Attention Residuals 소개
트랜스포머(Transformer) 아키텍처의 핵심 구성 요소 중 하나인 잔차 연결(Residual Connection)은 딥러닝의 깊이 문제를 해결하기 위해 도입된 기법입니다. 그러나 표준 잔차 연결은 이전 모든 레이어 출력에 균등한 가중치(단위 가중치)를 적용하는 단순한 방식이라, 모델이 깊어질수록 은닉 상태의 크기가 무한정 커지는 'PreNorm 희석(PreNorm dilution)' 문제가 발생합니다. MoonshotAI(Kimi 개발사)의 연구팀이 공개한 Attention Residuals(AttnRes)는 이 고정된 잔차 연결을 학습된 어텐션(Attention) 메커니즘으로 대체하는 새로운 접근법입니다. arXiv에 공개된 논문(2603.15031)과 함께 공식 구현 코드가 GitHub에 공개되어 있습니다.
AttnRes의 핵심 아이디어는 각 레이어가 이전의 모든 레이어 출력을 균등하게 누적하는 대신, 소프트맥스(softmax) 어텐션을 통해 이전 표현들을 선택적으로 집계(aggregate)한다는 것입니다. 각 레이어는 "학습된 단일 의사 쿼리(single learned pseudo-query per layer)"를 사용하여 어떤 이전 레이어의 표현을 얼마나 참고할지를 콘텐츠에 따라 동적으로 결정합니다. 이는 입력에 따라 레이어 깊이 방향으로 선택적이고 내용 인식적인(content-aware) 접근을 가능하게 합니다. 특히 다단계 추론이나 코드 생성처럼 레이어 간 깊은 통합이 필요한 작업에서 큰 이점을 보입니다.
Attention Residuals의 구조 및 동작 방식
현대의 대규모 언어 모델(LLM)에서는 프리노름(PreNorm)을 적용한 잔차 연결(Residual connections)이 표준으로 사용되지만, 이는 고정된 단위 가중치를 사용하여 모든 레이어의 출력을 누적합니다. 이러한 균일한 집합(uniform aggregation)은 깊이가 깊어짐에 따라 은닉 상태(hidden-state)의 크기를 통제할 수 없이 증가시키고, 점진적으로 각 레이어의 기여도를 희석시킵니다.
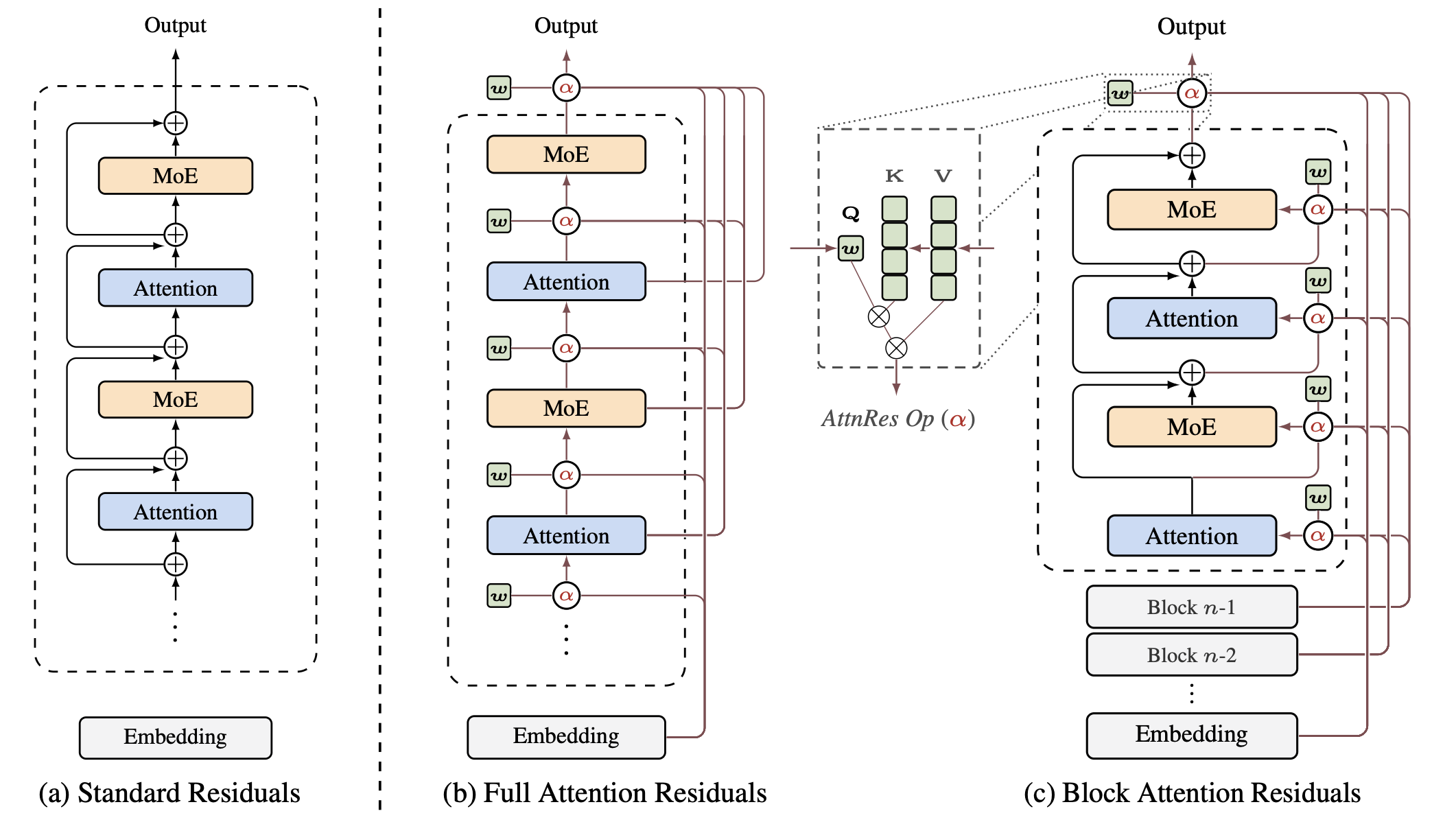
Attention Residuals(AttnRes)는 이러한 고정된 누적 방식을 이전 레이어 출력들에 대한 소프트맥스 어텐션(softmax attention)으로 대체합니다:
-
선택적 집합 (Selective Aggregation) : 각 레이어가 학습 가능하고 입력에 의존적인 가중치(learned, input-dependent weights)를 통해 이전 표현(earlier representations)들을 선택적으로 모을 수 있게 합니다.
-
의사 쿼리 (Pseudo-query) : 이 가중치는 각 레이어당 하나의 학습된 단일 의사 쿼리 벡터 $w_l \in \mathbb{R}^d$를 통해 계산됩니다.
AttnRes의 두 가지 변형: Full AttnRes와 Block AttnRes
Attention Residuals(AttnRes) 는 학습 규모에 따라 (1) 모든 이전 레이어를 대상으로 어텐션을 수행하는 전체 어텐션 잔차 모델(Full AttnRes) 과 (2) 연산 효율성을 위해 레이어들을 여러 블록으로 묶어 블록 단위로 어텐션을 수행하는 블록 어텐션 레지듀얼(Block AttnRes) 의 두 가지 구조를 제안합니다:
전체 어텐션 잔차 (Full AttnRes) 는 각 레이어가 학습된 어텐션 가중치를 통해 이전의 모든 레이어 출력을 선택적으로 적용하는 방식으로 동작합니다. 표현력은 최대화되지만, 하지만 이 방식은 대규모 모델 학습 시 모든 이전 레이어 출력을 어텐션의 대상으로 삼아야 하므로 메모리와 통신 오버헤드가 발생합니다. 즉, 레이어 수 L, 은닉 차원 d 에 대해서 O(Ld) 의 메모리 요구량이 발생합니다.
블록 어텐션 잔차 (Block AttnRes) 는 오버헤드 문제를 해결하기 위해 레이어들을 여러 블록(blocks)으로 분할하고, 블록 수준의 표현(block-level representations)에 대해서만 어텐션을 수행합니다. 블록 내에서는 단일 표현으로 축소되며, 블록 간 어텐션은 이 요약된 표현들에 적용됩니다. 이를 통해 메모리 요구량을 O(Ld) 에서 O(Nd) 로 대폭 줄어들게 됩니다. (N 은 블록의 수)
여러 실험 결과, 최적 블록 수는 약 8개이며, 메모리 요구량을 O(Nd) 로 줄이면서도 Full AttnRes 성능의 대부분을 회복합니다. 연산 오버헤드가 미미하여 기존 트랜스포머 아키텍처의 drop-in 대체재로 사용할 수 있습니다.
Block AttnRes의 PyTorch 형태의 의사코드는 다음과 같습니다:
def block_attn_res(blocks: list[Tensor], partial_block: Tensor, proj: Linear, norm: RMSNorm) -> Tensor:
"""
블록 간 어텐션(Inter-block attention): 블록 표현(block reps) + 부분 합(partial sum)에 어텐션(attend)합니다.
blocks:
형태(shape) [B, T, D]의 N개 텐서(tensors): 각 이전 블록(previous block)에 대한 완료된 블록 표현(completed block representations)
partial_block:
[B, T, D]: 블록 내 부분 합(intra-block partial sum) (b_n^i)
"""
V = torch.stack(blocks + [partial_block]) # [N+1, B, T, D]
K = norm(V)
logits = torch.einsum('d, n b t d -> n b t', proj.weight.squeeze(), K)
h = torch.einsum('n b t, n b t d -> b t d', logits.softmax(0), V)
return h
def forward(self, blocks: list[Tensor], hidden_states: Tensor) -> tuple[list[Tensor], Tensor]:
partial_block = hidden_states
# 어텐션(attn) 전에 블록 어텐션 잔차(block attnres) 적용(apply)
# 블록(blocks)은 이미 토큰 임베딩(token embedding)을 포함(include)합니다
h = block_attn_res(blocks, partial_block, self.attn_res_proj, self.attn_res_norm)
# 블록 경계(block boundary)에 도달(reach)하면, 새로운 블록(new block) 시작(start)
# 블록 크기(block_size)는 ATTN + MLP를 계산(count)합니다; 각 트랜스포머 레이어(transformer layer)는 2를 갖습니다
if self.layer_number % (self.block_size // 2) == 0:
blocks.append(partial_block)
partial_block = None
# 셀프 어텐션 레이어(self-attention layer)
attn_out = self.attn(self.attn_norm(h))
partial_block = partial_block + attn_out if partial_block is not None else attn_out
# MLP 전에 블록 어텐션 잔차(block attnres) 적용(apply)
h = block_attn_res(blocks, partial_block, self.mlp_res_proj, self.mlp_res_norm)
# MLP 레이어(MLP layer)
mlp_out = self.mlp(self.mlp_norm(h))
partial_block = partial_block + mlp_out
return blocks, partial_block
벤치마크 결과
Block AttnRes는 동일한 연산량에서 1.25배 더 많은 연산으로 훈련한 기준 모델과 동등한 성능을 달성합니다. 이는 학습 효율 측면에서 상당한 개선입니다.
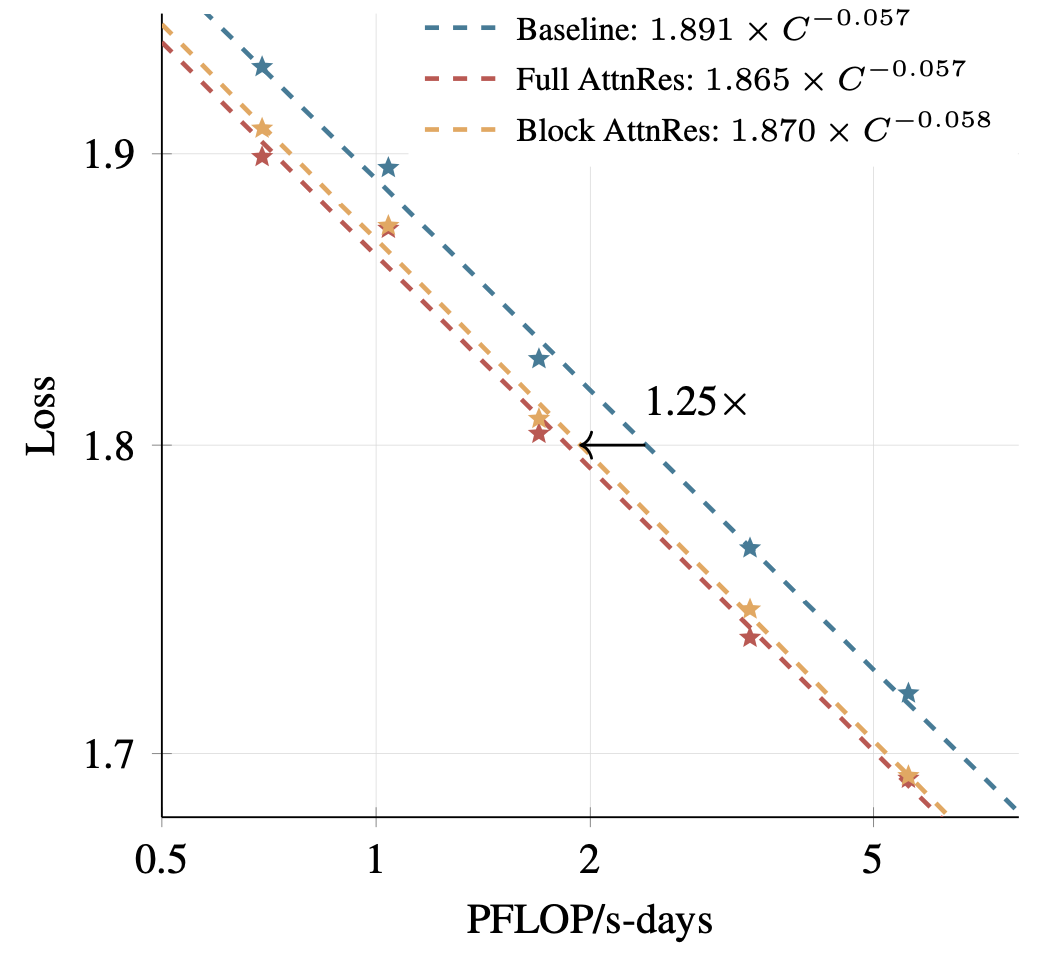
Kimi Linear 48B 모델을 기반으로 한 다운스트림 태스크 평가 결과는 다음과 같습니다:
| 벤치마크 | 기준 모델 | Block AttnRes | 개선 |
|---|---|---|---|
| GPQA-Diamond (추론) | 36.9 | 44.4 | +7.5점 |
| HumanEval (코드 생성) | 59.1 | 62.2 | +3.1점 |
| MMLU (지식) | 73.5 | 74.6 | +1.1점 |
다단계 추론(GPQA-Diamond)과 코드 생성(HumanEval)에서 가장 큰 향상이 관찰되었는데, 이는 AttnRes가 레이어 간 깊은 통합이 필요한 태스크에 특히 효과적임을 시사합니다.
Attention Residuals 설치 및 사용법
GitHub 저장소를 복제(Clone)하여 논문의 공식 구현 코드를 직접 사용할 수 있습니다:
git clone https://github.com/MoonshotAI/Attention-Residuals.git
cd Attention-Residuals
구체적인 설치 및 실행 방법은 저장소의 README 및 Attention Residuals 논문(2603.15031)을 참고하시기 바랍니다.
 Attention Residuals 논문
Attention Residuals 논문
 Attention Residuals 프로젝트 GitHub 저장소
Attention Residuals 프로젝트 GitHub 저장소
더 읽어보기
-
Engram: DeepSeek AI가 공개한 대규모 언어 모델을 위한 조건부 메모리(Conditional Memory) 아키텍처
-
flash-moe: 순수 C와 Metal로 구현한, M3 Max 맥북 프로에서 397B 파라미터 MoE 모델을 실행하는 고성능 추론 엔진
-
EPLB: MoE 모델에서 GPU들 간의 부하를 분배(Load Balancing)하는 라이브러리 (feat. DeepSeek)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()