
Mathematical Foundation of RL 소개
강화학습(Reinforcement Learning, RL)은 AI 및 머신러닝 분야에서 핵심적인 기술입니다. 하지만 수학적 기초 없이 이를 깊이 이해하는 것은 쉽지 않습니다. 최근 강화학습의 수학적 이론과 알고리즘을 체계적으로 학습할 수 있도록 돕는 “Mathematical Foundation of Reinforcement Learning” 도서가 무료로 공개되었습니다.
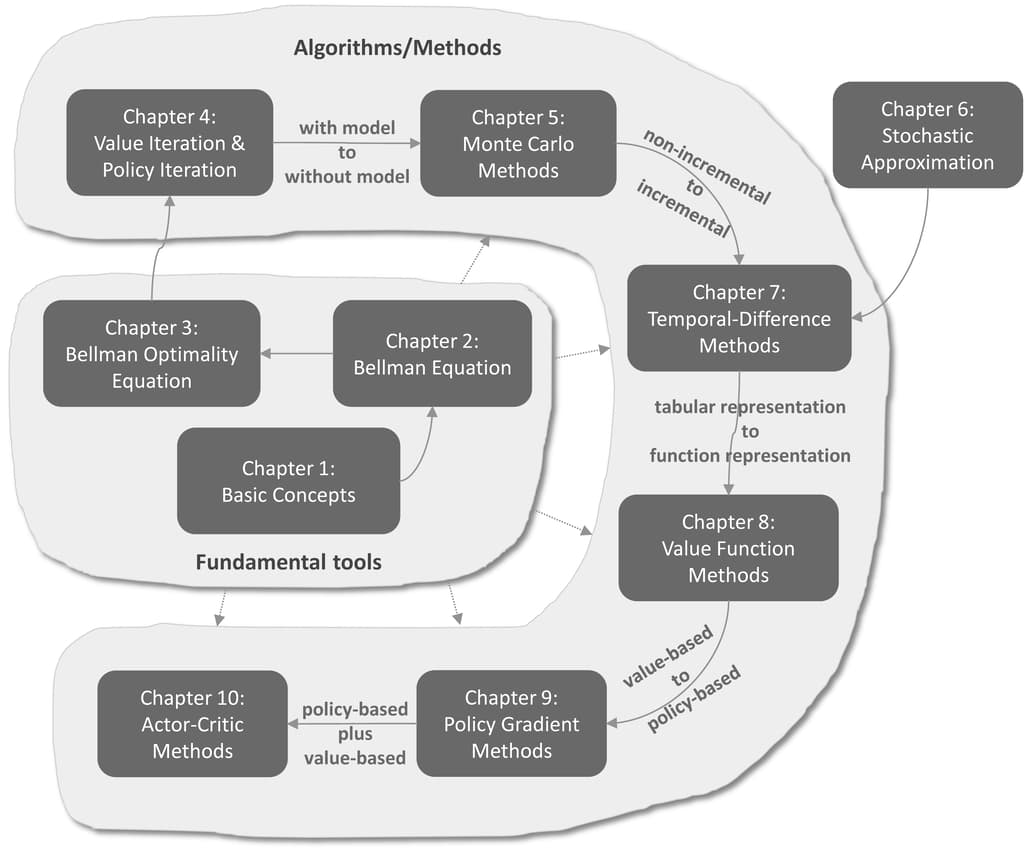
Mathematical Foundation of Reinforcement Learning는 강화학습의 수학적 기초를 다루는 책과 함께 강의 자료, 코드 등을 제공합니다. 주요 내용은 다음과 같습니다:
- 강화학습의 기본 개념: MDP(마르코프 결정 과정), 가치 함수(Value Function) 등 기본적인 개념을 다룹니다.
- 벨만 방정식(Bellman Equation): 강화학습에서 필수적인 가치 평가 방식과 최적화 방정식에 대해 설명합니다.
- 정책 기반 학습(Policy Gradient) 및 액터-크리틱(Actor-Critic) 방법: 최근 딥러닝 기반 RL 알고리즘에서 중요한 기법들을 포함하고 있습니다.
- 그 외, 몬테카를로(Monte Carlo) 방법과 Q-learning 같은 강화학습의 핵심 기법들도 정리되어 있습니다.
이 책의 가장 큰 장점은 이론과 수학적 설명을 통해 강화학습을 보다 깊이 이해할 수 있도록 도와준다는 점입니다. 또한, 예시 코드와 강의 영상, 슬라이드 등을 함께 제공하여 학습을 돕습니다.
Mathematical Foundation of Reinforcement Learning 자료
도서 (PDF / 영문)
아래는 책 내용 전체이며, GitHub 저장소에서 각 챕터별 파일을 다운로드 받을 수 있습니다:
코드 예제
Grid World 환경에서 강화학습을 실험할 수 있는 코드가 GitHub 저장소에 공개되어 있습니다:
강의 자료 및 슬라이드
YouTube에 강의 영상 전체가 공개되어 있습니다. 다음 강의 재생 목록을 참고해주세요:
강의 슬라이드는 GitHub 저장소에서 받을 수 있습니다:
Mathematical Foundation of Reinforcement Learning GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()