
소개
PDF 문서는 전 세계적으로 방대한 양의 텍스트 정보를 포함하고 있습니다. 하지만 다양한 레이아웃과 복잡한 구조 때문에 기존의 텍스트 추출 도구로는 충분한 품질의 데이터를 얻기가 어렵습니다.
olmOCR은 PDF 및 여러 이미지들(JPG, PNG 등)을 효과적으로 분석하고 구조화하여, 자연스러운 읽기 순서로 변환하면서도 구조적 요소(섹션, 표, 수식, 리스트 등)를 유지하는 것을 목표로 하는 오픈도스 도구입니다. 특히, 7B 규모의 최신 시각-언어 모델(VLM, Vision-Language Model)인 Qwen2-VL-7B-Instruct 모델을 활용하여 PDF의 다양한 레이아웃을 정확하게 인식하고, 텍스트를 Markdown 형식으로 변환합니다.
olmOCR은 학습 데이터로는 260,000개 이상의 PDF 페이지를 사용하였으며, 다양한 문서(과학 논문, 법률 문서, 광고 브로슈어, 슬라이드, 표, 다이어그램 등)를 처리할 수 있도록 설계되었습니다. 또한, 대량 문서 변환을 위한 최적화된 파이프라인을 제공하여 100만 페이지를 변환하는데 약 190달러 정도(시간당 $2.69의 H100 GPU / 초당 3k 토큰 출력 / 페이지당 650 토큰 / 20% 오버헤드 가정 시)의 저렴한 비용으로 실행할 수 있습니다. 모델 가중치, 학습 코드, 추론 코드까지 모두 공개되어 있어 연구 및 확장 가능성이 높습니다.
이러한 특징 덕분에 olmOCR은 기존 PDF 변환 도구 대비 더 높은 정확도와 낮은 비용을 제공하며, 특히 대규모 문서 데이터를 활용하는 AI 모델 연구자들에게 강력한 도구가 될 수 있습니다.
olmOCR 변환 예시
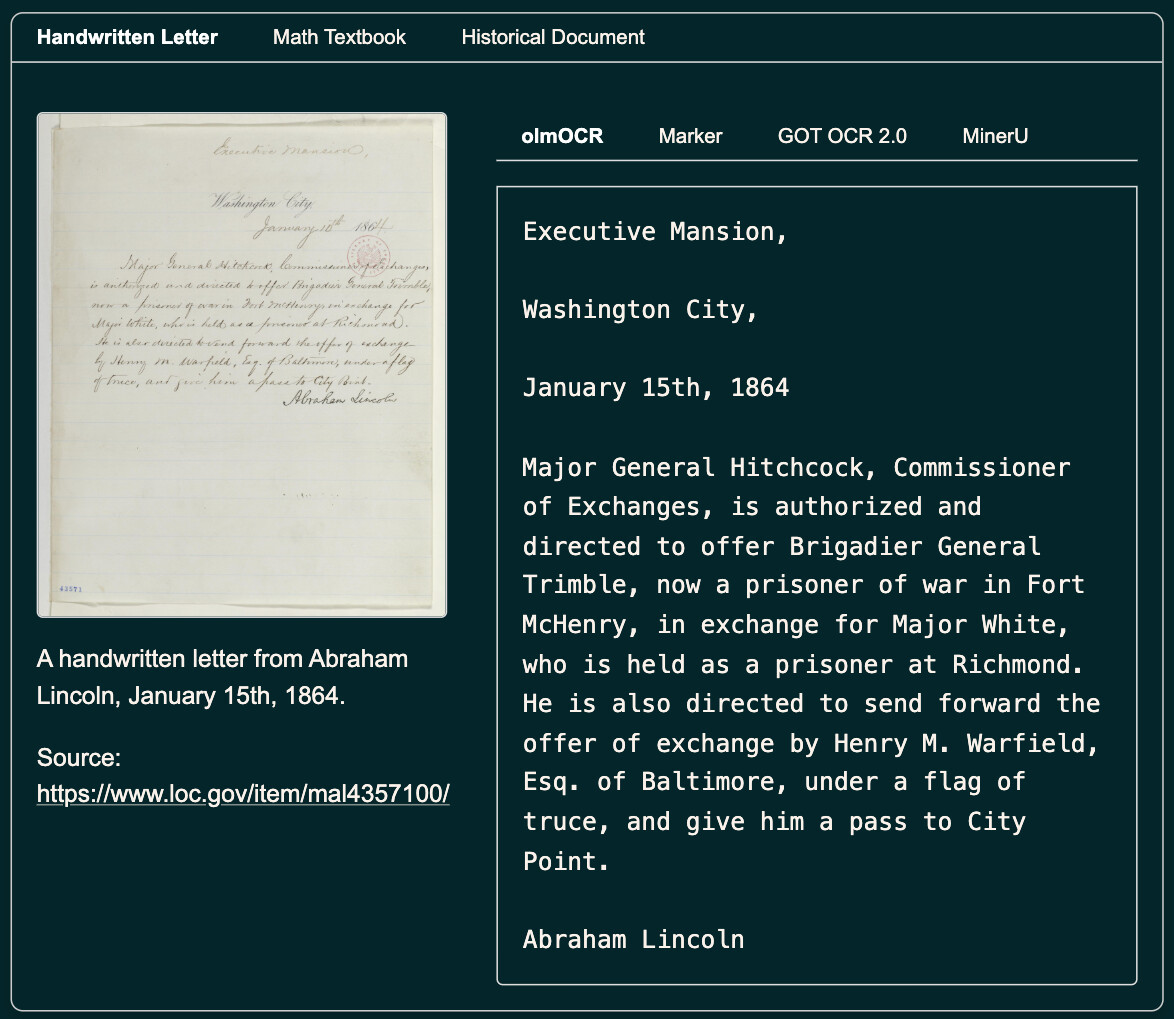


olmOCR의 주요 기능
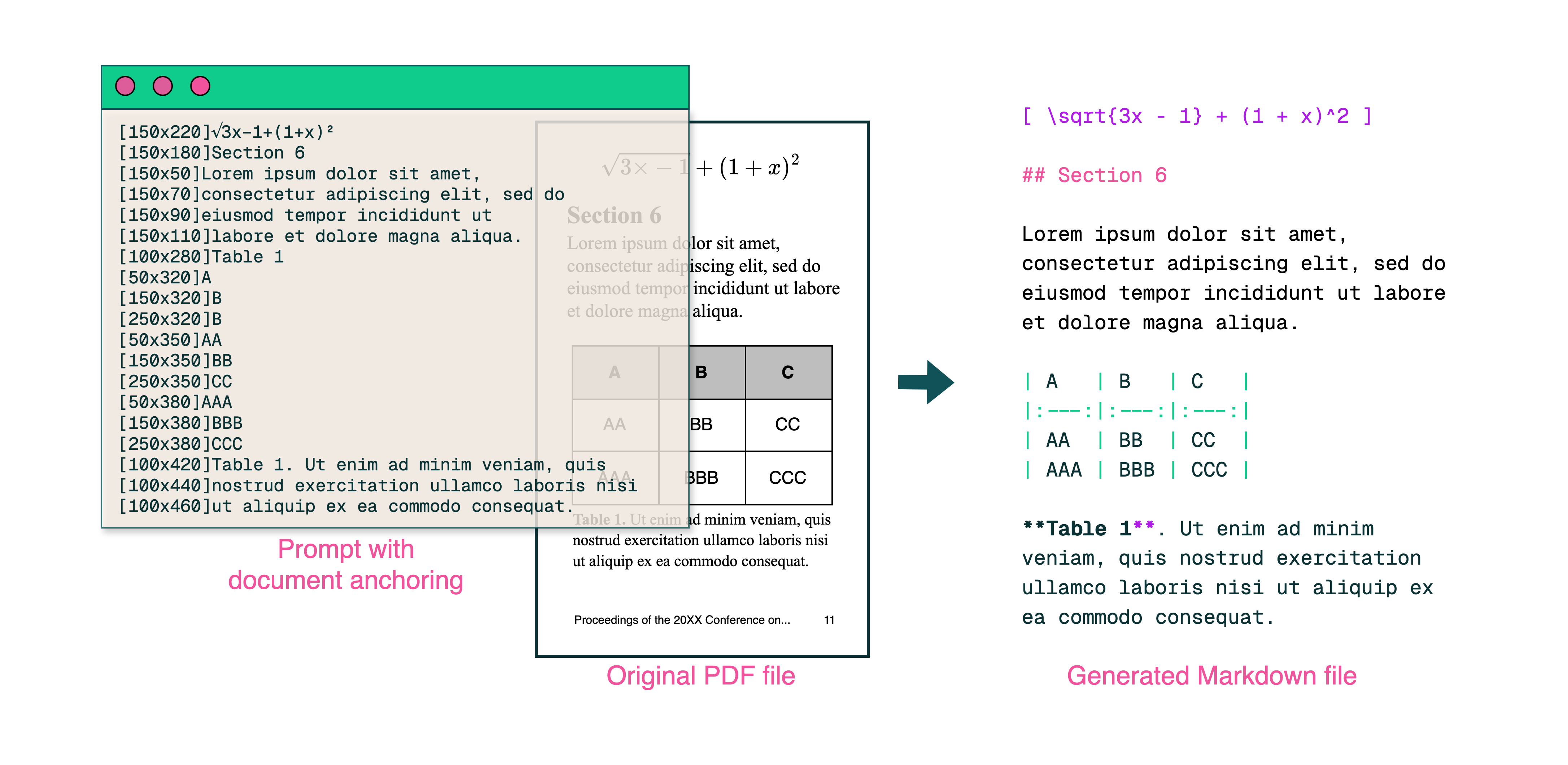
-
문서의 읽기 순서 유지: PDF, 이미지 문서에서도 원래의 문서 레이아웃을 반영하여 읽을 수 있도록 함
-
표, 수식, 손글씨까지 인식 가능: 기술 문서, 수학 교재, 논문 등을 OCR로 변환 가능
-
높은 정확도 및 낮은 환각(hallucination): 모델 최적화를 통해 기존 OCR에서 발생하는 무의미한 텍스트 출력을 줄임
-
자체 GPU 서버에서 실행 가능: 클라우드가 아닌 로컬에서 직접 배포 및 운영 가능
-
낮은 변환 비용: 100만 페이지 기준 약 $190(약 25만원) 수준의 비용으로 변환 가능
olmOCR 사용방법
데모 페이지에서 olmOCR의 성능을 확인하고, 자체적으로 설치하여 실행할 수 있습니다. 단, 직접 설치하여 사용하려면 NVIDIA GPU가 필요합니다(테스트된 GPU: RTX 4090, L40S, A100, H100). 또한, PDF 처리를 위해 추가적인 라이브러리를 설치해야 할 수 있습니다:
-
olmOCR 공식 페이지: PDF, JPG, PNG 파일을 업로드하여 변환 결과 확인 가능합니다. 제공된 샘플 문서(학술 논문, 수학 교재, 손글씨, 역사적 문서 등) 또는 직접 업로드하여 사용해볼 수 있습니다.
-
자체 서버에서 실행하기: GitHub 저장소 및 Hugging Face에서 olmOCR 툴킷 코드 및 데이터셋 체크포인트를 다운로드 후 설치할 수 있습니다. GPU 환경에서 배치 모드(batch mode)로 실행이 가능하며, 자세한 내용은 GitHub 저장소를 참고해주세요.
 olmOCR 홈페이지 및 데모
olmOCR 홈페이지 및 데모
 olmOCR 소개 블로그
olmOCR 소개 블로그
olmOCR 기술 문서
 olmOCR GitHub 저장소
olmOCR GitHub 저장소
 olmOCR 모델
olmOCR 모델
olmOCR 파인튜닝 데이터셋
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()