
Memori 소개
Memori는 대규모 언어 모델(LLM, Large Language Model), AI 에이전트, 그리고 복잡한 멀티 에이전트 시스템을 위한 오픈소스 메모리 계층(Memory Layer) 입니다. 인공지능 애플리케이션 개발에서 가장 큰 난제 중 하나는 상태 유지(Statefulness)입니다. LLM 자체는 기본적으로 상태를 저장하지 않는(Stateless) 속성을 가지고 있어, 대화가 길어지거나 세션이 종료되면 이전의 맥락을 모두 잊어버립니다. 이를 해결하기 위해 개발자들은 보통 전체 대화 로그를 프롬프트에 포함시키거나(비용 및 컨텍스트 윈도우 문제 발생), 단순한 벡터 데이터베이스(RAG)를 사용해 왔습니다.
Memori는 이러한 접근 방식을 넘어, 기업과 개발자가 이미 구축해 둔 SQL 데이터베이스 인프라를 활용하여 AI에게 장기 기억을 부여하는 솔루션입니다. 이를 Memory Fabric이라 칭하며, 단순히 대화 내용을 저장하는 것을 넘어 사용자의 선호(Preferences), 사실(Facts), 규칙(Rules), 관계(Relationships) 등을 실시간으로 추출하고 구조화하여 저장합니다.
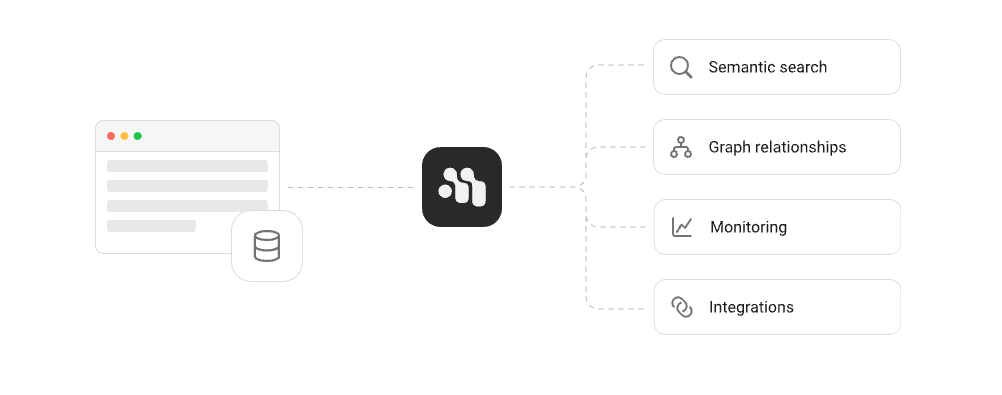
가장 큰 특징은 SQL 네이티브(SQL Native) 접근 방식과 불가지론적(Agnostic) 설계입니다. 특정 벡터 DB나 LLM 벤더에 종속되지 않고, PostgreSQL, MySQL, Oracle 등 기존 관계형 데이터베이스(RDBMS)를 그대로 메모리 저장소로 사용할 수 있습니다. 이를 통해 기업은 데이터 소유권을 완벽하게 통제하면서도, 토큰 비용을 획기적으로 절감하고 AI의 응답 품질을 높일 수 있습니다.
Memori의 이전 버전(v2) 대비 v3의 변화
Memori는 최근 v3로 업데이트되면서 아키텍처와 성능 면에서 비약적인 발전을 이루었습니다. 단순한 업데이트가 아닌, 상용 수준의 AI 서비스에 필수적인 기능들이 대거 추가되었습니다.
-
고급 증강(Advanced Augmentation) 및 제로 레이턴시(Zero Latency): v2의 추출 에이전트 방식을 스레드 기반의 비동기 아키텍처로 완전히 재설계했습니다. 사용자가 질문을 던지고 답변을 받는 동안, Memori는 백그라운드에서 대화 내용을 분석하고 기억을 형성합니다. 덕분에 사용자는 메모리 처리를 기다릴 필요 없이 즉각적인 응답을 받을 수 있습니다.
-
지식 그래프(Knowledge Graph)와 제3정규형(3NF): 단순한 텍스트 저장이 아니라, 데이터베이스 설계의 정석인 제3정규형 스키마를 적용했습니다. 특히 의미론적 트리플(Semantic Triples, 주어-술어-목적어)을 저장하여 지식 그래프를 자동으로 구축합니다. 이는 AI가 단편적인 정보뿐만 아니라 정보 간의 '관계'까지 이해하게 돕습니다.
-
벡터 메모리 및 시맨틱 검색: SQL 기반이지만 벡터화된 메모리와 인메모리(In-memory) 시맨틱 검색을 지원하여, 문맥상 가장 유사하고 중요한 정보를 정확하게 찾아냅니다.
-
완벽한 호환성(Agnostic): 주요 파운데이션 모델(OpenAI, Anthropic, Gemini, Grok, Bedrock 등)과 주요 데이터베이스(Postgres, MySQL, SQLite, CockroachDB 등)를 모두 지원하며, Agno나 LangChain 같은 최신 프레임워크와도 매끄럽게 연동됩니다.
Memori의 주요 기능
3단계 메모리 계층 구조 (The Hierarchy of Memory)
Memori는 기억을 체계적으로 관리하기 위해 세 가지 핵심 개념을 도입했습니다. 개발자는 이 구조를 통해 AI가 누구와(Who), 무엇을(What), 어떤 맥락(Context) 에서 대화하는지 명확히 정의할 수 있습니다:
-
Entity (엔티티): 기억의 주체입니다. 사용자(User), 장소, 사물 등이 될 수 있습니다. (예:
user_id: 12345) -
Process (프로세스): 기억을 형성하는 주체인 AI 에이전트나 프로그램입니다. (예:
shopping_bot,coding_assistant) -
Session (세션): 엔티티와 프로세스 간의 특정 상호작용 그룹입니다. 하나의 작업 단위나 대화 흐름을 묶어 관리합니다.
고급 증강 (Advanced Augmentation)의 작동 원리
Memori의 고급 증강(Advanced Augmentation) 기능은 대화가 오가는 동안 백그라운드에서 작동하며, 비정형 텍스트인 대화 내용을 다음과 같은 구조화된 데이터로 자동 분류하여 저장합니다.
- Facts (사실): 변하지 않는 정보 (예: "사용자는 서울에 거주한다.")
- Preferences (선호): 사용자의 취향 (예: "어두운 테마를 선호한다.", "매운 음식을 못 먹는다.")
- Rules (규칙): AI가 따라야 할 지침 (예: "항상 존댓말을 사용해라.")
- Relationships (관계): 엔티티 간의 연결 고리 (지식 그래프의 핵심)
- Events (이벤트): 특정 시점에 발생한 사건
- Skills (기술): 사용자가 보유한 기술이나 능력
이러한 정보는 다음 번 대화 때 자동으로 프롬프트에 주입(Injection) 되어, AI가 마치 오랜 친구처럼 사용자를 기억하고 맞춤형 대화를 하도록 만듭니다. 고급 증강 기능과 관련해서는 관련 문서를 참고해주세요.
데이터 소유권과 보안 (Your Database, Our Memory Layer)
Memori는 "데이터는 사용자의 DB에, 로직은 Memori에"라는 철학을 따릅니다. 클라우드 기반 메모리 솔루션들이 데이터를 외부 서버에 저장해야 하는 것과 달리, Memori는 개발자가 지정한 데이터베이스(PostgreSQL, MySQL 등)에 테이블을 생성하고 데이터를 저장합니다.
-
RBAC (Role Based Access Control, 역할 기반 접근 제어): 데이터베이스 자체의 권한 관리 시스템을 그대로 따릅니다. 기업의 보안 정책에 맞춰 읽기/쓰기 권한을 세밀하게 제어할 수 있습니다.
-
감사(Audit) 및 계보(Lineage): AI가 왜 그런 답변을 했는지 역추적할 수 있습니다. 어떤 메모리가 인출되었고, 언제 생성되었는지에 대한 메타데이터를 제공하여 AI의 설명 가능성(Explainability)을 높입니다.
Memori의 기술 스택 및 호환성
Memori는 플러그 앤 플레이(Plug & Play) 방식을 지향하여 기존 시스템에 최소한의 변경으로 통합될 수 있습니다.
지원하는 데이터베이스 (Datastores)
Python의 DB API 2.0 표준을 준수하는 거의 모든 드라이버를 지원합니다.
-
RDBMS: PostgreSQL, MySQL, MariaDB, SQLite, Oracle, CockroachDB, OceanBase, Neon, Supabase
-
NoSQL: MongoDB (일부 지원 및 예제 제공)
-
ORM: Django ORM, SQLAlchemy와의 네이티브 통합 지원
지원 LLM (Large Language Models)
-
OpenAI: Chat Completions & Responses API (동기/비동기, 스트리밍 지원)
-
Anthropic (Claude)
-
Google Gemini
-
xAI (Grok)
-
AWS Bedrock
-
Nebius AI Studio
지원 프레임워크
-
LangChain: 랭체인의 메모리 컴포넌트로 활용 가능
-
Agno: 에이전트 프레임워크 Agno와 호환
Memori 사용 예시
다음은 SQLite를 사용하여 OpenAI 기반의 챗봇에 기억 능력을 부여하는 전체 코드 예시입니다. Memori 클래스는 기존 OpenAI 클라이언트를 감싸는(Wrap) 형태로 동작하여 코드를 크게 수정할 필요가 없습니다:
import os
import sqlite3
from memori import Memori
from openai import OpenAI
# 1. 데이터베이스 연결 함수 정의 (SQLite 사용 예시)
# 실제 운영 환경에서는 PostgreSQL 등의 커넥션 풀을 사용할 것을 권장합니다.
def get_sqlite_connection():
return sqlite3.connect("memori.db")
# 2. OpenAI 클라이언트 생성
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 3. Memori 초기화 및 LLM 등록
# conn에는 DB 커넥션 팩토리 함수를 전달합니다.
memori = Memori(conn=get_sqlite_connection).llm.register(client)
# 4. Attribution 설정 (중요)
# 현재 대화의 주체(Entity)와 처리 에이전트(Process)를 식별합니다.
# 이 ID들을 기준으로 메모리가 격리되고 관리됩니다.
memori.attribution(entity_id="user_unique_id_123", process_id="customer_support_bot")
# 5. 스토리지 빌드 (최초 1회 혹은 스키마 변경 시 실행)
# 필요한 테이블과 인덱스를 자동으로 생성합니다.
memori.config.storage.build()
# 6. 대화 실행
# 개발자는 평소처럼 client.chat.completions.create를 호출하지만,
# 내부적으로 Memori가 관련 기억을 검색해 프롬프트에 추가하고,
# 응답이 완료되면 새로운 정보를 백그라운드에서 추출하여 저장합니다.
response = client.chat.completions.create(
model="gpt-4o", # 최신 모델 사용 권장
messages=[
{"role": "user", "content": "나는 유당불내증이 있어서 우유가 들어간 라떼는 못 마셔."}
]
)
print(f"AI 응답: {response.choices[0].message.content}")
# [참고] CLI나 짧은 스크립트에서는 백그라운드 작업이 끝나기 전에 프로세스가 종료될 수 있습니다.
# 이를 방지하기 위해 강제로 대기(wait)를 호출할 수 있습니다. (서버 환경에서는 불필요)
memori.augmentation.wait()
# --- 이후 다른 세션이나 대화에서 ---
# 사용자가 다시 질문을 했을 때, Memori는 위에서 저장한 '유당불내증' 정보를 기억합니다.
response_2 = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "나를 위해 커피 메뉴 하나 추천해줘."}
]
)
# 예상 응답: "우유가 들어가지 않은 아메리카노나, 두유로 변경한 소이 라떼는 어떠신가요?"
print(f"AI 응답 2: {response_2.choices[0].message.content}")
Memori에 저장된 데이터 확인 방법
저장된 데이터는 표준 SQL 쿼리로 직접 확인할 수 있습니다.
# 저장된 대화 로그 확인
sqlite3 memori.db "select * from memori_conversation_message"
# 추출된 사실(Fact) 확인
sqlite3 memori.db "select * from memori_entity_fact"
# 구축된 지식 그래프 확인
sqlite3 memori.db "select * from memori_knowledge_graph"
이러한 기능들을 바탕으로, 다음과 같은 분야에 사용할 수 있습니다:
-
초개인화된 이커머스 (E-commerce): 고객의 구매 이력뿐만 아니라 "붉은색 계열을 싫어함", "여름 휴가용 옷을 찾음"과 같은 대화 속 뉘앙스를 기억하여, 재방문 시 완벽하게 개인화된 상품을 추천합니다.
-
맥락을 이해하는 고객 지원 (Customer Support): 상담원이 바뀌거나 시간이 지나도 고객의 이전 불만 사항이나 특이 사항(예: "오전에만 통화 가능")을 기억하여, 반복적인 질문 없이 효율적인 상담을 제공합니다.
-
장기 실행 에이전트 (Long-running Agents): 코딩 어시스턴트나 연구 보조 AI가 프로젝트의 전체 히스토리와 사용자의 코딩 스타일 규칙을 지속적으로 유지하며 작업을 수행합니다.
라이선스
Memori 프로젝트는 Apache License 2.0 라이선스로 공개 및 배포됩니다. 개인 및 기업 사용자가 자유롭게 사용, 수정, 배포할 수 있습니다. 상업적 이용이 가능하며, 소스 코드 공개 의무가 없는 허용적인(Permissive) 라이선스입니다.
 Memori 공식 홈페이지
Memori 공식 홈페이지
 Memori 공식 문서 사이트
Memori 공식 문서 사이트
 Memori 프로젝트 GitHub 저장소
Memori 프로젝트 GitHub 저장소
더 읽어보기
-
AgentFS: AI 에이전트가 생성하는 파일, 상태, 도구 호출 기록 등을 관리하기 위한 파일 시스템 (feat. Turso)
-
OpenViking: AI 에이전트를 위한 '파일 시스템' 기반 맥락 데이터베이스 (Context Database)
-
AgentPG: PostgreSQL을 AI 에이전트의 지능형 저장소로 활용하는 프로젝트 (w/ golang)
-
Agentic RAG for Dummies: Agentic 기반 RAG 시스템을 이해하고 구축할 수 있도록 돕는 오픈소스 프로젝트 (feat. LangGraph)
-
Google, Context Engineering을 위한 세션(Session)과 메모리(Memory)의 개념 및 구현 전략에 대한 기술 백서 공개 [영문/PDF/72p]
-
LightMem: LLM 및 AI Agent를 위한 효율적인 경량 메모리 프레임워크에 대한 연구 및 라이브러리
-
Agentic Design Patterns: 지능형 에이전트 시대를 위한 설계 패턴 가이드 [Google Docs/영문/424p]
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()