
Pico-Banana-400K 소개
애플(Apple)이 공개한 Pico-Banana-400K는 약 40만 개의 텍스트 - 이미지 - 편집 결과의 삼중쌍(text-image-edit triplets) 으로 구성된, 텍스트 기반 이미지 편집(text-guided image editing) 연구를 위한 대규모 데이터셋입니다. 이 데이터셋은 오픈 이미지를 기반으로 생성된 원본 이미지, 사람처럼 자연스러운 편집 명령문, 그리고 AI 모델이 수행한 편집 결과를 포함합니다. 특히 Nano-Banana 모델이 실제 편집을 수행하고, Gemini-2.5-Pro 모델이 품질 평가를 수행하는 자동화된 검증 과정을 거쳤다는 점이 특징입니다.

이 데이터셋은 단순한 색조 변경부터 인물, 장면, 스타일 변환에 이르기까지 8개 범주, 35가지 편집 유형을 포함하고 있으며, 이를 통해 저수준(low-level) 조정과 고수준(high-level) 의미적 변형 모두를 다룰 수 있습니다. Pico-Banana-400K 데이터셋은 멀티턴(multi-turn) 편집이나, 보상 기반 학습(reward-based learning)과 같은 새로운 이미지 생성 패러다임을 실험하기 위한 기반 데이터가 될 것으로 기대합니다.
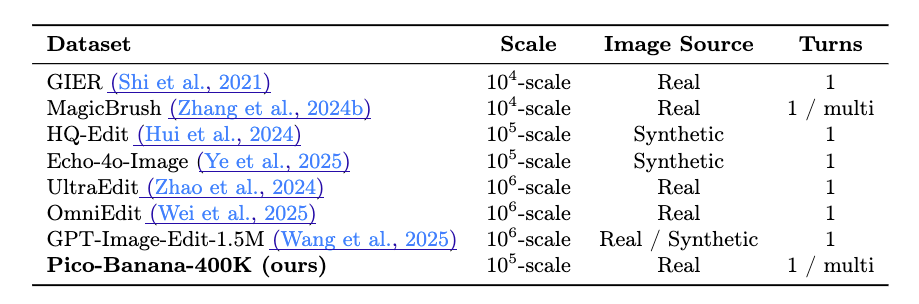
기존의 이미지 편집 데이터셋(예: InstructPix2Pix, T2I-Edit)은 대체로 데이터 규모가 제한적이며, 텍스트 지시문이 짧거나 단순하다는 한계가 있었습니다. 반면, Pico-Banana-400K는 약 40만 개의 고품질 트리플 데이터를 제공하며, Gemini 모델 계열이 생성한 자연어 지시문 덕분에 실제 사용자의 언어 습관에 근접한 표현을 학습할 수 있습니다.
또한 대부분의 기존 데이터셋은 단일 편집(single-turn)만을 다루지만, Pico-Banana-400K는 다중 편집(multi-turn editing) 시나리오를 지원하여 대화형 이미지 편집 모델 연구에도 활용이 가능합니다.
Pico-Banana-400K 데이터셋 구성 및 생성 과정

데이터 통계
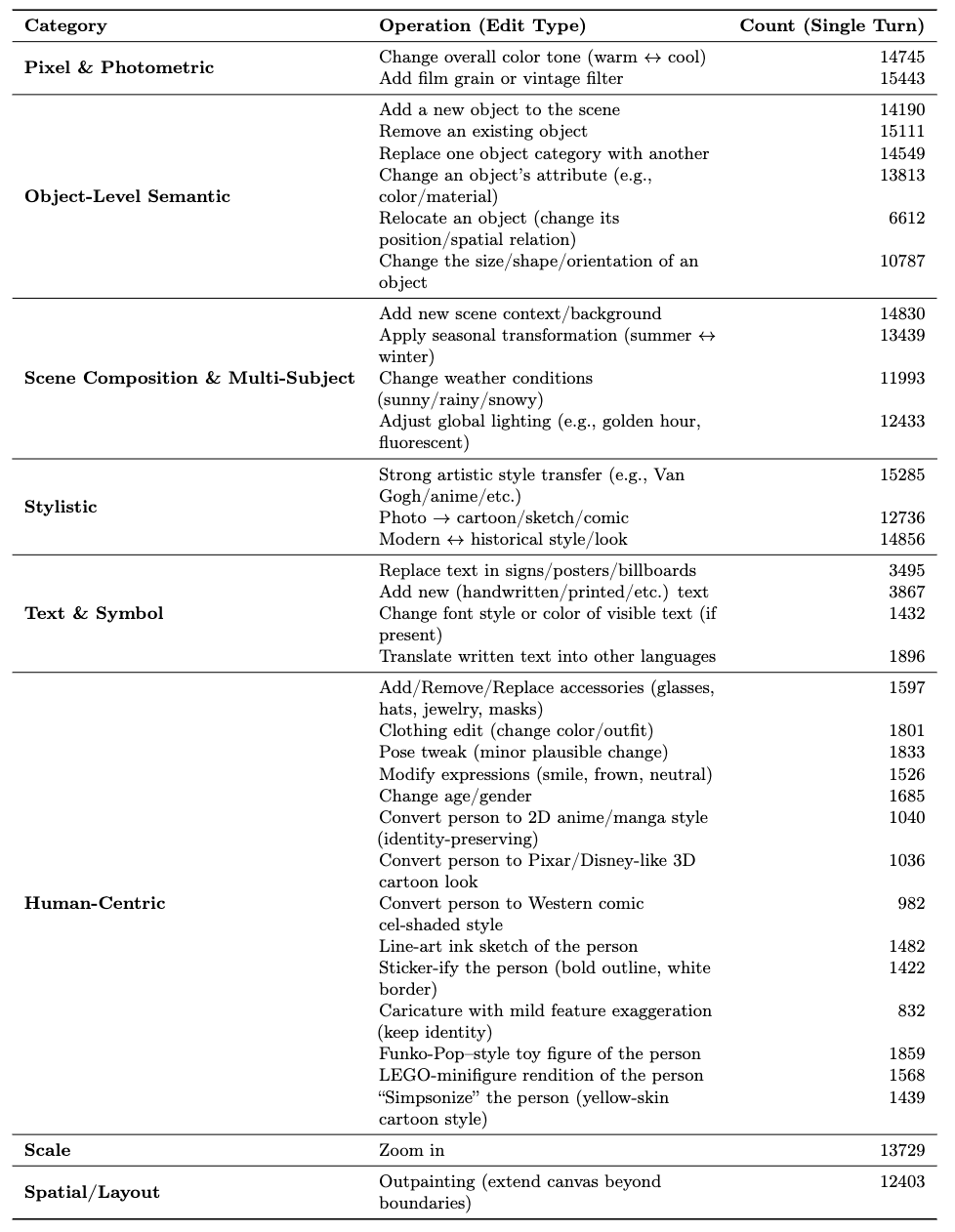
Pico-Banana-400K는 단일 편집과 다중 편집을 모두 포함하며, 다음과 같은 구성으로 이루어져 있습니다.
- 단일 편집(Single-Turn) 성공 사례: 약 257,000개
- 단일 편집 실패(Preference) 사례: 약 56,000개
- 다중 편집(Multi-Turn) 사례: 약 72,000개
이미지 해상도는 512~1024px이며, 인물, 텍스트, 사물, 장면 등 현실적인 이미지가 다양하게 포함되어 있습니다.
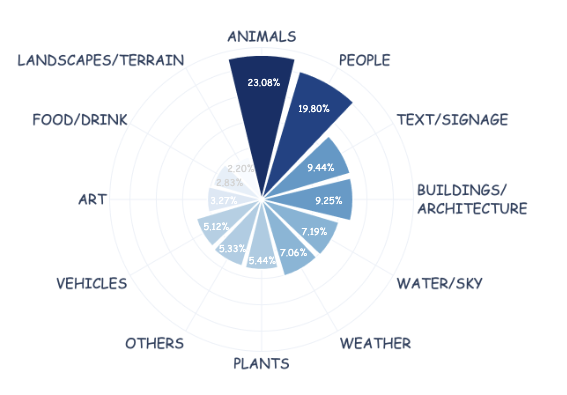
또한, 데이터셋의 편집 유형 분포는 다음과 같습니다:
| 범주 | 설명 | 비율 |
|---|---|---|
| 객체 수준(Object-Level) | 객체 추가, 제거, 교체, 재배치 | 35% |
| 장면 구성(Scene Composition) | 환경 및 맥락적 변환 | 20% |
| 인간 중심(Human-Centric) | 얼굴, 표정, 의상 등 | 18% |
| 스타일(Stylistic) | 예술적 스타일, 도메인 변환 | 10% |
| 텍스트/기호(Text & Symbol) | 간판, 텍스트 수정 | 8% |
| 픽셀/광도(Pixel & Photometric) | 밝기, 대비 등 조정 | 5% |
| 스케일/시점(Scale & Perspective) | 확대, 뷰포인트 변화 | 2% |
| 공간/레이아웃(Spatial/Layout) | 캔버스 확장, 재구성 | 2% |
데이터 생성 파이프라인
Pico-Banana-400K는 2단계 멀티모달 파이프라인을 통해 구축되었습니다.
-
지시문 생성 (Instruction Generation) 오픈 이미지(Open Images) 데이터의 각 샘플은 Gemini-2.5-Flash 모델을 통해 분석되며, 이미지의 시각적 내용에 기반한 간결하고 자연스러운 편집 지시문이 생성됩니다.예를 들어 "빨간색 자동차를 파란색으로 바꿔라"와 같은 문장이 자동 생성됩니다.이후 Qwen-2.5-Instruct-7B 모델이 이를 요약해 짧은 명령문 버전을 제공합니다.
-
편집 수행 및 자동 평가 (Editing + Self-Evaluation) 생성된 명령문은 Nano-Banana 모델에 입력되어 실제 이미지 편집이 수행됩니다.결과물은 다시 Gemini-2.5-Pro 모델의 품질 평가 시스템을 통해 점수화되며,평가 항목은 다음과 같습니다:

- 명령 수행 정확도(Instruction Compliance): 40%
- 편집의 사실성(Editing Realism): 25%
- 원본 유지 균형(Preservation Balance): 20%
- 기술적 품질(Technical Quality): 15%평균 점수가 0.7 이상인 경우만 성공 케이스로 분류되며, 나머지는 실패 데이터로서 선호도 학습(preference learning)에 활용됩니다.

Pico-Banana-400K 데이터셋의 주요 특징
- 다양한 편집 연산: 8개 의미적 범주, 35개 편집 연산 지원
- 다중 턴 대화형 데이터: 연속된 편집 명령 및 결과 포함
- 고품질 자동 평가: Gemini-2.5-Pro를 활용한 편집 품질 평가
- 실제 이미지 기반: Open Images 데이터셋에서 직접 추출
- 텍스트 생성 품질: Gemini-2.5-Flash 기반으로 인간 수준의 명령문 생성
이러한 특징 덕분에 Pico-Banana-400K 데이터셋을 텍스트 기반 이미지 생성, 멀티모달 보상 모델 학습, 대화형 이미지 조작 등 최신 연구 방향에 폭넓게 활용할 수 있습니다.
데이터 다운로드 가이드
Pico-Banana-400K는 애플의 공개 CDN에서 제공됩니다. 각 데이터 타입은 별도의 매니페스트 파일을 통해 접근할 수 있습니다.
- 단일 편집(SFT): sft_manifest.txt
- 선호도 학습(Preference): preference_manifest.txt
- 다중 편집(Multi-Turn): multi_turn_manifest.txt
원본 이미지는 라이선스 이슈로 Open Images에서 직접 다운로드해야 하며, GitHub 저장소의 매핑 스크립트(map_openimage_url_to_local.py)를 통해 URL과 로컬 파일을 연결할 수 있습니다.
상세한 내용은 아래 코드 및 GitHub 저장소의 README 파일을 참고해주세요:
# Install awscli if you don't have it (https://aws.amazon.com/cli/)
# Download Open Images packed files
aws s3 --no-sign-request --endpoint-url https://s3.amazonaws.com cp s3://open-images-dataset/tar/train_0.tar.gz .
aws s3 --no-sign-request --endpoint-url https://s3.amazonaws.com cp s3://open-images-dataset/tar/train_1.tar.gz .
# Create folder for extracted images
mkdir openimage_source_images
# Extract the tar files
tar -xvzf train_0.tar.gz -C openimage_source_images
tar -xvzf train_1.tar.gz -C openimage_source_images
# Download metadata CSV (ImageID ↔ OriginalURL mapping)
wget https://storage.googleapis.com/openimages/2018_04/train/train-images-boxable-with-rotation.csv
# Map urls to local paths
python map_openimage_url_to_local.py #please modify variable is_multi_turn and file paths as needed
라이선스
Pico-Banana-400K 데이터셋은 Creative Commons의 Attribution–NonCommercial–NoDerivatives (CC BY-NC-ND 4.0) 라이선스로 공개되어 있습니다. 이 CC BY-NC-ND 4.0 라이선스는 비상업적 연구 목적으로 사용이 가능하며, 상업적 이용 및 2차 배포는 금지됩니다. 자세한 내용은 라이선스 원문을 참고해주세요.
또한, 원본 이미지(Open Images)는 CC BY 2.0 라이선스를 따르므로 이 또한 준수해야 합니다.
 Pico-Banana-400K 데이터셋 GitHub 저장소
Pico-Banana-400K 데이터셋 GitHub 저장소
https://github.com/apple/pico-banana-400k
 Pico-Banana-400K 관련 논문
Pico-Banana-400K 관련 논문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()