
TorchTPU 소개
오늘날 최전선에 있는 거대 모델들은 더 이상 단일 가속기 위에서 학습되지 않습니다. Gemini, Veo, GPT 계열, Claude 계열 등 최신 모델들은 수만 개 단위의 가속기 클러스터를 동시에 활용하며, 이런 규모에서는 가속기 칩 자체의 연산 능력만큼이나 칩과 칩, 호스트와 호스트를 잇는 네트워크 토폴로지와 그 위에서 동작하는 소프트웨어 스택의 품질이 모델의 학습 속도와 비용을 결정합니다. 이러한 맥락에서 Google은 자체 설계한 TPU(Tensor Processing Unit)를 자사 인프라의 핵심으로 삼아왔고, Cloud TPU 형태로 외부 사용자들에게도 개방해 왔습니다.

문제는 PyTorch 사용자가 TPU를 자연스럽게 사용하기 어려웠다는 점이었습니다. 기존 PyTorch/XLA 경로는 동작은 했지만, SPMD(Single Program Multiple Data) 가정과 XLA 컴파일러의 제약 때문에 일반적인 PyTorch 코드를 그대로 옮기기에는 마찰이 적지 않았습니다. 결과적으로 TPU는 JAX 사용자에게는 친숙하지만, 압도적 다수를 차지하는 PyTorch 사용자에게는 진입 장벽이 있는 하드웨어로 남아 있었습니다.
이번에 Google Developers 블로그에 공개된 TorchTPU는 바로 이 격차를 메우기 위해 설계된 새로운 PyTorch 네이티브 TPU 백엔드입니다. 핵심 메시지는 단순합니다. "기존 PyTorch 스크립트의 디바이스 초기화만 tpu로 바꾸면, 학습 루프의 핵심 로직은 한 줄도 바꾸지 않고 TPU에서 그대로 돌아간다." TorchTPU는 PyTorch의 PrivateUse1 인터페이스 위에 직접 통합되어, 별도의 서브클래스나 래퍼 없이 평범한 torch.Tensor가 TPU 디바이스에 올라가는 진짜 네이티브 경험을 제공합니다. 더 나아가 세 가지 eager 모드, torch.compile 기반 정적 컴파일, 분산 학습(DDP/FSDPv2/DTensor), 그리고 Pallas/JAX 기반 커스텀 커널까지 폭넓은 사용 패턴을 한 스택 안에 담았습니다.
이 글에서는 TorchTPU 발표 내용을 정리하기에 앞서, TPU라는 하드웨어가 무엇이고 왜 PyTorch와 자연스럽게 결합하기 까다로웠는지를 먼저 짚은 뒤, TorchTPU의 아키텍처와 2026년 로드맵을 차례로 살펴봅니다.
TPU(Tensor Processing Unit)란 무엇인가
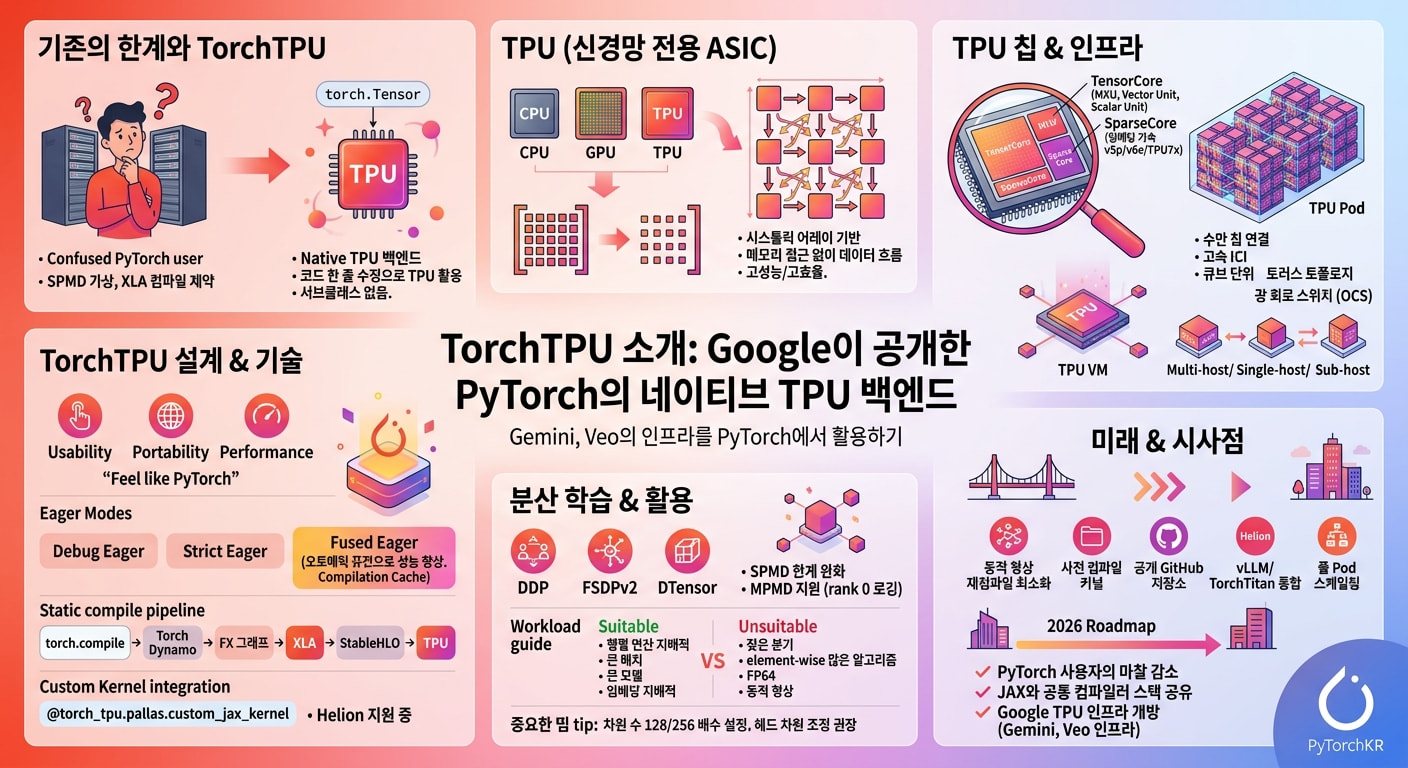
TPU를 한 문장으로 요약하면, 신경망의 행렬 연산만을 위해 설계된 ASIC(Application-Specific Integrated Circuit) 입니다. CPU나 GPU와 달리 워드프로세서를 돌리거나 일반 그래픽을 처리하지는 못하지만, 신경망에서 가장 자주 등장하는 거대한 행렬 곱셈(matmul)과 누적합(accumulate) 연산을 극단적으로 빠르게 수행하도록 만들어졌습니다.
CPU, GPU, TPU의 구조적 차이
CPU는 폰 노이만 구조(von Neumann architecture)를 따릅니다. 매 연산마다 메모리에서 값을 읽고, 계산하고, 다시 메모리에 결과를 저장합니다. 유연성은 최고이지만, 메모리 접근 속도가 연산 속도를 따라가지 못해 발생하는 폰 노이만 병목(von Neumann bottleneck)이 처리량의 상한을 결정합니다.
GPU는 한 칩 안에 수천 개의 ALU(Arithmetic Logic Unit)를 두어 동시에 수천 번의 곱셈/덧셈을 수행합니다. 신경망의 행렬 연산처럼 대규모 병렬성이 있는 작업에서 CPU보다 한 자릿수 이상 높은 처리량을 보여줍니다. 그러나 GPU 역시 범용 프로세서이기 때문에 매 연산마다 레지스터나 공유 메모리를 통해 피연산자와 중간 결과를 주고받는 비용이 그대로 남아 있습니다.
TPU는 여기서 한 걸음 더 나아갑니다. TPU의 핵심은 시스톨릭 어레이(Systolic Array) 구조의 MXU(Matrix Multiplication Unit)입니다. MXU 안에는 곱셈-누산기(multiply-accumulator)들이 격자 형태로 직접 연결되어 있어, 한 번 HBM(High Bandwidth Memory)에서 파라미터를 로드한 뒤에는 데이터가 셀과 셀 사이를 흘러다니며 곱셈-누산이 연쇄적으로 수행됩니다. 행렬 곱 도중에는 메모리 접근이 일어나지 않는다는 점이 핵심으로, 이 구조 덕분에 TPU는 신경망 연산에서 매우 높은 처리량과 에너지 효율을 달성합니다.
세대별 MXU 크기는 점점 커져 왔습니다. 초기 TPU와 v3, v4, v5p 등은 128x128 MXU를 사용하지만, 최신 TPU v6e와 TPU7x(Ironwood)는 256x256 MXU를 탑재하여 한 사이클당 더 많은 곱셈-누산 연산을 처리합니다. 모든 곱셈은 bfloat16 입력을 받지만, 누적은 FP32에서 수행하여 학습 안정성을 확보합니다.
TPU 칩의 내부 구성: TensorCore와 SparseCore
TPU 칩 한 장은 하나 이상의 TensorCore를 포함합니다. 각 TensorCore는 한 개 이상의 MXU와 벡터 유닛, 스칼라 유닛으로 구성되며, 각 역할은 다음과 같습니다.
- MXU: 한 사이클에 약 16K개의 곱셈-누산 연산을 처리하는 행렬 연산 코어로, TensorCore 연산력의 대부분을 담당
- 벡터 유닛(Vector Unit): 활성화 함수, softmax 등 element-wise 연산을 처리
- 스칼라 유닛(Scalar Unit): 제어 흐름, 메모리 주소 계산 등 보조 연산을 담당
여기에 더해 v5p와 TPU7x에는 칩당 4개, v6e에는 칩당 2개의 SparseCore 가 탑재됩니다. SparseCore는 추천 시스템에서 자주 등장하는 거대 임베딩 테이블의 gather/scatter 같은 불규칙 메모리 접근 패턴을 가속하기 위한 데이터플로우 프로세서로, 광고나 추천 모델처럼 임베딩이 지배적인 워크로드의 성능을 좌우하는 핵심 부품입니다.
TPU Pod와 ICI: "한 칩"이 아닌 "한 네트워크"로서의 TPU
TPU의 진짜 위력은 단일 칩이 아니라 수많은 칩이 묶인 거대한 네트워크에서 드러납니다. TPU 칩들은 칩과 칩을 직접 잇는 고속 ICI(Inter-Chip Interconnect) 링크를 통해 2D 또는 3D 토러스(Torus) 토폴로지로 연결되며, 이렇게 묶인 단위를 슬라이스(Slice) 라고 부르고, 한 슬라이스가 모인 더 큰 단위를 TPU Pod 라고 부릅니다. v4 이후로는 4x4x4 칩으로 구성된 TPU 큐브(cube) 가 3D 토폴로지의 기본 단위가 됩니다.
ICI는 일반적인 데이터센터 네트워크와 달리 칩 간 직결 링크에 가까워, 분산 학습에서 자주 등장하는 all-reduce나 reduce-scatter 같은 집합 통신(collective communication)을 매우 낮은 지연으로 수행할 수 있습니다. 큐브 사이를 잇는 광 회로 스위치(OCS) 구간에는 ICI 회복성(ICI resiliency) 기능이 적용되어, 광 링크 장애가 있을 때 경로를 우회시켜 슬라이스 가용성을 유지합니다.
슬라이스 하나로 부족한 대규모 워크로드의 경우 여러 슬라이스를 Multislice 구성으로 묶어, 슬라이스 간에는 데이터센터 네트워크(DCN)를 사용하면서 슬라이스 내에서는 ICI를 활용하는 하이브리드 병렬화를 구현할 수 있습니다.
TPU VM 아키텍처: 워크로드를 어디서 실행하는가
Cloud TPU는 TPU 하드웨어를 TPU VM 형태로 제공합니다. TPU VM은 TPU 디바이스에 직접 연결된 리눅스 가상 머신으로, 사용자는 SSH로 접속하여 root 권한으로 임의의 코드를 실행할 수 있고, 컴파일러와 런타임의 디버그 로그도 직접 확인할 수 있습니다. 이러한 TPU VM 아키텍처는 워크로드 실행 단위에 따라 다음 세 가지로 구분됩니다.
- Single-host workload: 단일 TPU VM에서 실행되는 워크로드
- Multi-host workload: 여러 TPU VM에 학습을 분산하는 워크로드
- Sub-host workload: 한 TPU VM의 일부 칩만 사용하는 워크로드
TPU VM은 직접 사용할 수도 있고, GKE(Google Kubernetes Engine)나 Vertex AI를 통해 더 추상화된 형태로 사용할 수도 있습니다.
TPU가 잘 맞는 워크로드와 그렇지 않은 워크로드
Cloud TPU 공식 문서에서는 TPU에 적합한 워크로드와 그렇지 않은 워크로드를 비교적 명확하게 구분하고 있습니다. 다음은 그 요약입니다.
| 적합한 워크로드 | 적합하지 않은 워크로드 |
|---|---|
| 행렬 연산이 지배적인 모델 | 잦은 분기와 element-wise 연산이 많은 알고리즘 |
| 학습 루프 내 커스텀 PyTorch/JAX 연산이 거의 없는 모델 | 고정밀(FP64 등) 연산이 필요한 워크로드 |
| 수 주~수 개월에 걸쳐 학습되는 모델 | 학습 메인 루프에 커스텀 연산이 많은 모델 |
| 큰 effective batch size를 사용하는 큰 모델 | 동적 텐서 형상(shape)이 빈번하게 바뀌는 모델 |
| 추천 모델처럼 거대 임베딩이 지배적인 모델 |
또한 TPU에서는 모델 설계 시 차원 수를 128 또는 256의 배수로 맞추는 것이 매우 중요합니다. MXU가 128x128 또는 256x256 시스톨릭 어레이이기 때문에, 그 배수에서 벗어난 차원은 zero-padding이 들어가 메모리와 연산을 모두 낭비하게 됩니다. 예를 들어 어텐션 헤드 차원을 흔히 64로 잡는 경우가 많은데, TorchTPU 발표에서도 이를 128 또는 256으로 늘리면 TPU의 dense tensor core를 더 잘 활용할 수 있다고 강조합니다.
TPU 하드웨어의 10년 역사와 설계 철학에 대해 더 알고 싶다면, 다음 PyTorchKR 게시물도 참고해주세요.
https://discuss.pytorch.kr/t/gn-tpu-ai-10
TorchTPU의 설계 원칙: "그냥 PyTorch처럼 느껴져야 한다"
이제 본론인 TorchTPU로 돌아가 보겠습니다. TorchTPU 엔지니어링팀이 내건 핵심 원칙은 세 가지입니다. 사용성(Usability), 이식성(Portability), 그리고 성능(Performance). 그리고 이 세 원칙을 한 문장으로 압축한 것이 바로 "It should feel like PyTorch" 입니다.
이전 세대인 PyTorch/XLA는 PyTorch 코드를 XLA HLO로 변환해 TPU에서 실행하는 경로를 제공했지만, 학습 루프 안에서 PyTorch 텐서가 여전히 lazy tensor로 추상화되어 동작하고, 코드가 SPMD 가정을 강하게 따라야 하는 등 PyTorch 사용자가 평소에 쓰던 코드와는 다른 흐름을 강요했습니다.
TorchTPU는 이 부분을 정면으로 바꿉니다. PyTorch 2.x에서 새로운 백엔드 통합 지점으로 도입된 PrivateUse1 인터페이스를 활용하여, torch.Tensor를 그대로 TPU 디바이스에 올린다는 단순하면서도 강력한 통합 방식을 채택했습니다. 서브클래스도, 별도 래퍼 클래스도 없습니다. 사용자가 보기에는 그냥 device="tpu"로 만든 평범한 PyTorch 텐서이고, 그 위에서 평범한 PyTorch 연산이 동작합니다.
TorchTPU 스택의 기술적 구조
Eager First: 정적 그래프 강제 없이도 충분한 성능
TorchTPU는 시작부터 Eager First 철학을 명시합니다. 즉, 사용자에게 정적 그래프 컴파일을 강제하지 않고, PyTorch 본연의 즉시 실행(eager) 경험을 우선적으로 제공한다는 것입니다. 이를 위해 TorchTPU는 세 가지 eager 모드를 마련했습니다.
Debug Eager: 한 번에 한 연산만 디스패치하고, 매 연산 후 CPU와 동기화합니다. 본질적으로 느리지만, 형상 불일치(shape mismatch), NaN 발생, OOM(out-of-memory) 같은 학습 도중의 미묘한 버그를 추적할 때 매우 유용합니다.
Strict Eager: 단일 연산 디스패치는 유지하되, 비동기로 실행합니다. CPU와 TPU가 동시에 일하다가 사용자 스크립트가 명시적으로 동기화 지점에 도달했을 때만 멈추기 때문에, PyTorch의 기본 eager 경험과 동일한 흐름을 제공합니다.
Fused Eager: TorchTPU의 진짜 차별화 지점입니다. 디스패치되는 연산 스트림을 자동으로 reflection하여 여러 연산을 더 큰, 연산 밀도가 높은 청크로 즉석에서 fusion한 뒤 TPU에 넘깁니다. TensorCore 활용도를 극대화하고 메모리 대역폭 오버헤드를 최소화함으로써, Strict Eager 대비 50%~100%+의 성능 향상을 사용자가 별도 설정 없이 얻을 수 있다고 발표는 밝히고 있습니다.
세 모드 모두 공유 컴파일 캐시(Compilation Cache) 로 뒷받침됩니다. 이 캐시는 단일 호스트에서 동작할 수도 있고, 멀티 호스트에 걸쳐 영구 저장되도록 설정할 수도 있습니다. 같은 워크로드를 반복할수록 컴파일 비용이 줄어들어 실제 학습/추론에 더 많은 시간을 쓸 수 있게 됩니다.
정적 컴파일: Dynamo, XLA, 그리고 StableHLO
피크 성능을 원하는 사용자를 위해 TorchTPU는 torch.compile 인터페이스를 통해 풀-그래프 컴파일도 지원합니다. 이 경로는 다음과 같이 구성됩니다.
-
Torch Dynamo로 사용자 코드에서 FX 그래프를 캡처
-
Torch Inductor 대신, 백엔드 컴파일러로 XLA 를 사용
-
PyTorch 연산자를 XLA의 IR인 StableHLO 로 직접 매핑
-
XLA가 TPU 토폴로지에 최적화된 바이너리를 생성
이 설계의 핵심은 "이미 검증된 XLA 경로를 그대로 재사용한다" 는 점입니다. XLA는 TPU 토폴로지에 대해 오랫동안 다듬어져 왔고, 특히 dense compute와 ICI 위에서 일어나는 collective communication 사이의 overlap을 자동으로 최적화하는 능력이 뛰어납니다. PyTorch 연산을 StableHLO로 직접 내려보냄으로써, eager 모드와 정적 컴파일 모드가 같은 lowering 경로를 공유하게 되어 성능과 안정성을 동시에 확보할 수 있게 되었습니다.
import torch
import torch_tpu # 가상의 import 예시
device = torch.device("tpu")
model = MyModel().to(device)
# eager: Strict/Fused 모드 자동 선택
out = model(x.to(device))
# 정적 컴파일이 필요한 경우
compiled_model = torch.compile(model)
out = compiled_model(x.to(device))
커스텀 커널: Pallas와 JAX, 그리고 Helion
성능을 마지막 한 방울까지 짜내야 하는 워크로드에서는 결국 손으로 작성한 커스텀 커널이 필요합니다. TorchTPU는 JAX 생태계의 커스텀 커널 자산을 PyTorch에서도 그대로 활용할 수 있게 합니다. JAX 함수에 @torch_tpu.pallas.custom_jax_kernel 데코레이터를 붙이면, Pallas 또는 JAX로 작성된 저수준 커널이 TorchTPU의 lowering 경로에 직접 연결됩니다. 또한 PyTorch 진영의 신생 커널 DSL인 Helion 지원도 진행 중이라고 밝혔습니다.
이 부분이 흥미로운 이유는, JAX/Pallas 진영에서 만들어지고 있는 Tokamax 같은 고성능 커널 라이브러리들을 PyTorch 사용자도 사실상 그대로 빌려 쓸 수 있는 길이 열린다는 데 있습니다.
분산 학습과 MPMD 챌린지
TorchTPU는 시작부터 PyTorch의 분산 API를 1급 시민으로 다룹니다. 발표 시점 기준으로 다음 세 가지 분산 학습 방식이 별도 코드 변경 없이 지원됩니다.
- DDP(Distributed Data Parallel): 가장 보편적인 데이터 병렬화
- FSDPv2(Fully Sharded Data Parallel v2): 파라미터/그래디언트/옵티마이저 상태를 샤딩하는 대규모 학습
- DTensor: 분산 텐서 추상화
또한 PyTorch 분산 API 위에 만들어진 다수의 서드파티 라이브러리들도 코드 수정 없이 TorchTPU에서 동작함을 확인했다고 밝혔습니다.
가장 큰 변화는 PyTorch/XLA의 한계였던 순수 SPMD 가정을 완화한 것입니다. 실제 PyTorch 학습 코드에서는 rank 0이 로깅이나 메트릭 집계를 위해 다른 rank들과 약간 다른 일을 하는 패턴이 매우 흔한데, 이는 SPMD에 강하게 최적화된 XLA 입장에서는 문제를 일으키기 쉽고, 사용자는 이를 회피하기 위해 코드를 어색하게 다듬어야 했습니다.
TorchTPU는 이러한 MPMD(Multiple Program Multiple Data) 패턴을 지원하도록 설계되었습니다. 필요한 경우 통신 프리미티브를 격리하여 정확성을 보장하고, 그 외의 영역에서는 XLA가 분산 TPU 배치에 대한 글로벌 뷰를 가지고 통신과 연산의 overlap을 최적화하도록 합니다. 즉, PyTorch 사용자에게 자연스러운 코드 스타일을 허용하면서도, XLA의 SPMD 최적화 이점을 가능한 한 유지한다는 균형 설계입니다.
TPU 하드웨어 인지(Hardware Awareness)
이식성을 강조하더라도 하드웨어 특성을 완전히 가릴 수는 없습니다. 앞서 TPU 소개에서 짚은 것처럼, 어텐션 헤드 차원을 64로 둔 모델은 TPU에서 128 또는 256으로 조정해 줘야 MXU의 dense tensor core를 충분히 활용할 수 있습니다. TorchTPU는 이를 강제하기보다, 다음과 같은 단계적 워크플로우를 제시합니다.
- 먼저 기존 PyTorch 모델을 TorchTPU 위에서 정확하게 동작시킨다
- 이후 공개될 deep-dive 가이드를 따라 suboptimal한 아키텍처를 식별하고 리팩터링한다
- 필요한 경우 Pallas 커널을 주입하여 성능을 끌어올린다
심화 학습: TPU 하드웨어와 컴파일러 스택
2026 로드맵: TorchTPU가 앞으로 채워나갈 빈칸
TorchTPU는 학습과 서빙 모두에서 견고한 기반을 갖췄지만, PyTorch 생태계의 마찰 없는 백엔드가 되기 위해 채워야 할 부분도 분명합니다. 발표에서는 2026년에 다음 항목들을 우선순위로 두고 있다고 밝혔습니다.
- 동적 시퀀스 길이/배치 사이즈에 의한 재컴파일 최소화: XLA의 bounded dynamism을 고도화하여, 형상 변화에 대해 컴파일 오버헤드 없이 처리. 다음 토큰을 반복적으로 예측하는 LLM 추론 같은 워크로드에 특히 중요한 개선
- 표준 연산을 위한 사전 컴파일된 TPU 커널 라이브러리 확충: 첫 실행 iteration의 지연을 크게 낮추는 데 기여
- 공개 GitHub 저장소 런칭: 광범위한 문서와 재현 가능한 아키텍처 튜토리얼 포함
- PyTorch Helion DSL과의 통합으로 커스텀 커널 능력 확장
torch.compile을 통한 dynamic shape의 1급 지원- Native multi-queue 지원으로 메모리/연산 스트림을 분리한 비동기 코드베이스의 마이그레이션 용이화
- vLLM, TorchTitan 등 생태계 핵심 라이브러리와의 깊은 통합, 그리고 풀 Pod 사이즈 인프라까지의 검증된 선형 스케일링
시사점: PyTorch와 JAX, 그리고 TPU의 새로운 균형점
TorchTPU 발표는 단순히 새로운 백엔드 하나가 추가됐다는 사실을 넘어, 몇 가지 방향성을 시사합니다.
첫째, PyTorch 사용자가 GPU 외 가속기로 이동할 때 마찰이 점점 줄어들고 있다는 점입니다. PyTorch 2.x의 PrivateUse1 인터페이스, Dynamo + StableHLO 조합은 PyTorch가 특정 하드웨어 벤더에 종속되지 않고 다양한 백엔드를 지원하기 위한 구조적 토대를 마련했고, TorchTPU는 그 토대를 가장 야심차게 활용한 사례 중 하나입니다.
둘째, JAX와 PyTorch가 점점 더 같은 컴파일러 스택을 공유하는 방향으로 수렴하고 있다는 점입니다. XLA, StableHLO, Pallas, OpenXLA는 원래 JAX/TensorFlow 진영의 자산이었지만, 이제 PyTorch 사용자도 이 자산들을 자연스럽게 누리게 됩니다. 이는 PyTorch는 죽었다, JAX 만세 같은 자극적인 담론과는 별개로, 두 프레임워크 사용자가 모두 이득을 보는 방향의 변화입니다.
셋째, Gemini와 Veo를 떠받쳐 온 TPU 인프라가 더 많은 외부 개발자에게 열린다는 점입니다. 그동안 TPU의 잠재력은 대부분 Google 내부 팀과 일부 JAX 사용자만이 충분히 누렸지만, TorchTPU가 안정화되면 PyTorch 기반의 일반 연구자/엔지니어도 학습 코드를 거의 그대로 옮겨 Cloud TPU에서 실험할 수 있게 됩니다. Ironwood(TPU7x) 세대를 비롯한 차세대 TPU의 가용성을 고려하면, GPU 일변도였던 학습/추론 인프라 선택지가 한층 다양해질 것으로 보입니다.
물론 발표 시점 기준으로 TorchTPU의 공개 GitHub 저장소는 아직 준비 중이며, 실제 사용자가 손쉽게 접근할 수 있는 환경은 2026년 로드맵을 따라 점진적으로 갖춰질 예정입니다. 그럼에도 "기존 PyTorch 스크립트를 한 줄도 안 바꾸고 TPU에서 돌린다" 는 약속과, 그것을 뒷받침하는 Eager First/Fused Eager/StableHLO 라우팅/MPMD 지원이라는 구체적 설계는 충분히 기대할 만한 그림입니다.
 TorchTPU 소개 블로그
TorchTPU 소개 블로그
 Cloud TPU 제품 페이지
Cloud TPU 제품 페이지
TorchTPU 더 알아보기
Cloud TPU Documentation - Introduction to Cloud TPU
Cloud TPU Documentation - TPU Architecture
Ironwood: The age of inference - Google Cloud Blog
OpenXLA - StableHLO
PyTorch/XLA GitHub Repository
Pallas TPU Documentation
Helion GitHub Repository
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()