
SmithDB 소개: 에이전트 관측성을 위한 새로운 데이터 계층
LangChain이 자사의 관측성(Observability) 플랫폼인 LangSmith의 핵심 워크로드를 떠받치는 새로운 분산 데이터베이스 SmithDB를 공개했습니다. SmithDB는 LLM 기반 에이전트의 트레이스(trace) 데이터를 저장하고 질의하기 위해 Rust로 처음부터 다시 설계된 데이터 계층으로, 이미 LangSmith US Cloud의 인제스션(ingestion)과 UI 질의 트래픽 100%를 처리하고 있습니다.

LangSmith가 2023년에 처음 출시되었을 때만 해도 AI 애플리케이션은 RAG 파이프라인이나 단순한 프롬프트 체인, 초기 단계의 에이전트가 주류였습니다. 그러나 그동안 에이전트는 훨씬 더 보편화되고 실행 시간도 길어졌으며, LLM의 컨텍스트 윈도우 크기가 비약적으로 커지고 이미지나 오디오 같은 멀티모달 콘텐츠를 포함하는 워크로드도 늘어났습니다. 그 결과 현대의 에이전트가 만들어내는 트레이스 데이터는 건수(volume) 와 개별 페이로드 크기(size) 양쪽에서 모두 폭발적으로 증가했고, 하나의 트레이스에 수백 개의 깊이 중첩된 스팬(span)이 포함되는 경우가 흔해졌습니다.
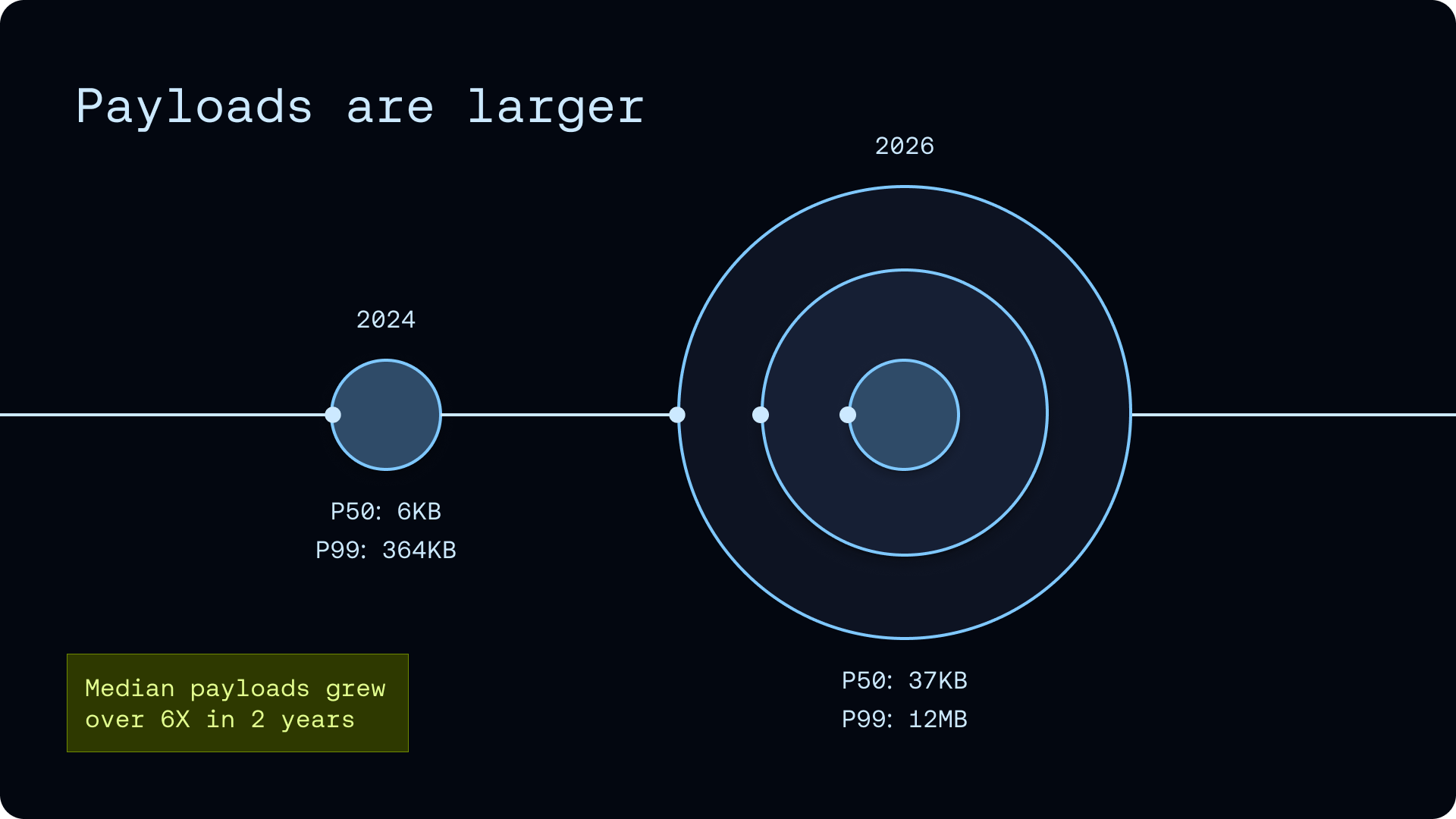
기존의 관측성 저장소는 짧고 단발성에 가까운 요청/응답을 가정하여 설계되었기 때문에, 분 단위 혹은 시간 단위로 열린 채 남아 있다가 부분적으로 도착하는 에이전트의 긴 스팬을 효율적으로 처리하기 어렵습니다. 또한 메타데이터 슬라이싱, 전체 텍스트 검색, JSON 키 경로 필터링, 트리 인식 질의, 스레드 재구성, 집계 등 다양한 질의 패턴을 낮은 지연으로 동시에 지원해야 합니다. SmithDB는 바로 이러한 에이전트 네이티브(agent-native) 질의 패턴과 자가 호스팅(self-hosting) 및 멀티 클라우드 요구사항을 한꺼번에 만족시키기 위해 새롭게 설계된 시스템입니다.
에이전트 트레이스가 만든 새로운 데이터 문제
에이전트 관측성에서 트레이스는 단순한 로그가 아니라 에이전트의 핵심 행동 기록(core behavioral record) 입니다. 코드가 일반 소프트웨어의 동작을 문서화한다면, 트레이스는 AI 에이전트가 실제로 어떻게 사고하고 행동했는지를 보여주는 1차 자료에 해당합니다. LangChain은 이전 글 In Software, the Code Documents the App. In AI, the Traces Do.에서 이 관점을 자세히 풀어낸 바 있습니다.
이러한 트레이스 데이터를 분석하기 위해 필요한 질의 패턴도 점점 복잡해지고 있습니다. SmithDB가 지원해야 하는 주요 워크로드는 다음과 같습니다:
- 랜덤 액세스(Random access): 특정 실행(run)이나 트레이스를 즉시 불러오기
- 인터랙티브 필터링(Interactive filtering): 메타데이터, 피드백, 지연시간, 오류, 태그, 시간 등 다양한 축으로 대용량 트레이스 데이터셋을 슬라이싱
- 전체 텍스트 검색(Full-text search): 에이전트의 입력과 출력 안에서 특정 문구나 패턴 검색
- JSON 필터링(JSON filtering): 사용자가 자유롭게 정의한 메타데이터나 구조화된 도구 출력에 대한 질의
- 트리 인식 질의(Tree-aware queries): 루트 실행, 자식 실행, 트레이스 내 임의 노드 기준으로 필터링
- 스레드 재구성(Thread reconstruction): 여러 에이전트 트레이스에 걸쳐 진행된 장시간 대화를 즉시 재구성
- 집계(Aggregations): 다양한 필터 조건에서 비용, 지연시간, 토큰 사용량, 평가자 점수 등을 계산
이 모든 요구사항을 대용량 에이전트 트레이스 위에서, 낮은 지연으로, 자가 호스팅과 멀티 클라우드를 지원하면서 동시에 만족시키려면 근본적으로 새로운 아키텍처가 필요했고, 그것이 SmithDB의 출발점이었습니다.
SmithDB의 전체 아키텍처
SmithDB는 Rust로 구현되었으며, Apache DataFusion 질의 엔진과 Vortex 파일 툴킷을 기반으로 하되 LangSmith 특유의 워크로드를 위해 광범위한 커스터마이징을 더했습니다. Apache DataFusion은 Apache Arrow 위에 구축된 임베디드 가능한 질의 엔진으로, 컬럼형(columnar) 실행과 SQL/DataFrame API를 제공합니다. Vortex는 객체 스토리지에 최적화된 차세대 컬럼형 파일 포맷 프로젝트로, Parquet보다 빠른 랜덤 액세스를 목표로 합니다.
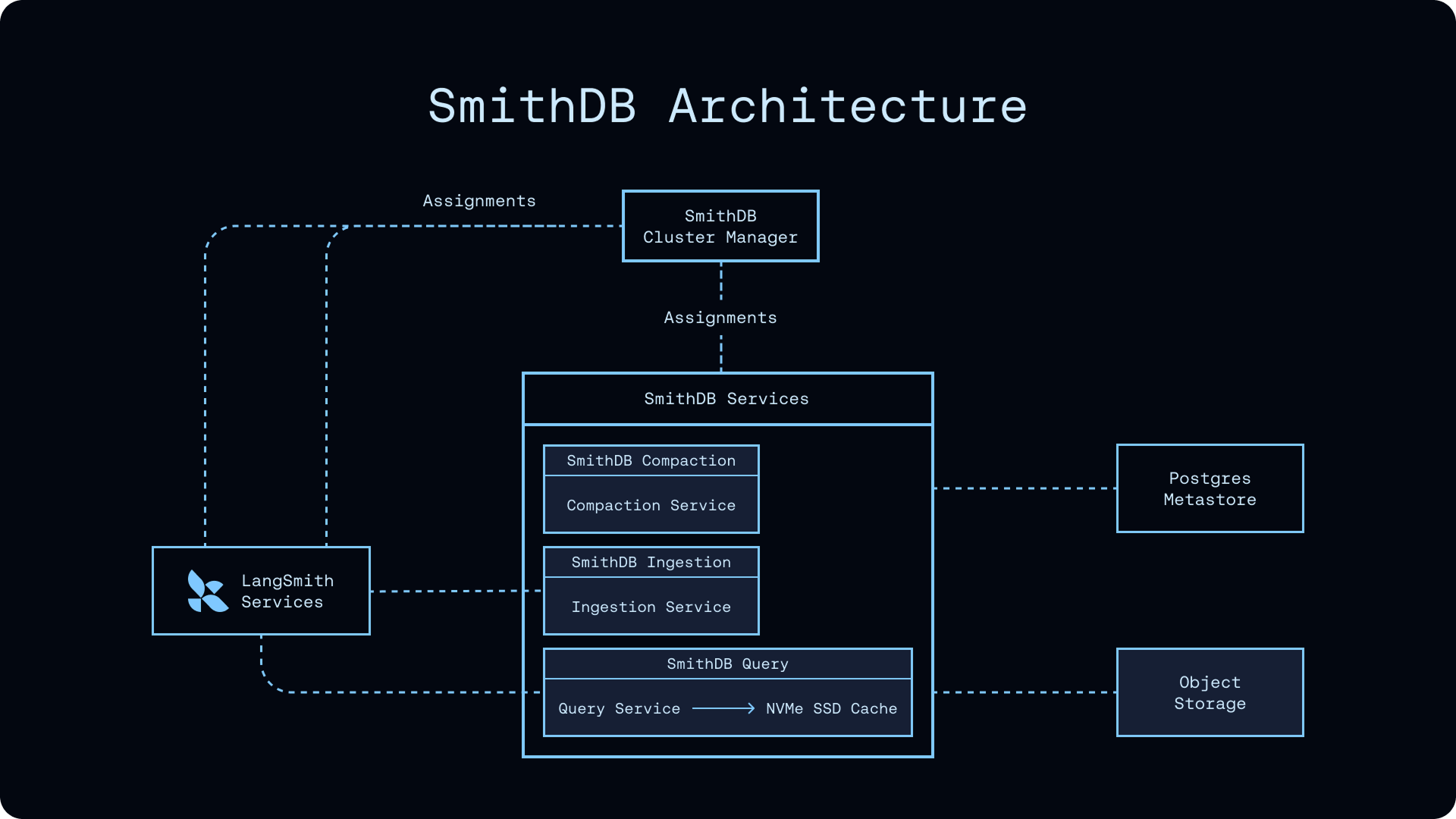
높은 수준에서 SmithDB는 세 가지 구성 요소로 이루어져 있습니다:
-
객체 스토리지(Object storage): Amazon S3, Google Cloud Storage, Azure Blob Storage 같은 환경에 트레이스 데이터를 내구성 있게 저장
-
소규모 PostgreSQL 메타스토어: 세그먼트 메타데이터를 관리
-
상태 없는(stateless) 인제스션, 질의, 컴팩션 서비스: 컴퓨트 노드를 추가하는 방식으로 수평 확장
상태 없는 서비스 계층과 내구성 있는 객체 스토리지를 분리하는 이 아키텍처는 Snowflake, Databricks, ClickHouse Cloud 같은 현대적인 데이터 플랫폼이 공유하는 설계 철학과 맞닿아 있습니다. 다만 SmithDB는 일반적인 OLAP 분석이 아닌, 에이전트 트레이스라는 매우 특수한 워크로드에 맞춰 LSM 트리 기반 인제스션과 트리 인식 질의 같은 도메인 특화 기능을 제공한다는 점이 차별점입니다.
성능: 최대 15배 빠른 LangSmith
관측성 도구의 성능은 단순한 부가 기능이 아닙니다. 사람이든 에이전트든, 느린 관측성 도구는 에이전트 개발 루프 자체의 병목이 되어 디버깅과 개선 속도를 끌어내립니다. SmithDB는 핵심 LangSmith 경험을 이전보다 최대 15배 빠르게 만들었으며, 주요 워크로드별 지연시간은 다음과 같습니다.
| 워크로드 | SmithDB 지연시간 |
|---|---|
| 트레이스 트리 로드 (Trace tree load) | P50 92ms / P99 595ms |
| 단일 실행 로드 (Single run load) | P50 71ms / P99 358ms |
| 실행 필터링 (Runs filtering) | P50 82ms / P99 434ms |
| 트레이스 인제스션 (Trace ingestion) | P50 630ms / P99 1.47s |
| 전체 텍스트 검색 (Full-text search) | P50 400ms / P99 870ms |
| 스레드 필터링 (Threads filtering) | P50 131ms / P95 268ms |
대용량 트레이스를 가진 프로젝트일수록 차이가 더 두드러지며, 트레이스 탐색이 병목이던 환경에서 즉각적인 체감 개선이 보고되었습니다.
포터블한 배포 모델
SmithDB는 객체 스토리지를 기반으로 동작하므로 관리해야 할 로컬 디스크가 없습니다. 질의와 인제스션 서비스는 상태 없는(stateless) 형태이며, 시스템은 컴퓨트를 추가하는 방식으로 확장되고 내구성 있는 데이터는 객체 스토리지에 머무릅니다.
이러한 구조는 로컬 디스크와 복잡한 샤딩(sharding)을 요구하는 전통적인 분산 데이터베이스 클러스터에 비해, 자가 호스팅과 멀티 클라우드 환경에서 훨씬 단순한 운영을 가능하게 합니다. 이는 데이터를 자사 인프라에서 직접 운영해야 하는 규제 산업이나 보안 민감 조직에서 LangSmith를 도입할 때 중요한 차별점이 됩니다.
프로덕션 적용 현황
SmithDB는 발표 시점에 이미 다음 트래픽을 처리하고 있습니다:
- US Cloud 인제스션의 100% 가 SmithDB로 들어가고 있습니다.
- 트레이싱 UI 질의 트래픽의 100% (스레드 포함)가 SmithDB에서 처리됩니다.
- 모든 주요 필터 (메타데이터, 피드백, 텍스트 검색, 트리 필터, 트레이스 필터)가 SmithDB로 백엔드됩니다.
- 실행 규칙(run rules), 대량 내보내기(bulk export), 실험(experiments) 같은 제품 통합도 마무리 단계입니다.
앞으로는 관련 제품 표면 전반이 SmithDB 위에서 동작하도록 이전될 예정이며, LangSmith의 자가 호스팅(self-hosted) 배포 에서도 SmithDB를 사용할 수 있게 할 계획입니다.
초기 사용자 피드백
LangChain은 지난 몇 달간 Clay, Vanta, Unify, Cogent Security 같은 고객사의 워크로드를 SmithDB로 점진적으로 이전해 왔습니다. 이들이 공통적으로 보고한 것은 대규모 트레이스 탐색의 체감 속도가 즉각적으로 개선되었다는 점이었습니다.
"우리는 매일 수억 건의 에이전트 관측성 이벤트를 LangSmith에 기록합니다. SmithDB는 우리 팀이 그 데이터를 프로덕션 환경에서 에이전트를 개선하는 데 필요한 속도로 검색, 디버깅, 분석할 수 있게 만들어 주었습니다. 특히 트레이스 탐색이 병목이던 대규모 프로젝트에서 성능 개선이 즉각적이고 인상적입니다."
— Jeff Barg, Head of AI at Clay
"SmithDB로 옮긴 이후 성능 개선이 즉시 느껴졌습니다. UX가 훨씬 더 빠릿하게 반응하고, 데이터를 파고드는 작업이 어느 때보다 빠르고 직관적으로 이루어집니다."
— Andy Almonte, Senior Engineering Manager, AI at Vanta
"우리는 큰 도구 호출이 포함된 트레이스를 많이 가지고 있는데, SmithDB로 이전한 뒤 여러 프로젝트에 걸친 트레이스를 질의하고 읽어 들이는 일이 훨씬 수월해졌습니다. 덕분에 엣지 케이스를 짚어내고 평가 데이터셋을 구축하며 트레이스 위에서 반복 개선하는 속도가 이전보다 훨씬 빨라졌습니다."
— Kunal Rai, Software Engineer, AI at Unify
"Cogent에서는 백그라운드 에이전트가 한 번에 엄청난 양의 트레이스를 만들어 냅니다. 그런 시스템에는 실시간 관측성이 필요한데, SmithDB는 다른 공급자에서 분 단위로 보이던 트레이스를 초 단위로 볼 수 있게 해 주었습니다."
— Larsen Weigle, Member of Technical Staff at Cogent Security
핵심 엔지니어링 과제
높은 수준에서 SmithDB는 객체 스토리지 기반의 Log-Structured Merge Tree (LSM) 로 구축되었습니다. LSM은 쓰기를 메모리에 버퍼링하다가 불변(immutable)의 정렬된 배치로 영구 스토리지에 플러시하고, 주기적으로 그 세그먼트들을 컴팩션하는 구조입니다. 질의 시점에는 여러 세그먼트가 함께 읽혀 정렬된 단일 스트림으로 병합됩니다. 이 아키텍처는 Apache Cassandra, ScyllaDB, LevelDB, RocksDB 같은 시스템에서 검증된 패턴이지만, SmithDB는 이를 객체 스토리지와 에이전트 트레이스 도메인에 맞춰 다시 설계했습니다.
SmithDB의 다섯 가지 주요 구성 요소는 다음과 같습니다:
- 인제스션 서비스(Ingestion service): 트레이스 쓰기를 받아 파티션과 시간 버킷별로 배치(batch)하여 불변 파일로 저장
- 메타스토어(Metastore): 세그먼트의 위치, 시간 범위, 행 수, 업데이트/삭제 벡터(update/delete vectors) 등의 메타데이터를 기록
- 질의 서비스(Query service): LangSmith의 실행 의미론과 객체 스토리지를 이해하는 커스텀 실행 계획(execution plan)을 갖춘 질의 인터페이스. SSD와 메모리 캐싱이 적극 활용됨
- 컴팩션 서비스(Compaction service): 쓰기 최적화 세그먼트를 질의 최적화 세그먼트로 다시 쓰면서, 삭제 적용, 업그레이드, TTL 만료, 인덱스 병합을 함께 수행
- 클러스터 매니저(Cluster manager): 살아 있는 서비스 노드에 키 범위를 할당. 단순한 부하 분산이 아니라, 반복되는 질의가 적절한 데이터를 캐시한 노드에 도달하도록 만드는 것이 목적
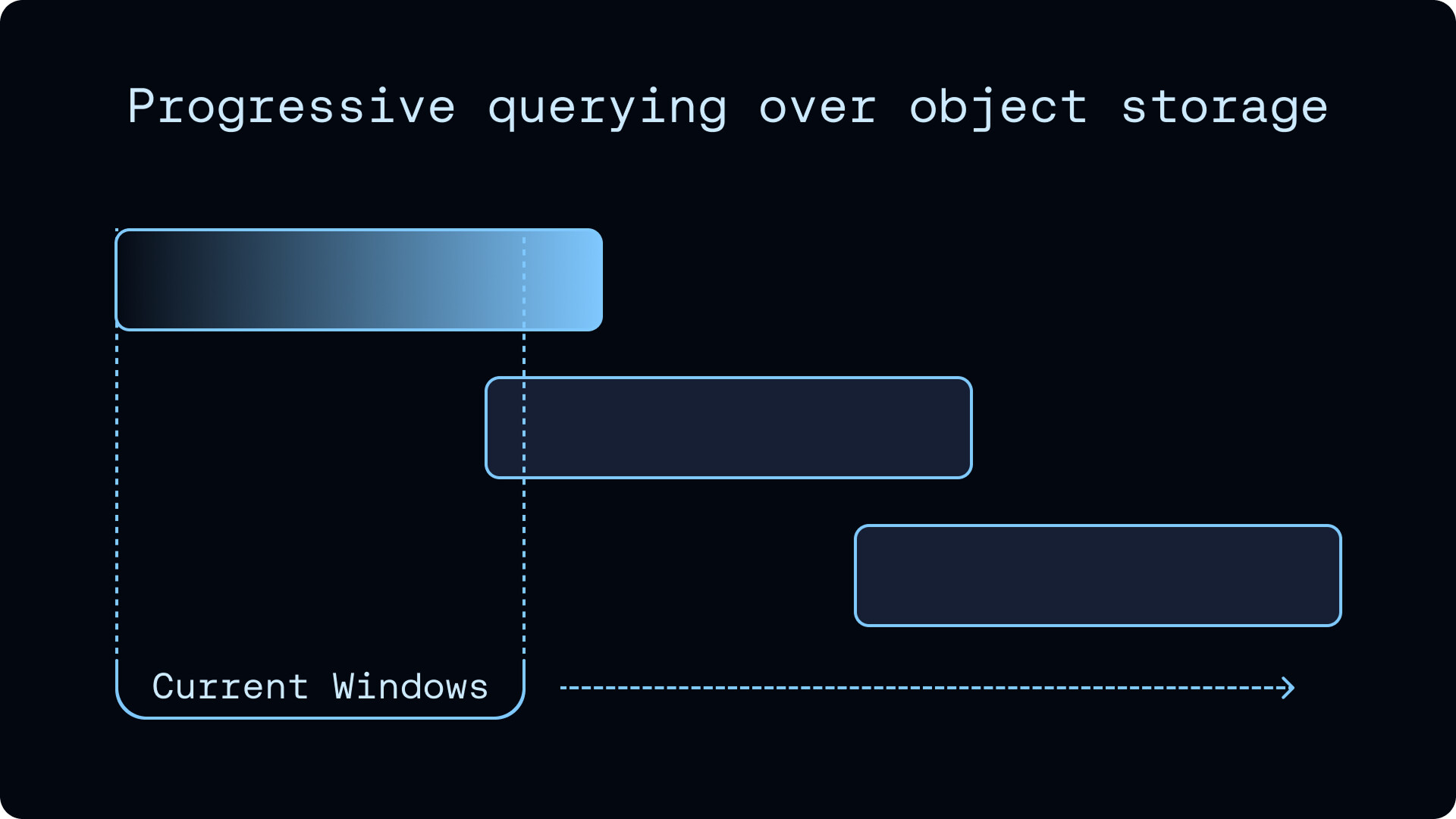
객체 스토리지 위에서의 점진적 질의(Progressive querying)
LangSmith의 많은 질의는 특정 테넌트(tenant)와 트레이싱 프로젝트의 가장 최신 실행 을 요청합니다. 단순한 객체 스토리지 계획이라면 후보가 되는 모든 파일을 찾아 열고, 정렬-병합으로 데이터를 중복 제거한 다음, 마지막에 LIMIT을 적용할 것입니다. 이 방식은 최신 데이터 한 조각을 보기 위해 사실상 전체 데이터를 스캔하게 됩니다.
SmithDB는 시간을 거꾸로 거슬러 올라가면서 가장 최신 후보 세그먼트들로 경계가 있는 시간 윈도우 를 구성합니다. "모든 것을 정렬한 뒤 자르기" 가 아니라 "가장 최신의 경계 있는 슬라이스를 읽어 스트리밍·병합·중복 제거하고, 정확성이 허락하는 순간 멈추기" 가 되어, "Top K" 스타일 질의에서 스캔하는 데이터양을 크게 줄입니다.
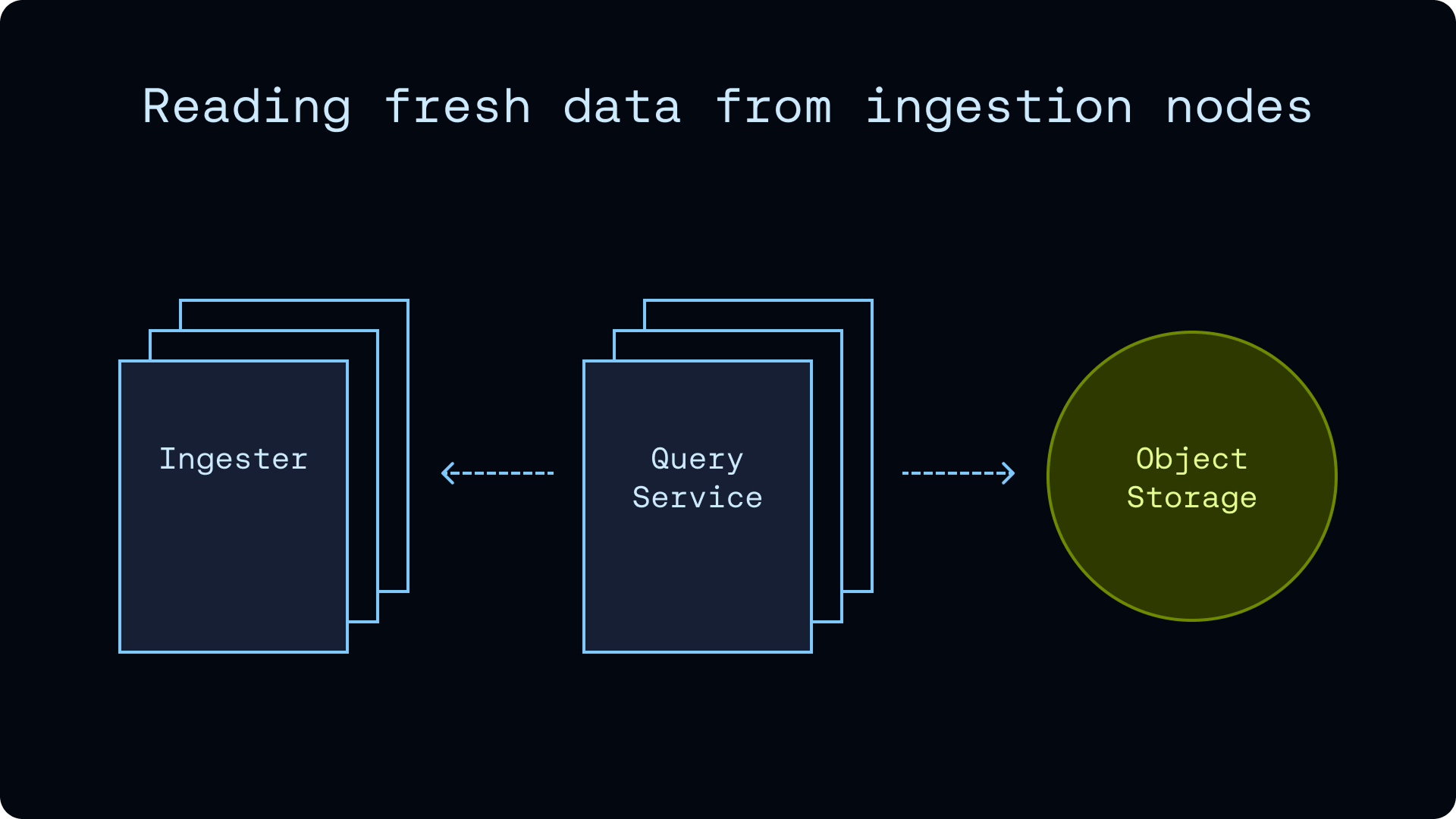
인제스션 노드에서 최신 데이터 읽기
객체 스토리지는 진실의 원천(durable source of truth)이지만, 가장 최신(Fresh)의 데이터는 여전히 해당 데이터를 방금 쓴 인제스션 노드에 남아 있을 가능성이 높습니다. 이 데이터를 굳이 객체 스토리지로 왕복해서 다시 읽어 오는 것은 비효율적입니다.
각 파일 세그먼트는 그것을 만든 노드의 서버 식별자(server identifier)를 함께 기록합니다. 작성자 노드가 아직 살아 있다면, 질의 플래너는 객체 스토리지 대신 해당 인제스션 노드의 로컬 SSD와 메모리 캐시에서 직접 그 파일들을 스캔하는 커스텀 계획을 사용할 수 있습니다. 덕분에 최신 데이터(leading-edge) 를 다루는 질의에서 객체 스토리지로부터 수십 개의 작은 파일을 끌어와야 하는 비용을 피할 수 있습니다.
한 번 실행(run)에 여러 이벤트가 들어오는 문제
에이전트 관측성은 장시간 실행되는 스팬(long-running spans) 을 중심으로 설계됩니다. 전통적인 요청/응답 애플리케이션에서는 스팬이 밀리초 단위로 시작하고 끝나지만, 에이전트 스팬은 훨씬 더 오래 열려 있을 수 있습니다. 하나의 실행이 모델 완성, 도구 호출, 재시도, 백그라운드 작업, 다른 에이전트로의 핸드오프 등을 포함할 수 있고, 스팬이 끝날 때까지 기다렸다가 한꺼번에 쓰는 방식은 관측성 관점에서 바람직하지 않습니다.
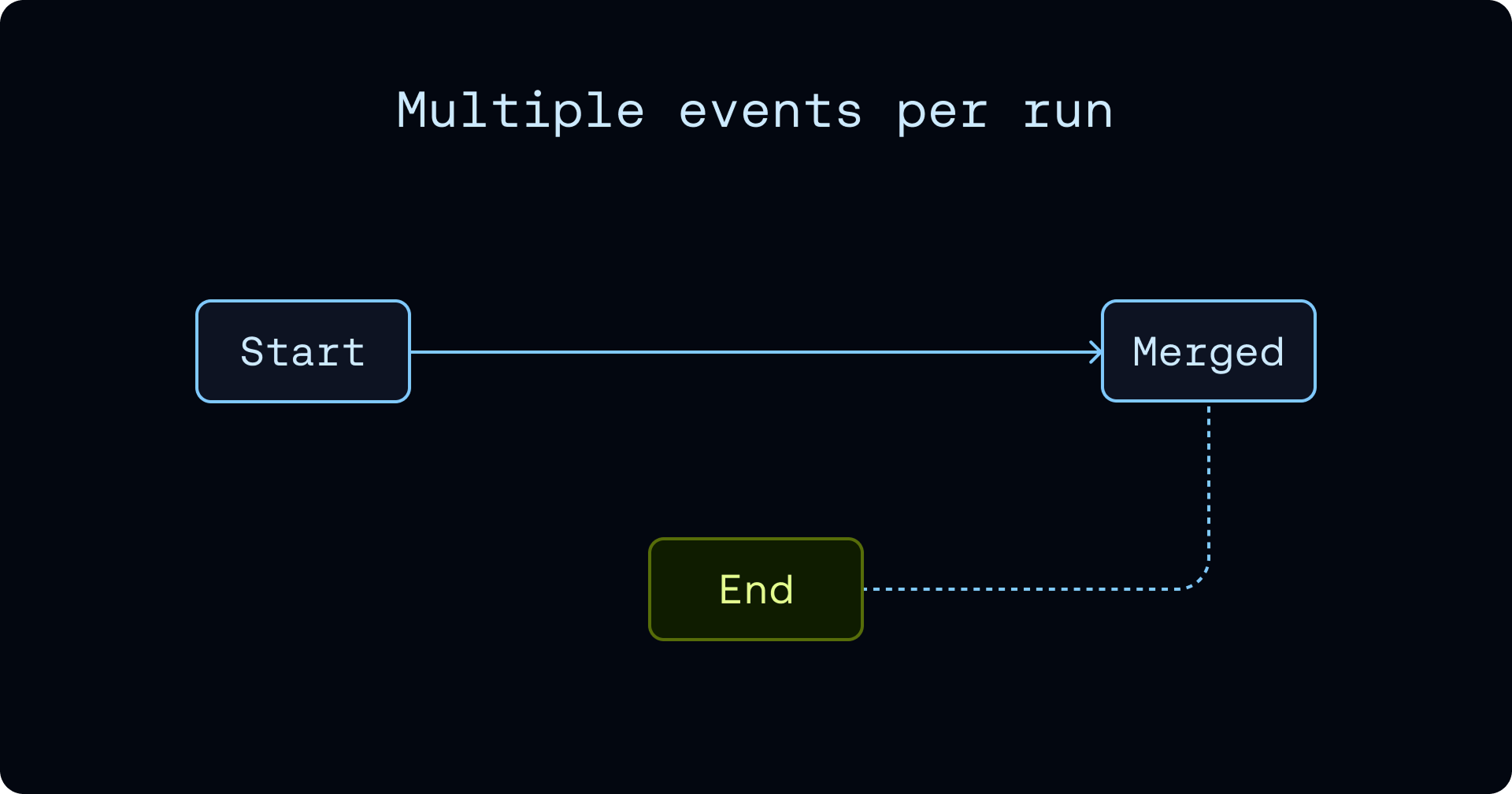
SmithDB에서는 하나의 실행이 단일 불변 행이 아니라 이벤트의 시퀀스(sequence of events) 로 모델링됩니다. 말은 단순해 보이지만, 이 결정은 질의 엔진 전체에 영향을 미칩니다. 특정 이벤트를 겨냥하도록 필터를 팬아웃(fanout)시키고, 질의 시점에 이벤트들을 효율적으로 병합해야 하며, 이는 곧 컴팩션 전략에도 영향을 줍니다.
시간 계층 컴팩션(Time-tiered compaction)
인제스션은 쓰기 지연시간(write latency)에 최적화되며, 그 결과 많은 작은 불변 세그먼트를 만들어 냅니다. 그것들을 영원히 그 상태로 질의하면 파일 오픈 오버헤드와 중복 제거 작업이 누적되어 질의가 느려집니다.
컴팩션은 쓰기 최적화 세그먼트를 질의 최적화 세그먼트로 다시 씁니다. SmithDB는 시간 계층(time-tiered) 전략을 사용합니다. 최신 데이터는 아직 종료(end) 이벤트가 더 도착할 가능성이 높으므로 너무 일찍 큰 파일로 합치면 불필요한 쓰기 증폭(write amplification)이 발생합니다. 반대로 오래된 데이터는 더 안정적이고 반복적으로 스캔될 가능성이 높아 큰 파일로 합치는 것이 유리합니다. 이 전략 덕분에 인제스션은 빠르게 유지되면서도 오래된 데이터는 점차 더 저렴하게 질의할 수 있게 됩니다.
삭제, TTL, 보존 정책 변경
관측성 시스템에서 삭제(delete)나 업그레이드 같은 변경(mutation)은 까다로운 문제입니다. 데이터 파일이 불변이기 때문입니다. SmithDB는 기본적으로 삭제마다 데이터 파일을 동기적으로 다시 쓰지 않습니다. 대신 메타스토어가 세그먼트 항목에 삭제 벡터(deletion vector) 와 업그레이드 벡터(upgrade vector) 를 첨부합니다. 질의와 컴팩션 경로는 이 벡터들을 사용해 불변 파일을 올바르게 해석합니다. 실제 파일 다시 쓰기는 컴팩션 시점에 일어납니다. 이 아이디어는 Delta Lake의 deletion vectors 나 Apache Iceberg의 equality/position deletes 같은 현대적인 레이크하우스 포맷에서도 비슷한 형태로 채택되어 있습니다.
이 전략은 SmithDB에서 변경을 매우 확장 가능하게 만들며, 보존 정책이 트레이스마다 다르게 적용되는 에이전트 관측성에 특히 잘 어울립니다. 대부분의 트레이스는 최근 디버깅과 모니터링, 평가에만 유용하고, 일부만이 내용에 따라 장기간 보관됩니다.
큰 필드의 지연 머터리얼라이제이션(Late materialization)
에이전트 트레이스는 종종 크고 경계가 없는(unbounded) 페이로드를 포함합니다. SmithDB는 일반적인 목록과 필터 질의가 빠르게 유지되도록 핵심 실행 필드와 큰 필드를 분리 합니다. 핵심 행(core row)은 큰 필드 파일에 대한 포인터만 가지고 있고, 질의 엔진은 사용자가 실제로 그 필드를 프로젝션하거나 해당 실행을 열어볼 때에만 큰 페이로드를 가져옵니다.
이 덕분에 실행 목록을 불러오거나 필터를 적용할 때, 사용자가 실제로 그 큰 페이로드를 요청하지 않는 한 메가바이트 단위의 JSON을 읽어 들일 필요가 없습니다. 이는 일반적인 컬럼형 데이터베이스의 late materialization 최적화와 같은 원리를 도메인에 맞게 확장한 것입니다.
전체 텍스트 검색과 JSON 필터링
1MB 이상의 페이로드 위에서 서브초(sub-second) 단위의 전체 텍스트 검색과 JSON 키 경로 필터링을 지원하는 것은 그 자체로 어려운 엔지니어링 문제입니다. 로컬 디스크 기반 인덱스는 값싼 시크(seek)와 많은 작은 읽기에 의존할 수 있지만, 객체 스토리지에서는 그 패턴이 무너집니다. 불필요한 요청 하나하나가 지연을 더하고, 큰 포스팅 리스트(postings list)나 위치 리스트(positions list)를 너무 일찍 가져오면 질의 시간을 지배해 버립니다.
SmithDB는 객체 스토리지에 최적화된 커스텀 역색인(inverted index) 레이아웃 으로 이를 해결합니다. 용어(term)는 로우 그룹(row group)으로 정렬되며, 각 로우 그룹은 자신의 최소/최대 용어 영역(min/max term zone)을 기록합니다. 따라서 정확 일치나 접두사 질의(prefix query)는 포스팅 바이트를 가져오기 전에 인덱스 로우 그룹을 가지치기(prune)할 수 있습니다. 포스팅과 위치는 용어 사전(term dictionary)과 분리된 청크로 저장되어, 흔한 용어가 거대한 인-메모리 할당이나 객체 스토리지 범위 읽기 하나를 강제하지 않도록 합니다. 로우 그룹과 청크 임계값은 빌더의 메모리와 질의 시점 I/O 모두를 제한합니다. 이 설계는 Apache Lucene 계열의 전통적인 역색인 구조를 객체 스토리지 환경에 맞게 재해석한 것에 가깝습니다.
클러스터 관리와 스티키 라우팅(Sticky routing)
SmithDB는 어떤 서비스 노드가 어떤 트래픽을 소유하는지를 통제하는 가벼운 클러스터 매니저를 포함합니다. 이것이 중요한 이유는 단순한 부하 분산이 아니라, 반복되는 질의가 이미 적절한 데이터를 캐시한 노드에 도달하도록 만드는 것 이 목적이기 때문입니다.
이 클러스터 매니저는 Google의 Slicer와 Databricks의 Dicer 프로젝트에서 영감을 받아, 키스페이스(keyspace)를 슬라이스로 나눠 각 슬라이스를 안정적인 서비스 노드 집합에 할당합니다. 라우터는 이 할당 정보를 이용해 관련된 요청을 같은 노드 혹은 작은 복제본 집합으로 보냅니다. 그 결과 SmithDB는 두 가지 중요한 성질을 얻습니다:
- 스티키 라우팅(Sticky routing): 관련된 요청이 이미 올바른 메타데이터나 세그먼트 바이트를 캐시한 노드에 도달할 가능성이 높습니다.
- 적응형 밸런싱(Adaptive balancing): 노드가 합류, 이탈하거나 과부하 상태가 되면, 클러스터 매니저가 내구성 있는 세그먼트 메타데이터를 건드리지 않고도 슬라이스를 이동시킬 수 있습니다.
데이터 인프라 관점에서 본 SmithDB의 위치
SmithDB가 등장한 맥락을 이해하려면 최근 데이터 인프라 트렌드와 비교해 보는 것이 도움이 됩니다.
| 시스템 | 워크로드 | 스토리지 모델 | 차별점 |
|---|---|---|---|
| ClickHouse | OLAP 분석, 실시간 메트릭 | 로컬 디스크 / 객체 스토리지 (Cloud) | 컬럼형 OLAP, 폭넓은 범용성 |
| Apache Druid | 시계열 분석 | 객체 스토리지 + 미들 매니저 | 실시간 인제스션, 시계열 특화 |
| Grafana Tempo | 분산 트레이싱 | 객체 스토리지 | OpenTelemetry 호환, 단순한 트레이스 룩업 |
| Honeycomb Retriever | 관측성 트레이스 | 커스텀 컬럼형 + 객체 스토리지 | 고카디널리티 이벤트 분석 |
| SmithDB | 에이전트 트레이스 | 객체 스토리지 + LSM | 트리 인식 질의, 다중 이벤트 실행, 큰 JSON 페이로드 |
SmithDB는 일반 OLAP 엔진이나 전통적인 분산 트레이싱 백엔드와 달리, 하나의 실행이 여러 이벤트로 점진적으로 도착하고 깊이 중첩된 트리를 이루는 에이전트 워크로드의 특수성에 맞춰 설계되었다는 점이 핵심 차별점입니다. OpenTelemetry 기반의 일반 트레이싱이 잘 다루지 못하는 영역, 즉 시간/스팬 정합성이 느슨하고 페이로드가 거대한 LLM 에이전트 워크로드를 정조준하고 있습니다.
앞으로의 방향
LangChain은 LangSmith UI 더 많은 부분을 SmithDB로 옮기는 작업과 함께, 이 새로운 데이터 계층이 가능하게 만들 새로운 제품 경험을 예고하고 있습니다. LangSmith의 다음 단계는 단순히 트레이스를 더 빨리 불러오는 것이 아니라, 트레이스 데이터를 더 유용하게(more useful) 만드는 것입니다. 즉, 검색하기 쉽고, 분석하기 쉬우며, 다시 에이전트 개발 루프로 피드백되기 쉬운 형태로 만드는 것이 목표입니다. SmithDB는 이 비전을 가능하게 하는 기반 계층 역할을 할 것입니다.
LangChain은 또한 SmithDB의 다음 단계를 함께할 시스템 및 데이터베이스 엔지니어를 채용하고 있으며, 향후 블로그 시리즈로 각 엔지니어링 과제를 더 깊이 있게 다룰 예정이라고 밝혔습니다.
SmithDB가 우리에게 시사하는 것
SmithDB의 등장은 단순히 LangSmith의 백엔드가 바뀌었다는 사실을 넘어, 에이전트 관측성이 이제 별도의 데이터 시스템을 정당화할 만큼 독립적인 워크로드 분야로 자리잡았다 는 것을 보여줍니다. RAG 파이프라인 시절의 트레이스가 단순한 함수 호출 로그였다면, 멀티 에이전트와 장시간 실행 에이전트가 만들어 내는 트레이스는 시계열 분석, 분산 트레이싱, 대규모 JSON 검색을 동시에 요구하는 복합 워크로드입니다.
비슷한 관측성 인프라를 직접 구축하려는 팀이라면, SmithDB가 채택한 객체 스토리지 + LSM + 컬럼형 인덱스 + 시간 계층 컴팩션 조합은 좋은 출발점이 됩니다. 한편 외부에 의존하고 싶다면, LangSmith 외에도 Langfuse, Arize Phoenix, Honeycomb 같은 관측성 도구들이 비슷한 문제를 각자의 방식으로 다루고 있어 비교해 볼 가치가 있습니다.
 SmithDB 소개 블로그 (We built SmithDB, the data layer for agent observability)
SmithDB 소개 블로그 (We built SmithDB, the data layer for agent observability)
 SmithDB 사용해보기 (LangSmith)
SmithDB 사용해보기 (LangSmith)
더 읽어보기
-
Agentic Harness Engineering(AHE): 관측 가능성 기반 코딩 에이전트 하네스의 자동 진화 프레임워크에 대한 연구
-
Langchain-AutoTools: Python SDK을 Langchain에서 사용 가능한 도구로 변환하는 프로젝트
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()