llm-from-scratch 소개
대규모 언어 모델(Large Language Model)이 어떻게 작동하는지 알고 싶다는 학습 동기는 매우 흔하지만, 막상 시작하려고 하면 진입 장벽이 만만치 않습니다. Hugging Face의 from_pretrained() 한 줄로 모델을 불러와 본 적은 있어도, 토크나이저, 어텐션, 학습 루프, 샘플링이 어떤 식으로 맞물려 동작하는지를 직접 코드로 써 본 경험은 드뭅니다. Andrej Karpathy의 nanoGPT(![]()
![]() 소개 글)가 GPT-2(124M 파라미터)를 수백 줄로 재현하며 이 격차를 좁혔지만, 워크숍 한 세션 동안 끝까지 따라 하기에는 여전히 분량이 적지 않습니다. llm-from-scratch는 이 nanoGPT의 정신을 이어받되, 약 1,000만 파라미터 규모의 모델을 일반 노트북에서 한 시간 안에 학습할 수 있도록 더 가볍게 다듬어진 핸즈온 워크숍입니다.
소개 글)가 GPT-2(124M 파라미터)를 수백 줄로 재현하며 이 격차를 좁혔지만, 워크숍 한 세션 동안 끝까지 따라 하기에는 여전히 분량이 적지 않습니다. llm-from-scratch는 이 nanoGPT의 정신을 이어받되, 약 1,000만 파라미터 규모의 모델을 일반 노트북에서 한 시간 안에 학습할 수 있도록 더 가볍게 다듬어진 핸즈온 워크숍입니다.
이 프로젝트의 핵심 접근법은 "블랙박스 라이브러리를 쓰지 않는다"는 원칙을 끝까지 밀어붙이는 것입니다. model = AutoModel.from_pretrained() 같은 추상화는 사용하지 않고, 토크나이저(Tokenizer)부터 트랜스포머(Transformer) 아키텍처, 학습 루프(Training Loop), 텍스트 생성(Text Generation)까지 모든 컴포넌트를 학습자가 직접 작성합니다. 그 결과물은 셰익스피어 풍의 텍스트를 생성할 수 있는 작은 GPT 모델로, M3 Pro 노트북 기준으로 기본 설정에서 약 45분 안에 학습이 완료되는 분량입니다. Apple Silicon의 MPS, NVIDIA의 CUDA, CPU를 자동으로 감지해 사용하므로 별도의 GPU 환경 구축 없이도 시작할 수 있습니다.
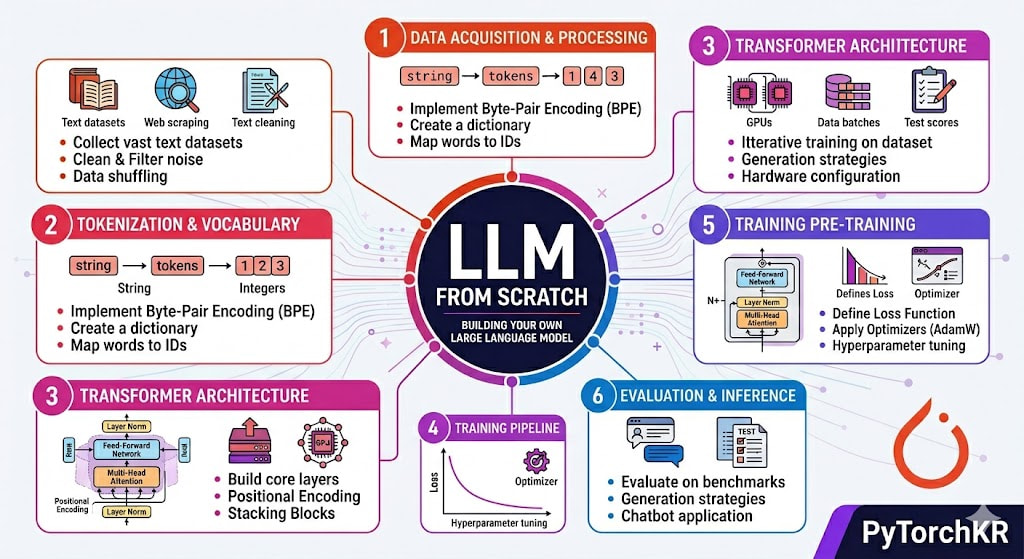
워크숍은 6개 파트로 구성되어 있으며, 각 파트마다 작성해야 할 코드 단위(model.py, train.py, generate.py)와 다루는 개념이 명확히 구분됩니다. 캐릭터 단위 토큰화의 동기와 BPE를 사용하지 않는 이유 같은 의도적 선택까지 함께 설명되어, 독자가 단순히 따라 치는 것을 넘어 "왜 이 결정을 내렸는가"를 이해할 수 있도록 구성되어 있습니다.
llm-from-scratch의 학습 커리큘럼
워크숍은 한 번에 끝까지 읽기보다는 순서대로 한 파트씩 따라가도록 설계되어 있습니다. 각 파트는 작성해야 할 코드와 함께 그 코드가 의미하는 개념을 함께 설명하므로, 마지막까지 마치면 직접 작성한 model.py, train.py, generate.py가 손에 남습니다.
| 파트 | 작성할 코드 | 핵심 개념 |
|---|---|---|
| Part 1: Tokenization | 캐릭터 단위 토크나이저 | 캐릭터 인코딩, 어휘 크기, 작은 데이터에서 BPE가 실패하는 이유 |
| Part 2: The Transformer | 전체 GPT 모델 아키텍처 | 임베딩, 셀프 어텐션, LayerNorm, MLP 블록 |
| Part 3: The Training Loop | 학습 파이프라인 전체 | 손실 함수, AdamW, 그래디언트 클리핑, 학습률 스케줄링 |
| Part 4: Text Generation | 추론과 샘플링 | Temperature, Top-k, 자기회귀적 디코딩 |
| Part 5: Putting It All Together | 실제 데이터 학습과 실험 | 손실 곡선, 스케일링 실험, 다음 단계 |
| Part 6: Competition | 최고의 AI 시인 학습 | 데이터셋 선택, 스케일 업, 베스트 결과 제출 |
llm-from-scratch의 GPT 아키텍처 한눈에 보기
워크숍에서 작성하는 모델은 디코더 전용(Decoder-only) GPT 구조를 따릅니다. 입력 텍스트가 토큰 ID로 변환된 뒤 임베딩과 위치 정보가 더해지고, 여러 개의 트랜스포머 블록을 통과한 결과가 어휘 크기만큼의 로짓(logits)으로 사영(projection)됩니다. 각 트랜스포머 블록은 LayerNorm → Self-Attention → 잔차 연결과 LayerNorm → MLP → 잔차 연결의 표준적인 Pre-Norm 구조로 되어 있습니다.
Input Text
│
▼
┌─────────────────┐
│ Tokenizer │ "hello" → [20, 43, 50, 50, 53] (캐릭터 단위)
└────────┬────────┘
▼
┌─────────────────┐
│ Token Embed + │ 토큰 ID → 벡터 (n_embd 차원)
│ Position Embed │ + 위치 정보
└────────┬────────┘
▼
┌─────────────────┐
│ Transformer │ × n_layer
│ Block: │
│ ┌────────────┐ │
│ │ LayerNorm │ │
│ │ Self-Attn │ │ n_head 개의 병렬 어텐션 헤드
│ │ + Residual │ │
│ ├────────────┤ │
│ │ LayerNorm │ │
│ │ MLP (FFN) │ │ 4배 확장, GELU, 다시 사영
│ │ + Residual │ │
│ └────────────┘ │
└────────┬────────┘
▼
┌─────────────────┐
│ LayerNorm │
│ Linear → logits│ vocab_size 출력 (다음 토큰 확률)
└─────────────────┘
워크숍의 PyTorch 의사 코드(pseudo-code)로 표현하면 트랜스포머 블록 한 개의 forward는 다음과 같이 단순하게 표현됩니다.
class TransformerBlock(nn.Module):
def __init__(self, n_embd, n_head):
super().__init__()
self.ln1 = nn.LayerNorm(n_embd)
self.attn = CausalSelfAttention(n_embd, n_head)
self.ln2 = nn.LayerNorm(n_embd)
self.mlp = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.GELU(),
nn.Linear(4 * n_embd, n_embd),
)
def forward(self, x):
x = x + self.attn(self.ln1(x)) # Pre-Norm + 잔차 연결
x = x + self.mlp(self.ln2(x)) # Pre-Norm + 잔차 연결
return x
llm-from-scratch의 모델 설정과 학습 시간
워크숍은 학습 환경에 따라 세 가지 모델 크기를 제공합니다. 가장 작은 Tiny 설정은 5분, 중간인 Small은 20분, 기본값인 Medium은 약 45분(M3 Pro 기준)이면 학습이 끝납니다. 모든 설정은 캐릭터 단위 토큰화(어휘 크기 65)와 블록 길이 256을 공유하므로, 같은 데이터로 모델 크기에 따른 학습 곡선과 생성 품질을 직접 비교할 수 있습니다.
| Config | 파라미터 | n_layer | n_head | n_embd | 학습 시간 (M3 Pro) |
|---|---|---|---|---|---|
| Tiny | ~0.5M | 2 | 2 | 128 | ~5분 |
| Small | ~4M | 4 | 4 | 256 | ~20분 |
| Medium (기본) | ~10M | 6 | 6 | 384 | ~45분 |
llm-from-scratch의 토큰화 선택: 캐릭터 vs BPE
워크숍이 캐릭터 단위 토큰화를 채택한 이유는 데이터 규모와 직접적으로 관련됩니다. 셰익스피어 데이터셋은 약 1MB로 매우 작아서, GPT-2가 사용하는 BPE 어휘(50,257개)를 그대로 적용하면 대부분의 토큰 바이그램이 너무 희소하게 등장해 모델이 패턴을 학습할 수 없게 됩니다. 반대로 캐릭터 단위는 어휘 크기가 약 65로 매우 작아 작은 데이터에서도 모델이 의미 있는 표현을 학습할 수 있습니다.
| 토크나이저 | 어휘 크기 | 적합한 데이터 규모 |
|---|---|---|
| 캐릭터 단위 | ~65 | 작음 (셰익스피어, ~1MB) |
| BPE (tiktoken) | 50,257 | 큼 (TinyStories+, 100MB+) |
Part 5에서는 더 큰 데이터셋을 다루기 위해 BPE로 전환하는 방법까지 함께 설명되므로, 워크숍을 마친 뒤에는 자연스럽게 더 실전에 가까운 학습 환경으로 확장할 수 있습니다.
llm-from-scratch 시작하기
설치는 uv를 활용해 매우 단순화되어 있습니다. Python 3.12 이상과 PyTorch만 있으면 어떤 OS에서도 동작합니다.
# uv 설치 (macOS / Linux)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 프로젝트 셋업
uv sync
mkdir scratchpad && cd scratchpad
로컬 환경이 없다면 Google Colab에서 진행할 수 있습니다.
!pip install torch numpy tqdm tiktoken
# data/shakespeare.txt를 Colab에 업로드한 뒤
# 노트북 셀에서 코드를 작성하거나 .py 파일을 업로드하여 실행
!python train.py
 llm-from-scratch 프로젝트 GitHub 저장소
llm-from-scratch 프로젝트 GitHub 저장소
더 읽어보기
-
SpreadSheet is All You Need: 스프레드시트(또는 엑셀)로 이해하는 nanoGPT의 동작 원리
-
LLM Internals: 토크나이저부터 Flash Attention까지, LLM 내부 구조를 단계별로 학습하는 오픈소스 교육 자료
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()