
Gemma 3 QAT 모델 소개
지난달 Google은 자사 오픈모델 중 가장 최신 버전인 Gemma 3를 공개했습니다. BF16 기반으로 H100급 서버에서 실행될 정도로 고성능을 자랑하지만, 일반 개발자 입장에서는 접근성이 떨어지는 것이 사실이었습니다. 이를 개선하기 위해, Google은 Quantization-Aware Training(QAT) 기법을 적용한 버전을 새롭게 공개했는데요, 이는 메모리 사용량을 크게 줄이면서도 기존의 성능을 거의 유지할 수 있게 합니다.
QAT 덕분에 이제 Gemma 3 27B 모델도 RTX 3090과 같은 소비자용 GPU에서 실행할 수 있게 되었고, Gemma 3 12B는 노트북 GPU인 RTX 4060에서도 잘 돌아갑니다. 이는 단순히 모델 경량화를 넘어, 더 많은 개발자들이 실질적인 활용을 할 수 있도록 돕는 중요한 전환점입니다.
전통적으로 대형 언어모델을 로컬에서 실행하려면 최소한의 FP16 환경을 요구했으며, 그나마도 수십 GB의 VRAM을 요구했습니다. 하지만 Gemma 3 QAT 모델은 int4 (4bit 정밀도) 기반으로 모델을 학습하면서도 성능 저하를 최소화했기 때문에, LLaMA 시리즈나 기존의 Post-Training Quantization 기반 모델들보다 훨씬 효율적인 구조를 보여줍니다.
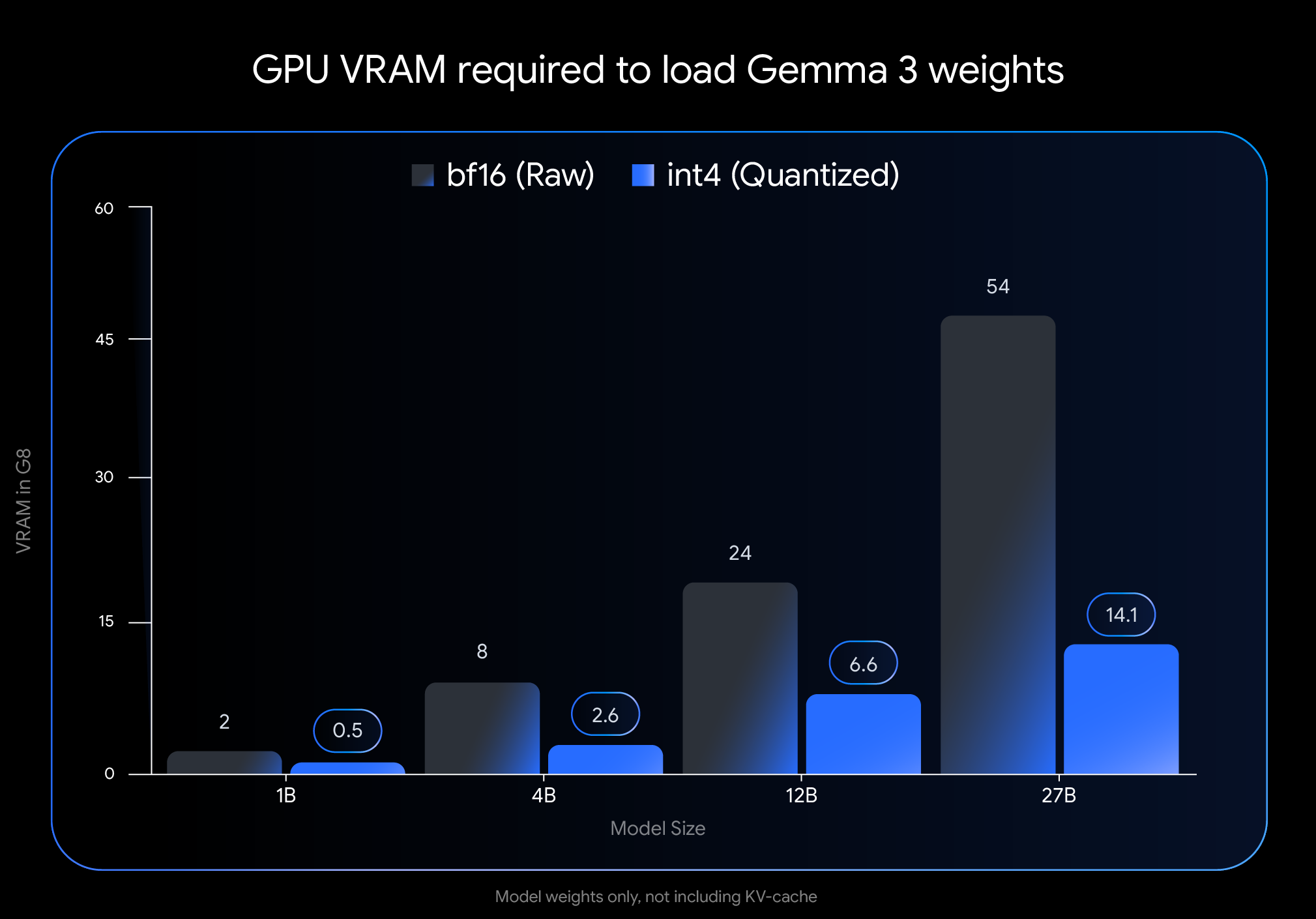
| 모델 | VRAM (BF16 기준) | VRAM (int4 기준) |
|---|---|---|
| Gemma 3 27B | 54GB | 14.1GB |
| Gemma 3 12B | 24GB | 6.6GB |
| Gemma 3 4B | 8GB | 2.6GB |
| Gemma 3 1B | 2GB | 0.5GB |
Gemma 3 QAT 모델은 Hugging Face 및 Kaggle을 통해 제공되며, 다음과 같은 도구들과 쉽게 연동할 수 있습니다:
- Ollama: 간단한 커맨드로 모델 실행 가능.
- LM Studio: 데스크탑에서 GUI 기반으로 쉽게 실행 가능.
- MLX: Apple Silicon 환경에서 최적화된 실행 지원.
- llama.cpp: GGUF 포맷을 통해 로컬 추론 가능.
Gemma 3 QAT 모델의 주요 특징
- QAT 기반 훈련: 학습 단계에서부터 양자화를 반영해 모델을 학습시켜, 후처리 양자화보다 성능 저하가 적음.
- int4 양자화: 메모리 사용량을 최대 4배까지 줄임.
- RTX 3090, RTX 4060 등 소비자 GPU에서 실행 가능 : 클라우드 서버 없이도 대형 모델 실행이 가능.
- 다양한 도구와 연동: Ollama, llama.cpp, MLX, LM Studio 등과 호환.
 Google의 Gemma 3 QAT 모델 공개 블로그
Google의 Gemma 3 QAT 모델 공개 블로그
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()