
GPT-5.4 출시 소개
2026년 3월 5일, OpenAI는 복잡한 전문가용 워크플로우를 위해 설계된 최신 프런티어 모델인 GPT-5.4를 공식 출시했습니다. 최근 AI 업계는 단순한 질의응답을 넘어 스스로 사고하고 행동하는 에이전트 기반의 자동화 기술로 빠르게 진화하고 있습니다. 이러한 흐름 속에서 등장한 이 모델은 코딩, 고도화된 추론, 그리고 에이전트 기능을 하나의 시스템으로 통합하여 기존 언어 모델의 한계를 크게 뛰어넘었습니다. 특히, 소프트웨어 엔지니어, 데이터 분석가 등 전문가들이 일상적으로 마주하는 고난도 작업을 더욱 빠르고 정확하게 처리하는 데 초점을 맞추고 있습니다. 이번 출시는 엔터프라이즈 환경에서의 AI 활용 방식을 근본적으로 바꿀 중요한 이정표로 평가받고 있습니다.
GPT-5.4 모델의 가장 큰 특징 중 하나는 OpenAI의 주요 모델 최초로 컴퓨터 제어(Computer-Use) 기능을 기본적으로 탑재했다는 점입니다. 이를 통해 AI 에이전트는 사용자를 대신하여 직접 화면의 UI를 인식하고, 마우스 클릭 및 키보드 입력을 통해 다양한 소프트웨어와 웹사이트를 자율적으로 조작할 수 있습니다. 또한, 최대 105만(1.05M) 토큰에 달하는 방대한 컨텍스트 윈도우를 지원하여 거대한 코드베이스나 수많은 문서 문맥을 한 번에 분석하고 처리하는 것이 가능해졌습니다.
더불어, 코딩 플랫폼인 Codex에 깊이 통합되어 다단계 개발 워크플로우를 실행하거나 복잡한 버그를 추적하는 능력도 이전 세대 대비 크게 향상되었습니다. 결과적으로 사용자는 중간 개입을 최소화하면서도 완성도 높은 결과물을 내놓는 강력한 자율형 디지털 작업자를 얻게 된 셈입니다.
이와 함께 시스템의 배포 신뢰성과 안전성을 강화하기 위한 다양한 방어 조치도 철저하게 적용되었습니다. OpenAI는 사이버 보안(Cybersecurity) 분야의 'High' 등급 역량에 대한 안전 완화(Mitigation) 가이드라인을 범용 모델 최초로 이 모델에 구현하여 악용 가능성을 차단했습니다. 이를 통해, 시스템 제어 권한을 가진 에이전트가 복잡한 작업을 수행하는 과정에서 발생할 수 있는 잠재적 보안 위험을 크게 줄였습니다.
뿐만 아니라, 환각(Hallucination) 현상을 이전 세대 대비 대폭 감소시켜 답변의 사실성과 정확도를 엔터프라이즈 프로덕션 수준으로 끌어올렸습니다. 이러한 발전은 궁극적으로 기업 고객과 개발자들이 더욱 안전하고 신뢰할 수 있는 기반 위에서 AI 비즈니스 로직을 설계하고 배포할 수 있도록 돕습니다.
기존 GPT-5.2 및 경쟁 모델과의 비교

이번 출시는 직전의 주요 추론 모델이었던 GPT-5.2 Thinking을 직접적으로 대체하며, 다양한 벤치마크에서 괄목할 만한 성능 향상을 보여줍니다. 참고로, GPT-5.3 Thinking 모델은 존재하지 않으며, GPT-5.3 라인업은 Codex 및 Instant 버전으로만 운영되었습니다.
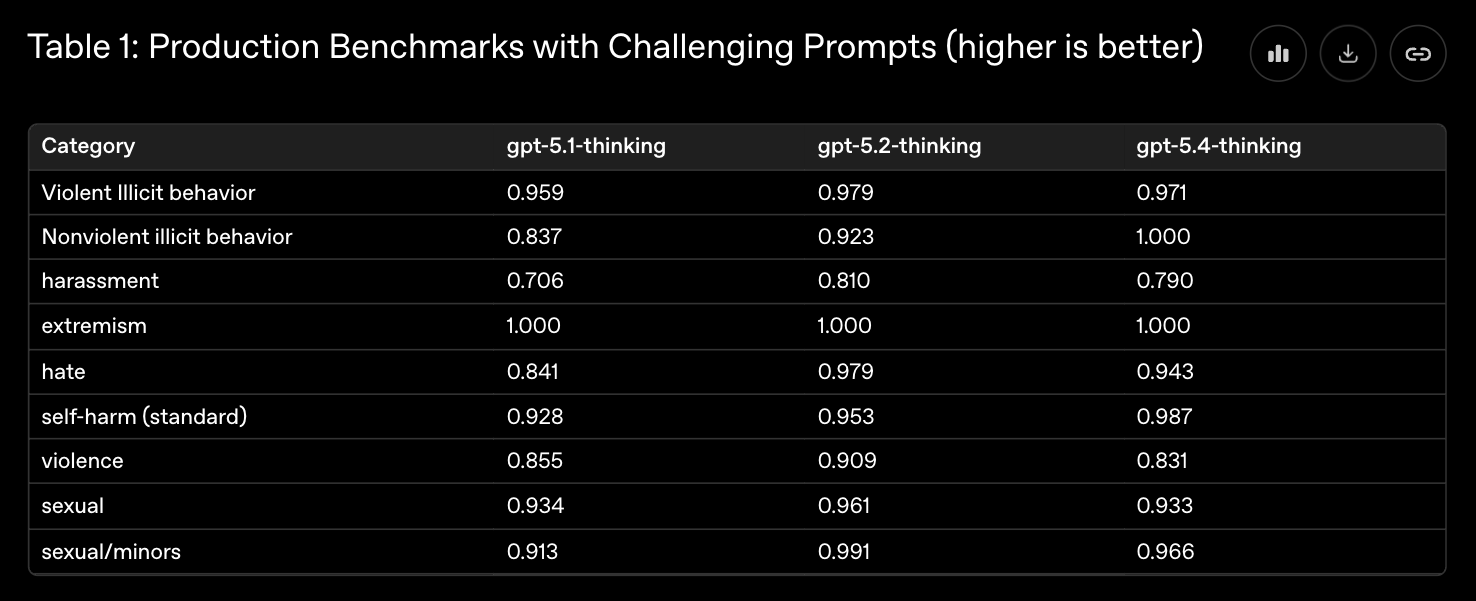
가장 두드러지는 차이는 데이터 분석 및 금융 모델링과 같은 전문 작업에서의 신뢰성입니다. 주니어 투자 은행 수준의 재무 모델링 평가(Junior investment banking-style modeling)에서 GPT-5.2가 68.4%의 점수를 기록했던 반면, 새로운 모델은 87.3%라는 비약적인 성장을 이뤄냈습니다.

또한 텍스트 생성의 정확성 면에서도 큰 진전이 있어, 기존 대비 거짓 정보(할루시네이션)를 생성할 확률이 33% 감소했으며, 전체 답변에서 발생하는 오류의 빈도 역시 18% 줄어들었습니다. 프레젠테이션 시각화 품질에서도 인간 평가자의 68%가 기존 모델보다 새로운 모델의 결과물을 선호했습니다.
한편, 이 모델은 엔터프라이즈 에이전트 시장에서 빠르게 점유율을 늘리고 있는 Anthropic의 Claude Opus 4.6 및 Sonnet 4.6 등 최신 모델들과 직접적으로 경쟁하며, 특히 코딩 역량과 네이티브 컴퓨터 제어 기능 면에서 차별화를 두고 있습니다.
GPT-5.4 모델의 주요 특징
두 가지 특화 모델 라인업: Thinking과 Pro
OpenAI는 사용자 요구사항과 작업의 복잡도에 맞춰 GPT-5.4의 두 가지 주요 모델군을 공개하였습니다:
-
GPT-5.4 Thinking (
gpt-5.4-thinking): 깊은 추론과 다단계 문제 해결에 최적화된 모델입니다. 답변을 생성하기 전에 내부적인 추론 계획(Plan)을 사용자에게 먼저 표시하는 새로운 상호작용 방식을 도입했습니다. 사용자는 모델이 응답을 완성하기 전에 추론 방향을 검토하고 중간에 개입하여 지시사항을 수정할 수 있어, 불필요한 프롬프트 반복을 줄일 수 있습니다. -
GPT-5.4 Pro (
gpt-5.4-pro): 엔터프라이즈급의 최고난도 작업을 위해 설계된 고성능 모델입니다. 더 많은 컴퓨팅 자원을 활용하여 깊게 사고(Think harder)하며, 다중 턴 상호작용 지원을 위해 현재 API에서는 Responses API를 통해서만 제공됩니다. 이 모델은 복잡성을 처리하는 대신 응답에 수 분이 걸릴 수 있어 백그라운드 모드 실행이 권장됩니다.
에이전트 워크플로우와 컴퓨터 제어 (Computer-use) 기능
GPT-5.4에는 단순한 텍스트 챗봇을 넘어 소프트웨어 환경과 직접 상호작용할 수 있는 능력이 내장되었습니다. 이를 통해 Native Computer Use 기능이 API와 Codex를 통해 지원되며, 에이전트가 사용자의 컴퓨터 화면을 시각적으로 분석하고 마우스 이동, 클릭, 키보드 타이핑 등을 직접 수행할 수 있습니다.
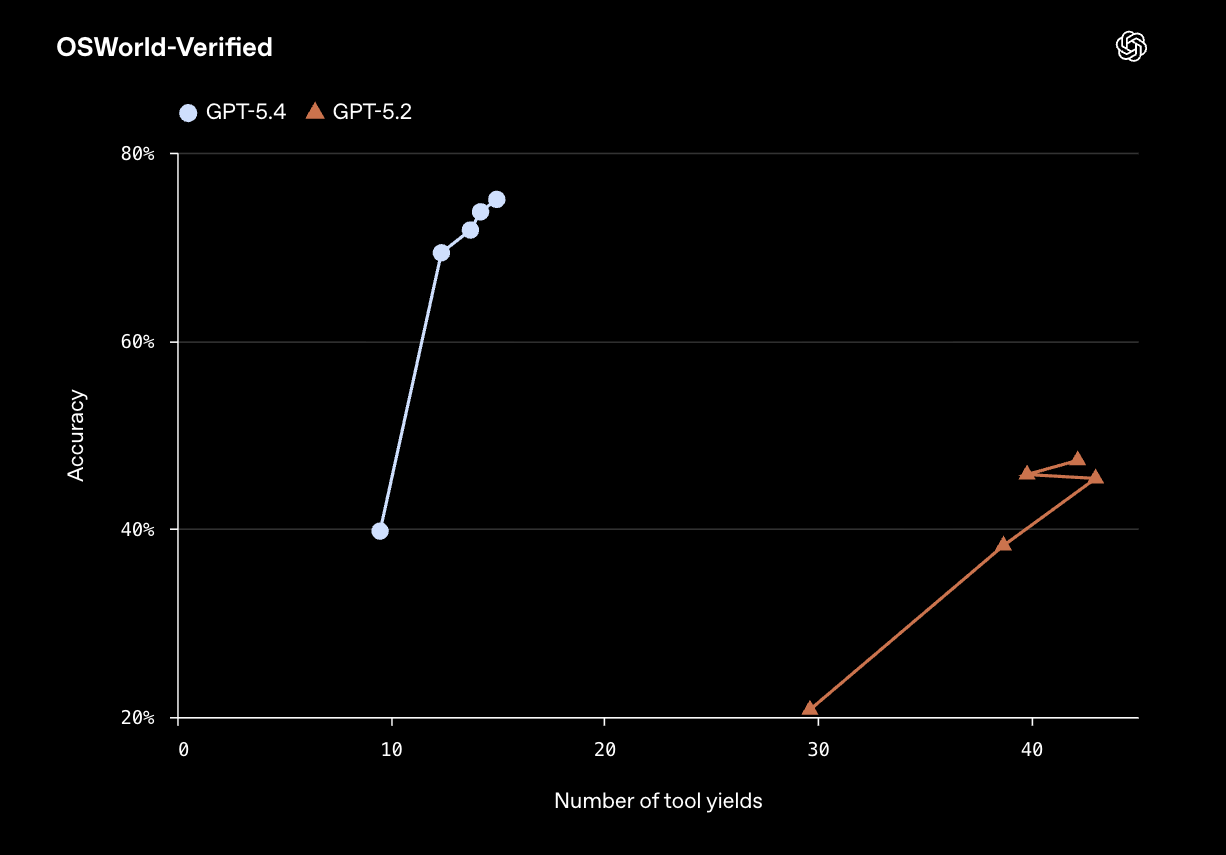
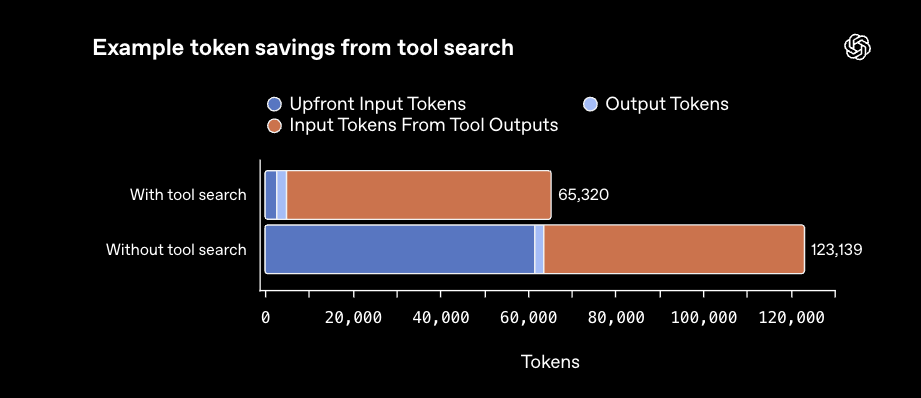
또한, GPT-5.4 API에서는 도구 호출(Tool Calling) 프로세스를 최적화하는 Tool Search 기능이 도입되었습니다. 모델이 실행 중에 필요한 도구나 함수의 정의를 실시간으로 검색하여 불러옴으로써, 방대한 도구 목록을 컨텍스트에 모두 포함할 때 발생하는 토큰 낭비를 획기적으로 줄여줍니다.
방대한 컨텍스트 윈도우와 개발자 API
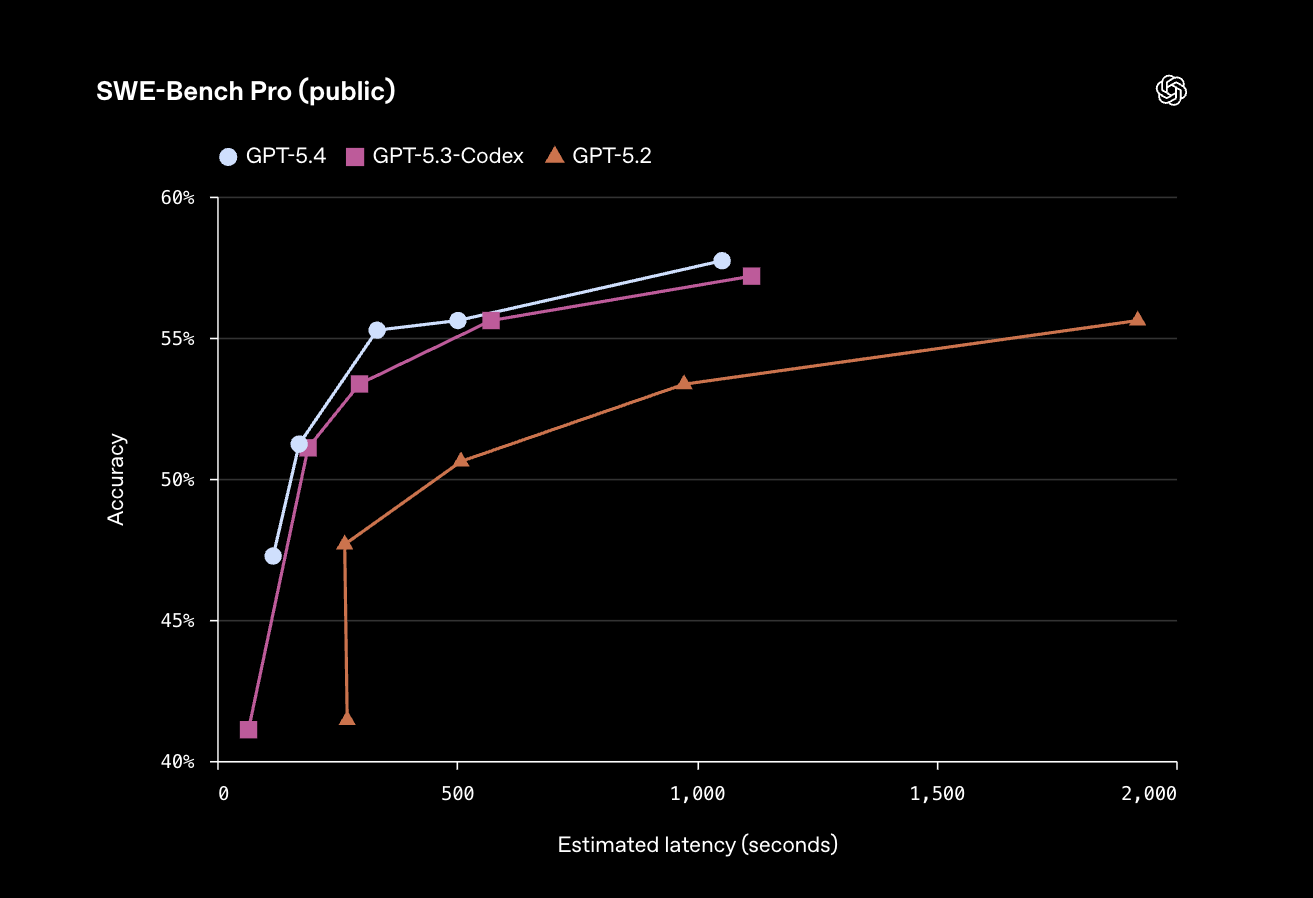
최대 1.05M(1,050,000) 토큰의 컨텍스트 윈도우를 지원하여, 한 번에 약 1,575페이지 분량의 문서를 처리할 수 있습니다. 또한,GPT-5.3-Codex의 코딩 역량을 계승하고 발전시켜, 소프트웨어 엔지니어링 벤치마크인 SWE-Bench Pro에서 57.7%의 높은 점수를 달성했습니다.
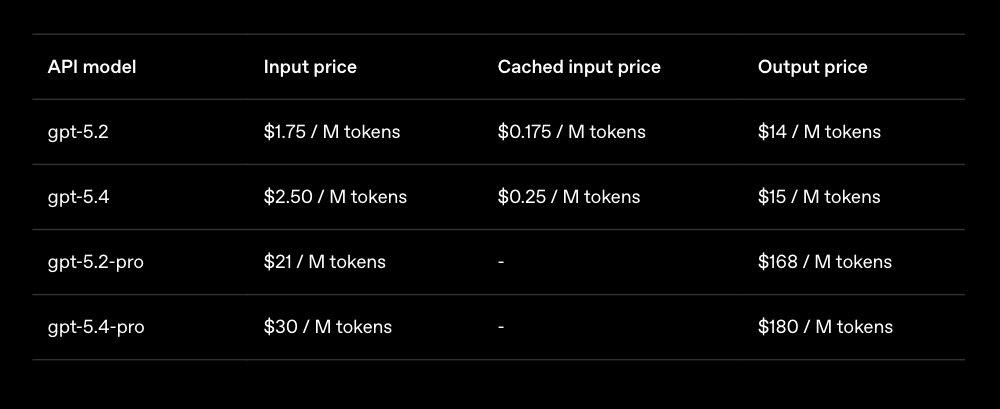
GPT-5.4의 API 요금 및 한도는 다음과 같이 책정되었습니다:
- 기본 모델은 입력 100만 토큰당 $2.50, 출력 100만 토큰당 $15.00입니다.
- Pro 모델은 고비용 연산을 반영하여 입력 $30.00, 출력 $180.00로 책정되었습니다.
- 1.05M 컨텍스트를 지원하지만, 표준 272K 토큰을 초과하는 대규모 프롬프트 입력 시 입력 요금은 2배, 출력 요금은 1.5배로 할증 적용됩니다.
다음은 공식 연동 환경에서 지원하는 기본적인 컴퓨터 제어 및 추론 요청의 파이썬 코드 스니펫 예시입니다.
import openai
# OpenAI 클라이언트 초기화 및 API 키 설정
client = openai.OpenAI(
api_key="YOUR_API_KEY"
)
# GPT-5.4 모델을 호출하여 복잡한 재무 지표 분석 및 문서화 요청
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": "당신은 전문적인 재무 분석가이자 데이터 엔지니어입니다."},
{"role": "user", "content": "제공된 10년 치 재무 데이터베이스 접근 기록을 바탕으로 핵심 성장 지표를 분석하고 엑셀 스프레드시트 구조로 명확하게 정리하여 출력해 주십시오."}
],
max_tokens=4096,
temperature=0.2
)
# 추론된 결과물 출력
print(response.choices[0].message.content)
엑셀 통합 기능: ChatGPT for Excel
데이터 분석가와 재무 전문가를 위해 *ChatGPT for Excel(베타)* 애드온(Add-on)이 새롭게 출시되었습니다. 이 플러그인은 Microsoft Excel 워크북에 AI를 직접 임베딩하여, 복잡한 재무 모델을 구축하고 수식을 생성하며 시나리오 분석을 자동화할 수 있도록 지원합니다.
https://chatgpt.com/apps/spreadsheets/?openaicom-did=4a507df1-2895-4ef4-9ea2-997a839a332a
또한, 향후 Codex와 API에서도 스프레드시트(Spreadsheet) 및 프리젠테이션(Presentation) 스킬을 사용할 수 있도록 업데이트할 예정입니다.
시스템 보안 및 안전성 (System Card)
GPT-5.4의 시스템 카드(System Card)에 따르면, GPT-5.4는 범용 모델 최초로 사이버 보안(Cybersecurity) 역량 'High' 등급에 해당하는 엄격한 안전 완화(Mitigation) 조치를 통과했습니다. 또한, 자율 에이전트 기능 추가에 따른 위험을 통제하기 위해 최고 수준의 보안 아키텍처가 적용되었습니다.
악의적인 프롬프트 인젝션이나 권한 탈취를 막기 위해 내부적으로 서브 에이전트(Sub-agents)를 활용하여 요약과 필터링을 거치는 다층 방어 체계를 갖추고 있습니다.
사고 과정 모니터링 (Chain of Thought Monitorability)
GPT-5.4 Thinking 모델이 도입한 가장 중요한 패러다임 변화 중 하나는 사고 과정 모니터링(Chain of Thought Monitorability) 기능의 공식 지원입니다. 기존의 대형 언어 모델(LLM)들이 프롬프트 입력 후 최종 결과물만을 반환하는 블랙박스(Black-box) 형태로 동작했다면, 새로운 모델은 AI가 정답을 도출하기 위해 거치는 중간 추론 단계(Hidden Reasoning Tokens)를 실시간으로 노출하여 시스템의 투명성을 극대화했습니다.
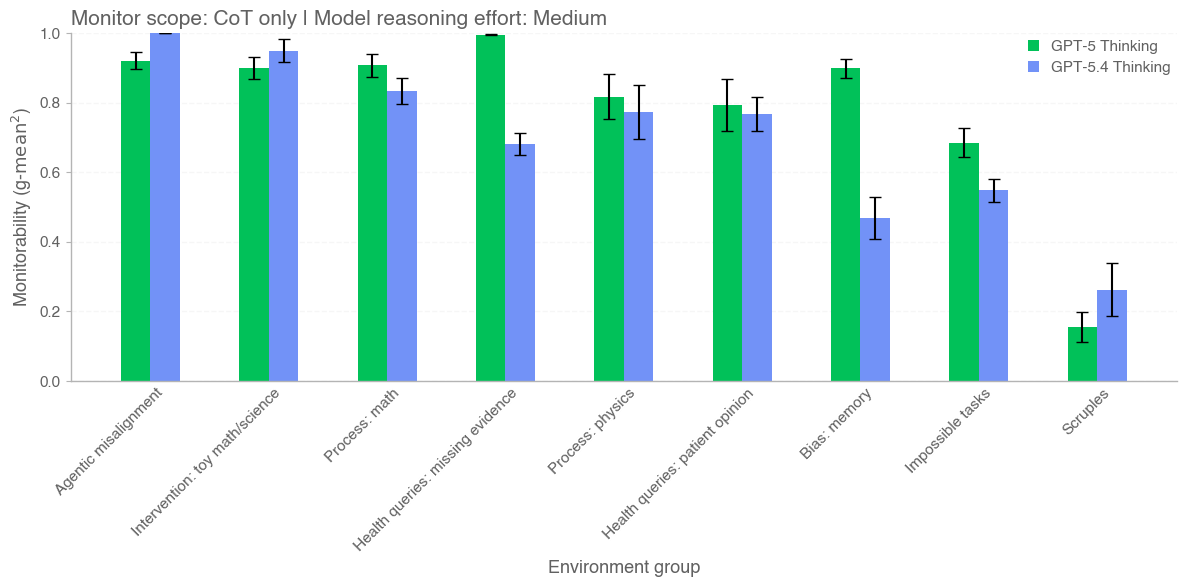
이러한 가시성 확보는 소프트웨어 엔지니어링 및 엔터프라이즈 환경에서 다음과 같은 강력한 이점을 제공합니다.
-
실시간 디버깅 및 경로 수정 (Real-time Debugging & Intervention): 복잡한 코드베이스의 버그를 추적하거나 수학적 알고리즘을 설계할 때, 개발자는 AI가 논리를 전개하는 과정을 직접 살펴볼 수 있습니다. 만약 AI가 잘못된 전제조건을 바탕으로 코드를 작성하기 시작한다면, 최종 결과물이 나오기 전에 즉시 개입(Intervention)하여 추론 방향을 올바르게 교정할 수 있습니다. 이는 컴퓨팅 자원의 낭비를 막고 작업 속도를 비약적으로 향상시킵니다.
-
에이전트 행동의 안전성 검증 (Safety & Alignment Check): GPT-5.4는 시스템의 화면을 읽고 직접 컴퓨터를 제어(Computer-use)할 수 있는 자율 에이전트 기능을 갖추고 있습니다. 사고 과정 모니터링은 이 에이전트가 특정 파일에 접근하거나 시스템 명령어를 실행하기 전에 **'왜 그러한 행동을 계획했는지'**를 사전에 검토할 수 있는 안전장치 역할을 합니다. 이를 통해 예기치 않은 시스템 손상이나 권한 오남용을 미연에 방지할 수 있습니다.
-
엔터프라이즈 감사 및 컴플라이언스 (Audit & Compliance): 금융 모델링이나 의료 데이터 분석과 같이 규제가 엄격한 산업군에서는 AI가 특정 결론을 내린 근거(Explainability)를 증명하는 것이 필수적입니다. 개발자는 API(예:
reasoning_content스트리밍 객체)를 통해 전달받은 AI의 추론 로그를 별도로 저장하여, 내부 감사(Audit)나 규제 기관의 컴플라이언스 요구사항을 충족하는 아티팩트(Artifact)로 활용할 수 있습니다.
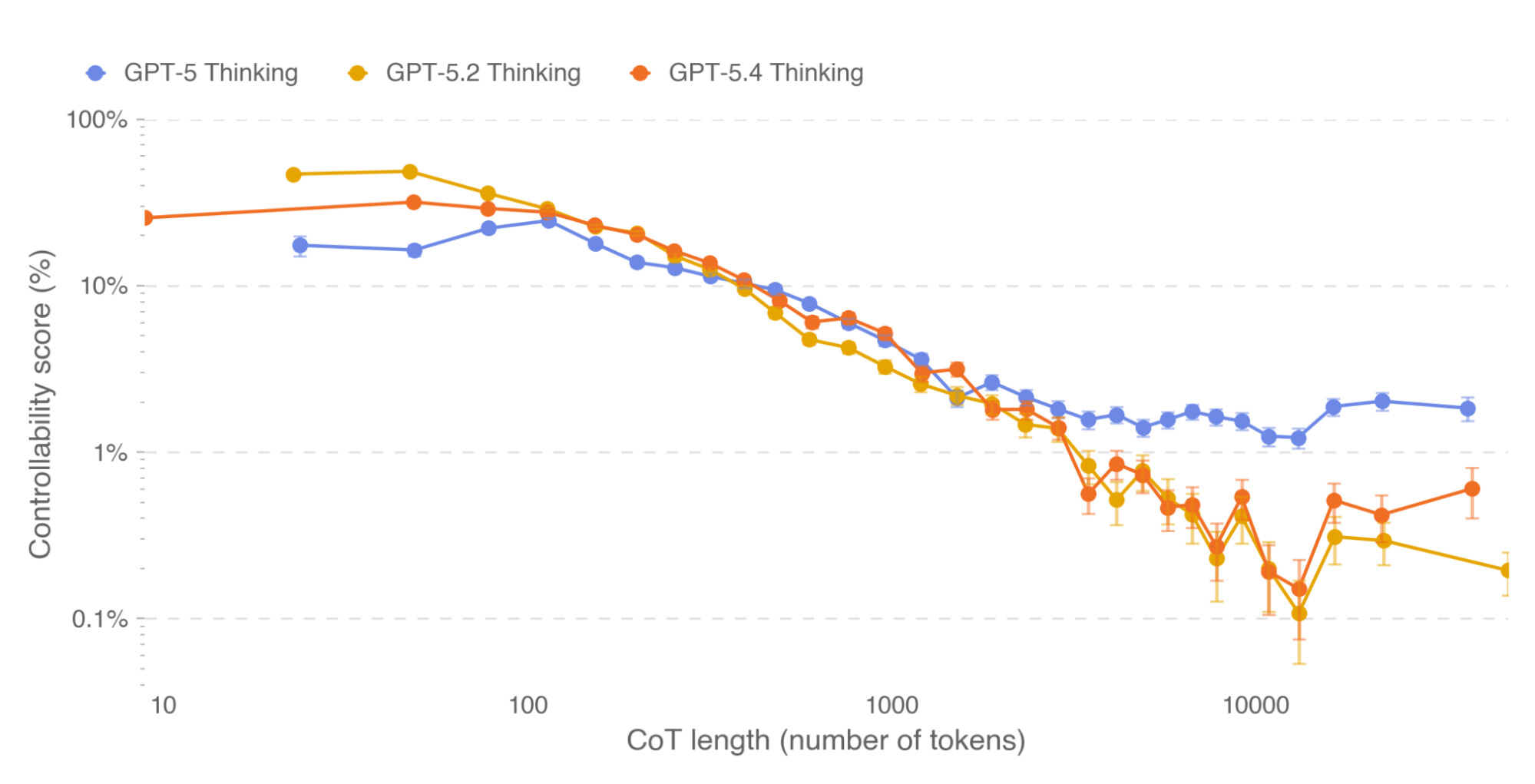
결과적으로 사고 과정 모니터링은 AI를 단순한 질의응답 도구에서 **'신뢰하고 통제할 수 있는 협업 파트너'**로 격상시키는 핵심 기술 아키텍처로 기능합니다.
대비 프레임워크(Preparedness Framework) 기반의 위험 관리
OpenAI는 최첨단 AI 모델이 야기할 수 있는 심각한 위험을 사전에 추적하고 대비하기 위해 고유의 대비 프레임워크를 운영하고 있습니다. 고성능 모델의 잠재적 위험을 최소화하기 위한 이 안전 기준에 따라, GPT-5.4 Thinking 모델은 다음과 같이 역량이 평가되고 안전 장치가 적용되었습니다.
-
생물학 및 화학 (Biological and Chemical) 분야: 기존 GPT-5.2 Thinking 모델과 동일하게 '높음(High)' 수준의 잠재적 역량을 가진 것으로 평가되었습니다. 이에 따라 GPT-5 시스템 카드에 명시된 엄격한 보호 및 완화 조치가 적용되었습니다.
-
사이버 보안 (Cybersecurity) 분야: 코드 생성 능력이 뛰어났던 GPT-5.3 Codex와 마찬가지로 사이버 보안 영역에서도 '높음(High)' 수준의 역량을 갖춘 것으로 분류되어, 악용을 막기 위한 철저한 안전 장치가 구현되었습니다.
-
AI 자가 개선 (AI self-improvement): AI가 스스로 성능을 개선하는 역량에 대한 최종 체크포인트 평가 결과, 이전 세대 모델들과 마찬가지로 '높음' 위험 임계값에 도달할 가능성은 없는 것으로 확인되어 통제 가능한 범위 내에 있음이 입증되었습니다.
 OpenAI의 GPT-5.4 출시 블로그
OpenAI의 GPT-5.4 출시 블로그
https://openai.com/index/introducing-gpt-5-4/
GPT-5.4 Thinking 모델 시스템 카드 (Web 및 PDF)
GPT-5.4 개발자 API 문서
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()