
Palantir Sovereign AI OS 소개
인공지능 기술이 전 산업과 국가 인프라의 핵심 경쟁력으로 부상함에 따라, 민감한 데이터를 다루는 글로벌 엔터프라이즈와 정부 기관들은 심각한 딜레마에 직면해 있습니다. 최첨단 대구모 언어 모델(LLM)과 AI 기술을 도입하여 생산성을 혁신하고 싶지만, 국가 기밀, 국방 데이터, 기업의 핵심 영업 비밀을 퍼블릭 클라우드 환경에 업로드하는 것은 엄격한 보안 규제와 '데이터 주권(Data Sovereignty)' 측면에서 불가능에 가깝기 때문입니다. 이로 인해 많은 조직이 강력한 컴퓨팅 성능을 필요로 하면서도, 외부 네트워크와 완전히 단절된 에어갭(Air-gapped) 환경이나 자체 데이터센터 내에서 구동할 수 있는 완성형 솔루션을 갈망해 왔습니다.
이러한 업계의 절실한 요구에 부응하여, 데이터 분석 및 보안 소프트웨어 분야의 독보적 선도 기업인 Palantir와 AI 컴퓨팅 하드웨어의 절대 강자인 NVIDIA가 전략적 파트너십을 맺고 새로운 해답을 제시했습니다. "AI의 미래는 온프레미스에 있다(The future of AI is on-prem)" 라는 비전 아래 공개된 Palantir Sovereign AI Operating System Reference Architecture는 실리콘 설계부터 시스템 구축, 소프트웨어 최적화에 이르는 전 과정을 아우르는 턴키(Turnkey) 방식의 풀스택(Full-stack) 레퍼런스 아키텍처입니다. 양사의 기술력이 집약된 이 솔루션은 기업이 자체적인 통제권을 100% 유지하면서도 현존하는 최고의 AI 성능을 온프레미스(On-premise), 엣지(Edge), 그리고 소버린 클라우드 환경에서 누릴 수 있도록 설계되었습니다.
Palantir Sovereign AI OS는 하드웨어 조달부터 애플리케이션의 배포 및 라이프사이클 관리까지 모든 과정을 프로덕션 레디(Production-ready) 상태로 제공합니다. 단순히 서버와 소프트웨어를 납품하는 것을 넘어, 철저하게 통제된 환경 속에서 AI가 어떻게 안전하게 조직의 데이터에 접근하고 추론하며, 이를 바탕으로 실제 비즈니스 로직을 수행할 수 있는지에 대한 완벽한 거버넌스 템플릿을 제공합니다. 이는 각 산업 분야의 고객들이 외부의 위협이나 데이터 유출 걱정 없이 자신만의 독점 데이터를 활용해 맞춤형 모델을 훈련시키고, 신뢰할 수 있는 에이전틱 엔터프라이즈(Agentic Enterprise)로 진화할 수 있는 토대를 마련해 줍니다.
Palantir Sovereign AI OS의 주요 구성 요소
Palantir AIOS-RA는 크게 4가지 계층(Layer)으로 구성되어 있으며, 각 계층은 안전하고 확장 가능한 AI 배포를 위해 상호 유기적으로 결합되어 있습니다.
아키텍처의 4대 핵심 계층 (Architecture Layers)
-
애플리케이션 계층 (Application Layer - Palantir AIP + NVAIE): 대규모 언어 모델(LLM)을 엔터프라이즈 데이터 및 비즈니스 로직과 직접 통합하는 계층입니다. NVIDIA AI Enterprise (NVAIE) 라이브러리의 가속을 받아 자연어 처리(NLP), 물류 최적화, 데이터 분석 등의 턴키 운영 앱을 제공하며 프로덕션 수준의 AI 에이전트 워크플로우를 지원합니다.
-
플랫폼 계층 (Platform Layer - Palantir Foundry): 동적 온톨로지(Dynamic ontology), 데이터 관리, 모델 오케스트레이션을 통합하는 안전한 워크스페이스입니다. 내부 팀이 민감한 정보를 보호하면서 AI 워크플로
우를 신속하게 구축할 수 있도록 철저한 거버넌스와 데이터 제어를 강제합니다. -
런타임 계층 (Runtime Layer - Palantir Rubix & Apollo): 제로 트러스트 기반의 컨테이너화된 런타임 환경입니다. 네임스페이스 격리(Namespace isolation)를 통한 다중 테넌트 보안을 제공하며, "한 번 빌드하면 어디서든 실행(Build once, run anywhere)" 가능한 배포 모델과 자동화된 롤백을 포함한 지속적 전송(Continuous delivery)을 지원합니다.
-
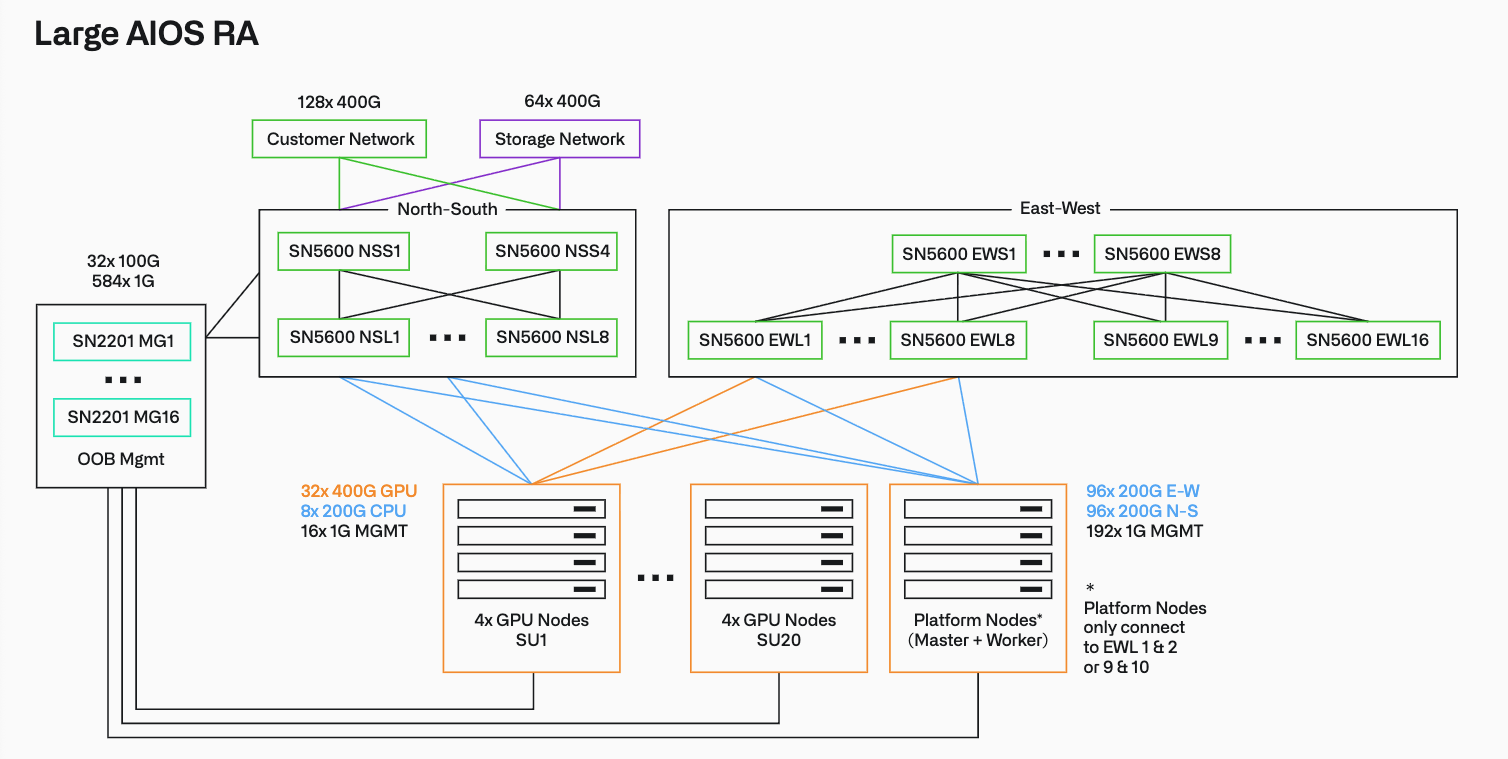
하드웨어 계층 (Hardware Layer - NVIDIA Certified Systems): NVIDIA Spectrum-X 이더넷 네트워킹으로 상호 연결된 3가지 유형의 서버(Master CPU 노드, Worker CPU 노드, GPU 노드)로 구성됩니다.
하드웨어 노드 상세 사양 (Dell Technologies 기반)
이 레퍼런스 아키텍처는 하드웨어 호환성 및 운영 효율성을 위해 Dell Technologies의 최신 서버 라인업을 기반으로 설계되었습니다.
-
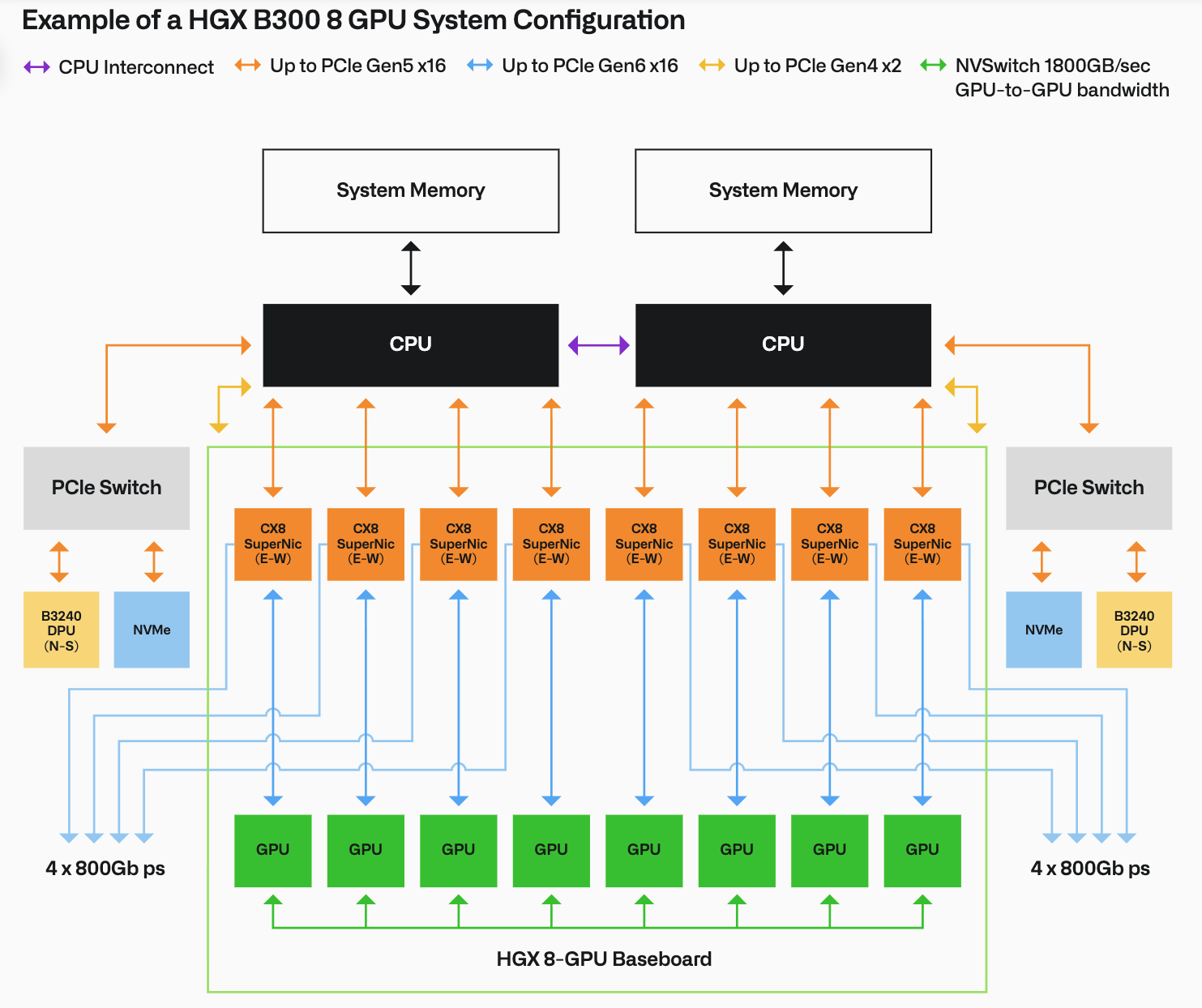
GPU 노드 (Dell PowerEdge XE9780): AI 훈련 및 추론의 핵심 장비로, 4개의 노드가 하나의 확장 단위(Scalable Unit, SU)를 구성합니다.
-
GPU: 하나의 베이스보드에 8개의 NVIDIA B300 SXM GPU가 탑재되며, NVSwitch를 통해 노드 내에서 최대 64TB/s의 총 대역폭을 제공합니다. 노드당 총 2.30TB의 HBM3e 메모리를 갖추어 10조 개 이상의 파라미터를 가진 초대형 모델 훈련도 가능합니다.
-
네트워크: 이스트-웨스트(East-West) 컴퓨팅 통신을 위해 노드당 8개의 ConnectX-8 SuperNIC(어댑터당 최대 800Gbps)가 탑재되어 GPU와 NIC 간 1:1 매칭을 이룹니다.
-
-
플랫폼 노드 (Master & Worker - Dell PowerEdge R670): Palantir Foundry 서비스(Catalog, Alta, Multipass 등)와 Kubernetes 컨트롤 플레인을 구동하는 전용 CPU 노드입니다.
-
스펙: 2개의 Intel Xeon 6 Performance 프로세서와 1TB의 DDR5 메모리를 탑재합니다.
-
스토리지 최적화: Foundry의 온톨로지 워크로드는 CEPH 기반 객체 스토리지에 크게 의존하므로, PCIe Gen5 NVMe 드라이브(총 12개, FIPS 암호화 지원)를 사용하여 낮은 지연 시간과 높은 처리량을 보장합니다.
-
3중 패브릭 기반의 Spectrum-X 네트워크 아키텍처
이번 아키텍처에서 가장 주목할 점은 모든 네트워크가 이더넷(Ethernet) 기반으로만 표준화되었다는 것입니다. Palantir Rubix/Apollo의 IP 기반 네트워킹 및 다중 테넌트 격리 요구사항으로 인해 InfiniBand는 지원되지 않습니다.
-
컴퓨팅 네트워크 (East-West Network): GPU 간의 분산 학습과 빠른 통신을 위한 패브릭입니다. ConnectX-8 SuperNIC를 사용하여 노드당 400 GB/s (8x 400 Gb/s)의 막대한 대역폭을 제공하며, RoCE (RDMA over Converged Ethernet) 및 레일 최적화된(Rail-optimized) 스파인-리프(Spine-Leaf) 토폴로지를 사용합니다.
-
컨버지드 네트워크 (North-South Network): 스토리지와 인밴드(In-band) 관리를 위한 융합형 네트워크입니다. 컴퓨팅 패브릭과 독립적으로 구성되어 성능 간섭을 막고, 노드당 2개의 400GbE (또는 200GbE) 포트를 사용하여 CEPH 스토리지 접근 및 고객 네트워크와의 연동을 처리합니다.
-
아웃 오브 밴드 (OOB) 관리 네트워크: 서버의 BMC/iDRAC 및 스위치 관리 포트를 연결하는 물리적으로 격리된 1GbE 네트워크입니다. 이 모든 네트워크 운영 상태는 NVIDIA NetQ 도구를 통해 실시간 모니터링 및 문제 해결이 가능합니다.
엔터프라이즈 규모에 맞춘 자율적 확장성 (Scalable Units)
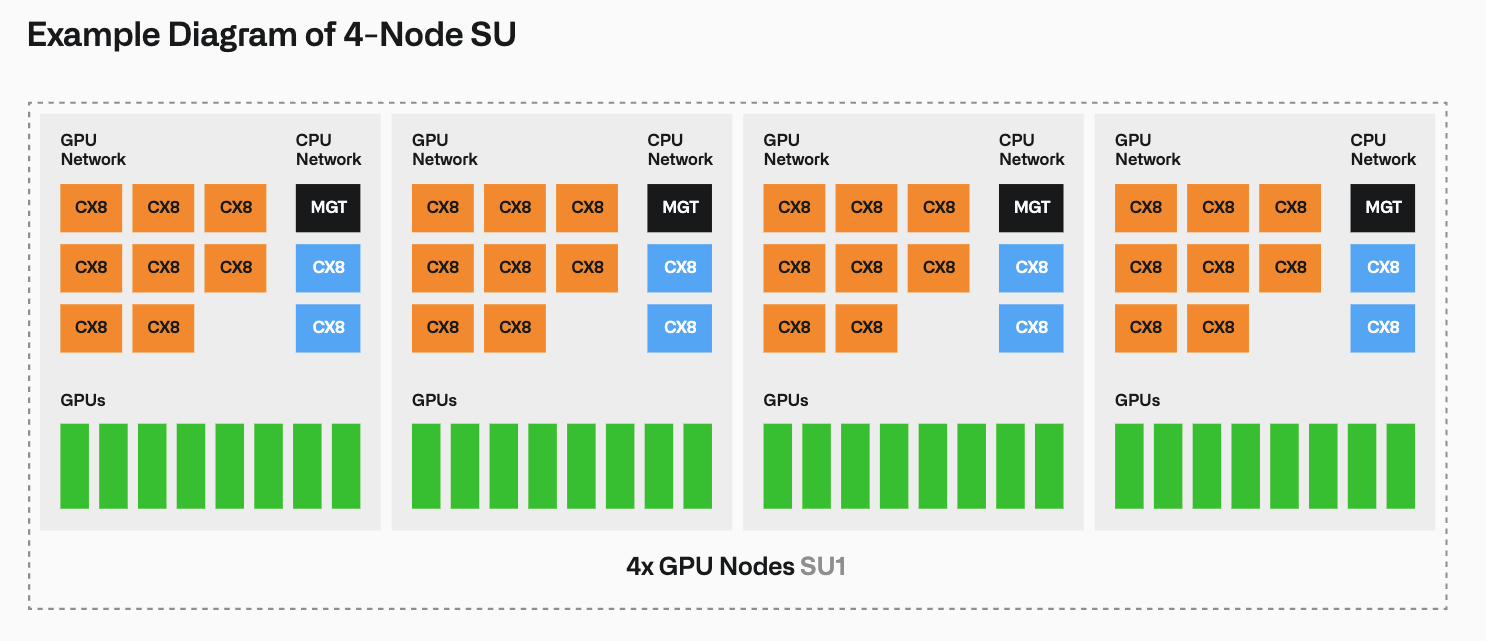
이 인프라는 4개의 GPU 노드를 하나로 묶은 '확장 단위(Scalable Unit, SU)'를 기반으로 모듈식으로 설계되어 조직의 크기와 요구에 맞춰 유연하게 도입할 수 있습니다.
-
Small (부서급 파일럿 및 특수 워크로드): 3개의 Master 노드, 9개의 Worker 노드로 구성되며, 1~4개의 SU (32~128개 GPU)를 지원합니다.
-
Medium (전사적 AI 및 다중 테넌트 프로덕션): 3개의 Master 노드, 21개의 Worker 노드로 구성되며, 4~10개의 SU (128~320개 GPU)를 지원합니다.
-
Large (대규모 미션 크리티컬 워크로드): 3개의 Master 노드, 45개의 Worker 노드로 구성되며, 10~20개의 SU (320~640개 GPU)까지 대규모 확장이 가능합니다.
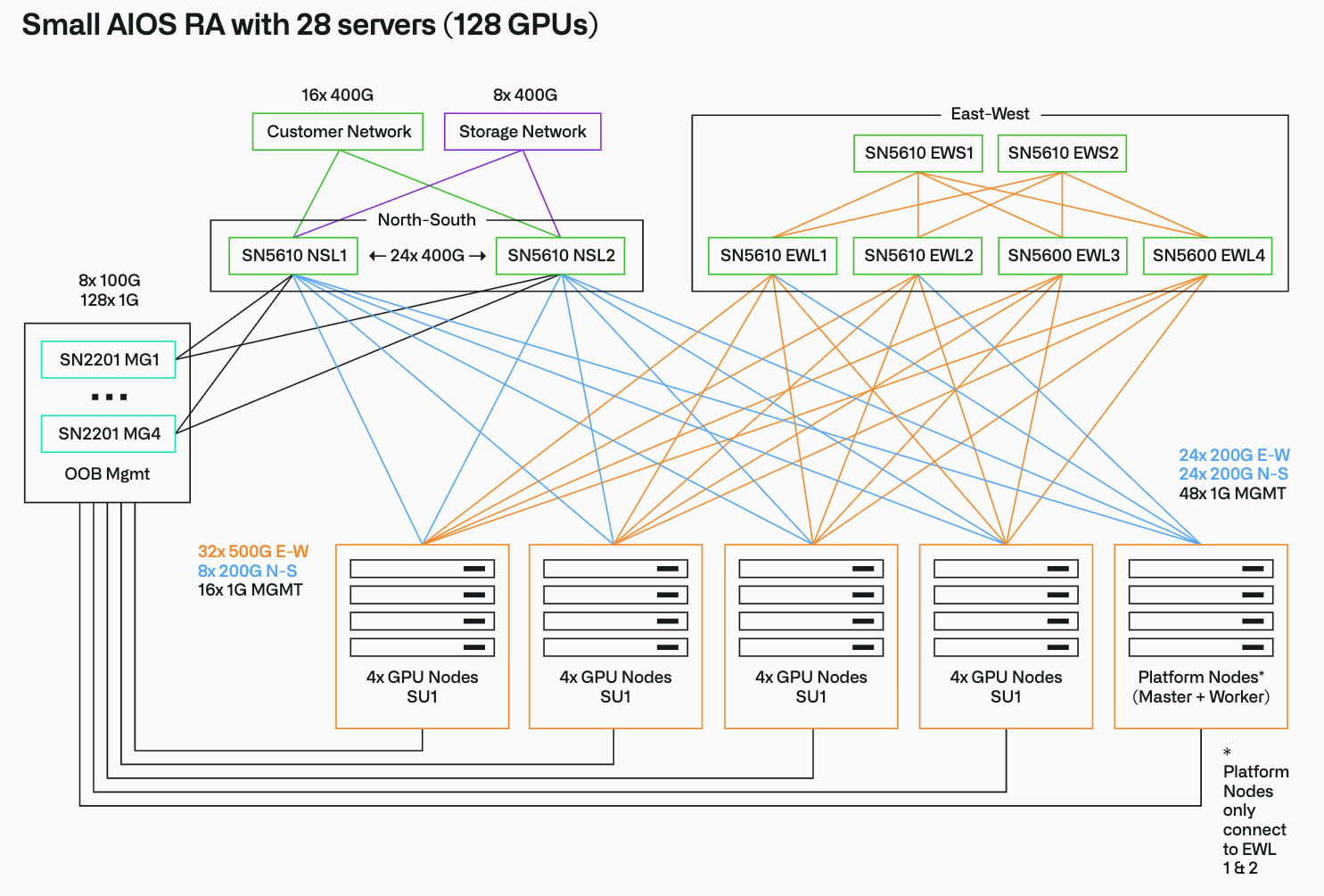
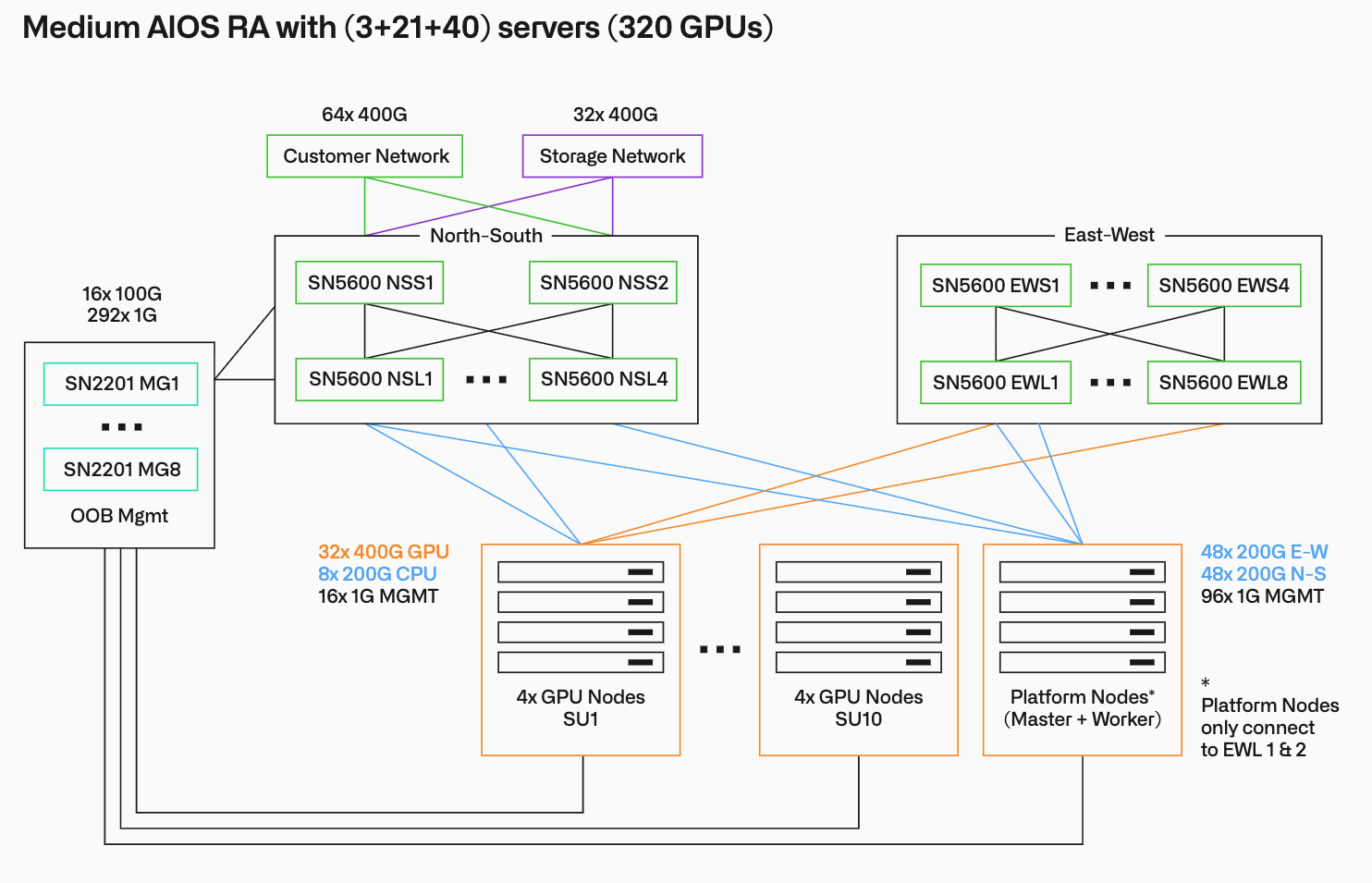
이러한 도입 프로세스는 ① 하드웨어 조달 → ② Apollo 부트스트랩(환경 구성) → ③ Rubix(강화된 쿠버네티스 기저) 배포 → ④ Foundry 서비스 배포 → ⑤ 고객 데이터 연동을 통한 AIP 활성화 → ⑥ 모델 및 워크플로우 배포라는 체계적인 6단계 파이프라인을 거쳐 자율적으로 완료됩니다.
Palantir Sovereign AI OS의 주요 특징
에어갭 및 폐쇄망을 위한 차세대 온프레미스 인프라 (Rubix & Apollo)
개발자와 인프라 엔지니어 관점에서 온프레미스 환경의 가장 큰 고충은 분산된 클러스터의 관리와 소프트웨어의 지속적인 업데이트입니다. Palantir Sovereign AI OS는 오픈소스 쿠버네티스의 한계를 극복하기 위해 Palantir의 독자적인 플랫폼인 Apollo와 제로 트러스트(Zero-trust) 기반의 강화된 쿠버네티스 기저인 Rubix를 통합 관리 플레인(Unified Management Plane)으로 채택했습니다.
Rubix는 엄격한 네트워크 격리가 필요한 환경에서도 다중 테넌트(Multi-tenancy) 간의 철저한 보안을 보장하며, 컨테이너 수준에서의 권한 통제를 수행합니다. 여기에 결합된 Apollo는 자율 배포(Autonomous deployment) 및 라이프사이클 관리를 담당합니다. 인터넷 연결이 단절된 에어갭 환경이나 군사 작전 지역과 같은 엣지 환경에서도, Apollo는 소프트웨어 버전의 일관성을 유지하고 롤백 및 종속성 관리를 자동화하여 DevOps 엔지니어의 운영 부담을 획기적으로 줄여줍니다. 이는 기존의 수동적인 온프레미스 관리를 '클라우드 네이티브' 수준의 경험으로 끌어올리는 차세대 인프라의 핵심입니다.
대규모 언어 모델(LLM)과 온톨로지 기반의 철저한 데이터 주권 확립 (AIP)
보안이 생명인 국가 기관 및 엔터프라이즈 환경에서는 LLM이 조직의 민감한 데이터에 무분별하게 접근하는 것을 반드시 차단해야 합니다. 이 아키텍처의 중심에는 기업의 데이터와 AI 모델을 안전하게 연결하는 Palantir AIP(Artificial Intelligence Platform)가 자리 잡고 있습니다.
AIP는 조직의 파편화된 데이터를 통합하여 의미론적 모델인 온톨로지(Ontology)를 구축합니다. 중요한 점은 철저한 역할 기반 접근 제어(RBAC, Role-Based Access Control)가 모델의 추론 과정 깊숙이 통합되어 있다는 것입니다. 사용자가 LLM에 질의를 던질 때, 시스템은 사용자의 보안 등급과 접근 권한을 실시간으로 평가하여, 오직 권한이 있는 데이터만을 컨텍스트로 활용해 답변을 생성합니다. 이를 통해 국방이나 금융과 같은 특수 환경에서도 데이터 유출(Data exfiltration)의 위험 없이 생성형 AI의 강력한 추론 능력을 비즈니스 및 작전 워크플로우에 안전하게 도입할 수 있습니다.
실무 엔지니어를 위한 강력한 MLOps 및 개발자 경험(DX) 제공
새로운 인프라가 도입되더라도 내부 개발자와 데이터 사이언티스트들이 이를 원활하게 활용하지 못한다면 무용지물입니다. Palantir Sovereign AI OS는 70개 이상의 워크플로우 도구 생태계를 통해 조직 내 자체적인 AI 개발 및 MLOps 파이프라인 구축을 지원합니다.
NVIDIA 인프라 위에서 구동되는 AIP FDE, AIP Assist, AIP Analyst 등의 도구들은 내부 엔지니어들이 복잡한 코딩 없이도 AI 워크플로우를 시각적으로 설계하고 배포할 수 있도록 돕습니다. 데이터 사이언티스트들은 NVIDIA의 CUDA-X 라이브러리와 가속화된 컴퓨팅 파워를 활용하여 조직 내부의 폐쇄망 데이터를 바탕으로 오픈소스 및 상용 모델을 빠르고 안전하게 미세 조정(Fine-tuning)할 수 있습니다.
이렇게 파인튜닝된 모델들은 즉시 사내 애플리케이션에 API 형태로 배포되어, 개발자들이 프롬프트 엔지니어링과 비즈니스 로직을 쉽게 결합할 수 있는 최적의 개발자 경험을 선사합니다.
양사 전진 배치 엔지니어(FDE)를 통한 밀착 지원 모델
Palantir Sovereign AI OS의 특별한 점은 하드웨어와 소프트웨어의 통합에서 그치지 않고, 양사의 최고급 엔지니어 인력이 현장에 직접 투입되는 밀착 지원(FDE, Forward Deployed Engineer)을 포함한다는 것입니다.
-
NVIDIA FDE: 고객의 데이터센터에 최적화된 형태로 GPU 클러스터를 구성하고, 특수한 레이턴시(Latency) 요구사항에 맞춰 모델 추론 속도를 최적화합니다. 또한 다단계 추론(Multi-step reasoning) 등 복잡한 태스크를 위한 맞춤형 모델 훈련을 기술적으로 지원합니다.
-
Palantir FDE: 도입 기관의 특수한 도메인 지식(Tradecraft)을 AI 애플리케이션으로 구현하는 데 집중합니다. 내부 규제와 거버넌스를 충족하는 데이터 파이프라인을 설계하고, 기관 내부의 소프트웨어 엔지니어 및 데이터 팀에게 기술과 노하우를 전수하여 궁극적으로 자립적인 운영이 가능하도록 돕습니다.
 Palantir Sovereign AI OS 홈페이지
Palantir Sovereign AI OS 홈페이지
 Palantir Sovereign AI OS 레퍼런스 아키텍처 소개 (PDF)
Palantir Sovereign AI OS 레퍼런스 아키텍처 소개 (PDF)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()