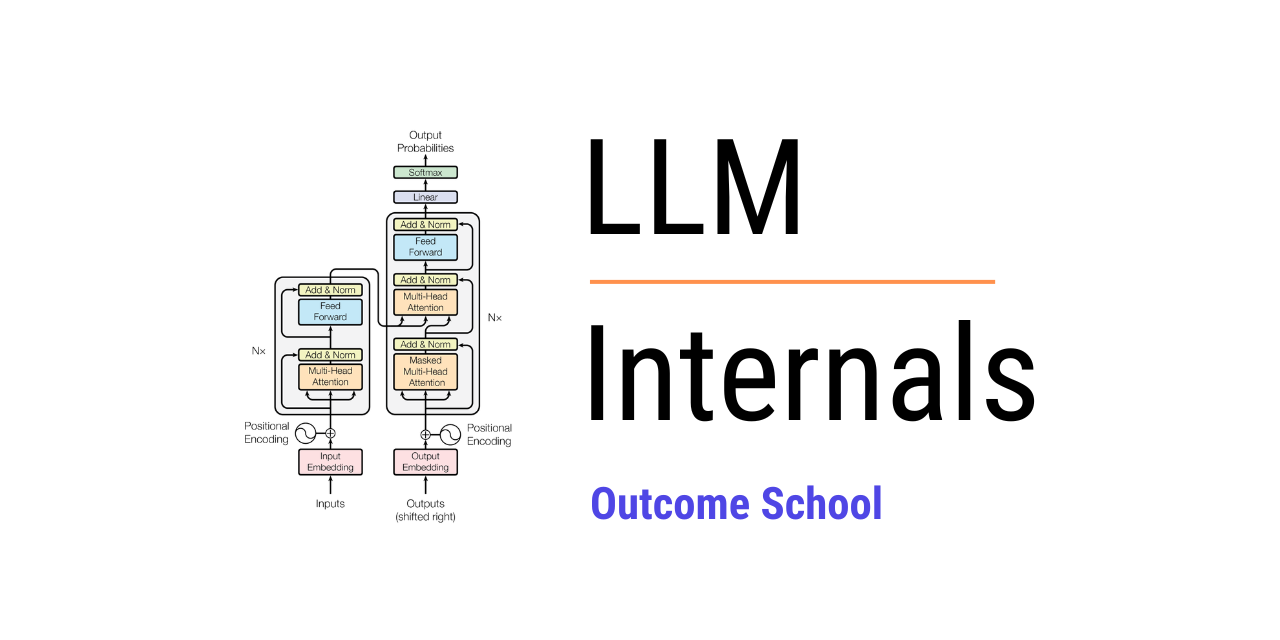
LLM Internals 소개
대규모 언어 모델(Large Language Model, LLM)의 놀라운 성능 뒤에는 수십 가지의 복잡한 기술들이 맞물려 작동하고 있습니다. 단순히 모델을 사용하는 것을 넘어 그 작동 원리를 깊이 이해하고자 하는 개발자와 연구자들에게, 어디서부터 어떻게 공부해야 할지 막막한 경우가 많습니다. LLM Internals는 이 문제를 해결하기 위해 만들어진 오픈소스 교육 리소스로, Outcome School의 창립자인 Amit Shekhar가 제작하고 관리하고 있습니다. 토크나이저(Tokenizer)부터 시작해 어텐션 메커니즘(Attention Mechanism), 트랜스포머 아키텍처, 추론 최적화에 이르기까지 LLM의 핵심 개념들을 단계별로 체계화하여 제공하며, 블로그 포스트와 YouTube 영상을 함께 활용하여 수식과 코드를 시각적으로 이해할 수 있도록 설계되었습니다.
LLM Internals 프로젝트가 주목받는 이유는 단순한 개념 나열이 아닌, 실제 수치 예시를 통한 수학적 원리의 단계적 설명에 있습니다. 예를 들어, 쿼리(Query)·키(Key)·값(Value)의 행렬 곱 연산이 왜 스케일링 인수 \frac{1}{\sqrt{d_k}} 를 필요로 하는지, 역전파(Backpropagation)에서 연쇄 법칙(Chain Rule)이 어떻게 적용되는지를 숫자를 직접 대입하여 보여줍니다. 또한 "이 시리즈는 계속 성장할 것"이라고 명시하고 있어, LLM 기술의 발전에 맞춰 새로운 주제가 꾸준히 추가될 것으로 기대를 모으고 있습니다.
LLM Internals의 학습 경로 및 자료 형식
LLM Internals는 기초 개념부터 고급 최적화 기법까지 순차적으로 학습할 수 있도록 구성되어 있습니다. 각 주제는 독립적이면서도 이전 개념을 바탕으로 쌓아 올리는 방식으로 설계되었습니다.
LLM Internals의 모든 콘텐츠는 Outcome School 웹사이트의 블로그 포스트와 YouTube 영상으로 제공됩니다. 각 주제는 텍스트로 된 수학적 설명과 시각적인 영상 설명을 함께 제공하여, 독자의 학습 스타일에 맞는 방식으로 접근할 수 있습니다. 특히 수식을 단순히 나열하는 것이 아니라 실제 숫자를 대입한 예시를 통해 계산 과정을 따라갈 수 있도록 설계되어 있습니다.
인공지능 엔지니어링 및 토큰화 기초
LLM을 이해하기 위한 가장 첫 번째 관문은 모델이 텍스트 데이터를 어떻게 입력받고 처리하는지 아는 것입니다. 컴퓨터는 텍스트를 그대로 이해할 수 없으므로, 이를 숫자로 변환하는 과정이 필수적입니다.
인공지능 엔지니어링 전반의 이해
현대의 AI 애플리케이션은 단순히 모델을 호출하는 것을 넘어 복잡한 파이프라인으로 구성됩니다. 원문에서는 대형 언어 모델(LLM)의 기본 개념부터 시작하여, 외부 지식을 검색해 답변의 정확도를 높이는 RAG(Retrieval-Augmented Generation), 모델이 다양한 도구를 사용할 수 있게 해주는 MCP(Model Context Protocol), 자율적으로 작업을 수행하는 AI 에이전트(Agent), 특정 도메인에 맞게 모델을 훈련하는 미세 조정(Fine-tuning), 그리고 모델의 가중치 정밀도를 낮춰 크기와 연산량을 줄이는 양자화(Quantization) 기법까지 AI 엔지니어링의 핵심 요소들을 포괄적으로 소개합니다.

토큰화(Tokenization)와 Byte Pair Encoding (BPE)
LLM은 문장이나 단어 전체를 한 번에 처리하지 않고, '토큰(Token)'이라는 더 작은 단위로 쪼개어 처리합니다. 토큰화는 언어 모델이 텍스트의 패턴을 학습할 수 있게 하는 가장 기본적인 단계입니다.
")
특히 현대 LLM에서 가장 널리 사용되는 알고리즘인 **Byte Pair Encoding (BPE)**은 데이터 압축 기법에서 유래했습니다. BPE는 문자 단위에서 시작하여 가장 자주 등장하는 글자 쌍(Pair)을 하나의 새로운 토큰으로 병합(Merge)해 나가는 방식을 취합니다. 이 방식을 사용하면 자주 쓰이는 단어는 하나의 통째 토큰으로, 처음 보는 희귀한 단어(Out-of-vocabulary)는 여러 개의 의미 있는 하위 토큰(Subword)으로 쪼개어 처리할 수 있어 모델의 어휘집(Vocabulary) 크기를 효율적으로 관리할 수 있습니다.
어텐션(Attention) 메커니즘과 수학적 이해
트랜스포머(Transformer) 아키텍처가 기존의 RNN을 밀어내고 표준이 될 수 있었던 이유는 문장 내 단어들 사이의 관계를 병렬로 계산하는 '어텐션 메커니즘' 덕분입니다.
어텐션의 수학적 원리 (Q, K, V)
어텐션 메커니즘은 본질적으로 정보 검색 시스템과 유사합니다. 입력된 각 단어는 세 가지 벡터, 즉 쿼리(Query, 찾고자 하는 정보), 키(Key, 내가 가지고 있는 정보의 특징), 값(Value, 실제 담고 있는 의미)으로 변환됩니다. 어텐션 점수는 쿼리 행렬(Q) 과 키 행렬(K) 을 전치하여 내적(Q \times K^T) 함으로써 계산됩니다. 이 내적 값이 클수록 두 단어 사이의 연관성이 높다는 것을 의미하며, 이후 Softmax 함수를 통과하여 확률 값으로 변환된 뒤 값 행렬(V)과 곱해져 최종 문맥을 반영한 단어 벡터가 출력됩니다.
스케일링 팩터 (\sqrt{d_k}) 의 비밀
어텐션 수식을 보면 내적 값을 키 벡터의 차원 수의 제곱근인 \sqrt{d_k} 로 나누는 과정이 있습니다. 차원 수(d_k) 가 커질수록 두 벡터를 내적한 결과값의 분산(Variance) 역시 d_k 만큼 커지게 됩니다. 내적 값이 비정상적으로 커지면 Softmax 함수가 극단적인 값(0 또는 1에 수렴)을 반환하게 되어, 신경망 학습 시 기울기 소실(Gradient Vanishing) 문제가 발생합니다. 따라서 분산을 1로 맞추고 학습을 안정화하기 위해 \sqrt{d_k} 로 스케일링을 수행하는 것입니다.
인과적 마스킹 (Causal Masking)
문장을 생성할 때 모델은 오직 과거와 현재의 단어만 보고 다음 단어를 예측해야 합니다. 미래의 토큰을 미리 '커닝'하는 것을 막기 위해, 어텐션 스코어 행렬의 대각선 위쪽(미래 시점) 값을 음의 무한대(-\infty)로 덮어씌우는 마스킹 행렬을 적용합니다. 이렇게 하면 Softmax를 통과할 때 해당 값들이 0이 되어 미래 토큰에 대한 어텐션 가중치가 완전히 차단됩니다.
트랜스포머 아키텍처와 신경망 학습
단일 어텐션 레이어들이 모여 거대한 언어 모델을 구성하며, 이 모델이 정답을 맞히도록 학습시키는 과정에는 깊은 수학적 원리가 숨어있습니다.
역전파(Backpropagation)의 수학적 이해
신경망이 예측한 값과 실제 정답 사이의 오차(Loss)를 줄이기 위해, 출력층에서부터 입력층 방향으로 오차를 역으로 전파하며 가중치를 업데이트하는 과정이 역전파입니다. 이는 미적분학의 연쇄 법칙(Chain Rule)에 기반합니다. 원문에서는 순전파(Forward pass)로 손실을 계산하고, 기울기를 구해 경사 하강법(Gradient descent)으로 가중치를 수정하는 과정을 숫자를 대입한 예제와 파이썬 코드를 통해 직관적으로 설명합니다.
트랜스포머 아키텍처 해부 및 피드포워드 신경망 (FFN)
트랜스포머는 문맥을 이해하는 인코더(Encoder)와 텍스트를 생성하는 디코더(Decoder)로 나뉩니다. 위치 정보를 주입하는 Positional Encoding, 여러 관점에서 문맥을 파악하는 Multi-Head Attention, 그리고 학습을 돕는 잔차 연결(Residual Connections)과 레이어 정규화(Layer Normalization)가 유기적으로 결합되어 있습니다.
특히, 어텐션 연산 직후에 위치하는 피드포워드 신경망(Feed-Forward Networks) 은 모델 전체 파라미터의 상당 부분을 차지합니다. FFN은 입력 벡터의 차원을 크게 확장(Expand)하여 비선형 활성화 함수(ReLU 등)를 통해 복잡한 특징을 학습한 뒤, 다시 원래 차원으로 축소(Contract)하는 병목 구조를 가집니다. 이는 모델이 단순한 패턴 매칭을 넘어 추상적인 개념을 깊이 있게 이해할 수 있도록 돕습니다.
추론 최적화 및 최신 LLM 기술
모델의 크기가 수십억, 수천억 개의 파라미터로 커지면서, 실제 서비스 시 사용자에게 빠르게 답변을 제공하기 위한 엔지니어링 최적화가 필수 기술이 되었습니다.
KV Cache와 Paged Attention
LLM은 텍스트를 한 번에 한 토큰씩 생성(Auto-regressive)합니다. 다음 토큰을 생성할 때마다 이전까지 생성된 모든 토큰의 어텐션을 다시 계산하는 것은 엄청난 연산 낭비입니다. 이를 해결하기 위해 이전 토큰들의 Key와 Value 연산 결과를 GPU 메모리에 미리 저장해두고 재사용하는 것이 KV Cache입니다. (Query는 현재 시점의 단어에 대해서만 필요하므로 캐싱하지 않습니다.)
하지만 전통적인 KV Cache는 메모리를 미리 큰 덩어리로 할당하기 때문에 메모리 파편화와 심각한 공간 낭비를 초래합니다. 이를 해결하기 위해 운영체제의 가상 메모리 페이징(Paging) 기법에서 영감을 받은 Paged Attention이 등장했습니다. 캐시 메모리를 작은 블록(Page) 단위로 나누어 동적으로 할당함으로써 메모리 낭비를 없애고, 하나의 서버가 동시에 처리할 수 있는 사용자 수를 비약적으로 늘렸습니다.
Flash Attention과 전문가 혼합 (Mixture of Experts, MoE)
어텐션 연산은 행렬 크기가 커질수록 느려지는데, 주된 병목 원인은 GPU의 연산 능력이 아니라, 느린 HBM(고대역폭 메모리)과 빠른 SRAM 사이에서 데이터를 주고받는 데 걸리는 시간입니다. Flash Attention은 행렬을 작은 타일(Tiling)로 쪼개어 SRAM 내에서 Softmax 계산(Online Softmax)을 끝냄으로써 메모리 접근 횟수를 극단적으로 줄인 혁신적인 알고리즘입니다.
또한, 모델의 연산 속도를 유지하면서 성능을 높이는 아키텍처로 **Mixture of Experts (MoE)**가 소개됩니다. 모든 파라미터가 매번 연산에 참여하는 대신, 라우터(Router) 네트워크가 각 토큰의 특성에 가장 잘 맞는 소수의 '전문가(Expert)' 신경망만을 선택적으로 활성화(Sparse activation)하여 속도와 정확도를 동시에 잡는 원리를 상세히 다루고 있습니다.
하네스 엔지니어링 (Harness Engineering in AI)
일반적인 소프트웨어 공학에서 '테스트 하네스(Test Harness)'란 특정 모듈을 자동화된 방식으로 테스트하고 실행하기 위해 뼈대를 잡아주는 코드나 환경을 의미합니다. AI 생태계에서도 이와 마찬가지로, 대형 언어 모델(LLM)을 안전하고 통제된 방식으로 실행하고 평가하기 위해 둘러싸는 프레임워크를 AI 하네스(AI Harness) 라고 부릅니다. 단순히 API를 호출하는 것을 넘어, 모델을 실제 프로덕션 수준의 시스템에 통합하기 위한 필수적인 엔지니어링 기법입니다. 구체적으로는 하네스 엔지니어링이 왜 필요한지, 그리고 구체적으로 어떻게 활용되는지를 설명합니다.
 LLM Internals 프로젝트 GitHub 저장소
LLM Internals 프로젝트 GitHub 저장소
 LLM Internals 공식 홈페이지 (Outcome School)
LLM Internals 공식 홈페이지 (Outcome School)
더 읽어보기
-
Andrej Karpathy, 개발자를 위한 LLM 소개 영상 'ChatGPT와 같은 LLM 심층 분석' 공개 📺 [영어/YouTube/3:31:23]
-
DeepLearning.AI, 트랜스포머 기반 LLM의 동작에 대한 무료 강의 공개 [무료/영어/온라인] (feat. Jay Alammar)
-
Machine Learning from Scratch: Python과 NumPy만을 사용하여 인공신경망과 트랜스포머의 내부 구조를 학습할 수 있는 GitHub 저장소
-
CS146S: AI-native 개발 워크플로우 학습을 목표로 하는 스탠포드 대학교의 2025년 가을학기 강의 - 9bow 님의 게시물 #2
-
머신러닝(ML) 및 그 이상을 위한 행렬 미적분학(Matrix Calculus) 강의 자료 및 강의노트 [PDF/영문/101p]
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()