GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개

- GPT-4(32k), MPT(65k), Calude(100k) 등 더 긴 컨텍스트를 가진 언어모델이 출현
- 트랜스포머의 컨텍스트 길이를 확장하는 것은 런타임&메모리 요구사항이 4제곱으로 증가하기 때문에 어려움
- 작년에 출시한 FlashAttention은 메모리 사용량을 줄이고 어텐션 속도를 증가시켜서 다양한 곳에서 이용됨
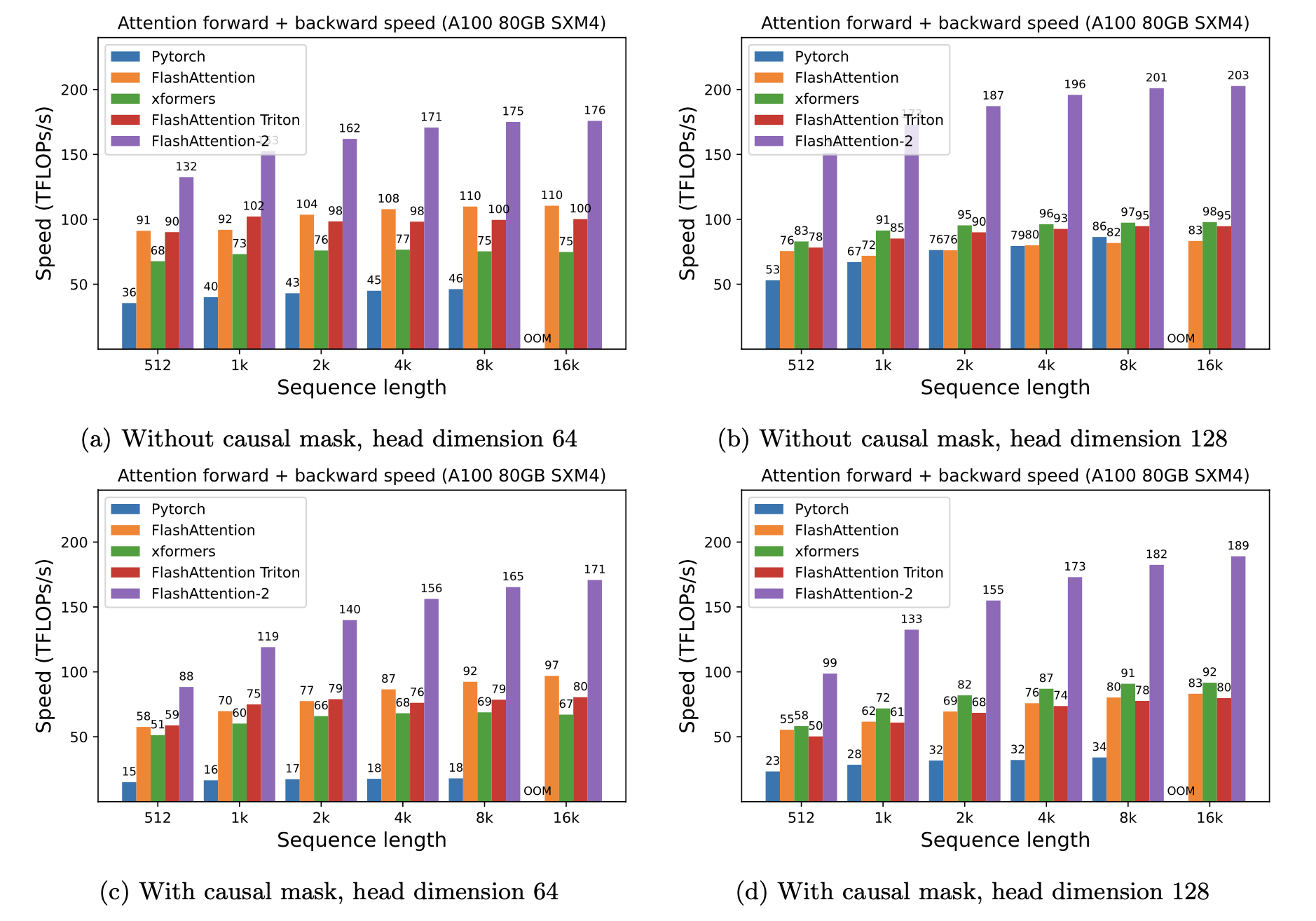
- 출시 당시에 이미 2~4배 빨랐지만, 아직 개선할 여지가 있음. 최적화된 행렬 곱 연산(GEMM)에 비해 여전히 빠르지 않고, 이론상 최대 FLOPs/s 의 25~40%에 불과(A100 GPU에서 최대 124 TFLOPs/s)
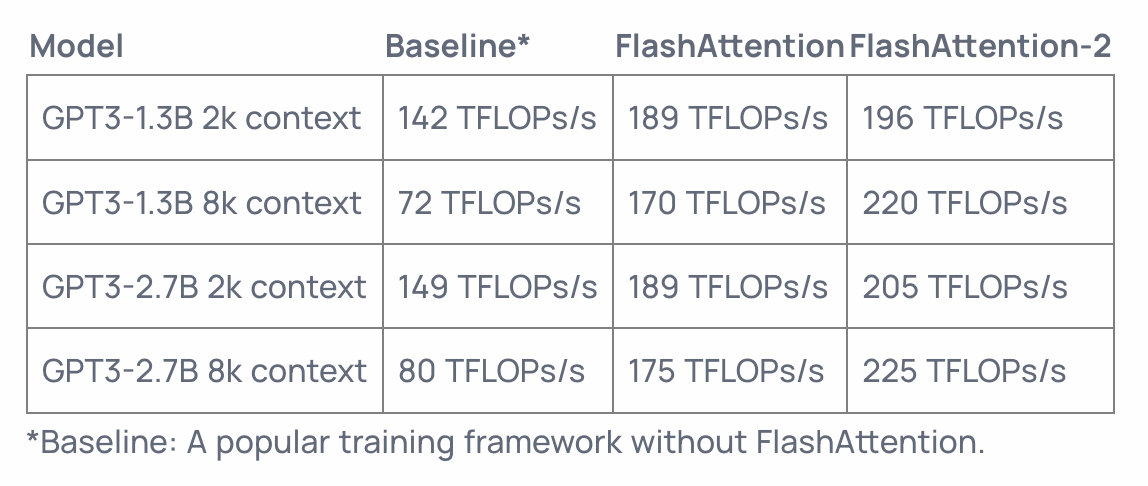
- FlashAttention-2는 이전 버전보다 2배 빠르고, A100 GPU에서 최대 230 TFLOP/s 의 성능을 제공
- GPT 형태의 언어모델 훈련에서는 최대 225 TFLOPS까지 도달했음(72% 모델 FLOP 활용도)
- 알고리듬을 조정하여 non-matmul FLOPs를 줄였음
- 더 나은 병렬화, 각 스레드 블록에서의 작업 분할방법 변경
- Head Dimensions 개수를 128에서 256개로 확장
원문
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning