
에이전틱 하네스 엔지니어링(AHE) 소개
코딩 에이전트와 하네스의 중요성
숙련된 소프트웨어 엔지니어가 새로운 프로젝트에 합류하는 상황을 상상해 봅시다. 이 엔지니어의 역량은 프로그래밍 언어에 대한 지식뿐 아니라, 사용하는 IDE의 설정, 자동화 스크립트, 디버깅 도구, 그리고 이전 프로젝트에서 축적한 노하우에 의해서도 결정됩니다. AI 코딩 에이전트의 세계에서도 정확히 같은 원리가 작동합니다. 에이전트의 성능은 언어 모델의 지능만이 아니라, 그것을 둘러싼 도구와 환경의 설계에 크게 좌우됩니다.
최근 코딩 에이전트(coding agent)는 실제 GitHub 이슈 해결부터 복잡한 터미널 워크플로까지, 장기 소프트웨어 엔지니어링 작업에서 눈에 띄는 발전을 이루고 있습니다. SWE-bench, Terminal-Bench, MLE-bench 등 다양한 벤치마크에서 에이전트의 성능이 빠르게 향상되고 있으며, 이 발전은 단순히 기반 언어 모델의 능력 향상만으로 설명되지 않습니다.
에이전트 성능을 결정짓는 또 다른 핵심 요소가 바로 하네스(harness) 입니다. 하네스란 모델이 파일 시스템, 셸, 외부 서비스와 상호작용하는 방식을 중재하는 시스템 프롬프트, 도구(tool), 미들웨어(middleware), 스킬(skill), 장기 기억(long-term memory) 등의 구성 요소를 총칭합니다. Claude Code, OpenHands, SWE-agent 같은 시스템들이 보여주듯, 동일한 기반 모델을 사용하더라도 하네스 설계에 따라 벤치마크 성능이 크게 달라집니다.
기존 하네스 최적화 접근법의 한계
현재 하네스 개발은 대부분 수작업에 의존합니다. 사람이 에이전트의 실행 궤적(trajectory)을 직접 검토하고, 반복적인 실패 패턴을 식별한 후, 프롬프트나 도구를 수정하는 방식입니다. 하지만 기반 모델의 능력이 빠르게 발전하는 상황에서, 이 수동 루프는 비용이 높고, 확장이 어려우며, 과학적 연구로 발전시키기도 힘들다는 한계가 있습니다.
이를 자동화하려는 시도들도 있었습니다. Reflexion 과 Self-Refine 같은 접근법은 에이전트의 에피소드별 자기 반성(episodic critique)을 통해 출력을 개선하고, ACE(Agentic Context Engineering) 는 자연어 플레이북(playbook)을 인컨텍스트로 주입하여 에이전트의 행동을 개선합니다. TF-GRPO(Training-Free Group Relative Policy Optimization) 는 성공적인 도구 사용 시퀀스를 강화하는 방식을 취합니다. 하지만 이들은 모두 프롬프트 수준의 편집에 머무르며, 도구 구현, 미들웨어, 장기 기억 같은 하네스의 핵심 구성 요소는 건드리지 못합니다. 마치 자동차의 핸들만 조정하면서 엔진, 서스펜션, 변속기는 그대로 두는 것과 비슷합니다.
더 근본적인 문제도 있습니다. 코딩 에이전트의 실행 궤적은 수백만 토큰에 달하는 비구조화된 로그로 구성되어 있어, 진화 에이전트(evolution agent)가 소비할 수 있는 유의미한 신호를 추출하기 어렵습니다. 수천 줄의 셸 출력, 도구 호출 결과, 중간 추론 과정이 뒤섞인 원시 궤적에서 "어떤 하네스 결함이 이 실패를 초래했는가"를 식별하는 것은, 사람에게도 어려운 작업입니다. 또한 기존 하네스 프레임워크는 구성 요소 간 결합도가 높아, 프롬프트 이외의 수정이 연쇄적으로 오류를 유발하기 쉽습니다.
이러한 어려움들 때문에, DSPy의 파이프라인 최적화, Voyager의 스킬 라이브러리 진화, AlphaEvolve의 프로그램 아카이브 돌연변이 등 자동 에이전트 최적화 연구가 활발히 진행되고 있지만, 대부분 프롬프트나 단일 편집 표면에 초점을 맞추고 있었습니다. 하네스 전체를 하나의 결합된 시스템(combinatorial whole)으로 최적화하는 연구는 아직 초기 단계입니다.
관측 가능성이라는 발상의 전환
그렇다면 하네스 엔지니어링의 자동화는 왜 이토록 어려운 것일까요? 연구팀은 네 가지 핵심 난제를 식별합니다: (1) 프롬프트, 도구, 미들웨어 등 성격이 전혀 다른 구성 요소들이 뒤섞인 이질적인 액션 공간(heterogeneous action space), (2) 태스크 통과/실패라는 희박하고 노이즈가 많은 평가 신호(sparse and noisy evaluation signal), (3) 단일 롤아웃에서 수백만 토큰에 달하는 긴 궤적(multi-million-token trajectories), 그리고 (4) 특정 편집의 효과를 다음 라운드의 성과에 귀속시키기 어려운 문제(attribution difficulty) 입니다.
이 연구의 핵심 통찰은 명확합니다. 이 네 가지 난제의 병목은 에이전트의 능력이 아니라 관측 가능성(observability) 이라는 것입니다. 진화 에이전트에게 명확한 행동 공간(action space) 위에 구조화된 맥락을 제공하면, 에이전트는 안정적으로 더 나은 하네스 설계에 수렴할 수 있습니다.
Fudan University, Peking University, Shanghai Qiji Zhifeng의 연구팀은 이 통찰을 구현한 AHE(Agentic Harness Engineering) 프레임워크를 제안합니다. AHE는 하네스 진화 루프의 세 단계, 즉 구성 요소 편집, 궤적 검사, 의사 결정 각각에 대응하는 세 가지 관측 가능성 기둥(observability pillar)을 세워, 모든 편집을 반증 가능한 계약(falsifiable contract) 으로 전환합니다.
이 논문의 세 가지 핵심 기여를 요약하면 다음과 같습니다. 첫째, 코딩 에이전트에 대한 에이전트 주도 하네스 진화(agent-driven harness evolution)를 공식화하고, 구성 요소, 궤적, 의사 결정 전반에 걸친 관측 가능성이 프롬프트 전용 편집이 아닌 전체 하네스의 공동 진화를 가능케 하는 설계 핵심(design pivot)임을 식별합니다. 둘째, 분리된 구성 요소 기판, 계층적 궤적 증류 파이프라인, 다음 라운드에서 검증되는 자기 선언적 예측이 포함된 변경 매니페스트라는 세 가지 관측 가능성 기둥을 통해 AHE를 제안합니다. 셋째, 경험적으로 AHE의 효과를 검증합니다.
실험 결과, AHE는 10 회 반복만으로 Terminal-Bench 2에서 pass@1을 69.7\% 에서 77.0\% 로 끌어올렸습니다. 이는 사람이 설계한 Codex-CLI(71.9\%)는 물론, 자기 진화 베이스라인인 ACE와 TF-GRPO를 모두 능가하는 수치입니다. 더 주목할 점은, 진화를 멈추고 고정한 하네스가 SWE-bench-verified와 다른 모델 패밀리에도 추가 진화 없이 전이(transfer)된다는 사실입니다. 그리고 성능 향상이 프롬프트가 아닌 도구, 미들웨어, 장기 기억에 집중된다는 구성 요소 분석(component ablation) 결과는, 기존 프롬프트 중심 최적화 패러다임에 대한 재고를 촉구합니다.
AHE의 세 가지 관측 가능성 기둥
AHE는 하네스 최적화를 폐쇄 루프(closed loop)로 전환합니다. 기반 모델은 고정한 채, 오직 하네스의 명시적 구성 요소만 편집합니다. 설계 원칙은 이 루프의 모든 단계가 관측 가능해야 한다는 것입니다.
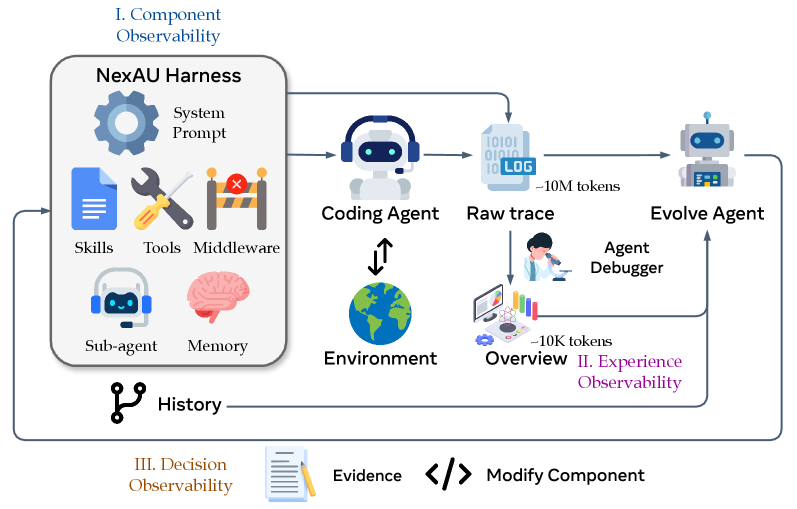
구성 요소 관측 가능성: NexAU 프레임워크
첫 번째 기둥인 구성 요소 관측 가능성(component observability) 은 NexAU 프레임워크를 통해 실현됩니다. NexAU는 하네스를 7 가지 직교적(orthogonal) 구성 요소 유형으로 분해하여, 각각을 작업 공간 내 고정된 마운트 포인트에 독립적인 파일로 노출합니다:
- 시스템 프롬프트(System Prompt): 에이전트의 전반적인 행동 지침과 규율을 정의합니다
- 도구 설명(Tool Description): 각 도구의 용도, 매개변수, 반환값을 기술합니다
- 도구 구현(Tool Implementation): 실제 도구의 실행 로직을 담당합니다
- 미들웨어(Middleware): 도구 호출 전후에 개입하는 훅(hook)으로, 검증이나 후처리를 수행합니다
- 스킬(Skill): 특정 작업 패턴을 캡슐화한 재사용 가능한 작업 단위입니다
- 서브 에이전트 구성(Sub-agent Configuration): 보조 에이전트의 설정과 호출 조건을 정의합니다
- 장기 기억(Long-term Memory): 이전 경험에서 학습한 교훈과 패턴을 저장합니다
이 분리(decoupling)가 핵심입니다. 미들웨어를 추가할 때 시스템 프롬프트를 수정할 필요가 없고, 스킬을 추가할 때 도구를 건드릴 필요가 없습니다. 마치 UNIX 철학에서 각 프로그램이 하나의 일을 잘 수행하도록 설계되는 것처럼, 각 구성 요소가 하나의 관심사(concern)만 담당합니다. 각 실패 패턴이 하나의 구성 요소 클래스에 매핑되므로, 진화 에이전트에게 깔끔한 행동 공간을 제공하고, 모든 성능 변화를 수백 줄의 비구조화된 프롬프트가 아닌 단일 파일에 귀속시킬 수 있습니다. 각 논리적 편집은 작업 공간의 git 이력에 하나의 커밋으로 기록되어, 파일 수준의 diff와 롤백 세분성(rollback granularity)이 자연스럽게 따라옵니다.
기존 하네스 프레임워크들과 비교하면, NexAU의 차별점이 선명해집니다. 예를 들어 OpenHands나 SWE-agent 같은 시스템에서는 하네스의 각 부분이 긴밀하게 얽혀 있어, 하나의 구성 요소를 수정하면 다른 부분에 의도치 않은 영향이 전파됩니다. NexAU의 느슨한 결합(loose coupling)은 이 문제를 원천적으로 해소하여, 진화 에이전트가 안전하게 실험할 수 있는 환경을 만듭니다.
중요한 설계 결정으로, 시드 하네스 H_0 는 의도적으로 최소한으로 설정됩니다. 셸 실행 도구(bash tool) 하나만 포함하고, 미들웨어, 스킬, 서브 에이전트, 장기 기억이 전혀 없습니다. 이는 실험 과학의 대조군(control group) 설계와 같은 원칙입니다. 만약 시드가 이미 대상 벤치마크에 맞춰져 있다면, 이후 모든 편집의 기여도 분석(attribution)이 오염됩니다. 최소한의 시드는 AHE가 추가하는 모든 구성 요소가 실측된 실행 결과로 자신의 가치를 증명하도록 강제합니다.
경험 관측 가능성: Agent Debugger
두 번째 기둥인 경험 관측 가능성(experience observability) 은 Agent Debugger 를 통해 실현됩니다. 벤치마크의 각 태스크에 대해 k 개의 실행 궤적이 생성되는데, 이 원시 궤적은 수백만 토큰에 달하며 하네스의 결함에서 비롯된 오류가 산재해 있습니다.
Agent Debugger는 이 궤적들을 파일 기반 환경으로 프레이밍합니다. 각 궤적 메시지가 개별 파일에 저장되고, 일반적인 셸 및 스크립팅 도구로 탐색할 수 있는 구조입니다. 마치 개발자가 로그 파일을 grep과 less로 탐색하듯, Agent Debugger는 궤적을 탐색 가능한 파일 시스템으로 변환합니다. 동일한 쿼리를 가진 궤적들은 하나의 환경에 배치되며, 디버거는 실패의 근본 원인이나 성공 패턴을 분석하여 태스크별 분석 보고서(per-task analysis report) 를 생성합니다.
Agent Debugger의 분석은 두 가지 수준으로 구성됩니다. 먼저, 각 태스크에 대해 통과/실패 상태와 함께 근본 원인을 기술하는 태스크별 보고서가 생성됩니다. 이 보고서는 Evolve Agent가 구체적인 편집 근거를 확보하는 데 사용됩니다. 그다음, 모든 태스크별 보고서는 벤치마크 수준 개요(benchmark-level overview) 로 집계되어, 반복적으로 나타나는 실패 패턴과 성공 패턴을 조감도로 제공합니다. 이 개요가 각 진화 반복의 진입점 역할을 합니다.
이 접근법은 Anthropic이 제안한 점진적 공개(progressive disclosure) 원칙을 따릅니다. 진화 에이전트는 기본적으로 요약된 보고서를 소비하되, 필요하면 원시 궤적까지 드릴다운하여 보고서의 주장을 직접 검증할 수 있습니다. 원시 궤적은 그대로의 형태와 불필요한 콘텐츠를 제거한 정제된 형태 모두 파일로 제공됩니다. 이 계층적 구조는 토큰 소비를 절약하면서도, 에이전트가 필요한 깊이의 증거에 언제든 접근할 수 있도록 보장합니다.
Agent Debugger의 궤적 분석 코드는 AHE 저장소에 부분적으로 공개되어 있으며, 전체 프레임워크는 NexAU 저장소를 통해 접근할 수 있습니다.
런타임 인프라 측면에서, Agent Debugger는 동시성(concurrency) 16 으로 실행되며 태스크당 600 초의 타임아웃이 적용됩니다. 모든 롤아웃은 E2B 원격 샌드박스 내에서 실행되어, 셸 부작용이 태스크 간에 유출되지 않도록 격리합니다.
결정 관측 가능성: Evolve Agent
세 번째 기둥인 결정 관측 가능성(decision observability) 은 Evolve Agent 가 실현합니다. Evolve Agent는 AHE 루프를 닫는 역할을 합니다. 매 라운드마다 Agent Debugger가 생성한 계층적 증거 코퍼스를 읽고, 어떤 하네스 구성 요소를 추가, 수정, 제거할지 결정한 후, 작업 공간에 해당 편집을 적용하고, 모든 편집의 이유를 기록합니다.
두 가지 제약 조건이 이 편집을 통제합니다. 첫째는 통제 가능성(controllability) 입니다. Evolve Agent는 하네스 작업 공간 내부에만 쓸 수 있으며, 실행 디렉토리, 트레이서, 검증기, LLM 설정은 읽기 전용입니다. 시드 시스템 프롬프트는 삭제 불가로 표시됩니다. 이러한 제한은 검증기를 비활성화하거나, 모델을 교체하거나, 추론 예산을 늘리는 등의 지름길을 차단하여, 기록된 모든 성능 향상이 하네스 편집에 귀속되도록 합니다.
둘째는 증거 기반 편집(evidence-driven edits) 입니다. 모든 변경 사항에는 매니페스트(manifest) 항목이 첨부됩니다. 이 항목에는 다음 네 가지가 포함됩니다:
- 실패 증거: 어떤 태스크의 어떤 궤적에서 문제가 관찰되었는가
- 추론된 근본 원인: 해당 실패가 어떤 하네스 결함에서 비롯되었는가
- 목표 수정: 이 편집이 구체적으로 무엇을 변경하는가
- 예상 영향: 어떤 태스크가 수정될 것이고, 어떤 태스크에 회귀 위험이 있는가
다음 라운드에서 예측된 수정/회귀 집합이 실제 태스크별 변화와 교차 검증되어, 각 편집에 대한 판정이 내려집니다. 효과가 없었다고 판정된 편집은 파일 수준에서 자동으로 롤백됩니다. 마치 과학적 가설이 실험을 통해 반증되는 것처럼, 각 편집이 다음 평가에 의해 반증 가능한 계약이 되는 것입니다. 이 메커니즘은 "자기 정당화(self-justification)"에 의한 편집 누적을 방지합니다. 아무리 그럴듯한 이유를 제시하더라도, 다음 라운드의 실측 결과가 이를 뒷받침하지 않으면 해당 편집은 제거됩니다.
AHE 외부 루프의 동작 과정

위와 같은 알고리즘으로 정리된 AHE의 외부 루프는 다음과 같이 구성됩니다:
- 롤아웃(Rollout): 현재 하네스로 벤치마크의 각 태스크에 대해 k 개의 궤적을 생성합니다. 여기서 k \geq 2 는 의도적인 설계입니다. 각 태스크가 통과율 신호를 가지게 되어, 부분 통과(partial-pass) 태스크가 비교 진단의 자연스러운 기준점이 됩니다
- 정제(Clean): base64 인코딩 제거, 중복 도구 출력 제거 등 궤적을 정리합니다
- 귀속(Attribute): t \geq 2 일 때, 이전 라운드의 매니페스트를 현재 결과와 대조하여 각 편집의 유효성을 판정하고, 무효한 편집을 롤백합니다
- 증류(Distill): Agent Debugger가 정제된 궤적을 계층적 증거 코퍼스로 변환합니다
- 진화(Evolve): Evolve Agent가 증거를 바탕으로 하네스 구성 요소를 편집하고 새로운 매니페스트를 생성합니다
- 커밋(Commit): 변경 사항을 git에 태깅합니다
- H_{best} 업데이트: 현재 반복의 \text{pass@1}(T_t) 가 지금까지의 최고 기록을 넘으면, H_{best} 를 H_t 로 갱신합니다. 이를 통해 비단조적 진화 곡선에서도 최적 하네스가 항상 보존됩니다
귀속 단계가 증류 이전에 실행되는 점이 주목할 만합니다. 이전 매니페스트의 판정 결과가 증거 코퍼스에 포함되어, 각 매니페스트 항목이 단순한 근거(rationale)가 아닌 계약(contract)으로 기능합니다. 이를 통해 Evolve Agent는 이전 반복에서 어떤 편집이 실제로 효과가 있었고 어떤 편집이 실패했는지를 명확히 인지한 상태에서 다음 편집을 결정할 수 있습니다.
추가로, 첫 번째 반복과 병렬로 탐색 에이전트(Explore Agent) 가 실행됩니다. 이 에이전트는 NexAU 소스 코드와 공개된 코딩 에이전트 레퍼런스에서 소수의 재사용 가능한 스킬을 시드합니다. 이 스킬들은 특별한 보호를 받지 않으며, 두 번째 반복부터 Evolve Agent가 관측된 롤아웃에 기반하여 유지, 정제, 또는 제거할 수 있습니다. 이는 초기 부트스트래핑을 제공하되, 이후 진화 과정에서 증거 기반으로 필터링되도록 하는 설계입니다.
실험 설계
평가 환경 및 지표
연구팀은 Terminal-Bench 2의 전체 89 개 태스크(Easy 4 개, Medium 55 개, Hard 30 개)에서 AHE를 평가했습니다. 태스크별 타임아웃은 1 시간으로 설정되었습니다. 교차 벤치마크 전이를 위해서는 7 개 저장소에 걸친 500 개 태스크의 SWE-bench-verified에서 추가 평가를 수행했습니다.
주요 평가 지표는 두 가지입니다. 첫째, pass@1 은 태스크당 k 개 롤아웃의 평균 이진 성공률입니다. 인프라 중단이나 타임아웃으로 종료된 시행도 실패(r=0)로 처리하는 엄격한 기준을 적용하여, 공식 Terminal-Bench 리더보드와 일관된 수치를 보장합니다. 둘째, tokens/trial 은 모든 LLM 호출의 프롬프트 및 완료 토큰 합산 평균(천 단위)으로, 비용 효율성을 측정합니다. 두 지표를 결합한 Succ/Mtok(백만 토큰당 예상 성공 수)도 SWE-bench-verified 실험에서 보고됩니다.
모든 실험에서 세 가지 역할 에이전트(Code Agent, Agent Debugger, Evolve Agent)는 하나의 기반 모델인 GPT-5.4(high reasoning 설정)를 공유합니다. 이는 의도적인 실험 설계입니다. 세 역할이 동일한 모델을 사용함으로써, 관측된 성능 향상이 분석기(analyzer)나 편집기(editor)의 능력 차이가 아닌 하네스 편집 자체에서 비롯됨을 격리할 수 있습니다. 교차 모델 전이 실험에서는 GPT-5.4(medium, xhigh), Qwen-3.6-plus, Gemini-3.1-flash-lite-preview, DeepSeek-v4-flash 등 5 개 대안 모델을 추가로 평가했습니다.
실험 결과 및 성능 분석
Terminal-Bench 2 주요 결과
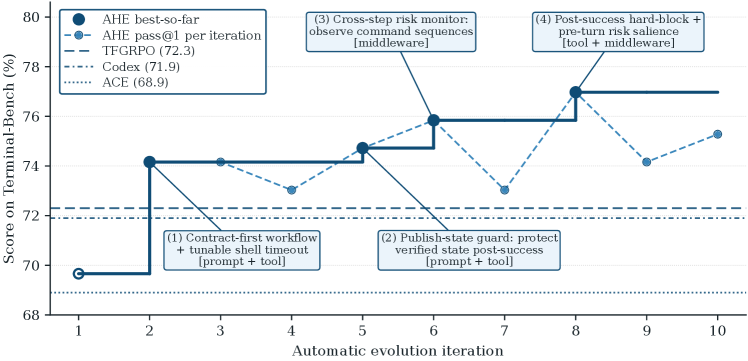
AHE는 bash 전용 NexAU0 시드에서 시작하여, 태스크당 k=2 롤아웃으로 10 회 반복을 수행했으며, 약 32 시간 만에 완료되었습니다. 두 자기 진화 베이스라인(ACE, TF-GRPO)도 동일한 NexAU0 시드에서 출발합니다.
AHE는 패널의 모든 베이스라인을 능가합니다. 비교 대상은 사람이 설계한 세 가지 하네스, 즉 opencode, terminus-2, 그리고 OpenAI의 Codex-CLI, 그리고 두 자기 진화 베이스라인인 ACE와 TF-GRPO입니다. 이 모든 베이스라인을 AHE가 넘어섰습니다.
구체적인 수치를 살펴보면, NexAU0 시드의 pass@1 69.7\% 에서 출발하여, AHE는 10 회 반복 후 77.0\% 에 도달합니다. 이는 Codex-CLI의 71.9\% 를 5.1 pp 차이로 앞서는 수치입니다. Figure 1의 진화 곡선에서 볼 수 있듯, 성능 향상은 반복 전반에 걸쳐 누적되며, 연속적인 진화가 pass@1을 NexAU0 시드 위로 지속적으로 밀어올립니다.
난이도별로 세분화하면 흥미로운 패턴이 드러납니다. Easy(4 개 태스크)와 Medium(55 개 태스크)에서는 AHE가 모든 베이스라인을 능가하거나 동률을 기록합니다. Hard(30 개 태스크)에서만 AHE가 Codex-CLI에 근소하게 뒤처지는데, 연구팀은 이 격차를 장기 태스크에서 AHE 구성 요소 간 간섭(interference)으로 추적합니다. 장기 기억, 미들웨어, 시스템 프롬프트가 모두 마감 검증을 반복적으로 트리거하여 한정된 턴 예산을 소진하는 것입니다. 흥미롭게도, AHE의 장기 기억만 NexAU0 시드에 단독으로 교체하면 Hard에서 Codex-CLI를 이미 능가합니다. 이는 구성 요소 간 상호작용 문제이지, 누락된 능력의 문제가 아닙니다.
프롬프트 전용 자기 진화의 한계
ACE와 TF-GRPO가 AHE에 뒤처지는 이유는 레이어 불일치(layer mismatch)에 있습니다. ACE는 자연어 플레이북을 인컨텍스트로 주입하고, TF-GRPO는 성공적인 도구 시퀀스를 강화하지만, 둘 다 동일한 NexAU0 시드에서 출발하면서 주변 스캐폴딩(scaffolding)을 편집하지 않습니다.
구성 요소 수준의 분석이 이를 증명합니다. AHE의 도구를 단독 교체하면 +3.3 pp, 미들웨어는 +2.2 pp, 장기 기억은 +5.6 pp의 향상을 가져오는 반면, 시스템 프롬프트 단독 교체는 -2.3 pp로 오히려 성능이 하락합니다. ACE와 TF-GRPO가 편집하지 않는 구성 요소들이 바로 성능 향상이 존재하는 곳입니다.
교차 벤치마크 전이: SWE-bench-verified
하지만 'Terminal-Bench 2에서 잘 작동하는 하네스가 다른 벤치마크에서도 효과적일까?'라는 질문이 자연스럽게 따라옵니다. AHE 하네스는 Terminal-Bench 2에서 진화되었지만, 연구팀은 추가 진화 없이 SWE-bench-verified에 그대로 적용하여 이 질문에 답합니다.
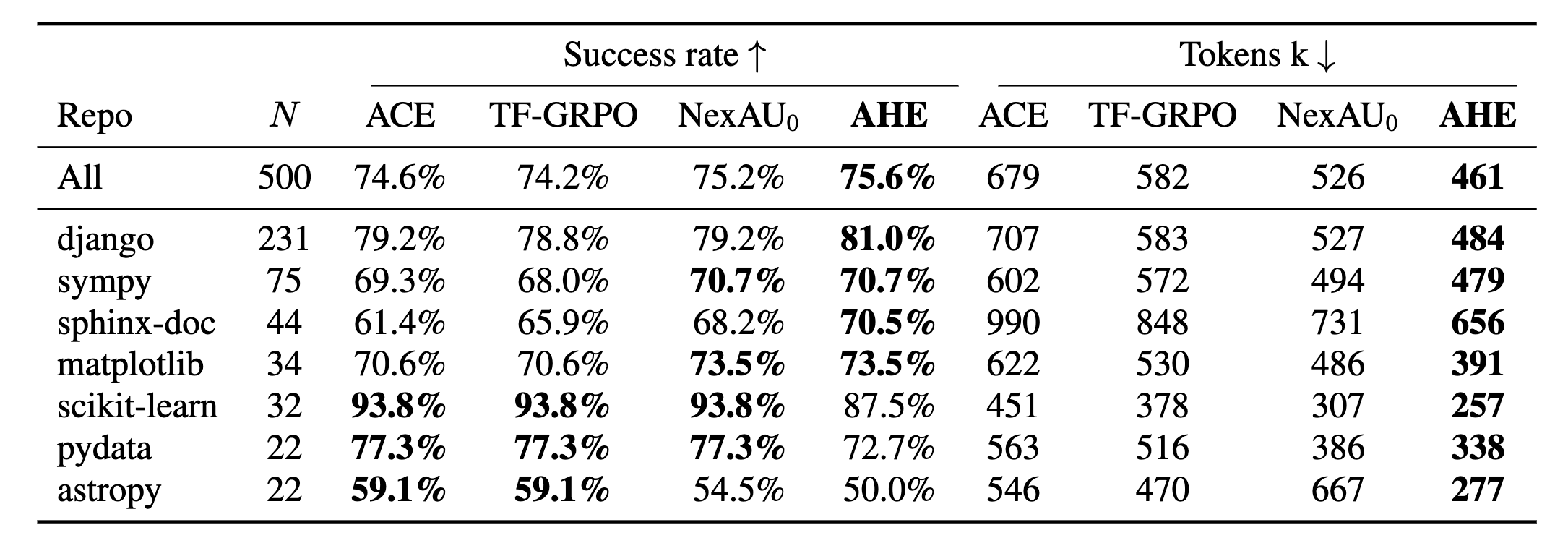
결과는 명확합니다. ACE와 TF-GRPO는 둘 다 원래의 NexAU0 시드보다 SWE-bench-verified에서 성능이 하락합니다. 시드 대비 11\% 에서 29\% 더 많은 토큰을 소비하면서도 전반적인 성공률이 떨어집니다. 이 현상의 원인은 구조적입니다. ACE가 주입하는 플레이북과 TF-GRPO가 강화하는 궤적 분포는 Terminal-Bench 궤적에서 증류된 것으로, 모든 모델 호출의 프롬프트에 실려(ride) 전달됩니다. 다른 태스크 표면에서는 이 텍스트가 비용만 추가하고 기반 정책을 실질적으로 변경하지 못합니다. 프롬프트에 행동을 인코딩하는 접근법의 근본적 한계가 드러나는 지점입니다.
반면 AHE는 가장 높은 전반적 성공률을 달성합니다. 시드 대비 향상이 django와 sphinx-doc, 즉 가장 크고 토큰 소비가 많은 두 저장소에 집중됩니다. 이들 저장소의 다단계 편집-검증 루프가 AHE의 도구, 미들웨어, 장기 기억이 Terminal-Bench 2에서 압축한 구조와 일치하기 때문입니다. 소규모 저장소 3 곳에서는 근소한 회귀가 나타나지만, 이는 소규모 저장소에서의 pass@1 분산이 저장소별 향상 폭을 초과하는 수준으로, 통계적 노이즈에 가깝습니다.
토큰 효율성 측면에서도 AHE의 우위가 확인됩니다. AHE는 ACE 대비 32\%, TF-GRPO 대비 21\%, 시드 대비 12\% 의 토큰을 절감합니다. 이 차이의 핵심은 인코딩 위치에 있습니다. 행동을 프롬프트에 인코딩하면 매 LLM 호출마다 해당 텍스트를 재처리하는 비용이 발생합니다. 반면 도구, 미들웨어, 기억에 인코딩하면 실행 시점에 한 번만 활성화되므로, 프롬프트 기반 베이스라인이 매 호출마다 치르는 재유도 비용을 원천적으로 피할 수 있습니다.
교차 모델 전이
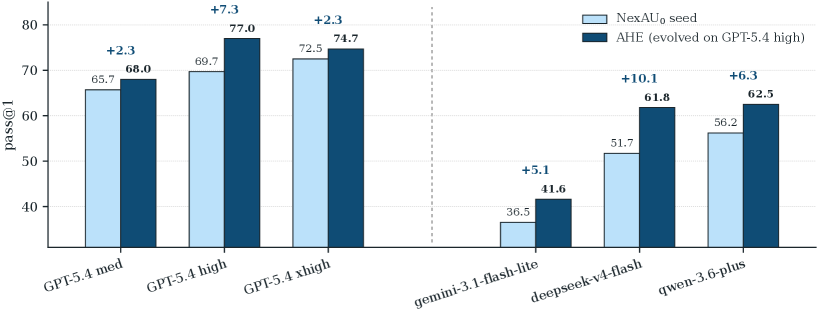
AHE의 고정된 하네스를 5 개 대안 기반 모델에 재평가한 결과, 모두 양의 pass@1 향상(+2.3 에서 +10.1 pp)을 보였습니다. 교차 패밀리 향상이 동일 패밀리 내 향상보다 큽니다:
- DeepSeek-v4-flash: 51.7\% 에서 61.8\% 로 +10.1 pp
- Qwen-3.6-plus: 56.2\% 에서 62.5\% 로 +6.3 pp
- Gemini-3.1-flash-lite-preview: 36.5\% 에서 41.6\% 로 +5.1 pp
포화 상태에서 먼 기반 모델일수록 AHE가 도구, 미들웨어, 장기 기억 안에 고정한 조정(coordination) 패턴에 더 많이 의존하는 반면, 더 강력한 기반 모델은 동일한 조정을 프롬프트에서 저비용으로 재유도할 수 있다는 해석이 가능합니다. 이는 AHE가 벤치마크 특화 튜닝이 아닌, 범용적인 엔지니어링 경험을 인코딩한다는 증거입니다.
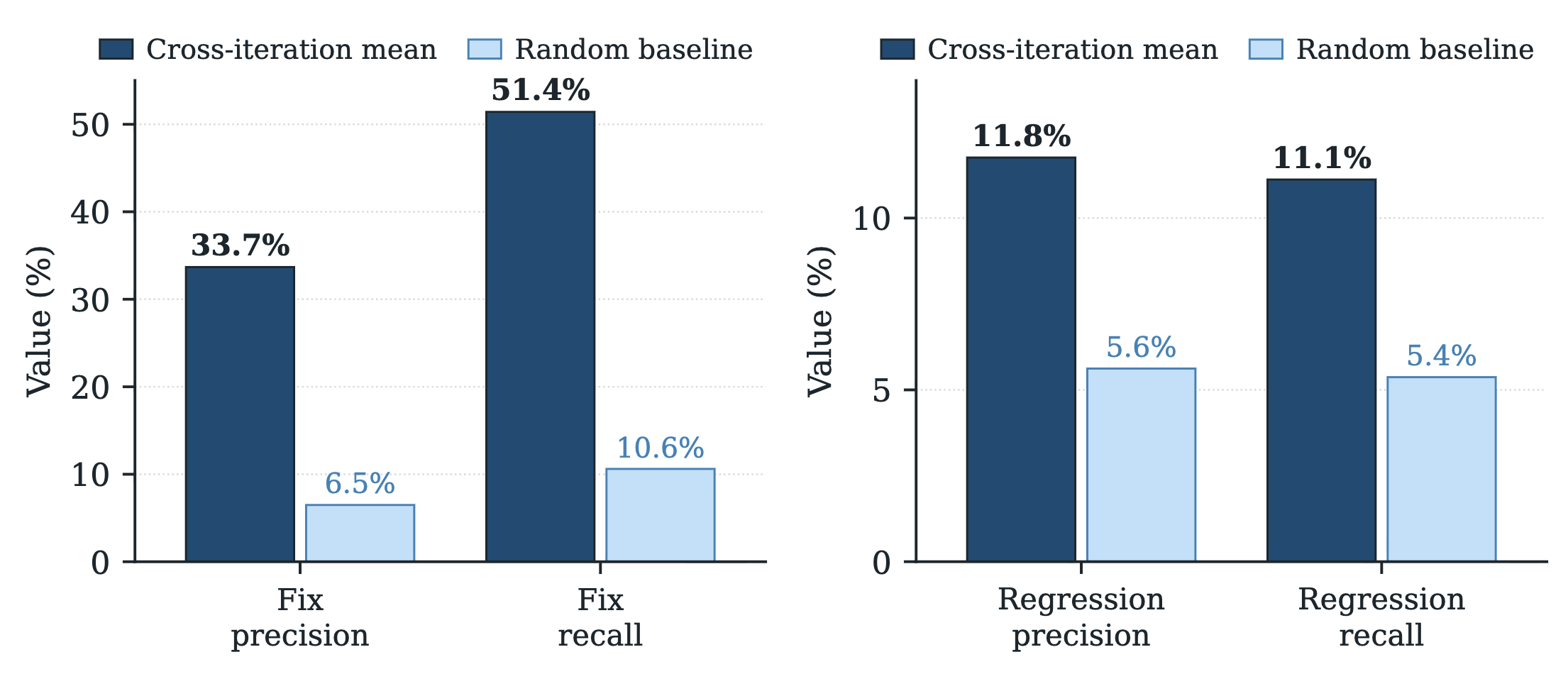
동일 패밀리(GPT-5.4) 내에서는 비단조적(non-monotone) 프로필이 관찰됩니다. medium에서 +2.3 pp, high에서 +7.3 pp, xhigh에서 +2.3 pp입니다. 이 패턴은 AHE의 스텝 예산과 태스크별 타임아웃이 GPT-5.4 high에 맞춰 진화 과정에서 조정되었기 때문입니다. medium은 스텝당 시간 여유가 더 크지만 추론 능력이 한 단계 낮고, xhigh는 더 많은 시행이 태스크별 타임아웃을 초과하여 실패로 처리됩니다. 연구팀은 이 타임아웃-예산 결합(timeout-budget coupling)을 일반화 위험 요소로 분류하고, 향후 개선 대상으로 논의합니다.
핵심적인 발견은, 모든 5 개 대안 모델에서 향상이 양수라는 점입니다. AHE 하네스가 특정 제공업체의 관용어(idiom)나 특정 추론 깊이에 특화되지 않았음을 의미합니다.
AHE가 진화시킨 구성 요소의 실제 사례
그렇다면 AHE가 구체적으로 어떤 구성 요소를 진화시켰는지 살펴보겠습니다.

10 회 반복을 거치면서 AHE가 진화시킨 구성 요소들은 구체적인 엔지니어링 교훈을 인코딩합니다. 장기 기억에는 12 개의 경계 사례 교훈이 축적되었는데, 예를 들어 "성능 마진이 요구사항의 경계에 있을 때 추가 검증이 필요하다", "대기열 초과 시 취소 처리 방식", "소스 패키징 시 디렉토리 레이아웃 규칙" 같은 구체적인 패턴들입니다. 이들은 추상적인 지침이 아니라, 실제 실패 궤적에서 추출된 경험적 지식입니다.
도구 측면에서는, 원래의 단순 bash 도구가 1364 줄의 확장된 셸 도구로 진화했습니다. 이 도구는 명령어 실행 시 주변 파일에서 관련 계약 힌트(contract hint)를 자동으로 탐색하여 에이전트에게 제공합니다. 미들웨어로는 finish-hook이 추가되어, 태스크 완료 전 평가자와 동형(isomorphic)인 마감 검사를 강제합니다. 이 모든 변화가 사람의 개입 없이, 순전히 롤아웃 증거에 기반하여 자동으로 이루어졌다는 점이 AHE의 핵심 가치입니다.
심층 분석: 구성 요소별 기여와 자기 귀속의 신뢰성
구성 요소별 가치 분석 (Ablation Study)
AHE의 성능 향상이 어디에서 비롯되는지 파악하기 위해, 각 구성 요소를 NexAU0 시드에 단독으로 교체하는 ablation 실험을 수행했습니다.
장기 기억(Long-term Memory): +5.6 pp. 성능 마진, 대기열 초과 취소, 평가자 스타일 마감, 소스 패키징 레이아웃 등 12 개의 경계 사례 교훈을 추가합니다. Hard에서는 장기 기억 단독이 전체 AHE를 능가하는 반면, Easy에서는 불필요한 재검증으로 감소합니다.
도구(Tools): +3.3 pp. 1364 줄의 셸 도구로, 각 명령어 근처 파일에서 계약 힌트를 자동으로 표면화합니다. Medium에서는 전체 AHE의 0.9 pp 이내에 도달하지만, Hard에서는 내장된 publish guard가 루프를 너무 일찍 종료합니다.
미들웨어(Middleware): +2.2 pp. 평가자와 동형(isomorphic)인 마감 검사를 강제하는 finish-hook을 추가합니다. Easy에서는 모든 태스크를 통과시키지만, Hard에서는 턴 수를 증가시킵니다.
시스템 프롬프트(System Prompt): -2.3 pp. 79 줄의 범용 규율을 인코딩하지만, 실행 가능성이 나머지 세 구성 요소에 의존합니다. 단독으로 삽입하면 오히려 성능이 하락합니다.
이 결과에서 가장 주목할 점은, 각 구성 요소가 서로 다른 실패 표면(failure surface)을 소유한다는 것입니다. 장기 기억은 경계 사례의 규칙을 인코딩하여 Hard 태스크에서 빛나고, 도구는 파일 근처의 계약 힌트를 자동 표면화하여 Medium에서 강하며, 미들웨어는 평가자 스타일의 마감 검사를 강제하여 Easy를 완전히 해결합니다. 각 구성 요소가 전문화된 영역이 다르기 때문에, 전체 하네스를 프롬프트 하나로 압축하는 것보다 분리된 구성 요소로 유지하는 것이 효과적입니다.
이 ablation 결과에서 도출되는 핵심 통찰은, 사실적 하네스 구조(factual harness structure) , 즉 도구, 미들웨어, 장기 기억은 태스크와 모델을 넘어 전이될 수 있지만, 산문 수준 전략(prose-level strategy) , 즉 시스템 프롬프트에 인코딩된 행동 지침은 전이되지 않는다는 것입니다. 이는 ACE나 TF-GRPO 같은 프롬프트 중심 접근법이 교차 벤치마크 전이에서 실패하는 이유를 구조적으로 설명합니다.
그러나 세 양의 단일 구성 요소 향상을 합산하면 +11.1 pp인데, 전체 AHE는 +7.3 pp에 그칩니다. 이는 구성 요소들이 비가산적(non-additively)으로 상호작용하기 때문입니다. 장기 기억, 미들웨어, 시스템 프롬프트가 모두 동일한 마감 스타일 검증을 향해 밀어, 중복 재검사에 턴을 소비합니다. 특히 Hard 태스크에서 장기 기억 단독이 전체 AHE를 초과하는 현상은, 스택된 구성 요소들이 장기 태스크의 한정된 턴 예산 내에서 서로 경쟁하고 있음을 보여줍니다. Evolve Agent가 55 개 Medium 태스크가 지배하는 전체 지표를 최적화하므로 Medium 중심 트레이드오프에 수렴하며, 난이도별 혹은 태스크 유형별 상호작용 인식 진화(interaction-aware evolution)는 향후 과제로 남겨집니다.
자기 귀속의 신뢰성 분석
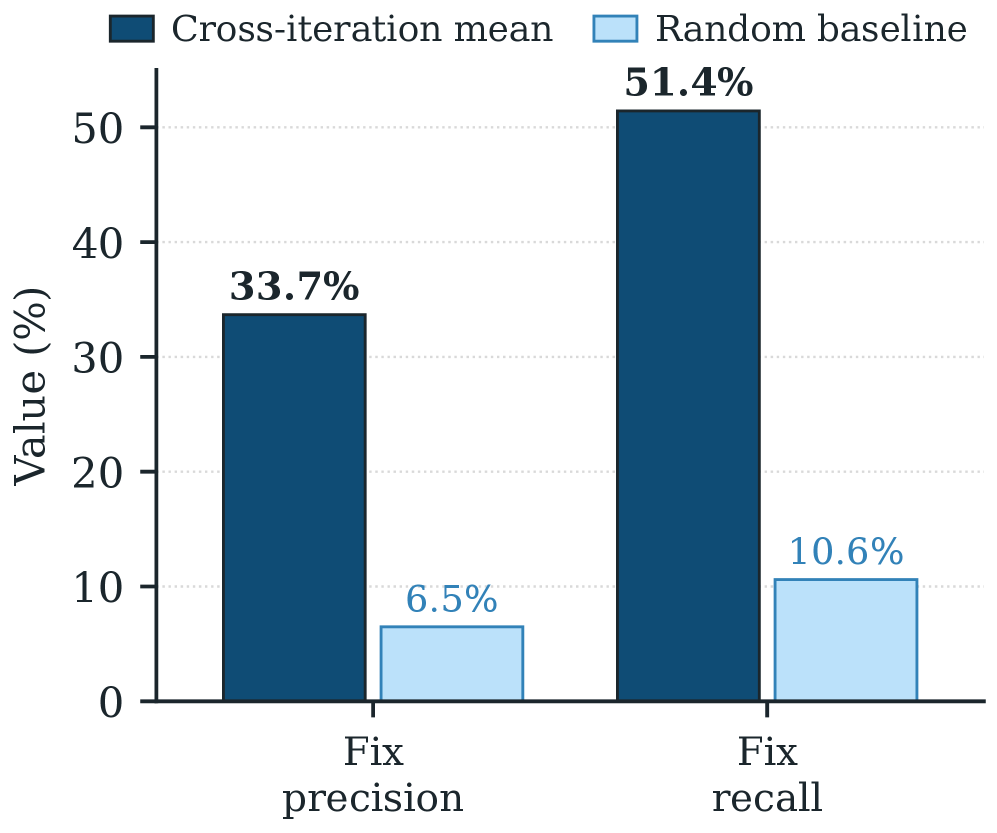
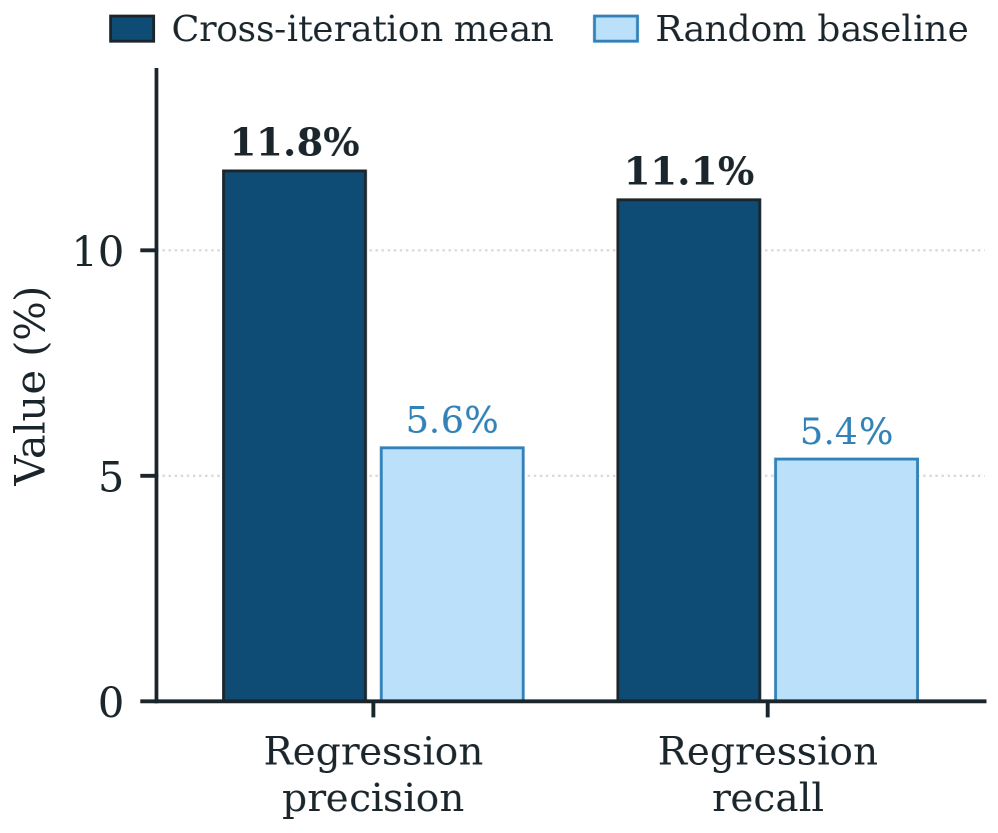
각 진화 라운드에서 Evolve Agent는 다음 라운드에 수정될 것으로 예상하는 태스크와 회귀 위험이 있는 태스크를 명시합니다. 이 예측의 정확도를 평가한 결과, 대조적인 패턴이 드러납니다.
수정 예측: 교차 반복 수정 정밀도 33.7\%, 수정 재현율 51.4\% 로, 랜덤 예측 베이스라인(6.5\% 정밀도, 10.6\% 재현율)의 약 5 배입니다. 각 하네스 편집이 무작위가 아닌 실제 증거에 기반한 목표를 가지고 있음을 보여줍니다.
회귀 예측: 교차 반복 회귀 정밀도 11.8\%, 회귀 재현율 11.1\% 로, 랜덤 베이스라인(5.6\% 정밀도, 5.4\% 재현율)의 약 2 배에 불과합니다. 에이전트는 편집이 왜 도움이 되는지 정당화할 수 있지만, 동일한 편집이 어떤 태스크를 깨뜨릴지는 안정적으로 예측하지 못합니다. 이 회귀 맹목(regression blindness) 이 진화 곡선의 비단조적(non-monotone) 계단을 만들어내며, 이를 개선하는 것이 자기 진화 루프의 가장 명확한 향후 연구 방향입니다.
한계점 및 향후 연구 방향
연구팀은 AHE(Agentic Harness Engineering) 연구의 한계를 솔직하게 제시합니다:
첫째, 현재 평가는 Terminal-Bench 2에 집중되어 있습니다. 이 벤치마크에서의 성능 향상이 다른 코딩 에이전트 환경, 프로그래밍 언어, 배포 환경으로 광범위하게 일반화됨을 보장하지 않습니다.
둘째, AHE는 여러 하네스 구성 요소에 대한 편집을 허용함으로써 에이전트의 적응 표면을 확장합니다. 이 유연성은 유용하지만, 벤치마크 특화 튜닝의 기회도 함께 만들어냅니다. 전이 및 분포 외(OOD) 실험이 이 위험을 직접 측정하도록 설계되었으나, 부정적 결과의 가능성은 열려 있습니다.
셋째, 현재 시스템에는 제한된 편집, 귀속, 롤백 같은 거버넌스 메커니즘이 포함되어 있으나, 완전한 가드레일을 제공하지는 않습니다. 장기 하네스 정리(cleanup)와 오용 방지는 아직 불완전합니다.
넷째, 각 반복이 벤치마크 실행, 궤적 분석, 작업 공간 관리를 필요로 하므로, 일회성 프롬프팅이나 수동 하네스 편집 대비 추가적인 엔지니어링 및 컴퓨트 오버헤드가 발생합니다. 전체 10 회 반복이 약 32 시간이 소요되었으며, 각 반복마다 89 개 태스크에 k=2 롤아웃을 수행하고, Agent Debugger와 Evolve Agent가 추가로 실행됩니다. 이는 소규모 팀이나 제한된 컴퓨트 환경에서는 부담이 될 수 있습니다.
다섯째, 자기 귀속 분석에서 드러난 회귀 맹목(regression blindness) 은 현재 AHE의 가장 뚜렷한 약점입니다. 에이전트는 편집이 왜 도움이 되는지는 잘 예측하지만, 같은 편집이 어떤 태스크를 깨뜨릴지는 거의 예측하지 못합니다. 이로 인해 진화 곡선에 비단조적 하락이 발생하며, 보다 정교한 회귀 예측 메커니즘이 필요합니다.
그럼에도 AHE는 코딩 에이전트 연구에서 중요한 방법론적 전환점을 제시합니다. 기존의 에이전트 최적화가 주로 모델의 가중치(weight)를 업데이트하거나 프롬프트를 개선하는 데 집중했다면, AHE는 모델 외부의 명시적 아티팩트, 즉 도구, 미들웨어, 기억을 학습 가능한 적응 표면(learnable adaptation surface)으로 격상시킵니다.
하네스 편집을 축적하고, 검사하고, 태스크 간 전이할 수 있다면, 코딩 에이전트는 숨겨진 매개변수 업데이트에만 의존하지 않고 명시적 아티팩트로 경험을 외부화할 수 있습니다. 이는 마치 인류의 지식이 개인의 뇌가 아닌 책, 도구, 제도에 축적되어 세대를 넘어 전이되는 것과 유사한 비전입니다. AHE는 테스트 타임 학습(test-time learning)을 더 감사 가능(auditable)하고 과학적으로 연구하기 쉽게 만들 수 있다는 가능성을 보여주는 초기 프레임워크이며, 관측 가능성 기반 진화가 코딩 에이전트 하네스를 지속적으로 개선하는 실용적 경로가 될 수 있음을 시사합니다.
AHE 설치 및 사용 방법
AHE 설치 및 사용을 위해서는 Python 3.13 이상과 uv 패키지 매니저, tmux가 필요합니다.
사전 요구 사항 설치
macOS에서는 다음과 같이 설치할 수 있습니다:
brew install uv tmux
Linux에서는 다음과 같습니다:
curl -LsSf https://astral.sh/uv/install.sh | sh
sudo apt install -y tmux
소스 코드 복제 및 의존성 설치
먼저 소스 코드를 복제하고 의존성을 설치합니다:
git clone https://github.com/Curry09/agentic-harness-engineering.git
cd agentic-harness-engineering
uv sync
환경 변수를 설정합니다:
cp .env.example .env
.env 파일에 최소한 다음 환경 변수를 설정합니다:
| 변수 | 용도 |
|---|---|
LLM_API_KEY / LLM_BASE_URL |
Code Agent와 Evolve Agent가 사용하는 주 LLM 엔드포인트 |
E2B_API_KEY |
E2B 샌드박스 (SaaS 또는 셀프 호스팅) |
GITHUB_TOKEN |
비공개 의존성(NexAU, harbor-LJH) 접근 |
SERPER_API_KEY |
Evolve Agent의 웹 검색 |
ADB_LLM_*과 GPT54_LLM_*은 선택 사항으로, 설정하지 않으면 LLM_* 값을 그대로 사용합니다. Agent Debugger에 더 강력한 모델을 별도로 지정하고 싶을 때 활용할 수 있습니다.
E2B 템플릿 빌드 및 실험 실행
데이터셋별로 E2B 템플릿을 빌드한 후:
uv run python scripts/build_templates.py --dataset-dir /path/to/dataset -j 16
실험을 실행합니다:
./scripts/evolve.sh configs/experiments/exp-003-simple-code-gpt54.yaml
--attach 플래그를 추가하면 로그 스트림에 자동으로 연결됩니다. 중단된 실험을 특정 반복부터 재개하려면 다음과 같이 실행합니다:
./scripts/evolve.sh \
--experiment 2026-04-10__23-20-14__gpt54 \
--start-iteration 16 \
configs/experiments/exp-003-simple-code-gpt54.yaml
--skip-eval 플래그를 사용하면 평가를 건너뛰고 기존 롤아웃을 재사용할 수 있어, Evolve Agent의 디버깅에 유용합니다.
 Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses 논문
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses 논문
 agentic-harness-engineering GitHub 저장소
agentic-harness-engineering GitHub 저장소
관측 가능성 기반 하네스 진화 프레임워크의 공식 구현체입니다. MIT 라이선스로 공개되어 있습니다.
NexAU GitHub 저장소
NexAU는 AHE의 기반이 되는 범용 에이전트 프레임워크로, 도구 기능을 갖춘 지능형 에이전트를 구축할 수 있습니다.
더 읽어보기
-
Meta-Harness: Stanford IRIS Lab이 공개한, LLM 주변 실행 코드를 자동으로 최적화하는 에이전트 하네스 탐색 프레임워크에 대한 연구
-
OpenHarness: Claude Code보다 44배 가벼운 Python 기반 오픈소스 AI 에이전트 하네스 프레임워크 (feat. HKUDS)
-
Browser Harness: LLM이 직접 Chrome을 제어하며 부족한 기능을 스스로 구현하는 자기 치유형 브라우저 자동화 프레임워크
-
Mini-Coding-Agent: AI 코딩 에이전트의 6가지 핵심 구성 요소를 설명하는 최소 구현체 (feat. Sebastian Raschka)
-
Anthropic이 제시하는, 신뢰할 수 있는 AI 에이전트 구축을 위한 실천 원칙: 에이전트의 4가지 구성 요소와 다층 방어 전략 (feat. Anthropic)
-
장시간 자율 코딩을 위한 에이전트 하네스 설계: GAN에서 영감 받은 멀티 에이전트 아키텍처 (feat. Anthropic)
-
DeerFlow v2: 리서치, 코딩, 창작 등의 작업을 위한 오픈소스 SuperAgent Harness (feat. ByteDance)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()