
'장시간 자율 애플리케이션 개발을 위한 에이전트 하네스 설계' 연구 개요
연구 소개 및 배경
AI 코딩 에이전트가 빠르게 발전하면서, 단순한 코드 생성을 넘어 장시간 자율적으로 완성도 높은 애플리케이션을 개발할 수 있는지가 중요한 화두가 되고 있습니다. 글을 작성한 Prithvi Rajasekaran 및 그가 소속된 Anthropic Labs 팀은 이 문제에 대해 수개월간 실험하며, 클로드(Claude)가 고품질의 프론트엔드 디자인을 자율적으로 생성하게 만드는 문제와 독립적으로 장시간 실행되며 완전한 애플리케이션을 스스로 구축하게 만드는 두 가지 상호 연결된 핵심 과제에 집중해 왔습니다.
이 연구는 Anthropic이 이전에 발표한 프론트엔드 디자인 스킬과 장시간 코딩 에이전트 하네스 연구의 연장선에 있습니다. 이러한 연구 단계들에서 고도화된 프롬프트 엔지니어링과 하네스 설계를 통해 기존 기준치 이상의 괄목할 만한 성능 향상을 이루어냈지만, 개발이 거듭될수록 결국 어느 순간 품질 향상의 한계에 부딪히는 정체 현상을 경험하게 되었습니다.
연구자들은 적대적 생성 신경망(GAN)의 대립적 학습 구조에서 영감을 받아, 코드를 실제로 생성하는 생성자(generator) 에이전트와 이를 객관적으로 평가하는 평가자(evaluator) 에이전트로 분리하는 멀티 에이전트 구조를 설계하고, 여기에 기획자(planner) 를 추가하여 최종적으로 3-에이전트 아키텍처로 발전시켰습니다. 이 구조를 통해 수 시간에 걸친 자율 코딩 세션에서 풍부한 풀스택 애플리케이션을 생성하는 데 성공했습니다.
단순한 구현이 실패하는 이유
장시간 에이전트 코딩에서 반복적으로 나타나는 두 가지 핵심적인 실패 원인들이 있습니다:
첫 번째는 컨텍스트 윈도우 문제입니다. 모델은 긴 작업을 수행하면서 컨텍스트 윈도우가 채워지면 일관성을 잃는 경향이 있습니다. 일부 모델은 "컨텍스트 불안(Context Anxiety)"이라는 현상을 보이는데, 컨텍스트 한계에 가까워졌다고 판단하면 작업을 조기에 마무리하려고 시도합니다. 이를 해결하기 위해 컨텍스트 리셋(Context Reset) 방식을 사용합니다. 대화 내역을 요약하는 컴팩션(Compaction)과 달리, 컨텍스트를 완전히 비우고 새로운 에이전트를 시작하면서 이전 에이전트의 상태와 다음 단계를 구조화된 핸드오프를 통해 전달합니다. 기존 테스트에서 Claude Sonnet 4.5는 컴팩션만으로는 충분하지 않을 만큼 컨텍스트 불안을 강하게 보여, 컨텍스트 리셋은 하네스 설계의 핵심 요소가 되었습니다.
이러한 컨텍스트 리셋 방식이 전체 시스템 오케스트레이션의 복잡성을 가중시키고 막대한 토큰 오버헤드 및 응답 지연 시간을 유발하는 단점이 있었지만, 모델이 보여주는 강한 컨텍스트 불안을 확실하게 억제하고 장기 작업의 신뢰성 높은 성능을 보장하기 위해서는 불가피하고도 가장 강력한 해결책이었습니다.
이전 연구에서도 유사한 접근이 등장한 바 있으며, 개발자 커뮤니티에서 "Ralph Wiggum" 방법이라 불리는 훅(hook)이나 스크립트를 활용한 지속적 반복 기법도 같은 맥락입니다(참고: 컨텍스트 엔지니어링).
두 번째는 자기 평가의 한계입니다. 에이전트에게 자신이 만든 결과물을 평가하라고 요청하면, 품질이 떨어지더라도 자신감 있게 칭찬하는 경향이 있습니다. 특히 디자인처럼 주관적 판단이 필요한 작업에서 이 문제가 두드러집니다. 작업을 수행하는 에이전트와 판단하는 에이전트를 분리하는 것이 이 문제를 해결하는 핵심 레버가 됩니다. 독립적인 평가자를 회의적으로 튜닝하는 것이, 생성자 스스로 자기 비판적으로 만드는 것보다 훨씬 다루기 쉽기 때문입니다.
이처럼 외부의 독립적이고 비판적인 피드백 구조가 확립되면, 생성자 에이전트는 단순히 자신의 논리나 코드를 맹신하는 매너리즘에서 벗어나 구체적이고 매서운 지적 사항들을 바탕으로 결과물을 실질적으로 반복 개선할 수 있는 확고한 기술적 기준점을 얻게 됩니다. 이는 결과적으로 전체 에이전트 시스템이 의미 없는 자기 만족적인 피드백 루프에 빠지는 것을 원천적으로 방지하고, 최종 결과물의 시각적 품질과 소프트웨어의 안정성을 전문적인 인간 개발자 수준에 가깝게 끌어올리는 데 결정적인 역할을 수행하게 됩니다.
프론트엔드 디자인: 주관적 품질을 평가 가능하게 만들기
먼저, 자기 평가(Self-Evaluation) 문제가 가장 뚜렷하게 드러나는 프론트엔드 디자인 부분부터 실험을 시작했습니다. 아무런 외부의 평가적 개입이나 제어가 없을 경우 클로드는 기술적으로는 오류 없이 기능하지만 시각적으로는 전혀 눈에 띄지 않는, 지극히 안전하고 예측 가능하며 다소 진부한 형태의 레이아웃만을 반복적으로 생성하려는 보수적인 경향을 보였습니다.
프론트엔드 디자인을 위한 하네스 디자인 중 얻은 두 가지 인사이트가 있습니다. 첫째는 인간의 미적 감각을 수치화하여 정의하는 것은 어려운 문제지만, 이를 대신하여 디자인 원칙 및 인간 디자이너의 선호도를 논리적으로 인코딩한 채점 기준을 기반으로는 평가 및 개선할 수 있다는 것입니다. 즉, "이 디자인이 아름다운가?"에는 대답하기 어렵지만, "좋은 디자인을 위해 우리의 원칙을 따르고 있는가?"라는 질문과 평가는 가능합니다. 둘째로는 프론트엔드 생성과 평가를 분리하면 생성자를 더 나은 결과로 이끄는 피드백 루프를 만들 수 있다는 것입니다.
이를 위해, 생성자와 평가자 에이전트 모두에게 다음 네 가지 평가 기준을 프롬프트로 제공했습니다:
-
디자인 품질(Design quality): 색상, 타이포그래피, 레이아웃, 이미지 등이 조화롭게 어우러져 고유한 분위기와 정체성을 만들어내는지
-
독창성(Originality): 템플릿 레이아웃이나 라이브러리 기본값이 아닌, 의도적인 창작 결정의 증거가 있는지. 보라색 그라디언트 위에 흰색 카드 같은 전형적인 AI 생성 패턴은 감점
-
완성도(Craft): 타이포그래피 계층구조, 간격 일관성, 색상 조화, 대비율 등 기술적 실행의 완성도
-
기능성(Functionality): 미적 요소와 별개로, 사용자가 인터페이스의 기능을 이해하고 주요 동작을 수행할 수 있는지
특히 연구진은 클로드가 미학적인 위험을 기꺼이 감수하고 더욱 과감한 시각적 시도를 하도록 유도하기 위해 디자인 품질과 독창성에 상대적으로 훨씬 더 높은 평가 가중치를 부여했습니다. 또한, 평가자의 최종 판단이 실제 인간 수석 디자이너의 선호도와 일치하도록 매우 상세한 점수 분석이 포함된 퓨샷(few-shot) 예제를 프롬프트에 제공하여 채점 기준을 세밀하게 보정함으로써, 수많은 반복적인 생성 과정 속에서도 평가 기준이 흔들리거나 점수 인플레이션이 발생하지 않도록하는 통제 시스템을 구축하였습니다.
실시간 피드백 루프와 3D 네덜란드 미술관 사례
주관적 미학을 객관적이고 측정 가능한 기준으로 변환한 이후, 연구진은 클로드 에이전트 소프트웨어 개발 키트(SDK)를 기반으로 실시간으로 작동하며 점진적 개선을 이끌어내는 강력한 피드백 루프 환경을 체계적으로 구축했습니다.
실행 프로세스를 살펴보면, 먼저 생성자 에이전트가 사용자의 간단한 프롬프트를 바탕으로 HTML, CSS, 자바스크립트 코드를 짜내어 일차적인 프론트엔드를 생성합니다. 이후, 평가자 에이전트는 Playwright MCP를 사용하여 브라우저 상에서 실제 작동하는 라이브 웹페이지와 직접적으로 상호작용하며 스크린샷을 남깁니다. 이 과정에서 평가자는 단순히 렌더링된 정적인 스크린샷 화면 하나만을 보고 판단하기보다, 페이지 구석구석을 능동적으로 탐색하고 앞서 설정된 엄격한 기준에 따라 구체적인 점수를 매기고 비평을 작성하여 생성자에게 피드백을 전달합니다.
이 피드백은 다시 생성자 에이전트에게 입력으로 제공되며, 전체 과정은 몇 차례 반복합니다. 연구진들은 실험당 5~15번의 반복을 수행하였으며, 전체 실험은 최대 4시간까지 소요되었습니다.
한 가지 인상적인 사례로, 연구진들이 네덜란드 미술관 웹사이트를 프롬프트로 지시했을 때, 9번째 반복까지는 깔끔한 다크 테마 랜딩 페이지를 만들었습니다. 그런데 10번째 반복에서 접근 방식을 완전히 바꿔, CSS perspective로 렌더링한 바둑판 바닥의 3D 공간으로 사이트를 재구상했습니다. 벽에 자유 배치된 작품, 스크롤이나 클릭 대신 문을 통한 갤러리 간 이동 등, 단일 패스 생성에서는 기대하기 어려운 창의적 도약이었습니다.
풀스택 코딩으로 확장: 3-에이전트 아키텍처
아키텍처
프론트엔드 디자인 실험에서 검증된 적대적 생성 신경망(GAN) 기반의 패턴을 전체 애플리케이션을 구축하는 풀스택 개발 환경으로 확장하여 적용했습니다. 이를 위해 전체 개발 프로세스를 기획자(Planner), 생성자(Generator), 평가자(Evaluator)라는 세 가지 독립적인 에이전트로 구성된 시스템으로 세분화했습니다.
기획자 에이전트(Planner): 먼저 기획자 에이전트는 사용자가 입력한 1문장에서 4문장 정도의 짧고 단순한 프롬프트를 바탕으로 전체 제품의 상세한 스펙을 확장하여 작성하는 역할을 담당합니다. 기획 단계에서는 프로젝트의 범위를 충분히 넓게 설정하되, 세부적인 기술 구현 방식보다는 전체 제품의 비즈니스 맥락과 고수준의 시스템 아키텍처 설계에 집중하도록 프롬프트를 구성했습니다. 이는 기획자가 초기 단계에서 세부 기술 사항을 잘못 지정할 경우, 그 논리적 오류가 이후의 코드 구현 단계에 연쇄적으로 영향을 미쳐 전체 시스템의 구조적 결함을 유발할 수 있기 때문입니다. 추가적으로 기획자에게는 인공지능 기반의 기능들을 제품 스펙에 자연스럽게 통합하여 시스템을 설계하도록 명시적인 지시를 포함시켜 결과물의 활용 범위를 넓혔습니다.
생성자 에이전트(Generator): 기획자가 스펙 작성을 완료하면, 생성자 에이전트가 해당 스펙에 명시된 기능들을 스프린트(Sprint) 단위로 하나씩 순차적으로 구현합니다. 생성자는 React, Vite, FastAPI, SQLite(이후 아키텍처 테스트에서는 PostgreSQL로 전환)로 구성된 현대적인 웹 기술 스택을 기본 프레임워크로 사용하며, 각 기능 스프린트가 끝날 때마다 자체적인 코드 리뷰 및 평가를 수행한 뒤 품질 보증(QA) 단계로 작업물을 이관합니다. 소프트웨어 개발의 표준 관행에 따라 버전 관리를 위해 git 시스템을 시스템 내에 통합하여 각 변경 사항을 추적 가능하게 기록합니다.
평가자 에이전트(Evaluator): 이어지는 단계에서는 평가자 에이전트가 Playwright MCP 도구를 사용하여 현재 실행 중인 애플리케이션을 실제 사용자의 관점에서 직접 클릭하고 탐색하며 철저한 동작 테스트를 진행합니다. 평가자는 사용자 인터페이스(UI)의 기능적 응답성, 백엔드 API 엔드포인트의 정상 통신 상태, 데이터베이스의 데이터 무결성을 종합적으로 검증하고, 각 스프린트의 결과물을 제품의 논리적 깊이, 기능성, 시각적 디자인, 코드 품질이라는 네 가지 객관적 기준으로 채점합니다. 각 채점 기준에는 미리 정의된 하한 임계값이 존재하며, 단 하나의 항목이라도 이 임계값에 미달할 경우 해당 스프린트는 시스템적으로 실패로 처리되고 생성자에게 문제 해결을 위한 상세한 디버깅 피드백이 즉각 전달됩니다.
특히 각 스프린트의 코드를 작성하기 전, 생성자와 평가자가 미리 '스프린트 계약(Sprint contract)'을 협상하여 어떤 상태가 작업 완료를 의미하는지 사전에 명확히 합의함으로써 고수준의 스펙과 실제 테스트 가능한 구현 사이의 간극을 논리적으로 메우는 검증 절차를 파이프라인에 도입했습니다.
이러한 에이전트들 간의 통신은 파일을 기반으로 이뤄집니다: 어떤 에이전트가 파일을 작성하면, 다른 에이전트가 파일을 읽고, 파일 내에 답변을 작성하거나 새로운 파일을 생성하여 다음 턴에 이전 에이전트가 읽을 수 있도록 합니다.
레트로 게임 메이커 실험
지금까지 제안된 아키텍처의 실효성을 교차 검증하기 위해 "2D 레트로 게임 메이커를 만들어 달라(Create a 2D retro game maker with features including a level editor, sprite editor, entity behaviors, and a playable test mode.)"는 단일 문장의 프롬프트를 사용하여 에이전트 단독 하네스(Solo) 실행 환경과 전체 하네스(Full Harness) 실행 환경의 결과를 정량적 및 정성적으로 비교 분석했습니다.
분석 결과, 단독 하네스(Solo) 방식은 시스템 실행 완료까지 약 20분이 소요되고 9달러의 비교적 저렴한 API 호출 비용이 발생했습니다. 반면 전체 하네스(Full Harness) 방식은 복잡한 다중 에이전트 추론 과정을 거치며 약 6시간의 긴 물리적 실행 시간과 200달러의 연산 비용이 청구되어 리소스 소모 측면에서 20배 이상의 큰 격차를 보였습니다.
| 하네스 | 소요 시간 | 비용 |
|---|---|---|
| Solo | 20분 | $9 |
| Full Harness | 6시간 | $200 |
그러나 결과물의 소프트웨어적 작동 상태를 살펴보면, 단독 에이전트가 생성한 결과물은 초기 UI 레이아웃이 화면의 렌더링 공간을 비효율적으로 사용하고 전체 사용자 워크플로우가 경직되게 설계되어 있었습니다. 더욱 뚜렷한 차이점은 게임 소프트웨어의 핵심인 게임 플레이 로직 자체가 브라우저 상에서 전혀 기능하지 않았다는 점입니다.
문제의 원인을 디버깅하기 위해 코드를 직접 분석한 결과, 화면에 표시될 엔티티를 정의하는 정적 데이터 구조 로직과 실제 물리 법칙을 연산하는 동적 게임 런타임 엔진 사이의 내부 브릿지 스크립트가 누락되거나 참조 오류로 인해 끊어져 있는 것이 확인되었습니다.

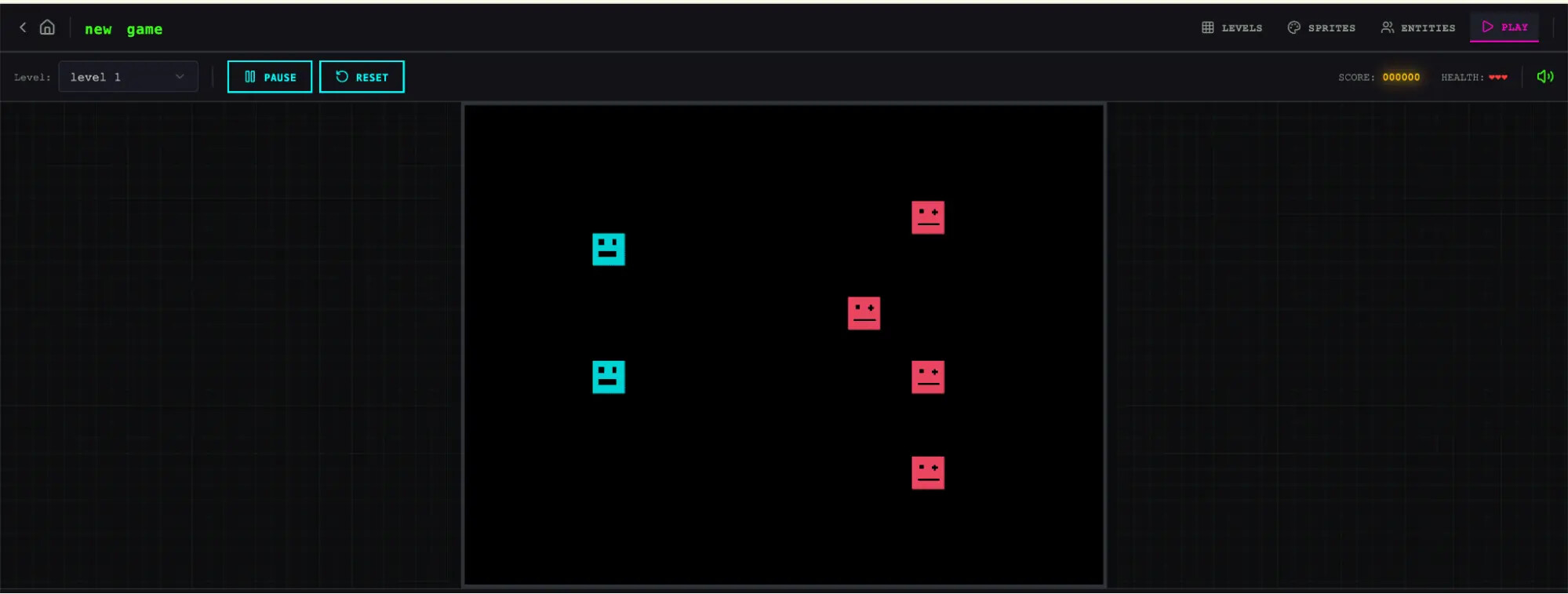
이는 단일 에이전트가 애플리케이션의 겉모습은 단편적으로 구성할 수 있으나 복잡하게 상호작용하는 다계층 시스템 아키텍처를 일관되게 설계하고 의존성을 연결하는 데에는 명백한 구조적 한계가 있음을 시사합니다.
이와 대조적으로, 전체 하네스 시스템 환경에서는 기획자 에이전트가 한 줄의 초기 프롬프트를 10번의 개발 스프린트와 16개의 독립적인 기능 스펙으로 세밀하고 체계적으로 확장하여 전체 프로젝트를 구성했습니다. 그 결과 게임 제작을 위한 핵심 에디터와 플레이 모드를 비롯하여 스프라이트 애니메이션 렌더링 시스템, 객체별 행동 템플릿, 사운드 효과 처리 모듈, 인공지능 기반 스프라이트 에셋 생성기, 그리고 최종 게임 내보내기 및 URL 공유 기능까지 모두 포함된 통합형 시스템이 구축되었습니다.
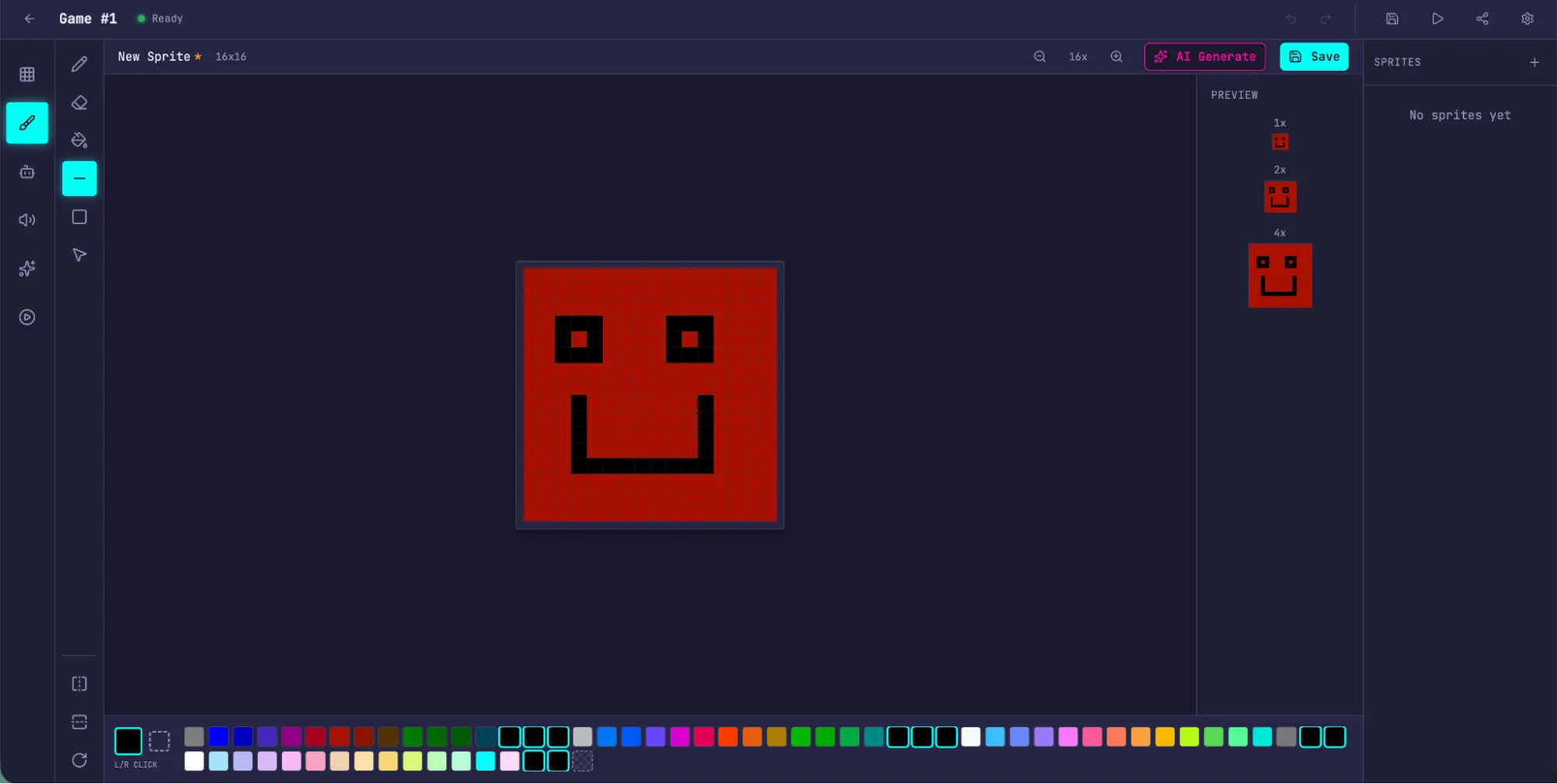
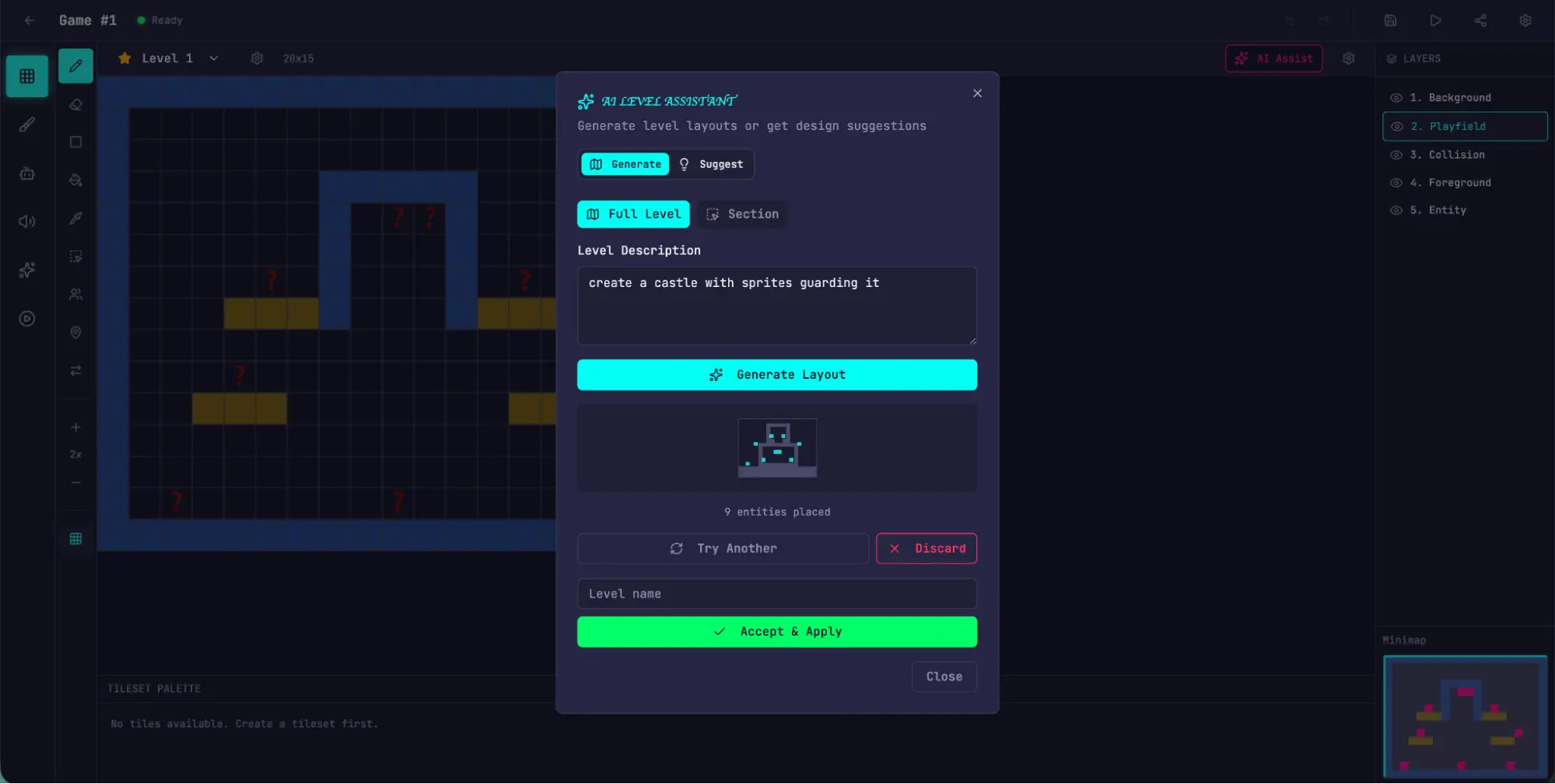
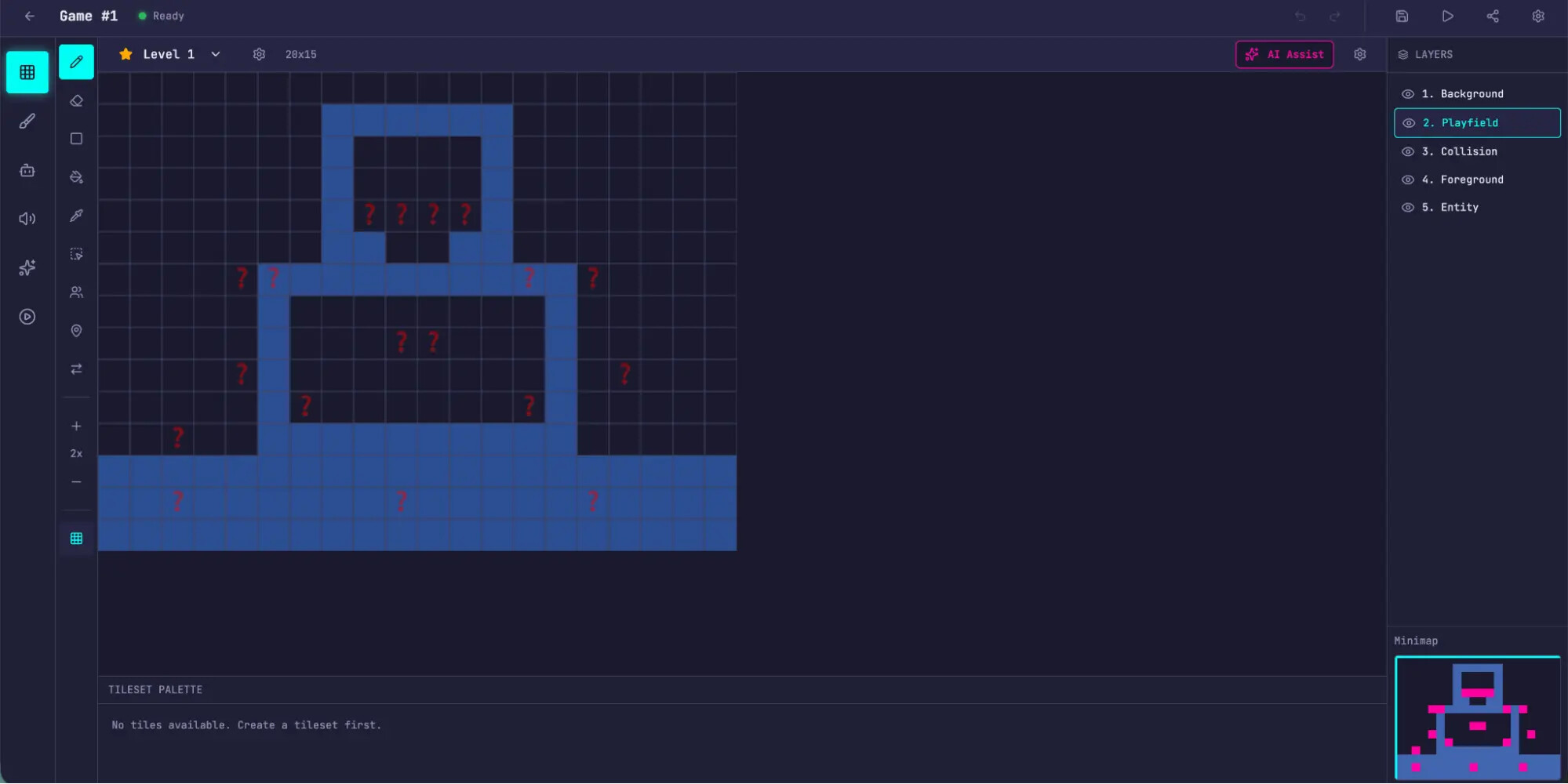
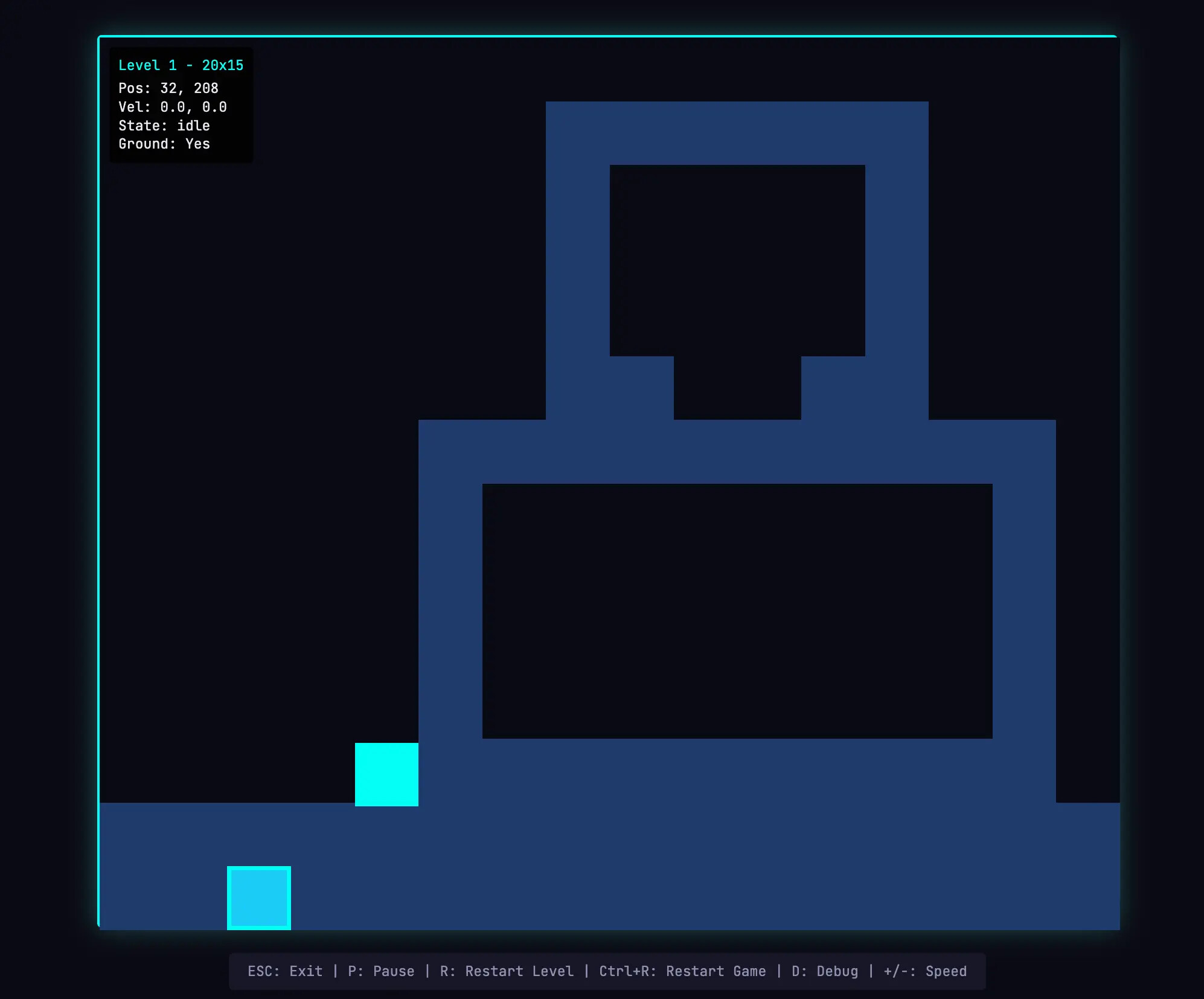
앞선 단독 실행의 오작동 결과와 달리, 다중 에이전트 하네스를 통해 빌드된 버전은 사용자가 직접 조작 키를 입력하여 렌더링된 맵 위에서 객체를 이동시키고 실제로 게임 엔진을 구동할 수 있는 정상 작동 상태를 도출했습니다. 이처럼 작동 가능한 상태의 소프트웨어를 컴파일해 낼 수 있었던 주된 기전은 평가자 에이전트가 철저한 통합 테스트 검증을 통해 생성자가 작성한 코드의 기능적 결함을 지속적으로 리팩터링하도록 강제했기 때문입니다.
초기 스프린트 단계부터 평가자는 Playwright 도구를 활용하여 프론트엔드 컴포넌트와 백엔드 API 간의 데이터 상호작용을 면밀히 모니터링하고 사전 명세서에 정의된 계약 기준을 교차 검사했습니다. 이러한 폐쇄 루프 형태의 엄격한 검증 과정은 생성자가 단편적인 코드 조각 생성을 넘어 실제로 오류 없이 런타임 환경에서 실행되는 통합 아키텍처를 구축하도록 이끄는 핵심적인 역할을 수행했습니다.
| 계약 기준 (Contract criterion) |
평가자 발견 사항 (Evaluator finding) |
|---|---|
| 직사각형 채우기 도구가 드래그로 영역 채우기 | 실패: 드래그 시작/끝 지점에만 타일 배치. fillRectangle 함수가 mouseUp에서 제대로 트리거되지 않음 |
| 배치된 엔티티 스폰 포인트 선택 및 삭제 | 실패: Delete 키 핸들러가 selection과 selectedEntityId 모두 필요하지만, 엔티티 클릭은 selectedEntityId만 설정 |
| API를 통한 애니메이션 프레임 순서 변경 | 실패: PUT /frames/reorder 라우트가 /{frame_id} 뒤에 정의되어, FastAPI가 'reorder'를 정수로 파싱 시도 후 422 에러 반환 |
평가자 에이전트가 시스템 런타임 중에 구체적으로 어떤 오류들을 식별하고 코드 개선을 유도했는지 로그를 분석해 보면 시스템의 동작 방식이 뚜렷하게 확인됩니다. 위 표에서 볼 수 있듯, 프론트엔드 환경에서 직사각형 채우기 도구가 사용자의 드래그 좌표 영역 전체를 타일 객체로 채우지 못하고 시작점과 끝점에만 단일 타일을 배치하는 로직 오류를 식별하여, 관련 채우기 함수가 마우스 업(mouseUp) 이벤트 리스너에서 정상적으로 트리거되지 않음을 정확히 짚어냈습니다.
또한, 레벨 에디터 내에서 이미 배치된 엔티티의 스폰 포인트를 삭제하려는 기능 구현 테스트에서, 삭제 키 이벤트 핸들러 로직이 요구하는 이중 변수 조건과 실제 클릭 동작 시 단일하게 설정되는 변수 상태가 일치하지 않아 발생하는 상태 불일치 버그를 찾아내어 실패 판정을 기록했습니다.
백엔드 API 환경의 경우, 클라이언트가 애니메이션 프레임 순서를 변경하도록 요청하는 라우팅 경로가 서버 로직 상에서 잘못된 순서로 정의된 것을 탐지해 냈으며, 이로 인해 FastAPI 프레임워크가 일반 문자열인 'reorder'를 동적 경로의 정수형 변수로 잘못 파싱하려 시도하다 422 Unprocessable Entity 에러를 반환하는 백엔드 라우팅 계층의 버그까지 식별했습니다.
그러나 이처럼 객관적인 버그 탐지 능력을 갖춘 평가자 파이프라인을 구축하는 과정에는 초기 모델 프롬프트 튜닝에 상당한 반복적인 엔지니어링 리소스 투입이 요구되었습니다. 기본 베이스라인 상태의 Claude 모델은 소프트웨어 품질 보증(QA) 에이전트로서 작동하도록 프롬프팅 되었을 때, 명백한 동작 버그를 발견하고도 전체 시스템 구동에 치명적이지 않다고 스스로 가중치를 낮추어 해석하여 테스트를 통과시켜버리는 긍정 편향성을 내재하고 있었기 때문입니다.
이러한 기저 언어 모델의 편향적 허용성을 통제하기 위해 연구진은 체계적이고 반복적인 로그 분석 및 프롬프트 튜닝 루프를 파이프라인에 도입해야만 했습니다. 수많은 하네스 실행 과정을 거치면서 평가자가 출력한 대량의 실행 기록 및 상태 판단 로그를 교차 검증하고, 실제 시니어 인간 엔지니어의 엄격한 QA 기준과 어긋나는 판단 지점들을 데이터셋으로 수집했습니다.
수집된 예외 및 오판 사례들을 바탕으로 QA 에이전트의 시스템 프롬프트에 구체적인 엣지 케이스 처리 지침과 예외 없는 엄격한 실패 기준을 명시적으로 주입하는 하이퍼파라미터 수준의 미세 조정 작업을 여러 차례 반복 수행했습니다. 이러한 튜닝 과정을 거친 후에야 에이전트 내부의 주관적 타협 프로세스를 배제하고, 사전 설정된 코드 품질 기준과 계약 조건에 따라 객관적 데이터로 버그를 짚어내는 현재의 안정적인 평가 시스템을 구축할 수 있었습니다.
최적화가 완료된 평가자 시스템은 복잡한 소프트웨어 라이프사이클 속에서 인간 개발자의 직접적인 개입 빈도를 최소화하면서도 일정한 기준 이상의 코드 베이스 품질을 유지할 수 있는 핵심적인 검증 파이프라인 역할을 수행합니다. 이는 생성형 AI 모델의 역할을 단순한 코드 자동 완성 보조 도구로 국한하지 않고, 상호 견제 기반의 코드 리뷰어와 자동화 테스터의 역할까지 위임하여 독립적인 마이크로서비스 형태의 개발 환경 아키텍처를 구성할 수 있음을 검증한 사례에 해당합니다.
하네스 반복 개선: Opus 4.6과 단순화
초기 연구를 통해 설계된 3-에이전트 하네스 아키텍처는 기능적으로 유효한 애플리케이션 코드를 컴파일하는 데에는 성공했으나, 시스템 실행 소요 시간이 수 시간 단위로 측정되고 과도한 토큰 소비로 인한 API 비용이 높아 빈번하게 발생하는 프로덕션 환경의 CI/CD 파이프라인에 상시 통합하기에는 경제적, 시간적 오버헤드가 컸습니다. 이러한 구조적 비효율에 대응하여 시스템 아키텍처를 최적화하기 위해 Anthropic이 이전 공개한 효과적인 에이전트 구축(Building Effective Agents) 블로그에서 제시한 핵심 철학을 도입했습니다.
해당 철학은 시스템 설계 시 가능한 한 가장 연산 비용이 낮고 단순한 해결책을 베이스라인으로 우선 적용하고, 해당 구조의 성능 한계로 인해 목표 달성이 불가능할 때만 예외적으로 시스템의 복잡성을 점진적으로 높이는 실용주의적 소프트웨어 공학의 원칙을 강조합니다. 이 원칙에 입각하여 연구진은 기존 무거운 하네스 시스템을 구성하던 여러 복잡한 스캐폴딩 요소들을 하나씩 순차적으로 제거하거나 비활성화하며 전체 출력 코드의 품질과 성공률에 미치는 영향을 객관적으로 측정하는 통제 변인 기반의 제거(Ablation) 실험을 진행했습니다.
이러한 시스템 구조의 단순화 및 파이프라인 경량화 작업은 시스템의 추론 및 코드 생성을 담당하는 기저 언어 모델이 Claude Opus 4.6 버전으로 메이저 아키텍처 업데이트를 거치면서 본격적인 탄력을 받았습니다. Anthropic의 공식 기술 릴리스 노트에 명시된 지표에 따르면, 해당 버전의 모델은 작업 큐 시작 전의 장기 계획(Long-term planning) 능력이 이전 세대 대비 유의미하게 향상되었고, 긴 토큰 길이의 작업 컨텍스트 환경에서도 에이전트의 초기 지시 상태 벡터를 잃지 않고 유지하는 지시 이행 안정성을 확보했습니다.
더욱 확장된 컨텍스트 윈도우를 바탕으로 Opus 4.6 모델은 수천 줄에 달하는 방대한 규모의 레거시 및 신규 코드베이스 파일들을 조작할 때의 문맥 참조 오류 비율이 크게 감소했으며, 자체적인 코드 리뷰 로직과 에러 메시지 기반 디버깅 능력 또한 아키텍처 수준에서 대폭 강화되었습니다. 특히 장문 컨텍스트 버퍼 내에서의 구체적인 식별자(변수나 함수) 정보 검색(Retrieval) 정확도가 기술적으로 높아짐에 따라 모델 자체의 단일 추론 능력이 전체적으로 상승하는 벤치마크 결과를 보여주었습니다.
결과적으로 이전 버전의 기저 모델(Base Model)에서 잦게 발생했던 컨텍스트 토큰 소실이나 주의력 집중 불안 현상 등 기존 하네스 시스템이 복잡한 우회 로직과 빈번한 상태 저장을 통해 강제로 보완해야 했던 기술적 결함들이 모델 자체의 기본기로 대부분 상쇄 및 해소되었습니다.
스프린트 구조 제거
기저 모델(Base Model)의 역량 강화에 따른 가장 핵심적인 시스템 아키텍처 변화는 생성자 에이전트의 작업 흐름을 인위적으로 분절하고 통제하던 스프린트(Sprint) 단위 분할 구조의 전면적인 제거입니다. 향상된 인지적 안정성과 컨텍스트 무결성 덕분에, 기획자가 산출한 다중 기능의 복잡한 전체 스펙을 여러 단계의 짧은 개발 스프린트로 강제 분해하여 세션의 컨텍스트를 지속적으로 초기화하지 않더라도 모델이 단일 실행 세션 내에서 논리적 일관성을 온전히 유지하며 소프트웨어 전체를 코딩할 수 있음이 실험을 통해 검증되었습니다.
이러한 파이프라인 간소화 과정에서 작업 실행 단위로서의 스프린트 분할 로직은 삭제되었지만, 전체 시스템의 기능적 요구사항 스코프를 기획하고 비즈니스 방향성을 설정하는 기획자 에이전트 노드와 최종적인 코드의 기능 무결성을 런타임에서 검증하는 평가자 에이전트 노드는 시스템의 안전망 확보를 위해 제거되지 않고 유지되었습니다.
스프린트 구조 제거를 위한 제어 실험 결과, 기획자 에이전트가 누락된 환경에서는 단일 생성자 모델이 임의로 시스템 아키텍처 개발 난이도를 낮추어 전체 요구사항의 스코프를 자의적으로 축소하려는 경향이 나타나 이를 선제적으로 방지하기 위한 강제 제약 장치로서 기획자의 역할은 필수적인 것으로 확인되었습니다.
평가자 에이전트 로직 역시 기저 모델의 성능이 향상되었음에도 불구하고 여전히 깊은 콜스택을 가지거나 복잡하게 상태가 얽힌 중첩된 코드의 미세한 논리적 결함을 찾아내는 가치 있는 독립적 검증 레이어의 기능을 지속적으로 수행했습니다. 다만 전체 시스템 성능 프로파일링 결과에 따라, 평가 시스템의 프로세스 개입 방식은 각 세부 기능의 스프린트 종료 시점마다 반복적으로 스크립트를 실행하여 I/O 병목과 토큰 낭비를 유발하던 기존 구조에서, 전체 애플리케이션의 프론트엔드 및 백엔드 생성 프로세스가 1차적으로 완전히 종료되어 렌더링된 이후 단 한 번만 전체 시스템 통합 테스트(Integration Test)를 스캔하는 일괄 평가(Batch evaluation) 방식으로 아키텍처가 변경되어 실행 오버헤드를 대폭 줄였습니다.
이번 최적화 실험 과정의 데이터를 분석하여 도출한 기술적 통찰은, 평가자 에이전트 인스턴스의 실질적인 결함 탐지 유용성이 사용자가 요구하는 소프트웨어 아키텍처 난이도와 현재 시스템에 적용된 언어 모델의 기술적 한계 능력 경계선(Frontier) 사이의 역학 관계 지표에 크게 좌우된다는 점입니다. 이전 세대 모델인 Opus 4.5 런타임 환경에서는 일반적인 애플리케이션 빌드 작업 자체의 난이도가 생성자 모델의 연산 한계치에 매우 근접했기 때문에, 작업 트랜잭션 도중 다수의 심각한 결함이 필연적으로 발생했고 평가자가 이를 유의미한 비율로 식별하여 가치를 증명했습니다.
반면, Opus 4.6 런타임 환경에서는 모델의 기본 코딩 정확도 역량이 획기적으로 향상됨에 따라 기술적 한계선이 외부로 넓게 확장되어, 과거 기준의 복잡한 작업들이 모델의 안정적인 정상 처리 범위 안쪽으로 편입되면서 결과적으로 시스템 평가자가 개입하거나 수정 지시를 내릴 만한 치명적 오류의 발생 빈도가 급격히 감소하는 데이터 패턴을 보였습니다.
DAW(디지털 오디오 워크스테이션) 생성 실험
아키텍처 구조가 업데이트되고 프로세스가 경량화된 새로운 형태의 하네스 성능을 기술적 한계점까지 스트레스 테스트하기 위해, "브라우저 환경에서 Web Audio API를 활용하여 완전하게 기능하는 디지털 오디오 워크스테이션(DAW) 시스템을 구축해 달라(Build a fully featured DAW in the browser using the Web Audio API)"는 고난이도의 도메인 특화 프롬프트를 입력하여 소프트웨어 생성 실험을 구동했습니다.
디지털 오디오 파이프라인 구성이라는 고도로 복잡한 도메인 지식과 이벤트 기반 실시간 오디오 처리 로직이 요구되는 이 애플리케이션 컴파일 프로세스는 기획자의 초기 아키텍처 스펙 확장을 시작으로 시스템 내에서 총 세 번의 자율적인 반복 빌드 및 품질 보증(QA) 루프를 거쳐 코드 베이스가 통합되었습니다.
최종 코드 병합 및 브라우저 테스트 완료 시점까지 총 3시간 50분의 물리적 서버 시간이 소요되었으며, 전체 에이전트 인스턴스들이 통신 과정에서 소비한 토큰에 대한 총 API 호출 비용 누적액은 약 124.70달러로 집계되었습니다.
| 에이전트 및 단계 | 소요 시간 | 비용 |
|---|---|---|
| 기획자 | 4.7분 | $0.46 |
| 빌드 (1라운드) | 2시간 7분 | $71.08 |
| QA (1라운드) | 8.8분 | $3.24 |
| 빌드 (2라운드) | 1시간 2분 | $36.89 |
| QA (2라운드) | 6.8분 | $3.09 |
| 빌드 (3라운드) | 10.9분 | $5.88 |
| QA (3라운드) | 9.6분 | $4.06 |
| 합계 | 3시간 50분 | $124.70 |
시스템 단계별 리소스 소모 내역 데이터를 정량적으로 세분화하여 분석해 보면, 첫 기획 프롬프트 추론 단계에 약 4.7분이 소요되었고 첫 번째 메인 빌드 라운드에서 생성자 에이전트가 스프린트 분해 프로세스 없이 2시간 7분 동안 단일 컨텍스트 세션으로 일관되게 코드를 컴파일하며 가장 큰 비중의 연산 리소스와 API 비용을 투입했습니다. 이후 순차적으로 실행된 첫 번째 독립 QA 검증 라운드는 약 8.8분 동안 브라우저 상의 전체 오디오 시스템 인터페이스와 이벤트 리스너를 교차 검증하여 결함 리포트를 생성했고, 해당 페이로드를 바탕으로 생성자가 다시 1시간 2분 동안 두 번째 코드 빌드를 진행하여 식별된 구조적 오류들을 패치했습니다.
이어지는 2라운드의 마이너 QA 과정과 3라운드의 마지막 핫픽스 빌드 및 QA 검증 과정은 상대적으로 적은 토큰과 짧은 시간 내에 잔여 엣지 케이스 버그를 수정하고 전체 오디오 파이프라인 아키텍처의 상태 안정성을 최종적으로 확보하는 데 연산 리소스를 할당했습니다. 이러한 실행 프로파일 데이터는 생성자 노드가 과거와 같은 분절된 스프린트 단위의 명시적 구분 로직 없이도 단일 세션 내에서 장시간 동안 주어진 목표 아키텍처 스키마를 유지하며 방대한 규모의 레포지토리를 메모리 오버플로우 없이 안정적으로 조작할 수 있는 향상된 추론 역량을 확보했음을 교차 입증하는 정량적 근거로 작용합니다.
생성자 에이전트의 단일 세션 컨텍스트 유지 능력이 구조적으로 향상되었음에도 불구하고, 아키텍처 하단에 배치된 독립적인 QA 에이전트는 애플리케이션의 세부적인 기능 명세 누락을 정확하게 탐지하여 소프트웨어 결과물의 질적 개선에 직접적인 기여를 수행했습니다. 첫 번째 QA 라운드 종료 후 반환된 분석 로그에 따르면, 평가자는 컴파일된 프론트엔드가 요구된 뷰포트 디자인 충실도를 보이며 인공지능 에이전트 연동 인터페이스와 백엔드 API 라우팅 구조를 정상 상태로 갖추고 있음을 1차적으로 확인했습니다.
그러나 기능 테스트 관점에서 DOM 트리 상의 타임라인 인터페이스에서 오디오 클립 요소(Element)를 마우스로 드래그하여 X축으로 이동시키는 핵심적인 좌표 갱신 이벤트 로직이 구현되지 않았고, 개별 채널의 악기를 조작할 수 있는 UI 패널 컴포넌트 및 시각적 이펙트 필터 에디터가 렌더링되지 않아 시스템 요구사항 명세 기준 기능 완성도 항목에서 치명적 실패(Critical Failure)라고 엄격하게 플래그를 지정했습니다.
코드 패치 및 병합 후 진행된 두 번째 QA 통합 테스트 라운드에서는 브라우저의 마이크 접근 권한을 통한 오디오 녹음 기능의 백엔드 처리 로직이 실제 하드웨어 미디어 스트림 입력과 바인딩되지 않은 채 빈 반환 값을 던지는 단순 스텁(Stub) 함수 형태로 방치되어 있음을 정밀하게 찾아냈습니다.
나아가 생성된 오디오 클립의 재생 범위를 조절하는 크기 조정(Resize) 기능과 특정 오프셋을 기준으로 트랙을 분할(Split)하는 버퍼 처리 기능 로직이 소스코드 상에 반영되지 않았으며, 오디오 이펙트 노드 매개변수를 제어하는 사용자 인터페이스 컴포넌트가 전문적인 오디오 파형 시각화 캔버스 없이 HTML 표준의 단순한 숫자 입력 슬라이더(input type="range") 태그만으로 급조되어 기능적 직관성이 떨어진다는 추가적인 UI/UX 명세 위반 결함을 식별해 냈습니다.
다중 에이전트 노드 간의 이러한 반복적인 비판적 검증 및 핫픽스 루프를 거쳐 컴파일이 완료된 최종 DAW 애플리케이션은 상용화된 네이티브 전문 음악 제작 소프트웨어의 C++ 기반 메모리 최적화 깊이에는 미치지 못하지만, 웹 브라우저 DOM 환경 위에서 정상적으로 렌더링되고 구동되는 다중 트랙 어레인지 뷰, Web Audio API 기반의 다중 채널 오디오 믹서 라우팅, 그리고 전체 재생 커서 동기화를 제어하는 트랜스포트 컨트롤 모듈을 성공적으로 구축해 냈습니다.
특히, 시스템에 통합된 인공지능 에이전트 모듈을 활용하여, 사용자가 간단한 텍스트 프롬프트를 전송하는 행위만으로 애플리케이션 글로벌 상태(Global state)의 템포(BPM)와 키 매개변수를 자동으로 덮어쓰기하고, 미디 형태의 멜로디 시퀀스와 드럼 트랙 배열 데이터를 절차적으로 계산하여 생성해 냈습니다. 또한 오디오 노드의 게인(Gain) 값을 조절하여 믹서의 채널별 볼륨 레벨을 동적으로 맞추거나, 컨볼루션 리버브 버퍼를 할당하여 이펙트 효과를 실시간 연산 파이프라인에 추가함으로써 짧은 음악 트랙 패턴을 서버 통신 없이 클라이언트 단에서 유기적으로 조합 및 렌더링할 수 있는 고도화된 기능성까지 시스템에 통합 제공했습니다.
시사점과 향후 전망
이번 연구의 하네스 단순화 프로세스와 일련의 DAW 생성 실험들을 통해 도출된 핵심적인 소프트웨어 엔지니어링 교훈은 다중 에이전트 기반 자율 하네스 아키텍처의 기술적 본질과 향후 발전 파이프라인의 명확한 구조적 방향성을 제시합니다:
첫 번째로 도출된 아키텍처 원칙은, 특정 버전에 맞추어 복잡하게 설계된 하네스 래퍼(Wrapper) 로직의 모든 구성 요소는 개발 당시 사용 가능한 기저 추론 모델이 자체적으로 연산 및 해결하지 못하는 인지적 병목이나 컨텍스트 제약에 대해 개발자가 설계한 추론적 우회 가정(Assumptions)들을 시스템 내부에 정적 코드로 인코딩한 임시방편의 구조물이라는 점입니다.
따라서 컨텍스트 처리량과 추론 능력이 더 진보된 신규 기저 모델이 릴리스 파이프라인에 배포될 때마다, 백엔드 시스템 엔지니어는 전체 에이전트 오케스트레이션 아키텍처를 전면적으로 재검토하여 신규 모델이 자체 가중치로 정상 처리할 수 있게 된 하네스 내부의 방어 로직 블록들을 코드베이스에서 과감히 제거해야 합니다. 그렇게 시스템 경량화를 통해 확보된 토큰 여력과 I/O 처리 대역폭을 과거 세대에서는 연산 비용 한계로 시도하지 못했던 새롭고 복잡한 고급 기능 탐색이나 병렬 에이전트 호출을 위한 상위 계층의 스캐폴딩(Scaffolding) 구조로 전환 배치하는 아키텍처 최적화 실무 루프를 필수적으로 구축하고 실행해야 합니다.
두 번째로 검증된 교훈은 상용 프로덕션 수준의 거대한 코드베이스를 다루는 복잡한 소프트웨어 라이프사이클 작업을 대규모 언어 모델 API 레이어에 위임할 때의 구조적 접근법에 관한 것으로, 전체 모놀리식 프로젝트를 독립적으로 검증 가능한 세분화된 마이크로 논리 단위로 분해하는 아키텍처 설계가 절대적으로 요구된다는 점입니다.
기획 시맨틱 구성, 코드 렌더링 타겟팅, 품질 통합 테스트 등 시스템의 각기 다른 도메인 측면에 맞추어 고도로 최적화된 시스템 프롬프트 가중치를 지닌 개별 에이전트 인스턴스들을 파이프라인의 각 노드에 분리 할당하는 접근법이, 모든 컨텍스트를 하나의 프롬프트에 구겨 넣는 단일 거대 모델 추론 방식보다 압도적인 에러 핸들링 역량 확보 및 전체 트랜잭션 성공률 향상을 보장합니다. 특히, 소스 코드를 직접 렌더링하고 생성하는 쓰기 권한을 가진 에이전트 인스턴스와 컴파일된 결과물을 외부에서 블랙박스 형태로 비판적 검증하는 읽기 및 실행 권한 전용 에이전트 주체를 시스템 아키텍처 및 네트워크 상으로 엄격히 분리하는 디커플링(Decoupling) 전략이 요구됩니다.
이러한 역할 분리 아키텍처는 백엔드 컴포넌트의 논리적, 문법적 정확성을 보장하는 객관적 단위 테스트(Unit Test)를 넘어, 클라이언트 프론트엔드의 사용자 인터페이스(UI) 접근성과 같은 정량적 평가 코드를 짜기 까다로운 주관적이고 정성적인 결과물의 산출 품질을 일관되게 향상시키는 데 있어서도 가장 신뢰성 높은 기술적 억지력(Deterrence)이자 안전장치로 작동합니다.
마지막으로 확인된 기술적 동향은, 대규모 언어 모델 추론 성능의 파라미터가 스케일링 법칙에 따라 시간의 흐름과 함께 지속적으로 고도화됨에 따라 특정 하네스 래퍼 구조 설계를 통해 유의미한 비즈니스 ROI를 창출할 수 있는 아키텍처 유효 조합의 집합 크기가 단순히 축소되거나 소멸하는 것이 아니라 시스템의 상위 복잡도 차원으로 점진적으로 이동(Shift)한다는 수학적 분포의 변화입니다.
기저 모델 컨테이너가 더 길고 복잡한 다중 턴 작업 컨텍스트를 메모리 손실 없이 독립적으로 안정 처리할 수 있게 되면서 얕은 수준의 작업을 보조하던 과거 레거시 파이프라인의 유지 구조는 기술 부채로 전락하지만, 동시에 기저 모델의 기본 연산 한계선이 크게 확장됨에 따라 과거의 GPU 연산 자원 제약 하에서는 시도조차 불가능했던 훨씬 더 방대하고 수준 높은 소프트웨어 엔지니어링 도메인(예: 복잡한 3D 렌더링 파이프라인 역엔지니어링, 실시간 분산 시스템 스캐폴딩 등)을 자동화 돌파할 수 있는 완전히 새로운 차원의 거대 하네스 아키텍처 설계 공간 개척이 가능해집니다.
결론적으로 현대 클라우드 네이티브 환경에서 AI 모델 기반 시스템을 다루는 소프트웨어 엔지니어의 핵심 직무 영역은, 단순히 단일 모델 API 인드포인트에 텍스트 지시 프롬프트를 페이로드로 전송하는 수동적인 조작자 레벨을 벗어나는 양상을 보입니다. 현재 런타임에서 가용할 수 있는 최고 성능 모델의 컨텍스트 윈도우 한계점과 파인튜닝 확장 가능성을 정확하게 프로파일링하고 벤치마킹하여, 모델이 업데이트되는 각 기술적 릴리스 시점에 맞추어 전체 시스템의 처리 효율과 코드 무결성을 가장 완벽하게 달성할 수 있는 다음 세대의 다중 에이전트 협업 토폴로지(Topology) 로직을 끊임없이 탐색, 설계, 구현, 검증하는 고도화된 아키텍처 엔지니어링 패러다임으로 그 정체성이 빠르게 진화하고 있습니다.
 Harness design for long-running application development 소개 블로그
Harness design for long-running application development 소개 블로그
더 읽어보기
-
Codex 하네스의 비밀 풀기: App Server 구축기 (Unlocking the Codex harness: how we built the App Server)
-
[GN⁺] 내가 LLM으로 소프트웨어를 만드는 방법 (How I write software with LLMs)
-
Planning with Files: Markdown 파일을 에이전트의 작업 기억으로 사용하는 Manus의 동작 방식을 Claude에 적용한 Skill
-
(Open) Agent Spec: 오라클(Oracle)이 제안하는, AI 에이전트 및 에이전트 시스템을 위한 공개 명세 프로젝트
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()