
FLUX.2 소개
FLUX.2는 Black Forest Labs(BFL)가 2025년 11월 25일 새롭게 발표한 최첨단 텍스트-이미지 생성 AI 모델입니다. 2024년 8월, 뛰어난 성능으로 오픈소스 커뮤니티를 강타했던 FLUX.1의 공식 후속작으로, 이번 버전은 단순한 업그레이드를 넘어 320억(32B) 파라미터라는 거대한 규모와 새로운 아키텍처를 도입하여 '생성형 AI의 시각적 지능'을 한 단계 끌어올렸다는 평가를 받고 있습니다.

FLUX.2의 가장 큰 특징은 단순히 이미지 패턴을 학습하는 것을 넘어, Mistral-3 24B (Mistral-Small-3.2-24B-Instruct-2506) 비전-언어 모델(VLM)을 통합하여 세상에 대한 물리적, 공간적 이해를 바탕으로 이미지를 생성한다는 점입니다. 이로 인해 기존 모델들이 어려워했던 복잡한 조명, 물리 법칙, 그리고 텍스트 렌더링(Typography)에서 압도적인 성능 향상을 이루어냈습니다. 특히 'World Knowledge(세상에 대한 지식)'가 강화되어, 프롬프트의 미묘한 뉘앙스나 복잡한 공간적 배치를 훨씬 더 정확하게 반영합니다.
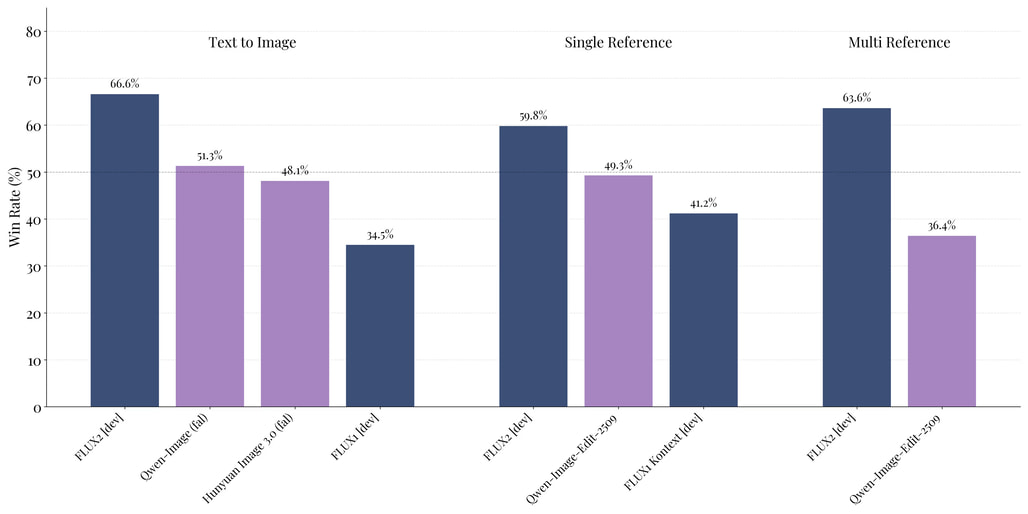
이 모델은 개발자와 기업이 실제 프로덕션 환경에서 사용할 수 있도록 설계되었습니다. 단순한 이미지 생성을 넘어, 최대 10장의 레퍼런스 이미지를 동시에 입력받아 캐릭터나 스타일의 일관성을 유지하는 '멀티 레퍼런스' 기능을 제공하며, JSON 형식의 구조화된 프롬프팅을 지원하여 개발자가 API를 통해 더욱 정밀하게 이미지를 제어할 수 있게 되었습니다.
FLUX.2를 주목해야 하는 이유는 명확합니다. 현재 존재하는 오픈 웨이트(Open Weights) 모델 중 가장 강력한 성능을 자랑하며, Midjourney나 DALL-E 3와 같은 폐쇄형 모델과 대등하거나 그 이상의 품질을 제공하면서도 개발자가 직접 커스터마이징하고 배포할 수 있는 자유를 주기 때문입니다. 다만, 32B라는 거대한 모델 크기로 인해 구동을 위해서는 상당한 VRAM(최적화 시 약 64GB)이 요구되어 하드웨어 진입 장벽이 다소 높아졌다는 점은 미리 고려해야 할 사항입니다.
이전 모델 및 경쟁 모델과의 간략한 비교
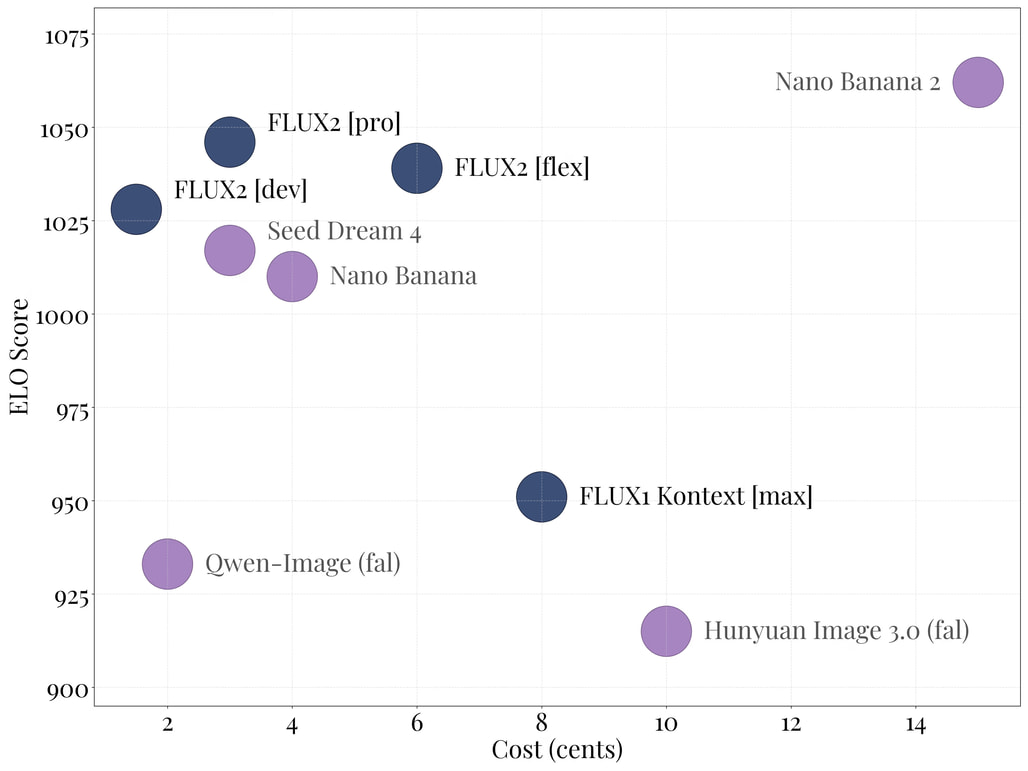
FLUX.1이 뛰어난 텍스트 묘사력과 인체 해부학적 정확성으로 호평받았다면, FLUX.2는 이해력과 제어력 측면에서 큰 도약을 이루었습니다. 기존 모델들이 단순히 텍스트 태그를 이미지로 매핑하는 느낌이었다면, FLUX.2는 내장된 대형 언어 모델(VLM) 덕분에 프롬프트의 복합적인 상황을 논리적으로 이해하고 그려냅니다.
| 비교 항목 | FLUX.2 (New) | FLUX.1 | 경쟁 모델 (Midjourney/SD3 등) |
|---|---|---|---|
| 파라미터 크기 | 32B (320억) | 12B (120억) | 다양함 (공개 안 됨 / 2B~8B) |
| 핵심 아키텍처 | VLM (Mistral-3 24B) + Flow Matching | Flow Matching Transformer | Diffusion Transformer (DiT) 등 |
| 텍스트 묘사 | 매우 우수 (UI, 인포그래픽 가능) | 우수 | 모델에 따라 상이함 |
| 일관성 유지 | 멀티 레퍼런스 (최대 10장) | LoRA 학습 필요 | 주로 단일 이미지 참조 |
| 하드웨어 요구 | 매우 높음 (H100/A100 급 권장) | 소비자용 GPU (24GB) 가능 | 클라우드 전용이 많음 |
FLUX.2의 주요 특징
혁신적인 아키텍처: VLM과 Flow Matching의 결합
FLUX.2는 기존의 확산(Diffusion) 모델 방식에서 한 걸음 더 나아갔습니다. 이미지 생성부에는 Rectified Flow Transformer를 사용하되, 텍스트와 이미지를 이해하는 인코더 부분에 Mistral-3 24B 파라미터 모델을 결합했습니다.
덕분에 FLUX.2는 기존의 CLIP이나 T5 인코더보다 훨씬 깊이 있는 언어 이해력을 가집니다. "빨간 공이 파란 상자 위에 있고, 그 상자는 거울 옆에 있다"와 같은 복잡한 공간 관계나 물리적 상호작용을 훨씬 더 사실적으로 묘사할 수 있게 되었습니다. 그 결과, 기존의 'AI스러운' 플라스틱 질감이 줄어들고, 사진과 구별하기 힘든 400만 화소(4MP) 급의 고해상도 이미지를 생성할 수 있게 되었습니다.
다양한 모델 라인업 (Variants)
![가변 스텝(variable steps)으로의 생성 결과: FLUX.2 [flex]는 '스텝(steps)' 매개변수(parameter)를 제공하며, 이는 타이포그래피 정확도(typography accuracy)와 지연 시간(latency)을 절충(trading off)합니다. 왼쪽에서 오른쪽으로: 6 스텝, 20 스텝, 50 스텝.](https://discuss.pytorch.kr/uploads/default/original/2X/2/2dc8dc2db92b38f796be39b592b47570254a7392.jpeg)
Generating designs with variable steps: FLUX.2 [flex] provides a “steps” parameter, trading off typography accuracy and latency. From left to right: 6 steps, 20 steps, 50 steps.
Black Forest Labs는 사용자의 목적에 맞춰 Flux.2의 4가지 변형 모델들을 함께 공개했습니다:
-
FLUX.2 [pro]: 최고의 성능을 제공하는 API 전용 모델로, 기존의 폐쇄형 모델(Closed Model)에 필적하는 최첨단 이미지 품질을 제공합니다. 가장 높은 디테일과 프롬프트 준수율을 보여줍니다. BFL Playground 및 BFL API 등을 통해 사용할 수 있습니다.
-
FLUX.2 [flex]: 다양한 모델 매개변수를 제어하여 품질, 프롬프트 준수(prompt adherence) 및 속도에 대한 완전한 제어권을 제공하는 모델입니다. 텍스트 및 미세한 세부 묘사 렌더링에 탁월하며, [pro] 모델과 같이 BFL Playground 및 BFL API 등을 통해 사용할 수 있습니다.
-
FLUX.2 [dev]: FLUX.2 기본 모델에서 파생된 32B 규모의 오픈 웨이트(Open Weights) 모델로, 텍스트-이미지 합성 및 다중 입력 이미지를 사용한 이미지 편집을 결합한, 현재 사용 가능한 가장 강력한 오픈 웨이트 이미지 생성 및 편집 모델입니다. Hugging Face에서 다운로드 가능하며, 비상업적 용도로 사용 가능합니다.
-
FLUX.2 [klein](출시 예정): FLUX.2 기본 모델에서 크기 증류된(size-distilled) 모델로, Apache 2.0 라이선스로 제공되는 가장 빠른 모델입니다. 동일한 크기의 비교 가능한 모델보다 더 강력하고 로컬 개발 및 개인 사용에 최적화되어 있으며, 속도가 빠르면서도 준수한 품질을 보여줍니다. 베타에 참여하기 위해서는 베타 참여 신청 양식을 작성해주세요.
-
FLUX.2 - VAE: 학습 용이성, 품질 및 압축률 사이의 최적화된 균형을 제공하는 잠재 표현(latent representations)을 위한 새로운 변분 오토인코더(VAE)입니다. 이 모델은 모든 FLUX.2 플로우 백본(flow backbones)의 기반을 제공하며, 기술적 특성을 설명하는 심층 보고서는 기술 블로그를 참고해주세요.
FLUX.2 모델은 다음과 같은 출시 파트너와 함께 출시되었습니다:

강력한 제어 기능: 멀티 레퍼런스와 JSON 프롬프팅

FLUX.2는 현업 디자이너와 개발자를 위한 강력한 제어 기능을 도입했습니다.
먼저 멀티 레퍼런스 (Multi-Reference) 기능을 살펴보면, FLUX.2 모델은 최대 10장의 이미지를 입력받아 특정 캐릭터의 얼굴, 제품의 외형, 스타일을 유지하면서 새로운 장면을 생성할 수 있습니다. 별도의 파인튜닝(Fine-tuning) 없이도 일관성 있는 자산을 생성할 수 있어 게임이나 웹툰 제작에 유용합니다.
또한, JSON 프롬프팅 기능을 도입하여, 사용자는 자연어뿐만 아니라 JSON 포맷의 구조화된 지시 또한 가능합니다. 예를 들어, 다음과 같은 JSON 프롬프팅이 가능합니다:
{
"scene": "cyberspace office",
"subject": {"type": "robot", "color": "silver"},
"camera": {"angle": "wide", "focal_length": "35mm"},
"lighting": "neon purples and blues"
}
위 예시와 같이 명시적으로 각 속성들을 정의할 수 있어, API를 통한 자동화 작업 시에 (기존 모델 대비) 훨씬 예측 가능한 결과를 얻을 수 있습니다.
심층 분석: 잠재 공간(Latent Space)과 표현력의 딜레마 해결
생성형 AI 모델의 성능은 이미지를 얼마나 효율적으로 압축하고 복원하느냐에 달려 있습니다. BFL 연구팀은 이번 FLUX.2 개발 과정에서 생성 모델의 잠재 표현(Latent Representation)이 직면하는 근본적인 세 가지 트레이드오프(Three-way Trade-off) 문제를 정의하고 이를 해결하는 데 집중했습니다.
생성 모델의 삼중 딜레마 (The Trilemma)
연구팀은 이상적인 잠재 공간을 설계하기 위해 다음 세 가지 요소 사이의 균형을 맞추는 것이 필수적이라고 설명합니다.
-
학습 용이성 (Learnability): 생성 모델이 새로운 샘플을 얼마나 쉽게 학습할 수 있는지에 대한 요소입니다. 이 때, 의미론적 공간이 잘 정립될수록 학습은 쉽지만, 디테일은 떨어질 수 있습니다.
-
재구성 품질 (Quality/Perceptual Distortion): 압축된 정보를 다시 이미지로 복원했을 때 원본과 얼마나 똑같은지에 대한 요소입니다. 압축률을 높이면 미세한 디테일이 뭉개지는 현상이 발생합니다.
-
압축률 (Compression Rate): 데이터를 얼마나 작게 줄일 수 있는지에 대한 요소입니다. 높은 압축률은 효율성을 높이지만 정보 손실을 유발합니다.
경쟁 모델과의 비교 (SD-VAE, RAE vs FLUX.2 AE)
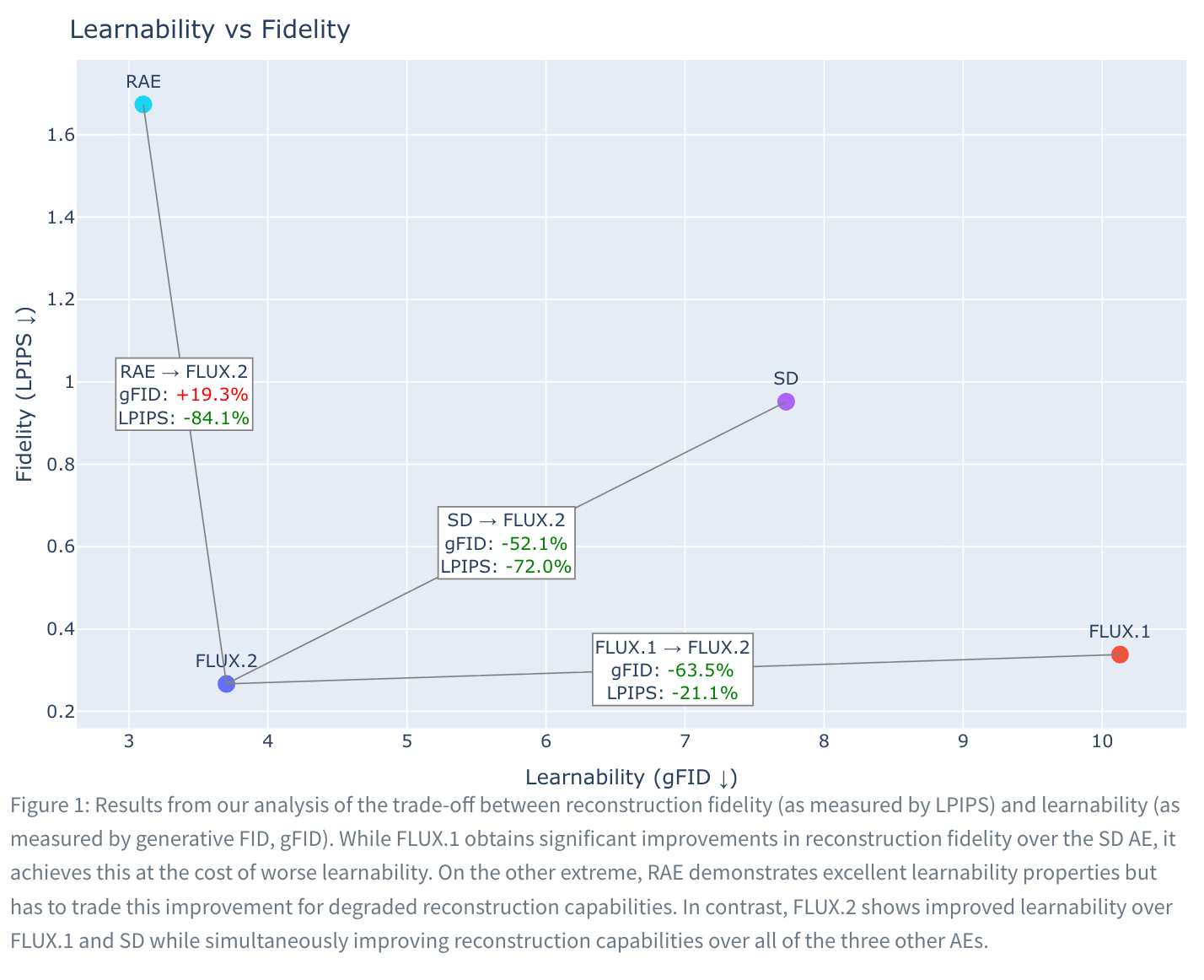
BFL은 기존의 Stable Diffusion에서 사용된 SD-VAE, 최근 학계에서 주목받는 RAE(Regularized AutoEncoder), 그리고 FLUX.1과 FLUX.2의 오토인코더(AE) 를 동일한 조건에서 비교 실험했습니다.
- RAE의 한계: RAE는 학습 용이성(Learnability) 측면에서는 뛰어난 모습을 보였으나, 이미지를 다시 복원하는 과정에서 재구성 품질(Reconstruction Quality)이 현저히 떨어지는 문제가 있었습니다.
- FLUX.2 AE의 혁신: 반면, FLUX.2의 새로운 오토인코더는 FLUX.1이나 SD-VAE보다 더 높은 학습 용이성을 가지면서도, 비교된 모든 모델 중 가장 뛰어난 재구성 품질을 기록했습니다. 즉, "학습하기 쉬우면서도 결과물은 가장 선명한" 균형점(Sweet Spot)을 찾아낸 것입니다.
실험 결과 및 검증
연구팀은 각기 다른 오토인코더의 잠재 공간 위에서 Flow Matching 모델을 학습시키는 방식으로 공정한 비교를 진행했습니다. 10만 스텝(100k steps)마다 모델을 샘플링하고, 고정된 50 Euler steps의 추론 환경에서 테스트한 결과, FLUX.2 AE가 가장 적절한 학습 시간 내에 최고의 화질을 생성함을 입증했습니다.
결론적으로 FLUX.2는 단순히 파라미터 수만 늘린 것이 아니라, 이미지 생성의 기초가 되는 '압축과 복원의 메커니즘' 자체를 재설계함으로써 고해상도 이미지에서도 텍스처가 뭉개지지 않고 살아있는 결과를 만들어냅니다.
이러한 잠재 공간(Latent Space) 설계에 대한 BFL의 더 상세한 내용은 아래 블로그 원문을 참고해주세요:
설치 및 사용법 (Python)
현재 공개된 FLUX.2 [dev] 모델은 diffusers 라이브러리를 통해 사용할 수 있습니다. (추후 [klein] 모델 공개 시 동일한 방식으로 지원될 것으로 예상됩니다.) 단, 32B 모델의 크기로 인해 실행 시 약 64GB 이상의 VRAM이 권장됩니다. 모델 규모가 상대적으로 크기 때문에 일반 소비자용 그래픽카드로는 구동이 매우 어렵거나, 양자화(Quantization) 및 CPU 오프로딩이 필수적입니다.
(GeForce RTX GPU와 같은 소비자용 GPU(consumer grade GPUs)에서는 NVIDIA 및 ComfyUI와 협력하여 제작된 최적화된 FP8 레퍼런스 구현의 FLUX.2 [dev]를 사용할 수 있습니다. 또한 FAL, Replicate, Runware, Verda, TogetherAI, Cloudflare, DeepInfra의 API 엔드포인트를 통해 Flux.2 [dev]를 샘플링할 수도 있습니다.)
설치 과정은 다음과 같습니다:
# diffusers 및 필요 라이브러리 설치
pip install -U diffusers transformers accelerate
# 또는, 공식 리포지토리 복제 후 직접 설치
git clone https://github.com/black-forest-labs/flux2
cd flux2
pip install -e ".[all]"
아래 예시와 같은 방식으로 Python 코드에서 직접 모델을 불러와 사용할 수 있습니다:
import torch
from diffusers import FluxPipeline
# FLUX.2 [dev] 로드 (bfloat16 사용 권장)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.2-dev",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload() # VRAM 절약을 위해 필수
prompt = "A futuristic city with flying cars, photorealistic, 8k, cinematic lighting"
image = pipe(
prompt,
height=1024,
width=1024,
guidance_scale=3.5,
num_inference_steps=50,
max_sequence_length=512,
generator=torch.Generator("cpu").manual_seed(42)
).images[0]
image.save("flux2_output.png")
라이선스
FLUX.2의 각 모델은 서로 다른 라이선스 정책을 따르고 있습니다:
FLUX.2 [klein] (출시 예정): Apache 2.0 License로 공개될 예정이며, 상업적 이용을 포함한 자유로운 사용이 가능합니다.
-
FLUX.2 [dev]: FLUX.2-dev Non-Commercial License를 따르며, 연구 및 비상업적 목적의 개인 작업에만 사용할 수 있습니다.
-
FLUX.2 [pro]: API를 통해서만 제공되며 상업적 이용이 가능합니다.
 BFL(Black Forest Labs) 공식 홈페이지
BFL(Black Forest Labs) 공식 홈페이지
 FLUX.2 출시 블로그
FLUX.2 출시 블로그
 FLUX.2 프로젝트 GitHub 저장소
FLUX.2 프로젝트 GitHub 저장소
https://github.com/black-forest-labs/flux2
 FLUX.2 모델 프롬프팅 가이드 문서
FLUX.2 모델 프롬프팅 가이드 문서
FLUX.2 문서 및 오버뷰
FLUX의 잠재 공간 분석 및 향상 - 표현 비교에 대한 블로그
 FLUX.2 [dev] 모델 다운로드
FLUX.2 [dev] 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()