
HiDream-O1-Image 소개
최근 이미지 생성 모델의 흐름은 텍스트 기반 생성, 지시 기반 편집(instruction editing), 주체 보존 개인화(subject-driven personalization) 등 서로 다른 작업을 어떻게 하나의 모델로 통합하느냐에 집중되고 있습니다. FLUX, Qwen-Image, SD3.5 등 기존의 대표적인 오픈 웨이트 모델들은 외부 VAE 인코더와 별도의 텍스트 인코더를 결합한 잠재 공간(latent space) 위에서 동작하는 디퓨전 트랜스포머(DiT) 구조를 채택해왔습니다. 그러나 이 방식은 픽셀 → VAE 잠재 → 텍스트 임베딩이라는 여러 도메인을 분리해 다루는 만큼, 정밀한 텍스트 렌더링이나 멀티 태스크 통합 측면에서 일관성을 유지하기 어렵다는 한계도 함께 안고 있습니다.
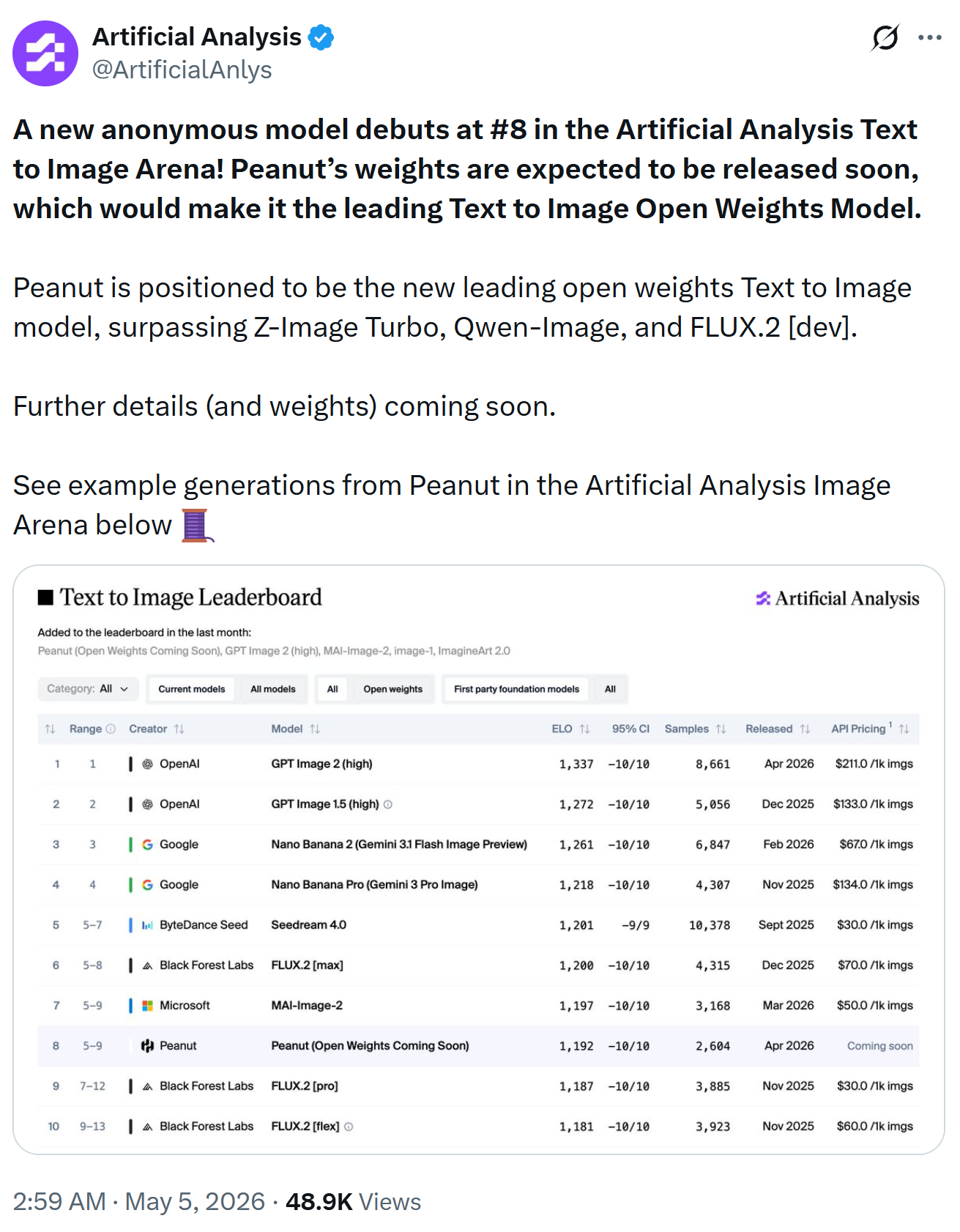
HiDream-O1-Image 는 이 문제를 한 발 더 밀어붙인 시도입니다. HiDream-ai 팀이 공개한 이 8B 파라미터 규모의 모델은, "Peanut" 이라는 코드네임으로 Artificial Analysis Text-to-Image Arena에서 8위로 데뷔하며 최신 오픈 웨이트 텍스트-이미지 모델로 자리 잡았습니다. 핵심 아이디어는 외부 VAE나 분리된 텍스트 인코더 없이, 원시 픽셀과 텍스트, 그리고 태스크별 조건(task-specific condition)을 단일 공유 토큰 공간(shared token space)에서 직접 인코딩하는 Pixel-Level Unified Transformer(UiT) 구조를 도입한 점입니다.

이 단일 아키텍처 위에서 텍스트-이미지 생성(text-to-image), 긴 텍스트 렌더링, 지시 기반 편집, 주체 보존 개인화, 스토리보드 생성을 모두 처리할 수 있으며, 최대 2,048 × 2,048 해상도까지 직접 합성이 가능합니다. 모델 가중치는 50-step 풀(full) 버전과 28-step 추론용 Dev 버전이 함께 공개되었고, 사용자의 거친 지시를 모델 친화적인 프롬프트로 재작성해주는 Reasoning-Driven Prompt Agent도 함께 제공됩니다. 코드와 가중치 모두 MIT 라이선스로 배포되어 연구뿐 아니라 상업적 활용까지 가능합니다.
HiDream-O1-Image의 Pixel-Level Unified Transformer 구조
기존의 디퓨전 트랜스포머는 입력 이미지를 VAE 인코더로 압축한 잠재 표현에서 노이즈를 예측하고, 텍스트는 별도의 텍스트 인코더(예: T5, CLIP)에서 처리한 임베딩을 cross-attention으로 결합하는 구조입니다. 이때 픽셀과 토큰은 서로 다른 모달리티로 분리되어 있고, 두 도메인 사이의 정렬을 맞추기 위한 추가 모듈이 필요합니다.
HiDream-O1-Image의 Pixel-Level Unified Transformer(UiT)는 이 분리를 없앤다는 점에서 차이가 큽니다. 원시 픽셀과 텍스트, 그리고 태스크 조건이 모두 동일한 토큰 시퀀스 위에서 처리되기 때문에, 별도의 VAE나 외부 텍스트 인코더 없이 단일 모델 안에서 픽셀과 텍스트 간의 정밀한 정렬을 학습할 수 있습니다. 이 구조 덕분에 같은 모델이 텍스트 렌더링, 객체 속성 제어, 다중 영역 레이아웃, 주체 보존 등의 작업을 모두 처리하는 멀티 태스크 환경에서도 일관된 표현을 유지할 수 있습니다.
또한 8B 파라미터라는 비교적 작은 규모로도, 24B/32B 같은 훨씬 큰 폐쇄형(closed-source) 또는 대형 오픈 웨이트 DiT 모델들과 견줄 만한 성능을 보입니다. 모델은 풀 모드에서 50 스텝, Dev 모드에서 28 스텝을 사용하며, 가이던스 스케일과 노이즈 클리핑 등의 하이퍼파라미터를 통해 출력 품질과 추론 속도 사이의 균형을 조정할 수 있습니다.
HiDream-O1-Image의 핵심 기능
HiDream-O1-Image는 단일 가중치로 다섯 가지의 핵심 기능을 모두 처리할 수 있습니다.
- 하나의 모델, 여러 작업: 텍스트-이미지 생성, 긴 텍스트 렌더링, 지시 기반 편집, 주체 보존 개인화, 스토리보드 생성을 단일 아키텍처에서 수행합니다.
- 추론 기반 프롬프트 에이전트: 생성 전에 암묵적 지식, 레이아웃, 텍스트 렌더링 요건을 명시적으로 추론하는 빌트인 "thinking" 에이전트가 함께 제공됩니다.
- 네이티브 고해상도 합성: 최대 2,048 × 2,048 해상도에서 디테일 손실 없이 직접 합성합니다.
- 8B 규모의 효율성: 8B 파라미터만으로 더 큰 오픈소스 DiT와 주요 폐쇄형 모델에 필적하거나 능가하는 품질을 달성합니다.
- Pixel-Level Unified Transformer: 원시 픽셀 위에서 직접 동작하는 단일 엔드투엔드 모델로, VAE와 분리된 텍스트 인코더가 필요하지 않습니다.
HiDream-O1-Image의 벤치마크 결과
기술 보고서(technical report)에 따르면 HiDream-O1-Image는 다섯 가지 대표 벤치마크에서 동급 또는 더 큰 모델들과 비교해 경쟁력 있는 성능을 보입니다. GenEval(구성 일반화), DPG-Bench(밀집 프롬프트 정렬), HPSv3(인간 선호), CVTG-2K(복잡 시각 텍스트 생성), LongText-Bench(긴 텍스트 렌더링) 모두에서 오픈 웨이트 8B 규모 모델 가운데 최상위권에 위치합니다.
예를 들어 GenEval에서는 HiDream-O1-Image(8B)가 0.90의 종합 점수로 FLUX.2 [Dev](24B+32B, 0.87)와 Qwen-Image(7B+20B, 0.87)를 앞섰으며, 200B 이상의 Pro 모델은 0.92로 최고치를 달성했습니다. DPG-Bench에서도 8B 버전이 89.83으로 FLUX.2 [Dev]의 87.57을 넘었습니다. 특히 영어·중국어 긴 텍스트 렌더링을 평가하는 LongText-Bench에서는 HiDream-O1-Image가 EN 0.979, ZH 0.978을 기록하여, GPT Image 2(EN 0.960, ZH 0.961)에 근접하거나 능가하는 결과를 보였습니다. 다음은 긴 텍스트 렌더링과 다중 영역 레이아웃 제어의 예시입니다.

HiDream-O1-Image의 주체 보존 개인화
주체 보존 개인화(subject-driven personalization)는 동일한 인물이나 IP를 새로운 장면에 자연스럽게 배치하는 작업입니다. HiDream-O1-Image는 두 장 이상의 레퍼런스 이미지와 새로운 장면 묘사 프롬프트를 함께 입력 받으면, 의상·헤어·소품·표정 등 식별 가능한 특징을 유지한 채 새로운 구도에서 생성을 수행합니다.

이 능력은 단순한 텍스트 임베딩에 기반한 스타일 전이와 달리, UiT의 공유 토큰 공간 위에서 픽셀과 텍스트, 레퍼런스 토큰을 함께 attend하는 구조에서 비롯됩니다. 별도의 LoRA 학습이나 파인튜닝 없이도, 추론 시 레퍼런스 이미지를 함께 제공하는 것만으로 개인화 결과를 얻을 수 있다는 점이 실용적인 강점입니다.
HiDream-O1-Image 설치 및 사용법
HiDream-O1-Image는 CUDA가 지원되는 GPU 환경에서 PyTorch 기반으로 실행됩니다. 저장소를 클론한 뒤 의존성을 설치하고, HuggingFace에서 가중치를 받아오는 흐름입니다.
# 1. 저장소 복제(Clone)
git clone https://github.com/HiDream-ai/HiDream-O1-Image.git
cd HiDream-O1-Image
# 2. 의존성 설치
pip install -r requirements.txt
# 3. (권장) Flash Attention 설치 - 속도 최적화
pip install flash-attn
Flash Attention을 설치하지 않은 경우 models/pipeline.py 의 291번째 줄에서 "use_flash_attn": True 를 False 로 바꿔야 합니다.
가중치는 HuggingFace의 HiDream-O1-Image 또는 HiDream-O1-Image-Dev 저장소에서 받을 수 있습니다. 텍스트-이미지 생성은 다음과 같이 실행합니다.
python inference.py \
--model_path /path/to/HiDream-O1-Image \
--prompt "medium shot, eye-level, front view. A woman is seated in an ornate bedroom, illuminated by candlelight, with a calm and composed expression..." \
--output_image results/t2i.png \
--height 2048 \
--width 2048
지시 기반 편집은 레퍼런스 이미지와 편집 명령어 한 줄을 함께 넘기는 방식입니다.
python inference.py \
--model_path /path/to/HiDream-O1-Image \
--prompt "remove the earphones" \
--ref_images assets/edit/test.jpg \
--output_image results/edit.png \
--keep_original_aspect
다중 레퍼런스를 사용하는 주체 보존 개인화도 같은 스크립트에서 --ref_images 인자에 여러 이미지를 나열하는 것만으로 처리할 수 있습니다. 또한 app.py 를 실행하면 사이드바에 Prompt Agent 패널이 포함된 Flask 기반의 자체 웹 데모를 띄울 수 있어, 명령줄 외에 GUI 환경에서도 모든 기능을 즉시 사용할 수 있습니다.
python app.py \
--model_path /path/to/HiDream-O1-Image \
--host 0.0.0.0 \
--port 7860
HiDream-O1-Image의 Reasoning-Driven Prompt Agent
HiDream-O1-Image는 거친 사용자 지시를 모델이 잘 처리할 수 있는 풍부한 영어 프롬프트로 재작성해주는 Reasoning-Driven Prompt Agent 를 함께 제공합니다. 에이전트는 레이아웃, 주체의 속성, 물리적 일관성, 텍스트 렌더링 요건을 명시적으로 추론한 뒤, 다음 세 필드를 가진 JSON을 출력합니다: 재작성된 영어 프롬프트(prompt), 추론 과정(reasoning), 그리고 추가로 해석한 지식(resolved_knowledge).
로컬 백엔드로 사용하려면 Gemma-4-31B-it 가중치를 받아 다음과 같이 실행합니다.
huggingface-cli download google/gemma-4-31B-it --local-dir /path/to/gemma-4-31B-it
python prompt_agent.py \
--backend local \
--model_id /path/to/gemma-4-31B-it \
--prompt "李白的静夜思写在古墙上"
또는 OpenAI 호환 API를 사용해 원격 백엔드로 호출할 수도 있습니다.
python prompt_agent.py \
--backend api \
--base_url https://api.openai.com/v1 \
--api_key $OPENAI_API_KEY \
--model_name deepseek-v4-pro \
--prompt "李白的静夜思写在古墙上"
이렇게 생성된 prompt 필드를 그대로 inference.py 의 --prompt 인자로 넘기면 복잡한 지시에 대해서도 더 안정적인 결과를 얻을 수 있습니다.
HiDream-O1-Image 라이선스
HiDream-O1-Image 저장소의 코드와 모델 가중치는 모두 MIT 라이선스로 공개되어 있어, 연구뿐 아니라 상업적 용도까지 자유롭게 사용·수정·재배포할 수 있습니다.
 HiDream-O1-Image 데모
HiDream-O1-Image 데모
 HiDream-O1-Image 기술 보고서
HiDream-O1-Image 기술 보고서
 HiDream-O1-Image 프로젝트 GitHub 저장소
HiDream-O1-Image 프로젝트 GitHub 저장소
 HiDream-O1-Image 모델 다운로드
HiDream-O1-Image 모델 다운로드
더 읽어보기
-
NextFlow: 대규모 학습의 불안정성 및 추론 속도의 한계를 극복한 멀티모달 생성 모델에 대한 연구 (feat. ByteDance)
-
LLaDA2.0-Uni: 마스크 토큰 예측 패러다임으로 멀티모달 이해와 생성을 통합한 확산 언어 모델에 대한 연구
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()