들어가며 

지난 5월 Anthropic에서 LLM 내부를 이해하기 위한 노력의 결과를 공개한데 이어, OpenAI와 Google 등에서도 유사한 연구들을 공개했었습니다:
- OpenAI, 2024/06: [2406.04093] Scaling and evaluating sparse autoencoders
- Google, 2024/08: [2408.05147] Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
이러한 프로젝트에 이어, Meta의 Llama 3.2 모델에 대해서도 유사한 시도를 진행한 연구가 있어 공유드립니다. ![]()
Llama3 Interpretability w/ SAE 프로젝트 소개
Paul Pauls의 llama3_interpretability_sae 프로젝트는 Sparse Autoencoders(SAEs)를 활용하여 Llama 3.2-3B 모델에서 명확하고 해석 가능한 특징을 추출하는 전체 파이프라인을 제공합니다.
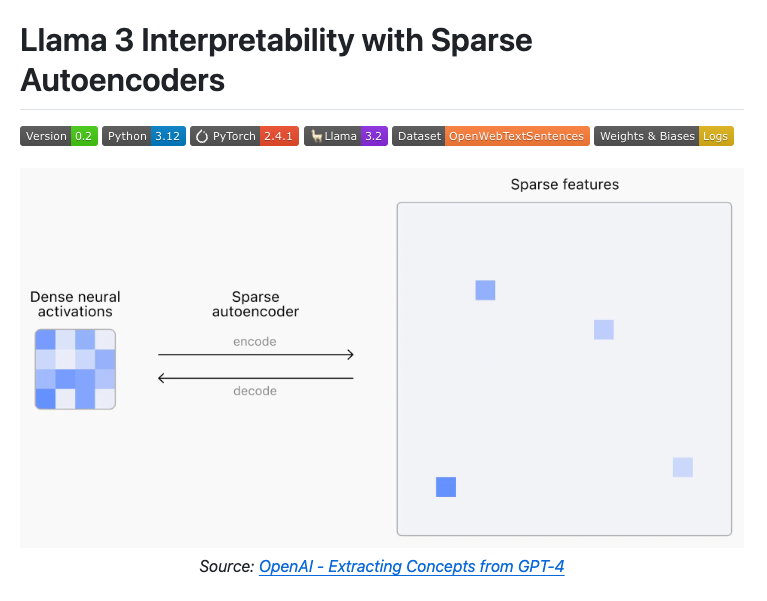
현대의 대규모 언어 모델(LLM)들은 뉴런 내에 여러 특징을 중첩(Superimpose)하여 개념을 인코딩하고 있습니다. 이를 해석할 때는 각 계층 내 모든 뉴런의 선형 중첩(Linear Superposition)을 분석해 문맥에 따라 뉴런이 다르게 활성화되는 방식으로 다양한 의미를 전달합니다. 이러한 방식을 슈퍼포지션(Superposition)이라 하며, 각 뉴런은 여러 해석 가능한 의미를 가지게 됩니다.

출처: OpenAI - Extracting Concepts from GPT-4
그러나 이러한 중첩 구조는 뉴런의 활성화를 명확히 해석하기 어렵게 합니다. Sparse Autoencoders(SAEs)는 이러한 중첩 표현을 해체해 뉴런의 활성화를 희소하고 명확한 특징으로 분리합니다. 이를 통해 각 뉴런이 하나의 명확한 개념만을 나타내도록 만들어 '단일 의미(Monosemantic)'를 나타내도록 합니다. 즉, 각 뉴런이 어떠한 개념을 나타내는지를 해석 가능(Interpretability)해지므로, 모델이 특정 입력에 대해서 어떻게 반응하는지를 더 명확히 이해할 수 있게 됩니다. 또한, 환각(Hallucination)의 원인을 확인하고 개선할 수 있을 것으로 기대합니다.
이 프로젝트는 다음과 같은 기능들을 구현 및 제공하며 Anthropic, OpenAI, Google DeepMind가 제안한 LLM 해석 가능성 연구를 재현하고 발전시키는 데 중점을 두고 있습니다:
-
Llama3 커스터마이징(Custom Llama Implementation)
- PyTorch 중심으로 모델을 재작성하며 특정 레이어의 활성화 상태를 캡쳐하고 SAE를 삽입하는 기능 등을 추가했습니다. 변경한 llama_3_inference.py를 포함하여 프로젝트의 llama_3/ 내부의 코드들을 확인해보세요.
-
데이터 캡처 (Data Capture):
- OpenWebText의 커스텀 문장 데이터셋을 사용하여 Llama 3.2-3B의 (전체 28개의 레이어 중) 23번째에서 활성화 데이터(최대 192 토큰 / 평균 27.3의 25M 문장)를 수집하였습니다.
-
SAE 구현 및 학습 (SAE Implementation)
- 인코더-디코더 기반의 Top-K(=64) 활성화 함수로 희소성을 제어하며 이전 단계에서 수집한 SAE를 학습.
-
해석 가능성 분석 (Interpretability Analysis)
- Anthropic의 기존 연구에서 제안한 방법을 기반으로 하되, 토큰이 아닌 문장 단위의 분석을 통해 해석 가능성을 분석
- 예를 들어, #896 잠재 변수(latent)는 'UN 기관, 인력, 운영 및 공식 문서 등을 참조*(References to United Nations institutions, personnel, operations, or official documentation using formal institutional terminology)*'하고 있었습니다. 상세 분석 결과는 다음과 같습니다:
<semantic_analysis> 1. Key Word Analysis: - Frequent terms: "UN", "United Nations", "Secretary-General" - Official titles: "Special Rapporteur", "Under-Secretary-General", "Coordinator" - Department names: "UNDP", "UNHCR", "OCHA", "UNODC" 2. Thematic Grouping: - UN organizational structure references - UN personnel and positions - UN reports and documentation - UN agencies and bodies - UN operations and activities 3. Pattern Analysis: - All sentences reference UN entities, personnel, or activities - Formal institutional language - Heavy use of official titles and department names - References to official documents and reports 4. Strength Assessment: - 50 out of 50 sentences contain direct UN references - Mix of department names, personnel titles, and activities - Consistent institutional terminology - No outliers identified 5. Certainty Calculation: - 100% of sentences contain UN references - Very strong institutional terminology consistency - Clear organizational focus - Direct and explicit connections The analysis reveals that every sentence relates to United Nations organizations, personnel, operations, or documentation, with extremely consistent institutional terminology and structure. The commonality is both obvious and comprehensive. </semantic_analysis>
-
결과 검증 (Verification and Testing)
- SAE(Sparse Autoencoder)가 모델 행동에 미치는 영향을 검증하고 분석하기 위해 다음 세 가지 주요 테스트 스크립트를 사용하여 실험적으로 결과를 검증하였습니다:
- llama_3_inference_chat_completion_test.py: 채팅 생성 작업에서 잠재 변수 활성화와 SAE의 영향을 검증하였습니다.
- llama_3_inference_text_completion_test.py: 텍스트 생성 작업에서 SAE를 활용한 분석을 수행합니다.
- llama_3_inference_text_completion_gradio.py: 사용자 친화적인 Gradio UI로 텍스트 생성 및 특징 조작(feature steering) 시뮬레이션을 지원합니다.
현재 이 프로젝트는 Llama 3.2-3B 모델에 대한 SAE 구현과 데이터셋, 학습된 모델, 전체 파이프라인 코드를 포함하고 있습니다. 그러나 이 작업은 많은 계산 자원과 비용이 필요한 비영리 프로젝트로, 현재 버전(0.2)은 효율적이고 확장 가능하지만 아직 최종 단계는 아닙니다. 향후 업데이트를 통해 지속적으로 개선될 예정이며, 코드나 피드백을 통해 누구나 기여할 수 있습니다.
프로젝트가 공개한 주요 리소스
이 프로젝트는 연구 및 실험을 재현하거나 향후 연구 확장에 활용할 수 있는 기초 데이터를 다음과 같이 제공합니다:
OpenWebText 문장 데이터셋 (OpenWebText Sentence Dataset)
- OpenWebText 데이터셋의 커스텀 버전
- 활성화 데이터 캡처를 목적으로 설계
- 원본 텍스트 데이터 유지 및 순서 보존
- Parquet 형식으로 저장하여 빠르게 접근 가능
- NLTK 3.9.1의 사전 학습된 “Punkt” 토크나이저를 사용해 문장 분리
캡처된 Llama 3.2-3B 활성화 데이터 (Captured Llama 3.2-3B Activations)
- 2,500만 문장에 대한 Llama 3.2-3B의 23번째 레이어 잔여 활성화 데이터
- 전체 데이터의 크기는 4TB으로, 압축 후에는 3.2TB 규모
- 100개로 분할하여 더 용이하게(manageable) 다운로드 가능
SAE 학습 로그
- Weights & Biases를 사용해 학습, 검증, 디버깅 지표 시각화 결과
- 10 epoch의 학습 과정 동안 10,000번의 단계를 기록함
- train/val 주 손실(main loss), 보조 손실(auxiliary loss) 및 학습 중 사용하지 않는 잠재(dead latent) 통계
학습된 SAE 모델 (Trained 65,536 latents SAE Model)
- 10 epoch 학습을 완료한 최종 SAE 모델
- 학습 구성에 따라 Llama 3.2-3B의 23번째 레이어의 활성화 데이터 6.5B (6.5B activations)
향후 연구 방향 및 개선 사항
- 잠재 공간 확장 및 희소성 강화: 계산 요구량 증가 문제를 해결하기 위해 효율성을 개선하거나 변화도 누적(gradient accumulation) 기법 도입 필요.
- 활성화 추적 및 분석 강화: latent_last_nonzero 텐서를 학습 중 자주 기록하여 잠재 변수 활성화 상태를 추적하여 복합 의미 표현(complex semantic representations)에 대한 이해 증진
- 고급 해석 가능성 분석 개발: 미묘한 의미적 특징을 더 잘 추출하고 모델의 정보 표현 방식을 개선하고 특징 추출뿐만 아니라 특징 조작(feature steering)의 해석 가능성도 연구
- Llama 3.1-8B 모델로 확장: 동일한 코드베이스를 사용하는 Llama 3.1-8B 모델로 실험을 확장하여 더 큰 모델에서의 잠재 변수와 특징의 변화 연구
- 다양한 활성화 캡처 지점 실험: 모델의 깊이(특히 초기 레이어) 또는 Transformer 블록 내 다양한 지점에서 활성화를 캡처하여 특정 레이어의 정보 흐름과 의미 표현 변화를 더 잘 이해
- 보조 손실 메커니즘 최적화: 현재 보조 손실(auxiliary loss) 메커니즘은 죽은 잠재를 복구하는 데 매우 효과적이므로, 사용하지 않는 활성화의 최소 임계값(minimum dead latents threshold)이 특징 품질(feature quality)에 미치는 영향을 분석
- SAE 구조 및 손실 함수 개선: 편향(bias) 및 주 손실(main loss) 함수를 조정하여 학습 안정성 향상 및 해석 가능성 강화
- 코드베이스 개선: 코드베이스 전반에 적절한 docstring을 추가하여 코드 가독성과 유지보수성의 강화
 Llama3 Interpretability w/ SAE 프로젝트 GitHub 저장소
Llama3 Interpretability w/ SAE 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()