
OCR4all 소개
OCR4all은 오픈소스 OCR 솔루션들을 결합하여 자동화된 OCR 워크플로우를 제공하는 솔루션입니다. OCR(광학 문자 인식) 기술은 역사적 문서의 디지털화, 필기체 인식, 대량의 인쇄물 처리 등 다양한 분야에서 필수적입니다. OCR4all은 이러한 작업을 간편하게 수행할 수 있도록 돕는 완전 무료, 오픈소스 OCR 솔루션입니다. 복잡한 코딩 없이도 UI 기반으로 OCR 작업을 진행할 수 있으며, Docker 기반 설치로 운영체제에 구애받지 않고 실행할 수 있습니다.
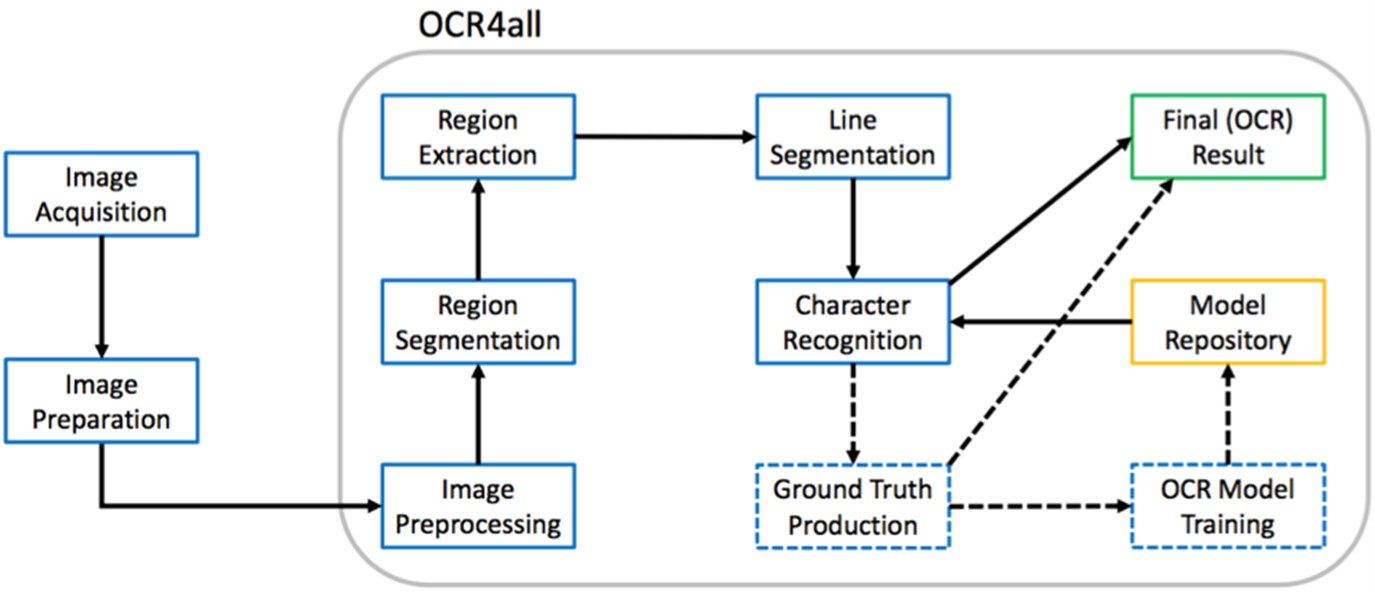
또한, OCR4all은 16세기~18세기 독일어권 인쇄물의 대량 디지털화 프로젝트인 OCR-D 프로젝트에도 활용되고 있습니다. 특히, Docker 기반 배포로 어떤 운영체제에서도 손쉽게 실행할 수 있으며, 프로그래밍 지식이 없는 사용자도 쉽게 사용할 수 있도록 직관적인 UI를 제공합니다.
OCR4all의 주요 특징은 다음과 같습니다:
- 완전 무료 & 오픈소스: 구독료 없음, 모든 기능이 공개
- 강력한 레이아웃 및 텍스트 주석 기능: LAREX 편집기 포함
- OCR-D 호환: **독일어권 고문헌 디지털화 프로젝트(OCR-D)**와 연동
- UI 기반 OCR 워크플로우 구성: 코드나 터미널 명령 없이 사용 가능
- 크로스플랫폼 지원: Docker 기반 배포로 Windows, macOS, Linux에서 실행 가능
OCR4all은 Tesseract OCR처럼 무료지만 UI 없이 CLI로만 동작하는 솔루션과 달리, 직관적인 UI 기반 워크플로우를 제공합니다. Google Cloud Vision이나 ABBYY FineReader 같은 유료 OCR 솔루션과 비교해도 필기체 인식 및 OCR 모델 학습 기능이 포함되어 있어 강력한 기능을 제공합니다. 다음은 OCR4all과 기존 OCR 솔루션들을 비교한 표입니다:
| 기능 | OCR4all | Tesseract OCR | Google Cloud Vision | ABBYY FineReader |
|---|---|---|---|---|
| 가격 | 무료 | 무료 | 유료 | 유료 |
| 오픈소스 여부 | ||||
| UI 지원 | ||||
| 필기체 인식 | ||||
| OCR 모델 학습 | ||||
| 대량 인쇄물 처리 최적화 |
OCR4all의 핵심 기능, OCR Workflow
OCR4all은 자동화된 OCR 처리 파이프라인을 제공합니다.

- 이미지 전처리 (이미지 보정, 대비 조절 등)
- 레이아웃 세분화 (LAREX 사용)
- 라인 세분화
- 텍스트 인식 (Calamari OCR 사용)
- 오류 수정 및 정답 데이터(Ground Truth) 생성
- OCR 모델 학습 및 최적화
라이선스
OCR4all은 MIT License로 배포됩니다.
 OCR4all 홈페이지
OCR4all 홈페이지
 OCR4all 논문
OCR4all 논문
https://www.mdpi.com/2076-3417/9/22/4853
 OCR4all GitHub 저장소
OCR4all GitHub 저장소
https://github.com/OCR4all/OCR4all
더 읽어보기
-
MinerU, PDF를 JSON/Markdown 변환 및 OCR 등을 지원하는 데이터 추출 도구 (feat. 한국어 지원)
-
NVIDIA-Ingest: PDF, Word, Powerpoint 등으로부터 텍스트, 이미지, 표 등을 추출하는 마이크로서비스
-
MarkItDown, Microsoft가 공개한 PDF, 이미지 및 오피스 문서 👉 Markdown 변환 도구
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()