
OCRmyPDF 소개
종이 문서를 스캐너로 넘긴 PDF는 겉보기에는 멀쩡하지만, 내용이 전부 이미지로 저장되어 있어 본문을 검색하거나 복사할 수 없습니다. OCRmyPDF는 이런 스캔 PDF에 OCR(광학 문자 인식) 텍스트 레이어를 덧입혀, 원본 이미지는 그대로 두면서도 그 아래에 인식된 글자를 배치합니다. 결과물은 뷰어에서 단어를 검색하고 드래그해 복사할 수 있는 PDF가 됩니다.
OCRmyPDF는 문자 인식 자체를 직접 수행하지 않고 Tesseract OCR 엔진을 호출해 100개가 넘는 언어를 처리합니다. 인식한 텍스트를 이미지 위가 아니라 정확히 아래층에 배치하기 때문에 화면에 보이는 문서 모양은 원본과 동일하게 유지되고, 복사·붙여넣기를 해도 글자가 어긋나지 않습니다. 기본 출력 형식은 장기 보관용 표준인 PDF/A이며, 이는 시간이 지나도 문서가 동일하게 재현되도록 설계된 포맷입니다.
![]()
OCRmyPDF 프로젝트는 스크립트로 자동화하기 좋은 명령줄 도구로 만들어졌습니다. 여러 CPU 코어에 작업을 분산하고, 기울어진 페이지를 바로잡고, 처리 과정에서 이미지를 최적화해 원본보다 작은 파일을 만들기도 합니다. 개발자는 기존의 무료 OCR 도구들이 텍스트를 이미지와 어긋난 위치에 넣거나, 다국어·악센트 문자를 제대로 다루지 못하거나, 이미지 해상도를 바꾸거나, 지나치게 큰 파일을 만들거나, 유효하지 않은 PDF를 생성하는 문제가 있어 직접 도구를 만들었다고 밝히고 있습니다.
OCRmyPDF의 핵심 기능
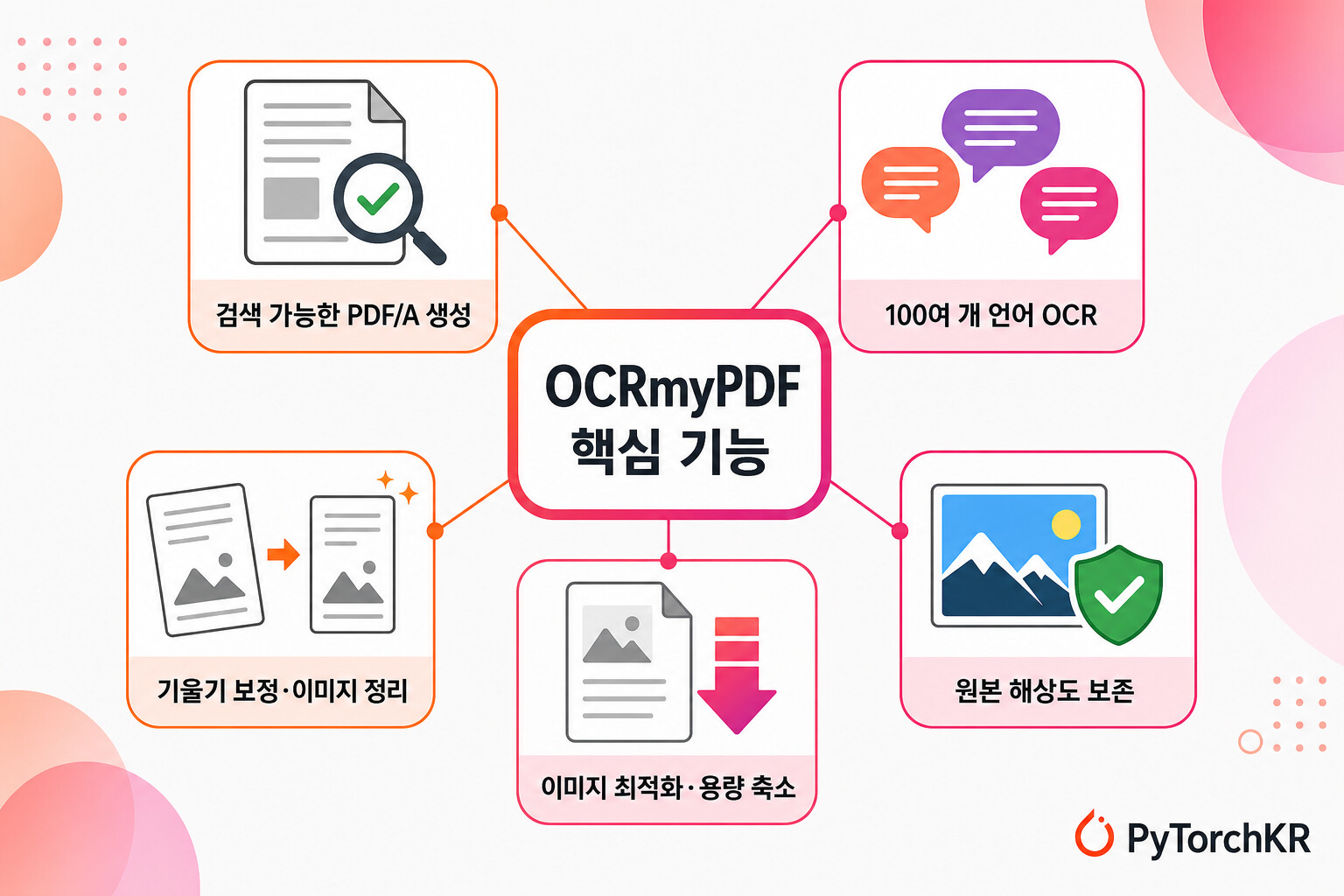
OCRmyPDF가 제공하는 주요 기능은 다음과 같습니다. 각 항목은 단순한 문자 인식을 넘어 스캔 문서를 실무에서 쓸 수 있는 형태로 다듬는 데 초점이 맞춰져 있습니다.
- 검색 가능한 PDF/A 생성: 일반 PDF에서 검색 가능한 PDF/A 파일을 만들고, OCR 텍스트를 이미지 바로 아래에 정확히 배치해 복사·붙여넣기를 쉽게 합니다.
- 원본 보존과 무손실 삽입: 원본에 포함된 이미지의 해상도를 그대로 유지하며, 가능한 경우 다른 내용을 건드리지 않는 무손실 방식으로 OCR 정보를 삽입합니다.
- 이미지 최적화: PDF 내부 이미지를 최적화해 입력 파일보다 더 작은 결과물을 만들기도 합니다.
- 전처리 옵션: 요청 시 OCR 이전에 기울기를 보정(deskew)하거나 이미지를 정리합니다.
- 검증과 확장성: 입력과 출력 파일의 유효성을 검사하고, 사용 가능한 모든 CPU 코어에 작업을 분산하며, 수천 페이지 규모의 파일도 처리하도록 설계되었습니다.
문서를 로컬에서 처리하므로 사적인 데이터가 외부로 나가지 않는다는 점도 저자가 강조하는 특징입니다.
OCRmyPDF의 설치 방법
OCRmyPDF는 순수 Python으로 작성되었지만, 문자 인식을 위한 Tesseract OCR과 PDF 처리를 위한 Ghostscript를 외부 프로그램으로 함께 요구합니다. Linux, macOS, Windows, FreeBSD를 지원하며 x64와 ARM용 Docker 이미지도 제공됩니다. 주요 배포판에서는 패키지 관리자로 바로 설치할 수 있습니다.
# Debian, Ubuntu
apt install ocrmypdf
# Fedora
dnf install ocrmypdf
# macOS (Homebrew)
brew install ocrmypdf
문자 인식은 Tesseract의 언어 팩에 의존합니다. 예를 들어 Debian·Ubuntu에서 특정 언어 팩을 설치한 뒤, -l 옵션으로 인식할 언어를 지정합니다. OCRmyPDF는 Tesseract 4.1.1 이상을 지원하며 PATH에서 먼저 발견되는 버전을 자동으로 사용합니다.
# Tesseract 언어 팩 설치 예시 (중국어 간체)
apt-get install tesseract-ocr-chi-sim
OCRmyPDF의 사용법
가장 기본적인 사용법은 입력 PDF와 출력 PDF를 인자로 넘기는 것입니다. 명령줄 도구인 만큼 언어 지정, 기울기 보정, 다국어 문서 처리 등을 옵션 조합으로 제어합니다. 다음은 저장소가 제시하는 사용 예시입니다.
# OCR 레이어를 추가하고 PDF/A로 출력
ocrmypdf --output-type pdfa input.pdf output.pdf
# 이미지를 단일 페이지 PDF로 변환
ocrmypdf input.jpg output.pdf
# 영어가 아닌 언어로 OCR (ISO 639-3 코드 사용)
ocrmypdf -l fra LeParisien.pdf LeParisien.pdf
# 여러 언어가 섞인 문서 OCR
ocrmypdf -l eng+fra Bilingual-English-French.pdf Bilingual-English-French.pdf
# 기울어진 페이지 바로잡기
ocrmypdf --deskew input.pdf output.pdf
여러 옵션은 한 번에 조합할 수 있습니다. 예를 들어 인식 언어를 지정하고(-l eng+fra), 기울어진 페이지를 바로잡고(--rotate-pages, --deskew), 여러 코어로 병렬 처리하고(--jobs 4), 출력 형식을 PDF/A로(--output-type pdfa) 두는 식입니다. 전체 옵션은 ocrmypdf --help로 확인하거나 문서 사이트에서 볼 수 있습니다.
OCRmyPDF의 플러그인과 확장
OCRmyPDF는 기능을 확장하거나 대체할 수 있는 플러그인 인터페이스를 제공합니다. 기본 엔진인 Tesseract를 다른 OCR 엔진으로 교체하는 플러그인들이 대표적입니다. 이 가운데 OCRmyPDF-EasyOCR은 표준 Tesseract 엔진을 EasyOCR로 바꾸는데, 저자는 EasyOCR을 PyTorch 기반의 비교적 최신 OCR 엔진이라고 설명하며 GPU 사용을 강하게 권장합니다.
이 외에도 macOS의 Apple Vision Framework를 사용하는 OCRmyPDF-AppleOCR, GPU 가속 엔진인 PaddleOCR로 교체하는 OCRmyPDF-PaddleOCR이 있습니다. 문서 관리 시스템인 paperless-ngx는 OCRmyPDF를 통합해 검색 가능한 문서 저장소를 구성합니다.
OCRmyPDF의 라이선스
OCRmyPDF 소프트웨어는 Mozilla Public License 2.0 (MPL-2.0)로 공개되어 있습니다. 이 라이선스는 상업용·비공개 코드를 포함한 다른 코드와의 통합을 허용하되, OCRmyPDF 자체에 가한 소스 수준의 수정은 공개하도록 요구합니다. 저장소 안내에 따르면 일부 비핵심 코드는 MIT로, 문서와 테스트 파일은 Creative Commons ShareAlike 4.0 (CC-BY-SA 4.0)으로 배포됩니다.
 OCRmyPDF 문서 사이트
OCRmyPDF 문서 사이트
 OCRmyPDF 프로젝트 GitHub 저장소
OCRmyPDF 프로젝트 GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! 텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다.
로 보내드립니다! 텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()