
Codex CLI와 에이전트 기술의 진화
Codex CLI는 개발자의 로컬 환경에서 고품질의 소프트웨어 변경 사항을 생성하고 실행하기 위해 설계된 OpenAI의 크로스 플랫폼 소프트웨어 에이전트입니다. 단순히 텍스트를 생성하는 데 그치지 않고, 사용자의 머신에서 안전하고 효율적으로 코드를 수정하거나 명령어를 실행하는 능력을 갖추고 있습니다. OpenAI는 최근 Codex CLI를 오픈소스로 전환하며 그 내부 동작 원리를 상세히 공개하기 시작했습니다. 이는 인공지능이 단순한 '채팅 상대'를 넘어 실제 개발 워크플로우를 주도하는 '에이전트'로 진화하고 있음을 보여주는 중요한 이정표입니다.
Codex 프로젝트는 Codex CLI뿐만 아니라 클라우드 기반의 Codex Cloud, 그리고 VS Code 확장 프로그램을 모두 아우르는 거대한 에코시스템을 지향합니다. 그중에서도 Codex Harness라고 불리는 핵심 로직은 에이전트 루프와 실행 엔진을 제공하여 모든 Codex 경험의 근간을 이룹니다. 이 시스템은 사용자의 명령을 이해하고, 필요한 도구를 호출하며, 결과물을 다시 분석하여 최적의 코드를 작성하는 일련의 과정을 자동화합니다. 개발자는 이제 반복적인 코드 수정 작업에서 벗어나 더 높은 수준의 아키텍처 설계와 비즈니스 로직에 집중할 수 있게 되었습니다.
에이전트 루프: 지능형 상호작용의 핵심 메커니즘

에이전트 루프는 에이전트 아키텍처의 가장 중추적인 부분으로, 사용자 입력부터 최종 응답까지의 모든 과정을 관리합니다. 이 루프는 크게 입력 프롬프트 준비, 모델 추론(Inference), 도구 실행(Tool Execution)의 세 단계로 구성되며, 각 단계는 정교한 프로토콜에 따라 맞물려 돌아갑니다.
프롬프트 생성과 토큰화 과정
사용자가 입력을 제공하면 에이전트는 이를 포함한 텍스트 지침 세트인 프롬프트를 구성합니다. 이 프롬프트는 OpenAI의 토큰(Tokens) 개념을 기반으로 정수 시퀀스로 변환되어 모델에 전달됩니다.
토큰은 모델이 언어를 이해하는 최소 단위이며, 추론 과정에서 모델은 이 토큰들을 샘플링하여 다음에 올 가장 적절한 토큰 시퀀스를 생성합니다. 이 과정이 실시간으로 수행되기 때문에 사용자는 스트리밍 형태로 출력되는 응답을 확인할 수 있습니다.
도구 호출과 루프의 반복
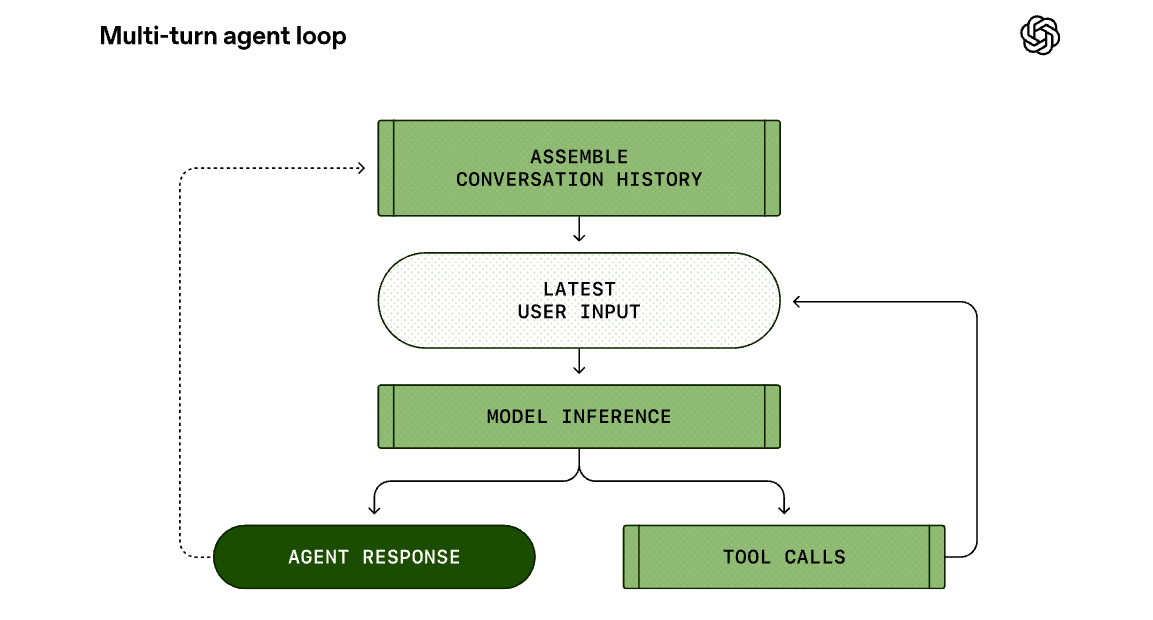
추론 단계에서 모델은 단순히 텍스트 응답을 내놓는 대신 특정 도구의 실행을 요청할 수 있습니다. 예를 들어 "현재 디렉토리의 파일 목록을 보여달라"는 요청에 대해 모델은 ls 명령어를 실행하는 도구 호출(Tool call) 을 생성합니다. 에이전트는 이 요청을 받아 로컬 환경에서 실제로 명령을 수행하고, 그 결과를 다시 프롬프트에 추가하여 모델에 재질의합니다.
모델은 추가된 정보를 바탕으로 다음 행동을 결정하며, 더 이상의 도구 호출이 필요 없을 때까지 이 루프를 반복합니다. 최종적으로 어시스턴트 메시지가 출력되면 에이전트의 한 턴(Turn)이 완료되고 제어권이 다시 사용자에게 돌아옵니다.
모델 추론(Model Inference)과 엔드포인트 전략
Codex CLI는 로컬 환경과 클라우드 모델 사이의 가교 역할을 수행하며, 이를 위해 OpenAI의 Responses API를 핵심 엔진으로 사용합니다. 에이전트 루프의 첫 단추인 모델 추론은 단순한 텍스트 생성을 넘어 에이전트가 다음에 취할 행동(도구 호출 또는 응답)을 결정하는 지능적 판단 과정입니다. Codex는 사용자의 인증 방식과 실행 환경에 따라 최적의 엔드포인트를 선택하여 요청을 보냅니다.
사용자가 ChatGPT 계정으로 로그인한 경우 https://chatgpt.com/backend-api/codex/responses를 사용하며, 일반적인 OpenAI API 키를 사용하는 개발자에게는 https://api.openai.com/v1/responses를 기본 엔드포인트로 제공합니다. 특히 로컬 개발 생태계와의 호환성을 위해 gpt-oss 모드를 지원하는데, 이는 Ollama나 LM Studio 같은 로컬 추론 엔진과 연동되어 http://localhost:11434/v1/responses를 통해 사설 환경에서도 에이전트 기능을 활용할 수 있게 합니다.
정교한 프롬프트 구조와 역할 정의
Codex가 모델에 보내는 프롬프트는 단순한 텍스트 뭉치가 아니라, 각 요소가 명확한 역할(Role)을 가진 체계적인 데이터 구조입니다.
Responses API는 클라이언트가 전달한 정보를 바탕으로 system, developer, user, assistant 순의 우선순위를 가진 리스트를 구성하여 모델의 컨텍스트를 형성합니다.
초기 컨텍스트 구축

에이전트 루프(Agent Loop)가 시작될 때 Codex는 대화의 기초가 되는 지침들을 input 항목으로 구성합니다. 여기에는 가장 먼저 Codex 전용 shell 도구의 샌드박스 정책을 설명하는 developer 메시지가 포함됩니다.
이 메시지는 모델이 로컬 시스템의 파일을 수정하거나 네트워크에 접근할 때 지켜야 할 가이드라인과 사용자 승인 절차를 정의합니다. 그 뒤를 이어 사용자의 config.toml에서 읽어온 개별 지침들이 추가됩니다.
다층적 사용자 지침의 통합
사용자 지침은 단일 파일이 아닌 여러 소스에서 수집되어 계층적으로 쌓입니다. $CODEX_HOME에 위치한 전역 설정 파일인 AGENTS.md부터 프로젝트 루트 디렉토리의 특정 지침들까지 순차적으로 결합됩니다. Codex는 현재 작업 디렉토리(CWD)에서 상위 디렉토리로 올라가며 관련 문서를 탐색하며, 최대 32KiB까지의 정보를 취합하여 모델에게 현재 프로젝트의 맥락을 주입합니다.
만약, 특정 기술(Skills)이 설정되어 있다면 해당 스킬의 메타데이터(Metadata)와 어떻게 스킬을 사용해야 하는지도 이 단계에서 포함됩니다.
프롬프트 캐싱과 성능의 경제학

에이전트 루프가 반복될수록 프롬프트의 길이는 기하급수적으로 늘어납니다. 이는 모델 추론 비용의 상승과 응답 지연을 초래할 수 있는데, Codex는 이를 방지하기 위해 프롬프트 캐싱(Prompt Caching) 기술을 극한으로 활용합니다.
프롬프트 캐싱은 이전 요청과 정확히 일치하는 접두사(Prefix)가 발견될 경우 해당 연산 결과를 재사용하는 방식입니다. Codex는 이 캐시 적중률을 극대화하기 위해 고정된 지침과 도구 정의를 프롬프트의 가장 앞부분에 배치하고, 가변적인 사용자 입력과 도구 실행 결과는 뒤쪽에 배치하는 전략을 고수합니다.
하지만 이러한 캐싱 구조는 매우 민감하여 사소한 변경만으로도 캐시 미스(Cache Miss)가 발생할 수 있습니다. 예를 들어 대화 도중 사용할 수 있는 도구(Tools)의 목록이 바뀌거나, 타겟 모델이 변경되거나, 심지어 작업 디렉토리가 바뀌는 것만으로도 수천 개의 토큰에 대한 연산을 새로 수행해야 할 수 있습니다. Codex 팀은 이를 방지하기 위해 MCP(Model Context Protocol) 도구의 순서를 일관되게 유지하고, 환경 변화가 발생할 경우 기존 프롬프트를 수정하는 대신 새로운 메시지를 뒤에 덧붙이는 방식을 채택하여 기존 캐시를 보호합니다.
데이터 보안과 Zero Data Retention (ZDR)

기업 환경에서 에이전트를 사용할 때 가장 큰 우려는 데이터의 저장과 유출입니다. Codex는 ZDR(Zero Data Retention) 설정을 완벽하게 지원하도록 설계되었습니다. 일반적으로 Responses API는 상태 유지를 위해 previous_response_id라는 매개변수를 지원하지만, Codex는 이를 의도적으로 사용하지 않습니다.
모든 요청을 상태 비저장(Stateless) 방식으로 처리함으로써, 서버가 사용자의 대화 데이터를 영구적으로 저장할 필요가 없도록 만듭니다. ZDR 모드에서 작동할 때 모델의 내부 사고 과정(Reasoning) 데이터는 암호화된 상태(encrypted_content)로 클라이언트에 전달되며, 다음 대화 시에 다시 서버로 전송되어 모델의 이해도를 복원합니다. 이 과정에서 OpenAI는 복호화 키만 일시적으로 관리할 뿐 사용자의 원본 데이터는 저장하지 않으므로 보안과 성능의 균형을 맞출 수 있습니다.
컨텍스트 윈도우 압축과 효율적 대화 유지
장기간 지속되는 코딩 작업에서는 모델의 컨텍스트 한계를 넘어서는 경우가 빈번합니다. Codex는 이를 관리하기 위해 자동 압축(Auto Compaction) 메커니즘을 사용합니다. 토큰 수가 특정 임계치(auto_compact_limit)를 초과하면 Codex는 /responses/compact 엔드포인트를 호출합니다.
이 압축 과정은 단순히 대화 이력을 삭제하는 것이 아니라, 전체 문맥의 '잠재적 이해(Latent Understanding)'를 보존하는 특수한 압축 항목을 생성합니다. 이 항목은 암호화된 불투명한 데이터 형태로 대화 이력의 상단에 위치하게 되며, 이를 통해 에이전트는 수천 줄의 코드 맥락을 잃지 않으면서도 새로운 작업을 수행할 수 있는 충분한 컨텍스트 여유 공간을 확보하게 됩니다.
 OpenAI Codex 홈페이지
OpenAI Codex 홈페이지
 OpenAI Codex 개발자 문서
OpenAI Codex 개발자 문서
 OpenAI Codex의 Agent Loop 심층 분석 블로그
OpenAI Codex의 Agent Loop 심층 분석 블로그
https://openai.com/index/unrolling-the-codex-agent-loop/
 OpenAI Codex GitHub 저장소
OpenAI Codex GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()