GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
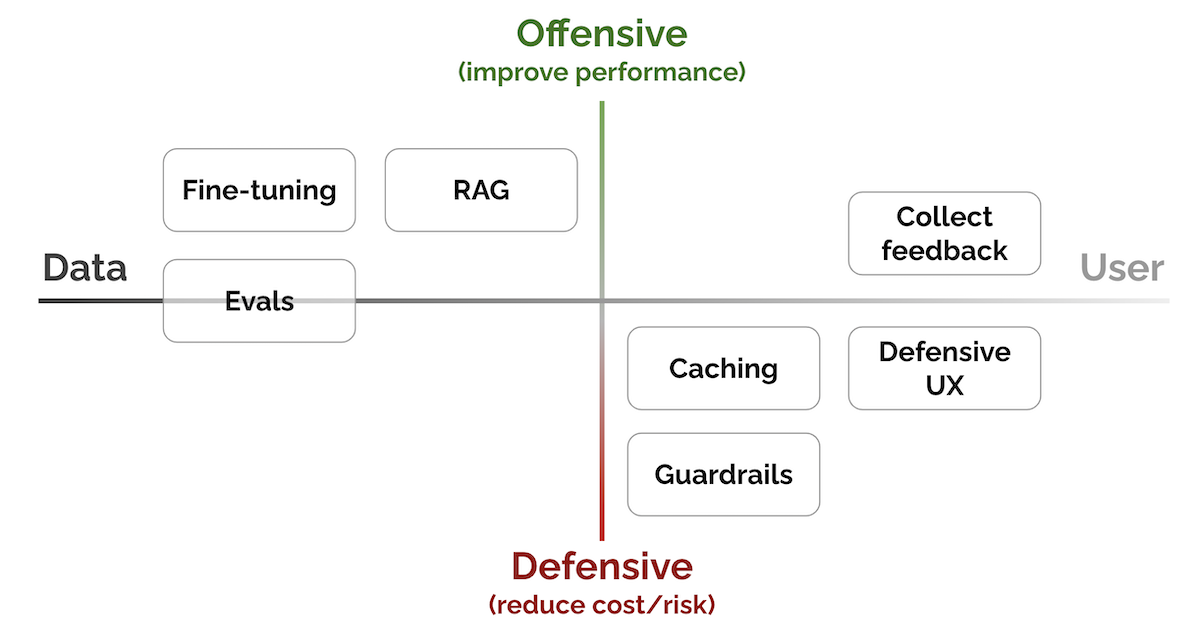
- 7가지 핵심 패턴을 "성능 향상 vs. 비용/리스크 감소" 및 "데이터 친화 vs 사용자 친화" 로 정리
- Evals: 성능 측정
- RAG(Retrieval-Augmented Generation): 최신, 외부 지식을 추가
- Fine-tuning: 특정 작업을 더 잘 수행하기 위해
- Caching: 레이턴시 및 비용 감소
- Guardrails: 출력 품질 보장
- Defensive UX: 오류를 에측하고 관리하기 위해
- Collect user feedback: 데이터 플라이 휠 구축
Evals: 성능 측정
- Evals는 작업에서 모델의 성능을 평가하는데 사용되는 일련의 측정값들
- 벤치마크 데이터 및 메트릭 포함
- 시스템 또는 제품이 얼마나 잘 작동하고 있는지 측정하고, 퇴보를 감지할 수 있음
- 언어 모델링 분야에 많은 벤치마크들이 있음: MMLU, EleutherAI Eval, HELM, AlpacaEval
- 메트릭을 두개의 카테고리로 구분 가능: Context-dependent 또는 Context-free
- 공통적으로 사용하는 메트릭들: BLEU, ROUGE, BERTScore, MoverScore
- 요즘 뜨는 트렌드는 강력한 LLM을 reference-free metric으로 이용하여 다른 LLM들의 생성물을 평가하는 것
- G-Eval, Vicuna 논문, QLoRA
RAG(Retrieval-Augmented Generation): 최신, 외부 지식을 추가
- 파운데이션 모델 외부로부터 정보를 가져와 이 데이터로 입력을 강화하여 더 풍부한 컨텍스트를 제공함으로써 출력을 개선
- RAG는 검색된 컨텍스트에 모델을 기반으로 하여 환각을 줄이는데 도움을 줘서 사실성을 높임
- 또한 LLM을 지속적으로 사전 학습하는 것보다 검색 인덱스를 최신 상태로 유지하는 것이 더 저렴
- 이런 비용 효율성 때문에 LLM이 RAG을 통해 최신 데이터에 억세스 가능
- 편향되거나 유해한 문서와 같은 데이터를 업데이트/제거해야 하는 경우 검색 인덱스를 업데이트하는 것이 더 간단함(LLM을 미세조정 하는 것에 비해)
- RAG을 위해서는 텍스트 임베딩에 대해 먼저 이해하는 것이 도움이 됨
- 텍스트 임베딩은 임의 길이의 텍스트를 숫자의 고정 크기 벡터로 표현할 수 있는 텍스트 데이터의 압축된 추상 표현
- 일반적으로 Wikipedia같은 텍스트 코퍼스에서 학습함
- 유사한 항목은 서로 가깝고, 유사하지 않은 항목은 더 멀리 떨어져 있는 텍스트에 대한 범용 인코딩으로 생각하면 됨
- 좋은 임베딩은 유사 항목 검색 같은 다운스트림 작업을 잘 수행하는 것
- Huggingface의 Massive Text Embedding Benchmark (MTEB)는 분류,클러스터링,검색,요약 같은 다양한 작업에서 모델의 점수를 매김
- 여기서는 주로 텍스트 임베딩에 대해 이야기 하지만, 임베딩은 다양한 모달리티가 사용될 수 있음
- Fusion-in-Decoder(FiD)는 오픈 도메인 QA를 위해 생성형 모델과 검색을 같이 사용함
- Internet-augmented LM들은 기존 검색엔진을 이용하여 LLM 강화를 제안
- RAG 적용 방법
- 하이브리드 검색(전통적인 검색 인덱스 + 임베딩 기반 검색)이 각각 단독보다 더 잘 동작함
Fine-tuning: 특정 작업을 더 잘 수행하기 위해
- 미세 조정은 사전 훈련된 모델(방대한 양의 데이터로 이미 훈련된 모델)을 가져와 특정 작업에 대해 추가로 정제하는 프로세스
- 모델이 사전 훈련 중에 이미 획득한 지식을 활용하여 일반적으로 더 작은 작업별 데이터 세트를 포함하는 특정 작업에 적용하기 위함
- 파인 튜닝이란 용어는 느슨하게 사용되어 다양한 개념을 나타내는데 이용 됨
- 지속적인 사전 훈련
- 인스트럭션 파인 튜닝
- 단일 작업 파인 튜닝
- RLHF
- 왜 파인 튜닝을 할까 ?
- 성능 및 제어:
- 기성 기본 모델의 성능을 개선하고, 써드파티 LLM 능가도 가능
- LLM 동작을 보다 잘 제어할 수 있으므로 시스템이나 제품이 더욱 강력해짐
- 미세 조정을 통해 단순히 타사 또는 개방형 LLM을 사용하는 것과 차별화된 제품을 구축할 수 있음
- 모듈화:
- 단일 작업 미세 조정을 통해 각각 고유한 작업을 전문으로 하는 더 작은 모델들의 부대를 만들 수 있음
- 이런 설정을 통해서 시스템을 콘텐츠 모더레이션, 추출, 요약등의 태스크로 모듈화 가능
- 종속성 감소:
- 자체 모델을 미세 조정하고 호스팅함으로써 외부 API에 노출되는 독점 데이터(예: PII, 내부 문서 및 코드)에 대한 법적 문제를 줄일 수 있음
- 또한 속도 제한, 높은 비용 또는 지나치게 제한적인 안전 필터와 같은 써드파티 LLM의 제약 조건을 극복
- 성능 및 제어:
- Generative Pre-trained Transformers (GPT; decoder only)
- Text-to-text Transfer Transformer (T5; encoder-decoder)
- InstructGPT
- Soft prompt tuning & Prefix Tuning
- Low-Rank Adaptation (LoRA) & QLoRA
- 파인튜닝 적용 방법
- 데모 데이터/라벨 수집
- 평가지표를 정의
- 사전 학습 모델 선택
- 모델 아키텍처 업데이트
- 파인 튜닝 방법 선택(LoRA, QLoRA등 )
- 기본 하이퍼파라미터 튜닝
Caching: 레이턴시 및 비용 감소
- 캐싱은 이전에 검색하거나 계산한 데이터를 저장하는 기술
- 동일한 데이터에 대한 향후 요청을 더 처리 가능
- LLM에서는 입력 요청의 임베딩에 대한 LLM 응답을 캐쉬하고, 다음 요청에서 의미상 유사한 요청이 들어오면 캐시된 응답을 제공하는 것
- 하지만 일부 실무자는 이게 "재앙이 일어나길 기다리는 것" 과 같다고 함. 나도 동의함
- 캐싱 패턴을 채택하기 위한 핵심은 의미론적 유사성에만 의존하는 대신, 안전하게 캐시하는 방법을 파악하는 것
- 왜 캐싱해야 할까? : 대기시간을 줄이고, LLM 요청수를 줄여서 비용을 절감
- 캐싱을 적용하는 방법?
- 사용자 요청 패턴을 잘 이해하는 것 부터 시작해야함
- 캐싱이 사용 패턴에 효과적인지 고려
Guardrails: 출력 품질 보장
- LLM의 출력을 검증하여 출력이 좋게 보일 뿐만 아니라 구문적으로 정확하고 사실적이며 유해한 콘텐츠가 없는지 확인
- 왜 가드레일이 필요할까?
- 모델 출력이 생산에 사용할 수 있을 만큼 신뢰할 수 있고 일관성이 있는지 확인하는 데 도움이 됨
- 추가 안전 계층을 제공하고 LLM의 출력에 대한 품질 관리를 유지
- 한 가지 접근 방식은 프롬프트를 통해 모델의 응답을 제어하는 것
- Anthropic은 모델이 도움이 되고 무해하며 정직한 (HHH) 응답을 생성하도록 안내하도록 설계된 프롬프트를 공유했음
- 보다 일반적인 접근 방식은 출력의 유효성을 검사하는 것 (Guardrails 패키지 같은)
- Nvidia의 NeMo-Guardrails는 유사한 원칙을 따르지만 LLM 기반 대화 시스템을 안내하도록 설계
- Microsoft의 Guidance 처럼 특정 문법을 준수하도록 출력을 직접 조정할 수도 있음 (LLM을 위한 DSL이라고 생각할 수 있음)
- 가드레일을 적용하는 방법
- Structural guidance
- Syntactic guardrails
- Content safety guardrails
- Semantic/factuality guardrails
- Input guardrails
Defensive UX: 오류를 예측하고 관리하기 위해
- 방어적 UX는 사용자가 기계 학습 또는 LLM 기반 제품과 상호 작용하는 동안 부정확성이나 환각과 같은 나쁜 일이 발생할 수 있음을 인정하는 디자인 전략
- 주로 사용자 행동을 안내하고, 오용을 방지하고, 오류를 적절하게 처리함으로써 이를 미리 예측하고 관리하는 것이 목표
- 왜 방어적인 UX인가?
- 기계 학습과 LLM은 완벽하지 않음. 부정확한 결과를 생성할 수 있음
- 같은 질문에 대해서 다르게 반응함
- 방어적 UX는 다음을 제공하여 위의 문제를 완화하는 데 도움
- 접근성 향상, 신뢰도 증가, Better UX
- 회사들이 정리한 지침 참조
- Microsoft’s Guidelines for Human-AI Interaction
- Google’s People + AI Guidebook
- Apple’s Human Interface Guidelines for Machine Learning
- 방어적 UX를 적용하는 방법
- 올바른 기대치를 설정하기
- 효율적인 해제를 가능하게 하기(Enable efficient dismissal)
- Attribution 제공
- Anchor on familiarity
Collect user feedback: 데이터 플라이 휠 구축
- 사용자 피드백을 수집하면 사용자의 선호도를 알 수 있음
- LLM 제품에 특정한 사용자 피드백은 평가, 미세 조정 및 가드레일 구축에 기여함
- 사전 교육을 위한 Corpus, 전문가가 만든 데모, 보상 모델링에 대한 인간의 선호도와 같은 데이터는 LLM 제품의 몇 안 되는 해자(Moat)임
- 피드백은 명시적이거나 암시적일 수 있음
- 명시적 피드백은 제품의 요청에 대한 응답으로 사용자가 제공하는 정보
- 암시적 피드백은 사용자가 의도적으로 피드백을 제공할 필요 없이 사용자 상호 작용에서 학습하는 정보
- 사용자 피드백을 수집하는 이유
- 사용자 피드백은 모델을 개선하는 데 도움이 됨
- 사용자가 좋아하는 것, 싫어하는 것 또는 불평하는 것을 학습함으로써 모델을 개선하여 그들의 요구 사항을 더 잘 충족시킬 수 있음
- 또한 개인의 선호도에 적응할 수 있음
- 피드백 루프는 시스템의 전반적인 성능을 평가하는 데 도움이 됨
- 사용자 피드백 수집 방법
- 사용자가 쉽게 피드백을 남길 수 있게 만들기: ChatGPT처럼 응답에 추천/비추천 선택
- 암시적 피드백도 고려하기 : 사용자가 제품과 상호 작용할 때 발생하는 정보