장기 실행 에이전트 글 소개
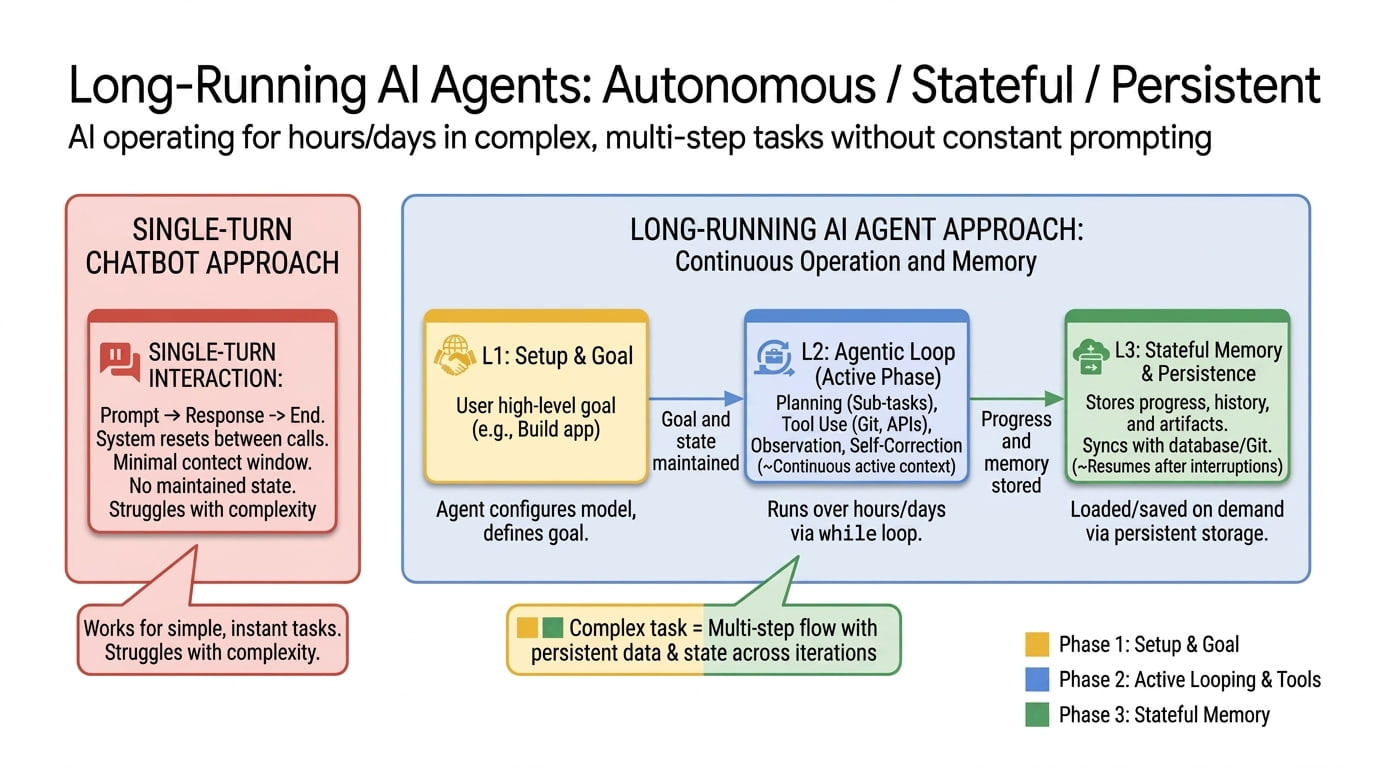
- AI 에이전트가 단일 채팅 세션이 아닌 수일~수주간 자율 실행되며, 여러 컨텍스트 윈도우와 샌드박스를 넘나들고 실패에서 복구하며 중단 지점부터 재개하는 새로운 패러다임 등장
- 기존 에이전트는 컨텍스트 윈도우 소진, 자기 평가 과신, 이전 수정 사항 재도입 등 단일 세션의 구조적 한계에 부딪힘
- Anthropic, Google, Cursor 등 주요 기업이 모델 루프, 실행 샌드박스, 세션 로그 분리 아키텍처로 수렴 중
- 장기 실행 에이전트의 핵심 과제는 영속 상태 관리, 자기 검증, 컨텍스트 압축이며, 이를 해결하는 다섯 가지 설계 패턴 제시
- 모델 자체보다 모델을 감싸는 상태, 세션, 구조화된 핸드오프 레이어가 실제 생산성 차이를 만드는 핵심 투자 영역
"장기 실행"의 세 가지 의미
- Long-horizon reasoning: 많은 의존 단계에 걸쳐 계획, 실행하는 능력으로, 주로 모델 품질의 문제. METR의 time horizon 지표에 따르면 프론티어 모델이 50% 신뢰도로 완료 가능한 작업 시간이 2019년 이후 약 7개월마다 두 배로 증가 중이며, 이 추세가 유지되면 2028년에 일 단위, 2034년에 연 단위 작업 완료 가능
- Long-running execution: 에이전트 프로세스가 수시간~수일 실행되며, 모델이 수천 번 호출될 수 있는 구조로, 주로 하네스(harness) 설계의 문제
- Persistent agency: 단일 작업을 넘어 에이전트가 정체성을 유지하며 메모리를 축적하고 사용자 선호를 학습하는 형태. Google의 Memory Bank 이 대표적 사례
- 실제 프로덕션 에이전트는 세 가지가 결합되지만, 각각의 엔지니어링 문제와 해법은 상이
장기 실행 에이전트가 중요한 이유
- 10분 실행 에이전트는 질문 답변이나 소규모 버그 수정 수준이지만, 10시간 실행 에이전트는 전체 기능 개발, 6분기 동안 밀린 마이그레이션 완료, 주니어 애널리스트급 리서치 수행 가능
- Anthropic의 Claude Sonnet 발표에서 내부 테스트 기준 30시간 이상 자율 코딩 사례 공개, 한 실행에서 11,000줄 규모의 Slack 스타일 앱 생성
- Project Vend 에서 Claude 인스턴스가 한 달간 실제 사무실 자판기 사업을 운영하며 재고 관리, 가격 설정, 공급업체 소통을 수행. 첫 번째 단계에서 유의미한 실패 사례가 도출되었고, 두 번째 단계에서 크게 개선
- 핵심은 수익성이 아니라, 에이전트가 턴이 아닌 주 단위로 정체성을 유지할 때 발생하는 일관성 문제를 관찰하는 것
모든 장기 실행 에이전트가 부딪히는 세 가지 벽
- 유한한 컨텍스트: 1M 토큰 윈도우도 결국 소진되며, 윈도우가 채워지기 전에 이미 context rot (모델 성능 점진적 저하)이 발생. 24시간 실행은 현재 어떤 컨텍스트 윈도우 로드맵에도 맞지 않음
- 영속 상태 부재: 새 세션은 백지 상태에서 시작. Anthropic은 이를 "교대 근무하는 엔지니어가 이전 근무에서 무슨 일이 있었는지 전혀 모르고 도착하는 것"에 비유
- 자기 검증 부재: 모델이 자기 작업을 평가하면 일관되게 긍정 편향 발생. "완료했나?"라는 질문에 실제보다 더 자주 "예"라고 응답하며, 별도의 검증 신호 없이는 30% 완성 상태에서 완전한 확신과 함께 결과물 제출
Ralph 루프: 실무자용 장기 실행 에이전트의 간단한 구현
- Ralph 루프 (Ralph Wiggum 기법)는 Geoffrey Huntley와 Ryan Carson이 대중화한 실무자용 장기 실행 에이전트 패턴으로, 레퍼런스 구현이 bash 스크립트 하나
- 동작 순서: 미완료 작업 선택(
prd.json) → 작업, 컨텍스트, 메모로 프롬프트 구성 → 에이전트 호출 → 테스트 실행 → 결과를progress.txt에 추가 → 작업 목록 업데이트 → 반복 - 핵심 원리: 에이전트 자체는 기억상실이지만 파일시스템은 기억을 유지.
prd.json이 계획,progress.txt가 랩 노트,AGENTS.md가 롤링 룰북 역할 - Ryan Carson의 Compound Product 는 분석 루프(일일 리포트 읽기) → 계획 루프(PRD 생성) → 실행 루프(코드 작성) 형태로 여러 루프를 체이닝하며, 이는 Anthropic이 독자적으로 도달한 planner-generator-evaluator 삼중 구조의 오픈소스 버전
- bash 스크립트와 JSON 파일만으로 하룻밤에 작동하는 장기 실행 에이전트 구축 가능. Google과 Anthropic이 제품화한 것은 이 패턴을 복구 가능하고, 안전하며, 관측 가능하게 만드는 작업
Anthropic: 하네스에서 Brain/Hands/Session 분리로
- 첫 번째 접근(하네스 구조): 자율 풀스택 개발을 위한 2-에이전트 하네스. Initializer 에이전트가 프로젝트 초기 환경 구성, 프롬프트를
feature-list.json으로 확장, 부팅 스크립트(init.sh) 작성. Coding 에이전트가 반복적으로 깨어나 기능 단위 진행, 테스트 실행,claude-progress.txt작성, 커밋 수행- 테스트 래칫(test ratchet) 규칙: "테스트를 삭제하거나 수정하는 것은 허용되지 않음" - 에이전트가 실패하는 테스트를 삭제해서 통과시키는 흔한 실패 방지
- InfoQ 확장 버전에서 planner, generator, evaluator 삼중 구조로 발전. 생성과 평가 분리가 중요한 이유: 모델이 자기 작업을 너무 관대하게 평가
- 두 번째 접근(Brain/Hands/Session 분리): Claude Managed Agents(2026년 4월 초 출시)의 아키텍처
- Brain: 모델과 하네스 루프
- Hands: 도구가 실제 실행되는 샌드박스화된 임시 실행 환경
- Session: 모든 사고, 도구 호출, 관찰의 추가 전용(append-only) 이벤트 로그
- Anthropic의 핵심 프레이밍: "하네스의 모든 컴포넌트는 모델이 스스로 할 수 없는 것에 대한 가정을 인코딩"하며, 결합하면 가정이 구식이 될 때 전체 시스템을 바꿔야 하고, 분리하면 하네스가 무상태가 되고 샌드박스는 cattle(소모품) 취급 가능
- 새 컨테이너가
wake(sessionId)를 호출해 로그에서 상태 재구성 가능. time-to-first-token이 p50에서 약 60%, p95에서 90% 이상 감소 - 샌드박스 준비 전에 추론 시작이 가능해진 결과 - 세션-이벤트-로그 개념이 가장 과소평가되는 부분. 이것이 장기 실행 에이전트를 복구 가능하게 만드는 핵심. 없으면 컨테이너 장애가 곧 세션 장애
- 과학 컴퓨팅용 스택:
CLAUDE.md(에이전트가 학습하며 편집하는 살아 있는 계획),CHANGELOG.md(이식 가능한 랩 노트),tmux+SLURM+git(실행, 조정 레이어), Ralph 루프(완료 주장 시 재확인)- 대표 사례: Claude Opus가 며칠에 걸쳐 구축한 Boltzmann 솔버가 레퍼런스 CLASS 구현과 1% 미만 오차 달성. 연구자 수개월~수년의 작업 압축
Cursor: Planner, Worker, Judge 구조
- Cursor의 장기 자율 코딩 확장 과정에서 세 번의 설계 반복
- 첫 번째(플랫 조정): 동등 지위 에이전트들이 락으로 공유 파일에 쓰기 → 병목 발생, 에이전트가 위험 회피적으로 변해 churning(반복만 하고 커밋 안 함) 발생
- 두 번째(낙관적 동시성 제어): 병목은 해소했으나 조정 문제는 미해결
- 세 번째(현재 프로덕션): Planner(코드베이스 탐색, 작업 생성, 하위 플래너 재귀 스폰 가능), Worker(집중 실행, 상호 조정 없이 독립 작업), Judge(반복 완료 판정, 재시작 결정)
- 핵심 발견: "시스템 동작의 놀라울 정도로 많은 부분이 하네스나 모델보다 프롬프트에 좌우됨"
- 모델-역할 매칭이 설계 표면의 일부: GPT 모델이 장시간 자율 작업에서 Opus보다 우수. Opus는 조기 중단과 지름길 선택 경향. 같은 작업, 다른 역할, 다른 모델
- Composer 2 (독자적 프론티어 코딩 모델)와 백그라운드 클라우드 에이전트: 장기 작업이 로컬이 아닌 Anysphere 클라우드 인프라에서 실행. 8시간 리팩토링과 코드베이스 전체 마이그레이션이 노트북을 닫아도 지속
- 로컬에서 시작 후 30분 이상 걸릴 것으로 판단되면 클라우드로 전환, 이후 모바일에서 재접속 가능
- 각 에이전트가 격리된 git worktree에서 실행, PR을 통해 병합
- 최종 구조는 Anthropic과 유사: 역할 분리, 세션 지속, judge가 worker 옆에 위치, 장기 작업은 클라우드 샌드박스에서 git 기반 조정
Google: Agent Platform의 장기 실행 에이전트
- Cloud Next '26 에서 Vertex AI를 Gemini Enterprise Agent Platform으로 통합, 장기 실행 에이전트를 SLA가 명시된 정식 제품으로 전환
- Agent Runtime: "수일간 자율 실행" 지원, 서브초 콜드 스타트, 온디맨드 샌드박스 프로비저닝. 예시 유즈케이스: 일주일 소요되는 영업 프로스펙팅 시퀀스
- Agent Sessions: 대화 및 이벤트 이력 영속화. 커스텀 세션 ID를 CRM이나 DB 레코드에 매핑해 에이전트 상태를 비즈니스 상태와 함께 저장 가능
- Agent Memory Bank: Next '26 기준 GA(일반 출시)된 장기 메모리 레이어. 세션에서 메모리를 큐레이션하고 사용자 ID에 스코핑, 검색 API 제공. Payhawk 사례에서 Memory Bank 기반 에이전트가 경비 제출 시간 50% 이상 단축
- Agent Sandbox(강화된 코드 실행), Agent-to-Agent Orchestration, Agent Registry, Agent Identity, Agent Gateway, Agent Observability, Agent Simulation 등 프로덕션 운영에 필요한 거의 모든 관심사를 커버. 엔터프라이즈에 필요한 암호화 ID, 감사 로그 포함
- 아키텍처적으로 Anthropic의 brain/hands/session 분리와 동일 구조를 플랫폼 규모로 제품화, ADK (코드 퍼스트 개발 키트)와 Agent Studio(비주얼 도구) 번들. 3년 전에는 직접 구축해야 했던 것을 이제는 "어떤 버전의 brain/hands/session 분리를 빌릴 것인가" 선택의 문제
프로덕션 장기 실행 에이전트를 위한 다섯 가지 패턴
- Checkpoint-and-resume: 가장 흔한 다일 실패는 컨텍스트 손실. 200개 문서 처리 후 201번째에서 오류 발생 시 체크포인트 없이는 처음부터 재시작. 에이전트를 장기 실행 서버 프로세스처럼 취급: 중간 상태 디스크 저장, N 작업 단위마다 체크포인트, 장애 복구. 적절한 체크포인트 단위 결정(매 단계도 아니고 끝에만도 아닌)이 핵심
- Delegated approval(human-in-the-loop): 기존 구현은 상태를 JSON 직렬화 → 웹훅 → 응답 대기이지만, 상태가 stale해지고 알림이 묻히는 문제 발생. 장기 실행 런타임에서는 에이전트가 추론 체인, 작업 메모리, 도구 이력, 보류 액션 전체를 유지한 채 일시정지 가능. 인간 검토 시간 동안 컴퓨트 소비 제로, 서브초 지연으로 재개. Google의 Mission Control이 이를 위한 인박스 역할
- Memory-layered context: 7일 실행 에이전트는 세션 상태 이상이 필요. Memory Bank(장기 큐레이션 메모리) + Memory Profiles(저지연 조회). 프로덕션 실패 모드는 memory drift - 에이전트가 비정형 상호작용에서 절차적 지름길을 학습해 광범위하게 적용. 메모리를 마이크로서비스처럼 거버넌스 필요. Agent Identity(읽기/쓰기 권한), Agent Registry(에이전트 버전 추적), Agent Gateway(정책 적용)
- Ambient processing: 인간과 대화하지 않고 Pub/Sub 스트림이나 BigQuery 테이블에서 이벤트에 반응하는 에이전트(콘텐츠 모더레이션, 이상 탐지, 인박스 분류). 정책을 에이전트에 하드코딩하지 않고 Gateway에 정의하면 재배포 없이 수백 개 에이전트에 정책 변경 반영 가능
- Fleet orchestration: 실제 시스템에서는 하나의 에이전트가 아닌 코디네이터가 전문가(Lead Researcher Agent, Scoring Agent, Outreach Agent)에게 하위 작업 위임. 각 전문가가 고유 Identity(Outreach Agent는 Scoring용 금융 데이터 접근 불가), 고유 정책, 고유 Registry 항목 보유. ADK가 그래프 기반 워크플로우로 선언적 처리
- 패턴은 조합 가능. 컴플라이언스 시스템 예시: 문서 처리에 체크포인팅 + 리뷰 게이트에 위임 승인 + 세션 간 지식에 메모리 레이어링 + 전문가 조정에 플릿 오케스트레이션
실제 구축 방법
- 자체 리포에서 장기 코딩 작업을 원하는 개발자: Claude Code, Antigravity, Cursor, Codex 등 활용.
AGENTS.md를 파일럿 체크리스트처럼 관리(짧게, 실제 실패 경험에서 얻은 항목만). 타입체크, 린트 훅 추가, 시작 전 계획 파일 작성, 에이전트 완료 주장 시 Ralph 루프로 재확인. 멀티 시간/야간 작업은 worktree에서 실행해 노트북 닫아도 유지, 의미 있는 작업 단위마다 커밋. 대부분의 사람에게 가장 높은 레버리지 경로 - 호스팅 에이전트 제품 구축: 런타임을 직접 구축하지 말고 매니지드 선택. 현재 실질적 옵션 3가지: Google Agent Platform (Agent Engine + Memory Bank + Sessions), Claude Managed Agents, 또는 ADK, Claude Agent SDK, Codex SDK 위에 자체 호스팅. 매니지드는 brain/hands/session 분리, 관측성, ID, 감사 추적 기본 제공. 자체 호스팅은 제어권과 특수 모델 사용 가능
- 자율, 운영 업무(모니터링, 리서치, 운영): Memory Bank 스타일 영속성 필요. ADK + Memory Bank + Cloud Run + Cloud Scheduler가 "N시간마다 에이전트 실행, 상태 축적, 임계값 알림"에 가장 깔끔한 스택
경로 무관한 핵심 실천 사항
- 에이전트 시작 전 완료 조건 명문화: 장기 실행에서 가장 높은 레버리지. 외부 파일에 명시적, 테스트 가능한 완료 기준 작성 → 에이전트가 실행 중 "완료"를 재정의하는 것을 방지
- 평가자와 생성자 분리: 자기 채점이 핵심 실패 모드. planner/worker/judge 파이프라인 또는 generator/evaluator 쌍은 스타일이 아닌 실제 아키텍처 패턴. 같은 모델이라도 다른 역할, 다른 프롬프트로 분리
- 프롬프트가 아닌 세션 로그에 투자: 추가 전용 이벤트 로그가 에이전트를 복구, 디버깅, 감사 가능하게 만듦. 지난 24시간의 에이전트 활동을 영속 스토리지에서 재구성할 수 없다면, LLM을 호출하는 장기 실행 셸 스크립트일 뿐
- 압축과 컨텍스트 리셋을 일급 시민으로 취급: Anthropic은 매우 긴 작업에서 요약 기반 압축만으로 불충분했으며, 하네스가 세션을 완전히 해체하고 구조화된 핸드오프 파일에서 재구축하는 전체 컨텍스트 리셋이 필요. 이는 본질적으로 새 엔지니어를 온보딩하는 방식과 동일
현재의 실질적 한계
- 비용: 프론티어 모델로 24시간 실행 시 비용이 상당. 예산, 서킷 브레이커, 도구 지출 하드캡 없이는 오후 한나절에 일주일 API 예산 소진 가능
- 보안: API 키, 클라우드 접근, 셸 명령 실행 권한을 가진 장기 실행 에이전트는 채팅 세션보다 훨씬 넓은 공격 표면. brain/hands 분리 패턴이 중요. 모델 생성 코드가 실행되는 샌드박스에서 크레덴셜 접근 불가 상태 유지 필요
- Alignment drift: 여러 컨텍스트 윈도우를 거치며 에이전트가 표류. 원래 목표가 요약되고, 재요약되며 충실도 저하. 훅과 judge가 이를 방어하기 위해 존재하며, "에이전트가 요청하지 않은 작업을 수행"하는 가장 흔한 원인
- 검증: 24시간 자율 활동 감사는 실제 인간 시간 문제. 관측성과 구조화된 산출물(PR, 커밋, 브리핑, 테스트 실행)이 이를 tractable하게 만드는 방법
- 인간의 역할: 에이전트가 하루 동안 실행할 수 있을 만큼 작업을 정밀하게 정의하는 것이 직접 작업하는 것보다 어려움. 가치가 상승 중인 기술은 코드 작성이 아니라 자율 실행자와의 접촉에서 살아남는 스펙 작성
향후 방향
- Google, Anthropic, Cursor가 동일한 구조로 수렴: 모델 루프, 실행 샌드박스, 세션 로그 분리, 계획, 생성, 평가 분리, 압축, 훅, 컨텍스트 리셋 내장, 메모리를 매니지드 서비스로 노출
- 차이는 표면적: Google Agent Platform은 엔터프라이즈 스택(ID, 감사 추적 내장), Claude Managed Agents는 "Anthropic 하네스 호스팅 버전", Cursor 백그라운드 에이전트는 "IDE에서 클라우드로 빼낸 장기 코딩"
- 향후 1년의 더 어려운 문제는 개별 레이어가 아닌 그 위의 조정: 공유 코드베이스에서 다수의 장기 에이전트 운영, 자기 트레이스를 읽고 자체 하네스를 패치하는 에이전트, 작업에 맞춰 도구와 컨텍스트를 JIT(just-in-time) 조립하는 하네스
- 모델은 여전히 핵심이지만, 채팅 윈도우와 야간 실행 가능한 에이전트 사이의 격차는 대부분 상태, 세션, 구조화된 핸드오프에 있으며, 이것이 현재 학습 시간을 투자할 영역

원문
출처 / GeekNews
더 읽어보기
-
과학 컴퓨팅을 위한 Claude 장기 실행에 대한 연구: Ralph 루프 및 실질적인 연구 방법 공유 (feat. Anthropic)
-
Deep Researcher Agent: 잠든 사이에도 24시간 딥러닝 실험을 자율 수행하는 LLM 에이전트 프레임워크
함께 보면 좋은 글β
 알려드립니다
알려드립니다
이 글은 국내외 IT 소식들을 공유하는 GeekNews의 운영자이신 xguru님께 허락을 받아 GeekNews에 게제된 AI 관련된 소식을 공유한 것입니다.
출처의 GeekNews 링크를 방문하시면 이 글과 관련한 추가적인 의견들을 보시거나 공유하실 수 있습니다! ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~ ![]()