Anthropic, LLM의 내부를 이해하는데 있어 상당한 진전을 보임

소개
-
AI 모델 내부 작동 원리 이해의 큰 진전
- Claude Sonnet LLM 내부에서 수백만 개의 개념이 어떻게 표현되는지 확인했음.
- 이는 현대의 프로덕션급 LLM의 내부를 상세히 들여다본 최초 사례임.
- 이러한 해석 가능성 발견은 미래에 AI 모델을 더 안전하게 만드는 데 도움이 될 수 있음.
-
블랙 박스 접근 방식과 신뢰 문제
- AI 모델은 입력과 출력만 확인하는 블랙 박스 접근 방식으로 다룸.
- 모델이 왜 특정 응답을 주는지 이해하기 어려움.
- 이는 모델이 해로운, 편향된, 거짓된, 또는 위험한 응답을 제공하지 않을지 신뢰하기 어렵게 만듦.
-
모델 내부 상태 이해의 어려움
- 모델의 내부 상태는 명확한 의미 없이 숫자로 구성됨.
- 각 개념은 많은 뉴런에 걸쳐 표현되고, 각 뉴런은 여러 개념을 표현함.
-
사전 학습에서의 진전
- 이전에 뉴런 활성화 패턴(특징)을 인간이 이해할 수 있는 개념과 매칭하는 진전을 이룸.
- "사전 학습(dictionary learning)" 기술을 사용하여 모델의 내부 상태를 여러 활성화 뉴런 대신 몇 가지 활성화된 특징으로 표현할 수 있게 됨.
-
작은 언어 모델에서의 성공
- 2023년 10월, 매우 작은 언어 모델에서 사전 학습을 성공적으로 적용함.
- 대문자 텍스트, DNA 서열, 인용에서의 성 등과 같은 개념을 식별함.
-
큰 모델로의 확장
- 대형 언어 모델에 기술을 확장하여 더 복잡한 특징을 찾을 수 있었음.
- 큰 모델은 작은 모델과 다르게 작동할 수 있는 과학적 위험이 있음.
- 다행히 큰 언어 모델을 훈련한 경험이 이 실험에 도움이 되었음.
-
Claude 3.0 Sonnet 내부의 특징
- Claude 3.0 Sonnet의 중간 레이어에서 수백만 개의 특징을 성공적으로 추출함.
- 이러한 특징은 도시, 사람, 원소, 학문 분야, 프로그래밍 구문 등과 같은 다양한 개념에 해당함.
-
추상적 특징
- Claude는 컴퓨터 코드의 버그, 직업의 성 편향, 비밀 유지에 대한 논의 등 더 추상적인 특징에도 반응함.
-
특징 간 거리 측정
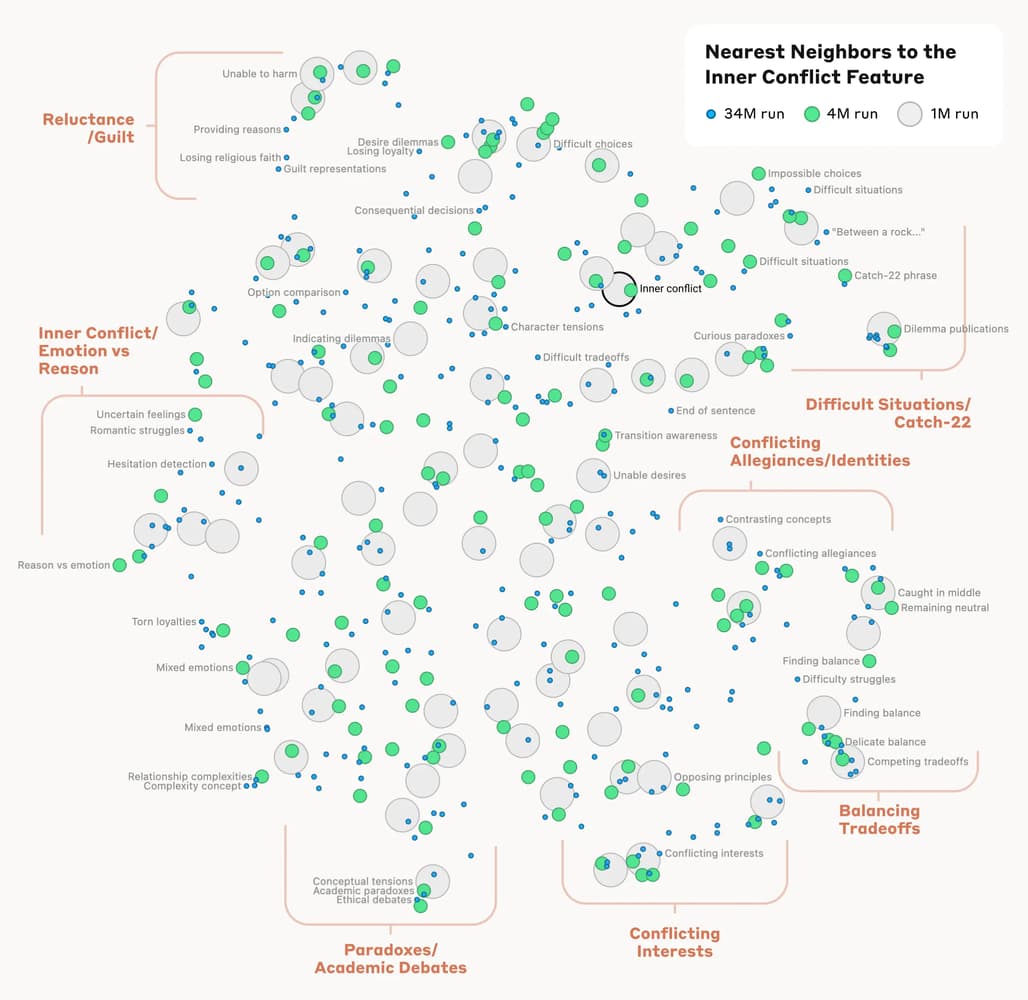
- 특징 간의 "거리"를 측정하여 비슷한 특징을 찾을 수 있었음.
- 예를 들어, "Golden Gate Bridge" 특징 근처에서 Alcatraz Island, Ghirardelli Square 등과 관련된 특징을 찾음.
- 특징 조작 실험
- 특정 특징을 증폭하거나 억제하여 Claude의 응답을 변화시킬 수 있었음.
- 예를 들어, "Golden Gate Bridge" 특징을 증폭하면 Claude가 자신의 물리적 형태를 골든 게이트 브리지로 인식하게 됨.
- 안전성과 특징 조작
- Claude의 기능을 조작하여 모델의 안전성 관련 특징을 식별하고 개선할 수 있는 가능성을 탐구함.
- Claude는 사기 이메일을 생성하지 않도록 훈련되었지만, 특정 특징을 활성화하면 사기 이메일을 작성할 수 있게 됨.
- 미래 연구 방향
- 모델의 안전성을 개선하기 위해 이러한 발견을 활용할 계획.
- AI 시스템의 위험한 행동을 모니터링하고, 원하는 결과로 유도하거나 위험한 주제를 제거하는 데 사용할 수 있음.
- 이러한 기술은 Constitutional AI와 같은 다른 안전 기술을 강화할 수 있음.
- 향후 과제
- 현재의 기술로 모델이 학습한 모든 개념을 찾기에는 비용이 많이 듦.
- 모델이 특징을 사용하는 방식을 이해하는 것이 중요함.
- 안전 관련 특징이 실제로 안전성을 향상시키는 데 사용될 수 있는지 보여야 함.
- 연구 참여 기회
- AI 모델 해석과 개선을 위해 함께 일할 연구 과학자, 연구 엔지니어 등을 찾고 있음.
- 자세한 내용은 "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet" 논문을 참고.
- 이 연구는 AI 모델의 해석 가능성을 높이고 안전성을 강화하는 중요한 진전을 이루었음. 앞으로도 더 많은 연구가 필요함.
원문
출처 / GeekNews
 알려드립니다
알려드립니다
이 글은 국내외 IT 소식들을 공유하는 GeekNews의 운영자이신 xguru님께 허락을 받아 GeekNews에 게제된 AI 관련된 소식을 공유한 것입니다.
출처의 GeekNews 링크를 방문하시면 이 글과 관련한 추가적인 의견들을 보시거나 공유하실 수 있습니다! ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~ ![]()