
GPT-NL 소개
GPT-NL은 네덜란드가 자국어와 자국의 사회적 맥락을 위해 처음부터 직접 학습한 주권형 언어 모델(Sovereign Language Model) 입니다. 네덜란드의 대표 응용연구기관인 TNO가 국가 연구·교육 인프라를 담당하는 SURF, 법무·안전부 산하 네덜란드 포렌식 연구소(NFI, Nederlands Forensisch Instituut)와 함께 개발하고 있으며, 경제기후정책부를 대신해 네덜란드 기업청(RVO)이 총 1,350만 유로(약 200억 원)를 투자한 공공 프로젝트입니다.
GPT-NL이 주목받는 이유는 단순히 "또 하나의 거대 언어 모델(LLM)"이기 때문이 아닙니다. 대부분의 최신 LLM이 미국 빅테크의 손에서 만들어지고, 출처가 불분명한 웹 스크래핑 데이터로 학습되며, 저작권과 개인정보 문제에서 자유롭지 못한 상황에서, GPT-NL은 "공공의 가치와 강력한 AI가 양립할 수 있다" 는 것을 실제로 증명하려는 시도이기 때문입니다. 데이터를 어디서 어떻게 모았는지 투명하게 공개하고, 데이터를 제공한 창작자에게 수익의 일부를 되돌려주며, 모델 전체를 유럽의 법과 가치에 맞춰 통제 가능한 형태로 운영하는 것이 핵심 목표입니다.
이러한 흐름은 한국에서도 낯설지 않습니다. 자국의 데이터·언어·가치를 반영한 소버린 AI(Sovereign AI) 에 대한 관심은 전 세계적으로 빠르게 커지고 있으며, 네이버의 HyperCLOVA X SEED처럼 한국형 소버린 AI 생태계를 향한 움직임도 본격화되고 있습니다. 이 글에서는 2026년 2월 26일 발행된 GPT-NL의 두 번째 진행 보고서(Progress Report #2)를 바탕으로, 유럽의 한 작은 나라가 제한된 예산으로 어떻게 "깨끗하고 합법적인" 국가 언어 모델을 만들어가고 있는지, 그리고 그 과정에서 어떤 도전과 시사점이 있었는지를 정리합니다.
네 가지 핵심 가치: 신뢰, 투명, 호혜, 주권
GPT-NL은 책임 있는 AI(Responsible AI)라는 TNO의 비전 위에서 네 가지 가치를 중심에 둡니다. 이 가치들은 단순한 구호가 아니라, 데이터 수집부터 모델 배포까지 모든 설계 결정의 기준이 됩니다.
주권(Sovereign): GPT-NL은 네덜란드와 유럽 안에서 개발되어, 모델·데이터·선택에 대한 완전한 통제권을 확보합니다. 비유럽 공급자에 대한 의존을 피하고, 자국의 법과 가치, 사회적 목표에 부합하는 지속 가능한 AI 생태계에 투자하는 것을 지향합니다.
투명(Open and Transparent): 데이터 수집과 학습 과정에서 내린 선택, 그리고 편향(bias)이나 윤리적 우려 같은 위험을 어떻게 다루는지를 명확히 문서화합니다. 소스 코드는 오픈소스로 공개하고, 데이터셋에 대한 상세한 정보도 함께 공유합니다. 모델 가중치(weights)는 통제된 라이선스(controlled licence) 아래 제공되어, 누가 모델을 사용하는지 파악하고 데이터 옵트아웃(opt-out) 등 변경 사항을 사용자에게 알릴 수 있도록 합니다.
신뢰(Trustworthy): GPT-NL은 기존 모델을 가져와 미세조정하는 대신 완전히 처음부터(from scratch) 학습합니다. 이를 통해 기존 모델로부터 출처가 불분명한 데이터, 저작권 위험, 잠재적 개인정보가 그대로 상속되는 것을 원천적으로 차단합니다.
호혜(Reciprocal): 깨끗하고 합법적인 데이터 공급망을 의도적으로 구축하고, 데이터 제공자와 긴밀히 협력하며 이들을 모델 개발 과정에 적극적으로 참여시킵니다. 콘텐츠 보드(Content Board)를 통해 데이터 제공자와 권리자가 GPT-NL의 미래에 목소리를 낼 수 있고, 수익의 일부는 창작자에게 환류됩니다. 가치를 일방적으로 추출(extract)하는 대신 공유(share)하는 더 공정한 혁신 모델을 만들겠다는 것입니다.
처음부터 직접 학습: 깨끗하고 합법적인 데이터 공급망
GPT-NL의 가장 큰 기술적·윤리적 차별점은 신뢰할 수 있는 토대를 위해 데이터 수집 단계에서부터 엄격한 기준을 적용했다는 점입니다. 모델 학습에 들어가기 전, 수집된 데이터는 다음 조건을 충족해야 합니다.
-
지식재산권 보호: 저작권이 있는 콘텐츠는 권리자와의 합의를 통해서만 사용합니다.
-
개인정보 제거 및 익명화: 학습 이전에 개인정보를 삭제하거나 익명화 처리합니다.
-
기밀정보 배제: 민감하거나 기밀에 해당하는 정보는 학습 데이터에서 제외합니다.
-
유해 콘텐츠 배제: 해로운 콘텐츠를 걸러냅니다.
-
중복 제거: 데이터셋 내의 중복을 피해 학습 효율과 품질을 높입니다.
AI 개발에는 막대한 연산 자원과 에너지가 필요합니다. GPT-NL 팀은 과학적 연구를 바탕으로 모델의 크기와 학습 과정을 최적화하면서, 에너지와 물 소비량까지 명시적으로 고려하는 에너지 효율을 함께 추구하고 있습니다. 제한된 예산(1,350만 유로)과 공적 책임이라는 두 가지 제약이, 역설적으로 "더 작고 더 효율적인" 모델을 설계하도록 이끈 셈입니다.
두 번째 해의 성과와 도전
보고서의 첫 장은 제품 책임자 사스키아 렌싱크(Saskia Lensink)와 R&D 책임자 프랑크 브링크켐퍼르(Frank Brinkkemper)의 대담으로 시작합니다. 1년 전만 해도 GPT-NL은 "건설 현장의 비계(steiger)" 단계, 즉 아직 뼈대를 세우는 중이었지만, 2026년에 들어서며 새로운 국면에 접어들었다는 평가입니다.
가장 자랑스러운 성과로 두 사람은 입을 모아 상업 뉴스 미디어와의 라이선스 합의를 꼽았습니다. 뉴스 산업 협회인 NDP Nieuwsmedia를 통해 체결한 이 합의로 크고 질 높은 데이터셋을 확보했을 뿐 아니라, 다른 데이터 제공자들에게도 중요한 신호를 보냈다는 것입니다. 기술적으로도 당초 예상보다 훨씬 많은 데이터를, 법적·윤리적으로 문제없는 방식으로 모았다는 점을 큰 성과로 평가합니다.
기술적 진척도 분명합니다. 팀은 1,350만 유로의 예산으로 모델의 사전학습(pre-training) 을 이미 완료했습니다. 사스키아 렌싱크는 "요약(summarizing) 같은 특정 작업에서는 GPT-NL이 ChatGPT-3(GPT-3) 같은 구형 모델보다 더 나은 성능을 보인다" 며, "당시 그 모델들이 어떤 예산으로 만들어졌는지를 생각하면 상당히 특별한 일" 이라고 강조했습니다. 모델 검증에는 표준 벤치마크가 활발히 쓰입니다. 예컨대 긴 텍스트를 모델에 주고 요약하게 한 뒤 검증된 참조 요약과 비교하는 식입니다. 프랑크 브링크켐퍼르는 EuroEval 같은 벤치마크가 이제 시장의 표준으로 자리 잡았다고 언급하면서, 네덜란드어에 완벽히 맞춰진 것은 아니지만 팀에서 보정 작업을 거쳐 성능을 제대로 비교하고 있다고 설명했습니다.
물론 도전도 만만치 않았습니다. GPT-NL은 약 25명의 비교적 작은 팀이 여러 조직에 흩어진 채, 제한된 예산으로 진행하는 복잡한 프로젝트입니다. 그러면서도 법적·윤리적 측면을 제대로 지켜야 한다는 부담이 컸습니다. 다만 지난 한 해 동안 법적 프레임워크가 한결 명확해졌고, 유능한 법률가들이 합류하면서 "데이터를 수집하고, 그것을 문서로 남기는" 안정적인 작업 방식을 찾았다는 점이 큰 도움이 되었다고 합니다.
가장 의외였던 점으로는 금융 서비스 같은 분야에서 예상보다 훨씬 큰 관심이 쏟아진 것, 그리고 "첫 버전을 만들었다고 해서 끝이 아니라" 자본 집약적이고 장기적인 헌신이 필요한 일이라는 사실을 많은 이들이 뒤늦게 깨달았다는 점을 들었습니다. 사용자들로부터 가장 자주 받는 질문은 "GPT-NL이 미국 기업이 되어버리는 것은 아니냐" 는 주권에 대한 우려였는데, 프랑크는 "GPT-NL은 공공 조직에 뿌리내리고 있으며, TNO는 결코 미국 기업이 되지 않을 것" 이라고 단언했습니다.
첫 도입 고객(Launching Customers): GPT-NL의 실제 사용 사례
새로운 국면의 핵심은 모델을 실제 현장에 투입하는 것입니다. GPT-NL 팀은 2026년 2월부터 소수의 첫 도입 고객(Launching Customers) 그룹과 함께 작업을 시작했습니다. 우선 5개 조직과 시작해 10개까지 확대하는 것이 목표이며, 각 조직과는 먼저 실현 가능성 연구(Feasibility Study) 를 진행합니다. GPT-NL이 해당 조직의 맥락에서, 그들의 하드웨어 위에서, 그들의 구체적인 사용 사례에 대해 어떻게 작동하는지를 검증하는 단계입니다. 참여 조직은 정부 부처, 안보 영역, 대형 금융기관 등 개인정보 보호와 컴플라이언스가 결정적으로 중요한 곳들입니다.

보고서에 공개된 공공 부문의 첫 사용 사례는 모두 내무부(Ministerie van Binnenlandse Zaken)의 지원으로 진행됩니다.
-
챗봇 'Gem' (ICTU 협력): 약 30개 지방자치단체가 6년째 매일 사용하는 챗봇으로, 2024년 한 해에만 약 7만 건의 대화를 처리했습니다. 이 사용 사례에서는 사용자 질문에 답하는 데 GPT-NL이 더하는 가치를 검증하고, 지자체 업무에 실제로 관련된 질문 맥락에서 답변 품질을 평가합니다.
-
Overheid.nl 디지털 어시스턴트 (Overheid.nl 협력): 시민과 사업자가 정부 서비스에 대한 정보를 찾기란 쉽지 않습니다. 여러 정부 기관의 웹사이트에 정보가 흩어져 있기 때문입니다. 내무부는 신뢰할 수 있는 Overheid.nl의 정보를 바탕으로 답변하는 디지털 어시스턴트를 만들고 있으며, GPT-NL의 답변을 현재 쓰이는 상용 모델의 답변과 비교합니다.
-
정부 공문서 작성 보조 'HIP' (PNA 협력): 정부가 보내는 공문은 채무나 수당처럼 중요한 내용을 다루면서도 늘 이해하기 쉬운 것은 아닙니다. 커뮤니케이션 보조 도구 HIP(Helder, Intelligent en Productief, 즉 명료하고 지능적이며 생산적인)는 공무원이 이해하기 쉬운 언어로 공문을 작성·점검하도록 돕습니다. 이 사례에서는 현재 HIP에 쓰이는 최고 성능 모델과 GPT-NL을 비교합니다.
여기에 더해, 두 곳의 GPT-NL 파트너 기관이 직접 내부 사용 사례를 검증하고 있습니다.

-
TNO 사내 도입: TNO의 많은 프로젝트는 보안 등급이 부여된 문서나 개인정보 민감 데이터를 다루며, 프라이버시·보안·컴플라이언스에 높은 기준을 요구합니다. TNO의 생성형 AI 도입 원칙은 "Copilot, 단(tenzij)", 즉 "원칙적으로 Copilot을 쓰되 예외가 있다"는 것인데, 바로 그 "예외"에 해당하는 영역을 GPT-NL로 다루려 합니다. 실현 가능성 연구는 GPT-NL을 자체 서버에 설치·운영하는 온프레미스(on-premise) 배포에 초점을 맞춰 그 부가가치를 검증합니다.
-
네덜란드 포렌식 연구소(NFI): 수사 업무에서 언어 모델은 이미 수년째 없어서는 안 될 도구입니다. 테라바이트 단위의 증거 자료를 분석하는 일은 거대한 과제이며, 사람이 그렇게 방대한 데이터를 일일이 파헤치기란 사실상 불가능합니다. 이 사례에서 GPT-NL은 포렌식 데이터로 미세조정(fine-tuning) 되며, 미세조정된 모델이 NFI가 현재 쓰는 모델보다 분류(classification) 작업에서 더 나은 성능을 내는지를 검증합니다.
GPT-NL에 참여해야 하는 다섯 가지 이유
보고서는 조직들이 첫 도입 고객으로 참여해야 하는 이유를 다섯 가지로 정리합니다. 이는 GPT-NL이 내세우는 가치 제안을 압축적으로 보여줍니다.
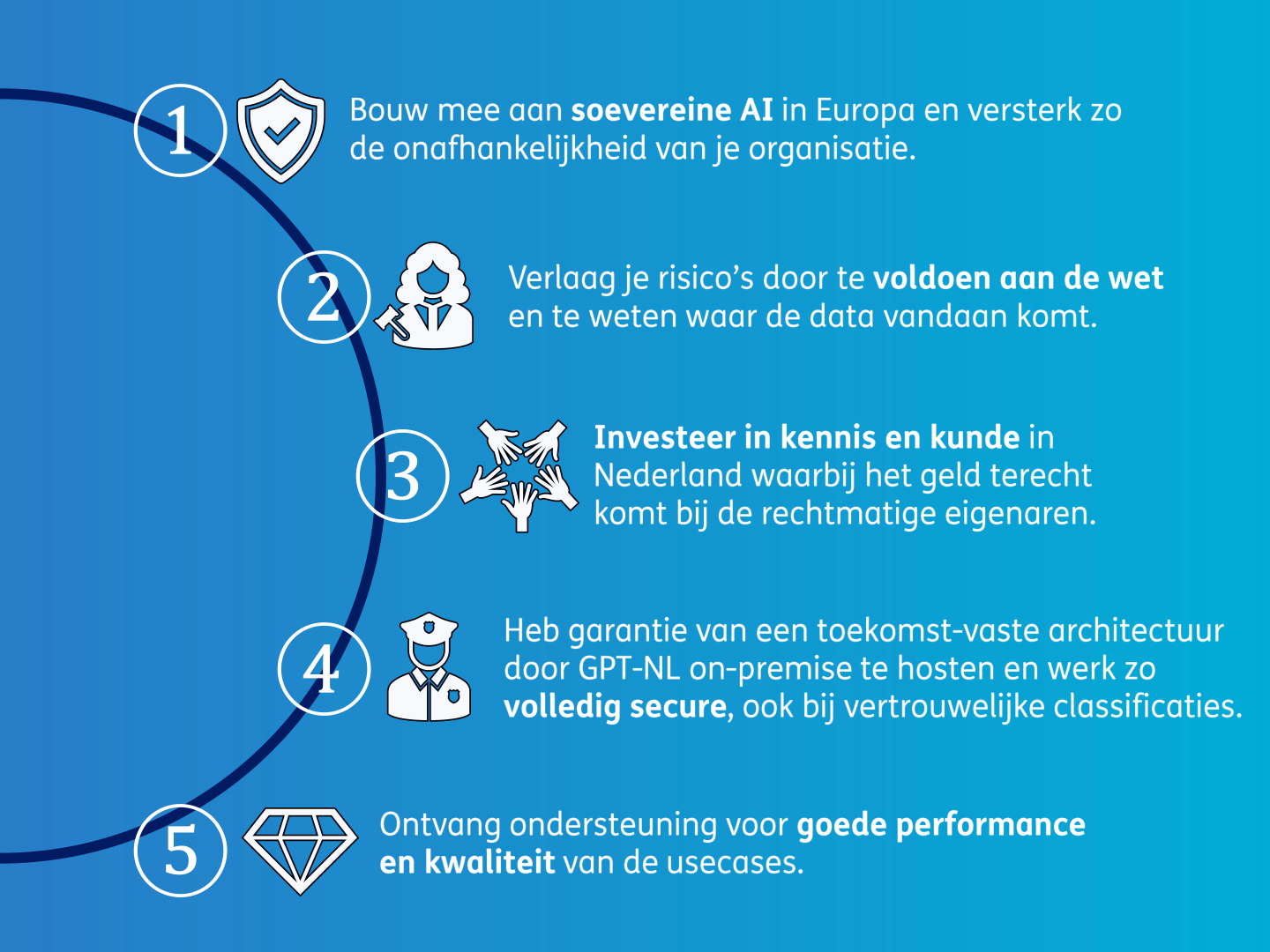
- 유럽의 주권형 AI 구축에 기여하여 조직의 독립성을 강화합니다.
- 법을 준수하고 데이터의 출처를 정확히 앎으로써 위험을 낮춥니다.
- 네덜란드의 지식과 역량에 투자하되, 그 돈이 정당한 권리자에게 돌아가도록 합니다.
- GPT-NL을 온프레미스로 호스팅하여 미래에도 견고한 아키텍처를 보장하고, 기밀 등급의 데이터에서도 완전히 안전하게 작업합니다.
- 사용 사례의 우수한 성능과 품질을 위한 지원을 받습니다.
흥미로운 점은, GPT-NL 팀이 "전 세계 최고의 모델과 곧바로 어깨를 나란히 할 필요는 없지만, 실무에서 가치를 더하는 제품은 반드시 만들어야 한다" 고 분명히 선을 그었다는 것입니다. 그리고 그것은 오직 실제 사용자 피드백을 통해서만 가능하다고 봅니다. 규모 경쟁이 아니라 실용성과 신뢰성에 초점을 맞춘 전략입니다.
콘텐츠 보드(Content Board): 거래가 아닌 생태계
이 보고서에서 기술적으로나 제도적으로 가장 흥미로운 부분은 GPT-NL 1.0을 위한 데이터 수집 과정을 다룬 심층 분석(Deep Dive)입니다. 데이터 수집 팀은 이를 "청사진 없이 시작하기(Beginnen zonder blauwdruk)" 라고 표현합니다.
상업 기업과 공공 기관을 아우르며 LLM 학습용 데이터를 모으는 이런 종류의 작업은, 시작 시점에 따라 할 수 있는 정해진 매뉴얼도, 그대로 베낄 수 있는 기존 생태계도 존재하지 않았습니다. TNO는 데이터 생태계 경험이 있었지만 GPT-NL은 그것과는 다른 무언가를 요구했고, 고전적인 연구 프로젝트처럼 다룰 수도 없었습니다. 결국 팀은 도서관, 대학, 미디어 기업, 문화유산 기관 같은 잠재적 데이터 제공자들과 공동 세션을 열며 "왜 기존 언어 모델의 대안을 만드는가", "왜 다른 데이터 제공자들과 함께 손잡는가", "당신의 데이터가 학습 데이터셋에 쓰이면 실제로 무슨 일이 벌어지는가" 를 설명하는 데 많은 시간을 쏟았습니다.
여기서 GPT-NL이 내린 핵심적인 선택이 바로 콘텐츠 보드(Content Board) 입니다. 데이터 제공자와의 관계를 단순한 거래(transaction)로 만들지 않겠다는 의식적 결정이었습니다. 참여 기관을 데이터의 "판매자(verkoper)" 로 자리매김하는 대신, "성공적인 언어 모델"이라는 공동의 목표를 가진 일종의 컨소시엄을 만든 것입니다. 참여 여부는 각 기관이 스스로 선택하며, 거버넌스를 설계하는 등 준비에 더 많은 공이 들지만 장기적으로 훨씬 견고한 구조라는 판단입니다.
이 접근은 데이터 기관을 향한 현실적인 메시지이기도 합니다. GPT-NL은 콘텐츠 제공자와 서로를 강화하는 생태계를 지향하며, 상업 LLM 공급자처럼 막대한 예산이나 별도의 수익 모델을 갖춘 "이익 창출 기계"가 아닙니다. 데이터를 경제적 자본으로 여기는 데 익숙한 기관들과는 솔직한 대화가 필요했습니다. 한 기관의 데이터는 그 자체로 가치 있는 경우가 드물고, "신뢰할 수 있고 컴플라이언스를 준수하며 사용 가능한 모델 안에서 다른 기관의 데이터와 맺는 관계 속에서 가치가 발생한다" 는 인식이 자리 잡았다는 것입니다.
호텔 캘리포니아 문제: 들어오고 나가는 자유
데이터 생태계 설계에서 까다로웠던 쟁점은 참여 기관이 자유롭게 들어오고 나갈 수 있는가였습니다. 처음에는 언제든 참여하고 탈퇴할 수 있게 한다는 계획이었지만, 개별 요청마다 이를 실현하기는 비현실적이었습니다. 모델을 계속 재학습할 수도 없고, 모든 GPT-NL 사용자가 최신 버전을 쓰도록 보장해야 하기 때문입니다. 그래서 한 기관이 탈퇴를 원할 경우 두 가지 선택지를 두었습니다. 하나는 해당 기관의 콘텐츠가 모델 출력에 다시 나타나지 않도록 조치하는 것이고, 다른 하나는 새 버전이 학습될 때까지 콘텐츠가 모델에 남아 있는 동안 보상을 받는 것입니다. "한 번 들어오면 영영 나갈 수 없는" 호텔 캘리포니아(Hotel California) 같은 느낌을 주지 않으면서도, 기술적으로 가능한 것이 무엇인지에 대해 정직하려는 시도입니다. 모든 데이터 제공자와의 라이선스 계약에는 동일한 규칙이 적용되며, 이 약정은 웹사이트에서 공개적으로 확인할 수 있습니다.
세계 최초의 뉴스 미디어 라이선스 합의
데이터 수집 과정의 중요한 이정표는 뉴스 산업 협회 NDP를 통한 상업 뉴스 미디어와의 라이선스 합의입니다. GPT-NL 팀은 이를 "전 세계에서 처음으로, 모든 발행사와 그들의 콘텐츠 사용 및 기여에 대한 공정한 보상에 합의한 사례" 라고 설명합니다. 전국지부터 NU.nl, RTL Nieuws, BNR Nieuwsradio 같은 플랫폼까지 두루 참여했습니다.
이 합의가 특별한 이유는, 뉴스 미디어야말로 LLM 혁명에서 가장 큰 피해를 볼 수 있는 당사자이기 때문입니다. 뉴스 콘텐츠가 동의나 보상 없이 대량으로 스크래핑되어 LLM 학습에 쓰이고, 그렇게 만들어진 모델이 다시 (거의) 무료로 뉴스를 생성해 제공하는 구조 속에서, 이런 합의가 저절로 성사될 리 없었습니다. 정당한 우려가 있었던 것입니다. 팀은 이 우려에 귀 기울인 결과, 라이선스가 적용된 자료가 기술적인 방법으로 모델에서 추출되는 것을 막는 추가 조치까지 설계에 반영했습니다.
"우리는 이 움직임으로 네덜란드 저널리즘의 위치를 장기적으로 강화하는 선례를 만들고 있습니다. AI 혁신은 저널리스트의 작업물을 대규모로 부당하게 사용하지 않고도, 윤리적이고 책임 있는 방식으로 이뤄질 수 있습니다."
"We scheppen met deze beweging een precedent waarmee we de positie van de journalistiek in Nederland op termijn verstevigen."
리엔 판 베이먼(Rien van Beemen), NDP Nieuwsmedia 회장
라이선스 계약 외에도 팀은 네덜란드의 공공 데이터(정부 정보, 판례 등)를 LLM 학습에 적합한 형태로 한곳에 모으는 데 상당한 노력을 기울였습니다. 이 과정에서 공공 기관들과 Open State Foundation의 큰 도움을 받았으며, 해당 데이터는 2026년 1분기에 HuggingFace에 공개될 예정입니다.

GPT-NL 1.0 데이터셋에는 NDP Nieuwsmedia, ANP, 네덜란드어 연구소(Instituut voor de Nederlandse Taal), KB 국립도서관, DANS, Overheid.nl, Wikiwijs, de Rechtspraak(사법부), Tweede Kamer(하원), VNG(지자체 협회), DNB(네덜란드 중앙은행), 유럽의회 등 뉴스·공공·학술·문화유산을 아우르는 폭넓은 기관들이 참여했습니다. 저작권이 있는 콘텐츠에 대해서는 데이터셋 전체 구성의 투명성을 위해 메타데이터를 함께 공개합니다.
데이터 수집에 깊이 관여한 법률가 마레인 스토름(Marijn Storm)은 이 과정의 차별성을 이렇게 요약합니다.
"GPT-NL 세션에 참여한 모든 사람이 느꼈습니다. 이것은 당신의 데이터를 빅테크 기업에 파는 것과는 완전히 다른 일이라는 것을요. 문서화, 개방성, 학습 이전의 데이터 정제, 이런 것은 다른 어디서도 볼 수 없습니다."
디지털 주권의 절박함: 로케 모럴(Lokke Moerel)의 시각
GPT-NL의 개발은 틸뷔르흐 대학교(Tilburg University) 글로벌 ICT 법 교수이자 법률사무소 Morrison Foerster의 파트너인 로케 모럴(Lokke Moerel)의 법적 전문성 없이는 불가능했습니다. 기술과 입법이 만나는 지점의 전문가인 그는, 정부·기업·사회 조직이 대부분 비유럽 클라우드 플랫폼과 오피스 소프트웨어, AI 도구에 의존하고 있는 현실의 위험을 매일 목격합니다. 이 의존은 프라이버시나 컴플라이언스 때문만이 아니라 지정학적 불확실성 때문에도 점점 더 문제가 되고 있다는 것입니다.
모럴은 디지털 주권을 시급한 통점(urgent pijnpunt) 으로 규정합니다. 주권형 AI는 더 넓은 디지털 기반의 일부가 되어야 하며, 이는 이념적 주장이 아니라 전략적 필요라는 것입니다. 그래서 그는 신중하게 설계된 두 갈래 정책(tweesporenbeleid) 을 제안합니다. 한편으로는 유럽의 규제와 공공 가치에 부합하는 자체 디지털 인프라와 서비스에 투자하고, 다른 한편으로는 글로벌 네트워크 안에서 주권을 능동적으로 확보해 유럽이 단일 실패 지점(single point of failure)에 의존하지 않도록 하는 것입니다. 고립이 아니라, "취약해지지 않으면서 함께 협력할 수 있을 만큼 충분히 강한 위치" 를 확보하는 것이 목표입니다.
그가 GPT-NL을 특히 중요하게 보는 이유는, 규칙을 만드는 것만으로는 부족하기 때문입니다. 유럽은 규제에는 강하지만 그것만으로는 충분치 않다는 것입니다.
"빅테크와 거대 언어 모델이 개발되는 방식을 비판할 수도 있습니다. 아니면, 좋은 대안을 직접 만들 수도 있습니다."
"Je kunt kritiek hebben op Big Tech en op de manier waarop large language models worden ontwikkeld, óf je bouwt een goed alternatief."
로케 모럴(Lokke Moerel)
모럴은 "다른 이들이 만드는 기술에 대해 규칙만 만든다면, 늘 현실에 뒤처질 수밖에 없다" 며, "기술을 직접 개발하지 않으면 외국 공급자의 수액(infuus)에 매달린 채 협상력을 갖지 못한다" 고 지적합니다. 그는 GPT-NL이 이미 일으킨 연쇄 반응에 주목합니다. 다른 유럽 회원국들이 이 프로젝트를 지켜보며, 공공과 민간이 협력하는 생태계가 법적·조직적으로 어떻게 구성되었는지 묻기 시작했다는 것입니다.
동시에 그는 GPT-NL이 처한 단계에 대해 현실적입니다. "여기는 아직 어딘가 스타트업 같은 면이 있다" 면서도, 진짜 도전은 "이것을 어떻게 확장 가능하고 사회의 구조적 일부가 되는 무언가로 만드느냐" 에 있다고 봅니다. 그러려면 더 많은 역량과 투자, 시장 및 공공 조직과의 더 강한 연결, 그리고 무엇보다 "주권적 대안에는 돈이 든다는 사실을 인정할 용기" 가 필요하다고 강조합니다. 향후 GPT-NL이 주권형 클라우드 환경에서 SaaS 형태로 제공되고, 네덜란드와 유럽의 사업자들이 단순히 호스팅하는 데 그치지 않고 기술을 직접 개발·관리·발전시키는 인프라로 이어지기를 그는 기대합니다.
"바로 누구도 다르게 될 수 있다고 더는 상상하지 못할 때, 실제로 가능하다는 것을 보여줘야 합니다. GPT-NL이 그 증거입니다. 이제는 규모를 키울 때입니다."
로케 모럴(Lokke Moerel)
향후 계획과 시사점
보고서의 마지막 부분은 2026년의 계획을 문답 형식으로 정리합니다. 핵심을 추리면 다음과 같습니다.
-
더 넓은 도입 시점: 1분기에는 첫 도입 고객들이 먼저 시작해 앞서나가고, 더 넓은 확산(rollout)은 2026년 하반기로 예정되어 있습니다. 이때부터 전문 라이선스(professional licence)를 통해 GPT-NL을 이용할 수 있으며, 호스팅 사업자를 통한 호스티드 버전도 준비 중입니다.
-
연구 목적 이용: 연구자를 위한 이용도 하반기의 넓은 확산과 함께 가능해질 전망입니다.
-
v1.0 데이터셋 공개: GPT-NL 1.0의 공개 데이터셋은 2026년 1분기에 HuggingFace에 공개될 예정이며, 저작권 보호 콘텐츠에 대해서는 메타데이터를 공개해 데이터셋 구성의 투명성을 제공합니다.
-
차기 버전(v2.0)을 위한 데이터 수집: 현재는 실현 가능성 연구와 하반기 확산 준비에 집중하고 있으며, 이후 GPT-NL v2.0을 위한 본격적인 콘텐츠·데이터셋 수집을 시작할 예정입니다.
-
기능 로드맵: 단기적으로는 개선된 검색 증강 생성(RAG, Retrieval-Augmented Generation) 기능과 음성(speech) 지원에 착수하며, 중장기적으로는 여러 언어와 기능을 지원하는 강력한 후속 모델의 가능성을 검토하고 있습니다.
GPT-NL 사례가 한국의 AI 커뮤니티에 던지는 시사점은 분명합니다. 첫째, "규모 경쟁에서 곧바로 승리하지 않아도, 자국어와 자국 맥락에서 실제 가치를 더하는 모델" 이라는 목표 설정은, 제한된 자원으로 소버린 AI를 추진하는 어떤 나라에도 현실적인 전략적 좌표가 됩니다. 둘째, 콘텐츠 보드와 NDP 라이선스 합의처럼 데이터 제공자(특히 뉴스·창작 산업)와의 관계를 거래가 아닌 생태계로 설계한 시도는, 저작권과 데이터 보상이 전 세계적 쟁점이 된 지금 중요한 제도적 참고 사례입니다. 마이크로소프트가 증류 없이 바닥부터 학습한 MAI 모델 패밀리를 공개하는 등 "from scratch" 학습이 다시 주목받는 흐름과도 맞닿아 있습니다. 셋째, "규칙만 만들 것이냐, 기술을 직접 만들 것이냐" 는 로케 모럴의 질문은, 규제와 산업 육성 사이에서 균형을 고민하는 모든 정부에 유효한 화두입니다.
GPT-NL은 모델 가중치를 통제된 라이선스로, 소스 코드를 오픈소스로 공개하고, 데이터셋 정보까지 투명하게 제공하는 방향을 택했습니다. 완성된 결과물이라기보다 "공공의 가치와 강력한 AI가 양립할 수 있음을 증명해가는 진행형 실험" 에 가까우며, 그래서 더 지켜볼 가치가 있습니다.
 GPT-NL 프로젝트 소개
GPT-NL 프로젝트 소개
GPT-NL Progress Report #2 (2026년 2월, 네덜란드어 PDF)
 GPT-NL 공식 홈페이지
GPT-NL 공식 홈페이지
더 읽어보기
-
[GN] 2026 기술 트렌드 보고서: AI 에이전트부터 소버린 AI, 피지컬 AI까지 [PDF/영문/102p]
-
Palantir, NVIDIA와 함께 엔터프라이즈 및 국가 기관을 위한 On-Premise용 Palantir Sovereign AI OS 공개
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()