
Google I/O 2026 소개
(현지시간) 2026년 5월 19일 열린 Google I/O 2026 키노트에서 Sundar Pichai CEO는 지난 1년간의 AI 기술 진전을 정리하고, Google이 "에이전트 Gemini 시대(agentic Gemini era)"에 본격 진입했음을 선언했습니다. 이번 발표의 핵심 키워드는 단순한 모델 성능 향상이 아니라, 모델이 사용자를 대신해 장시간 동안 작업을 수행하는 에이전트(Agent) 가 모든 제품의 뼈대로 자리잡기 시작했다는 점입니다. 검색(Search), Gemini 앱, Google Antigravity, Google Flow 같은 주요 제품에 일제히 에이전트가 박혀 들어갔고, 이를 떠받치는 TPU 8t/8i 신형 칩과 Gemini 3.5 Flash 모델이 함께 공개되었습니다.
특히 주목할 만한 변화는 사용량 지표입니다. 2024년 5월 월 9.7조(9.7T) 토큰을 처리하던 Google 표면(Search, Gemini 앱, Workspace 등)은 2025년 5월 약 480조(480T) 토큰을 거쳐, 2026년 5월에는 월 3.2 quadrillion(3.2 천조) 토큰을 처리하는 규모에 도달했습니다. 2년 만에 약 330배, 직전 1년 대비 7배 성장한 수치입니다. 같은 기간 Gemini 앱의 월간 활성 사용자(MAU)는 4억 명에서 9억 명으로 두 배 이상 늘었고, AI Overviews와 AI Mode는 각각 25억, 10억 MAU를 돌파했습니다. 자체 OpenAI 호환 추론과 자체 TPU를 갖추고 있는 Google이 인프라/모델/제품/단말까지 풀스택을 수직 통합한 결과가 본격적으로 모이기 시작한 발표라고 정리할 수 있습니다.
이번 글에서는 키노트에서 공개된 발표를 (1) 인프라와 칩, (2) Gemini 3.5 Flash와 Antigravity 2.0, (3) Gemini Omni 멀티모달 모델, (4) Gemini Spark 등 소비자용 에이전트, (5) 검색과 Workspace 통합, (6) SynthID 등 안전성과 투명성, 그리고 (7) Gemini for Science와 스마트 안경 등 폼팩터 확장 순으로 정리해보도록 하겠습니다.
핵심 발표 요약
-
Gemini 3.5 Flash 출시: Gemini 3 라인업의 새 주력 모델. 대부분의 벤치마크에서 이전 Gemini 3.1 Pro를 능가하면서도 다른 프런티어 모델 대비 4배(Antigravity 환경에서는 12배) 빠른 출력 속도와 절반 이하 가격을 제공합니다.
-
Gemini Omni Flash 공개: 모든 입력 모달리티에서 모든 출력 모달리티로 변환 가능한 옴니 모달 생성 모델. 우선 비디오 출력으로 출시되었으며, Gemini 앱, Google Flow, YouTube Shorts에서 바로 사용할 수 있습니다.
-
Gemini Spark, 24/7 개인 에이전트: 전용 Google Cloud VM 위에서 24시간 돌아가는 개인 AI 에이전트. MCP(Model Context Protocol)를 통한 서드파티 도구 연동, Android Halo UI, 그리고 Chrome 내장 에이전트 모드를 예고했습니다.
-
TPU 8t / 8i 도입: 학습 전용 TPU 8t와 추론 전용 TPU 8i로 처음으로 듀얼 칩 전략을 채택. 학습은 JAX와 Pathways 위에서 100만 개 이상의 TPU를 여러 데이터센터에 걸쳐 학습 클러스터로 묶을 수 있게 되었고, 추론은 와트당 성능이 2배까지 향상되었습니다.
-
Antigravity 2.0: Antigravity 가 IDE 안의 코딩 도구에서 벗어나 자율 에이전트 무리를 오케스트레이션하는 데스크톱 앱으로 확장됩니다. 같은 흐름에서 Google Pics, Daily Brief, Docs Live, Ask YouTube 등 제품 내 에이전트 기능도 함께 공개되었습니다.
-
SynthID 확대와 산업 표준화: 누적 1,000억 장 이상의 이미지/영상과 6만 년 분량의 오디오에 워터마크가 입혀졌고, 이번에 OpenAI, Kakao, ElevenLabs가 SynthID에 합류해 cross-industry 합의가 한 걸음 더 나아갔습니다.
풀스택 AI 모멘텀: 토큰으로 측정하는 규모
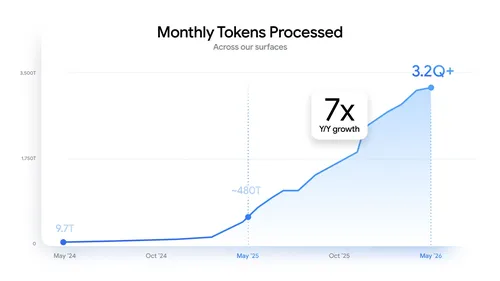
Pichai CEO는 "사람들이 AI에서 가치를 보기 시작한 사이클에 와있다"고 짚으면서, 진전을 측정하는 가장 좋은 프락시로 처리 토큰(tokens processed) 을 들었습니다. 2024년 5월 월 9.7조 토큰이었던 처리량은 2025년 I/O 시점에 약 480조, 2026년 I/O 시점에 월 3.2 quadrillion+ (3,200조) 로 늘었고, 이는 직전 해 대비 약 7배 성장에 해당합니다. 그 배경에는 다음과 같은 수치가 자리합니다:
- 매월 850만 명 이상의 개발자 가 Google 모델을 활용해 새 앱과 경험을 만들고 있습니다.
- Google의 모델 API는 분당 약 190억 토큰 을 처리하고 있습니다.
- 지난 12개월 동안 375개 이상의 Google Cloud 고객사 가 각각 1조 토큰 이상을 처리했습니다. 이는 산업 전반에서 AI 수요가 폭증하고 있음을 보여주는 신호입니다.
제품 측면에서는 10억 명 이상의 사용자가 쓰는 제품이 13개, 그중 30억 명 이상이 쓰는 제품이 5개 입니다. Google 검색, Gmail, Google 지도, YouTube, Android 등 거대 제품에 Gemini가 일제히 박히면서, "AI 기능 = 별도 앱"이라는 인식이 빠르게 사라지고 있습니다. 50억 장 이상이 생성된 Nano Banana 이미지 모델 도 같은 흐름에서 사용자들의 일상 도구로 자리잡았습니다.
인프라: TPU 8t와 TPU 8i, 그리고 1,800억 달러 자본지출(CapEx)

Google은 이러한 규모를 떠받치기 위한 인프라 투자를 2022년 연간 310억 달러에서 2026년 약 1,800~1,900억 달러 수준으로 6배가량 늘렸습니다. 핵심은 자체 실리콘인 TPU(Tensor Processing Unit)이며, 이번 I/O에서는 8세대 TPU 를 학습 전용(8t)과 추론 전용(8i)으로 분리한 듀얼 칩 전략 을 처음으로 도입했다고 밝혔습니다.
-
TPU 8t (학습용): 대규모 사전 학습(pretraining)에 최적화된 칩으로, 이전 세대 대비 약 3배의 원시 컴퓨팅 성능을 제공합니다. JAX 와 Pathways 런타임 덕분에 학습이 더 이상 단일 데이터센터의 한계에 묶이지 않으며, 전 세계 100만 개 이상의 TPU 를 여러 사이트에 걸쳐 하나의 학습 클러스터로 묶을 수 있게 되었습니다. 그 결과 더 크고 더 능력 있는 모델을 "달 단위"가 아닌 "주 단위"로 학습할 수 있다는 것이 Google의 설명입니다.
-
TPU 8i (추론용): 모든 단계에서 속도가 크게 개선된 추론 전용 칩입니다. Pichai는 "27년간 검색을 만들며 배운 것이 있다면 그것은 레이턴시가 중요하다(latency matters) 는 사실"이라고 강조했습니다.
-
에너지 효율: 두 칩 모두 와트당 성능이 최대 2배 향상 되었습니다. 단순한 raw FLOPs 증가가 아니라 지속 가능한 확장성을 함께 챙긴 것이 8세대의 특징입니다.
학습이 단일 데이터센터 경계를 벗어났다는 점은 일반 개발자에게도 의미가 큽니다. DeepSpeed, PyTorch FSDP, Megatron-LM 등 기존 대규모 학습 도구가 한 데이터센터 내 인터커넥트에 강하게 의존해온 반면, JAX/Pathways 기반의 멀티 사이트 학습은 발전소 단위가 아닌 지역 단위로 분산된 학습을 본격적으로 보여주는 사례입니다.
Gemini 3.5 Flash: 프런티어 지능 + 액션
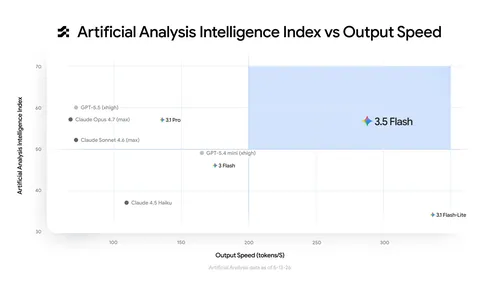
이번 I/O의 모델 측 주연은 Gemini 3.5 Flash 입니다. Google은 "지능(intelligence)과 액션(action)을 결합한 첫 모델 시리즈 의 시작"이라고 표현했습니다. 핵심은 다음 두 가지입니다:
-
벤치마크 우위: Gemini 3.1 Pro와 비교했을 때, 3.5 Flash는 대부분의 벤치마크에서 더 좋습니다. 특히 코딩이 크게 개선되었고, 실제 경제적 가치가 있는 작업을 측정하는 GDPVal 에서 극적인 점수 상승을 보였습니다. 즉, 같은 라인업의 더 큰 직전 모델보다 작은 모델이 더 강한 "역전 현상"이 발생했습니다.
-
속도/비용: Artificial Analysis 의 지능 지수 vs 출력 속도 산점도에서 3.5 Flash는 GPT-5.5(xhigh), Claude Opus 4.7(max) 같은 프런티어 모델들과 어깨를 나란히 하면서도 출력 토큰 기준으로 약 4배 빠른 영역에 위치합니다. 가격은 비교 가능한 프런티어 모델의 절반 이하 로 책정되었습니다.

Google 내부에서는 3.5 Flash가 새로운 Antigravity 에이전트 개발 플랫폼과 결합되면서 개발 속도를 극적으로 끌어올렸다고 합니다. 2026년 3월 사내 AI 개발 도구가 처리하던 토큰은 일 5,000억 개였지만, 몇 주마다 두 배씩 늘어 현재는 일 3조 개를 넘었습니다. 이 피드백 루프가 다시 3.5의 품질 개선에 활용되는 구조입니다.
Pichai는 비용 측면 시나리오도 구체적으로 제시했습니다. 상위 기업들이 하루 약 1조 토큰을 처리한다고 할 때, 워크로드의 80%를 다른 프런티어 모델에서 3.5 Flash로 옮기면 연간 10억 달러 이상의 비용을 절감 할 수 있다는 추산입니다. 이는 OpenAI, Anthropic 등과의 직접적인 가격 경쟁 선언으로 읽힙니다. 차세대 모델인 Gemini 3.5 Pro 는 다음 달 공개 예정으로, 내부 테스트에서 "큰 향상"을 보이고 있다고 합니다.
Antigravity 2.0: 에이전트 무리를 다루는 데스크톱
이전 세대의 Antigravity 가 코딩 환경에 머물렀다면, 이번에 공개된 Antigravity 2.0 은 자율 AI 에이전트 코호트(cohorts)를 개발하고 관리하는 플랫폼으로 진화합니다. 구체적으로는 (1) 별도 데스크톱 앱이 추가되어 모든 에이전트 상호작용의 중심 허브가 되고, (2) 사용자는 그 안에서 다양한 작업을 위한 에이전트 무리를 오케스트레이션할 수 있으며, (3) Antigravity 환경에 최적화된 별도 버전의 Flash가 도입되어 다른 프런티어 모델 대비 약 12배 빠른 코딩 응답 속도를 제공합니다. 자세한 변경 사항은 I/O 2026 개발자 하이라이트 에 정리되어 있습니다.
Cursor, Cline, Aider, Claude Code 와 같은 에이전트형 개발 도구가 빠르게 늘어나는 가운데, Google은 모델과 IDE, OS, 클라우드 자원을 한 번에 통합한 패키지를 제시한 셈입니다.
Gemini Omni: 멀티모달에서 옴니모달로

Gemini Omni 는 임의의 입력 모달리티에서 임의의 출력 모달리티 샘플을 생성할 수 있는 모델입니다. 이번 I/O에서는 그 첫 번째 모델인 Gemini Omni Flash 가 비디오 출력을 시작으로 공개되었으며, 이후 이미지와 텍스트 출력을 차례로 지원할 예정입니다. 이는 Gemini의 추론 능력과 Veo, Lyria, Imagen 같은 생성 미디어 모델 라인업을 하나의 모델에 통합한 결과로, "텍스트를 예측하는 모델"에서 "현실을 시뮬레이션하는 모델"로의 전환점을 강조하는 발표였습니다.
Gemini Omni Flash는 발표 당일부터 Gemini 앱, Google Flow, YouTube Shorts에서 사용할 수 있고, API를 통한 개발자/엔터프라이즈용 출시는 몇 주 내로 진행됩니다.
옴니 모달 모델은 GPT-4o, Claude, Qwen-Omni 등에서 이미 윤곽을 그려온 흐름이지만, Google이 이를 자사 생성 미디어 모델과 합쳐 "월드 모델(world model)"이라는 표현을 쓴 점이 눈에 띕니다. 텍스트 토큰 기반이 아니라 영상/오디오/이미지가 모델의 1급 시민이 되는 방향입니다.
Gemini Spark: 24시간 가동되는 개인 에이전트

소비자용 발표 중 가장 무게가 실린 것은 Gemini Spark 입니다. Gemini 앱 안에 박힌 개인 AI 에이전트로, 디지털 생활 전반을 사용자 지시 아래 자율적으로 처리합니다. 핵심 특징은 다음과 같습니다:
-
전용 가상 머신 + 24/7 작동: Spark는 Google Cloud 위 전용 VM에서 24시간 돌아갑니다. 노트북을 켜둘 필요가 없고, 사용자가 자는 동안에도 장기 작업이 진행됩니다.
-
3.5 Flash + Antigravity 하니스: 모델은 Gemini 3.5 Flash이고, 그 위에 Antigravity 에이전트 하니스가 얹혀 장기간(long-horizon)의 다단계 작업을 백그라운드에서 수행합니다.
-
MCP를 통한 서드파티 통합: 우선 Google 자체 도구로 시작하지만, 곧 MCP(Model Context Protocol) 를 통해 외부 도구를 연결할 예정입니다. Anthropic이 공개한 MCP 가 Google의 소비자 에이전트에서도 표준 어댑터로 채택된다는 점은 의미가 큽니다.
-
다채널 사용: Gemini 앱뿐 아니라 이메일/채팅에서도 Spark에 일을 시킬 수 있습니다.
-
Android Halo: Android에서는 새 UI 영역인 Android Halo 를 통해 Spark 같은 에이전트의 라이브 진행 상황을 항상 볼 수 있습니다.
-
에이전틱 브라우저로서의 Chrome: 이번 여름 말 Spark는 Chrome 안에서 직접 작동해 웹 전반을 가로지르는 "에이전틱 브라우저" 역할을 하게 됩니다.
Gemini Spark는 이번 주부터 신뢰할 수 있는 테스터들에게 롤아웃되며, 다음 주에는 미국 Google AI Ultra 구독자들에게 베타가 열립니다.
에이전틱 검색: 정보 에이전트와 생성 UI

검색은 가장 직접적으로 영향을 받는 영역입니다. 이번 I/O에서는 세 갈래의 새 기능이 공개되었습니다:
-
정보 에이전트(Information Agents): 사용자가 미리 설정해 두면 24시간 백그라운드에서 돌아가며, 필요한 정보가 등장하는 정확한 순간에 알림을 보내고 후속 행동까지 도와주는 개인화 에이전트입니다. 이번 여름부터 Google AI Pro 및 Ultra 구독자에게 우선 제공됩니다.
-
생성 UI(Generative UI): Gemini 3.5 Flash와 Antigravity의 코딩 능력이 검색에 박히면서, 검색 결과 페이지 자체가 질의에 맞춰 그때그때 빌드되는 다이내믹 레이아웃 과 인터랙티브 비주얼 로 채워집니다. 이는 모든 사용자에게 무료로 이번 여름 제공됩니다.
-
지속형 대시보드와 트래커: 한 번의 검색이 아닌, 사용자가 반복해서 돌아오는 장기 과제에 대해 검색이 직접 "미니 앱"을 만들어줍니다. 사용자는 그 위에서 진척도를 추적하고 후속 액션을 이어갈 수 있습니다.
검색이 단일 쿼리에 답하는 도구에서 "계속 이어지는 대화(ongoing conversation) "로 바뀌고 있다는 표현이 인상적입니다. AI Overviews 가 월 25억 MAU, AI Mode 가 출시 1년 만에 월 10억 MAU를 돌파했다는 점이 이러한 방향성의 근거로 제시되었습니다.
음성 대화와 창작 도구의 에이전트화: Ask YouTube, Docs Live, Flow, Pics, Daily Brief
또 다른 큰 흐름은 음성/대화형 인터페이스가 제품 안으로 깊이 들어왔다는 것입니다. 최근 지도 에 추가된 Ask Maps 가 사용자들에게 더 복잡하고 긴 질문을 끌어내고 있는 데 이어, 이번 I/O에서는 두 가지가 더 공개되었습니다:
-
Ask YouTube: 사용자가 YouTube 검색창에 던지는 질문에 대해, 단순히 관련 동영상 리스트를 반환하는 대신 답이 들어 있는 정확한 영상 구간으로 점프 합니다. 이는 영상 시청 경험을 "도큐먼트 읽기"에 가깝게 바꾸는 시도이며, 이번 여름 미국에서 광범위하게 롤아웃됩니다.
-
Docs Live: Google Docs 에서 정확한 프롬프트를 타이핑할 필요 없이, 사용자가 머릿속의 생각을 그대로 음성으로 "브레인 덤프" 하면 Gemini가 문서를 만들어 줍니다. 이번 여름부터 구독자에게 제공되며, 같은 시기에 음성 기능이 Gmail 과 Keep 에도 들어갑니다.

같은 흐름에서 소비자/크리에이터 도구 전반에도 에이전트 기능이 추가되었습니다:
-
Google Flow의 에이전트 기능: 영상 제작 도구 Google Flow 에 작업을 계획하고 추론하는 에이전트가 추가됩니다. 초기 브레인스토밍, 생성, 편집을 돕고, Flow 안에서 직접 "바이브 코딩(vibe coding)"으로 비디오 이펙트, 손그림 애니메이션, 텍스트 레이어링 같은 창작 도구를 만들 수 있습니다.
-
Google Pics: 최신 Nano Banana 모델을 기반으로 한 새 이미지 창작/편집 도구입니다. 이미지를 평면적 픽셀 묶음이 아니라 개별 객체(element) 단위로 다루기 때문에 부분 교체나 디테일 수정이 자유롭습니다. 우선 신뢰할 수 있는 테스터에게 공개되었고, 이번 여름 미국 Google AI Pro/Ultra 구독자에게 Workspace 안에서 롤아웃됩니다.
-
Daily Brief: Gemini 앱에 들어가는 박스 형태의 개인화 디지털 비서로, 받은 편지함, 캘린더, 할 일을 합쳐 그날 가장 중요한 것을 우선순위화하고, 다음 행동까지 제안해주는 짧은 모닝 요약을 만들어줍니다. 단순 요약이 아니라 정리/우선순위/추천이 결합되어 있어, Microsoft Copilot, Notion AI, Mem 같은 개인 생산성 AI들과 동일한 영역을 노립니다.
SynthID와 콘텐츠 자격 증명: 투명성의 산업 표준화
생성 AI가 좋아질수록 출처와 진위 확인 도구의 필요성이 커집니다. Google에 따르면 사람들은 고품질 딥페이크 비디오를 정확히 식별하는 비율이 약 25%에 불과합니다. 이를 보완하기 위해 도입된 SynthID 는 육안으로 보이지 않는 워터마크를 콘텐츠에 새기는 기술로, 그동안 1,000억 장 이상의 이미지/영상과 6만 년 분량의 오디오 에 적용되었습니다.
이번 I/O에서는 Gemini 앱의 SynthID 디텍터를 검색과 Chrome으로 확장하고, Content Credentials 라는 산업 표준 메타데이터 기반의 콘텐츠 자격 증명도 함께 표시하기로 했습니다. 사용자는 콘텐츠가 AI 생성인지, 카메라로 촬영된 것인지, 생성 AI 도구로 편집된 것인지를 일관된 방식으로 확인할 수 있게 됩니다.
표준화 측면에서 큰 변화는 OpenAI, Kakao, ElevenLabs가 SynthID에 새로 합류 했다는 점입니다. 작년 NVIDIA가 합류한 데 이은 행보로, 모델 공급자들 사이에 "어차피 워터마킹은 표준이 되는 방향이라면, 일찍 합의된 표준에 합류하는 편이 유리하다"는 균형점이 형성되고 있음을 시사합니다.
Gemini for Science와 스마트 안경: 폼팩터와 도메인의 확장

마지막으로, Gemini는 과학 연구와 새로운 폼팩터로 확장됩니다.
-
Gemini for Science: Deep Think, Deep Research, 그리고 새로운 Science Skills 가 결합되어, Google Antigravity 와 같은 에이전트 플랫폼을 30개 이상의 주요 생명과학 데이터베이스/도구 와 연결합니다. Google Labs 에서 시도해볼 수 있고, Science Skills 는 GitHub와 Antigravity에서 바로 사용할 수 있습니다. AlphaFold, Med-Gemini 의 흐름이 일반 연구자가 직접 쓸 수 있는 도구 레이어로 내려온 셈입니다.
-
인텔리전트 아이웨어: 작년에 살짝 공개된 스마트 안경 라인이 두 갈래로 정리되었습니다.

오디오 글래스는 귀에 음성 안내를 들려주는 핸즈프리 보조이고, 디스플레이 글래스는 시야 한쪽에 필요한 정보를 띄워줍니다. 두 종류 모두 Gemini에게 말로 묻기만 하면 되며, 오디오 글래스가 먼저 올가을 출시될 예정입니다. Project Astra 의 연장선상에서, 모델·OS·하드웨어가 함께 묶이는 그림이 점점 또렷해지고 있습니다.
시사점: 모델이 아니라 "에이전트 + 인프라" 경쟁의 시대로
이번 I/O 2026이 보여준 그림은 분명합니다. 경쟁의 축이 벤치마크 1점 더 높은 모델 에서, "모델 + 에이전트 하니스 + 전용 칩 + 멀티 데이터센터 학습 + 제품 통합 + 폼팩터 "까지 모두 묶은 풀스택 패키지로 옮겨갔다는 것입니다. Gemini 3.5 Flash가 가격/속도/지능을 모두 끌어올린 것은 이 패키지 안에서의 한 조각일 뿐이고, Antigravity 2.0과 Gemini Spark가 그 모델을 24시간 작동하는 자율 에이전트 로 묶어내는 방식이 더 큰 메시지입니다.
PyTorch와 JAX 양쪽 생태계, vLLM / SGLang 같은 추론 엔진, LangGraph / AutoGen / CrewAI 같은 에이전트 프레임워크 입장에서는, 이번 발표가 다음과 같은 질문을 던집니다:
(1) 멀티 데이터센터 학습이 일반화되면, 단일 노드/단일 클러스터에 최적화된 학습 라이브러리는 어디까지 따라갈 수 있을까?
(2) "에이전트 무리(cohort)"가 표준이 되는 환경에서, 오픈 소스 에이전트 런타임은 어떤 추상화를 표준으로 잡아야 할까?
(3) Spark가 MCP 를 채택했듯, 모델 공급자 간 상호운용 프로토콜이 진짜 표준으로 굳어질 수 있을까?
위 세 질문에 대한 답이 향후 1~2년 오픈소스 AI 진영의 큰 방향을 결정할 가능성이 높습니다.
 I/O 2026: Welcome to the agentic Gemini era 소개 블로그
I/O 2026: Welcome to the agentic Gemini era 소개 블로그
 Google I/O 2026 발표 모음
Google I/O 2026 발표 모음
더 읽어보기
-
TorchTPU, Google이 공개한 PyTorch의 네이티브 TPU 백엔드, Gemini와 Veo를 떠받치는 슈퍼컴퓨팅 인프라를 PyTorch에서 직접 활용하기
-
TorchTPU, Google이 공개한 PyTorch의 네이티브 TPU 백엔드, Gemini와 Veo를 떠받치는 슈퍼컴퓨팅 인프라를 PyTorch에서 직접 활용하기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()