
Gemma 3n 모델 소개
2023년 구글이 공개한 첫 번째 Gemma 모델은 AI 개발자 커뮤니티와 오픈소스 생태계에서 매우 큰 반향을 일으켰습니다. Gemma는 공개 이후 1억 6천만 건 이상의 다운로드를 기록하며, 범용 모델뿐 아니라 의료, 보안, 컴퓨터 비전 등 다양한 특화 모델로 진화해 왔습니다. 그동안 전 세계 개발자와 연구자들은 Gemma를 활용해 독창적인 프로젝트를 진행해 왔으며, 이러한 움직임은 Gemma 모델이 실질적으로 현장의 요구에 부합하는 방향으로 발전하는 데 결정적인 역할을 했습니다.

이러한 흐름을 바탕으로, 구글은 Gemma 3n의 정식 버전을 발표했습니다. Gemma 3n은 "모바일 퍼스트" 아키텍처를 기반으로 설계된 차세대 오픈 AI 모델로, 개발자를 위한 다양한 지원과 손쉬운 활용성을 핵심으로 내세웁니다. Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX 등 다양한 오픈소스 생태계와의 호환성, 그리고 손쉬운 파인튜닝과 온디바이스 배포가 가능하다는 점이 큰 특징입니다.
특히 Gemma 3n은 텍스트뿐만 아니라 이미지, 오디오, 비디오 등 멀티모달 데이터를 자연스럽게 처리할 수 있습니다. 기존에는 클라우드 기반 대규모 모델에서만 볼 수 있었던 성능을 엣지 디바이스와 모바일 환경에서도 구현할 수 있게 되었으며, 이는 AI 기술의 실제 응용 범위를 크게 넓힐 수 있다는 점에서 주목받고 있습니다.

Gemma 3n은 기존의 Gemma 2, Llama, Phi, GPT-4o 등 여러 AI 오픈모델과 비교해 다음과 같은 차별점을 보입니다. 첫째, 멀티모달 입력(텍스트, 이미지, 오디오, 비디오)을 네이티브로 지원하면서도, 2GB~3GB 수준의 메모리에서 동작하는 초경량 설계가 특징입니다. 둘째, MatFormer(마트료시카 트랜스포머) 아키텍처를 도입해, 하나의 큰 모델 안에 여러 크기의 모델을 동적으로 내장할 수 있어 유연한 인퍼런스 및 최적화가 가능합니다. 셋째, Per Layer Embeddings, KV Cache Sharing 등 온디바이스 환경에 최적화된 다양한 구조적 혁신이 반영되어 있습니다. 마지막으로, 새로운 MobileNet-V5 비전 인코더와 USM 기반 오디오 인코더를 통해 엣지 디바이스에서의 멀티모달 처리 성능이 대폭 개선되었습니다.
이러한 특장점으로 인해, Gemma 3n은 텍스트와 멀티모달 AI 응용 분야에서 Llama 3, GPT-4o-nano, Phi-4 등과 비교했을 때 10B 파라미터 미만 모델 중 최고의 벤치마크 점수(LMArena 1300+)를 기록하고 있습니다.
Gemma 3n 주요 기술 및 아키텍처
Gemma 3n의 주요 특징
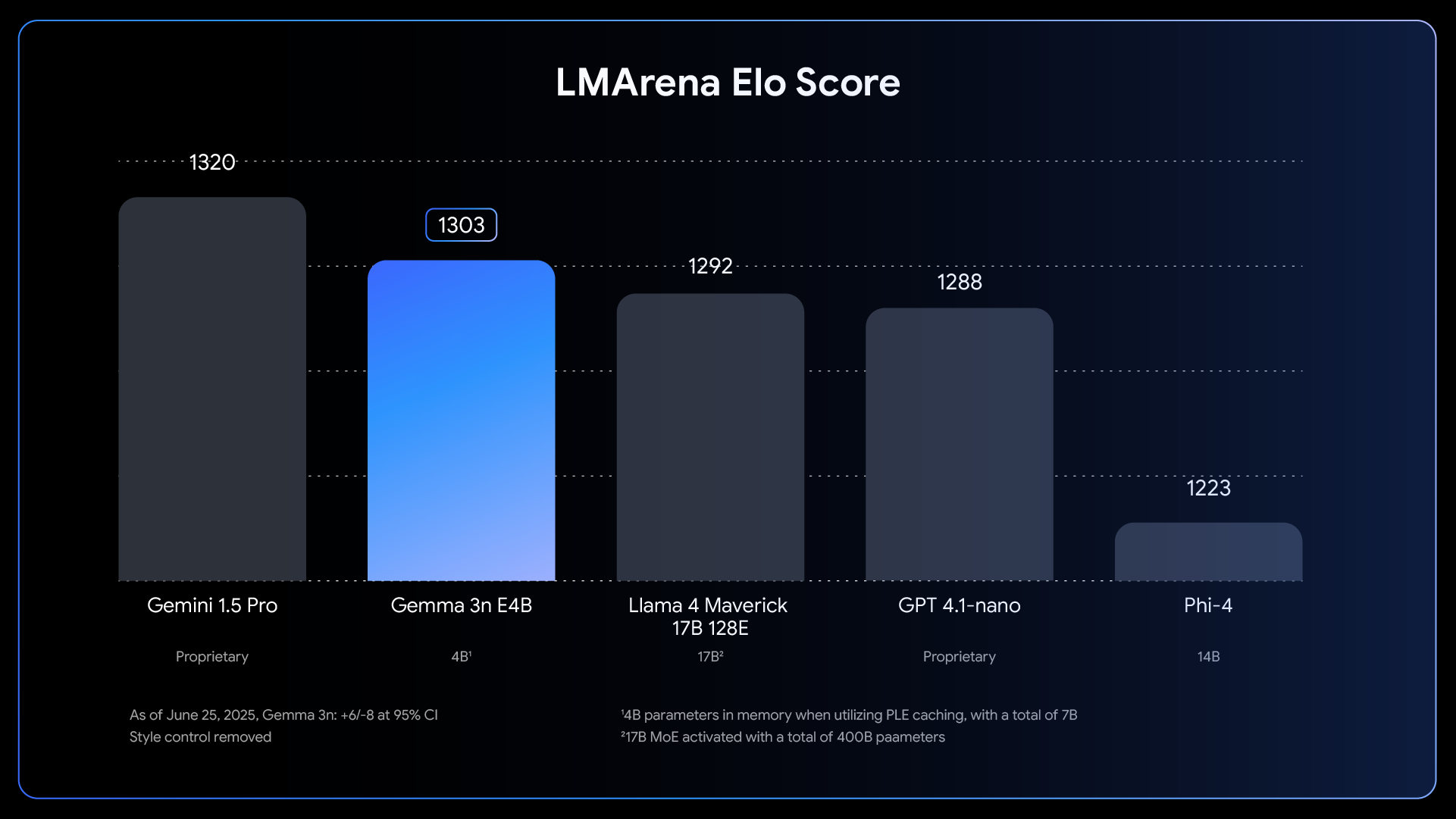
Gemma 3n은 온디바이스 AI 모델로 설계되어, 기존 클라우드 전용 AI와 달리 엣지 환경에서 실질적인 활용이 가능하도록 다양한 혁신 기술을 도입했습니다. 2B(E2B), 4B(E4B) 두 가지 모델 크기를 제공하며, 각각 2GB와 3GB 메모리만으로도 실행이 가능합니다. 특히, 효율적인 메모리 구조와 최신 아키텍처 혁신 덕분에 실제 인퍼런스 시 전통적인 2B/4B 모델과 유사한 메모리 사용량으로 동작합니다.
또한, Gemma 3n은 멀티모달 모델로 설계되어 텍스트, 이미지, 오디오, 비디오 등 다양한 입력을 동시에 처리할 수 있습니다. 140개 언어의 텍스트 및 35개 언어의 멀티모달 이해를 지원하며, 수학, 코딩, 논리적 추론 등 고난도 태스크에서도 뛰어난 성능을 보입니다.
MatFormer: 가변형 트랜스포머 아키텍처

Gemma 3n의 핵심은 MatFormer(![]() Matryoshka Transformer; 마트료시카 트랜스포머) 아키텍처에 있습니다. 이 구조는 하나의 모델 내에 여러 크기의 하위 모델을 중첩(마치 러시아의 마트료시카 인형처럼)시켜, 개발자가 필요에 따라 모델 크기와 성능을 유연하게 조절할 수 있도록 합니다. 예를 들어, 4B(E4B) 모델을 훈련할 때 동시에 2B(E2B) 서브모델도 함께 최적화됩니다. 이를 통해 개발자는 성능이 우선이면 E4B, 속도가 우선이면 E2B를 선택적으로 활용할 수 있습니다.
Matryoshka Transformer; 마트료시카 트랜스포머) 아키텍처에 있습니다. 이 구조는 하나의 모델 내에 여러 크기의 하위 모델을 중첩(마치 러시아의 마트료시카 인형처럼)시켜, 개발자가 필요에 따라 모델 크기와 성능을 유연하게 조절할 수 있도록 합니다. 예를 들어, 4B(E4B) 모델을 훈련할 때 동시에 2B(E2B) 서브모델도 함께 최적화됩니다. 이를 통해 개발자는 성능이 우선이면 E4B, 속도가 우선이면 E2B를 선택적으로 활용할 수 있습니다.
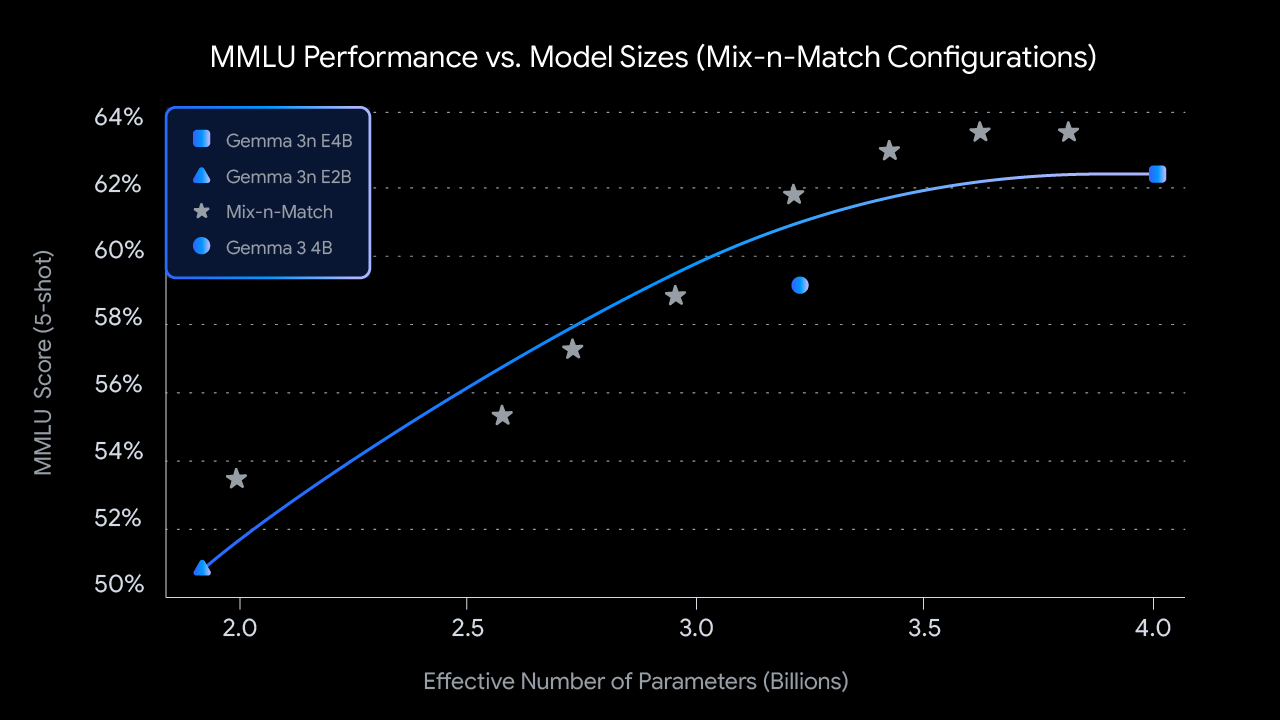
또한, 'Mix-n-Match'라는 기법을 활용하면 레이어별 피드포워드 네트워크 차원이나 레이어 수를 조절하여, E2B와 E4B 사이의 다양한 커스텀 모델을 생성할 수 있습니다. 이는 실제 하드웨어 제약에 맞춘 모델 최적화와 메모리/성능 밸런싱에 큰 장점을 제공합니다.
Per Layer Embeddings(레이어별 임베딩): 메모리 효율화

Per Layer Embeddings(이하 PLE)는 모델 품질을 유지하면서도, 가속기(GPU/TPU) 메모리 사용량을 획기적으로 줄이는 기술입니다. PLE 덕분에, 실제로는 5B/8B 규모의 모델이지만, 고속 메모리에 올려야 할 파라미터는 2B(E2B), 4B(E4B) 수준에 불과합니다. 임베딩 파라미터는 CPU 등 느린 메모리에서 효율적으로 처리할 수 있어, 엣지 디바이스에서의 대용량 모델 운용이 현실적으로 가능해졌습니다.
KV Cache Sharing: 긴 입력 처리 성능 향상
오디오/비디오 스트림 등 긴 시퀀스 입력을 처리할 때, Gemma 3n은 KV Cache Sharing이라는 구조적 최적화로 초기 프리필(prefill) 단계를 대폭 단축했습니다. 이는 기존 대비 2배 빠른 시퀀스 처리 속도를 제공하며, 온디바이스 멀티모달 AI 애플리케이션의 반응성을 크게 향상시킵니다.
오디오 이해: Universal Speech Model(USM) 기반
Gemma 3n은 Google의 Universal Speech Model(USM)을 기반으로 한 오디오 인코더를 탑재해, 160ms 단위로 오디오를 토큰화하고, 이를 자연스럽게 텍스트 처리에 통합합니다. 이를 통해 고품질 음성 인식(ASR)과 자동 음성 번역(AST)이 온디바이스에서 구현 가능합니다. 특히 영어-스페인어, 프랑스어, 이탈리아어, 포르투갈어 등 주요 언어 쌍 간 번역 성능이 매우 뛰어납니다.
MobileNet-V5: 차세대 비전 인코더
이미지와 영상 처리 성능 역시 크게 강화되었습니다. MobileNet-V5-300M 비전 인코더는 256x256, 512x512, 768x768 등 다양한 해상도를 지원하며, 60fps의 고속 비디오 분석이 가능합니다. 기존 대비 13배 이상의 속도, 46% 적은 파라미터, 4배 작은 메모리 풋프린트로도 높은 정확도를 기록하며, 엣지 디바이스의 실시간 멀티모달 태스크에 최적화되어 있습니다.
Gemma 3n 활용 및 시작 방법
Gemma 3n은 Hugging Face, Kaggle 등에서 바로 다운로드할 수 있으며, AI Studio, Ollama, llama.cpp, MLX, LMStudio 등 다양한 도구와 프레임워크에서 바로 실험 및 배포가 가능합니다. 또한, Google Cloud Vertex AI, NVIDIA API Catalog 등 여러 클라우드와 온프레미스 환경에 최적화되어 있어, 개발자는 원하는 방식대로 손쉽게 모델을 통합할 수 있습니다.
구글은 Gemma 3n의 출시와 함께 "Gemma 3n Impact Challenge" 해커톤도 개최 중입니다. 실제 온디바이스, 오프라인, 멀티모달 활용사례를 영상 데모와 함께 제출하면 총 15만 달러의 상금이 제공되니, 관심 있는 개발자라면 참여해 보는 것도 좋겠습니다.
라이선스
Gemma 3n 모델의 라이선스는 Gemma 모델 공식 라이선스로 공개 및 배포되고 있습니다. 상업적 활용에는 일부 제약이 있을 수 있으니, 반드시 라이선스 전문을 확인하시기 바랍니다.
 Gemma 3n 블로그 - 'Introducing Gemma 3n: The developer guide'
Gemma 3n 블로그 - 'Introducing Gemma 3n: The developer guide'
 Gemma 3n 모델 다운로드
Gemma 3n 모델 다운로드
 Gemma 3n 공식 문서
Gemma 3n 공식 문서
더 읽어보기
-
MatFormer 아키텍처 논문: [2310.07707] MatFormer: Nested Transformer for Elastic Inference
-
Universal Speech Model(USM) 논문: [2303.01037] Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
-
Gemma 라이선스 문서: https://ai.google.dev/gemma/docs/gemma-license
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()