Context Extension) 실험에서, Engram-27B는 Multi-Query NIAH(Needle In A Haystack) 테스트 정확도를 베이스라인의 84.2%에서 97.0%로, Variable Tracking 점수를 77.0%에서 89.0%로 끌어올리는 성능 향상을 기록했습니다.
이는 Engram이 단순히 메모리를 늘리는 것을 넘어, 제한된 어텐션 용량을 가장 중요한 정보 처리에 사용할 수 있도록 최적화해 준다는 것을 보여줍니다.
시스템 효율성: 인프라 인식 설계
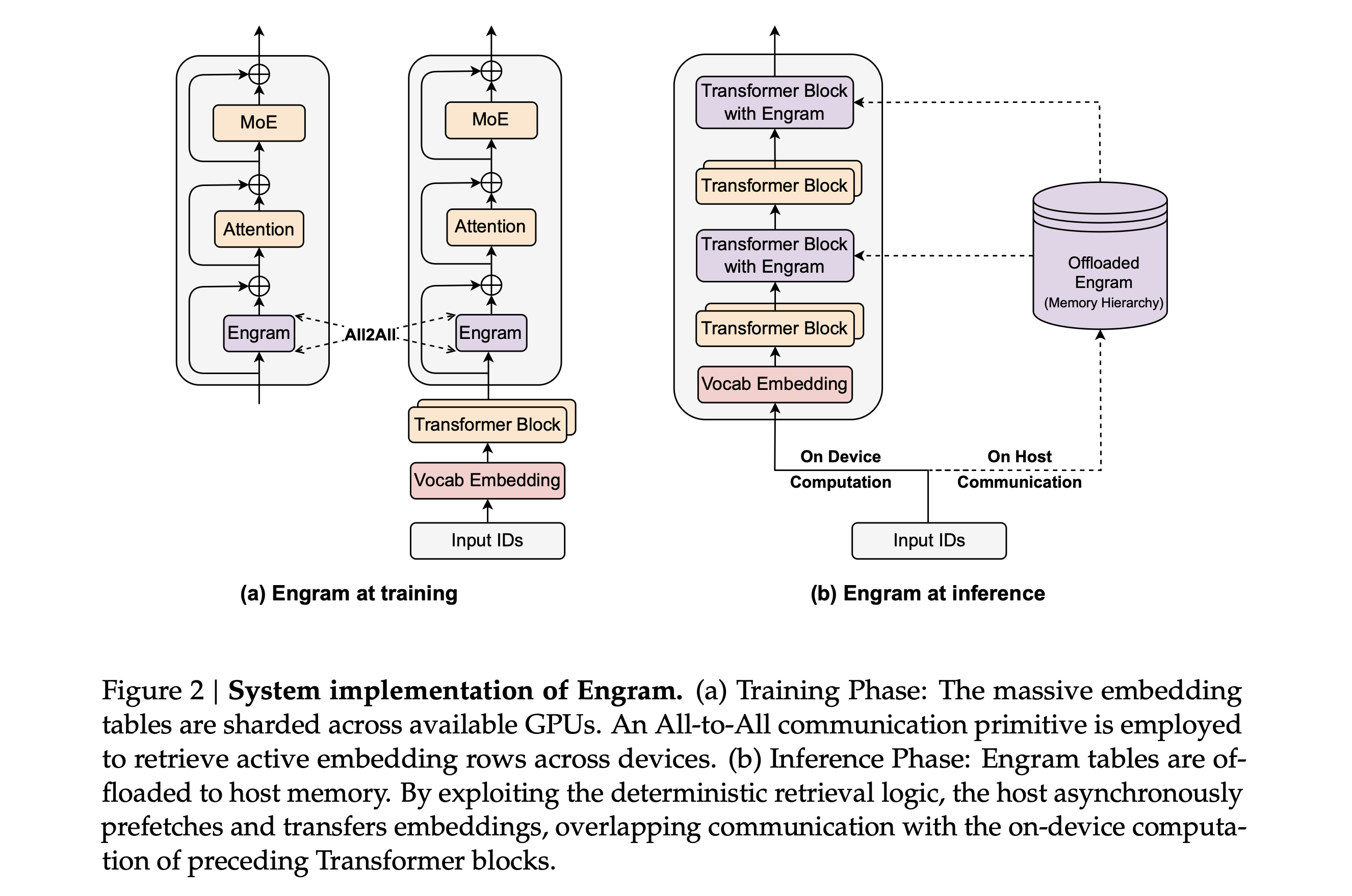
Engram은 시스템 관점에서도 매우 효율적으로 설계되었습니다. MoE의 라우팅이 런타임에 결정되는 동적인 과정인 것과 달리, Engram의 주소 지정은 입력 토큰만 알면 미리 알 수 있는 결정론적(Deterministic) 특성을 가집니다.
이러한 특징은 실제 추론 시, GPU가 이전 레이어를 연산하는 동안 CPU가 호스트 메모리(RAM)에 저장된 거대한 임베딩 테이블에서 데이터를 미리 가져오는 프리페칭(Prefetching) 과 오프로딩(Offloading) 을 가능하게 합니다.
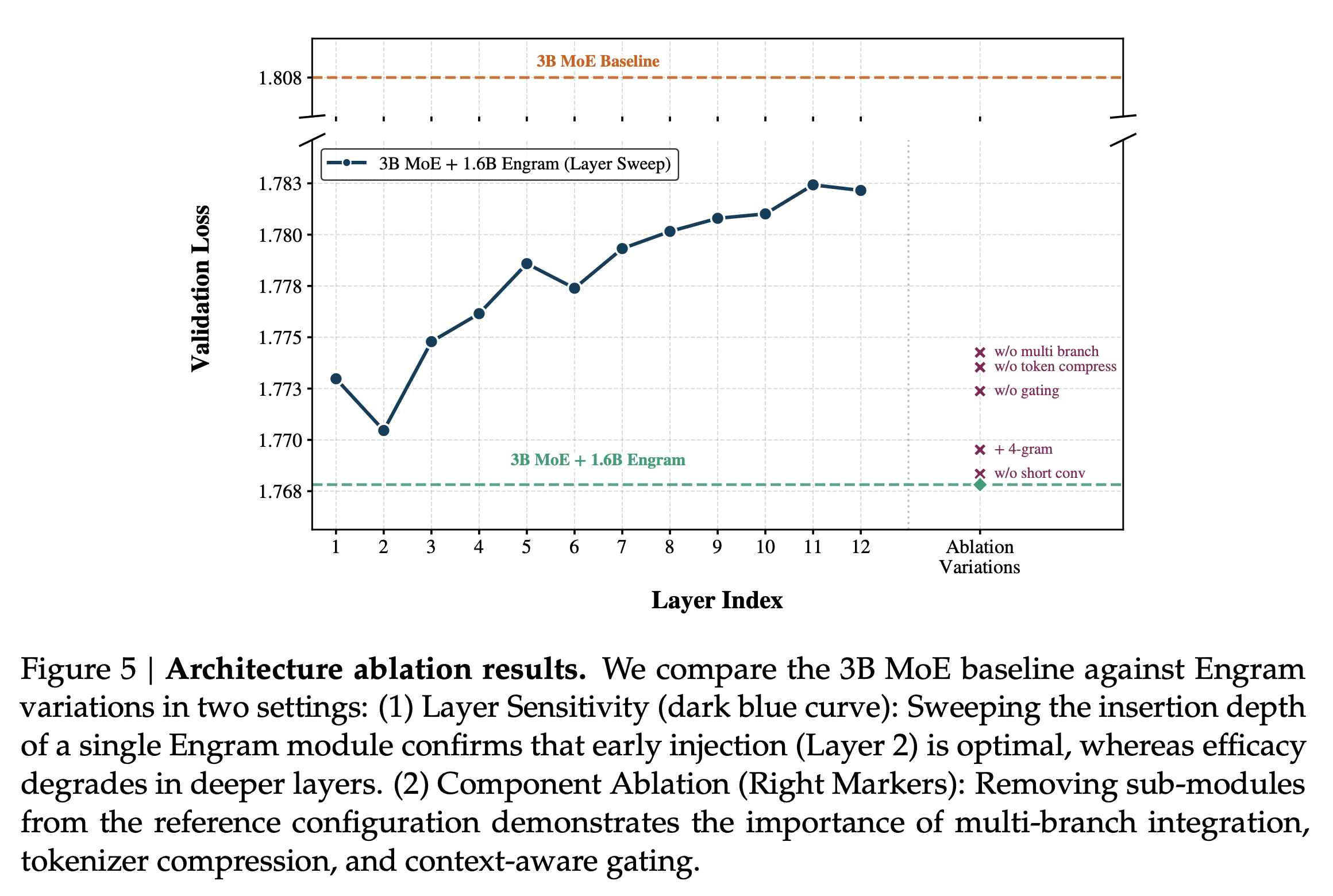
실제 실험에서 100B 파라미터 규모의 임베딩 테이블(Embedding Table)을 전적으로 호스트 메모리에 두고 오프로딩 방식을 사용했음에도 불구하고, 추론 처리량(Throughput) 저하는 3% 미만 에 불과했습니다. 이는 값비싼 GPU 메모리(HBM)의 제약 없이 모델의 파라미터 사이즈를 수천억, 수조 단위로 확장할 수 있는 현실적인 길을 열어준 것입니다.
Engram GitHub 저장소
DeepSeek-AI 및 베이징 대학교의 연구진들은 GitHub에 Engram의 소스코드를 공개하였습니다. 이 저장소에는 연구 논문 원본(Engram_paper.pdf)과 함께, O(1) 속도의 N-gram 조회 및 문맥 인식 게이팅(Gating) 과정이 실제로 어떻게 작동하는지 데이터 흐름을 통해 파악할 수 있는 Engram 데모 코드(engram_demo_v1.py)가 포함되어 있습니다.
전체 모델의 학습 파이프라인 대신 아키텍처의 핵심 로직을 이해하기 쉬운 독립형 스크립트 형태로 제공하며, 소스 코드는 Apache 2.0 라이선스 하에 배포되어 개발자들이 자유롭게 분석하고 실험해 볼 수 있습니다.
다만, GitHub 저장소 README 문서에는 "Engram 모델의 사용은 모델 라이선스를 따른다(The use of Engram models is subject to the Model License)"라고 명시되어 있습니다 . 이는 향후 공개될 수 있는 학습된 모델 가중치(Weights)에는 코드와 다른 별도의 라이선스 정책이 적용될 수 있음을 의미하므로, 모델 사용 시 주의가 필요합니다.
 Engram 논문: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Engram 논문: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
 Engram 프로젝트 GitHub 저장소
Engram 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()