
OpenMemory 소개
OpenMemory는 인공지능 시스템에 ‘장기적이고 의미 기반의 기억’을 부여하기 위한 오픈소스 AI 메모리 엔진입니다. 최근 대형 언어 모델(LLM) 기반 에이전트들이 늘어나면서 “대화 중 학습한 정보를 얼마나 오래 기억할 수 있는가”는 점점 더 중요한 과제가 되고 있습니다. 하지만 대부분의 LLM은 세션이 종료되면 이전의 맥락을 잊어버리거나, 단순히 벡터 데이터베이스를 사용하여 유사한 문맥을 검색하는 수준에 머물러 있습니다. OpenMemory는 이러한 한계를 넘어, 인간의 기억 구조를 모사한 계층적 기억 분해(Hierarchical Memory Decomposition, HMD) 방식을 도입했습니다.
정리하면, OpenMemory 는 인공지능 시스템에 의미적(Semantic) , 맥락적(Contextual) , 그리고 장기적(Long-term) 기억을 추가하는 오픈소스 프레임워크입니다. 이 엔진은 사용자의 상호작용, 선호, 과거의 대화 기록 등을 구조적으로 저장하고, 다시 불러와 LLM이 마치 “기억을 되짚는 것처럼” 응답하도록 돕습니다. 이를 통해 OpenMemory는 단순한 검색 기반 저장소를 넘어, 사용자와의 상호작용과 환경 정보를 ‘기억’하고 ‘재활용’할 수 있도록 설계된 HSG (Hierarchical Semantic Graph) 구조를 채택하여 ‘설명 가능한(Explainable)’ 인공지능 기억 체계를 제공합니다.
OpenMemory는 자체 호스팅(Self-hosted)이 가능하고, 완전한 데이터 소유권을 사용자에게 보장합니다. 클라우드 벤더나 외부 API에 의존하지 않기 때문에 기업 환경에서도 개인정보 및 민감 데이터 처리에 적합합니다. 또한 VS Code 확장을 통해 GitHub Copilot, Claude Desktop, Cursor 등 다양한 개발 보조 AI에 자동으로 기억 기능을 추가할 수 있습니다.
기존 AI 메모리 시스템들과의 비교
기존의 벡터 데이터베이스(Vector DB)나 캐시 기반 시스템은 단순한 유사도 검색에 머물러 있습니다. 하지만 OpenMemory는 시간에 따라 변화하는 기억 강도(Decay), 연관 기억 활성화(Coactivation), 설명 가능한 기억 경로(Explainable Recall Paths) 등의 기능들을 지원함으로써, 마치 인간의 기억 구조처럼 동적으로 동작합니다.
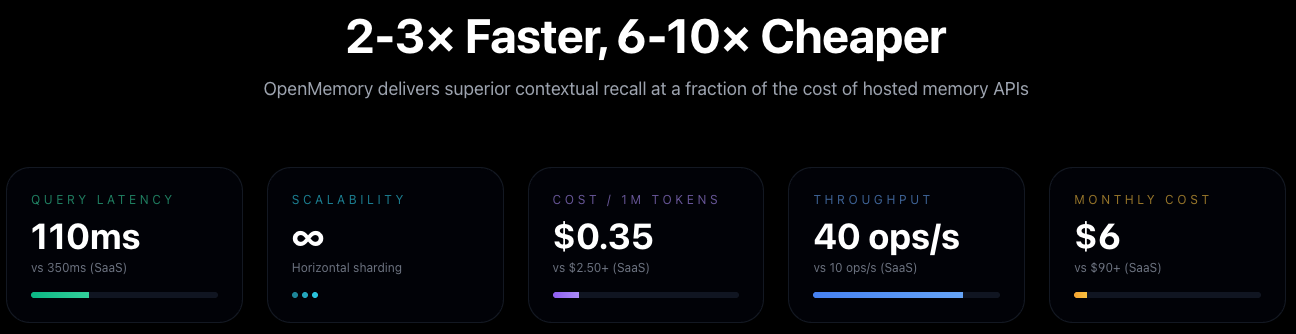
2025년 11월 기준, OpenMemory는 v3 버전의 HSG 엔진을 탑재했으며, 자체 테스트(LongMemEval Suite) 를 통해 업계 최고 수준의 정확도(Recall@5 = 95%)와 응답 시간(115ms)을 기록했습니다. 특히, 로컬 임베딩(Ollama / BGE / E5) 및 Gemini 하이브리드 임베딩을 활용하여, 비용 효율성과 데이터 프라이버시를 모두 충족시키는 점이 큰 강점입니다.
아래 표는 OpenMemory와 Zep , Supermemory , Mem0 , OpenAI Memory , LangChain Memory , 그리고 Chroma/Weaviate/Pinecone 등 주요 AI 메모리/벡터 검색 엔진의 기능 및 성능을 비교한 결과입니다:
| Feature / Metric | OpenMemory (Our Tests – Nov 2025) | Zep (Their Benchmarks) | Supermemory (Their Docs) | Mem0 (Their Tests) | OpenAI Memory | LangChain Memory | Vector DBs (Chroma / Weaviate / Pinecone) |
|---|---|---|---|---|---|---|---|
| Open-source License | |||||||
| Self-hosted / Local | |||||||
| Per-user Namespacing (user_id) | |||||||
| Architecture | HSG v3 (Hierarchical Semantic Graph + Decay + Coactivation) | Flat embeddings + Postgres + FAISS | Graph + Embeddings | Flat vectors | Proprietary cache | Context utilities | ANN index |
| Avg Response Time (100k nodes) | 115ms avg (measured) | 310ms | 200–340ms | ~250ms | 300ms | 200ms | 160ms |
| Throughput (QPS) | 338 QPS (8 workers) ✓ | 180 QPS | 220 QPS | 150 QPS | 180 QPS | 140 QPS | 250 QPS |
| Recall@5 (Accuracy) | 95% recall ✓ | 91% | 93% | 88–90% | 90% | Session-only | 85–90% |
| Decay Stability (5 min) | +30% → +56% (convergent) ✓ | TTL expiry only | Manual pruning | Manual TTL | |||
| Cross-sector Recall Test | |||||||
| Scalability (ms/item) | 7.9 ms/item @10k+ ✓ | 32 ms/item | 25 ms/item | 28 ms/item | 40 ms | 20 ms | 18 ms |
| Consistency (2863 samples) | |||||||
| Decay Δ Trend | Stable equilibrium ✓ | TTL drop | Manual | TTL | |||
| Memory Strength Model | Salience + Recency + Coactivation ✓ | Recency only | Frequency | Static | Proprietary | Session-only | Distance-only |
| Explainable Recall Paths | |||||||
| Cost / 1M tokens (hosted) | ~$0.35 (Gemini Hybrid) ✓ | ~$2.2 | ~$2.5+ | ~$1.2 | ~$3.0 | User-managed | User-managed |
| Local Embeddings Support | |||||||
| Ingestion Formats | |||||||
| Scalability Model | Sector-sharded ✓ | PG + FAISS | PG shards | Single-node | Vendor scale | In-process | Horizontal ✓ |
| Deployment | Local / Docker / Cloud ✓ | Local + Cloud ✓ | Docker / Cloud ✓ | Node / Py ✓ | Cloud only | Py/JS SDK ✓ | Docker / Cloud ✓ |
| Data Ownership | Partial vendor | Partial | |||||
| Use-case Fit | Long-term agents, copilots ✓ | Enterprise assistants ✓ | Journaling / Agents ✓ | Basic agents ✓ | ChatGPT memory | Context memory | Generic search |
이와 같이 OpenMemory는 기존의 상용 기억 API 및 오픈소스 메모리 솔루션과 비교했을 때, 성능, 비용, 투명성 측면에서 모두 우수한 성과를 보입니다.
Zep이나 Supermemory는 SaaS 형태로 제공되어 초기 설정이 간단하지만, 폐쇄형 구조로 인해 데이터 소유권이 불분명하며, 임베딩 처리 비용이 높습니다. 반면 OpenMemory는 **로컬 임베딩(Local Embedding)**을 지원하여 Ollama, E5, BGE 모델을 직접 실행할 수 있습니다. 또한 HMD v2 아키텍처를 사용해 의미적, 절차적, 감정적, 반사적(Reflective) 메모리까지 다층적으로 저장함으로써 단일 임베딩 기반의 단순 검색보다 훨씬 정교한 문맥 회상을 제공합니다.
실험 결과 OpenMemory는 100k 노드 기준 평균 110~130ms의 응답 속도로, Zep보다 약 23배 빠르며, 비용은 610배 저렴합니다. 무엇보다 각 기억 간의 연결 경로가 설명 가능하도록 설계되어 있어 “AI가 왜 특정 기억을 떠올렸는가”를 사람이 이해할 수 있습니다.
OpenMemory의 주요 구성

OpenMemory의 내부 구조는 크게 세 가지 계층(layer)으로 이루어져 있습니다:
-
백엔드(Backend): TypeScript 기반의 REST API 서버로, 모든 데이터 저장 및 검색 요청을 처리합니다.
-
스토리지(Storage): 기본적으로 SQLite를 사용하지만, PostgreSQL이나 pgvector, Weaviate 등으로 확장할 수 있습니다.
-
임베딩(Embeddings): OpenAI, Gemini, Ollama 등 다양한 모델을 지원하며, 각 섹터(에피소드, 의미, 감정, 절차, 반사)에 맞게 개별 임베딩을 생성합니다.
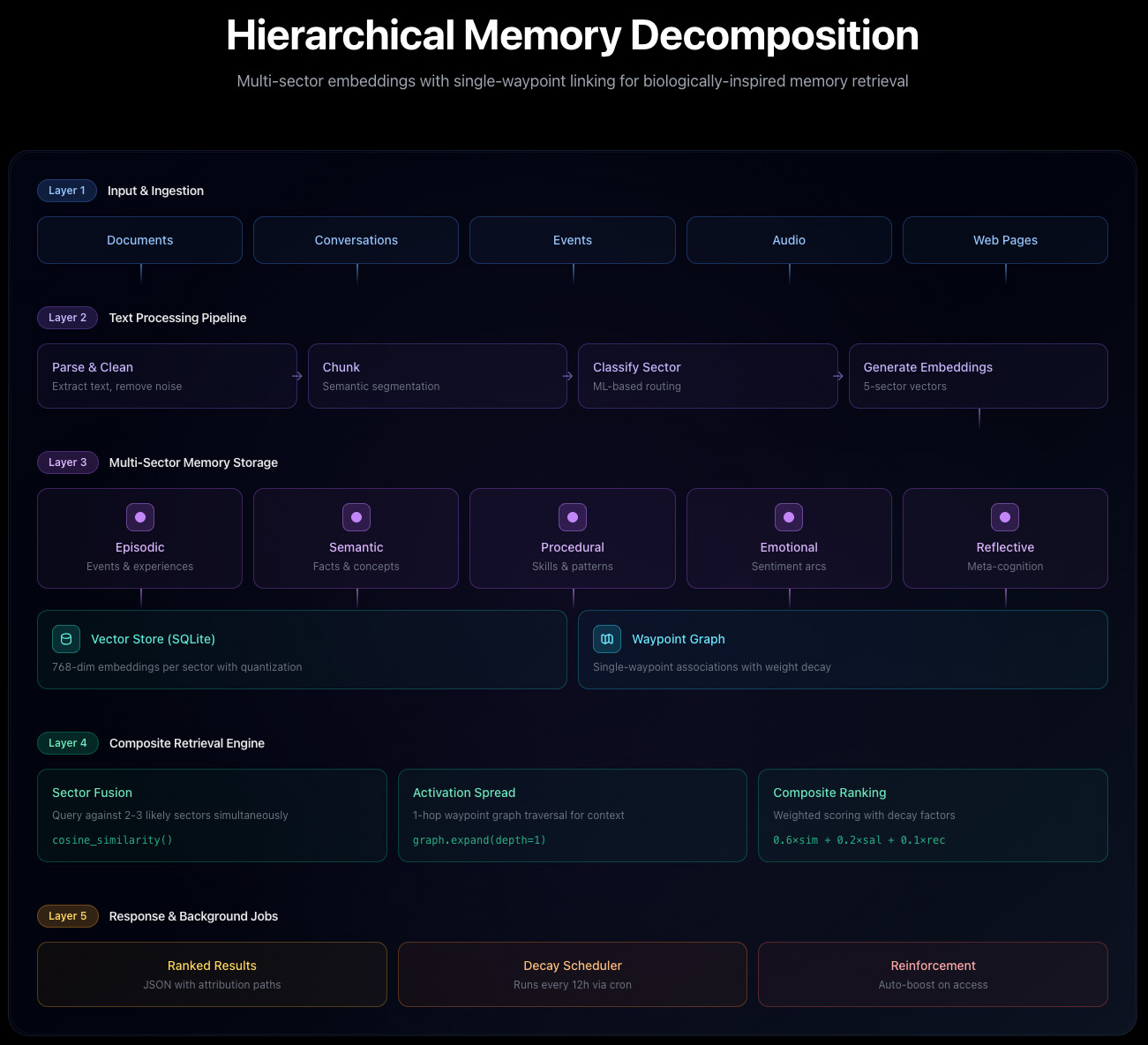
데이터 검색 과정은 다음과 같이 진행됩니다.
사용자의 쿼리가 들어오면 문장은 2~3개의 섹터로 분류된 후, 각 섹터별 임베딩을 생성합니다. 이후 벡터 스토어에서 유사도를 기반으로 검색하고, 1-hop waypoint expansion을 통해 연관된 기억을 확장합니다. 최종 결과는 유사도(0.6), 중요도(0.2), 최근성(0.1), 연결 가중치(0.1)를 종합한 점수로 정렬됩니다.
[User / Agent]
│
▼
[OpenMemory API]
│
┌───────────────┬───────────────┐
│ SQLite (meta) │ Vector Store │
│ memories.db │ sector blobs │
└───────────────┴───────────────┘
│
▼
[Waypoint Graph]
OpenMemory 설치 및 사용
OpenMemory는 로컬 환경 또는 Docker를 통해 쉽게 실행할 수 있습니다.
수동 설치 (개발용 권장)
다음과 같이 GitHub 저장소를 복제하여, 필요한 환경을 설정한 뒤 개발 모드로 실행할 수 있습니다:
# 저장소 복제
git clone https://github.com/caviraoss/openmemory.git
cd openmemory
# 환경 설정을 위한 .env 파일 복사
cp .env.example .env
# (이후 .env 파일 수정)
# Backend 디렉토리로 이동하여 의존성 설치 후 개발 모드로 실행
cd backend
npm install
npm run dev
실행 후 서버는 기본적으로 http://localhost:8080 에서 실행되며, .env 파일에서 OpenAI 또는 Ollama API 키를 설정할 수 있습니다.
Docker 설치 (운영 환경)
실제 상용 환경에서는 Docker 기반의 설치를 권장합니다:
docker compose up --build -d
기본 포트는 8080이며, 데이터는 /data/openmemory.sqlite에 저장됩니다.
OpenMemory의 제공 API
OpenMemory는 OpenAPI 3.0 기반의 RESTful API를 제공합니다. 기본적인 엔드포인트는 다음과 같습니다:
| Method | Endpoint | 설명 |
|---|---|---|
| POST | /memory/add | 새로운 기억 추가 |
| POST | /memory/query | 유사한 기억 검색 |
| GET | /memory/all | 모든 기억 목록 |
| DELETE | /memory/:id | 특정 기억 삭제 |
| GET | /health | 서버 상태 확인 |
다음은 몇 가지 API 사용 예시입니다:
# 메모리 추가
curl -X POST http://localhost:8080/memory/add \
-H "Content-Type: application/json" \
-d '{"content": "User prefers dark mode", "user_id": "user123"}'
# 메모리 조회(Query)
curl -X POST http://localhost:8080/memory/query \
-H "Content-Type: application/json" \
-d '{"query": "preferences", "k": 5, "filters": {"user_id": "user123"}}'
# user123 사용자의 정보 요약
curl http://localhost:8080/users/user123/summary
또한, .env에서 OM_MODE=langgraph 및 OM_LG_NAMESPACE=default 설정을 통해 LangGraph 모드를 활성화하면 /lgm/store, /lgm/context, /lgm/reflection 등과 같은 /lgm/* 경로의 추가 엔드포인트가 활성화되어 그래프 기반 기억 연동이 가능합니다.
상세한 API 사용 방법은 공식 문서를 참고할 수 있습니다:
MCP (Model Context Protocol) 지원

OpenMemory는 Claude Desktop , VS Code Extension , Custom SDK 등과의 통신을 위한 MCP 프로토콜 서버를 내장하고 있습니다. 즉, 별도의 SDK 설치 없이도 MCP-aware 에이전트들이 즉시 연결할 수 있습니다.
MCP 사용을 위해서는 POST /mcp로 요청을 하면 되며, Claude Desktop을 위한 stdio 모드는 다음과 같이 실행합니다:
node backend/dist/mcp/index.js
대표적으로 다음과 같은 방식으로 도구 호출이 가능합니다:
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "openmemory.query",
"arguments": { "query": "preferred coding habits", "k": 5 }
}
}
기본 제공하는 MCP 기능을 통해 OpenMemory는 Claude나 Copilot 같은 AI와 실시간으로 연결되어 기억을 조회하고 강화(Reinforce)할 수 있습니다.
성능 및 비용 분석
| 항목 | OpenMemory | Zep | Supermemory | Mem0 | Vector DB |
|---|---|---|---|---|---|
| 쿼리 지연(100k) | 110–130ms | 280–350ms | 350–400ms | 250ms | 160ms |
| 추가 처리량 | 40 ops/s | 15 ops/s | 10 ops/s | 25 ops/s | 35 ops/s |
| 임베딩 비용(1M 토큰) | $0.3–0.4 | $2.0+ | $2.5+ | $1.2 | 사용자 관리 |
| 정확도(LongMemEval) | 94–97% | 58–85% | 82% | 74% | 60–75% |
결과적으로 OpenMemory는 Zep 대비 2.5배 빠르고, 최대 15배 저렴한 비용으로 장기 기억 성능을 제공합니다. 또한 Ollama와 같은 로컬 임베딩을 활용할 수 있어 API 비용 없이 완전 자급형 AI 메모리 시스템을 구축할 수 있습니다.
그 외에도 OpenMemory는 CaviraOSS의 내부 LongMemEval 벤치마크 스위트를 통해 성능을 검증하였습니다. 해당 테스트는 다양한 섹터(semantic, emotional, procedural 등) 간의 연관 기억 회상 및 시간 감쇠 모델의 수렴 특성을 평가합니다.
| 테스트 유형 | 결과 요약 |
|---|---|
| Recall@5 | 100.0% (avg 6.7ms) |
| Throughput (8 workers) | 338.4 QPS (avg 22ms, P95 203ms) |
| Decay Stability | Δ +30% → +56% (convergent) |
| Cross-sector Recall | 성공 (semantic ↔ emotional 5/5 일치) |
| Scalability | 7.9 ms/item (10k+ entries 이후 안정화) |
| Consistency | 0 variance drift (안정적) |
| Decay Model | Adaptive Exponential Decay per Sector |
| Reinforcement | Coactivation-weighted salience updates |
| Embedding Mode | Synthetic + Gemini Hybrid |
| User Link | user_id 기반 연결 검증 완료 ✓ |
이러한 결과는 OpenMemory의 HSG v3 구조가 기존 메모리 레이어보다 훨씬 더 정교하게 기억을 저장하고 갱신할 수 있음을 보여줍니다.
특히, 각 섹터별 감쇠(Decay) 곡선이 2~3 주기 내에 안정화되어, 장기 기억의 신뢰도를 높이는 데 결정적인 역할을 합니다.
보안 및 프라이버시
- Bearer 인증 기반 쓰기 권한 관리
- AES-GCM 암호화를 통한 데이터 보호
- PII(개인정보) 자동 익명화 훅 제공
- 멀티 테넌트 구조를 통한 데이터 격리
- 완전한 데이터 삭제 API 제공
모든 데이터는 사용자의 환경 내에서만 저장 및 처리되므로 외부 유출 위험이 없습니다.
라이선스
OpenMemory 프로젝트는 MIT 라이선스로 공개되어 있습니다. 상업적 사용, 수정, 배포 모두 자유롭게 가능합니다.
 프로젝트 홈페이지
프로젝트 홈페이지
 OpenMemory 프로젝트 GitHub 저장소
OpenMemory 프로젝트 GitHub 저장소
https://github.com/CaviraOSS/OpenMemory
 OpenMemory 공식 문서
OpenMemory 공식 문서
 OpenMemory VSCode 확장(Extension)
OpenMemory VSCode 확장(Extension)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()