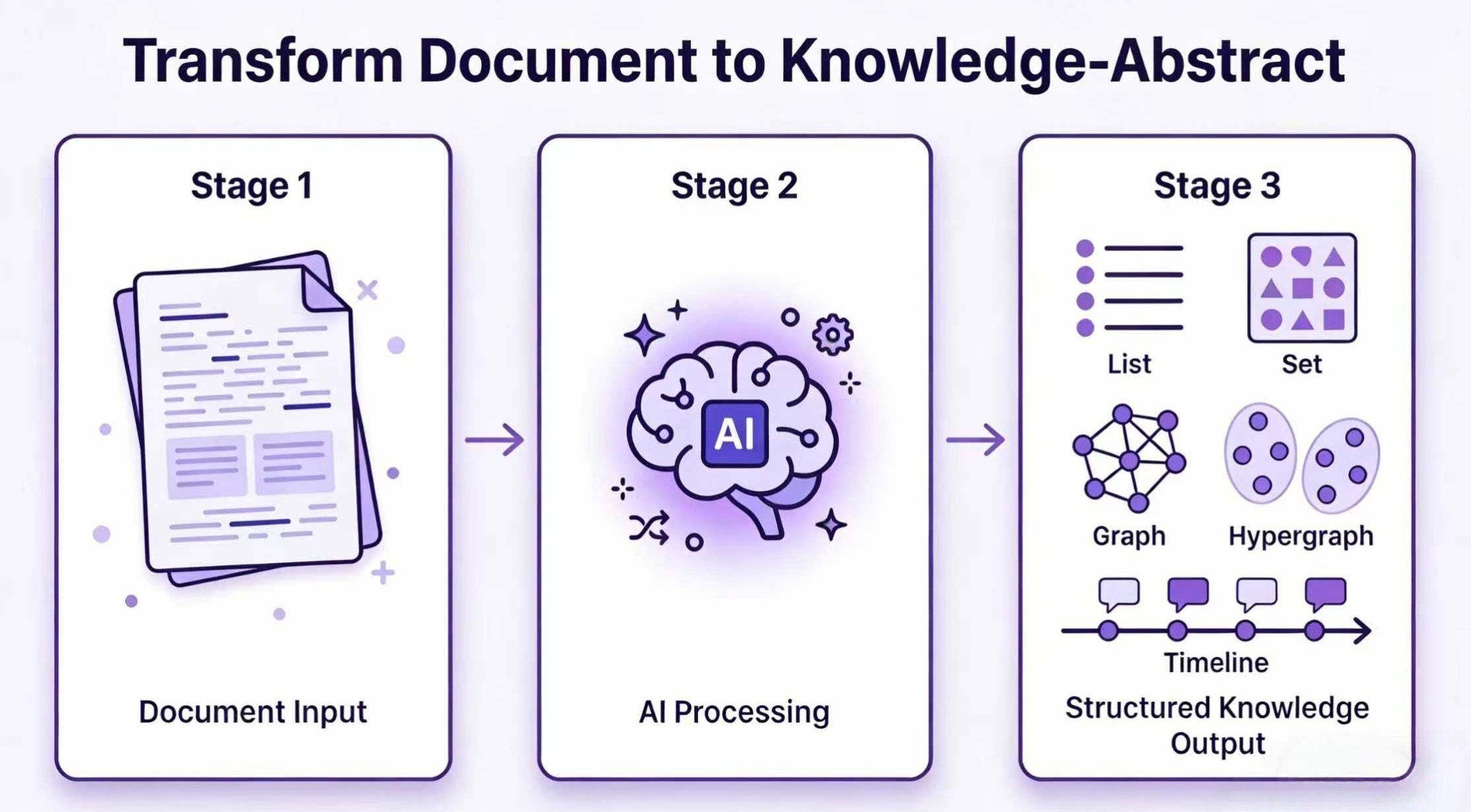
Hyper-Extract 소개
문서를 읽고 그 안의 개념과 관계를 사람이 일일이 정리하는 일은 오래 걸리고 일관성을 유지하기도 어렵습니다. LLM은 이 작업을 거들 수 있지만, 자유 형식 출력은 다시 정형화하기 까다롭고 매번 결과가 달라지기 쉽습니다. Hyper-Extract는 이 간극을 메우려는 도구로, 고도로 비정형적인 텍스트를 지속 가능하고 예측 가능하며 강타입(strongly-typed)인 지식 추상(Knowledge Abstract) 으로 바꿉니다.
Hyper-Extract는 LLM 기반의 지식 추출·진화 프레임워크입니다. 추출 결과를 단순한 컬렉션(리스트·세트)이나 Pydantic 모델 같은 레코드 형태부터, 지식 그래프(Knowledge Graph), 하이퍼그래프(Hypergraph), 나아가 시공간 그래프(Spatio-Temporal Graph)까지 폭넓은 형식으로 뽑아낼 수 있습니다. 저자는 이 도구의 지향을 "Stop reading. Start understanding." 라는 한 줄로 표현합니다.
Hyper-Extract는 he 라는 명령줄 도구를 중심으로 동작하며, 문서를 한 번의 명령으로 구조화된 지식 베이스로 바꾸고 검색·시각화·내보내기까지 이어 줍니다. 새 문서를 언제든 추가해 기존 지식 베이스를 점진적으로 확장하는 증분 진화(incremental evolution)를 지원하고, 추출한 그래프를 위키링크([[wikilinks]])로 연결된 Obsidian 볼트로 내보낼 수도 있습니다. 아래 그림은 Hyper-Extract의 전체 아키텍처를 한눈에 보여줍니다.
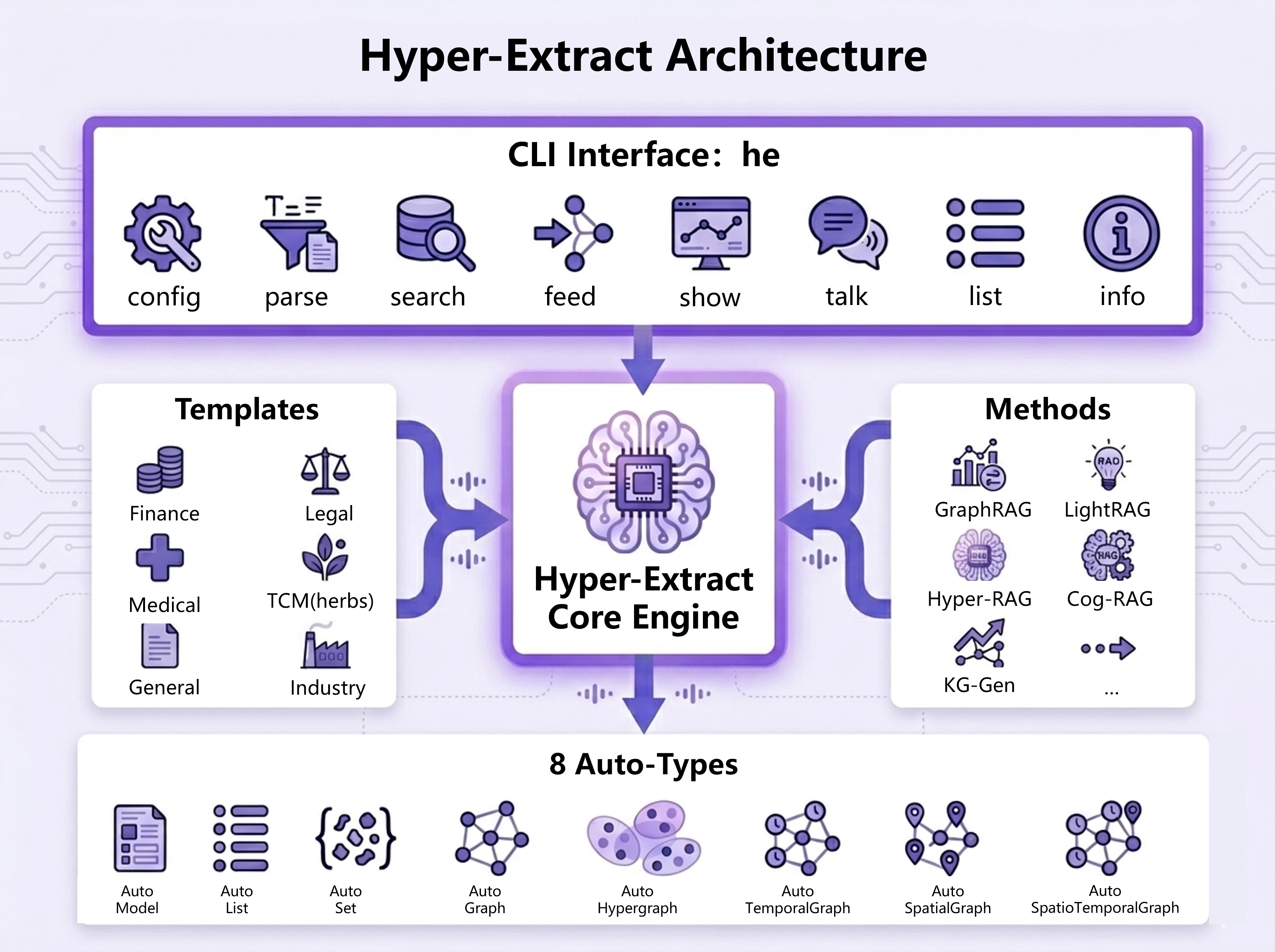
Hyper-Extract의 아키텍처
Hyper-Extract는 세 개의 계층으로 구성됩니다.
- Auto-Types: 8가지 강타입 데이터 구조입니다. 레코드 계열의 Model, List, Set과 그래프 계열의 Graph, Hypergraph, Temporal Graph, Spatial Graph, Spatio-Temporal Graph로 나뉩니다.
- Methods: 추출 알고리즘 계층입니다. KG-Gen, GraphRAG, LightRAG, Hyper-RAG, Cog-RAG 등 10가지 이상의 엔진을 골라 쓸 수 있습니다.
- Templates: 6개 도메인(금융, 법률, 의료, 한의학(TCM), 산업, 일반)에 걸친 80개 이상의 프리셋입니다. YAML로 정의되어 있어 코드를 쓰지 않고도 추출을 설정할 수 있습니다.
이 세 계층은 명령줄 인터페이스(he)를 통해 한데 묶입니다. Hyper-Extract는 LLM의 구조화 출력 능력(json_schema 또는 함수 호출)에 의존해, 모델이 자유 텍스트가 아니라 정해진 스키마에 맞는 결과를 내도록 강제합니다.
Hyper-Extract가 지원하는 지식 구조
Hyper-Extract의 핵심은 데이터의 성격에 맞는 구조를 직접 고를 수 있다는 점입니다. 단순한 레코드부터 복잡한 시공간 그래프까지 8가지 구조가 준비되어 있습니다.
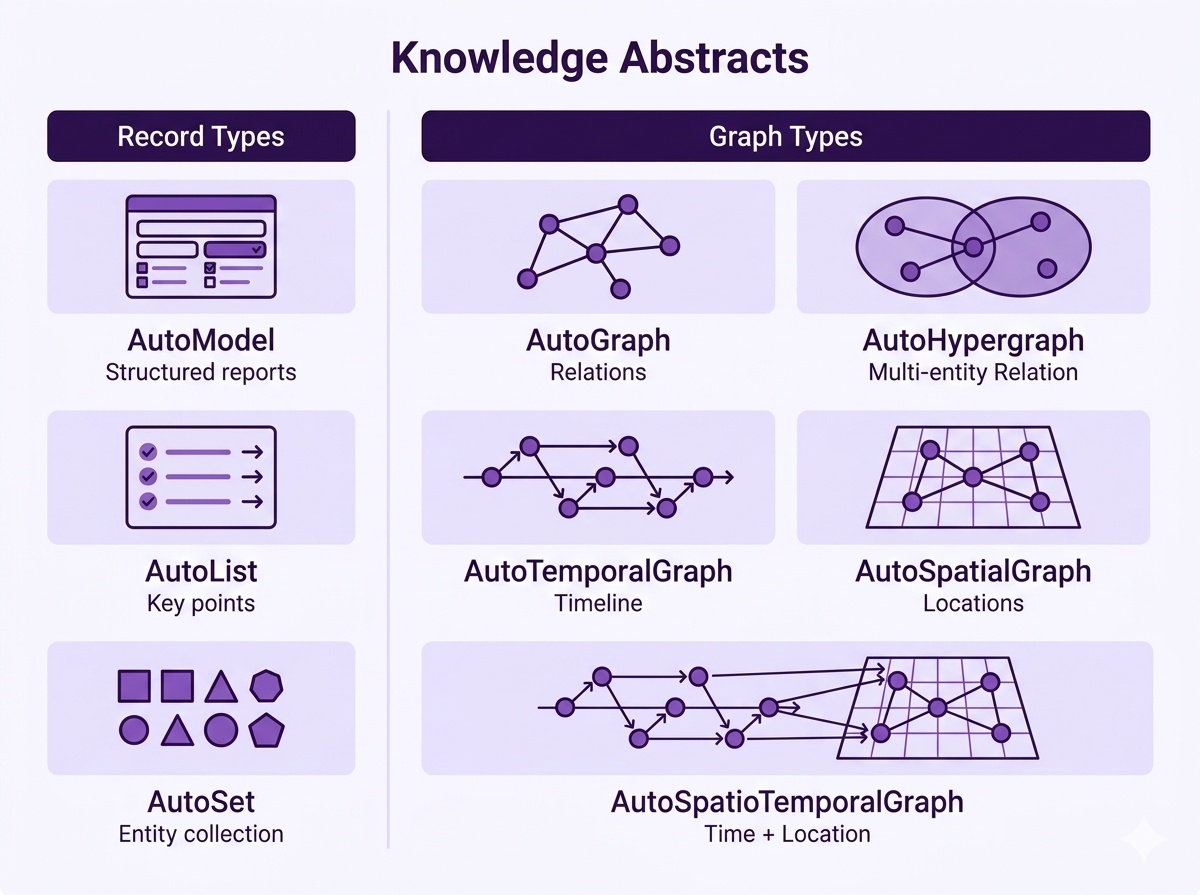
레코드 계열에는 정형 보고서를 위한 AutoModel, 핵심 포인트를 정리하는 AutoList, 엔티티 모음을 담는 AutoSet이 있습니다. 그래프 계열에는 관계를 담는 AutoGraph, 다중 엔티티 관계를 하나의 엣지로 묶는 AutoHypergraph, 시간 흐름을 담는 AutoTemporalGraph, 위치를 담는 AutoSpatialGraph, 그리고 시간과 위치를 함께 담는 AutoSpatioTemporalGraph가 있습니다. 일반적인 그래프가 두 노드 사이의 관계만 표현하는 데 비해, 하이퍼그래프는 여러 엔티티가 한꺼번에 맺는 관계를 하나의 단위로 다룰 수 있습니다.
기존 도구와 Hyper-Extract의 비교
저자가 README에 정리한 비교 표에 따르면, Hyper-Extract는 지식 그래프 추출 도구들이 공통으로 다루는 영역을 넘어 공간 그래프와 하이퍼그래프, 도메인 템플릿까지 지원한다는 점을 차별점으로 내세웁니다.
| 기능 | GraphRAG | LightRAG | KG-Gen | ATOM | Hyper-Extract |
|---|---|---|---|---|---|
| 지식 그래프 | |||||
| 시간 그래프 | |||||
| 공간 그래프 | |||||
| 하이퍼그래프 | |||||
| 도메인 템플릿 | |||||
| 대화형 CLI | |||||
| 다국어 |
Hyper-Extract의 모델 지원과 시각화
Hyper-Extract는 구조화 출력을 지원하는 다양한 플랫폼과 모델에서 동작합니다. OpenAI(gpt-4o, gpt-4o-mini, gpt-5), Anthropic(claude-opus-4-8, claude-sonnet-4-6, claude-haiku-4-5), 알리바바 클라우드 바이롄(qwen-plus, qwen-turbo, deepseek-r1), 그리고 vLLM으로 띄운 로컬 모델(Qwen3.5-9B)이 검증된 조합으로 README에 정리되어 있습니다. 임베딩(의미 검색용)은 OpenAI 호환 엔드포인트라면 text-embedding-3-small, bge-m3 등 무엇이든 쓸 수 있습니다. Anthropic은 임베딩 API가 없으므로, Claude를 LLM으로 쓸 때는 OpenAI 호환 임베더와 짝지어 사용합니다.
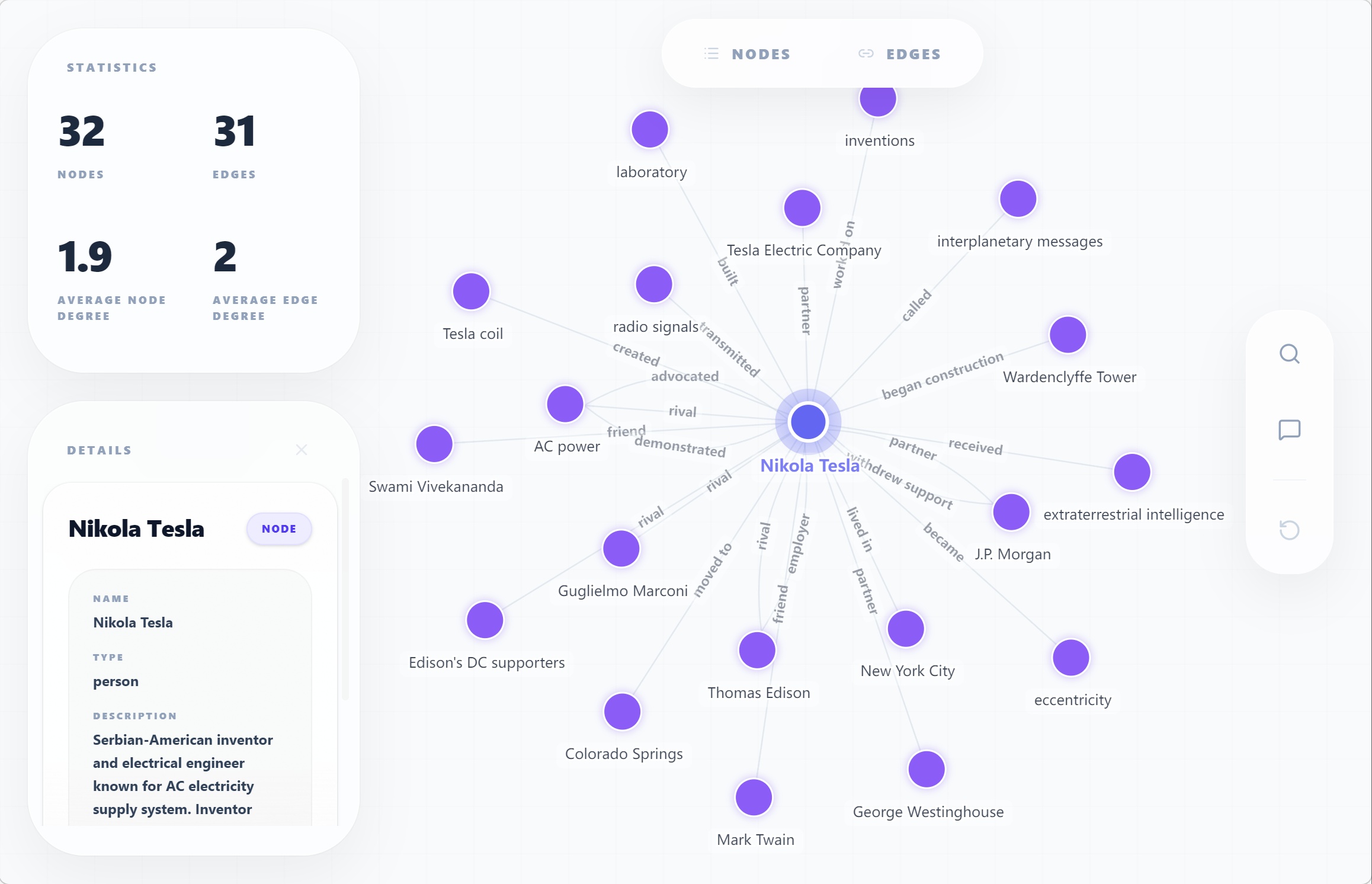
추출한 지식 베이스는 he show 명령으로 인터랙티브하게 시각화할 수 있습니다. 아래는 AutoGraph 결과를 시각화한 예시입니다.
MCP-capable 어시스턴트(Claude Desktop, IDE 에이전트)에는 Model Context Protocol 기반의 MCP 서버(he-mcp)로 지식 추상을 노출할 수 있습니다. 읽기와 내보내기 전용이며, list_templates, info, search, ask(RAG), export_obsidian 도구를 제공합니다.
Hyper-Extract 설치 및 사용법
Hyper-Extract는 Python 3.11 이상에서 동작하며, hyperextract 라는 이름으로 PyPI에 배포되어 있습니다. 명령줄 도구로 설치하는 30초 빠른 시작은 다음과 같습니다.
# 설치
uv tool install hyperextract
# API 키 설정
he config init -k YOUR_OPENAI_API_KEY
# 문서에서 지식 추출
he parse examples/en/tesla.md -t general/biography_graph -o ./output/ -l en
# 질의
he search ./output/ "What are Tesla's major achievements?"
# 시각화
he show ./output/
# Obsidian 볼트로 내보내기
he export obsidian ./output/ -o ./vault/
Python API로도 같은 작업을 할 수 있습니다.
from hyperextract import Template
ka = Template.create("general/biography_graph")
with open("examples/en/tesla.md") as f:
result = ka.parse(f.read())
result.show()
데이터를 외부로 내보내지 않아야 하는 경우에는 vLLM으로 로컬 모델(Qwen3.5-9B + bge-m3)을 띄워 온프레미스로 운영할 수 있습니다. 80개 이상의 프리셋 템플릿은 저장소의 presets/ 디렉토리에서 둘러볼 수 있고, 템플릿 설계 가이드를 따라 직접 만들 수도 있습니다.
Hyper-Extract의 라이선스
Hyper-Extract는 Apache-2.0 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용할 수 있습니다.
 Hyper-Extract 공식 문서
Hyper-Extract 공식 문서
 Hyper-Extract 프로젝트 GitHub 저장소
Hyper-Extract 프로젝트 GitHub 저장소
더 읽어보기
-
LightRAG: 지식 그래프 기반의 이중 검색 구조로 GraphRAG보다 빠른 RAG 프레임워크 (feat. EMNLP 2025)
-
Fast GraphRAG, 더 빠르고 해석 가능한 GraphRAG 구현을 위한 프레임워크 (feat. Circlemind)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()