Open-Parse - LLM을 위한 PDF 레이아웃 분할(Chunking)
소개
- 복잡한 문서를 사람처럼 쉽게 분할하는 라이브러리
- 문서 청킹은 모든 RAG의 기반이지만, 대부분의 오픈소스는 복잡한 문서 처리에 한계가 있음
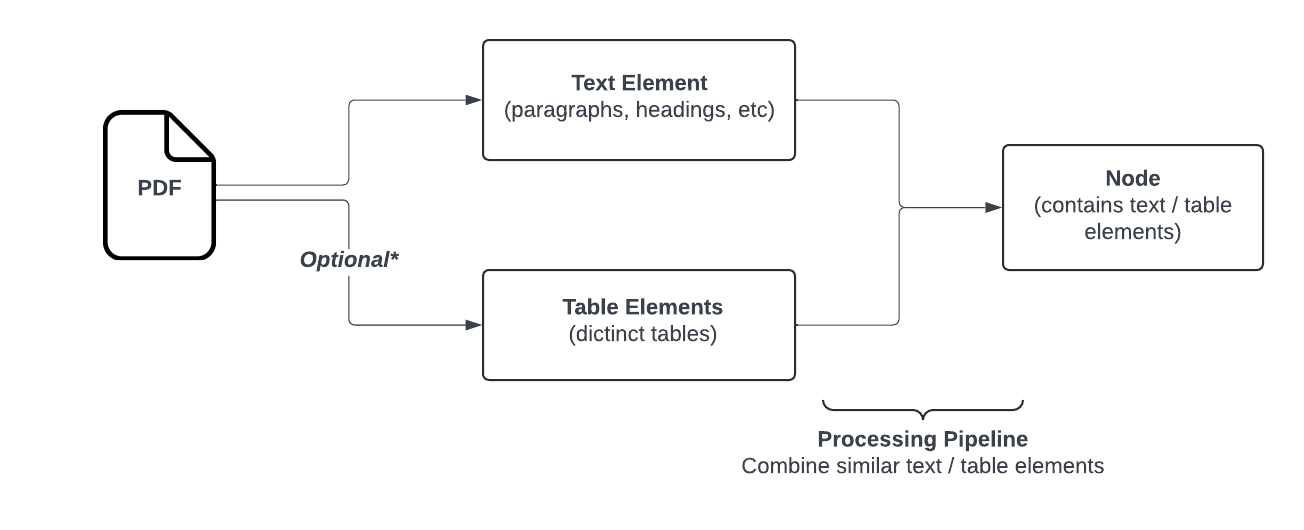
- Open Parse는 문서 레이아웃을 시각적으로 식별하고 효과적으로 분할할 수 있는 유연하고 사용하기 쉬운 라이브러리를 제공하여 이 격차를 메우도록 설계됨
Open Parse의 주요 기능
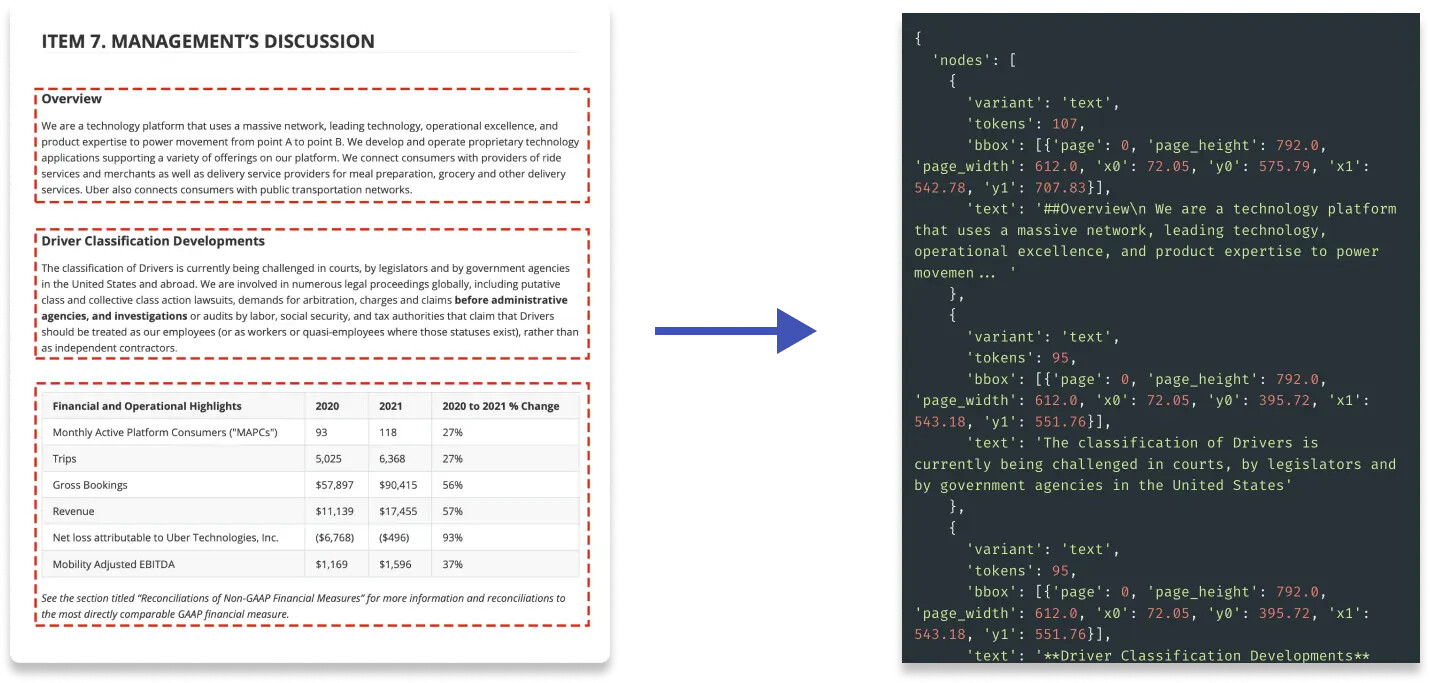
- 시각 기반(Visually-Driven) : 단순한 텍스트 분할을 넘어 문서를 시각적으로 분석하여 우수한 LLM 입력을 제공
- 마크다운 지원 : 제목, 굵게, 기울임꼴 파싱을 위한 기본 마크다운 지원
- 고정밀 테이블 지원 : 기존 도구를 능가하는 정확도로 테이블을 깨끗한 마크다운 형식으로 추출
- 확장성 : 사용자 정의 후처리 단계를 쉽게 구현 가능
- 직관적 : 훌륭한 에디터 지원과 어디에서나 자동 완성 기능으로 디버깅 시간 단축
- 용이성 : 사용과 학습이 쉽도록 설계되어 문서 읽는 시간 단축
원문
프로젝트 홈페이지
GitHub 저장소
https://github.com/Filimoa/open-parse
출처 / GeekNews
 알려드립니다
알려드립니다
이 글은 국내외 IT 소식들을 공유하는 GeekNews의 운영자이신 xguru님께 허락을 받아 GeekNews에 게제된 AI 관련된 소식을 공유한 것입니다.
출처의 GeekNews 링크를 방문하시면 이 글과 관련한 추가적인 의견들을 보시거나 공유하실 수 있습니다! ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~ ![]()