llm.c로 GPT-2(124M)를 90분만에 $20달러로 직접 재현해보기 (feat. 갓파시)
들어가며 

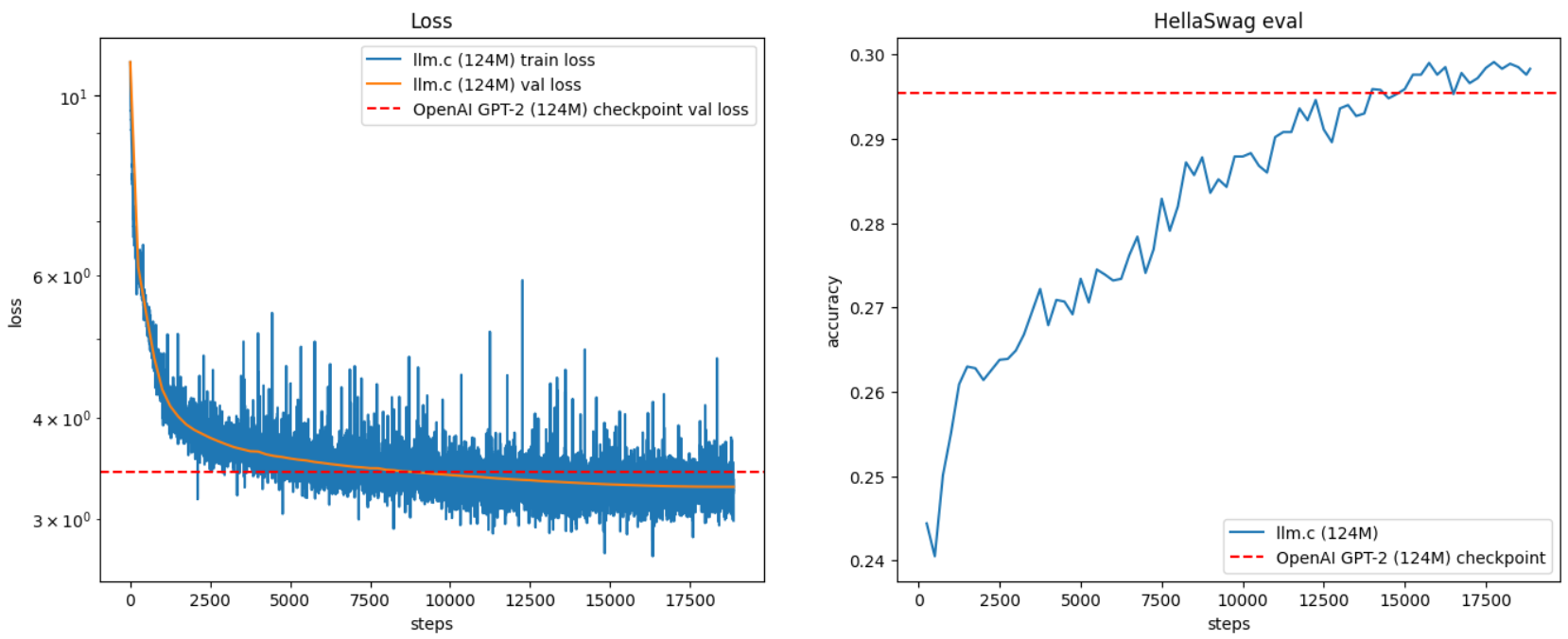
Andrej Karpathy 갓파시 가 지난 달 llm.c를 공개했었는데요, 이번에는 124M 파라매터를 갖는 GPT-2 모델을 llm.c와 람다랩스(lambda labs)에서 제공하는 A100(80GB) x8 SXM 노드를 사용하여 90여분만에 학습을 진행했습니다. 이 SXM 노드는 사용 비용이 시간당 ~$14 가량으로, 90분간 사용하여 약 $20로 전체 GPT-2 모델을 재현했습니다. 어떻게 했는지 함께 살펴보시죠. ![]()
소개
GPT-2(124M)는 OpenAI가 2019년에 공개한 언어 모델 중 하나로, 현재에도 많은 인기를 끌고 있습니다. 이 글에서는 llm.c라는 C/CUDA 기반의 경량화된 코드베이스를 이용해 GPT-2 모델을 재현하는 방법을 설명합니다. llm.c는 약 4,000줄의 코드로 구성되어 있으며, 효율적으로 모델을 훈련시킬 수 있습니다. Lambda Labs에서 제공하는 8X A100 80GB SXM 노드를 이용해 약 90분 동안 훈련시킬 수 있으며, 비용은 약 $20에 불과합니다.
GPT-2(124M) 모델을 재현하기 위해 다양한 방법들이 있습니다. PyTorch와 같은 프레임워크를 이용할 수도 있지만, llm.c는 더욱 경량화되고 최적화된 성능을 자랑합니다. 예를 들어, PyTorch를 이용한 훈련은 더 많은 메모리와 시간이 소요될 수 있습니다. 또한, llm.c는 CUDA 기반의 커널 최적화를 통해 더욱 효율적인 훈련이 가능합니다.
주요 내용
-
경량화된 코드베이스: llm.c는 약 4,000줄의 C/CUDA 코드로 구성되어 있어, 가벼운 실행 환경을 제공합니다.
-
효율적인 모델 플롭스 활용: 최대 60%의 모델 플롭스 활용도로, 빠르고 효율적인 훈련이 가능합니다.
-
저렴한 비용: Lambda Labs의 GPU 노드를 이용해 약 $20의 비용으로 모델을 재현할 수 있습니다.
-
다양한 최적화 옵션: CUDA 및 cuDNN을 이용한 플래시 어텐션, 다중 GPU 지원 등 다양한 최적화 옵션을 제공합니다.
학습 환경 설정
학습을 위해 필요한 환경 설정은 다음과 같습니다:
- Linux x86 64bit Ubuntu 22.04
- CUDA 12
- Miniconda 설치
- PyTorch 및 관련 라이브러리 설치
- cudnn 설치
- MPI 설치(다중 GPU 사용 시)
# install miniconda
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
source ~/.bashrc
# pytorch nightly (optional)
conda install --yes pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch-nightly -c nvidia
# pip installs
yes | pip install tqdm tiktoken requests datasets
# install cudnn
wget https://developer.download.nvidia.com/compute/cudnn/9.1.1/local_installers/cudnn-local-repo-ubuntu2204-9.1.1_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2204-9.1.1_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2204-9.1.1/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn-cuda-12
# "install" cudnn-frontend to ~/
git clone https://github.com/NVIDIA/cudnn-frontend.git
# install MPI (optional, if you intend to use multiple GPUs)
sudo apt install openmpi-bin openmpi-doc libopenmpi-dev
학습 과정
FineWeb 데이터셋의 10억 토큰으로 GPT-2 124M 모델을 학습합니다. 다음은 학습 과정입니다:
- FineWeb 데이터셋을 토크나이징합니다.
- llm.c를 컴파일하고 훈련을 시작합니다.
# tokenize the FineWeb dataset
git clone https://github.com/karpathy/llm.c.git
cd llm.c
python dev/data/fineweb.py --version 10B
# compile llm.c (mixed precision, with cuDNN flash-attention)
make train_gpt2cu USE_CUDNN=1
# train on a single GPU
./train_gpt2cu \
-i "dev/data/fineweb10B/fineweb_train_*.bin" \
-j "dev/data/fineweb10B/fineweb_val_*.bin" \
-o log124M \
-e "d12" \
-b 64 -t 1024 \
-d 524288 \
-r 1 \
-z 1 \
-c 0.1 \
-l 0.0006 \
-q 0.0 \
-u 700 \
-n 5000 \
-v 250 -s 20000 \
-h 1
# if you have multiple GPUs (e.g. 8), simply prepend the mpi command, e.g.:
# mpirun -np 8 ./train_gpt2cu \
# ... (the rest of the args are same)
위 학습 코드를 실행 시 다음과 같이 학습 과정을 출력합니다. 다음 내용은 단일 A100 40GB PCIe GPU($1.29/hr)에서의 학습 예시입니다:
step 80/18865 | train loss 7.577051 | norm 1.1461 | lr 6.86e-05 | 2950.68 ms | 49.0% A100 fp16 MFU | 177968 tok/s
step 81/18865 | train loss 7.540626 | norm 1.4001 | lr 6.94e-05 | 2952.59 ms | 49.0% A100 fp16 MFU | 177948 tok/s
step 82/18865 | train loss 7.465753 | norm 1.0613 | lr 7.03e-05 | 2953.98 ms | 48.9% A100 fp16 MFU | 177924 tok/s
step 83/18865 | train loss 7.472681 | norm 1.1553 | lr 7.11e-05 | 2955.67 ms | 48.9% A100 fp16 MFU | 177897 tok/s
그 외 시각화, 샘플링 등을 포함한 자세한 내용은 Karpathy가 작성한 원문 글을 참고해주세요.
FAQ
-
샘플링 가능 여부: 가능하지만 비효율적입니다.
-
채팅 가능 여부: 현재는 사전 훈련만 가능하며 채팅 미세 조정은 지원되지 않습니다.
-
다중 노드 분산 훈련: 원칙적으로 가능하지만 실제로 시도해보지 않았습니다.
-
비트 단위 결정론적 여부: 거의 결정론적이지만, 한 커널이 패치되어야 합니다.
-
fp8 훈련 가능 여부: 현재 bf16으로 훈련 중이며, 곧 fp8 지원 예정입니다.
-
비 NVIDIA GPU 지원 여부: llm.c는 C/CUDA만 지원합니다.
-
CPU에서의 훈련 가능 여부: GPT-2 모델을 재현할 수는 없지만, 다른 데이터에 대한 OpenAI GPT-2 모델의 미세 조정 프로젝트를 수행할 수 있습니다.
-
PyTorch와의 비교: llm.c는 C/CUDA 구현입니다. PyTorch 코드는 참조용으로 제공되며 모든 기능을 갖추지는 않습니다.
이후 계획
다음 목표는 740M 및 1558M 모델입니다. 1558M 모델의 경우 1주일 동안 약 $2.5K의 비용이 소요될 것으로 예상됩니다.
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()