9bow
(박정환)
1
GeekNews의 xguru 님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. 
소개

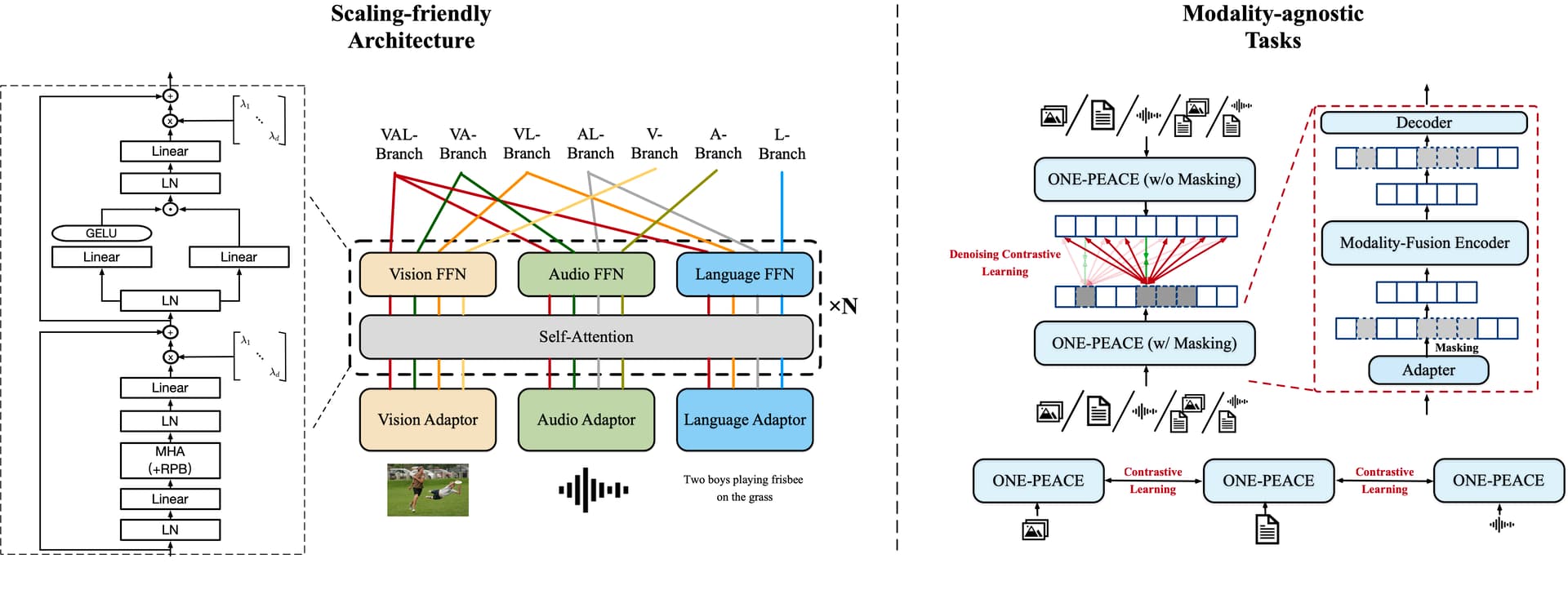
- 비젼, 오디오, 언어 모달리티를 모두 아우르는 General Represenation Model
- 사전학습된 모델 없이도 통합된 작업들에 훌륭한 결과를 냄
- 강력한 Emergent Zero-shot Retrieval로 훈련 데이터에서 페어링 되지 않은 모달리티를 얼라인 가능
- Audio-to-Image, Audtio+Text-to-Image, Audio+Image-to-Image
원문

https://github.com/OFA-Sys/ONE-PEACE
9bow
(박정환)
2
어제 소개드렸던 TLDR AI 뉴스에도 포함된 내용인데요,
ONE-PEACE 논문은 아래에서,
이미지를 기준으로 하나의 Vector Space에 멀티 모달의 임베딩을 정렬해서 올리는 Meta의 ImageBind 블로그 글과 논문은 아래에서 읽어보실 수 있습니다.
ImageBind에 대해서는 아래 글에서도 정리해서 소개하고 있으니 바쁘신 분들께서는 위 Meta의 블로그와 아래 블로그 글을 보시는 것을 추천드립니다 
(아래 TLDR 뉴스에서 소개되었던 글입니다)